

Commit
·
1c8d125
1
Parent(s):
c02fe3a
initial commit
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitignore +167 -0
- README.md +128 -2
- configs/example.yaml +118 -0
- data/nan_stats.json +0 -0
- examples/generate_synthetic_data.py +324 -0
- examples/quick_start_tempo_pfn.ipynb +286 -0
- examples/quick_start_tempo_pfn.py +95 -0
- examples/utils.py +115 -0
- gift_eval/submission/all_results.csv +98 -0
- gift_eval/submission/config.json +6 -0
- pyproject.toml +57 -0
- src/__init__.py +0 -0
- src/data/__init__.py +0 -0
- src/data/augmentations.py +1318 -0
- src/data/batch_composer.py +705 -0
- src/data/constants.py +25 -0
- src/data/containers.py +272 -0
- src/data/datasets.py +267 -0
- src/data/filter.py +73 -0
- src/data/frequency.py +538 -0
- src/data/loaders.py +661 -0
- src/data/scalers.py +360 -0
- src/data/time_features.py +564 -0
- src/data/utils.py +75 -0
- src/gift_eval/__init__.py +0 -0
- src/gift_eval/aggregate_results.py +160 -0
- src/gift_eval/constants.py +83 -0
- src/gift_eval/data.py +234 -0
- src/gift_eval/dataset_properties.json +152 -0
- src/gift_eval/evaluate.py +529 -0
- src/gift_eval/model_wrapper.py +349 -0
- src/models/__init__.py +0 -0
- src/models/blocks.py +58 -0
- src/models/model.py +427 -0
- src/optim/lr_scheduler.py +360 -0
- src/plotting/__init__.py +0 -0
- src/plotting/gift_eval_utils.py +215 -0
- src/plotting/plot_timeseries.py +292 -0
- src/synthetic_generation/__init__.py +0 -0
- src/synthetic_generation/abstract_classes.py +97 -0
- src/synthetic_generation/anomalies/anomaly_generator.py +293 -0
- src/synthetic_generation/anomalies/anomaly_generator_wrapper.py +64 -0
- src/synthetic_generation/audio_generators/financial_volatility_generator.py +103 -0
- src/synthetic_generation/audio_generators/financial_volatility_wrapper.py +91 -0
- src/synthetic_generation/audio_generators/multi_scale_fractal_generator.py +75 -0
- src/synthetic_generation/audio_generators/multi_scale_fractal_wrapper.py +77 -0
- src/synthetic_generation/audio_generators/network_topology_generator.py +113 -0
- src/synthetic_generation/audio_generators/network_topology_wrapper.py +93 -0
- src/synthetic_generation/audio_generators/stochastic_rhythm_generator.py +86 -0
- src/synthetic_generation/audio_generators/stochastic_rhythm_wrapper.py +81 -0
.gitignore
ADDED
|
@@ -0,0 +1,167 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
logs/
|
| 2 |
+
*.png
|
| 3 |
+
*.pth
|
| 4 |
+
# *.sh
|
| 5 |
+
*.slurm
|
| 6 |
+
*.pkl
|
| 7 |
+
|
| 8 |
+
wandb/
|
| 9 |
+
AutogluonModels/
|
| 10 |
+
.vscode/
|
| 11 |
+
|
| 12 |
+
# Byte-compiled / optimized / DLL files
|
| 13 |
+
__pycache__/
|
| 14 |
+
*.py[cod]
|
| 15 |
+
*$py.class
|
| 16 |
+
|
| 17 |
+
# C extensions
|
| 18 |
+
*.so
|
| 19 |
+
|
| 20 |
+
# Distribution / packaging
|
| 21 |
+
.Python
|
| 22 |
+
build/
|
| 23 |
+
develop-eggs/
|
| 24 |
+
dist/
|
| 25 |
+
downloads/
|
| 26 |
+
eggs/
|
| 27 |
+
.eggs/
|
| 28 |
+
lib/
|
| 29 |
+
lib64/
|
| 30 |
+
parts/
|
| 31 |
+
sdist/
|
| 32 |
+
var/
|
| 33 |
+
wheels/
|
| 34 |
+
share/python-wheels/
|
| 35 |
+
*.egg-info/
|
| 36 |
+
.installed.cfg
|
| 37 |
+
*.egg
|
| 38 |
+
MANIFEST
|
| 39 |
+
|
| 40 |
+
# PyInstaller
|
| 41 |
+
# Usually these files are written by a python script from a template
|
| 42 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 43 |
+
*.manifest
|
| 44 |
+
*.spec
|
| 45 |
+
|
| 46 |
+
# Installer logs
|
| 47 |
+
pip-log.txt
|
| 48 |
+
pip-delete-this-directory.txt
|
| 49 |
+
|
| 50 |
+
# Unit test / coverage reports
|
| 51 |
+
htmlcov/
|
| 52 |
+
.tox/
|
| 53 |
+
.nox/
|
| 54 |
+
.coverage
|
| 55 |
+
.coverage.*
|
| 56 |
+
.cache
|
| 57 |
+
nosetests.xml
|
| 58 |
+
coverage.xml
|
| 59 |
+
*.cover
|
| 60 |
+
*.py,cover
|
| 61 |
+
.hypothesis/
|
| 62 |
+
.pytest_cache/
|
| 63 |
+
cover/
|
| 64 |
+
|
| 65 |
+
# PyBuilder
|
| 66 |
+
.pybuilder/
|
| 67 |
+
target/
|
| 68 |
+
|
| 69 |
+
# Jupyter Notebook
|
| 70 |
+
.ipynb_checkpoints
|
| 71 |
+
|
| 72 |
+
# IPython
|
| 73 |
+
profile_default/
|
| 74 |
+
ipython_config.py
|
| 75 |
+
|
| 76 |
+
# pyenv
|
| 77 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 78 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 79 |
+
# .python-version
|
| 80 |
+
|
| 81 |
+
# pipenv
|
| 82 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 83 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 84 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 85 |
+
# install all needed dependencies.
|
| 86 |
+
#Pipfile.lock
|
| 87 |
+
|
| 88 |
+
# UV
|
| 89 |
+
# Similar to Pipfile.lock, it is generally recommended to include uv.lock in version control.
|
| 90 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 91 |
+
# commonly ignored for libraries.
|
| 92 |
+
#uv.lock
|
| 93 |
+
|
| 94 |
+
# poetry
|
| 95 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 96 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 97 |
+
# commonly ignored for libraries.
|
| 98 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 99 |
+
#poetry.lock
|
| 100 |
+
|
| 101 |
+
# pdm
|
| 102 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 103 |
+
#pdm.lock
|
| 104 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 105 |
+
# in version control.
|
| 106 |
+
# https://pdm.fming.dev/latest/usage/project/#working-with-version-control
|
| 107 |
+
.pdm.toml
|
| 108 |
+
.pdm-python
|
| 109 |
+
.pdm-build/
|
| 110 |
+
|
| 111 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 112 |
+
__pypackages__/
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
# SageMath parsed files
|
| 116 |
+
*.sage.py
|
| 117 |
+
|
| 118 |
+
# Environments
|
| 119 |
+
.env
|
| 120 |
+
.venv
|
| 121 |
+
env/
|
| 122 |
+
venv/
|
| 123 |
+
ENV/
|
| 124 |
+
env.bak/
|
| 125 |
+
venv.bak/
|
| 126 |
+
|
| 127 |
+
# Spyder project settings
|
| 128 |
+
.spyderproject
|
| 129 |
+
.spyproject
|
| 130 |
+
|
| 131 |
+
# Rope project settings
|
| 132 |
+
.ropeproject
|
| 133 |
+
|
| 134 |
+
# mkdocs documentation
|
| 135 |
+
/site
|
| 136 |
+
|
| 137 |
+
# mypy
|
| 138 |
+
.mypy_cache/
|
| 139 |
+
.dmypy.json
|
| 140 |
+
dmypy.json
|
| 141 |
+
|
| 142 |
+
# Pyre type checker
|
| 143 |
+
.pyre/
|
| 144 |
+
|
| 145 |
+
# pytype static type analyzer
|
| 146 |
+
.pytype/
|
| 147 |
+
|
| 148 |
+
# Cython debug symbols
|
| 149 |
+
cython_debug/
|
| 150 |
+
|
| 151 |
+
.idea/
|
| 152 |
+
|
| 153 |
+
# Ruff stuff:
|
| 154 |
+
.ruff_cache/
|
| 155 |
+
|
| 156 |
+
# PyPI configuration file
|
| 157 |
+
.pypirc
|
| 158 |
+
|
| 159 |
+
# Datasets, logs, plots, etc.
|
| 160 |
+
outputs/
|
| 161 |
+
models/*
|
| 162 |
+
|
| 163 |
+
*.arrow
|
| 164 |
+
*.png
|
| 165 |
+
*.pt
|
| 166 |
+
*.pdf
|
| 167 |
+
*.gif
|
README.md
CHANGED
|
@@ -1,2 +1,128 @@
|
|
| 1 |
-
# TempoPFN
|
| 2 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# TempoPFN: Synthetic Pre-Training of Linear RNNs for Zero-Shot Time Series Forecasting
|
| 2 |
+
|
| 3 |
+
[](https://arxiv.org/abs/2510.25502)
|
| 4 |
+
[](https://github.com/automl/TempoPFN/blob/main/LICENSE)
|
| 5 |
+
|
| 6 |
+
---
|
| 7 |
+
|
| 8 |
+
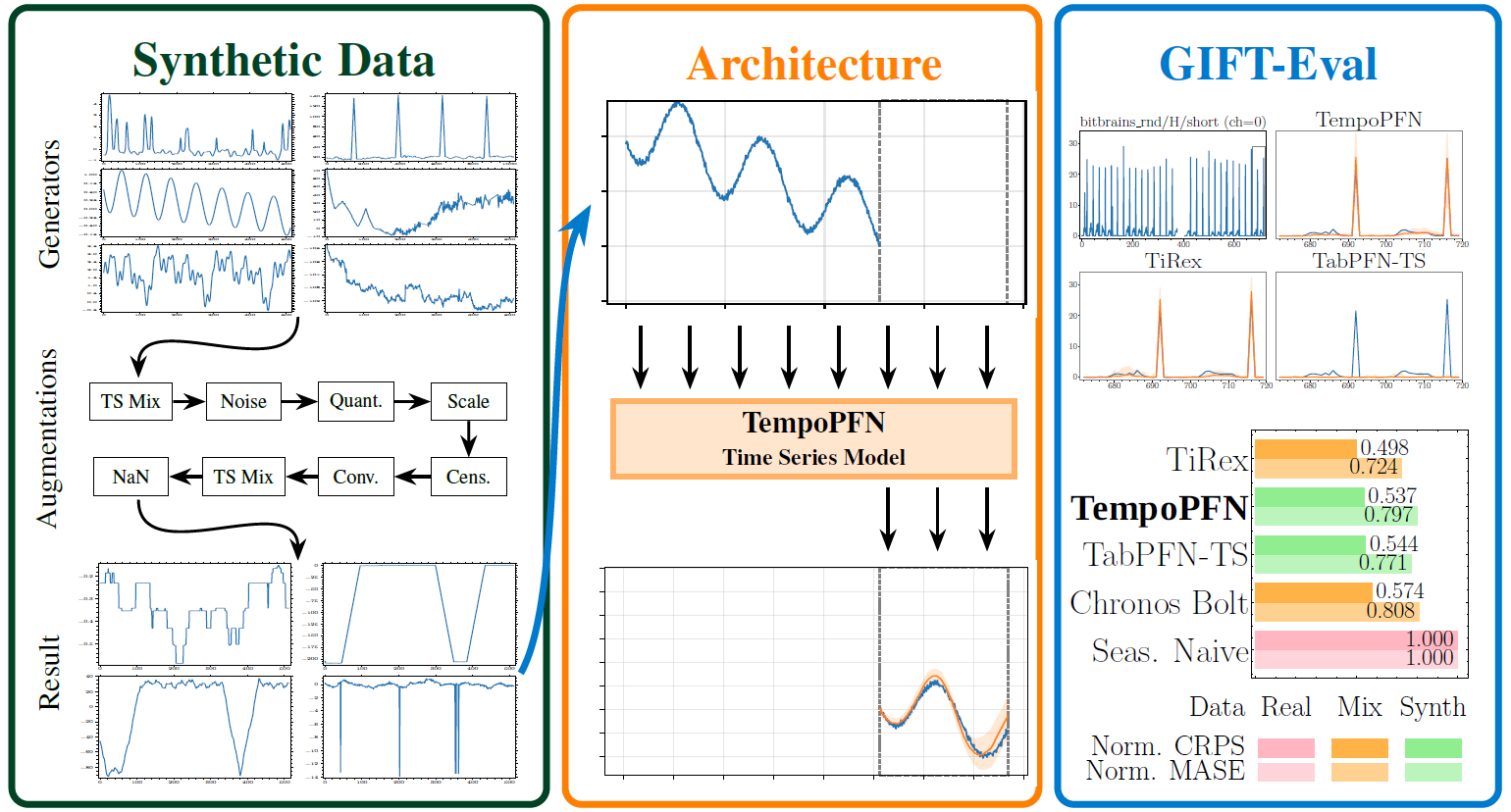
**TempoPFN** introduced in [TempoPFN: Synthetic Pre-Training of Linear RNNs for Zero-Shot Time Series Forecasting](https://arxiv.org/abs/2510.25502), is a univariate time series foundation model pretrained **entirely on synthetic data**. It delivers top-tier zero-shot forecasting accuracy while remaining fully reproducible and free from real-data leakage.
|
| 9 |
+
|
| 10 |
+
Built on a **Linear RNN (GatedDeltaProduct)** backbone, TempoPFN performs end-to-end forecasting without patching or windowing. Its design enables fully parallelizable training and inference while maintaining stable temporal state-tracking across long sequences.
|
| 11 |
+
|
| 12 |
+
This repository includes the [**pretrained 35M parameter model,**](https://www.dropbox.com/scl/fi/5vmjr7nx9wj9w1vl2giuv/checkpoint.pth?rlkey=qmk08ojp7wj0l6kpm8hzgbzju&st=dyr07d00&dl=0), all training and inference code, and the **complete synthetic data generation pipeline** used for pretraining.
|
| 13 |
+
|
| 14 |
+
## ✨ Why TempoPFN?
|
| 15 |
+
|
| 16 |
+
* **High Performance, No Real Data:** Achieves top-tier competitive results on **GIFT-Eval, outperforming all existing synthetic-only approaches** and **surpassing the vast majority of models trained on real-world data**. This ensures full reproducibility and eliminates benchmark leakage.
|
| 17 |
+
* **Parallel and Efficient:** The linear recurrence design enables full-sequence parallelization. This gives us the best of both worlds: the linear efficiency of an RNN, but with the training parallelism of a Transformer.
|
| 18 |
+
* **Open and Reproducible:** Includes the full synthetic data pipeline, configurations, and scripts to reproduce training from scratch.
|
| 19 |
+
* **State-Tracking Stability:** The GatedDeltaProduct recurrence and *state-weaving* mechanism preserve temporal continuity and information flow across long horizons, improving robustness without non-linear recurrence.
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
## ⚙️ Installation
|
| 25 |
+
|
| 26 |
+
```bash
|
| 27 |
+
git clone https://github.com/automl/TempoPFN.git
|
| 28 |
+
cd TempoPFN
|
| 29 |
+
python -m venv venv && source venv/bin/activate
|
| 30 |
+
|
| 31 |
+
# 1. Install PyTorch first (see PyTorch website for your specific CUDA version)
|
| 32 |
+
# Example for CUDA 12.6:
|
| 33 |
+
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
|
| 34 |
+
|
| 35 |
+
# 2. Install TempoPFN and all other dependencies
|
| 36 |
+
pip install .
|
| 37 |
+
export PYTHONPATH=$PWD
|
| 38 |
+
```
|
| 39 |
+
|
| 40 |
+
## 🚀 Quick Start: Run the Demo
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
**Prerequisites:**
|
| 45 |
+
* You must have a **CUDA-capable GPU** with a matching PyTorch version installed.
|
| 46 |
+
* You have run `export PYTHONPATH=$PWD` from the repo's root directory (see Installation).
|
| 47 |
+
|
| 48 |
+
### 1. Run the Quick Start Script
|
| 49 |
+
|
| 50 |
+
Run a demo forecast on a synthetic sine wave:
|
| 51 |
+
```bash
|
| 52 |
+
python examples/quick_start_tempo_pfn.py
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
### 2. Run with a Local Checkpoint
|
| 56 |
+
|
| 57 |
+
If you have already downloaded the model (e.g., to `models/checkpoint.pth`), you can point the script to it:
|
| 58 |
+
```bash
|
| 59 |
+
python examples/quick_start_tempo_pfn.py --checkpoint models/checkpoint.pth
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
### 3. Run the Notebook version
|
| 63 |
+
|
| 64 |
+
```bash
|
| 65 |
+
jupyter notebook examples/quick_start_tempo_pfn.ipynb
|
| 66 |
+
```
|
| 67 |
+
|
| 68 |
+
### Hardware & Performance Tips
|
| 69 |
+
|
| 70 |
+
**GPU Required:** Inference requires a CUDA-capable GPU. Tested on NVIDIA A100/H100.
|
| 71 |
+
|
| 72 |
+
**Triton Caches:** To prevent slowdowns from writing caches to a network filesystem, route caches to a local directory (like `/tmp`) before running:
|
| 73 |
+
```bash
|
| 74 |
+
LOCAL_CACHE_BASE="${TMPDIR:-/tmp}/tsf-$(date +%s)"
|
| 75 |
+
mkdir -p "${LOCAL_CACHE_BASE}/triton" "${LOCAL_CACHE_BASE}/torchinductor"
|
| 76 |
+
export TRITON_CACHE_DIR="${LOCAL_CACHE_BASE}/triton"
|
| 77 |
+
export TORCHINDUCTOR_CACHE_DIR="${LOCAL_CACHE_BASE}/torchinductor"
|
| 78 |
+
|
| 79 |
+
python examples/quick_start_tempo_pfn.py
|
| 80 |
+
```
|
| 81 |
+
|
| 82 |
+
## 🚂 Training
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
### Single-GPU Training (for debugging)
|
| 86 |
+
```bash
|
| 87 |
+
torchrun --standalone --nproc_per_node=1 src/training/trainer_dist.py --config ./configs/train.yaml
|
| 88 |
+
```
|
| 89 |
+
|
| 90 |
+
### Multi-GPU Training (Single-Node)
|
| 91 |
+
|
| 92 |
+
This example uses 8 GPUs. The training script uses PyTorch DistributedDataParallel (DDP).
|
| 93 |
+
```bash
|
| 94 |
+
torchrun --standalone --nproc_per_node=8 src/training/trainer_dist.py --config ./configs/train.yaml
|
| 95 |
+
```
|
| 96 |
+
|
| 97 |
+
### Configuration
|
| 98 |
+
|
| 99 |
+
All training and model parameters are controlled via YAML files in `configs/` (architecture, optimizers, paths).
|
| 100 |
+
|
| 101 |
+
## 💾 Synthetic Data Generation
|
| 102 |
+
|
| 103 |
+
A core contribution of this work is our open-source synthetic data pipeline, located in `src/synthetic_generation/`. It combines diverse generators with a powerful augmentation cascade.
|
| 104 |
+
|
| 105 |
+
**Generators Used:**
|
| 106 |
+
|
| 107 |
+
* **Adapted Priors:** ForecastPFN, KernelSynth, GaussianProcess (GP), and CauKer (Structural Causal Models).
|
| 108 |
+
* **Novel Priors:** SDE (a flexible regime-switching Ornstein-Uhlenbeck process), Sawtooth, StepFunction, Anomaly, Spikes, SineWave, and Audio-Inspired generators (Stochastic Rhythms, Financial Volatility, Network Topology, Multi-Scale Fractals).
|
| 109 |
+
|
| 110 |
+
You can easily generate your own data by instantiating a generator wrapper. See `examples/generate_synthetic_data.py` for a minimal script, or inspect the generator code in `src/synthetic_generation/`.
|
| 111 |
+
|
| 112 |
+
## 🤝 License
|
| 113 |
+
|
| 114 |
+
This project is licensed under the Apache 2.0 License. See the LICENSE file for details. This permissive license allows for both academic and commercial use.
|
| 115 |
+
|
| 116 |
+
## 📚 Citation
|
| 117 |
+
|
| 118 |
+
If you find TempoPFN useful in your research, please consider citing our paper:
|
| 119 |
+
```bibtex
|
| 120 |
+
@misc{moroshan2025tempopfn,
|
| 121 |
+
title={TempoPFN: Synthetic Pre-Training of Linear RNNs for Zero-Shot Time Series Forecasting},
|
| 122 |
+
author={Vladyslav Moroshan and Julien Siems and Arber Zela and Timur Carstensen and Frank Hutter},
|
| 123 |
+
year={2025},
|
| 124 |
+
eprint={2510.25502},
|
| 125 |
+
archivePrefix={arXiv},
|
| 126 |
+
primaryClass={cs.LG}
|
| 127 |
+
}
|
| 128 |
+
```
|
configs/example.yaml
ADDED
|
@@ -0,0 +1,118 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
train_data_path: null # Replace with the path to root of the training data directory with subdirectories for each generator (e.g. gp, kernel, etc.)
|
| 2 |
+
model_path: ./models # Path where the model will be saved
|
| 3 |
+
model_name: TempoPFN
|
| 4 |
+
continue_training: false
|
| 5 |
+
checkpoint_path: null # Replace with the path to the checkpoint file
|
| 6 |
+
seed: 2025
|
| 7 |
+
wandb: true # whether to log to wandb
|
| 8 |
+
wandb_project_name: TempoPFNTraining
|
| 9 |
+
wandb_entity: university-of-freiburg-2024
|
| 10 |
+
wandb_plots: false
|
| 11 |
+
|
| 12 |
+
batch_size: 40
|
| 13 |
+
num_training_iterations: 1000000 # 1M
|
| 14 |
+
validation_batch_size: 64
|
| 15 |
+
num_validation_batches: 1
|
| 16 |
+
num_workers: 4
|
| 17 |
+
gradient_accumulation_enabled: true
|
| 18 |
+
accumulation_steps: 5 # Number of batches to accumulate before updating (effective batch size = batch_size * accumulation_steps)
|
| 19 |
+
log_interval: 2048
|
| 20 |
+
save_every: 100000
|
| 21 |
+
|
| 22 |
+
generator_proportions:
|
| 23 |
+
forecast_pfn: 1.0
|
| 24 |
+
gp: 1.0
|
| 25 |
+
kernel: 1.0
|
| 26 |
+
sawtooth: 1.0
|
| 27 |
+
sinewave: 1.0
|
| 28 |
+
step: 1.0
|
| 29 |
+
anomaly: 1.0
|
| 30 |
+
spike: 1.0
|
| 31 |
+
cauker_univariate: 1.0
|
| 32 |
+
ou_process: 3.0
|
| 33 |
+
audio_financial_volatility: 0.1
|
| 34 |
+
audio_multi_scale_fractal: 0.1
|
| 35 |
+
audio_network_topology: 0.5
|
| 36 |
+
audio_stochastic_rhythm: 0.5
|
| 37 |
+
augmented_per_sample_2048: 2.0
|
| 38 |
+
augmented_temp_batch_2048: 2.0
|
| 39 |
+
|
| 40 |
+
# Learning Rate Scheduler Configuration
|
| 41 |
+
lr_scheduler: cosine # Options: "warmup_stable_decay", "cosine_with_warmup", "cosine_with_restarts", "cosine"
|
| 42 |
+
|
| 43 |
+
# Learning Rate Parameters
|
| 44 |
+
peak_lr: 0.0002 # 2e-4 - Peak learning rate
|
| 45 |
+
min_lr_ratio: 0.01 # Minimum LR as fraction of peak LR
|
| 46 |
+
|
| 47 |
+
# WSD Scheduler Specific Parameters
|
| 48 |
+
warmup_ratio: 0.003 # 0.3% of total steps for warmup
|
| 49 |
+
stable_ratio: 0.90 # 90% of total steps at stable learning rate
|
| 50 |
+
decay_type: cosine # Type of decay: "cosine" or "linear"
|
| 51 |
+
|
| 52 |
+
# Alternative Scheduler Parameters (if using different schedulers)
|
| 53 |
+
num_cycles: 0.5 # For cosine_with_warmup: 0.5 = half cosine wave
|
| 54 |
+
num_restart_cycles: 4 # For cosine_with_restarts: number of restart cycles
|
| 55 |
+
|
| 56 |
+
# Optimizer Configuration
|
| 57 |
+
weight_decay: 0.01 # Weight decay for AdamW
|
| 58 |
+
beta1: 0.9 # Adam beta1 parameter
|
| 59 |
+
beta2: 0.98 # Adam beta2 parameter (optimized for transformers)
|
| 60 |
+
optimizer_eps: 1e-6 # Adam epsilon
|
| 61 |
+
|
| 62 |
+
# Training Stability
|
| 63 |
+
gradient_clip_val: 100.0
|
| 64 |
+
scaler: custom_robust
|
| 65 |
+
|
| 66 |
+
gift_eval:
|
| 67 |
+
evaluate_on_gift_eval: false
|
| 68 |
+
max_context_length: 3072
|
| 69 |
+
create_plots: false
|
| 70 |
+
max_plots: 5
|
| 71 |
+
dataset_storage_path: null # Replace with the path to the dataset storage path
|
| 72 |
+
|
| 73 |
+
data_augmentation:
|
| 74 |
+
nan_augmentation: true
|
| 75 |
+
scaler_augmentation: false
|
| 76 |
+
length_shortening: true
|
| 77 |
+
nan_stats_path: ./data/nan_stats.json
|
| 78 |
+
|
| 79 |
+
augmentation_probabilities:
|
| 80 |
+
scaler_augmentation: 0.5
|
| 81 |
+
|
| 82 |
+
TimeSeriesModel:
|
| 83 |
+
# Core architecture
|
| 84 |
+
embed_size: 512
|
| 85 |
+
num_encoder_layers: 10
|
| 86 |
+
|
| 87 |
+
# Scaling and preprocessing
|
| 88 |
+
scaler: custom_robust
|
| 89 |
+
epsilon: 0.00001
|
| 90 |
+
scaler_clamp_value: null
|
| 91 |
+
handle_constants: false
|
| 92 |
+
|
| 93 |
+
# Time features
|
| 94 |
+
K_max: 25
|
| 95 |
+
time_feature_config:
|
| 96 |
+
use_enhanced_features: true
|
| 97 |
+
use_holiday_features: false
|
| 98 |
+
use_index_features: true
|
| 99 |
+
include_seasonality_info: true
|
| 100 |
+
|
| 101 |
+
drop_enc_allow: false
|
| 102 |
+
encoding_dropout: 0.0
|
| 103 |
+
|
| 104 |
+
# Encoder configuration
|
| 105 |
+
encoder_config:
|
| 106 |
+
attn_mode: chunk
|
| 107 |
+
num_heads: 4
|
| 108 |
+
expand_v: 1.0
|
| 109 |
+
use_gate: false
|
| 110 |
+
use_short_conv: true
|
| 111 |
+
conv_size: 16
|
| 112 |
+
allow_neg_eigval: true
|
| 113 |
+
use_forget_gate: true
|
| 114 |
+
num_householder: 4
|
| 115 |
+
weaving: true
|
| 116 |
+
|
| 117 |
+
loss_type: 'quantile'
|
| 118 |
+
quantiles: [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]
|
data/nan_stats.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
examples/generate_synthetic_data.py
ADDED
|
@@ -0,0 +1,324 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import os
|
| 3 |
+
from typing import Optional
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
|
| 7 |
+
from src.data.containers import BatchTimeSeriesContainer
|
| 8 |
+
from src.data.utils import sample_future_length
|
| 9 |
+
from src.plotting.plot_multivariate_timeseries import plot_from_container
|
| 10 |
+
from src.synthetic_generation.anomalies.anomaly_generator_wrapper import (
|
| 11 |
+
AnomalyGeneratorWrapper,
|
| 12 |
+
)
|
| 13 |
+
from src.synthetic_generation.audio_generators.financial_volatility_wrapper import (
|
| 14 |
+
FinancialVolatilityAudioWrapper,
|
| 15 |
+
)
|
| 16 |
+
from src.synthetic_generation.audio_generators.multi_scale_fractal_wrapper import (
|
| 17 |
+
MultiScaleFractalAudioWrapper,
|
| 18 |
+
)
|
| 19 |
+
from src.synthetic_generation.audio_generators.network_topology_wrapper import (
|
| 20 |
+
NetworkTopologyAudioWrapper,
|
| 21 |
+
)
|
| 22 |
+
from src.synthetic_generation.audio_generators.stochastic_rhythm_wrapper import (
|
| 23 |
+
StochasticRhythmAudioWrapper,
|
| 24 |
+
)
|
| 25 |
+
from src.synthetic_generation.cauker.cauker_generator_wrapper import (
|
| 26 |
+
CauKerGeneratorWrapper,
|
| 27 |
+
)
|
| 28 |
+
from src.synthetic_generation.forecast_pfn_prior.forecast_pfn_generator_wrapper import (
|
| 29 |
+
ForecastPFNGeneratorWrapper,
|
| 30 |
+
)
|
| 31 |
+
from src.synthetic_generation.generator_params import (
|
| 32 |
+
AnomalyGeneratorParams,
|
| 33 |
+
CauKerGeneratorParams,
|
| 34 |
+
FinancialVolatilityAudioParams,
|
| 35 |
+
ForecastPFNGeneratorParams,
|
| 36 |
+
GPGeneratorParams,
|
| 37 |
+
KernelGeneratorParams,
|
| 38 |
+
MultiScaleFractalAudioParams,
|
| 39 |
+
NetworkTopologyAudioParams,
|
| 40 |
+
OrnsteinUhlenbeckProcessGeneratorParams,
|
| 41 |
+
SawToothGeneratorParams,
|
| 42 |
+
SineWaveGeneratorParams,
|
| 43 |
+
SpikesGeneratorParams,
|
| 44 |
+
StepGeneratorParams,
|
| 45 |
+
StochasticRhythmAudioParams,
|
| 46 |
+
)
|
| 47 |
+
from src.synthetic_generation.gp_prior.gp_generator_wrapper import (
|
| 48 |
+
GPGeneratorWrapper,
|
| 49 |
+
)
|
| 50 |
+
from src.synthetic_generation.kernel_synth.kernel_generator_wrapper import (
|
| 51 |
+
KernelGeneratorWrapper,
|
| 52 |
+
)
|
| 53 |
+
from src.synthetic_generation.ornstein_uhlenbeck_process.ou_generator_wrapper import (
|
| 54 |
+
OrnsteinUhlenbeckProcessGeneratorWrapper,
|
| 55 |
+
)
|
| 56 |
+
from src.synthetic_generation.sawtooth.sawtooth_generator_wrapper import (
|
| 57 |
+
SawToothGeneratorWrapper,
|
| 58 |
+
)
|
| 59 |
+
from src.synthetic_generation.sine_waves.sine_wave_generator_wrapper import (
|
| 60 |
+
SineWaveGeneratorWrapper,
|
| 61 |
+
)
|
| 62 |
+
from src.synthetic_generation.spikes.spikes_generator_wrapper import (
|
| 63 |
+
SpikesGeneratorWrapper,
|
| 64 |
+
)
|
| 65 |
+
from src.synthetic_generation.steps.step_generator_wrapper import (
|
| 66 |
+
StepGeneratorWrapper,
|
| 67 |
+
)
|
| 68 |
+
|
| 69 |
+
# Configure logging
|
| 70 |
+
logging.basicConfig(
|
| 71 |
+
level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s"
|
| 72 |
+
)
|
| 73 |
+
logger = logging.getLogger(__name__)
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def visualize_batch_sample(
|
| 77 |
+
generator,
|
| 78 |
+
batch_size: int = 8,
|
| 79 |
+
output_dir: str = "outputs/plots",
|
| 80 |
+
sample_idx: Optional[int] = None,
|
| 81 |
+
prefix: str = "",
|
| 82 |
+
seed: Optional[int] = None,
|
| 83 |
+
) -> None:
|
| 84 |
+
"""
|
| 85 |
+
Visualize a sample from a batch of synthetic multivariate time series from any generator.
|
| 86 |
+
Also plot artificial predictions for demonstration if requested.
|
| 87 |
+
|
| 88 |
+
Args:
|
| 89 |
+
generator: Any generator wrapper (LMC, Kernel, GP, etc.)
|
| 90 |
+
batch_size: Number of samples to generate in the batch
|
| 91 |
+
output_dir: Directory to save plots
|
| 92 |
+
sample_idx: Index of the sample to visualize
|
| 93 |
+
seed: Seed for the generator
|
| 94 |
+
"""
|
| 95 |
+
os.makedirs(output_dir, exist_ok=True)
|
| 96 |
+
|
| 97 |
+
generator_name = generator.__class__.__name__
|
| 98 |
+
logger.info(f"[{generator_name}] Generating batch of size {batch_size}")
|
| 99 |
+
|
| 100 |
+
batch = generator.generate_batch(batch_size=batch_size, seed=seed)
|
| 101 |
+
values = torch.from_numpy(batch.values)
|
| 102 |
+
if values.ndim == 2:
|
| 103 |
+
values = values.unsqueeze(-1) # Add channel dimension: [batch_size, seq_len, 1]
|
| 104 |
+
|
| 105 |
+
future_length = sample_future_length(range="gift_eval")
|
| 106 |
+
# Slice along the time dimension (dimension 1)
|
| 107 |
+
history_values = values[:, :-future_length, :]
|
| 108 |
+
future_values = values[:, -future_length:, :]
|
| 109 |
+
|
| 110 |
+
batch = BatchTimeSeriesContainer(
|
| 111 |
+
history_values=history_values,
|
| 112 |
+
future_values=future_values,
|
| 113 |
+
start=batch.start,
|
| 114 |
+
frequency=batch.frequency,
|
| 115 |
+
)
|
| 116 |
+
|
| 117 |
+
logger.info(
|
| 118 |
+
f"[{generator_name}] Batch history values shape: {batch.history_values.shape}"
|
| 119 |
+
)
|
| 120 |
+
logger.info(
|
| 121 |
+
f"[{generator_name}] Batch future values shape: {batch.future_values.shape}"
|
| 122 |
+
)
|
| 123 |
+
logger.info(f"[{generator_name}] Batch start: {batch.start}")
|
| 124 |
+
logger.info(f"[{generator_name}] Batch frequency: {batch.frequency}")
|
| 125 |
+
|
| 126 |
+
if sample_idx is None:
|
| 127 |
+
for sample_idx in range(batch_size):
|
| 128 |
+
filename = f"{prefix}_{generator_name.lower().replace('generatorwrapper', '')}_sample_{sample_idx}.png"
|
| 129 |
+
output_file = os.path.join(output_dir, filename)
|
| 130 |
+
title = f"{prefix.capitalize()} {generator_name.replace('GeneratorWrapper', '')} Synthetic Time Series (Sample {sample_idx})"
|
| 131 |
+
|
| 132 |
+
plot_from_container(
|
| 133 |
+
batch=batch,
|
| 134 |
+
sample_idx=sample_idx,
|
| 135 |
+
output_file=output_file,
|
| 136 |
+
show=False,
|
| 137 |
+
title=title,
|
| 138 |
+
)
|
| 139 |
+
logger.info(
|
| 140 |
+
f"[{generator_name}] Saved plot for sample {sample_idx} to {output_file}"
|
| 141 |
+
)
|
| 142 |
+
logger.info("--------------------------------")
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
if __name__ == "__main__":
|
| 146 |
+
# Configuration
|
| 147 |
+
batch_size = 2
|
| 148 |
+
total_length = 2048
|
| 149 |
+
output_dir = "outputs/plots"
|
| 150 |
+
global_seed = 2025
|
| 151 |
+
|
| 152 |
+
logger.info(f"Saving plots to {output_dir}")
|
| 153 |
+
|
| 154 |
+
kernel_params_univariate = KernelGeneratorParams(
|
| 155 |
+
global_seed=global_seed,
|
| 156 |
+
length=total_length,
|
| 157 |
+
)
|
| 158 |
+
kernel_gen_univariate = KernelGeneratorWrapper(kernel_params_univariate)
|
| 159 |
+
|
| 160 |
+
gp_params_univariate = GPGeneratorParams(
|
| 161 |
+
global_seed=global_seed,
|
| 162 |
+
length=total_length,
|
| 163 |
+
)
|
| 164 |
+
gp_gen_univariate = GPGeneratorWrapper(gp_params_univariate)
|
| 165 |
+
|
| 166 |
+
forecast_pfn_univariate_params = ForecastPFNGeneratorParams(
|
| 167 |
+
global_seed=global_seed,
|
| 168 |
+
length=total_length,
|
| 169 |
+
)
|
| 170 |
+
forecast_pfn_univariate_gen = ForecastPFNGeneratorWrapper(
|
| 171 |
+
forecast_pfn_univariate_params
|
| 172 |
+
)
|
| 173 |
+
|
| 174 |
+
sine_wave_params = SineWaveGeneratorParams(
|
| 175 |
+
global_seed=global_seed,
|
| 176 |
+
length=total_length,
|
| 177 |
+
)
|
| 178 |
+
sine_wave_univariate_gen = SineWaveGeneratorWrapper(sine_wave_params)
|
| 179 |
+
|
| 180 |
+
sawtooth_params = SawToothGeneratorParams(
|
| 181 |
+
global_seed=global_seed,
|
| 182 |
+
length=total_length,
|
| 183 |
+
)
|
| 184 |
+
sawtooth_univariate_gen = SawToothGeneratorWrapper(sawtooth_params)
|
| 185 |
+
|
| 186 |
+
step_params = params = StepGeneratorParams(
|
| 187 |
+
length=2048,
|
| 188 |
+
global_seed=42,
|
| 189 |
+
)
|
| 190 |
+
step_gen_univariate = StepGeneratorWrapper(step_params)
|
| 191 |
+
|
| 192 |
+
anomaly_params = AnomalyGeneratorParams(
|
| 193 |
+
global_seed=global_seed,
|
| 194 |
+
length=total_length,
|
| 195 |
+
)
|
| 196 |
+
anomaly_gen_univariate = AnomalyGeneratorWrapper(anomaly_params)
|
| 197 |
+
|
| 198 |
+
spikes_params = SpikesGeneratorParams(
|
| 199 |
+
global_seed=global_seed,
|
| 200 |
+
length=total_length,
|
| 201 |
+
)
|
| 202 |
+
spikes_gen_univariate = SpikesGeneratorWrapper(spikes_params)
|
| 203 |
+
|
| 204 |
+
cauker_params_multivariate = CauKerGeneratorParams(
|
| 205 |
+
global_seed=global_seed,
|
| 206 |
+
length=total_length,
|
| 207 |
+
num_channels=5,
|
| 208 |
+
)
|
| 209 |
+
cauker_gen_multivariate = CauKerGeneratorWrapper(cauker_params_multivariate)
|
| 210 |
+
|
| 211 |
+
ou_params = OrnsteinUhlenbeckProcessGeneratorParams(
|
| 212 |
+
global_seed=global_seed,
|
| 213 |
+
length=total_length,
|
| 214 |
+
)
|
| 215 |
+
ou_gen_univariate = OrnsteinUhlenbeckProcessGeneratorWrapper(ou_params)
|
| 216 |
+
|
| 217 |
+
stochastic_rhythm_params = StochasticRhythmAudioParams(
|
| 218 |
+
global_seed=global_seed,
|
| 219 |
+
length=total_length,
|
| 220 |
+
)
|
| 221 |
+
stochastic_rhythm_gen_univariate = StochasticRhythmAudioWrapper(
|
| 222 |
+
stochastic_rhythm_params
|
| 223 |
+
)
|
| 224 |
+
|
| 225 |
+
financial_volatility_params = FinancialVolatilityAudioParams(
|
| 226 |
+
global_seed=global_seed,
|
| 227 |
+
length=total_length,
|
| 228 |
+
)
|
| 229 |
+
financial_volatility_gen_univariate = FinancialVolatilityAudioWrapper(
|
| 230 |
+
financial_volatility_params
|
| 231 |
+
)
|
| 232 |
+
|
| 233 |
+
multi_scale_fractal_params = MultiScaleFractalAudioParams(
|
| 234 |
+
global_seed=global_seed,
|
| 235 |
+
length=total_length,
|
| 236 |
+
)
|
| 237 |
+
multi_scale_fractal_gen_univariate = MultiScaleFractalAudioWrapper(
|
| 238 |
+
multi_scale_fractal_params
|
| 239 |
+
)
|
| 240 |
+
|
| 241 |
+
network_topology_params = NetworkTopologyAudioParams(
|
| 242 |
+
global_seed=global_seed,
|
| 243 |
+
length=total_length,
|
| 244 |
+
)
|
| 245 |
+
network_topology_gen_univariate = NetworkTopologyAudioWrapper(
|
| 246 |
+
network_topology_params
|
| 247 |
+
)
|
| 248 |
+
|
| 249 |
+
# Visualize samples from all generators
|
| 250 |
+
visualize_batch_sample(
|
| 251 |
+
kernel_gen_univariate, batch_size=batch_size, output_dir=output_dir
|
| 252 |
+
)
|
| 253 |
+
|
| 254 |
+
visualize_batch_sample(
|
| 255 |
+
gp_gen_univariate, batch_size=batch_size, output_dir=output_dir
|
| 256 |
+
)
|
| 257 |
+
|
| 258 |
+
visualize_batch_sample(
|
| 259 |
+
forecast_pfn_univariate_gen, batch_size=batch_size, output_dir=output_dir
|
| 260 |
+
)
|
| 261 |
+
|
| 262 |
+
visualize_batch_sample(
|
| 263 |
+
sine_wave_univariate_gen,
|
| 264 |
+
batch_size=batch_size,
|
| 265 |
+
output_dir=output_dir,
|
| 266 |
+
)
|
| 267 |
+
|
| 268 |
+
visualize_batch_sample(
|
| 269 |
+
sawtooth_univariate_gen,
|
| 270 |
+
batch_size=batch_size,
|
| 271 |
+
output_dir=output_dir,
|
| 272 |
+
)
|
| 273 |
+
|
| 274 |
+
visualize_batch_sample(
|
| 275 |
+
step_gen_univariate,
|
| 276 |
+
batch_size=batch_size,
|
| 277 |
+
output_dir=output_dir,
|
| 278 |
+
)
|
| 279 |
+
|
| 280 |
+
visualize_batch_sample(
|
| 281 |
+
anomaly_gen_univariate,
|
| 282 |
+
batch_size=batch_size,
|
| 283 |
+
output_dir=output_dir,
|
| 284 |
+
)
|
| 285 |
+
|
| 286 |
+
visualize_batch_sample(
|
| 287 |
+
spikes_gen_univariate,
|
| 288 |
+
batch_size=batch_size,
|
| 289 |
+
output_dir=output_dir,
|
| 290 |
+
)
|
| 291 |
+
|
| 292 |
+
visualize_batch_sample(
|
| 293 |
+
cauker_gen_multivariate,
|
| 294 |
+
batch_size=batch_size,
|
| 295 |
+
output_dir=output_dir,
|
| 296 |
+
prefix="multivariate",
|
| 297 |
+
)
|
| 298 |
+
|
| 299 |
+
visualize_batch_sample(
|
| 300 |
+
ou_gen_univariate,
|
| 301 |
+
batch_size=batch_size,
|
| 302 |
+
output_dir=output_dir,
|
| 303 |
+
seed=global_seed,
|
| 304 |
+
)
|
| 305 |
+
|
| 306 |
+
visualize_batch_sample(
|
| 307 |
+
stochastic_rhythm_gen_univariate, batch_size=batch_size, output_dir=output_dir
|
| 308 |
+
)
|
| 309 |
+
|
| 310 |
+
visualize_batch_sample(
|
| 311 |
+
financial_volatility_gen_univariate,
|
| 312 |
+
batch_size=batch_size,
|
| 313 |
+
output_dir=output_dir,
|
| 314 |
+
)
|
| 315 |
+
|
| 316 |
+
visualize_batch_sample(
|
| 317 |
+
multi_scale_fractal_gen_univariate,
|
| 318 |
+
batch_size=batch_size,
|
| 319 |
+
output_dir=output_dir,
|
| 320 |
+
)
|
| 321 |
+
|
| 322 |
+
visualize_batch_sample(
|
| 323 |
+
network_topology_gen_univariate, batch_size=batch_size, output_dir=output_dir
|
| 324 |
+
)
|
examples/quick_start_tempo_pfn.ipynb
ADDED
|
@@ -0,0 +1,286 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "231c6227",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"# Quick Start: Univariate Quantile Forecasting (CUDA, bfloat16)\n",
|
| 9 |
+
"\n",
|
| 10 |
+
"This notebook demonstrates how to:\n",
|
| 11 |
+
"- Generate synthetic sine wave time series data\n",
|
| 12 |
+
"- Pack data into `BatchTimeSeriesContainer`\n",
|
| 13 |
+
"- Load a pretrained model (from Dropbox)\n",
|
| 14 |
+
"- Run inference with bfloat16 on CUDA\n",
|
| 15 |
+
"- Visualize predictions\n"
|
| 16 |
+
]
|
| 17 |
+
},
|
| 18 |
+
{
|
| 19 |
+
"cell_type": "markdown",
|
| 20 |
+
"id": "bb6c5424-1c63-4cb0-a818-45d4199914e5",
|
| 21 |
+
"metadata": {},
|
| 22 |
+
"source": [
|
| 23 |
+
"## 1) Setup"
|
| 24 |
+
]
|
| 25 |
+
},
|
| 26 |
+
{
|
| 27 |
+
"cell_type": "code",
|
| 28 |
+
"execution_count": null,
|
| 29 |
+
"id": "612a78e8",
|
| 30 |
+
"metadata": {},
|
| 31 |
+
"outputs": [],
|
| 32 |
+
"source": [
|
| 33 |
+
"import os\n",
|
| 34 |
+
"import urllib.request\n",
|
| 35 |
+
"import torch\n",
|
| 36 |
+
"import numpy as np\n",
|
| 37 |
+
"from pathlib import Path\n",
|
| 38 |
+
"\n",
|
| 39 |
+
"# Ensure CUDA is available\n",
|
| 40 |
+
"if not torch.cuda.is_available():\n",
|
| 41 |
+
" raise RuntimeError(\"CUDA is required to run this demo. No CUDA device detected.\")\n",
|
| 42 |
+
"\n",
|
| 43 |
+
"device = torch.device(\"cuda:0\")\n",
|
| 44 |
+
"\n",
|
| 45 |
+
"# Resolve repository root to be robust to running from subdirectories (e.g., examples/)\n",
|
| 46 |
+
"repo_root = Path.cwd()\n",
|
| 47 |
+
"if not (repo_root / \"configs\").exists():\n",
|
| 48 |
+
" repo_root = repo_root.parent\n",
|
| 49 |
+
"\n",
|
| 50 |
+
"# Inline plotting\n",
|
| 51 |
+
"%matplotlib inline\n"
|
| 52 |
+
]
|
| 53 |
+
},
|
| 54 |
+
{
|
| 55 |
+
"cell_type": "markdown",
|
| 56 |
+
"id": "3facf37d-0a77-4222-8464-6e42182547f8",
|
| 57 |
+
"metadata": {},
|
| 58 |
+
"source": [
|
| 59 |
+
"## 2) Download checkpoint from Dropbox"
|
| 60 |
+
]
|
| 61 |
+
},
|
| 62 |
+
{
|
| 63 |
+
"cell_type": "code",
|
| 64 |
+
"execution_count": null,
|
| 65 |
+
"id": "16dcb883",
|
| 66 |
+
"metadata": {},
|
| 67 |
+
"outputs": [],
|
| 68 |
+
"source": [
|
| 69 |
+
"DROPBOX_URL = \"https://www.dropbox.com/scl/fi/5vmjr7nx9wj9w1vl2giuv/checkpoint.pth?rlkey=qmk08ojp7wj0l6kpm8hzgbzju&st=dyr07d00&dl=1\"\n",
|
| 70 |
+
"CHECKPOINT_DIR = repo_root / \"models\"\n",
|
| 71 |
+
"CHECKPOINT_PATH = CHECKPOINT_DIR / \"checkpoint.pth\"\n",
|
| 72 |
+
"\n",
|
| 73 |
+
"CHECKPOINT_DIR.mkdir(parents=True, exist_ok=True)\n",
|
| 74 |
+
"if not CHECKPOINT_PATH.exists():\n",
|
| 75 |
+
" print(f\"Downloading checkpoint to {CHECKPOINT_PATH} ...\")\n",
|
| 76 |
+
" urllib.request.urlretrieve(DROPBOX_URL, str(CHECKPOINT_PATH))\n",
|
| 77 |
+
" print(\"Done.\")\n",
|
| 78 |
+
"else:\n",
|
| 79 |
+
" print(f\"Using existing checkpoint at {CHECKPOINT_PATH}\")\n"
|
| 80 |
+
]
|
| 81 |
+
},
|
| 82 |
+
{
|
| 83 |
+
"cell_type": "markdown",
|
| 84 |
+
"id": "9be77e34-0c7a-4056-822f-ed2e3e090c40",
|
| 85 |
+
"metadata": {},
|
| 86 |
+
"source": [
|
| 87 |
+
"## 3) Generate synthetic sine wave data"
|
| 88 |
+
]
|
| 89 |
+
},
|
| 90 |
+
{
|
| 91 |
+
"cell_type": "code",
|
| 92 |
+
"execution_count": null,
|
| 93 |
+
"id": "1127526c",
|
| 94 |
+
"metadata": {},
|
| 95 |
+
"outputs": [],
|
| 96 |
+
"source": [
|
| 97 |
+
"from src.synthetic_generation.generator_params import SineWaveGeneratorParams\n",
|
| 98 |
+
"from src.synthetic_generation.sine_waves.sine_wave_generator_wrapper import (\n",
|
| 99 |
+
" SineWaveGeneratorWrapper,\n",
|
| 100 |
+
")\n",
|
| 101 |
+
"\n",
|
| 102 |
+
"batch_size = 3\n",
|
| 103 |
+
"total_length = 1024\n",
|
| 104 |
+
"seed = 2025\n",
|
| 105 |
+
"\n",
|
| 106 |
+
"sine_params = SineWaveGeneratorParams(global_seed=seed, length=total_length)\n",
|
| 107 |
+
"wrapper = SineWaveGeneratorWrapper(sine_params)\n",
|
| 108 |
+
"\n",
|
| 109 |
+
"batch = wrapper.generate_batch(batch_size=batch_size, seed=seed)\n",
|
| 110 |
+
"values = torch.from_numpy(batch.values).to(torch.float32)\n",
|
| 111 |
+
"if values.ndim == 2:\n",
|
| 112 |
+
" values = values.unsqueeze(-1) # [B, S, 1]\n",
|
| 113 |
+
"\n",
|
| 114 |
+
"future_length = 256\n",
|
| 115 |
+
"history_values = values[:, :-future_length, :]\n",
|
| 116 |
+
"future_values = values[:, -future_length:, :]\n",
|
| 117 |
+
"\n",
|
| 118 |
+
"print(\"History:\", history_values.shape, \"Future:\", future_values.shape)\n"
|
| 119 |
+
]
|
| 120 |
+
},
|
| 121 |
+
{
|
| 122 |
+
"cell_type": "markdown",
|
| 123 |
+
"id": "a8844488-e51c-4805-baa9-491bfc67e8ca",
|
| 124 |
+
"metadata": {},
|
| 125 |
+
"source": [
|
| 126 |
+
"## 4) Build BatchTimeSeriesContainer"
|
| 127 |
+
]
|
| 128 |
+
},
|
| 129 |
+
{
|
| 130 |
+
"cell_type": "code",
|
| 131 |
+
"execution_count": null,
|
| 132 |
+
"id": "f3b4d361",
|
| 133 |
+
"metadata": {},
|
| 134 |
+
"outputs": [],
|
| 135 |
+
"source": [
|
| 136 |
+
"from src.data.containers import BatchTimeSeriesContainer\n",
|
| 137 |
+
"\n",
|
| 138 |
+
"container = BatchTimeSeriesContainer(\n",
|
| 139 |
+
" history_values=history_values.to(device),\n",
|
| 140 |
+
" future_values=future_values.to(device),\n",
|
| 141 |
+
" start=batch.start,\n",
|
| 142 |
+
" frequency=batch.frequency,\n",
|
| 143 |
+
")\n",
|
| 144 |
+
"\n",
|
| 145 |
+
"container.batch_size, container.history_length, container.future_length\n"
|
| 146 |
+
]
|
| 147 |
+
},
|
| 148 |
+
{
|
| 149 |
+
"cell_type": "markdown",
|
| 150 |
+
"id": "b5e7e790-a9aa-49c2-9d45-2dc823036883",
|
| 151 |
+
"metadata": {},
|
| 152 |
+
"source": [
|
| 153 |
+
"## 5) Load model and run inference"
|
| 154 |
+
]
|
| 155 |
+
},
|
| 156 |
+
{
|
| 157 |
+
"cell_type": "code",
|
| 158 |
+
"execution_count": null,
|
| 159 |
+
"id": "1dd4e0e4",
|
| 160 |
+
"metadata": {},
|
| 161 |
+
"outputs": [],
|
| 162 |
+
"source": [
|
| 163 |
+
"import yaml\n",
|
| 164 |
+
"from src.models.model import TimeSeriesModel\n",
|
| 165 |
+
"\n",
|
| 166 |
+
"with open(repo_root / \"configs/example.yaml\", \"r\") as f:\n",
|
| 167 |
+
" config = yaml.safe_load(f)\n",
|
| 168 |
+
"\n",
|
| 169 |
+
"model = TimeSeriesModel(**config[\"TimeSeriesModel\"]).to(device)\n",
|
| 170 |
+
"ckpt = torch.load(CHECKPOINT_PATH, map_location=device)\n",
|
| 171 |
+
"model.load_state_dict(ckpt[\"model_state_dict\"])\n",
|
| 172 |
+
"model.eval()\n",
|
| 173 |
+
"\n",
|
| 174 |
+
"# bfloat16 autocast on CUDA\n",
|
| 175 |
+
"with (\n",
|
| 176 |
+
" torch.no_grad(),\n",
|
| 177 |
+
" torch.autocast(device_type=\"cuda\", dtype=torch.bfloat16, enabled=True),\n",
|
| 178 |
+
"):\n",
|
| 179 |
+
" output = model(container)\n",
|
| 180 |
+
"\n",
|
| 181 |
+
"preds = output[\"result\"].to(torch.float32)\n",
|
| 182 |
+
"if hasattr(model, \"scaler\") and \"scale_statistics\" in output:\n",
|
| 183 |
+
" preds = model.scaler.inverse_scale(preds, output[\"scale_statistics\"])\n",
|
| 184 |
+
"\n",
|
| 185 |
+
"preds.shape\n"
|
| 186 |
+
]
|
| 187 |
+
},
|
| 188 |
+
{
|
| 189 |
+
"cell_type": "markdown",
|
| 190 |
+
"id": "ba16120f-27c8-4462-91cb-c9b3e0630a9d",
|
| 191 |
+
"metadata": {},
|
| 192 |
+
"source": [
|
| 193 |
+
"## 6) Plot predictions"
|
| 194 |
+
]
|
| 195 |
+
},
|
| 196 |
+
{
|
| 197 |
+
"cell_type": "code",
|
| 198 |
+
"execution_count": null,
|
| 199 |
+
"id": "9bf02a0b",
|
| 200 |
+
"metadata": {},
|
| 201 |
+
"outputs": [],
|
| 202 |
+
"source": [
|
| 203 |
+
"import matplotlib.pyplot as plt\n",
|
| 204 |
+
"\n",
|
| 205 |
+
"plt.set_loglevel('error') \n",
|
| 206 |
+
"\n",
|
| 207 |
+
"# preds: [B, P, N, Q] for quantiles (univariate -> N=1)\n",
|
| 208 |
+
"preds_np = preds.cpu().numpy()\n",
|
| 209 |
+
"\n",
|
| 210 |
+
"batch_size = preds_np.shape[0]\n",
|
| 211 |
+
"prediction_length = preds_np.shape[1]\n",
|
| 212 |
+
"num_quantiles = preds_np.shape[-1]\n",
|
| 213 |
+
"\n",
|
| 214 |
+
"for i in range(batch_size):\n",
|
| 215 |
+
" fig, ax = plt.subplots(figsize=(12, 4))\n",
|
| 216 |
+
"\n",
|
| 217 |
+
" history = container.history_values[i, :, 0].detach().cpu().numpy()\n",
|
| 218 |
+
" future = container.future_values[i, :, 0].detach().cpu().numpy()\n",
|
| 219 |
+
"\n",
|
| 220 |
+
" # Time axes\n",
|
| 221 |
+
" hist_t = np.arange(len(history))\n",
|
| 222 |
+
" fut_t = np.arange(len(history), len(history) + len(future))\n",
|
| 223 |
+
"\n",
|
| 224 |
+
" # Plot history and ground truth future\n",
|
| 225 |
+
" ax.plot(hist_t, history, label=\"History\", color=\"black\")\n",
|
| 226 |
+
" ax.plot(fut_t, future, label=\"Ground Truth\", color=\"blue\")\n",
|
| 227 |
+
"\n",
|
| 228 |
+
" # Plot quantiles\n",
|
| 229 |
+
" median_idx = num_quantiles // 2\n",
|
| 230 |
+
" ax.plot(\n",
|
| 231 |
+
" fut_t,\n",
|
| 232 |
+
" preds_np[i, :, 0, median_idx],\n",
|
| 233 |
+
" label=\"Prediction (Median)\",\n",
|
| 234 |
+
" color=\"orange\",\n",
|
| 235 |
+
" linestyle=\"--\",\n",
|
| 236 |
+
" )\n",
|
| 237 |
+
" if num_quantiles >= 3:\n",
|
| 238 |
+
" ax.fill_between(\n",
|
| 239 |
+
" fut_t,\n",
|
| 240 |
+
" preds_np[i, :, 0, 0],\n",
|
| 241 |
+
" preds_np[i, :, 0, -1],\n",
|
| 242 |
+
" color=\"orange\",\n",
|
| 243 |
+
" alpha=0.2,\n",
|
| 244 |
+
" label=\"Prediction Interval\",\n",
|
| 245 |
+
" )\n",
|
| 246 |
+
"\n",
|
| 247 |
+
" ax.axvline(x=len(history), color=\"k\", linestyle=\":\", alpha=0.7)\n",
|
| 248 |
+
" ax.set_xlabel(\"Time Steps\")\n",
|
| 249 |
+
" ax.set_ylabel(\"Value\")\n",
|
| 250 |
+
" ax.set_title(f\"Sample {i + 1}\")\n",
|
| 251 |
+
" ax.legend()\n",
|
| 252 |
+
" ax.grid(True, alpha=0.3)\n",
|
| 253 |
+
" plt.show()\n"
|
| 254 |
+
]
|
| 255 |
+
},
|
| 256 |
+
{
|
| 257 |
+
"cell_type": "code",
|
| 258 |
+
"execution_count": null,
|
| 259 |
+
"id": "d88bb77b-b6be-4b00-a881-a4b556cce86f",
|
| 260 |
+
"metadata": {},
|
| 261 |
+
"outputs": [],
|
| 262 |
+
"source": []
|
| 263 |
+
}
|
| 264 |
+
],
|
| 265 |
+
"metadata": {
|
| 266 |
+
"kernelspec": {
|
| 267 |
+
"display_name": "Python 3 (ipykernel)",
|
| 268 |
+
"language": "python",
|
| 269 |
+
"name": "python3"
|
| 270 |
+
},
|
| 271 |
+
"language_info": {
|
| 272 |
+
"codemirror_mode": {
|
| 273 |
+
"name": "ipython",
|
| 274 |
+
"version": 3
|
| 275 |
+
},
|
| 276 |
+
"file_extension": ".py",
|
| 277 |
+
"mimetype": "text/x-python",
|
| 278 |
+
"name": "python",
|
| 279 |
+
"nbconvert_exporter": "python",
|
| 280 |
+
"pygments_lexer": "ipython3",
|
| 281 |
+
"version": "3.12.9"
|
| 282 |
+
}
|
| 283 |
+
},
|
| 284 |
+
"nbformat": 4,
|
| 285 |
+
"nbformat_minor": 5
|
| 286 |
+
}
|
examples/quick_start_tempo_pfn.py
ADDED
|
@@ -0,0 +1,95 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import logging
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
|
| 6 |
+
from examples.utils import (
|
| 7 |
+
download_checkpoint_if_needed,
|
| 8 |
+
load_model,
|
| 9 |
+
run_inference_and_plot,
|
| 10 |
+
)
|
| 11 |
+
from src.data.containers import BatchTimeSeriesContainer
|
| 12 |
+
from src.synthetic_generation.generator_params import SineWaveGeneratorParams
|
| 13 |
+
from src.synthetic_generation.sine_waves.sine_wave_generator_wrapper import (
|
| 14 |
+
SineWaveGeneratorWrapper,
|
| 15 |
+
)
|
| 16 |
+
|
| 17 |
+
# Configure logging
|
| 18 |
+
logging.basicConfig(
|
| 19 |
+
level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s"
|
| 20 |
+
)
|
| 21 |
+
logger = logging.getLogger(__name__)
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def main():
|
| 25 |
+
"""Main execution function."""
|
| 26 |
+
# CLI
|
| 27 |
+
parser = argparse.ArgumentParser(description="Quick start demo for TimeSeriesModel")
|
| 28 |
+
parser.add_argument(
|
| 29 |
+
"--config",
|
| 30 |
+
default="configs/example.yaml",
|
| 31 |
+
help="Path to model config YAML (default: configs/example.yaml)",
|
| 32 |
+
)
|
| 33 |
+
parser.add_argument(
|
| 34 |
+
"--checkpoint",
|
| 35 |
+
default=None,
|
| 36 |
+
help="Path to model checkpoint. If omitted, downloads from Dropbox.",
|
| 37 |
+
)
|
| 38 |
+
parser.add_argument("--batch_size", type=int, default=3)
|
| 39 |
+
parser.add_argument("--total_length", type=int, default=2048)
|
| 40 |
+
parser.add_argument("--seed", type=int, default=42)
|
| 41 |
+
parser.add_argument("--output_dir", default="outputs")
|
| 42 |
+
args = parser.parse_args()
|
| 43 |
+
|
| 44 |
+
# Configuration
|
| 45 |
+
batch_size = args.batch_size
|
| 46 |
+
total_length = args.total_length
|
| 47 |
+
output_dir = args.output_dir
|
| 48 |
+
seed = args.seed
|
| 49 |
+
|
| 50 |
+
config_path = args.config
|
| 51 |
+
if args.checkpoint:
|
| 52 |
+
model_path = args.checkpoint
|
| 53 |
+
else:
|
| 54 |
+
dropbox_url = "https://www.dropbox.com/scl/fi/5vmjr7nx9wj9w1vl2giuv/checkpoint.pth?rlkey=qmk08ojp7wj0l6kpm8hzgbzju&st=dyr07d00&dl=0"
|
| 55 |
+
model_path = download_checkpoint_if_needed(dropbox_url, target_dir="models")
|
| 56 |
+
|
| 57 |
+
logger.info("=== Time Series Model Demo (Univariate Quantile) ===")
|
| 58 |
+
|
| 59 |
+
# 1) Generate synthetic sine wave data
|
| 60 |
+
sine_params = SineWaveGeneratorParams(global_seed=seed, length=total_length)
|
| 61 |
+
sine_generator = SineWaveGeneratorWrapper(sine_params)
|
| 62 |
+
batch = sine_generator.generate_batch(batch_size=batch_size, seed=seed)
|
| 63 |
+
values = torch.from_numpy(batch.values).to(torch.float32)
|
| 64 |
+
if values.ndim == 2:
|
| 65 |
+
values = values.unsqueeze(-1) # Ensure [B, S, 1] for univariate
|
| 66 |
+
future_length = 256
|
| 67 |
+
history_values = values[:, :-future_length, :]
|
| 68 |
+
future_values = values[:, -future_length:, :]
|
| 69 |
+
|
| 70 |
+
# 2) Load the pretrained model (CUDA-only). This demo requires a CUDA GPU.
|
| 71 |
+
if not torch.cuda.is_available():
|
| 72 |
+
raise RuntimeError(
|
| 73 |
+
"CUDA is required to run this demo. No CUDA device detected."
|
| 74 |
+
)
|
| 75 |
+
device = torch.device("cuda:0")
|
| 76 |
+
model = load_model(config_path=config_path, model_path=model_path, device=device)
|
| 77 |
+
|
| 78 |
+
# 3) Pack tensors into the model's input container
|
| 79 |
+
container = BatchTimeSeriesContainer(
|
| 80 |
+
history_values=history_values.to(device),
|
| 81 |
+
future_values=future_values.to(device),
|
| 82 |
+
start=batch.start,
|
| 83 |
+
frequency=batch.frequency,
|
| 84 |
+
)
|
| 85 |
+
|
| 86 |
+
# 4) Run inference (bfloat16 on CUDA) and plot results
|
| 87 |
+
run_inference_and_plot(
|
| 88 |
+
model=model, container=container, output_dir=output_dir, use_bfloat16=True
|
| 89 |
+
)
|
| 90 |
+
|
| 91 |
+
logger.info("=== Demo completed successfully! ===")
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
if __name__ == "__main__":
|
| 95 |
+
main()
|
examples/utils.py
ADDED
|
@@ -0,0 +1,115 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import os
|
| 3 |
+
import urllib.request
|
| 4 |
+
from typing import List
|
| 5 |
+
|
| 6 |
+
import numpy as np
|
| 7 |
+
import torch
|
| 8 |
+
import yaml
|
| 9 |
+
|
| 10 |
+
from src.data.containers import BatchTimeSeriesContainer
|
| 11 |
+
from src.models.model import TimeSeriesModel
|
| 12 |
+
from src.plotting.plot_timeseries import plot_from_container
|
| 13 |
+
|
| 14 |
+
logger = logging.getLogger(__name__)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def load_model(
|
| 18 |
+
config_path: str, model_path: str, device: torch.device
|
| 19 |
+
) -> TimeSeriesModel:
|
| 20 |
+
"""Load the TimeSeriesModel from config and checkpoint."""
|
| 21 |
+
with open(config_path, "r") as f:
|
| 22 |
+
config = yaml.safe_load(f)
|
| 23 |
+
|
| 24 |
+
model = TimeSeriesModel(**config["TimeSeriesModel"]).to(device)
|
| 25 |
+
checkpoint = torch.load(model_path, map_location=device)
|
| 26 |
+
model.load_state_dict(checkpoint["model_state_dict"])
|
| 27 |
+
model.eval()
|
| 28 |
+
logger.info(f"Successfully loaded TimeSeriesModel from {model_path} on {device}")
|
| 29 |
+
return model
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def download_checkpoint_if_needed(url: str, target_dir: str = "models") -> str:
|
| 33 |
+
"""Download checkpoint from URL into target_dir if not present and return its path.
|
| 34 |
+
|
| 35 |
+
Ensures direct download for Dropbox links by forcing dl=1.
|
| 36 |
+
"""
|
| 37 |
+
os.makedirs(target_dir, exist_ok=True)
|
| 38 |
+
target_path = os.path.join(target_dir, "checkpoint.pth")
|
| 39 |
+
|
| 40 |
+
# Normalize Dropbox URL to force direct download
|
| 41 |
+
if "dropbox.com" in url and "dl=0" in url:
|
| 42 |
+
url = url.replace("dl=0", "dl=1")
|
| 43 |
+
|
| 44 |
+
if not os.path.exists(target_path):
|
| 45 |
+
logger.info(f"Downloading checkpoint from {url} to {target_path}...")
|
| 46 |
+
urllib.request.urlretrieve(url, target_path)
|
| 47 |
+
logger.info("Checkpoint downloaded successfully.")
|
| 48 |
+
else:
|
| 49 |
+
logger.info(f"Using existing checkpoint at {target_path}")
|
| 50 |
+
|
| 51 |
+
return target_path
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def plot_with_library(
|
| 55 |
+
container: BatchTimeSeriesContainer,
|
| 56 |
+
predictions_np: np.ndarray, # [B, P, N, Q]
|
| 57 |
+
model_quantiles: List[float] | None,
|
| 58 |
+
output_dir: str = "outputs",
|
| 59 |
+
show_plots: bool = True,
|
| 60 |
+
save_plots: bool = True,
|
| 61 |
+
):
|
| 62 |
+
os.makedirs(output_dir, exist_ok=True)
|
| 63 |
+
batch_size = container.batch_size
|
| 64 |
+
for i in range(batch_size):
|
| 65 |
+
output_file = (
|
| 66 |
+
os.path.join(output_dir, f"sine_wave_prediction_sample_{i + 1}.png")
|
| 67 |
+
if save_plots
|
| 68 |
+
else None
|
| 69 |
+
)
|
| 70 |
+
plot_from_container(
|
| 71 |
+
batch=container,
|
| 72 |
+
sample_idx=i,
|
| 73 |
+
predicted_values=predictions_np,
|
| 74 |
+
model_quantiles=model_quantiles,
|
| 75 |
+
title=f"Sine Wave Time Series Prediction - Sample {i + 1}",
|
| 76 |
+
output_file=output_file,
|
| 77 |
+
show=show_plots,
|
| 78 |
+
)
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
def run_inference_and_plot(
|
| 82 |
+
model: TimeSeriesModel,
|
| 83 |
+
container: BatchTimeSeriesContainer,
|
| 84 |
+
output_dir: str = "outputs",
|
| 85 |
+
use_bfloat16: bool = True,
|
| 86 |
+
) -> None:
|
| 87 |
+
"""Run model inference with optional bfloat16 and plot using shared utilities."""
|
| 88 |
+
device_type = "cuda" if (container.history_values.device.type == "cuda") else "cpu"
|
| 89 |
+
autocast_enabled = use_bfloat16 and device_type == "cuda"
|
| 90 |
+
with (
|
| 91 |
+
torch.no_grad(),
|
| 92 |
+
torch.autocast(
|
| 93 |
+
device_type=device_type, dtype=torch.bfloat16, enabled=autocast_enabled
|
| 94 |
+
),
|
| 95 |
+
):
|
| 96 |
+
model_output = model(container)
|
| 97 |
+
|
| 98 |
+
preds_full = model_output["result"].to(torch.float32)
|
| 99 |
+
if hasattr(model, "scaler") and "scale_statistics" in model_output:
|
| 100 |
+
preds_full = model.scaler.inverse_scale(
|
| 101 |
+
preds_full, model_output["scale_statistics"]
|
| 102 |
+
)
|
| 103 |
+
|
| 104 |
+
preds_np = preds_full.detach().cpu().numpy()
|
| 105 |
+
model_quantiles = (
|
| 106 |
+
model.quantiles if getattr(model, "loss_type", None) == "quantile" else None
|
| 107 |
+
)
|
| 108 |
+
plot_with_library(
|
| 109 |
+
container=container,
|
| 110 |
+
predictions_np=preds_np,
|
| 111 |
+
model_quantiles=model_quantiles,
|
| 112 |
+
output_dir=output_dir,
|
| 113 |
+
show_plots=True,
|
| 114 |
+
save_plots=True,
|
| 115 |
+
)
|
gift_eval/submission/all_results.csv
ADDED
|
@@ -0,0 +1,98 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
dataset,model,eval_metrics/MSE[mean],eval_metrics/MSE[0.5],eval_metrics/MAE[0.5],eval_metrics/MASE[0.5],eval_metrics/MAPE[0.5],eval_metrics/sMAPE[0.5],eval_metrics/MSIS,eval_metrics/RMSE[mean],eval_metrics/NRMSE[mean],eval_metrics/ND[0.5],eval_metrics/mean_weighted_sum_quantile_loss,domain,num_variates
|
| 2 |
+
bitbrains_fast_storage/5T/long,TempoPFN,3457994.418690934,3457994.418690934,327.16564021921977,0.9615742426354904,4.317236176373819,0.8336409912081381,19.490867974425026,1859.5683420328853,4.914283864546929,0.8646010960833215,0.6536844929905335,Web/CloudOps,2
|
| 3 |
+
bitbrains_fast_storage/5T/medium,TempoPFN,2800287.942594441,2800287.942594441,268.74003348343393,1.0930763358543272,3.2742632396336617,0.824830859725203,26.62443937663418,1673.406090162947,5.084269857453093,0.8165064414207498,0.6178037781792698,Web/CloudOps,2
|
| 4 |
+
bitbrains_fast_storage/5T/short,TempoPFN,1690352.428591824,1690352.428591824,162.1872711788372,0.8136291545842834,1.776193812092158,0.7668176303900445,20.32296781949572,1300.13554239234,4.082104033944751,0.5092279168950156,0.4037249136258121,Web/CloudOps,2
|
| 5 |
+
bitbrains_fast_storage/H/short,TempoPFN,2588949.8055826887,2588949.8055826887,300.81926572581165,1.1822543303101407,3.726231648106852,0.593958917999151,29.76405600888225,1609.0213813317362,4.586233656611166,0.8574326339199428,0.6458078536940699,Web/CloudOps,2
|
| 6 |
+
bitbrains_rnd/5T/long,TempoPFN,2990910.5081971884,2990910.5081971884,210.74577292406275,3.5186544815564527,2.529824679515041,0.7193304407946397,123.74784003341853,1729.4249067817857,6.625037355191929,0.8073195965870753,0.7073195661600815,Web/CloudOps,2
|
| 7 |
+
bitbrains_rnd/5T/medium,TempoPFN,2289257.9838845544,2289257.9838845544,152.20154125488185,4.54810611155951,0.5130282516077612,0.7426683109827628,167.72825817863563,1513.0294061532825,6.366085897951346,0.6403894606996178,0.6193602612637874,Web/CloudOps,2
|
| 8 |
+
bitbrains_rnd/5T/short,TempoPFN,2014077.5501842,2014077.5501842,135.98742661578987,1.8517397044034425,0.696232985412152,0.6817326560343352,63.2175943612252,1419.182000373525,5.806883078969316,0.5564212950558665,0.5257236486996486,Web/CloudOps,2
|
| 9 |
+
bitbrains_rnd/H/short,TempoPFN,2035943.7507352629,2035943.7507352629,166.20220717027726,6.030992589065415,1.762054722799612,0.5701899273183543,206.5459296074726,1426.865007888014,6.244659394585995,0.7273821760777641,0.6502124112431411,Web/CloudOps,2
|
| 10 |
+
bizitobs_application/10S/long,TempoPFN,5740816.497777778,5740816.497777778,1423.993611111111,3.481128281924532,0.0486669582790798,0.0496452288049222,25.03746966635237,2396.0001038768296,0.0924041469204081,0.0549177417154226,0.0475831149960796,Web/CloudOps,2
|
| 11 |
+
bizitobs_application/10S/medium,TempoPFN,2146376.1066666665,2146376.1066666665,832.4885416666667,2.154386004052589,0.0297427558898925,0.0299385500168018,15.690585782887144,1465.051571333469,0.0575282633018517,0.0326893748710731,0.0238959442034563,Web/CloudOps,2
|
| 12 |
+
bizitobs_application/10S/short,TempoPFN,376800.9244444444,376800.9244444444,333.5807638888889,1.045550170879607,0.0145058769649929,0.0146063554228645,8.24955441258388,613.8411231291403,0.0236733985259999,0.0128648767027747,0.0102197624925825,Web/CloudOps,2
|
| 13 |
+
bizitobs_l2c/5T/long,TempoPFN,332.849126984127,332.849126984127,12.822042410714284,1.22095704272019,0.9288389476299502,1.153716245249532,10.349816564139786,18.24415322738019,1.0243819286593263,0.7199385123737686,0.573918947104382,Web/CloudOps,7
|
| 14 |
+
bizitobs_l2c/5T/medium,TempoPFN,146.4688988095238,146.4688988095238,8.26147693452381,0.7818771866617815,0.5654391202343231,0.8614376093159631,7.573703014323006,12.10243359037858,0.636765980847373,0.4346751770356495,0.3544980423033946,Web/CloudOps,7
|
| 15 |
+
bizitobs_l2c/5T/short,TempoPFN,20.892621721540177,20.892621721540177,2.659001813616072,0.274018680480048,0.1498092349119431,0.2086212109555511,2.4052935303554963,4.570844749227453,0.1569813038038852,0.0913208814604556,0.0723605673125024,Web/CloudOps,7
|
| 16 |
+
bizitobs_l2c/H/long,TempoPFN,108.49439484126984,108.49439484126984,6.4422584170386905,0.6815875823888798,0.673632736325078,0.8544856513482197,5.284687159594512,10.416064268295862,0.6362432681202789,0.3935117376155234,0.3131677794751992,Web/CloudOps,7
|
| 17 |
+
bizitobs_l2c/H/medium,TempoPFN,85.11841517857142,85.11841517857142,5.809039015997024,0.6083751129472635,0.6200869245381406,0.8834569194800722,3.7736867069280655,9.225964186933062,0.55864614495367,0.3517461358421966,0.2719450016284953,Web/CloudOps,7
|
| 18 |
+
bizitobs_l2c/H/short,TempoPFN,58.60240730406746,58.60240730406746,4.6713135734437,0.4630005137848145,0.3948283755807854,0.6419900636889204,2.951036267389131,7.6552209180445905,0.4126360128422088,0.251795765049438,0.1985720701597805,Web/CloudOps,7
|
| 19 |
+
bizitobs_service/10S/long,TempoPFN,137172.65608465608,137172.65608465608,82.30403439153439,1.662345455331064,0.1011724369109623,0.0943146465267703,24.580062468505552,370.36827089352033,0.2743806554539279,0.0609734598710921,0.0557345053106378,Web/CloudOps,2
|
| 20 |
+
bizitobs_service/10S/medium,TempoPFN,7740.426666666666,7740.426666666666,30.32351686507937,1.4210776938224114,0.103039076063368,0.0716119877124027,22.67250742405877,87.9796946270369,0.0662155914274661,0.0228221933696611,0.0187131317044051,Web/CloudOps,2
|
| 21 |
+
bizitobs_service/10S/short,TempoPFN,2474.4792460317462,2474.4792460317462,19.176820798197756,1.1598653331648996,0.0666156292466259,0.0541983465988417,24.57783862628469,49.7441378056927,0.0368520491464996,0.0142068025239332,0.0115698518326863,Web/CloudOps,2
|
| 22 |
+
car_parts/M/short,TempoPFN,1.3818172451286372,1.3818172451286372,0.4672690957004653,0.8407515421652917,0.8293590893689794,1.893282740388816,25.816739632958576,1.175507228871281,2.8187457507850047,1.1204633588204531,1.016162704205562,Sales,1
|
| 23 |
+
covid_deaths/D/short,TempoPFN,290323.0616541353,290323.0616541353,95.88298186873432,36.82875379020991,0.0973305795059633,0.3802577731558227,838.2070203544016,538.8163524375772,0.2027322652277888,0.0360764368473681,0.0296493204600527,Healthcare,1
|
| 24 |
+
electricity/15T/long,TempoPFN,679367.7835053491,679367.7835053491,90.37124592952328,1.3619071064235215,0.2042962727803589,0.1999499070070441,10.487232652692931,824.2376984252473,1.3003359982860876,0.1425717174992594,0.1137251456887457,Energy,1
|
| 25 |
+
electricity/15T/medium,TempoPFN,410301.82361416105,410301.82361416105,74.23413740058417,1.1823607410007584,0.1802587787943053,0.1831106137567377,9.124865260310653,640.5480650303778,1.1037288021425813,0.1279128921376865,0.1022478853910184,Energy,1
|
| 26 |
+
electricity/15T/short,TempoPFN,197999.487064066,197999.487064066,69.58886888658678,1.2890658846498282,0.1882592086631687,0.2060175097324122,12.440409392978095,444.97133285647294,0.8771262285479021,0.1371733808638283,0.1124443744530128,Energy,1
|
| 27 |
+
electricity/D/short,TempoPFN,2460923936.675748,2460923936.675748,5265.180427927928,1.564314345775582,0.5004102473254829,0.1020489007479963,12.14133452277077,49607.70037681396,0.8152193034530106,0.0865244042438215,0.0664914998664846,Energy,1
|
| 28 |
+
electricity/H/long,TempoPFN,9660838.018114114,9660838.018114114,315.4014256756757,1.3657739992140687,0.3528330126922677,0.1644909658307117,11.137350730901831,3108.1888646145867,1.225868818973913,0.1243942340819344,0.1000007258954307,Energy,1
|
| 29 |
+
electricity/H/medium,TempoPFN,7117041.892843468,7117041.892843468,278.22569995777025,1.2130144034395085,0.2467986882167905,0.1500124404017645,9.945132926951258,2667.778456477125,1.0413218399707818,0.1086006587630108,0.0872520518606711,Energy,1
|
| 30 |
+
electricity/H/short,TempoPFN,2001828.2401337277,2001828.2401337277,199.38613109691724,1.0786172149769229,0.2218964961368299,0.1440280778205061,11.294129947761776,1414.8597952213242,0.6679148696019,0.0941244936083527,0.0771797324638773,Energy,1
|
| 31 |
+
electricity/W/short,TempoPFN,76183092615.61081,76183092615.61081,34727.13657094594,1.570365713856254,0.1694176463278896,0.0993488831601272,11.91788945218548,276012.8486422521,0.6297702574229203,0.0792358683497086,0.0606708906232695,Energy,1
|
| 32 |
+
ett1/15T/long,TempoPFN,11.819432043650794,11.819432043650794,1.9247003658234128,1.2507084318317785,0.7671729308733772,0.4743360534288272,8.737143903915339,3.437940087268944,0.6552747798713814,0.3668497927592424,0.288230653138245,Energy,7
|
| 33 |
+
ett1/15T/medium,TempoPFN,11.408509540860615,11.408509540860615,1.8437986488947795,1.1818547993600037,0.7281965758824728,0.4556773517772796,8.31158410608761,3.377648522398477,0.6437831670148321,0.3514298559046792,0.277877086121562,Energy,7
|
| 34 |
+
ett1/15T/short,TempoPFN,6.0998437790643605,6.0998437790643605,1.2401007697695778,0.7754559371204721,0.4745998734729215,0.2709062529464219,5.124313668126548,2.469786180839216,0.466892406241743,0.2344306713155297,0.1816328117134165,Energy,7
|
| 35 |
+
ett1/D/short,TempoPFN,40213.09841269841,40213.09841269841,133.03087797619048,1.6324476425289194,1.3032025049603175,0.4616568808156475,10.165232559778676,200.532038369679,0.5267040504936318,0.3494100136837688,0.2686181176947919,Energy,7
|
| 36 |
+
ett1/H/long,TempoPFN,164.89584986772488,164.89584986772488,7.56153480489418,1.3859274542018474,6981196483236.346,0.4785638067874847,10.00708086784301,12.841177900322265,0.6149361975860038,0.362105524659008,0.2816536526299331,Energy,7
|
| 37 |
+
ett1/H/medium,TempoPFN,158.99996279761905,158.99996279761905,7.330310639880952,1.3479604957613165,4318128927434.1104,0.442596366665559,9.590349301595682,12.609518737748044,0.6039660567793922,0.3511045032102148,0.2758386706555789,Energy,7
|
| 38 |
+
ett1/H/short,TempoPFN,104.70541410900296,104.70541410900296,5.155340358189174,0.8547778511929055,0.5003422782534644,0.2702135929272071,5.451980617457977,10.23256635009043,0.4775957088062226,0.2406208128310768,0.1863945925056479,Energy,7
|
| 39 |
+
ett1/W/short,TempoPFN,1183244.5,1183244.5,833.8333565848214,1.5044807548071886,0.5491453238895961,0.5423834221847527,8.346203452067822,1087.770426146988,0.4328498151953185,0.3318021943103104,0.2579454864080913,Energy,7
|
| 40 |
+
ett2/15T/long,TempoPFN,13.920968501984127,13.920968501984127,2.4372794208829367,1.0266229456075762,0.162421735656956,0.1912512110170139,7.240519836720884,3.731081411867627,0.1988360821855705,0.1298870321345517,0.1019580288018046,Energy,7
|
| 41 |
+
ett2/15T/medium,TempoPFN,12.987088216145834,12.987088216145834,2.3273520817832343,0.9702315616517476,0.1522595897167077,0.1778896720653481,6.742950364573618,3.6037602883857063,0.1920508963553819,0.1240287970544381,0.096317793490544,Energy,7
|
| 42 |
+
ett2/15T/short,TempoPFN,8.553860618954612,8.553860618954612,1.8131163824172247,0.7804718358045571,0.1129981226167575,0.1330301091075509,5.350648546766824,2.924698380851368,0.1388458481191596,0.0860750918808183,0.0685052637873467,Energy,7
|
| 43 |
+
ett2/D/short,TempoPFN,170239.08571428573,170239.08571428573,246.5058531746032,2.290326347664065,0.5867415170820932,0.181941641118808,19.77345328878349,412.6003947093189,0.2361420919863594,0.1410818036093808,0.1199711796314696,Energy,7
|
| 44 |
+
ett2/H/long,TempoPFN,218.90458002645505,218.90458002645505,8.95805431547619,0.9923323101716812,0.1756859628750919,0.1666816776540073,8.879245079301075,14.795424293559648,0.202611948300768,0.1226736592226554,0.1036227735159358,Energy,7
|
| 45 |
+
ett2/H/medium,TempoPFN,243.5093005952381,243.5093005952381,9.681060500372023,1.0446103612297537,0.1729210287876511,0.1670725712727777,7.986726475131007,15.60478454177558,0.2102845067618488,0.1304585158995543,0.1055031195534691,Energy,7
|
| 46 |
+
ett2/H/short,TempoPFN,108.53523995535714,108.53523995535714,6.435656592959449,0.7470950747417008,0.1237944578658914,0.1119298434719161,5.231412537431336,10.418024762658089,0.132129541137475,0.0816220321911712,0.0649374365945919,Energy,7
|
| 47 |
+
ett2/W/short,TempoPFN,3383120.0,3383120.0,1295.83203125,0.8951468014830303,0.1438319001879011,0.1607407323784273,9.470720058706704,1839.3259634985852,0.1542912497518785,0.1087004411060343,0.0918377144034967,Energy,7
|
| 48 |
+
hierarchical_sales/D/short,TempoPFN,29.123292892853453,29.123292892853453,2.330811869009017,0.7515128310580963,0.6410289944380209,1.0602027814719133,7.300803117167325,5.396600123490108,1.655617154145591,0.7150672692276139,0.5842758796416178,Sales,1
|
| 49 |
+
hierarchical_sales/W/short,TempoPFN,437.0786163847325,437.0786163847325,8.912233902236162,0.7289483130473005,0.5386128782220985,0.4609518352185516,6.64654723456629,20.906425241650773,0.9598242089373876,0.4091650177495076,0.3427086959502182,Sales,1
|
| 50 |
+
hospital/M/short,TempoPFN,3146.256471371143,3146.256471371143,18.09600954747936,0.768169214106615,0.1945593078361289,0.1746747839340947,5.195230182484194,56.09150088356652,0.2036251734486402,0.0656927168071784,0.0524846811483977,Healthcare,1
|
| 51 |
+
jena_weather/10T/long,TempoPFN,1802.1015893683864,1802.1015893683864,11.05077453290344,0.6480390269860509,0.8421329927032432,0.6608396658167077,6.431036388936636,42.45116711432544,0.2597659641659084,0.0676215825489287,0.0568675921221853,Nature,21
|
| 52 |
+
jena_weather/10T/medium,TempoPFN,1753.326057449495,1753.326057449495,10.45327409136003,0.6205262365569862,0.800809384246282,0.6752596791783848,5.983639047813428,41.8727364456814,0.2569722819618993,0.0641515679471918,0.0526090633894538,Nature,21
|
| 53 |
+
jena_weather/10T/short,TempoPFN,967.4834108746242,967.4834108746242,6.240461833893307,0.29785829799349,0.3495092146199383,0.5688907620872866,2.7136900415583747,31.104395362627194,0.1931972955145112,0.0387610926048839,0.0316042761177553,Nature,21
|
| 54 |
+
jena_weather/D/short,TempoPFN,407.6343998015873,407.6343998015873,10.096466548859128,1.2762104692374598,0.7647620393136633,0.4792207233136718,8.470860420630778,20.18995789499293,0.1215765454839294,0.0607972305335396,0.0502315688594873,Nature,21
|
| 55 |
+
jena_weather/H/long,TempoPFN,1450.035582010582,1450.035582010582,12.834169353505292,1.14925431188062,3.6454664207292495,0.6876010515835866,8.49444712038228,38.07933274114164,0.2292797721719729,0.0772759188138019,0.0615505784712624,Nature,21
|
| 56 |
+
jena_weather/H/medium,TempoPFN,1601.863988095238,1601.863988095238,11.43108181423611,0.830294830457016,2.907100446024271,0.6853773994144349,6.671981430906583,40.02329306910213,0.2449096285447175,0.069948816959045,0.0562073146926605,Nature,21
|
| 57 |
+
jena_weather/H/short,TempoPFN,1161.0002492396357,1161.0002492396357,8.45698316633054,0.5343309068765919,1.2899701263024146,0.6088007276136064,4.785975199754376,34.073453732189165,0.2088680861946653,0.0518407644501047,0.0420641895205845,Nature,21
|
| 58 |
+
kdd_cup_2018/D/short,TempoPFN,2957.558623620254,2957.558623620254,21.449108262527844,1.2022252741099626,0.5317497971257803,0.4686441782744058,9.261473936192472,54.38344071149098,1.2182468123931351,0.4804827982128498,0.3781022537751671,Nature,1
|
| 59 |
+
kdd_cup_2018/H/long,TempoPFN,4099.393834111588,4099.393834111588,24.37712764418711,1.0361222519400666,1.067596580941062,0.6143228628291789,7.771131914708889,64.02650883900814,1.502320679809611,0.5719859420463782,0.4457075391120335,Nature,1
|
| 60 |
+
kdd_cup_2018/H/medium,TempoPFN,5187.082299587964,5187.082299587964,25.7997948872936,1.076371675935021,0.996384455388961,0.5780413204727044,8.857767467515062,72.02140167747338,1.5075383869258192,0.5400364372465801,0.4275271421385803,Nature,1
|
| 61 |
+
kdd_cup_2018/H/short,TempoPFN,4423.398133663605,4423.398133663605,22.99868414981208,0.975075924949626,0.940964873703854,0.5088272138094274,7.590540688579701,66.50863202369753,1.3921461175037204,0.4814041106039762,0.3836356598458785,Nature,1
|
| 62 |
+
loop_seattle/5T/long,TempoPFN,157.56740910947713,157.56740910947713,7.634268714704449,1.191248365481325,0.294509001597258,0.1619458107627965,11.066948051479228,12.552585753918478,0.2219322959299876,0.1349754398667968,0.1102272021373501,Transport,1
|
| 63 |
+
loop_seattle/5T/medium,TempoPFN,150.1369470378612,150.1369470378612,7.426822445518092,1.1582245306263297,0.2787350445364528,0.1604399422057661,10.01895938551111,12.253038277825675,0.2180067277247357,0.1321384314672467,0.1067471651057607,Transport,1
|
| 64 |
+
loop_seattle/5T/short,TempoPFN,56.20837674450948,56.20837674450948,4.151334465349668,0.6528856304300188,0.1189866291357144,0.0868257500989403,5.418227383070815,7.497224602778649,0.1285608499805451,0.0711862209945109,0.0566841136858997,Transport,1
|
| 65 |
+
loop_seattle/D/short,TempoPFN,19.32995043617776,19.32995043617776,2.972921541920633,0.8969007376581118,0.0550185047066986,0.0549326847443657,7.26916754640511,4.396583950771071,0.0785728296906184,0.0531300802196517,0.043017058136015,Transport,1
|
| 66 |
+
loop_seattle/H/long,TempoPFN,89.40608606381149,89.40608606381149,5.467254720555985,1.12318926581471,0.184156507997936,0.123748771373072,7.909106132499233,9.455479155696526,0.1689820440045555,0.0977071455143036,0.0757696938381596,Transport,1
|
| 67 |
+
loop_seattle/H/medium,TempoPFN,82.05160402154283,82.05160402154283,5.249757043545214,1.067239394992798,0.1469916750156965,0.1198292414396702,7.71532453928058,9.058234045416514,0.1601032741074667,0.0927888688596669,0.0730646137379731,Transport,1
|
| 68 |
+
loop_seattle/H/short,TempoPFN,79.93021155830753,79.93021155830753,4.978952884492776,1.0019999078644888,0.1463370876655166,0.1132828703040474,7.663887880517498,8.94036976630763,0.1582536394917618,0.0881325309159338,0.0697681163822325,Transport,1
|
| 69 |
+
m4_daily/D/short,TempoPFN,1107302.1502247455,1107302.1502247455,200.0984529723884,4.4308070498735,0.0375582349397479,0.0325003448180839,73.85257371713408,1052.284253528839,0.162548835061418,0.0309096808387832,0.0255332842361311,Econ/Fin,1
|
| 70 |
+
m4_hourly/H/short,TempoPFN,1900790.397793584,1900790.397793584,269.87303079307173,0.8295739315523254,0.1211194871128469,0.1069586238356769,5.763527621155884,1378.691552811427,0.1882218572798091,0.036843631182058,0.028529335870705,Econ/Fin,1
|
| 71 |
+
m4_monthly/M/short,TempoPFN,1888038.791054398,1888038.791054398,550.6457703179253,0.9239334080470228,0.157533313108815,0.1295610419100214,7.634234953833278,1374.059238553563,0.2855766798961609,0.1144430942087997,0.0913401022550916,Econ/Fin,1
|
| 72 |
+
m4_quarterly/Q/short,TempoPFN,1796236.6248541668,1796236.6248541668,559.6329735514323,1.1747941926308771,0.1171090269982814,0.1022490358727294,8.829971053307407,1340.2375255357413,0.2243321614232385,0.0936727051500237,0.0748259755560803,Econ/Fin,1
|
| 73 |
+
m4_weekly/W/short,TempoPFN,583423.8894364688,583423.8894364688,281.9014021319905,2.5068974606709102,0.0621606022892198,0.0619608453649078,34.89581976015151,763.8218964107201,0.1391565014546586,0.0513580627371238,0.0419254044427488,Econ/Fin,1
|
| 74 |
+
m4_yearly/A/short,TempoPFN,3788840.647688692,3788840.647688692,918.094150872091,3.421401346947248,0.1715710473134636,0.1539546917894726,30.445192708697025,1946.4944509781403,0.3121294070682495,0.1472206523889813,0.1196218198038522,Econ/Fin,1
|
| 75 |
+
m_dense/D/short,TempoPFN,9482.795555555556,9482.795555555556,45.650052083333335,0.6899203610078747,0.1267966234392374,0.0999539874368826,7.043961677013339,97.3796465158688,0.1685785724555744,0.0790269926834956,0.0660205335795425,Transport,1
|
| 76 |
+
m_dense/H/long,TempoPFN,75216.58469135803,75216.58469135803,131.98908950617283,1.1099402431673535,0.4539421329801232,0.3155182786007836,8.274772567214445,274.2564214222851,0.4747784079532156,0.2284926254705489,0.1835932985711755,Transport,1
|
| 77 |
+
m_dense/H/medium,TempoPFN,66764.08444444444,66764.08444444444,124.88760416666666,1.0367512901513452,0.4164061887564455,0.3037215745855758,7.849365647315136,258.3874695964269,0.4495615533094931,0.2172886533776566,0.1733313995334337,Transport,1
|
| 78 |
+
m_dense/H/short,TempoPFN,66010.75111111111,66010.75111111111,120.28962565104166,1.0160056830633992,0.4109345557059414,0.2858404757066923,8.963124852594527,256.9255750428733,0.4557220010023848,0.213363846290401,0.1721874459654968,Transport,1
|
| 79 |
+
restaurant/D/short,TempoPFN,141.10532587289566,141.10532587289566,7.168732057134789,0.6880883048170244,0.6529455322995288,0.3943859221952507,4.677912027140814,11.878776278425976,0.5466888071812649,0.3299216590546327,0.2581917858443854,Sales,1
|
| 80 |
+
saugeen/D/short,TempoPFN,1375.7590625,1375.7590625,14.092150065104166,3.1309744145587413,0.3216047922770182,0.3610168146588098,30.500399370336144,37.09122621995665,1.20139365482093,0.4564480982807553,0.3755489541578553,Nature,1
|
| 81 |
+
saugeen/M/short,TempoPFN,450.8665829613095,450.8665829613095,13.476651146298362,0.7895196884776998,0.3773554620288667,0.3776235164111268,4.73649049060767,21.23361916775634,0.6374969476769328,0.4046094969866529,0.3102559834358562,Nature,1
|
| 82 |
+
saugeen/W/short,TempoPFN,1229.458984375,1229.458984375,16.6321533203125,1.349179934912743,0.4265083312988281,0.4078161463980466,9.738107739351932,35.0636419154514,1.058425187524238,0.5020553780303745,0.4004677568480909,Nature,1
|
| 83 |
+
solar/10T/long,TempoPFN,38.03510999594485,38.03510999594485,2.95217954414411,1.289682582185996,1.980939740009238,1.613347773805571,10.516784658746062,6.167261142188228,1.3329548105705944,0.6380663692211938,0.5039360963008123,Energy,1
|
| 84 |
+
solar/10T/medium,TempoPFN,31.73545226443265,31.73545226443265,2.5354660658571637,1.1083795980449829,2.376593457700527,1.55737387319841,8.328948817077988,5.6334227841013895,1.2500789187217176,0.5626300030254013,0.4351566003689724,Energy,1
|
| 85 |
+
solar/10T/short,TempoPFN,23.310370868023877,23.310370868023877,2.089681713540479,0.9104617574218964,3.088664790072517,1.572870007326998,5.75677115505075,4.828081489372758,1.4044883551066518,0.6078881723531575,0.4620934487157311,Energy,1
|
| 86 |
+
solar/D/short,TempoPFN,128838.1800486618,128838.1800486618,250.6613594890511,0.9782785201693562,1.044265071376977,0.4281686406100531,5.697261783834341,358.94035723036467,0.5185465709334212,0.3621202960611567,0.2800056850496608,Energy,1
|
| 87 |
+
solar/H/long,TempoPFN,875.8664436334144,875.8664436334144,13.072592888280615,0.9956236178493916,4.22992235524107,1.4246637276180487,7.401661699548643,29.59504086216835,1.0261141373748248,0.4532506793040977,0.3659397066604597,Energy,1
|
| 88 |
+
solar/H/medium,TempoPFN,969.7141119221412,969.7141119221412,12.987529225593066,0.9916768572605807,4.270079450594054,1.4254524509643212,7.490816829317306,31.140233010081044,1.1217438746826656,0.4678411157474254,0.3867255305832896,Energy,1
|
| 89 |
+
solar/H/short,TempoPFN,687.7860367694727,687.7860367694727,11.829851353484486,0.9153026829231484,3.298143647835289,1.4320977852338796,6.105712982423255,26.22567514420692,0.9666871244547572,0.4360522627061222,0.338930893375135,Energy,1
|
| 90 |
+
solar/W/short,TempoPFN,1837604.379562044,1837604.379562044,1080.8457458941605,1.1818483501196966,0.2449082423300638,0.2096709326072068,7.4416251763844,1355.5826716073218,0.2767083080725079,0.2206276340779138,0.160040923371332,Energy,1
|
| 91 |
+
sz_taxi/15T/long,TempoPFN,17.335278668091167,17.335278668091167,2.8752947771990742,0.5435739715185243,8150111586328.506,0.4184713652630097,4.380632638022632,4.163565619525069,0.3853721873400869,0.266132142205346,0.2125054942462848,Transport,1
|
| 92 |
+
sz_taxi/15T/medium,TempoPFN,17.73923068576389,17.73923068576389,2.88089839576656,0.5629010694446301,12249100752073.3,0.4169614441536142,4.14479162506023,4.211796610208509,0.3919779681855994,0.2681156770449617,0.2116726820657642,Transport,1
|
| 93 |
+
sz_taxi/15T/short,TempoPFN,17.57054233201694,17.57054233201694,2.8061145880283456,0.5602273611005313,959958212480.042,0.4052746826217428,4.012449587804747,4.191723074347462,0.3919440456333012,0.2623837225491499,0.2066414499332957,Transport,1
|
| 94 |
+
sz_taxi/H/short,TempoPFN,7.529553437844301,7.529553437844301,1.8911764356825087,0.5763698315699721,1.1282697131491115,0.3028206124743695,4.102259224272375,2.744003177447924,0.2556208258093829,0.1761747530810148,0.1390065711740581,Transport,1
|
| 95 |
+
temperature_rain/D/short,TempoPFN,186.81455040605852,186.81455040605852,5.9566782469540085,1.385070112921999,28.13298940652906,1.5239891474214418,25.51129792837534,13.668011940514925,1.60908637363345,0.7012585181375972,0.572396651054853,Nature,1
|
| 96 |
+
us_births/D/short,TempoPFN,188935.12,188935.12,266.77953125,0.3928744382386066,0.0256256341934204,0.0252893901831033,3.346242220924745,434.6666768916154,0.040746473841947,0.0250084162636546,0.0202561474459704,Healthcare,1
|
| 97 |
+
us_births/M/short,TempoPFN,53081706.66666666,53081706.66666666,5884.473958333333,0.6657763993191178,0.0181355277697245,0.018380189816312,3.8133237509773754,7285.719365077594,0.0226293946745239,0.0182771359947467,0.0136913144696876,Healthcare,1
|
| 98 |
+
us_births/W/short,TempoPFN,1710668.857142857,1710668.857142857,1002.7292131696428,0.9115505789348626,0.0135757678321429,0.0135867246503487,5.849062097782842,1307.9254019793548,0.0177549590839956,0.0136119507467408,0.0106687511144078,Healthcare,1
|
gift_eval/submission/config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"model": "TempoPFN",
|
| 3 |
+
"model_type": "pretrained",
|
| 4 |
+
"model_dtype": "float32",
|
| 5 |
+
"model_link": "https://github.com/automl/TempoPFN/tree/main"
|
| 6 |
+
}
|
pyproject.toml
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[project]
|
| 2 |
+
name = "TempoPFN"
|
| 3 |
+
version = "0.1.0"
|
| 4 |
+
description = "Univariate Time Series Forecasting Using Linear RNNs"
|
| 5 |
+
authors = [
|
| 6 |
+
]
|
| 7 |
+
readme = "README.md"
|
| 8 |
+
license = { file = "LICENSE" }
|
| 9 |
+
requires-python = ">=3.10,<3.13"
|
| 10 |
+
|
| 11 |
+
dependencies = [
|
| 12 |
+
"torch>=2.5.0",
|
| 13 |
+
"torchmetrics",
|
| 14 |
+
"triton==3.2.0",
|
| 15 |
+
"numpy",
|
| 16 |
+
"gpytorch",
|
| 17 |
+
"flash-linear-attention @ git+https://github.com/fla-org/flash-linear-attention@main",
|
| 18 |
+
"scikit-learn",
|
| 19 |
+
]
|
| 20 |
+
|
| 21 |
+
classifiers = [
|
| 22 |
+
"Intended Audience :: Science/Research",
|
| 23 |
+
"Intended Audience :: Developers",
|
| 24 |
+
"License :: OSI Approved :: Apache Software License",
|
| 25 |
+
"Programming Language :: Python",
|
| 26 |
+
"Topic :: Software Development",
|
| 27 |
+
"Topic :: Scientific/Engineering",
|
| 28 |
+
"Operating System :: POSIX",
|
| 29 |
+
"Operating System :: Unix",
|
| 30 |
+
"Operating System :: MacOS",
|
| 31 |
+
"Programming Language :: Python :: 3.9",
|
| 32 |
+
"Programming Language :: Python :: 3.10",
|
| 33 |
+
"Programming Language :: Python :: 3.11",
|
| 34 |
+
]
|
| 35 |
+
|
| 36 |
+
[project.optional-dependencies]
|
| 37 |
+
dev = [
|
| 38 |
+
"wandb",
|
| 39 |
+
"ujson",
|
| 40 |
+
"build",
|
| 41 |
+
"pre-commit",
|
| 42 |
+
"pytest>=8",
|
| 43 |
+
"ruff",
|
| 44 |
+
"mypy",
|
| 45 |
+
"commitizen",
|
| 46 |
+
"black",
|
| 47 |
+
"matplotlib",
|
| 48 |
+
"gluonts",
|
| 49 |
+
"pyo",
|
| 50 |
+
"statsmodels"
|
| 51 |
+
]
|
| 52 |
+
|
| 53 |
+
[build-system]
|
| 54 |
+
requires = ["setuptools>=68.2.2", "wheel>=0.41.2"]
|
| 55 |
+
build-backend = "setuptools.build_meta"
|
| 56 |
+
|
| 57 |
+
package-dir = {"" = "src"}
|
src/__init__.py
ADDED
|
File without changes
|
src/data/__init__.py
ADDED
|
File without changes
|
src/data/augmentations.py
ADDED
|
@@ -0,0 +1,1318 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import math
|
| 3 |
+
from collections import Counter
|
| 4 |
+
from pathlib import Path
|
| 5 |
+
from typing import Dict, List, Optional, Tuple
|
| 6 |
+
|
| 7 |
+
import numpy as np
|
| 8 |
+
import torch
|
| 9 |
+
import torch.nn as nn
|
| 10 |
+
from joblib import Parallel, delayed
|
| 11 |
+
from torch.quasirandom import SobolEngine
|
| 12 |
+
import torch.nn.functional as F
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
from src.gift_eval.data import Dataset
|
| 16 |
+
|
| 17 |
+
logger = logging.getLogger(__name__)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def find_consecutive_nan_lengths(series: np.ndarray) -> list[int]:
|
| 21 |
+
"""Finds the lengths of all consecutive NaN blocks in a 1D array."""
|
| 22 |
+
if series.ndim > 1:
|
| 23 |
+
# For multivariate series, flatten to treat it as one long sequence
|
| 24 |
+
series = series.flatten()
|
| 25 |
+
|
| 26 |
+
is_nan = np.isnan(series)
|
| 27 |
+
padded_is_nan = np.concatenate(([False], is_nan, [False]))
|
| 28 |
+
diffs = np.diff(padded_is_nan.astype(int))
|
| 29 |
+
|
| 30 |
+
start_indices = np.where(diffs == 1)[0]
|
| 31 |
+
end_indices = np.where(diffs == -1)[0]
|
| 32 |
+
|
| 33 |
+
return (end_indices - start_indices).tolist()
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def analyze_datasets_for_augmentation(gift_eval_path_str: str) -> dict:
|
| 37 |
+
"""
|
| 38 |
+
Analyzes all datasets to derive statistics needed for NaN augmentation.
|
| 39 |
+
This version collects the full distribution of NaN ratios.
|
| 40 |
+
"""
|
| 41 |
+
logger.info(
|
| 42 |
+
"--- Starting Dataset Analysis for Augmentation (Full Distribution) ---"
|
| 43 |
+
)
|
| 44 |
+
path = Path(gift_eval_path_str)
|
| 45 |
+
if not path.exists():
|
| 46 |
+
raise FileNotFoundError(
|
| 47 |
+
f"Provided raw data path for augmentation analysis does not exist: {gift_eval_path_str}"
|
| 48 |
+
)
|
| 49 |
+
|
| 50 |
+
dataset_names = []
|
| 51 |
+
for dataset_dir in path.iterdir():
|
| 52 |
+
if dataset_dir.name.startswith(".") or not dataset_dir.is_dir():
|
| 53 |
+
continue
|
| 54 |
+
freq_dirs = [d for d in dataset_dir.iterdir() if d.is_dir()]
|
| 55 |
+
if freq_dirs:
|
| 56 |
+
for freq_dir in freq_dirs:
|
| 57 |
+
dataset_names.append(f"{dataset_dir.name}/{freq_dir.name}")
|
| 58 |
+
else:
|
| 59 |
+
dataset_names.append(dataset_dir.name)
|
| 60 |
+
|
| 61 |
+
total_series_count = 0
|
| 62 |
+
series_with_nans_count = 0
|
| 63 |
+
nan_ratio_distribution = []
|
| 64 |
+
all_consecutive_nan_lengths = Counter()
|
| 65 |
+
|
| 66 |
+
for ds_name in sorted(dataset_names):
|
| 67 |
+
try:
|
| 68 |
+
ds = Dataset(name=ds_name, term="short", to_univariate=False)
|
| 69 |
+
for series_data in ds.training_dataset:
|
| 70 |
+
total_series_count += 1
|
| 71 |
+
target = np.atleast_1d(series_data["target"])
|
| 72 |
+
num_nans = np.isnan(target).sum()
|
| 73 |
+
|
| 74 |
+
if num_nans > 0:
|
| 75 |
+
series_with_nans_count += 1
|
| 76 |
+
nan_ratio = num_nans / target.size
|
| 77 |
+
nan_ratio_distribution.append(float(nan_ratio))
|
| 78 |
+
|
| 79 |
+
nan_lengths = find_consecutive_nan_lengths(target)
|
| 80 |
+
all_consecutive_nan_lengths.update(nan_lengths)
|
| 81 |
+
except Exception as e:
|
| 82 |
+
logger.warning(
|
| 83 |
+
f"Could not process {ds_name} for augmentation analysis: {e}"
|
| 84 |
+
)
|
| 85 |
+
|
| 86 |
+
if total_series_count == 0:
|
| 87 |
+
raise ValueError(
|
| 88 |
+
"No series were found during augmentation analysis. Check dataset path."
|
| 89 |
+
)
|
| 90 |
+
|
| 91 |
+
p_series_has_nan = (
|
| 92 |
+
series_with_nans_count / total_series_count if total_series_count > 0 else 0
|
| 93 |
+
)
|
| 94 |
+
|
| 95 |
+
logger.info("--- Augmentation Analysis Complete ---")
|
| 96 |
+
# Print summary statistics
|
| 97 |
+
logger.info(f"Total series analyzed: {total_series_count}")
|
| 98 |
+
logger.info(f"Series with NaNs: {series_with_nans_count} ({p_series_has_nan:.4f})")
|
| 99 |
+
logger.info(f"NaN ratio distribution: {Counter(nan_ratio_distribution)}")
|
| 100 |
+
logger.info(f"Consecutive NaN lengths distribution: {all_consecutive_nan_lengths}")
|
| 101 |
+
logger.info("--- End of Dataset Analysis for Augmentation ---")
|
| 102 |
+
return {
|
| 103 |
+
"p_series_has_nan": p_series_has_nan,
|
| 104 |
+
"nan_ratio_distribution": nan_ratio_distribution,
|
| 105 |
+
"nan_length_distribution": all_consecutive_nan_lengths,
|
| 106 |
+
}
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
class NanAugmenter:
|
| 110 |
+
"""
|
| 111 |
+
Applies realistic NaN augmentation by generating and caching NaN patterns on-demand
|
| 112 |
+
during the first transform call for a given data shape.
|
| 113 |
+
"""
|
| 114 |
+
|
| 115 |
+
def __init__(
|
| 116 |
+
self,
|
| 117 |
+
p_series_has_nan: float,
|
| 118 |
+
nan_ratio_distribution: List[float],
|
| 119 |
+
nan_length_distribution: Counter,
|
| 120 |
+
num_patterns: int = 100000,
|
| 121 |
+
n_jobs: int = -1,
|
| 122 |
+
nan_patterns_path: Optional[str] = None,
|
| 123 |
+
):
|
| 124 |
+
"""
|
| 125 |
+
Initializes the augmenter. NaN patterns are not generated at this stage.
|
| 126 |
+
|
| 127 |
+
Args:
|
| 128 |
+
p_series_has_nan (float): Probability that a series in a batch will be augmented.
|
| 129 |
+
nan_ratio_distribution (List[float]): A list of NaN ratios observed in the dataset.
|
| 130 |
+
nan_length_distribution (Counter): A Counter of consecutive NaN block lengths.
|
| 131 |
+
num_patterns (int): The number of unique NaN patterns to generate per data shape.
|
| 132 |
+
n_jobs (int): The number of CPU cores to use for parallel pattern generation (-1 for all cores).
|
| 133 |
+
"""
|
| 134 |
+
self.p_series_has_nan = p_series_has_nan
|
| 135 |
+
self.nan_ratio_distribution = nan_ratio_distribution
|
| 136 |
+
self.num_patterns = num_patterns
|
| 137 |
+
self.n_jobs = n_jobs
|
| 138 |
+
self.max_length = 2048
|
| 139 |
+
self.nan_patterns_path = nan_patterns_path
|
| 140 |
+
# Cache to store patterns: Dict[shape_tuple -> pattern_tensor]
|
| 141 |
+
self.pattern_cache: Dict[Tuple[int, ...], torch.BoolTensor] = {}
|
| 142 |
+
|
| 143 |
+
if not nan_length_distribution or sum(nan_length_distribution.values()) == 0:
|
| 144 |
+
self._has_block_distribution = False
|
| 145 |
+
logger.warning("NaN length distribution is empty. Augmentation disabled.")
|
| 146 |
+
else:
|
| 147 |
+
self._has_block_distribution = True
|
| 148 |
+
total_blocks = sum(nan_length_distribution.values())
|
| 149 |
+
self.dist_lengths = list(int(i) for i in nan_length_distribution.keys())
|
| 150 |
+
self.dist_probs = [
|
| 151 |
+
count / total_blocks for count in nan_length_distribution.values()
|
| 152 |
+
]
|
| 153 |
+
|
| 154 |
+
if not self.nan_ratio_distribution:
|
| 155 |
+
logger.warning("NaN ratio distribution is empty. Augmentation disabled.")
|
| 156 |
+
|
| 157 |
+
# Try to load existing patterns from disk
|
| 158 |
+
self._load_existing_patterns()
|
| 159 |
+
|
| 160 |
+
def _load_existing_patterns(self):
|
| 161 |
+
"""Load existing NaN patterns from disk if they exist."""
|
| 162 |
+
# Determine where to look for patterns
|
| 163 |
+
explicit_path: Optional[Path] = (
|
| 164 |
+
Path(self.nan_patterns_path).resolve()
|
| 165 |
+
if self.nan_patterns_path is not None
|
| 166 |
+
else None
|
| 167 |
+
)
|
| 168 |
+
|
| 169 |
+
candidate_files: List[Path] = []
|
| 170 |
+
if explicit_path is not None:
|
| 171 |
+
# If the explicit path exists, use it directly
|
| 172 |
+
if explicit_path.is_file():
|
| 173 |
+
candidate_files.append(explicit_path)
|
| 174 |
+
# Also search the directory of the explicit path for matching files
|
| 175 |
+
explicit_dir = explicit_path.parent
|
| 176 |
+
explicit_dir.mkdir(exist_ok=True, parents=True)
|
| 177 |
+
candidate_files.extend(
|
| 178 |
+
list(explicit_dir.glob(f"nan_patterns_{self.max_length}_*.pt"))
|
| 179 |
+
)
|
| 180 |
+
else:
|
| 181 |
+
# Default to the ./data directory
|
| 182 |
+
data_dir = Path("data")
|
| 183 |
+
data_dir.mkdir(exist_ok=True)
|
| 184 |
+
candidate_files.extend(
|
| 185 |
+
list(data_dir.glob(f"nan_patterns_{self.max_length}_*.pt"))
|
| 186 |
+
)
|
| 187 |
+
|
| 188 |
+
# De-duplicate candidate files while preserving order
|
| 189 |
+
seen: set[str] = set()
|
| 190 |
+
unique_candidates: List[Path] = []
|
| 191 |
+
for f in candidate_files:
|
| 192 |
+
key = str(f.resolve())
|
| 193 |
+
if key not in seen:
|
| 194 |
+
seen.add(key)
|
| 195 |
+
unique_candidates.append(f)
|
| 196 |
+
|
| 197 |
+
for pattern_file in unique_candidates:
|
| 198 |
+
try:
|
| 199 |
+
# Extract num_channels from filename
|
| 200 |
+
filename = pattern_file.stem
|
| 201 |
+
parts = filename.split("_")
|
| 202 |
+
if len(parts) >= 4:
|
| 203 |
+
num_channels = int(parts[-1])
|
| 204 |
+
|
| 205 |
+
# Load patterns
|
| 206 |
+
patterns = torch.load(pattern_file, map_location="cpu")
|
| 207 |
+
cache_key = (self.max_length, num_channels)
|
| 208 |
+
self.pattern_cache[cache_key] = patterns
|
| 209 |
+
|
| 210 |
+
logger.info(
|
| 211 |
+
f"Loaded {patterns.shape[0]} patterns for shape {cache_key} from {pattern_file}"
|
| 212 |
+
)
|
| 213 |
+
except (ValueError, RuntimeError, FileNotFoundError) as e:
|
| 214 |
+
logger.warning(f"Failed to load patterns from {pattern_file}: {e}")
|
| 215 |
+
|
| 216 |
+
def _get_pattern_file_path(self, num_channels: int) -> Path:
|
| 217 |
+
"""Resolve the target file path for storing/loading patterns for a given channel count."""
|
| 218 |
+
# If user provided a file path, use its directory as the base directory
|
| 219 |
+
if self.nan_patterns_path is not None:
|
| 220 |
+
base_dir = Path(self.nan_patterns_path).resolve().parent
|
| 221 |
+
base_dir.mkdir(exist_ok=True, parents=True)
|
| 222 |
+
else:
|
| 223 |
+
base_dir = Path("data").resolve()
|
| 224 |
+
base_dir.mkdir(exist_ok=True, parents=True)
|
| 225 |
+
|
| 226 |
+
return base_dir / f"nan_patterns_{self.max_length}_{num_channels}.pt"
|
| 227 |
+
|
| 228 |
+
def _generate_nan_mask(self, series_shape: Tuple[int, ...]) -> np.ndarray:
|
| 229 |
+
"""Generates a single boolean NaN mask for a given series shape."""
|
| 230 |
+
series_size = int(np.prod(series_shape))
|
| 231 |
+
sampled_ratio = np.random.choice(self.nan_ratio_distribution)
|
| 232 |
+
n_nans_to_add = int(round(series_size * sampled_ratio))
|
| 233 |
+
|
| 234 |
+
if n_nans_to_add == 0:
|
| 235 |
+
return np.zeros(series_shape, dtype=bool)
|
| 236 |
+
|
| 237 |
+
mask_flat = np.zeros(series_size, dtype=bool)
|
| 238 |
+
nans_added = 0
|
| 239 |
+
max_attempts = n_nans_to_add * 2
|
| 240 |
+
attempts = 0
|
| 241 |
+
while nans_added < n_nans_to_add and attempts < max_attempts:
|
| 242 |
+
attempts += 1
|
| 243 |
+
block_length = np.random.choice(self.dist_lengths, p=self.dist_probs)
|
| 244 |
+
|
| 245 |
+
if nans_added + block_length > n_nans_to_add:
|
| 246 |
+
block_length = n_nans_to_add - nans_added
|
| 247 |
+
if block_length <= 0:
|
| 248 |
+
break
|
| 249 |
+
|
| 250 |
+
nan_counts_in_window = np.convolve(
|
| 251 |
+
mask_flat, np.ones(block_length), mode="valid"
|
| 252 |
+
)
|
| 253 |
+
valid_starts = np.where(nan_counts_in_window == 0)[0]
|
| 254 |
+
|
| 255 |
+
if valid_starts.size == 0:
|
| 256 |
+
continue
|
| 257 |
+
|
| 258 |
+
start_pos = np.random.choice(valid_starts)
|
| 259 |
+
mask_flat[start_pos : start_pos + block_length] = True
|
| 260 |
+
nans_added += block_length
|
| 261 |
+
|
| 262 |
+
return mask_flat.reshape(series_shape)
|
| 263 |
+
|
| 264 |
+
def _pregenerate_patterns(self, series_shape: Tuple[int, ...]) -> torch.BoolTensor:
|
| 265 |
+
"""Uses joblib to parallelize the generation of NaN masks for a given shape."""
|
| 266 |
+
if not self._has_block_distribution or not self.nan_ratio_distribution:
|
| 267 |
+
return torch.empty(0, *series_shape, dtype=torch.bool)
|
| 268 |
+
|
| 269 |
+
logger.info(
|
| 270 |
+
f"Generating {self.num_patterns} NaN patterns for shape {series_shape}..."
|
| 271 |
+
)
|
| 272 |
+
|
| 273 |
+
with Parallel(n_jobs=self.n_jobs, backend="loky") as parallel:
|
| 274 |
+
masks_list = parallel(
|
| 275 |
+
delayed(self._generate_nan_mask)(series_shape)
|
| 276 |
+
for _ in range(self.num_patterns)
|
| 277 |
+
)
|
| 278 |
+
|
| 279 |
+
logger.info(f"Pattern generation complete for shape {series_shape}.")
|
| 280 |
+
return torch.from_numpy(np.stack(masks_list)).bool()
|
| 281 |
+
|
| 282 |
+
def transform(self, time_series_batch: torch.Tensor) -> torch.Tensor:
|
| 283 |
+
"""
|
| 284 |
+
Applies NaN patterns to a batch, generating them on-demand if the shape is new.
|
| 285 |
+
"""
|
| 286 |
+
if self.p_series_has_nan == 0:
|
| 287 |
+
return time_series_batch
|
| 288 |
+
|
| 289 |
+
history_length, num_channels = time_series_batch.shape[1:]
|
| 290 |
+
assert history_length <= self.max_length, (
|
| 291 |
+
f"History length {history_length} exceeds maximum allowed {self.max_length}."
|
| 292 |
+
)
|
| 293 |
+
|
| 294 |
+
# 1. Check cache and generate patterns if the shape is new
|
| 295 |
+
if (
|
| 296 |
+
self.max_length,
|
| 297 |
+
num_channels,
|
| 298 |
+
) not in self.pattern_cache:
|
| 299 |
+
# Try loading from a resolved file path if available
|
| 300 |
+
target_file = self._get_pattern_file_path(num_channels)
|
| 301 |
+
if target_file.exists():
|
| 302 |
+
try:
|
| 303 |
+
patterns = torch.load(target_file, map_location="cpu")
|
| 304 |
+
self.pattern_cache[(self.max_length, num_channels)] = patterns
|
| 305 |
+
logger.info(
|
| 306 |
+
f"Loaded NaN patterns from {target_file} for shape {(self.max_length, num_channels)}"
|
| 307 |
+
)
|
| 308 |
+
except (RuntimeError, FileNotFoundError):
|
| 309 |
+
# Fall back to generating if loading fails
|
| 310 |
+
patterns = self._pregenerate_patterns(
|
| 311 |
+
(self.max_length, num_channels)
|
| 312 |
+
)
|
| 313 |
+
torch.save(patterns, target_file)
|
| 314 |
+
self.pattern_cache[(self.max_length, num_channels)] = patterns
|
| 315 |
+
logger.info(
|
| 316 |
+
f"Generated and saved {patterns.shape[0]} NaN patterns to {target_file}"
|
| 317 |
+
)
|
| 318 |
+
else:
|
| 319 |
+
patterns = self._pregenerate_patterns((self.max_length, num_channels))
|
| 320 |
+
torch.save(patterns, target_file)
|
| 321 |
+
self.pattern_cache[(self.max_length, num_channels)] = patterns
|
| 322 |
+
logger.info(
|
| 323 |
+
f"Generated and saved {patterns.shape[0]} NaN patterns to {target_file}"
|
| 324 |
+
)
|
| 325 |
+
patterns = self.pattern_cache[(self.max_length, num_channels)][
|
| 326 |
+
:, :history_length, :
|
| 327 |
+
]
|
| 328 |
+
|
| 329 |
+
# Early exit if patterns are empty (e.g., generation failed or was disabled)
|
| 330 |
+
if patterns.numel() == 0:
|
| 331 |
+
return time_series_batch
|
| 332 |
+
|
| 333 |
+
batch_size = time_series_batch.shape[0]
|
| 334 |
+
device = time_series_batch.device
|
| 335 |
+
|
| 336 |
+
# 2. Vectorized decision on which series to augment
|
| 337 |
+
augment_mask = torch.rand(batch_size, device=device) < self.p_series_has_nan
|
| 338 |
+
indices_to_augment = torch.where(augment_mask)[0]
|
| 339 |
+
num_to_augment = indices_to_augment.numel()
|
| 340 |
+
|
| 341 |
+
if num_to_augment == 0:
|
| 342 |
+
return time_series_batch
|
| 343 |
+
|
| 344 |
+
# 3. Randomly sample patterns for each series being augmented
|
| 345 |
+
pattern_indices = torch.randint(
|
| 346 |
+
0, patterns.shape[0], (num_to_augment,), device=device
|
| 347 |
+
)
|
| 348 |
+
# 4. Select patterns and apply them in a single vectorized operation
|
| 349 |
+
selected_patterns = patterns[pattern_indices].to(device)
|
| 350 |
+
|
| 351 |
+
time_series_batch[indices_to_augment] = time_series_batch[
|
| 352 |
+
indices_to_augment
|
| 353 |
+
].masked_fill(selected_patterns, float("nan"))
|
| 354 |
+
|
| 355 |
+
return time_series_batch
|
| 356 |
+
|
| 357 |
+
|
| 358 |
+
class CensorAugmenter:
|
| 359 |
+
"""
|
| 360 |
+
Applies censor augmentation by clipping values from above, below, or both.
|
| 361 |
+
"""
|
| 362 |
+
|
| 363 |
+
def __init__(self):
|
| 364 |
+
"""Initializes the CensorAugmenter."""
|
| 365 |
+
pass
|
| 366 |
+
|
| 367 |
+
def transform(self, time_series_batch: torch.Tensor) -> torch.Tensor:
|
| 368 |
+
"""
|
| 369 |
+
Applies a vectorized censor augmentation to a batch of time series.
|
| 370 |
+
"""
|
| 371 |
+
batch_size, seq_len, num_channels = time_series_batch.shape
|
| 372 |
+
assert num_channels == 1
|
| 373 |
+
time_series_batch = time_series_batch.squeeze(-1)
|
| 374 |
+
with torch.no_grad():
|
| 375 |
+
batch_size, seq_len = time_series_batch.shape
|
| 376 |
+
device = time_series_batch.device
|
| 377 |
+
|
| 378 |
+
# Step 1: Choose an op mode for each series
|
| 379 |
+
op_mode = torch.randint(0, 3, (batch_size, 1), device=device)
|
| 380 |
+
|
| 381 |
+
# Step 2: Calculate potential thresholds for all series
|
| 382 |
+
q1 = torch.rand(batch_size, device=device)
|
| 383 |
+
q2 = torch.rand(batch_size, device=device)
|
| 384 |
+
q_low = torch.minimum(q1, q2)
|
| 385 |
+
q_high = torch.maximum(q1, q2)
|
| 386 |
+
|
| 387 |
+
sorted_series = torch.sort(time_series_batch, dim=1).values
|
| 388 |
+
indices_low = (q_low * (seq_len - 1)).long()
|
| 389 |
+
indices_high = (q_high * (seq_len - 1)).long()
|
| 390 |
+
|
| 391 |
+
c_low = torch.gather(sorted_series, 1, indices_low.unsqueeze(1))
|
| 392 |
+
c_high = torch.gather(sorted_series, 1, indices_high.unsqueeze(1))
|
| 393 |
+
|
| 394 |
+
# Step 3: Compute results for all possible clipping operations
|
| 395 |
+
clip_above = torch.minimum(time_series_batch, c_high)
|
| 396 |
+
clip_below = torch.maximum(time_series_batch, c_low)
|
| 397 |
+
|
| 398 |
+
# Step 4: Select the final result based on the op_mode
|
| 399 |
+
result = torch.where(
|
| 400 |
+
op_mode == 1,
|
| 401 |
+
clip_above,
|
| 402 |
+
torch.where(op_mode == 2, clip_below, time_series_batch),
|
| 403 |
+
)
|
| 404 |
+
augmented_batch = torch.where(
|
| 405 |
+
op_mode == 0,
|
| 406 |
+
time_series_batch,
|
| 407 |
+
result,
|
| 408 |
+
)
|
| 409 |
+
|
| 410 |
+
return augmented_batch.unsqueeze(-1)
|
| 411 |
+
|
| 412 |
+
|
| 413 |
+
class QuantizationAugmenter:
|
| 414 |
+
"""
|
| 415 |
+
Applies non-equidistant quantization using a Sobol sequence to generate
|
| 416 |
+
uniformly distributed levels. This implementation is fully vectorized.
|
| 417 |
+
"""
|
| 418 |
+
|
| 419 |
+
def __init__(
|
| 420 |
+
self,
|
| 421 |
+
p_quantize: float,
|
| 422 |
+
level_range: Tuple[int, int],
|
| 423 |
+
seed: Optional[int] = None,
|
| 424 |
+
):
|
| 425 |
+
"""
|
| 426 |
+
Initializes the augmenter.
|
| 427 |
+
|
| 428 |
+
Args:
|
| 429 |
+
p_quantize (float): Probability of applying quantization to a series.
|
| 430 |
+
level_range (Tuple[int, int]): Inclusive range [min, max] to sample the
|
| 431 |
+
number of quantization levels from.
|
| 432 |
+
seed (Optional[int]): Seed for the Sobol sequence generator for reproducibility.
|
| 433 |
+
"""
|
| 434 |
+
assert 0.0 <= p_quantize <= 1.0, "Probability must be between 0 and 1."
|
| 435 |
+
assert level_range[0] >= 2, "Minimum number of levels must be at least 2."
|
| 436 |
+
assert level_range[0] <= level_range[1], (
|
| 437 |
+
"Min levels cannot be greater than max."
|
| 438 |
+
)
|
| 439 |
+
|
| 440 |
+
self.p_quantize = p_quantize
|
| 441 |
+
self.level_range = level_range
|
| 442 |
+
|
| 443 |
+
# Initialize a SobolEngine. The dimension is the max number of random
|
| 444 |
+
# levels we might need to generate for a single series.
|
| 445 |
+
max_intermediate_levels = self.level_range[1] - 2
|
| 446 |
+
if max_intermediate_levels > 0:
|
| 447 |
+
# SobolEngine must be created on CPU
|
| 448 |
+
self.sobol_engine = SobolEngine(
|
| 449 |
+
dimension=max_intermediate_levels, scramble=True, seed=seed
|
| 450 |
+
)
|
| 451 |
+
else:
|
| 452 |
+
self.sobol_engine = None
|
| 453 |
+
|
| 454 |
+
def transform(self, time_series_batch: torch.Tensor) -> torch.Tensor:
|
| 455 |
+
"""
|
| 456 |
+
Applies augmentation in a fully vectorized way on the batch's device.
|
| 457 |
+
Handles input shape (batch, length, 1).
|
| 458 |
+
"""
|
| 459 |
+
# Handle input shape (batch, length, 1)
|
| 460 |
+
if time_series_batch.dim() == 3 and time_series_batch.shape[2] == 1:
|
| 461 |
+
is_3d = True
|
| 462 |
+
time_series_squeezed = time_series_batch.squeeze(-1)
|
| 463 |
+
else:
|
| 464 |
+
is_3d = False
|
| 465 |
+
time_series_squeezed = time_series_batch
|
| 466 |
+
|
| 467 |
+
if self.p_quantize == 0 or self.sobol_engine is None:
|
| 468 |
+
return time_series_batch
|
| 469 |
+
|
| 470 |
+
n_series, _ = time_series_squeezed.shape
|
| 471 |
+
device = time_series_squeezed.device
|
| 472 |
+
|
| 473 |
+
# 1. Decide which series to augment
|
| 474 |
+
augment_mask = torch.rand(n_series, device=device) < self.p_quantize
|
| 475 |
+
n_augment = torch.sum(augment_mask)
|
| 476 |
+
if n_augment == 0:
|
| 477 |
+
return time_series_batch
|
| 478 |
+
|
| 479 |
+
series_to_augment = time_series_squeezed[augment_mask]
|
| 480 |
+
|
| 481 |
+
# 2. Determine a variable n_levels for EACH series
|
| 482 |
+
min_l, max_l = self.level_range
|
| 483 |
+
n_levels_per_series = torch.randint(
|
| 484 |
+
min_l, max_l + 1, size=(n_augment,), device=device
|
| 485 |
+
)
|
| 486 |
+
max_levels_in_batch = n_levels_per_series.max().item()
|
| 487 |
+
|
| 488 |
+
# 3. Find min/max for each series
|
| 489 |
+
min_vals = torch.amin(series_to_augment, dim=1, keepdim=True)
|
| 490 |
+
max_vals = torch.amax(series_to_augment, dim=1, keepdim=True)
|
| 491 |
+
value_range = max_vals - min_vals
|
| 492 |
+
is_flat = value_range == 0
|
| 493 |
+
|
| 494 |
+
# 4. Generate quasi-random levels using the Sobol sequence
|
| 495 |
+
num_intermediate_levels = max_levels_in_batch - 2
|
| 496 |
+
if num_intermediate_levels > 0:
|
| 497 |
+
# Draw points from the Sobol engine (on CPU) and move to target device
|
| 498 |
+
sobol_points = self.sobol_engine.draw(n_augment).to(device)
|
| 499 |
+
# We only need the first `num_intermediate_levels` dimensions
|
| 500 |
+
quasi_rand_points = sobol_points[:, :num_intermediate_levels]
|
| 501 |
+
else:
|
| 502 |
+
# Handle case where max_levels_in_batch is 2 (no intermediate points needed)
|
| 503 |
+
quasi_rand_points = torch.empty(n_augment, 0, device=device)
|
| 504 |
+
|
| 505 |
+
scaled_quasi_rand_levels = min_vals + value_range * quasi_rand_points
|
| 506 |
+
level_values = torch.cat([min_vals, max_vals, scaled_quasi_rand_levels], dim=1)
|
| 507 |
+
level_values, _ = torch.sort(level_values, dim=1)
|
| 508 |
+
|
| 509 |
+
# 5. Find the closest level using a mask to ignore padded values
|
| 510 |
+
series_expanded = series_to_augment.unsqueeze(2)
|
| 511 |
+
levels_expanded = level_values.unsqueeze(1)
|
| 512 |
+
diff = torch.abs(series_expanded - levels_expanded)
|
| 513 |
+
|
| 514 |
+
arange_mask = torch.arange(max_levels_in_batch, device=device).unsqueeze(0)
|
| 515 |
+
valid_levels_mask = arange_mask < n_levels_per_series.unsqueeze(1)
|
| 516 |
+
masked_diff = torch.where(valid_levels_mask.unsqueeze(1), diff, float("inf"))
|
| 517 |
+
closest_level_indices = torch.argmin(masked_diff, dim=2)
|
| 518 |
+
|
| 519 |
+
# 6. Gather the results from the original level values
|
| 520 |
+
quantized_subset = torch.gather(level_values, 1, closest_level_indices)
|
| 521 |
+
|
| 522 |
+
# 7. For flat series, revert to their original values
|
| 523 |
+
final_subset = torch.where(is_flat, series_to_augment, quantized_subset)
|
| 524 |
+
|
| 525 |
+
# 8. Place augmented data back into a copy of the original batch
|
| 526 |
+
augmented_batch_squeezed = time_series_squeezed.clone()
|
| 527 |
+
augmented_batch_squeezed[augment_mask] = final_subset
|
| 528 |
+
|
| 529 |
+
# Restore original shape before returning
|
| 530 |
+
if is_3d:
|
| 531 |
+
return augmented_batch_squeezed.unsqueeze(-1)
|
| 532 |
+
else:
|
| 533 |
+
return augmented_batch_squeezed
|
| 534 |
+
|
| 535 |
+
|
| 536 |
+
class MixUpAugmenter:
|
| 537 |
+
"""
|
| 538 |
+
Applies mixup augmentation by creating a weighted average of multiple time series.
|
| 539 |
+
|
| 540 |
+
This version includes an option for time-dependent mixup using Simplex Path
|
| 541 |
+
Interpolation, creating a smooth transition between different mixing weights.
|
| 542 |
+
"""
|
| 543 |
+
|
| 544 |
+
def __init__(
|
| 545 |
+
self,
|
| 546 |
+
max_n_series_to_combine: int = 10,
|
| 547 |
+
p_combine: float = 0.4,
|
| 548 |
+
p_time_dependent: float = 0.5,
|
| 549 |
+
randomize_k_per_series: bool = True,
|
| 550 |
+
dirichlet_alpha_range: Tuple[float, float] = (0.1, 5.0),
|
| 551 |
+
):
|
| 552 |
+
"""
|
| 553 |
+
Initializes the augmenter.
|
| 554 |
+
|
| 555 |
+
Args:
|
| 556 |
+
max_n_series_to_combine (int): The maximum number of series to combine.
|
| 557 |
+
The actual number k will be sampled from [2, max].
|
| 558 |
+
p_combine (float): The probability of replacing a series with a combination.
|
| 559 |
+
p_time_dependent (float): The probability of using the time-dependent
|
| 560 |
+
simplex path method for a given mixup operation. Defaults to 0.5.
|
| 561 |
+
randomize_k_per_series (bool): If True, each augmented series will be a
|
| 562 |
+
combination of a different number of series (k).
|
| 563 |
+
If False, one k is chosen for the whole batch.
|
| 564 |
+
dirichlet_alpha_range (Tuple[float, float]): The [min, max] range to sample the
|
| 565 |
+
Dirichlet 'alpha' from. A smaller alpha (e.g., 0.2) creates mixes
|
| 566 |
+
dominated by one series. A larger alpha (e.g., 5.0) creates
|
| 567 |
+
more uniform weights.
|
| 568 |
+
"""
|
| 569 |
+
assert max_n_series_to_combine >= 2, "Must combine at least 2 series."
|
| 570 |
+
assert 0.0 <= p_combine <= 1.0, "p_combine must be between 0 and 1."
|
| 571 |
+
assert 0.0 <= p_time_dependent <= 1.0, (
|
| 572 |
+
"p_time_dependent must be between 0 and 1."
|
| 573 |
+
)
|
| 574 |
+
assert (
|
| 575 |
+
dirichlet_alpha_range[0] > 0
|
| 576 |
+
and dirichlet_alpha_range[0] <= dirichlet_alpha_range[1]
|
| 577 |
+
)
|
| 578 |
+
self.max_k = max_n_series_to_combine
|
| 579 |
+
self.p_combine = p_combine
|
| 580 |
+
self.p_time_dependent = p_time_dependent
|
| 581 |
+
self.randomize_k = randomize_k_per_series
|
| 582 |
+
self.alpha_range = dirichlet_alpha_range
|
| 583 |
+
|
| 584 |
+
def _sample_alpha(self) -> float:
|
| 585 |
+
log_alpha_min = math.log10(self.alpha_range[0])
|
| 586 |
+
log_alpha_max = math.log10(self.alpha_range[1])
|
| 587 |
+
log_alpha = log_alpha_min + np.random.rand() * (log_alpha_max - log_alpha_min)
|
| 588 |
+
return float(10**log_alpha)
|
| 589 |
+
|
| 590 |
+
def _sample_k(self) -> int:
|
| 591 |
+
return int(torch.randint(2, self.max_k + 1, (1,)).item())
|
| 592 |
+
|
| 593 |
+
def _static_mix(
|
| 594 |
+
self,
|
| 595 |
+
source_series: torch.Tensor,
|
| 596 |
+
alpha: float,
|
| 597 |
+
return_weights: bool = False,
|
| 598 |
+
):
|
| 599 |
+
"""Mixes k source series using a single, static set of Dirichlet weights."""
|
| 600 |
+
k = int(source_series.shape[0])
|
| 601 |
+
device = source_series.device
|
| 602 |
+
concentration = torch.full((k,), float(alpha), device=device)
|
| 603 |
+
weights = torch.distributions.Dirichlet(concentration).sample()
|
| 604 |
+
weights_view = weights.view(k, 1, 1)
|
| 605 |
+
mixed_series = (source_series * weights_view).sum(dim=0, keepdim=True)
|
| 606 |
+
if return_weights:
|
| 607 |
+
return mixed_series, weights
|
| 608 |
+
return mixed_series
|
| 609 |
+
|
| 610 |
+
def _simplex_path_mix(
|
| 611 |
+
self,
|
| 612 |
+
source_series: torch.Tensor,
|
| 613 |
+
alpha: float,
|
| 614 |
+
return_weights: bool = False,
|
| 615 |
+
):
|
| 616 |
+
"""Mixes k series using time-varying weights interpolated along a simplex path."""
|
| 617 |
+
k, length, _ = source_series.shape
|
| 618 |
+
device = source_series.device
|
| 619 |
+
|
| 620 |
+
# 1. Sample two endpoint weight vectors from the Dirichlet distribution
|
| 621 |
+
concentration = torch.full((k,), float(alpha), device=device)
|
| 622 |
+
dirichlet_dist = torch.distributions.Dirichlet(concentration)
|
| 623 |
+
w_start = dirichlet_dist.sample()
|
| 624 |
+
w_end = dirichlet_dist.sample()
|
| 625 |
+
|
| 626 |
+
# 2. Create a linear ramp from 0 to 1
|
| 627 |
+
alpha_ramp = torch.linspace(0, 1, length, device=device)
|
| 628 |
+
|
| 629 |
+
# 3. Interpolate between the endpoint weights over time
|
| 630 |
+
# Reshape for broadcasting: w vectors become [k, 1], ramp becomes [1, length]
|
| 631 |
+
time_varying_weights = w_start.unsqueeze(1) * (
|
| 632 |
+
1 - alpha_ramp.unsqueeze(0)
|
| 633 |
+
) + w_end.unsqueeze(1) * alpha_ramp.unsqueeze(0)
|
| 634 |
+
# The result `time_varying_weights` has shape [k, length]
|
| 635 |
+
|
| 636 |
+
# 4. Apply the time-varying weights
|
| 637 |
+
weights_view = time_varying_weights.unsqueeze(-1) # Shape: [k, length, 1]
|
| 638 |
+
mixed_series = (source_series * weights_view).sum(dim=0, keepdim=True)
|
| 639 |
+
|
| 640 |
+
if return_weights:
|
| 641 |
+
return mixed_series, time_varying_weights
|
| 642 |
+
return mixed_series
|
| 643 |
+
|
| 644 |
+
def transform(
|
| 645 |
+
self, time_series_batch: torch.Tensor, return_debug_info: bool = False
|
| 646 |
+
):
|
| 647 |
+
"""
|
| 648 |
+
Applies the mixup augmentation, randomly choosing between static and
|
| 649 |
+
time-dependent mixing methods.
|
| 650 |
+
"""
|
| 651 |
+
with torch.no_grad():
|
| 652 |
+
if self.p_combine == 0:
|
| 653 |
+
return (
|
| 654 |
+
(time_series_batch, {}) if return_debug_info else time_series_batch
|
| 655 |
+
)
|
| 656 |
+
|
| 657 |
+
batch_size, _, _ = time_series_batch.shape
|
| 658 |
+
device = time_series_batch.device
|
| 659 |
+
|
| 660 |
+
if batch_size <= self.max_k:
|
| 661 |
+
return (
|
| 662 |
+
(time_series_batch, {}) if return_debug_info else time_series_batch
|
| 663 |
+
)
|
| 664 |
+
|
| 665 |
+
# 1. Decide which series to replace
|
| 666 |
+
augment_mask = torch.rand(batch_size, device=device) < self.p_combine
|
| 667 |
+
indices_to_replace = torch.where(augment_mask)[0]
|
| 668 |
+
n_augment = indices_to_replace.numel()
|
| 669 |
+
|
| 670 |
+
if n_augment == 0:
|
| 671 |
+
return (
|
| 672 |
+
(time_series_batch, {}) if return_debug_info else time_series_batch
|
| 673 |
+
)
|
| 674 |
+
|
| 675 |
+
# 2. Determine k for each series to augment
|
| 676 |
+
if self.randomize_k:
|
| 677 |
+
k_values = torch.randint(2, self.max_k + 1, (n_augment,), device=device)
|
| 678 |
+
else:
|
| 679 |
+
k = self._sample_k()
|
| 680 |
+
k_values = torch.full((n_augment,), k, device=device)
|
| 681 |
+
|
| 682 |
+
# 3. Augment series one by one
|
| 683 |
+
new_series_list = []
|
| 684 |
+
all_batch_indices = torch.arange(batch_size, device=device)
|
| 685 |
+
debug_info = {}
|
| 686 |
+
|
| 687 |
+
for i, target_idx in enumerate(indices_to_replace):
|
| 688 |
+
current_k = k_values[i].item()
|
| 689 |
+
|
| 690 |
+
# Sample source indices
|
| 691 |
+
candidate_mask = all_batch_indices != target_idx
|
| 692 |
+
candidates = all_batch_indices[candidate_mask]
|
| 693 |
+
perm = torch.randperm(candidates.shape[0], device=device)
|
| 694 |
+
source_indices = candidates[perm[:current_k]]
|
| 695 |
+
source_series = time_series_batch[source_indices]
|
| 696 |
+
|
| 697 |
+
alpha = self._sample_alpha()
|
| 698 |
+
mix_type = "static"
|
| 699 |
+
|
| 700 |
+
# Randomly choose between static and time-dependent mixup
|
| 701 |
+
if torch.rand(1).item() < self.p_time_dependent:
|
| 702 |
+
mixed_series, weights = self._simplex_path_mix(
|
| 703 |
+
source_series, alpha=alpha, return_weights=True
|
| 704 |
+
)
|
| 705 |
+
mix_type = "simplex"
|
| 706 |
+
else:
|
| 707 |
+
mixed_series, weights = self._static_mix(
|
| 708 |
+
source_series, alpha=alpha, return_weights=True
|
| 709 |
+
)
|
| 710 |
+
|
| 711 |
+
new_series_list.append(mixed_series)
|
| 712 |
+
|
| 713 |
+
if return_debug_info:
|
| 714 |
+
debug_info[target_idx.item()] = {
|
| 715 |
+
"source_indices": source_indices.cpu().numpy(),
|
| 716 |
+
"weights": weights.cpu().numpy(),
|
| 717 |
+
"alpha": alpha,
|
| 718 |
+
"k": current_k,
|
| 719 |
+
"mix_type": mix_type,
|
| 720 |
+
}
|
| 721 |
+
|
| 722 |
+
# 4. Place augmented series back into a clone of the original batch
|
| 723 |
+
augmented_batch = time_series_batch.clone()
|
| 724 |
+
if new_series_list:
|
| 725 |
+
new_series_tensor = torch.cat(new_series_list, dim=0)
|
| 726 |
+
augmented_batch[indices_to_replace] = new_series_tensor
|
| 727 |
+
|
| 728 |
+
if return_debug_info:
|
| 729 |
+
return augmented_batch.detach(), debug_info
|
| 730 |
+
return augmented_batch.detach()
|
| 731 |
+
|
| 732 |
+
|
| 733 |
+
class TimeFlipAugmenter:
|
| 734 |
+
"""
|
| 735 |
+
Applies time-reversal augmentation to a random subset of time series in a batch.
|
| 736 |
+
"""
|
| 737 |
+
|
| 738 |
+
def __init__(self, p_flip: float = 0.5):
|
| 739 |
+
"""
|
| 740 |
+
Initializes the TimeFlipAugmenter.
|
| 741 |
+
|
| 742 |
+
Args:
|
| 743 |
+
p_flip (float): The probability of flipping a single time series in the batch.
|
| 744 |
+
Defaults to 0.5.
|
| 745 |
+
"""
|
| 746 |
+
assert 0.0 <= p_flip <= 1.0, "Probability must be between 0 and 1."
|
| 747 |
+
self.p_flip = p_flip
|
| 748 |
+
|
| 749 |
+
def transform(self, time_series_batch: torch.Tensor) -> torch.Tensor:
|
| 750 |
+
"""
|
| 751 |
+
Applies time-reversal augmentation to a batch of time series.
|
| 752 |
+
|
| 753 |
+
Args:
|
| 754 |
+
time_series_batch (torch.Tensor): The input batch of time series with
|
| 755 |
+
shape (batch_size, seq_len, num_channels).
|
| 756 |
+
|
| 757 |
+
Returns:
|
| 758 |
+
torch.Tensor: The batch with some series potentially flipped.
|
| 759 |
+
"""
|
| 760 |
+
with torch.no_grad():
|
| 761 |
+
if self.p_flip == 0:
|
| 762 |
+
return time_series_batch
|
| 763 |
+
|
| 764 |
+
batch_size = time_series_batch.shape[0]
|
| 765 |
+
device = time_series_batch.device
|
| 766 |
+
|
| 767 |
+
# 1. Decide which series in the batch to flip
|
| 768 |
+
flip_mask = torch.rand(batch_size, device=device) < self.p_flip
|
| 769 |
+
indices_to_flip = torch.where(flip_mask)[0]
|
| 770 |
+
|
| 771 |
+
if indices_to_flip.numel() == 0:
|
| 772 |
+
return time_series_batch
|
| 773 |
+
|
| 774 |
+
# 2. Select the series to be flipped
|
| 775 |
+
series_to_flip = time_series_batch[indices_to_flip]
|
| 776 |
+
|
| 777 |
+
# 3. Flip them along the time dimension (dim=1)
|
| 778 |
+
flipped_series = torch.flip(series_to_flip, dims=[1])
|
| 779 |
+
|
| 780 |
+
# 4. Create a copy of the batch and place the flipped series into it
|
| 781 |
+
augmented_batch = time_series_batch.clone()
|
| 782 |
+
augmented_batch[indices_to_flip] = flipped_series
|
| 783 |
+
|
| 784 |
+
return augmented_batch
|
| 785 |
+
|
| 786 |
+
|
| 787 |
+
class YFlipAugmenter:
|
| 788 |
+
"""
|
| 789 |
+
Applies y-reversal augmentation to a random subset of time series in a batch.
|
| 790 |
+
"""
|
| 791 |
+
|
| 792 |
+
def __init__(self, p_flip: float = 0.5):
|
| 793 |
+
"""
|
| 794 |
+
Initializes the TimeFlipAugmenter.
|
| 795 |
+
|
| 796 |
+
Args:
|
| 797 |
+
p_flip (float): The probability of flipping a single time series in the batch.
|
| 798 |
+
Defaults to 0.5.
|
| 799 |
+
"""
|
| 800 |
+
assert 0.0 <= p_flip <= 1.0, "Probability must be between 0 and 1."
|
| 801 |
+
self.p_flip = p_flip
|
| 802 |
+
|
| 803 |
+
def transform(self, time_series_batch: torch.Tensor) -> torch.Tensor:
|
| 804 |
+
"""
|
| 805 |
+
Applies time-reversal augmentation to a batch of time series.
|
| 806 |
+
|
| 807 |
+
Args:
|
| 808 |
+
time_series_batch (torch.Tensor): The input batch of time series with
|
| 809 |
+
shape (batch_size, seq_len, num_channels).
|
| 810 |
+
|
| 811 |
+
Returns:
|
| 812 |
+
torch.Tensor: The batch with some series potentially flipped.
|
| 813 |
+
"""
|
| 814 |
+
with torch.no_grad():
|
| 815 |
+
if self.p_flip == 0:
|
| 816 |
+
return time_series_batch
|
| 817 |
+
|
| 818 |
+
batch_size = time_series_batch.shape[0]
|
| 819 |
+
device = time_series_batch.device
|
| 820 |
+
|
| 821 |
+
# 1. Decide which series in the batch to flip
|
| 822 |
+
flip_mask = torch.rand(batch_size, device=device) < self.p_flip
|
| 823 |
+
indices_to_flip = torch.where(flip_mask)[0]
|
| 824 |
+
|
| 825 |
+
if indices_to_flip.numel() == 0:
|
| 826 |
+
return time_series_batch
|
| 827 |
+
|
| 828 |
+
# 2. Select the series to be flipped
|
| 829 |
+
series_to_flip = time_series_batch[indices_to_flip]
|
| 830 |
+
|
| 831 |
+
# 3. Flip them along the time dimension (dim=1)
|
| 832 |
+
flipped_series = -series_to_flip
|
| 833 |
+
|
| 834 |
+
# 4. Create a copy of the batch and place the flipped series into it
|
| 835 |
+
augmented_batch = time_series_batch.clone()
|
| 836 |
+
augmented_batch[indices_to_flip] = flipped_series
|
| 837 |
+
|
| 838 |
+
return augmented_batch
|
| 839 |
+
|
| 840 |
+
|
| 841 |
+
class DifferentialAugmenter:
|
| 842 |
+
"""
|
| 843 |
+
Applies calculus-inspired augmentations. This version includes up to the
|
| 844 |
+
fourth derivative and uses nn.Conv1d with built-in 'reflect' padding for
|
| 845 |
+
cleaner and more efficient convolutions.
|
| 846 |
+
|
| 847 |
+
The Gaussian kernel size and sigma for the initial smoothing are randomly
|
| 848 |
+
sampled at every transform() call from user-defined ranges.
|
| 849 |
+
"""
|
| 850 |
+
|
| 851 |
+
def __init__(
|
| 852 |
+
self,
|
| 853 |
+
p_transform: float,
|
| 854 |
+
gaussian_kernel_size_range: Tuple[int, int] = (5, 51),
|
| 855 |
+
gaussian_sigma_range: Tuple[float, float] = (2.0, 20.0),
|
| 856 |
+
):
|
| 857 |
+
"""
|
| 858 |
+
Initializes the augmenter.
|
| 859 |
+
|
| 860 |
+
Args:
|
| 861 |
+
p_transform (float): The probability of applying an augmentation to any given
|
| 862 |
+
time series in a batch.
|
| 863 |
+
gaussian_kernel_size_range (Tuple[int, int]): The [min, max] inclusive range
|
| 864 |
+
for the Gaussian kernel size.
|
| 865 |
+
Sizes will be forced to be odd.
|
| 866 |
+
gaussian_sigma_range (Tuple[float, float]): The [min, max] inclusive range
|
| 867 |
+
for the Gaussian sigma.
|
| 868 |
+
"""
|
| 869 |
+
self.p_transform = p_transform
|
| 870 |
+
self.kernel_size_range = gaussian_kernel_size_range
|
| 871 |
+
self.sigma_range = gaussian_sigma_range
|
| 872 |
+
|
| 873 |
+
# Validate ranges
|
| 874 |
+
if not (
|
| 875 |
+
self.kernel_size_range[0] <= self.kernel_size_range[1]
|
| 876 |
+
and self.kernel_size_range[0] >= 3
|
| 877 |
+
):
|
| 878 |
+
raise ValueError(
|
| 879 |
+
"Invalid kernel size range. Ensure min <= max and min >= 3."
|
| 880 |
+
)
|
| 881 |
+
if not (self.sigma_range[0] <= self.sigma_range[1] and self.sigma_range[0] > 0):
|
| 882 |
+
raise ValueError("Invalid sigma range. Ensure min <= max and min > 0.")
|
| 883 |
+
|
| 884 |
+
# Cache for fixed-kernel convolution layers (Sobel, Laplace, etc.)
|
| 885 |
+
self.conv_cache: Dict[Tuple[int, torch.device], Dict[str, nn.Module]] = {}
|
| 886 |
+
|
| 887 |
+
def _create_fixed_kernel_layers(
|
| 888 |
+
self, num_channels: int, device: torch.device
|
| 889 |
+
) -> dict:
|
| 890 |
+
"""
|
| 891 |
+
Creates and configures nn.Conv1d layers for fixed-kernel derivative operations.
|
| 892 |
+
These layers are cached to improve performance.
|
| 893 |
+
"""
|
| 894 |
+
sobel_conv = nn.Conv1d(
|
| 895 |
+
in_channels=num_channels,
|
| 896 |
+
out_channels=num_channels,
|
| 897 |
+
kernel_size=3,
|
| 898 |
+
padding="same",
|
| 899 |
+
padding_mode="reflect",
|
| 900 |
+
groups=num_channels,
|
| 901 |
+
bias=False,
|
| 902 |
+
device=device,
|
| 903 |
+
)
|
| 904 |
+
laplace_conv = nn.Conv1d(
|
| 905 |
+
in_channels=num_channels,
|
| 906 |
+
out_channels=num_channels,
|
| 907 |
+
kernel_size=3,
|
| 908 |
+
padding="same",
|
| 909 |
+
padding_mode="reflect",
|
| 910 |
+
groups=num_channels,
|
| 911 |
+
bias=False,
|
| 912 |
+
device=device,
|
| 913 |
+
)
|
| 914 |
+
d3_conv = nn.Conv1d(
|
| 915 |
+
in_channels=num_channels,
|
| 916 |
+
out_channels=num_channels,
|
| 917 |
+
kernel_size=5,
|
| 918 |
+
padding="same",
|
| 919 |
+
padding_mode="reflect",
|
| 920 |
+
groups=num_channels,
|
| 921 |
+
bias=False,
|
| 922 |
+
device=device,
|
| 923 |
+
)
|
| 924 |
+
d4_conv = nn.Conv1d(
|
| 925 |
+
in_channels=num_channels,
|
| 926 |
+
out_channels=num_channels,
|
| 927 |
+
kernel_size=5,
|
| 928 |
+
padding="same",
|
| 929 |
+
padding_mode="reflect",
|
| 930 |
+
groups=num_channels,
|
| 931 |
+
bias=False,
|
| 932 |
+
device=device,
|
| 933 |
+
)
|
| 934 |
+
|
| 935 |
+
sobel_kernel = (
|
| 936 |
+
torch.tensor([-1, 0, 1], device=device, dtype=torch.float32)
|
| 937 |
+
.view(1, 1, -1)
|
| 938 |
+
.repeat(num_channels, 1, 1)
|
| 939 |
+
)
|
| 940 |
+
laplace_kernel = (
|
| 941 |
+
torch.tensor([1, -2, 1], device=device, dtype=torch.float32)
|
| 942 |
+
.view(1, 1, -1)
|
| 943 |
+
.repeat(num_channels, 1, 1)
|
| 944 |
+
)
|
| 945 |
+
d3_kernel = (
|
| 946 |
+
torch.tensor([-1, 2, 0, -2, 1], device=device, dtype=torch.float32)
|
| 947 |
+
.view(1, 1, -1)
|
| 948 |
+
.repeat(num_channels, 1, 1)
|
| 949 |
+
)
|
| 950 |
+
d4_kernel = (
|
| 951 |
+
torch.tensor([1, -4, 6, -4, 1], device=device, dtype=torch.float32)
|
| 952 |
+
.view(1, 1, -1)
|
| 953 |
+
.repeat(num_channels, 1, 1)
|
| 954 |
+
)
|
| 955 |
+
|
| 956 |
+
sobel_conv.weight.data = sobel_kernel
|
| 957 |
+
laplace_conv.weight.data = laplace_kernel
|
| 958 |
+
d3_conv.weight.data = d3_kernel
|
| 959 |
+
d4_conv.weight.data = d4_kernel
|
| 960 |
+
|
| 961 |
+
for layer in [sobel_conv, laplace_conv, d3_conv, d4_conv]:
|
| 962 |
+
layer.weight.requires_grad = False
|
| 963 |
+
|
| 964 |
+
return {
|
| 965 |
+
"sobel": sobel_conv,
|
| 966 |
+
"laplace": laplace_conv,
|
| 967 |
+
"d3": d3_conv,
|
| 968 |
+
"d4": d4_conv,
|
| 969 |
+
}
|
| 970 |
+
|
| 971 |
+
def _create_gaussian_layer(
|
| 972 |
+
self, kernel_size: int, sigma: float, num_channels: int, device: torch.device
|
| 973 |
+
) -> nn.Module:
|
| 974 |
+
"""Creates a single Gaussian convolution layer with the given dynamic parameters."""
|
| 975 |
+
gauss_conv = nn.Conv1d(
|
| 976 |
+
in_channels=num_channels,
|
| 977 |
+
out_channels=num_channels,
|
| 978 |
+
kernel_size=kernel_size,
|
| 979 |
+
padding="same",
|
| 980 |
+
padding_mode="reflect",
|
| 981 |
+
groups=num_channels,
|
| 982 |
+
bias=False,
|
| 983 |
+
device=device,
|
| 984 |
+
)
|
| 985 |
+
ax = torch.arange(
|
| 986 |
+
-(kernel_size // 2),
|
| 987 |
+
kernel_size // 2 + 1,
|
| 988 |
+
device=device,
|
| 989 |
+
dtype=torch.float32,
|
| 990 |
+
)
|
| 991 |
+
gauss_kernel = torch.exp(-0.5 * (ax / sigma) ** 2)
|
| 992 |
+
gauss_kernel /= gauss_kernel.sum()
|
| 993 |
+
gauss_kernel = gauss_kernel.view(1, 1, -1).repeat(num_channels, 1, 1)
|
| 994 |
+
gauss_conv.weight.data = gauss_kernel
|
| 995 |
+
gauss_conv.weight.requires_grad = False
|
| 996 |
+
return gauss_conv
|
| 997 |
+
|
| 998 |
+
def _rescale_signal(
|
| 999 |
+
self, processed_signal: torch.Tensor, original_signal: torch.Tensor
|
| 1000 |
+
) -> torch.Tensor:
|
| 1001 |
+
"""Rescales the processed signal to match the min/max range of the original."""
|
| 1002 |
+
original_min = torch.amin(original_signal, dim=2, keepdim=True)
|
| 1003 |
+
original_max = torch.amax(original_signal, dim=2, keepdim=True)
|
| 1004 |
+
processed_min = torch.amin(processed_signal, dim=2, keepdim=True)
|
| 1005 |
+
processed_max = torch.amax(processed_signal, dim=2, keepdim=True)
|
| 1006 |
+
|
| 1007 |
+
original_range = original_max - original_min
|
| 1008 |
+
processed_range = processed_max - processed_min
|
| 1009 |
+
epsilon = 1e-8
|
| 1010 |
+
rescaled_signal = (
|
| 1011 |
+
(processed_signal - processed_min) / (processed_range + epsilon)
|
| 1012 |
+
) * original_range + original_min
|
| 1013 |
+
return torch.where(original_range < epsilon, original_signal, rescaled_signal)
|
| 1014 |
+
|
| 1015 |
+
def transform(self, time_series_batch: torch.Tensor) -> torch.Tensor:
|
| 1016 |
+
"""Applies a random augmentation to a subset of the batch."""
|
| 1017 |
+
with torch.no_grad():
|
| 1018 |
+
if self.p_transform == 0:
|
| 1019 |
+
return time_series_batch
|
| 1020 |
+
|
| 1021 |
+
batch_size, seq_len, num_channels = time_series_batch.shape
|
| 1022 |
+
device = time_series_batch.device
|
| 1023 |
+
|
| 1024 |
+
augment_mask = torch.rand(batch_size, device=device) < self.p_transform
|
| 1025 |
+
indices_to_augment = torch.where(augment_mask)[0]
|
| 1026 |
+
num_to_augment = indices_to_augment.numel()
|
| 1027 |
+
|
| 1028 |
+
if num_to_augment == 0:
|
| 1029 |
+
return time_series_batch
|
| 1030 |
+
|
| 1031 |
+
# --- 🎲 Randomly sample Gaussian parameters for this call ---
|
| 1032 |
+
min_k, max_k = self.kernel_size_range
|
| 1033 |
+
kernel_size = torch.randint(min_k, max_k + 1, (1,)).item()
|
| 1034 |
+
kernel_size = kernel_size // 2 * 2 + 1 # Ensure kernel size is odd
|
| 1035 |
+
|
| 1036 |
+
min_s, max_s = self.sigma_range
|
| 1037 |
+
sigma = (min_s + (max_s - min_s) * torch.rand(1)).item()
|
| 1038 |
+
|
| 1039 |
+
# --- Get/Create Convolution Layers ---
|
| 1040 |
+
gauss_conv = self._create_gaussian_layer(
|
| 1041 |
+
kernel_size, sigma, num_channels, device
|
| 1042 |
+
)
|
| 1043 |
+
|
| 1044 |
+
cache_key = (num_channels, device)
|
| 1045 |
+
if cache_key not in self.conv_cache:
|
| 1046 |
+
self.conv_cache[cache_key] = self._create_fixed_kernel_layers(
|
| 1047 |
+
num_channels, device
|
| 1048 |
+
)
|
| 1049 |
+
fixed_layers = self.conv_cache[cache_key]
|
| 1050 |
+
|
| 1051 |
+
# --- Apply Augmentations ---
|
| 1052 |
+
subset_to_augment = time_series_batch[indices_to_augment]
|
| 1053 |
+
subset_permuted = subset_to_augment.permute(0, 2, 1)
|
| 1054 |
+
|
| 1055 |
+
op_choices = torch.randint(0, 6, (num_to_augment,), device=device)
|
| 1056 |
+
|
| 1057 |
+
smoothed_subset = gauss_conv(subset_permuted)
|
| 1058 |
+
sobel_on_smoothed = fixed_layers["sobel"](smoothed_subset)
|
| 1059 |
+
laplace_on_smoothed = fixed_layers["laplace"](smoothed_subset)
|
| 1060 |
+
d3_on_smoothed = fixed_layers["d3"](smoothed_subset)
|
| 1061 |
+
d4_on_smoothed = fixed_layers["d4"](smoothed_subset)
|
| 1062 |
+
|
| 1063 |
+
gauss_result = self._rescale_signal(smoothed_subset, subset_permuted)
|
| 1064 |
+
sobel_result = self._rescale_signal(sobel_on_smoothed, subset_permuted)
|
| 1065 |
+
laplace_result = self._rescale_signal(laplace_on_smoothed, subset_permuted)
|
| 1066 |
+
d3_result = self._rescale_signal(d3_on_smoothed, subset_permuted)
|
| 1067 |
+
d4_result = self._rescale_signal(d4_on_smoothed, subset_permuted)
|
| 1068 |
+
|
| 1069 |
+
use_right_integral = torch.rand(num_to_augment, 1, 1, device=device) > 0.5
|
| 1070 |
+
flipped_subset = torch.flip(subset_permuted, dims=[2])
|
| 1071 |
+
right_integral = torch.flip(torch.cumsum(flipped_subset, dim=2), dims=[2])
|
| 1072 |
+
left_integral = torch.cumsum(subset_permuted, dim=2)
|
| 1073 |
+
integral_result = torch.where(
|
| 1074 |
+
use_right_integral, right_integral, left_integral
|
| 1075 |
+
)
|
| 1076 |
+
integral_result_normalized = self._rescale_signal(
|
| 1077 |
+
integral_result, subset_permuted
|
| 1078 |
+
)
|
| 1079 |
+
|
| 1080 |
+
# --- Assemble the results based on op_choices ---
|
| 1081 |
+
op_choices_view = op_choices.view(-1, 1, 1)
|
| 1082 |
+
augmented_subset = torch.where(
|
| 1083 |
+
op_choices_view == 0, gauss_result, subset_permuted
|
| 1084 |
+
)
|
| 1085 |
+
augmented_subset = torch.where(
|
| 1086 |
+
op_choices_view == 1, sobel_result, augmented_subset
|
| 1087 |
+
)
|
| 1088 |
+
augmented_subset = torch.where(
|
| 1089 |
+
op_choices_view == 2, laplace_result, augmented_subset
|
| 1090 |
+
)
|
| 1091 |
+
augmented_subset = torch.where(
|
| 1092 |
+
op_choices_view == 3, integral_result_normalized, augmented_subset
|
| 1093 |
+
)
|
| 1094 |
+
augmented_subset = torch.where(
|
| 1095 |
+
op_choices_view == 4, d3_result, augmented_subset
|
| 1096 |
+
)
|
| 1097 |
+
augmented_subset = torch.where(
|
| 1098 |
+
op_choices_view == 5, d4_result, augmented_subset
|
| 1099 |
+
)
|
| 1100 |
+
|
| 1101 |
+
augmented_subset_final = augmented_subset.permute(0, 2, 1)
|
| 1102 |
+
augmented_batch = time_series_batch.clone()
|
| 1103 |
+
augmented_batch[indices_to_augment] = augmented_subset_final
|
| 1104 |
+
|
| 1105 |
+
return augmented_batch
|
| 1106 |
+
|
| 1107 |
+
|
| 1108 |
+
class RandomConvAugmenter:
|
| 1109 |
+
"""
|
| 1110 |
+
Applies a stack of 1-to-N random 1D convolutions to a time series batch.
|
| 1111 |
+
|
| 1112 |
+
This augmenter is inspired by the principles of ROCKET and RandConv,
|
| 1113 |
+
randomizing nearly every aspect of the convolution process to create a
|
| 1114 |
+
highly diverse set of transformations. This version includes multiple
|
| 1115 |
+
kernel generation strategies, random padding modes, and optional non-linearities.
|
| 1116 |
+
"""
|
| 1117 |
+
|
| 1118 |
+
def __init__(
|
| 1119 |
+
self,
|
| 1120 |
+
p_transform: float = 0.5,
|
| 1121 |
+
kernel_size_range: Tuple[int, int] = (3, 31),
|
| 1122 |
+
dilation_range: Tuple[int, int] = (1, 8),
|
| 1123 |
+
layer_range: Tuple[int, int] = (1, 3),
|
| 1124 |
+
sigma_range: Tuple[float, float] = (0.5, 5.0),
|
| 1125 |
+
bias_range: Tuple[float, float] = (-0.5, 0.5),
|
| 1126 |
+
):
|
| 1127 |
+
"""
|
| 1128 |
+
Initializes the augmenter.
|
| 1129 |
+
|
| 1130 |
+
Args:
|
| 1131 |
+
p_transform (float): Probability of applying the augmentation to a series.
|
| 1132 |
+
kernel_size_range (Tuple[int, int]): [min, max] range for kernel sizes.
|
| 1133 |
+
Must be odd numbers.
|
| 1134 |
+
dilation_range (Tuple[int, int]): [min, max] range for dilation factors.
|
| 1135 |
+
layer_range (Tuple[int, int]): [min, max] range for the number of
|
| 1136 |
+
stacked convolution layers.
|
| 1137 |
+
sigma_range (Tuple[float, float]): [min, max] range for the sigma of
|
| 1138 |
+
Gaussian kernels.
|
| 1139 |
+
bias_range (Tuple[float, float]): [min, max] range for the bias term.
|
| 1140 |
+
"""
|
| 1141 |
+
assert kernel_size_range[0] % 2 == 1 and kernel_size_range[1] % 2 == 1, (
|
| 1142 |
+
"Kernel sizes must be odd."
|
| 1143 |
+
)
|
| 1144 |
+
|
| 1145 |
+
self.p_transform = p_transform
|
| 1146 |
+
self.kernel_size_range = kernel_size_range
|
| 1147 |
+
self.dilation_range = dilation_range
|
| 1148 |
+
self.layer_range = layer_range
|
| 1149 |
+
self.sigma_range = sigma_range
|
| 1150 |
+
self.bias_range = bias_range
|
| 1151 |
+
self.padding_modes = ["reflect", "replicate", "circular"]
|
| 1152 |
+
|
| 1153 |
+
def _rescale_signal(
|
| 1154 |
+
self, processed_signal: torch.Tensor, original_signal: torch.Tensor
|
| 1155 |
+
) -> torch.Tensor:
|
| 1156 |
+
"""Rescales the processed signal to match the min/max range of the original."""
|
| 1157 |
+
original_min = torch.amin(original_signal, dim=-1, keepdim=True)
|
| 1158 |
+
original_max = torch.amax(original_signal, dim=-1, keepdim=True)
|
| 1159 |
+
processed_min = torch.amin(processed_signal, dim=-1, keepdim=True)
|
| 1160 |
+
processed_max = torch.amax(processed_signal, dim=-1, keepdim=True)
|
| 1161 |
+
|
| 1162 |
+
original_range = original_max - original_min
|
| 1163 |
+
processed_range = processed_max - processed_min
|
| 1164 |
+
epsilon = 1e-8
|
| 1165 |
+
|
| 1166 |
+
is_flat = processed_range < epsilon
|
| 1167 |
+
|
| 1168 |
+
rescaled_signal = (
|
| 1169 |
+
(processed_signal - processed_min) / (processed_range + epsilon)
|
| 1170 |
+
) * original_range + original_min
|
| 1171 |
+
|
| 1172 |
+
original_mean = torch.mean(original_signal, dim=-1, keepdim=True)
|
| 1173 |
+
flat_rescaled = original_mean.expand_as(original_signal)
|
| 1174 |
+
|
| 1175 |
+
return torch.where(is_flat, flat_rescaled, rescaled_signal)
|
| 1176 |
+
|
| 1177 |
+
def _apply_random_conv_stack(self, series: torch.Tensor) -> torch.Tensor:
|
| 1178 |
+
"""
|
| 1179 |
+
Applies a randomly configured stack of convolutions to a single time series.
|
| 1180 |
+
|
| 1181 |
+
Args:
|
| 1182 |
+
series (torch.Tensor): A single time series of shape (1, num_channels, seq_len).
|
| 1183 |
+
|
| 1184 |
+
Returns:
|
| 1185 |
+
torch.Tensor: The augmented time series.
|
| 1186 |
+
"""
|
| 1187 |
+
num_channels = series.shape[1]
|
| 1188 |
+
device = series.device
|
| 1189 |
+
|
| 1190 |
+
num_layers = torch.randint(
|
| 1191 |
+
self.layer_range[0], self.layer_range[1] + 1, (1,)
|
| 1192 |
+
).item()
|
| 1193 |
+
|
| 1194 |
+
processed_series = series
|
| 1195 |
+
for i in range(num_layers):
|
| 1196 |
+
# 1. Sample kernel size
|
| 1197 |
+
k_min, k_max = self.kernel_size_range
|
| 1198 |
+
kernel_size = torch.randint(k_min // 2, k_max // 2 + 1, (1,)).item() * 2 + 1
|
| 1199 |
+
|
| 1200 |
+
# 2. Sample dilation
|
| 1201 |
+
d_min, d_max = self.dilation_range
|
| 1202 |
+
dilation = torch.randint(d_min, d_max + 1, (1,)).item()
|
| 1203 |
+
|
| 1204 |
+
# 3. Sample bias
|
| 1205 |
+
b_min, b_max = self.bias_range
|
| 1206 |
+
bias_val = (b_min + (b_max - b_min) * torch.rand(1)).item()
|
| 1207 |
+
|
| 1208 |
+
# 4. Sample padding mode
|
| 1209 |
+
padding_mode = np.random.choice(self.padding_modes)
|
| 1210 |
+
|
| 1211 |
+
conv_layer = nn.Conv1d(
|
| 1212 |
+
in_channels=num_channels,
|
| 1213 |
+
out_channels=num_channels,
|
| 1214 |
+
kernel_size=kernel_size,
|
| 1215 |
+
dilation=dilation,
|
| 1216 |
+
padding="same", # Let PyTorch handle padding calculation
|
| 1217 |
+
padding_mode=padding_mode,
|
| 1218 |
+
groups=num_channels,
|
| 1219 |
+
bias=True,
|
| 1220 |
+
device=device,
|
| 1221 |
+
)
|
| 1222 |
+
|
| 1223 |
+
# 5. Sample kernel weights from a wider variety of types
|
| 1224 |
+
weight_type = torch.randint(0, 4, (1,)).item()
|
| 1225 |
+
if weight_type == 0: # Gaussian kernel
|
| 1226 |
+
s_min, s_max = self.sigma_range
|
| 1227 |
+
sigma = (s_min + (s_max - s_min) * torch.rand(1)).item()
|
| 1228 |
+
ax = torch.arange(
|
| 1229 |
+
-(kernel_size // 2),
|
| 1230 |
+
kernel_size // 2 + 1,
|
| 1231 |
+
device=device,
|
| 1232 |
+
dtype=torch.float32,
|
| 1233 |
+
)
|
| 1234 |
+
kernel = torch.exp(-0.5 * (ax / sigma) ** 2)
|
| 1235 |
+
elif weight_type == 1: # Standard normal kernel
|
| 1236 |
+
kernel = torch.randn(kernel_size, device=device)
|
| 1237 |
+
elif weight_type == 2: # Polynomial kernel
|
| 1238 |
+
coeffs = torch.randn(3, device=device) # a, b, c for ax^2+bx+c
|
| 1239 |
+
x_vals = torch.linspace(-1, 1, kernel_size, device=device)
|
| 1240 |
+
kernel = coeffs[0] * x_vals**2 + coeffs[1] * x_vals + coeffs[2]
|
| 1241 |
+
else: # Noisy Sobel kernel
|
| 1242 |
+
# Ensure kernel is large enough for a Sobel filter
|
| 1243 |
+
actual_kernel_size = 3 if kernel_size < 3 else kernel_size
|
| 1244 |
+
sobel_base = torch.tensor(
|
| 1245 |
+
[-1, 0, 1], dtype=torch.float32, device=device
|
| 1246 |
+
)
|
| 1247 |
+
noise = torch.randn(3, device=device) * 0.1
|
| 1248 |
+
noisy_sobel = sobel_base + noise
|
| 1249 |
+
# Pad if the random kernel size is larger than 3
|
| 1250 |
+
pad_total = actual_kernel_size - 3
|
| 1251 |
+
pad_left = pad_total // 2
|
| 1252 |
+
pad_right = pad_total - pad_left
|
| 1253 |
+
kernel = F.pad(noisy_sobel, (pad_left, pad_right), "constant", 0)
|
| 1254 |
+
|
| 1255 |
+
# 6. Probabilistic normalization
|
| 1256 |
+
if torch.rand(1).item() < 0.8: # 80% chance to normalize
|
| 1257 |
+
kernel /= torch.sum(torch.abs(kernel)) + 1e-8
|
| 1258 |
+
|
| 1259 |
+
kernel = kernel.view(1, 1, -1).repeat(num_channels, 1, 1)
|
| 1260 |
+
|
| 1261 |
+
conv_layer.weight.data = kernel
|
| 1262 |
+
conv_layer.bias.data.fill_(bias_val)
|
| 1263 |
+
conv_layer.weight.requires_grad = False
|
| 1264 |
+
conv_layer.bias.requires_grad = False
|
| 1265 |
+
|
| 1266 |
+
# Apply convolution
|
| 1267 |
+
processed_series = conv_layer(processed_series)
|
| 1268 |
+
|
| 1269 |
+
# 7. Optional non-linearity (not on the last layer)
|
| 1270 |
+
if i < num_layers - 1:
|
| 1271 |
+
activation_type = torch.randint(0, 3, (1,)).item()
|
| 1272 |
+
if activation_type == 1:
|
| 1273 |
+
processed_series = F.relu(processed_series)
|
| 1274 |
+
elif activation_type == 2:
|
| 1275 |
+
processed_series = torch.tanh(processed_series)
|
| 1276 |
+
# if 0, do nothing (linear)
|
| 1277 |
+
|
| 1278 |
+
return processed_series
|
| 1279 |
+
|
| 1280 |
+
def transform(self, time_series_batch: torch.Tensor) -> torch.Tensor:
|
| 1281 |
+
"""Applies a random augmentation to a subset of the batch."""
|
| 1282 |
+
with torch.no_grad():
|
| 1283 |
+
if self.p_transform == 0:
|
| 1284 |
+
return time_series_batch
|
| 1285 |
+
|
| 1286 |
+
batch_size, seq_len, num_channels = time_series_batch.shape
|
| 1287 |
+
device = time_series_batch.device
|
| 1288 |
+
|
| 1289 |
+
augment_mask = torch.rand(batch_size, device=device) < self.p_transform
|
| 1290 |
+
indices_to_augment = torch.where(augment_mask)[0]
|
| 1291 |
+
num_to_augment = indices_to_augment.numel()
|
| 1292 |
+
|
| 1293 |
+
if num_to_augment == 0:
|
| 1294 |
+
return time_series_batch
|
| 1295 |
+
|
| 1296 |
+
subset_to_augment = time_series_batch[indices_to_augment]
|
| 1297 |
+
|
| 1298 |
+
subset_permuted = subset_to_augment.permute(0, 2, 1)
|
| 1299 |
+
|
| 1300 |
+
augmented_subset_list = []
|
| 1301 |
+
for i in range(num_to_augment):
|
| 1302 |
+
original_series = subset_permuted[i : i + 1]
|
| 1303 |
+
augmented_series = self._apply_random_conv_stack(original_series)
|
| 1304 |
+
|
| 1305 |
+
rescaled_series = self._rescale_signal(
|
| 1306 |
+
augmented_series.squeeze(0), original_series.squeeze(0)
|
| 1307 |
+
)
|
| 1308 |
+
augmented_subset_list.append(rescaled_series.unsqueeze(0))
|
| 1309 |
+
|
| 1310 |
+
if augmented_subset_list:
|
| 1311 |
+
augmented_subset = torch.cat(augmented_subset_list, dim=0)
|
| 1312 |
+
augmented_subset_final = augmented_subset.permute(0, 2, 1)
|
| 1313 |
+
|
| 1314 |
+
augmented_batch = time_series_batch.clone()
|
| 1315 |
+
augmented_batch[indices_to_augment] = augmented_subset_final
|
| 1316 |
+
return augmented_batch
|
| 1317 |
+
else:
|
| 1318 |
+
return time_series_batch
|
src/data/batch_composer.py
ADDED
|
@@ -0,0 +1,705 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import logging
|
| 3 |
+
import random
|
| 4 |
+
from typing import Dict, Optional, Tuple
|
| 5 |
+
|
| 6 |
+
import numpy as np
|
| 7 |
+
import pandas as pd
|
| 8 |
+
import torch
|
| 9 |
+
|
| 10 |
+
from src.data.augmentations import (
|
| 11 |
+
NanAugmenter,
|
| 12 |
+
)
|
| 13 |
+
from src.data.constants import DEFAULT_NAN_STATS_PATH, LENGTH_CHOICES, LENGTH_WEIGHTS
|
| 14 |
+
from src.data.containers import BatchTimeSeriesContainer
|
| 15 |
+
from src.data.datasets import CyclicalBatchDataset
|
| 16 |
+
from src.data.frequency import Frequency
|
| 17 |
+
from src.data.scalers import MeanScaler, MedianScaler, MinMaxScaler, RobustScaler
|
| 18 |
+
from src.data.utils import sample_future_length
|
| 19 |
+
|
| 20 |
+
logging.basicConfig(level=logging.INFO)
|
| 21 |
+
logger = logging.getLogger(__name__)
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
class BatchComposer:
|
| 25 |
+
"""
|
| 26 |
+
Composes batches from saved generator data according to specified proportions.
|
| 27 |
+
Manages multiple CyclicalBatchDataset instances and creates uniform or mixed batches.
|
| 28 |
+
"""
|
| 29 |
+
|
| 30 |
+
def __init__(
|
| 31 |
+
self,
|
| 32 |
+
base_data_dir: str,
|
| 33 |
+
generator_proportions: Optional[Dict[str, float]] = None,
|
| 34 |
+
mixed_batches: bool = True,
|
| 35 |
+
device: Optional[torch.device] = None,
|
| 36 |
+
augmentations: Optional[Dict[str, bool]] = None,
|
| 37 |
+
augmentation_probabilities: Optional[Dict[str, float]] = None,
|
| 38 |
+
nan_stats_path: Optional[str] = None,
|
| 39 |
+
nan_patterns_path: Optional[str] = None,
|
| 40 |
+
global_seed: int = 42,
|
| 41 |
+
chosen_scaler_name: Optional[str] = None,
|
| 42 |
+
rank: int = 0,
|
| 43 |
+
world_size: int = 1,
|
| 44 |
+
):
|
| 45 |
+
"""
|
| 46 |
+
Initialize the BatchComposer.
|
| 47 |
+
|
| 48 |
+
Args:
|
| 49 |
+
base_data_dir: Base directory containing generator subdirectories
|
| 50 |
+
generator_proportions: Dict mapping generator names to proportions
|
| 51 |
+
mixed_batches: If True, create mixed batches; if False, uniform batches
|
| 52 |
+
device: Device to load tensors to
|
| 53 |
+
augmentations: Dict mapping augmentation names to booleans
|
| 54 |
+
augmentation_probabilities: Dict mapping augmentation names to probabilities
|
| 55 |
+
global_seed: Global random seed
|
| 56 |
+
chosen_scaler_name: Name of the scaler that used in training
|
| 57 |
+
rank: Rank of current process for distributed data loading
|
| 58 |
+
world_size: Total number of processes for distributed data loading
|
| 59 |
+
"""
|
| 60 |
+
self.base_data_dir = base_data_dir
|
| 61 |
+
self.mixed_batches = mixed_batches
|
| 62 |
+
self.device = device
|
| 63 |
+
self.global_seed = global_seed
|
| 64 |
+
self.nan_stats_path = nan_stats_path
|
| 65 |
+
self.nan_patterns_path = nan_patterns_path
|
| 66 |
+
self.rank = rank
|
| 67 |
+
self.world_size = world_size
|
| 68 |
+
self.augmentation_probabilities = augmentation_probabilities or {
|
| 69 |
+
"noise_augmentation": 0.3,
|
| 70 |
+
"scaler_augmentation": 0.5,
|
| 71 |
+
}
|
| 72 |
+
# Optional preferred scaler name provided by training config
|
| 73 |
+
self.chosen_scaler_name = (
|
| 74 |
+
chosen_scaler_name.lower() if chosen_scaler_name is not None else None
|
| 75 |
+
)
|
| 76 |
+
|
| 77 |
+
# Setup random state
|
| 78 |
+
self.rng = np.random.default_rng(global_seed)
|
| 79 |
+
random.seed(global_seed)
|
| 80 |
+
torch.manual_seed(global_seed)
|
| 81 |
+
|
| 82 |
+
# Setup augmentations
|
| 83 |
+
self._setup_augmentations(augmentations)
|
| 84 |
+
|
| 85 |
+
# Setup generator proportions
|
| 86 |
+
self._setup_proportions(generator_proportions)
|
| 87 |
+
|
| 88 |
+
# Initialize datasets
|
| 89 |
+
self.datasets = self._initialize_datasets()
|
| 90 |
+
|
| 91 |
+
logger.info(
|
| 92 |
+
f"Initialized BatchComposer with {len(self.datasets)} generators, "
|
| 93 |
+
f"mixed_batches={mixed_batches}, proportions={self.generator_proportions}, "
|
| 94 |
+
f"augmentations={self.augmentations}, "
|
| 95 |
+
f"augmentation_probabilities={self.augmentation_probabilities}"
|
| 96 |
+
)
|
| 97 |
+
|
| 98 |
+
def _setup_augmentations(self, augmentations: Optional[Dict[str, bool]]):
|
| 99 |
+
"""Setup only the augmentations that should remain online (NaN)."""
|
| 100 |
+
default_augmentations = {
|
| 101 |
+
"nan_augmentation": False,
|
| 102 |
+
"scaler_augmentation": False,
|
| 103 |
+
"length_shortening": False,
|
| 104 |
+
}
|
| 105 |
+
|
| 106 |
+
self.augmentations = augmentations or default_augmentations
|
| 107 |
+
|
| 108 |
+
# Initialize NaN augmenter if needed
|
| 109 |
+
self.nan_augmenter = None
|
| 110 |
+
if self.augmentations.get("nan_augmentation", False):
|
| 111 |
+
stats_path_to_use = self.nan_stats_path or DEFAULT_NAN_STATS_PATH
|
| 112 |
+
stats = json.load(open(stats_path_to_use, "r"))
|
| 113 |
+
self.nan_augmenter = NanAugmenter(
|
| 114 |
+
p_series_has_nan=stats["p_series_has_nan"],
|
| 115 |
+
nan_ratio_distribution=stats["nan_ratio_distribution"],
|
| 116 |
+
nan_length_distribution=stats["nan_length_distribution"],
|
| 117 |
+
nan_patterns_path=self.nan_patterns_path,
|
| 118 |
+
)
|
| 119 |
+
|
| 120 |
+
def _should_apply_scaler_augmentation(self) -> bool:
|
| 121 |
+
"""
|
| 122 |
+
Decide whether to apply scaler augmentation for a single series based on
|
| 123 |
+
the boolean toggle and probability from the configuration.
|
| 124 |
+
"""
|
| 125 |
+
if not self.augmentations.get("scaler_augmentation", False):
|
| 126 |
+
return False
|
| 127 |
+
probability = float(
|
| 128 |
+
self.augmentation_probabilities.get("scaler_augmentation", 0.0)
|
| 129 |
+
)
|
| 130 |
+
probability = max(0.0, min(1.0, probability))
|
| 131 |
+
return bool(self.rng.random() < probability)
|
| 132 |
+
|
| 133 |
+
def _choose_random_scaler(self) -> Optional[object]:
|
| 134 |
+
"""
|
| 135 |
+
Choose a random scaler for augmentation, explicitly avoiding the one that
|
| 136 |
+
is already selected in the training configuration (if any).
|
| 137 |
+
|
| 138 |
+
Returns an instance of the selected scaler or None when no valid option exists.
|
| 139 |
+
"""
|
| 140 |
+
chosen: Optional[str] = None
|
| 141 |
+
if self.chosen_scaler_name is not None:
|
| 142 |
+
chosen = self.chosen_scaler_name.strip().lower()
|
| 143 |
+
|
| 144 |
+
candidates = ["custom_robust", "minmax", "median", "mean"]
|
| 145 |
+
|
| 146 |
+
# Remove the chosen scaler from the candidates
|
| 147 |
+
if chosen in candidates:
|
| 148 |
+
candidates = [c for c in candidates if c != chosen]
|
| 149 |
+
if not candidates:
|
| 150 |
+
return None
|
| 151 |
+
|
| 152 |
+
pick = str(self.rng.choice(candidates))
|
| 153 |
+
if pick == "custom_robust":
|
| 154 |
+
return RobustScaler()
|
| 155 |
+
if pick == "minmax":
|
| 156 |
+
return MinMaxScaler()
|
| 157 |
+
if pick == "median":
|
| 158 |
+
return MedianScaler()
|
| 159 |
+
if pick == "mean":
|
| 160 |
+
return MeanScaler()
|
| 161 |
+
return None
|
| 162 |
+
|
| 163 |
+
def _setup_proportions(self, generator_proportions):
|
| 164 |
+
"""Setup default or custom generator proportions."""
|
| 165 |
+
default_proportions = {
|
| 166 |
+
"forecast_pfn": 1.0,
|
| 167 |
+
"gp": 1.0,
|
| 168 |
+
"kernel": 1.0,
|
| 169 |
+
"sinewave": 1.0,
|
| 170 |
+
"sawtooth": 1.0,
|
| 171 |
+
"step": 0.1,
|
| 172 |
+
"anomaly": 1.0,
|
| 173 |
+
"spike": 2.0,
|
| 174 |
+
"cauker_univariate": 2.0,
|
| 175 |
+
"cauker_multivariate": 0.00,
|
| 176 |
+
"lmc": 0.00, # multivariate
|
| 177 |
+
"ou_process": 1.0,
|
| 178 |
+
"audio_financial_volatility": 0.1,
|
| 179 |
+
"audio_multi_scale_fractal": 0.1,
|
| 180 |
+
"audio_network_topology": 0.5,
|
| 181 |
+
"audio_stochastic_rhythm": 1.0,
|
| 182 |
+
"augmented_per_sample_2048": 3.0,
|
| 183 |
+
"augmented_temp_batch_2048": 3.0,
|
| 184 |
+
}
|
| 185 |
+
self.generator_proportions = generator_proportions or default_proportions
|
| 186 |
+
|
| 187 |
+
# Normalize proportions
|
| 188 |
+
total = sum(self.generator_proportions.values())
|
| 189 |
+
if total <= 0:
|
| 190 |
+
raise ValueError("Total generator proportions must be positive")
|
| 191 |
+
self.generator_proportions = {
|
| 192 |
+
k: v / total for k, v in self.generator_proportions.items()
|
| 193 |
+
}
|
| 194 |
+
|
| 195 |
+
def _initialize_datasets(self) -> Dict[str, CyclicalBatchDataset]:
|
| 196 |
+
"""Initialize CyclicalBatchDataset for each generator with proportion > 0."""
|
| 197 |
+
datasets = {}
|
| 198 |
+
|
| 199 |
+
for generator_name, proportion in self.generator_proportions.items():
|
| 200 |
+
# Only initialize datasets for generators with positive proportion
|
| 201 |
+
if proportion <= 0:
|
| 202 |
+
logger.info(f"Skipping {generator_name} (proportion = {proportion})")
|
| 203 |
+
continue
|
| 204 |
+
|
| 205 |
+
batches_dir = f"{self.base_data_dir}/{generator_name}"
|
| 206 |
+
|
| 207 |
+
try:
|
| 208 |
+
dataset = CyclicalBatchDataset(
|
| 209 |
+
batches_dir=batches_dir,
|
| 210 |
+
generator_type=generator_name,
|
| 211 |
+
device=None,
|
| 212 |
+
prefetch_next=True,
|
| 213 |
+
prefetch_threshold=32,
|
| 214 |
+
rank=self.rank,
|
| 215 |
+
world_size=self.world_size,
|
| 216 |
+
)
|
| 217 |
+
datasets[generator_name] = dataset
|
| 218 |
+
logger.info(
|
| 219 |
+
f"Loaded dataset for {generator_name} (proportion = {proportion})"
|
| 220 |
+
)
|
| 221 |
+
|
| 222 |
+
except Exception as e:
|
| 223 |
+
logger.warning(f"Failed to load dataset for {generator_name}: {e}")
|
| 224 |
+
continue
|
| 225 |
+
|
| 226 |
+
if not datasets:
|
| 227 |
+
raise ValueError(
|
| 228 |
+
f"No valid datasets found in {self.base_data_dir} or all generators have proportion <= 0"
|
| 229 |
+
)
|
| 230 |
+
|
| 231 |
+
return datasets
|
| 232 |
+
|
| 233 |
+
def _convert_sample_to_tensors(
|
| 234 |
+
self, sample: dict, future_length: Optional[int] = None
|
| 235 |
+
) -> Tuple[torch.Tensor, np.datetime64, Frequency]:
|
| 236 |
+
"""
|
| 237 |
+
Convert a sample dict to tensors and metadata.
|
| 238 |
+
|
| 239 |
+
Args:
|
| 240 |
+
sample: Sample dict from CyclicalBatchDataset
|
| 241 |
+
future_length: Desired future length (if None, use default split)
|
| 242 |
+
|
| 243 |
+
Returns:
|
| 244 |
+
Tuple of (history_values, future_values, start, frequency)
|
| 245 |
+
"""
|
| 246 |
+
# Handle both old and new data formats
|
| 247 |
+
num_channels = sample.get("num_channels", 1)
|
| 248 |
+
values_data = sample["values"]
|
| 249 |
+
generator_type = sample.get("generator_type", "unknown")
|
| 250 |
+
|
| 251 |
+
if num_channels == 1:
|
| 252 |
+
# Univariate data
|
| 253 |
+
if isinstance(values_data[0], list):
|
| 254 |
+
# New format: [[channel_values]]
|
| 255 |
+
values = torch.tensor(values_data[0], dtype=torch.float32)
|
| 256 |
+
logger.debug(
|
| 257 |
+
f"{generator_type}: Using new univariate format, shape: {values.shape}"
|
| 258 |
+
)
|
| 259 |
+
else:
|
| 260 |
+
# Old format: [values]
|
| 261 |
+
values = torch.tensor(values_data, dtype=torch.float32)
|
| 262 |
+
values = values.unsqueeze(0).unsqueeze(-1) # Shape: [1, seq_len, 1]
|
| 263 |
+
else:
|
| 264 |
+
# Multivariate data (LMC) - new format: [[ch1_values], [ch2_values], ...]
|
| 265 |
+
channel_tensors = []
|
| 266 |
+
for channel_values in values_data:
|
| 267 |
+
channel_tensor = torch.tensor(channel_values, dtype=torch.float32)
|
| 268 |
+
channel_tensors.append(channel_tensor)
|
| 269 |
+
|
| 270 |
+
# Stack channels: [1, seq_len, num_channels]
|
| 271 |
+
values = torch.stack(channel_tensors, dim=-1).unsqueeze(0)
|
| 272 |
+
logger.debug(
|
| 273 |
+
f"{generator_type}: Using multivariate format, {num_channels} channels, shape: {values.shape}"
|
| 274 |
+
)
|
| 275 |
+
|
| 276 |
+
# Handle frequency conversion
|
| 277 |
+
freq_str = sample["frequency"]
|
| 278 |
+
try:
|
| 279 |
+
frequency = Frequency(freq_str)
|
| 280 |
+
except ValueError:
|
| 281 |
+
# Map common frequency strings to Frequency enum
|
| 282 |
+
freq_mapping = {
|
| 283 |
+
"h": Frequency.H,
|
| 284 |
+
"D": Frequency.D,
|
| 285 |
+
"W": Frequency.W,
|
| 286 |
+
"M": Frequency.M,
|
| 287 |
+
"Q": Frequency.Q,
|
| 288 |
+
"A": Frequency.A,
|
| 289 |
+
"Y": Frequency.A, # Annual
|
| 290 |
+
"1min": Frequency.T1,
|
| 291 |
+
"5min": Frequency.T5,
|
| 292 |
+
"10min": Frequency.T10,
|
| 293 |
+
"15min": Frequency.T15,
|
| 294 |
+
"30min": Frequency.T30,
|
| 295 |
+
"s": Frequency.S,
|
| 296 |
+
}
|
| 297 |
+
frequency = freq_mapping.get(freq_str, Frequency.H) # Default to hourly
|
| 298 |
+
|
| 299 |
+
# Handle start timestamp
|
| 300 |
+
if isinstance(sample["start"], pd.Timestamp):
|
| 301 |
+
start = sample["start"].to_numpy()
|
| 302 |
+
else:
|
| 303 |
+
start = np.datetime64(sample["start"])
|
| 304 |
+
|
| 305 |
+
return values, start, frequency
|
| 306 |
+
|
| 307 |
+
def _effective_proportions_for_length(
|
| 308 |
+
self, total_length_for_batch: int
|
| 309 |
+
) -> Dict[str, float]:
|
| 310 |
+
"""
|
| 311 |
+
Build a simple, length-aware proportion map for the current batch.
|
| 312 |
+
|
| 313 |
+
Rules:
|
| 314 |
+
- For generators named 'augmented{L}', keep only the one matching the
|
| 315 |
+
chosen length L; zero out others.
|
| 316 |
+
- Keep non-augmented generators as-is.
|
| 317 |
+
- Drop generators that are unavailable (not loaded) or zero-weight.
|
| 318 |
+
- If nothing remains, fall back to 'augmented{L}' if available, else any dataset.
|
| 319 |
+
- Normalize the final map to sum to 1.
|
| 320 |
+
"""
|
| 321 |
+
|
| 322 |
+
def augmented_length_from_name(name: str) -> Optional[int]:
|
| 323 |
+
if not name.startswith("augmented"):
|
| 324 |
+
return None
|
| 325 |
+
suffix = name[len("augmented") :]
|
| 326 |
+
if not suffix:
|
| 327 |
+
return None
|
| 328 |
+
try:
|
| 329 |
+
return int(suffix)
|
| 330 |
+
except ValueError:
|
| 331 |
+
return None
|
| 332 |
+
|
| 333 |
+
# 1) Adjust proportions with the length-aware rule
|
| 334 |
+
adjusted: Dict[str, float] = {}
|
| 335 |
+
for name, proportion in self.generator_proportions.items():
|
| 336 |
+
aug_len = augmented_length_from_name(name)
|
| 337 |
+
if aug_len is None:
|
| 338 |
+
adjusted[name] = proportion
|
| 339 |
+
else:
|
| 340 |
+
adjusted[name] = (
|
| 341 |
+
proportion if aug_len == total_length_for_batch else 0.0
|
| 342 |
+
)
|
| 343 |
+
|
| 344 |
+
# 2) Keep only available, positive-weight datasets
|
| 345 |
+
adjusted = {
|
| 346 |
+
name: p for name, p in adjusted.items() if name in self.datasets and p > 0.0
|
| 347 |
+
}
|
| 348 |
+
|
| 349 |
+
# 3) Fallback if empty
|
| 350 |
+
if not adjusted:
|
| 351 |
+
preferred = f"augmented{total_length_for_batch}"
|
| 352 |
+
if preferred in self.datasets:
|
| 353 |
+
adjusted = {preferred: 1.0}
|
| 354 |
+
elif self.datasets:
|
| 355 |
+
# Choose any available dataset deterministically (first key)
|
| 356 |
+
first_key = next(iter(self.datasets.keys()))
|
| 357 |
+
adjusted = {first_key: 1.0}
|
| 358 |
+
else:
|
| 359 |
+
raise ValueError("No datasets available to create batch")
|
| 360 |
+
|
| 361 |
+
# 4) Normalize
|
| 362 |
+
total = sum(adjusted.values())
|
| 363 |
+
return {name: p / total for name, p in adjusted.items()}
|
| 364 |
+
|
| 365 |
+
def _compute_sample_counts_for_batch(
|
| 366 |
+
self, proportions: Dict[str, float], batch_size: int
|
| 367 |
+
) -> Dict[str, int]:
|
| 368 |
+
"""
|
| 369 |
+
Convert a proportion map into integer sample counts that sum to batch_size.
|
| 370 |
+
|
| 371 |
+
Strategy: allocate floor(batch_size * p) to each generator in order, and let the
|
| 372 |
+
last generator absorb any remainder to ensure the total matches exactly.
|
| 373 |
+
"""
|
| 374 |
+
counts: Dict[str, int] = {}
|
| 375 |
+
remaining = batch_size
|
| 376 |
+
names = list(proportions.keys())
|
| 377 |
+
values = list(proportions.values())
|
| 378 |
+
for index, (name, p) in enumerate(zip(names, values)):
|
| 379 |
+
if index == len(names) - 1:
|
| 380 |
+
counts[name] = remaining
|
| 381 |
+
else:
|
| 382 |
+
n = int(batch_size * p)
|
| 383 |
+
counts[name] = n
|
| 384 |
+
remaining -= n
|
| 385 |
+
return counts
|
| 386 |
+
|
| 387 |
+
def _calculate_generator_samples(self, batch_size: int) -> Dict[str, int]:
|
| 388 |
+
"""
|
| 389 |
+
Calculate the number of samples each generator should contribute.
|
| 390 |
+
|
| 391 |
+
Args:
|
| 392 |
+
batch_size: Total batch size
|
| 393 |
+
|
| 394 |
+
Returns:
|
| 395 |
+
Dict mapping generator names to sample counts
|
| 396 |
+
"""
|
| 397 |
+
generator_samples = {}
|
| 398 |
+
remaining_samples = batch_size
|
| 399 |
+
|
| 400 |
+
generators = list(self.generator_proportions.keys())
|
| 401 |
+
proportions = list(self.generator_proportions.values())
|
| 402 |
+
|
| 403 |
+
# Calculate base samples for each generator
|
| 404 |
+
for i, (generator, proportion) in enumerate(zip(generators, proportions)):
|
| 405 |
+
if generator not in self.datasets:
|
| 406 |
+
continue
|
| 407 |
+
|
| 408 |
+
if i == len(generators) - 1: # Last generator gets remaining samples
|
| 409 |
+
samples = remaining_samples
|
| 410 |
+
else:
|
| 411 |
+
samples = int(batch_size * proportion)
|
| 412 |
+
remaining_samples -= samples
|
| 413 |
+
generator_samples[generator] = samples
|
| 414 |
+
|
| 415 |
+
return generator_samples
|
| 416 |
+
|
| 417 |
+
def create_batch(
|
| 418 |
+
self,
|
| 419 |
+
batch_size: int = 128,
|
| 420 |
+
seed: Optional[int] = None,
|
| 421 |
+
future_length: Optional[int] = None,
|
| 422 |
+
) -> Tuple[BatchTimeSeriesContainer, str]:
|
| 423 |
+
"""
|
| 424 |
+
Create a batch of the specified size.
|
| 425 |
+
|
| 426 |
+
Args:
|
| 427 |
+
batch_size: Size of the batch to create
|
| 428 |
+
seed: Random seed for this batch
|
| 429 |
+
future_length: Fixed future length to use. If None, samples from gift_eval range
|
| 430 |
+
|
| 431 |
+
Returns:
|
| 432 |
+
Tuple of (batch_container, generator_info)
|
| 433 |
+
"""
|
| 434 |
+
if seed is not None:
|
| 435 |
+
batch_rng = np.random.default_rng(seed)
|
| 436 |
+
random.seed(seed)
|
| 437 |
+
else:
|
| 438 |
+
batch_rng = self.rng
|
| 439 |
+
|
| 440 |
+
if self.mixed_batches:
|
| 441 |
+
return self._create_mixed_batch(batch_size, future_length)
|
| 442 |
+
else:
|
| 443 |
+
return self._create_uniform_batch(batch_size, batch_rng, future_length)
|
| 444 |
+
|
| 445 |
+
def _create_mixed_batch(
|
| 446 |
+
self, batch_size: int, future_length: Optional[int] = None
|
| 447 |
+
) -> Tuple[BatchTimeSeriesContainer, str]:
|
| 448 |
+
"""Create a mixed batch with samples from multiple generators, rejecting NaNs."""
|
| 449 |
+
|
| 450 |
+
# Choose total length for this batch; respect length_shortening flag.
|
| 451 |
+
# When disabled, always use the maximum to avoid shortening.
|
| 452 |
+
if self.augmentations.get("length_shortening", False):
|
| 453 |
+
lengths = list(LENGTH_WEIGHTS.keys())
|
| 454 |
+
probs = list(LENGTH_WEIGHTS.values())
|
| 455 |
+
total_length_for_batch = int(self.rng.choice(lengths, p=probs))
|
| 456 |
+
else:
|
| 457 |
+
total_length_for_batch = int(max(LENGTH_CHOICES))
|
| 458 |
+
|
| 459 |
+
if future_length is None:
|
| 460 |
+
prediction_length = int(
|
| 461 |
+
sample_future_length(
|
| 462 |
+
range="gift_eval", total_length=total_length_for_batch
|
| 463 |
+
)
|
| 464 |
+
)
|
| 465 |
+
else:
|
| 466 |
+
prediction_length = future_length
|
| 467 |
+
|
| 468 |
+
history_length = total_length_for_batch - prediction_length
|
| 469 |
+
|
| 470 |
+
# Calculate samples per generator using simple, per-batch length-aware proportions
|
| 471 |
+
effective_props = self._effective_proportions_for_length(total_length_for_batch)
|
| 472 |
+
generator_samples = self._compute_sample_counts_for_batch(
|
| 473 |
+
effective_props, batch_size
|
| 474 |
+
)
|
| 475 |
+
|
| 476 |
+
all_values = []
|
| 477 |
+
all_starts = []
|
| 478 |
+
all_frequencies = []
|
| 479 |
+
actual_proportions = {}
|
| 480 |
+
|
| 481 |
+
# Collect valid samples from each generator using batched fetches to reduce I/O overhead
|
| 482 |
+
for generator_name, num_samples in generator_samples.items():
|
| 483 |
+
if num_samples == 0 or generator_name not in self.datasets:
|
| 484 |
+
continue
|
| 485 |
+
|
| 486 |
+
dataset = self.datasets[generator_name]
|
| 487 |
+
|
| 488 |
+
# Lists to hold valid samples for the current generator
|
| 489 |
+
generator_values = []
|
| 490 |
+
generator_starts = []
|
| 491 |
+
generator_frequencies = []
|
| 492 |
+
|
| 493 |
+
# Loop until we have collected the required number of VALID samples
|
| 494 |
+
max_attempts = 50
|
| 495 |
+
attempts = 0
|
| 496 |
+
while len(generator_values) < num_samples and attempts < max_attempts:
|
| 497 |
+
attempts += 1
|
| 498 |
+
# Fetch a batch larger than needed to reduce round-trips
|
| 499 |
+
need = num_samples - len(generator_values)
|
| 500 |
+
fetch_n = max(need * 2, 8)
|
| 501 |
+
samples = dataset.get_samples(fetch_n)
|
| 502 |
+
|
| 503 |
+
for sample in samples:
|
| 504 |
+
if len(generator_values) >= num_samples:
|
| 505 |
+
break
|
| 506 |
+
|
| 507 |
+
values, sample_start, sample_freq = self._convert_sample_to_tensors(
|
| 508 |
+
sample, future_length
|
| 509 |
+
)
|
| 510 |
+
|
| 511 |
+
# Skip if NaNs exist (we inject NaNs later in history only)
|
| 512 |
+
if torch.isnan(values).any():
|
| 513 |
+
continue
|
| 514 |
+
|
| 515 |
+
# Resize to target batch length when longer
|
| 516 |
+
if total_length_for_batch < values.shape[1]:
|
| 517 |
+
strategy = self.rng.choice(["cut", "subsample"]) # 50/50
|
| 518 |
+
if strategy == "cut":
|
| 519 |
+
max_start_idx = values.shape[1] - total_length_for_batch
|
| 520 |
+
start_idx = int(self.rng.integers(0, max_start_idx + 1))
|
| 521 |
+
values = values[
|
| 522 |
+
:, start_idx : start_idx + total_length_for_batch, :
|
| 523 |
+
]
|
| 524 |
+
else:
|
| 525 |
+
indices = np.linspace(
|
| 526 |
+
0,
|
| 527 |
+
values.shape[1] - 1,
|
| 528 |
+
total_length_for_batch,
|
| 529 |
+
dtype=int,
|
| 530 |
+
)
|
| 531 |
+
values = values[:, indices, :]
|
| 532 |
+
|
| 533 |
+
# Optionally apply scaler augmentation according to configuration
|
| 534 |
+
if self._should_apply_scaler_augmentation():
|
| 535 |
+
scaler = self._choose_random_scaler()
|
| 536 |
+
if scaler is not None:
|
| 537 |
+
values = scaler.scale(
|
| 538 |
+
values, scaler.compute_statistics(values)
|
| 539 |
+
)
|
| 540 |
+
|
| 541 |
+
generator_values.append(values)
|
| 542 |
+
generator_starts.append(sample_start)
|
| 543 |
+
generator_frequencies.append(sample_freq)
|
| 544 |
+
|
| 545 |
+
if len(generator_values) < num_samples:
|
| 546 |
+
logger.warning(
|
| 547 |
+
f"Generator {generator_name}: collected {len(generator_values)}/{num_samples} after {attempts} attempts"
|
| 548 |
+
)
|
| 549 |
+
|
| 550 |
+
# Add the collected valid samples to the main batch lists
|
| 551 |
+
if generator_values:
|
| 552 |
+
all_values.extend(generator_values)
|
| 553 |
+
all_starts.extend(generator_starts)
|
| 554 |
+
all_frequencies.extend(generator_frequencies)
|
| 555 |
+
actual_proportions[generator_name] = len(generator_values)
|
| 556 |
+
|
| 557 |
+
if not all_values:
|
| 558 |
+
raise RuntimeError(
|
| 559 |
+
"No valid samples could be collected from any generator."
|
| 560 |
+
)
|
| 561 |
+
|
| 562 |
+
combined_values = torch.cat(all_values, dim=0)
|
| 563 |
+
# Split into history and future
|
| 564 |
+
combined_history = combined_values[:, :history_length, :]
|
| 565 |
+
combined_future = combined_values[
|
| 566 |
+
:, history_length : history_length + prediction_length, :
|
| 567 |
+
]
|
| 568 |
+
|
| 569 |
+
if self.nan_augmenter is not None:
|
| 570 |
+
combined_history = self.nan_augmenter.transform(combined_history)
|
| 571 |
+
|
| 572 |
+
# Create container
|
| 573 |
+
container = BatchTimeSeriesContainer(
|
| 574 |
+
history_values=combined_history,
|
| 575 |
+
future_values=combined_future,
|
| 576 |
+
start=all_starts,
|
| 577 |
+
frequency=all_frequencies,
|
| 578 |
+
)
|
| 579 |
+
|
| 580 |
+
return container, "MixedBatch"
|
| 581 |
+
|
| 582 |
+
def _create_uniform_batch(
|
| 583 |
+
self,
|
| 584 |
+
batch_size: int,
|
| 585 |
+
batch_rng: np.random.Generator,
|
| 586 |
+
future_length: Optional[int] = None,
|
| 587 |
+
) -> Tuple[BatchTimeSeriesContainer, str]:
|
| 588 |
+
"""Create a uniform batch with samples from a single generator."""
|
| 589 |
+
|
| 590 |
+
# Select generator based on proportions
|
| 591 |
+
generators = list(self.datasets.keys())
|
| 592 |
+
proportions = [self.generator_proportions[gen] for gen in generators]
|
| 593 |
+
selected_generator = batch_rng.choice(generators, p=proportions)
|
| 594 |
+
|
| 595 |
+
# Sample future length
|
| 596 |
+
if future_length is None:
|
| 597 |
+
future_length = sample_future_length(range="gift_eval")
|
| 598 |
+
|
| 599 |
+
# Get samples from selected generator
|
| 600 |
+
dataset = self.datasets[selected_generator]
|
| 601 |
+
samples = dataset.get_samples(batch_size)
|
| 602 |
+
|
| 603 |
+
all_history_values = []
|
| 604 |
+
all_future_values = []
|
| 605 |
+
all_starts = []
|
| 606 |
+
all_frequencies = []
|
| 607 |
+
|
| 608 |
+
for sample in samples:
|
| 609 |
+
values, sample_start, sample_freq = self._convert_sample_to_tensors(
|
| 610 |
+
sample, future_length
|
| 611 |
+
)
|
| 612 |
+
|
| 613 |
+
total_length = values.shape[1]
|
| 614 |
+
history_length = max(1, total_length - future_length)
|
| 615 |
+
|
| 616 |
+
# Optionally apply scaler augmentation according to configuration
|
| 617 |
+
if self._should_apply_scaler_augmentation():
|
| 618 |
+
scaler = self._choose_random_scaler()
|
| 619 |
+
if scaler is not None:
|
| 620 |
+
values = scaler.scale(values, scaler.compute_statistics(values))
|
| 621 |
+
|
| 622 |
+
# Reshape to [1, seq_len, 1] for single sample
|
| 623 |
+
hist_vals = values[:, :history_length, :]
|
| 624 |
+
fut_vals = values[:, history_length : history_length + future_length, :]
|
| 625 |
+
|
| 626 |
+
all_history_values.append(hist_vals)
|
| 627 |
+
all_future_values.append(fut_vals)
|
| 628 |
+
all_starts.append(sample_start)
|
| 629 |
+
all_frequencies.append(sample_freq)
|
| 630 |
+
|
| 631 |
+
# Combine samples
|
| 632 |
+
combined_history = torch.cat(all_history_values, dim=0)
|
| 633 |
+
combined_future = torch.cat(all_future_values, dim=0)
|
| 634 |
+
|
| 635 |
+
# Create container
|
| 636 |
+
container = BatchTimeSeriesContainer(
|
| 637 |
+
history_values=combined_history,
|
| 638 |
+
future_values=combined_future,
|
| 639 |
+
start=all_starts,
|
| 640 |
+
frequency=all_frequencies,
|
| 641 |
+
)
|
| 642 |
+
|
| 643 |
+
return container, selected_generator
|
| 644 |
+
|
| 645 |
+
def get_dataset_info(self) -> Dict[str, dict]:
|
| 646 |
+
"""Get information about all datasets."""
|
| 647 |
+
info = {}
|
| 648 |
+
for name, dataset in self.datasets.items():
|
| 649 |
+
info[name] = dataset.get_info()
|
| 650 |
+
return info
|
| 651 |
+
|
| 652 |
+
def get_generator_info(self) -> Dict[str, any]:
|
| 653 |
+
"""Get information about the composer configuration."""
|
| 654 |
+
return {
|
| 655 |
+
"mixed_batches": self.mixed_batches,
|
| 656 |
+
"generator_proportions": self.generator_proportions,
|
| 657 |
+
"active_generators": list(self.datasets.keys()),
|
| 658 |
+
"total_generators": len(self.datasets),
|
| 659 |
+
"augmentations": self.augmentations,
|
| 660 |
+
"augmentation_probabilities": self.augmentation_probabilities,
|
| 661 |
+
"nan_augmenter_enabled": self.nan_augmenter is not None,
|
| 662 |
+
}
|
| 663 |
+
|
| 664 |
+
|
| 665 |
+
class ComposedDataset(torch.utils.data.Dataset):
|
| 666 |
+
"""
|
| 667 |
+
PyTorch Dataset wrapper around BatchComposer for training pipeline integration.
|
| 668 |
+
"""
|
| 669 |
+
|
| 670 |
+
def __init__(
|
| 671 |
+
self,
|
| 672 |
+
batch_composer: BatchComposer,
|
| 673 |
+
num_batches_per_epoch: int = 100,
|
| 674 |
+
batch_size: int = 128,
|
| 675 |
+
):
|
| 676 |
+
"""
|
| 677 |
+
Initialize the dataset.
|
| 678 |
+
|
| 679 |
+
Args:
|
| 680 |
+
batch_composer: The BatchComposer instance
|
| 681 |
+
num_batches_per_epoch: Number of batches to generate per epoch
|
| 682 |
+
batch_size: Size of each batch
|
| 683 |
+
"""
|
| 684 |
+
self.batch_composer = batch_composer
|
| 685 |
+
self.num_batches_per_epoch = num_batches_per_epoch
|
| 686 |
+
self.batch_size = batch_size
|
| 687 |
+
|
| 688 |
+
def __len__(self) -> int:
|
| 689 |
+
return self.num_batches_per_epoch
|
| 690 |
+
|
| 691 |
+
def __getitem__(self, idx: int) -> BatchTimeSeriesContainer:
|
| 692 |
+
"""
|
| 693 |
+
Get a batch by index.
|
| 694 |
+
|
| 695 |
+
Args:
|
| 696 |
+
idx: Batch index (used as seed for reproducibility)
|
| 697 |
+
|
| 698 |
+
Returns:
|
| 699 |
+
BatchTimeSeriesContainer
|
| 700 |
+
"""
|
| 701 |
+
# Use index as seed for reproducible batches
|
| 702 |
+
batch, _ = self.batch_composer.create_batch(
|
| 703 |
+
batch_size=self.batch_size, seed=self.batch_composer.global_seed + idx
|
| 704 |
+
)
|
| 705 |
+
return batch
|
src/data/constants.py
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from datetime import date
|
| 2 |
+
from typing import Dict
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
|
| 6 |
+
DEFAULT_START_DATE = date(1700, 1, 1)
|
| 7 |
+
DEFAULT_END_DATE = date(2200, 1, 1)
|
| 8 |
+
BASE_START_DATE = np.datetime64(DEFAULT_START_DATE)
|
| 9 |
+
BASE_END_DATE = np.datetime64(DEFAULT_END_DATE)
|
| 10 |
+
|
| 11 |
+
# Maximum years to prevent timestamp overflow
|
| 12 |
+
MAX_YEARS = 500
|
| 13 |
+
|
| 14 |
+
LENGTH_CHOICES = [128, 256, 512, 1024, 1536, 2048]
|
| 15 |
+
|
| 16 |
+
DEFAULT_NAN_STATS_PATH: str = "./data/nan_stats.json"
|
| 17 |
+
|
| 18 |
+
LENGTH_WEIGHTS: Dict[int, float] = {
|
| 19 |
+
128: 0.05,
|
| 20 |
+
256: 0.10,
|
| 21 |
+
512: 0.10,
|
| 22 |
+
1024: 0.10,
|
| 23 |
+
1536: 0.15,
|
| 24 |
+
2048: 0.50,
|
| 25 |
+
}
|
src/data/containers.py
ADDED
|
@@ -0,0 +1,272 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dataclasses import dataclass
|
| 2 |
+
from typing import List, Optional
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
|
| 7 |
+
from src.data.frequency import Frequency
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
@dataclass
|
| 11 |
+
class BatchTimeSeriesContainer:
|
| 12 |
+
"""
|
| 13 |
+
Container for a batch of multivariate time series data and their associated features.
|
| 14 |
+
|
| 15 |
+
Attributes:
|
| 16 |
+
history_values: Tensor of historical observations.
|
| 17 |
+
Shape: [batch_size, seq_len, num_channels]
|
| 18 |
+
future_values: Tensor of future observations to predict.
|
| 19 |
+
Shape: [batch_size, pred_len, num_channels]
|
| 20 |
+
start: Timestamp of the first history value.
|
| 21 |
+
Type: List[np.datetime64]
|
| 22 |
+
frequency: Frequency of the time series.
|
| 23 |
+
Type: List[Frequency]
|
| 24 |
+
history_mask: Optional boolean/float tensor indicating missing entries in history_values across channels.
|
| 25 |
+
Shape: [batch_size, seq_len]
|
| 26 |
+
future_mask: Optional boolean/float tensor indicating missing entries in future_values across channels.
|
| 27 |
+
Shape: [batch_size, pred_len]
|
| 28 |
+
"""
|
| 29 |
+
|
| 30 |
+
history_values: torch.Tensor
|
| 31 |
+
future_values: torch.Tensor
|
| 32 |
+
start: List[np.datetime64]
|
| 33 |
+
frequency: List[Frequency]
|
| 34 |
+
|
| 35 |
+
history_mask: Optional[torch.Tensor] = None
|
| 36 |
+
future_mask: Optional[torch.Tensor] = None
|
| 37 |
+
|
| 38 |
+
def __post_init__(self):
|
| 39 |
+
"""Validate all tensor shapes and consistency."""
|
| 40 |
+
# --- Tensor Type Checks ---
|
| 41 |
+
if not isinstance(self.history_values, torch.Tensor):
|
| 42 |
+
raise TypeError("history_values must be a torch.Tensor")
|
| 43 |
+
if not isinstance(self.future_values, torch.Tensor):
|
| 44 |
+
raise TypeError("future_values must be a torch.Tensor")
|
| 45 |
+
if not isinstance(self.start, list) or not all(
|
| 46 |
+
isinstance(x, np.datetime64) for x in self.start
|
| 47 |
+
):
|
| 48 |
+
raise TypeError("start must be a List[np.datetime64]")
|
| 49 |
+
if not isinstance(self.frequency, list) or not all(
|
| 50 |
+
isinstance(x, Frequency) for x in self.frequency
|
| 51 |
+
):
|
| 52 |
+
raise TypeError("frequency must be a List[Frequency]")
|
| 53 |
+
|
| 54 |
+
batch_size, seq_len, num_channels = self.history_values.shape
|
| 55 |
+
pred_len = self.future_values.shape[1]
|
| 56 |
+
|
| 57 |
+
# --- Core Shape Checks ---
|
| 58 |
+
if self.future_values.shape[0] != batch_size:
|
| 59 |
+
raise ValueError("Batch size mismatch between history and future_values")
|
| 60 |
+
if self.future_values.shape[2] != num_channels:
|
| 61 |
+
raise ValueError("Channel size mismatch between history and future_values")
|
| 62 |
+
|
| 63 |
+
# --- Optional Mask Checks ---
|
| 64 |
+
if self.history_mask is not None:
|
| 65 |
+
if not isinstance(self.history_mask, torch.Tensor):
|
| 66 |
+
raise TypeError("history_mask must be a Tensor or None")
|
| 67 |
+
if self.history_mask.shape[:2] != (batch_size, seq_len):
|
| 68 |
+
raise ValueError(
|
| 69 |
+
f"Shape mismatch in history_mask: {self.history_mask.shape[:2]} vs {(batch_size, seq_len)}"
|
| 70 |
+
)
|
| 71 |
+
|
| 72 |
+
if self.future_mask is not None:
|
| 73 |
+
if not isinstance(self.future_mask, torch.Tensor):
|
| 74 |
+
raise TypeError("future_mask must be a Tensor or None")
|
| 75 |
+
if not (
|
| 76 |
+
self.future_mask.shape == (batch_size, pred_len)
|
| 77 |
+
or self.future_mask.shape == self.future_values.shape
|
| 78 |
+
):
|
| 79 |
+
raise ValueError(
|
| 80 |
+
f"Shape mismatch in future_mask: expected {(batch_size, pred_len)} or {self.future_values.shape}, got {self.future_mask.shape}"
|
| 81 |
+
)
|
| 82 |
+
|
| 83 |
+
def to_device(
|
| 84 |
+
self, device: torch.device, attributes: Optional[List[str]] = None
|
| 85 |
+
) -> None:
|
| 86 |
+
"""
|
| 87 |
+
Move specified tensors to the target device in place.
|
| 88 |
+
|
| 89 |
+
Args:
|
| 90 |
+
device: Target device (e.g., 'cpu', 'cuda').
|
| 91 |
+
attributes: Optional list of attribute names to move. If None, move all tensors.
|
| 92 |
+
|
| 93 |
+
Raises:
|
| 94 |
+
ValueError: If an invalid attribute is specified or device transfer fails.
|
| 95 |
+
"""
|
| 96 |
+
all_tensors = {
|
| 97 |
+
"history_values": self.history_values,
|
| 98 |
+
"future_values": self.future_values,
|
| 99 |
+
"history_mask": self.history_mask,
|
| 100 |
+
"future_mask": self.future_mask,
|
| 101 |
+
}
|
| 102 |
+
|
| 103 |
+
if attributes is None:
|
| 104 |
+
attributes = [k for k, v in all_tensors.items() if v is not None]
|
| 105 |
+
|
| 106 |
+
for attr in attributes:
|
| 107 |
+
if attr not in all_tensors:
|
| 108 |
+
raise ValueError(f"Invalid attribute: {attr}")
|
| 109 |
+
if all_tensors[attr] is not None:
|
| 110 |
+
setattr(self, attr, all_tensors[attr].to(device))
|
| 111 |
+
|
| 112 |
+
def to(self, device: torch.device, attributes: Optional[List[str]] = None):
|
| 113 |
+
"""
|
| 114 |
+
Alias for to_device method for consistency with PyTorch conventions.
|
| 115 |
+
|
| 116 |
+
Args:
|
| 117 |
+
device: Target device (e.g., 'cpu', 'cuda').
|
| 118 |
+
attributes: Optional list of attribute names to move. If None, move all tensors.
|
| 119 |
+
"""
|
| 120 |
+
self.to_device(device, attributes)
|
| 121 |
+
return self
|
| 122 |
+
|
| 123 |
+
@property
|
| 124 |
+
def batch_size(self) -> int:
|
| 125 |
+
return self.history_values.shape[0]
|
| 126 |
+
|
| 127 |
+
@property
|
| 128 |
+
def history_length(self) -> int:
|
| 129 |
+
return self.history_values.shape[1]
|
| 130 |
+
|
| 131 |
+
@property
|
| 132 |
+
def future_length(self) -> int:
|
| 133 |
+
return self.future_values.shape[1]
|
| 134 |
+
|
| 135 |
+
@property
|
| 136 |
+
def num_channels(self) -> int:
|
| 137 |
+
return self.history_values.shape[2]
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
@dataclass
|
| 141 |
+
class TimeSeriesContainer:
|
| 142 |
+
"""
|
| 143 |
+
Container for batch of time series data without explicit history/future split.
|
| 144 |
+
|
| 145 |
+
This container is used for storing generated synthetic time series data where
|
| 146 |
+
the entire series is treated as a single entity, typically for further processing
|
| 147 |
+
or splitting into history/future components later.
|
| 148 |
+
|
| 149 |
+
Attributes:
|
| 150 |
+
values: np.ndarray of time series values.
|
| 151 |
+
Shape: [batch_size, seq_len, num_channels] for multivariate series
|
| 152 |
+
[batch_size, seq_len] for univariate series
|
| 153 |
+
start: List of start timestamps for each series in the batch.
|
| 154 |
+
Type: List[np.datetime64], length should match batch_size
|
| 155 |
+
frequency: List of frequency for each series in the batch.
|
| 156 |
+
Type: List[Frequency], length should match batch_size
|
| 157 |
+
"""
|
| 158 |
+
|
| 159 |
+
values: np.ndarray
|
| 160 |
+
start: List[np.datetime64]
|
| 161 |
+
frequency: List[Frequency]
|
| 162 |
+
|
| 163 |
+
def __post_init__(self):
|
| 164 |
+
"""Validate all shapes and consistency."""
|
| 165 |
+
# --- Numpy Type Checks ---
|
| 166 |
+
if not isinstance(self.values, np.ndarray):
|
| 167 |
+
raise TypeError("values must be a np.ndarray")
|
| 168 |
+
if not isinstance(self.start, list) or not all(
|
| 169 |
+
isinstance(x, np.datetime64) for x in self.start
|
| 170 |
+
):
|
| 171 |
+
raise TypeError("start must be a List[np.datetime64]")
|
| 172 |
+
if not isinstance(self.frequency, list) or not all(
|
| 173 |
+
isinstance(x, Frequency) for x in self.frequency
|
| 174 |
+
):
|
| 175 |
+
raise TypeError("frequency must be a List[Frequency]")
|
| 176 |
+
|
| 177 |
+
# --- Shape and Length Consistency Checks ---
|
| 178 |
+
if len(self.values.shape) < 2 or len(self.values.shape) > 3:
|
| 179 |
+
raise ValueError(
|
| 180 |
+
f"values must have 2 or 3 dimensions [batch_size, seq_len] or [batch_size, seq_len, num_channels], got shape {self.values.shape}"
|
| 181 |
+
)
|
| 182 |
+
|
| 183 |
+
batch_size = self.values.shape[0]
|
| 184 |
+
|
| 185 |
+
if len(self.start) != batch_size:
|
| 186 |
+
raise ValueError(
|
| 187 |
+
f"Length of start ({len(self.start)}) must match batch_size ({batch_size})"
|
| 188 |
+
)
|
| 189 |
+
if len(self.frequency) != batch_size:
|
| 190 |
+
raise ValueError(
|
| 191 |
+
f"Length of frequency ({len(self.frequency)}) must match batch_size ({batch_size})"
|
| 192 |
+
)
|
| 193 |
+
|
| 194 |
+
@property
|
| 195 |
+
def batch_size(self) -> int:
|
| 196 |
+
return self.values.shape[0]
|
| 197 |
+
|
| 198 |
+
@property
|
| 199 |
+
def seq_length(self) -> int:
|
| 200 |
+
return self.values.shape[1]
|
| 201 |
+
|
| 202 |
+
@property
|
| 203 |
+
def num_channels(self) -> int:
|
| 204 |
+
return self.values.shape[2] if len(self.values.shape) == 3 else 1
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
@dataclass
|
| 209 |
+
class TimeSeriesContainer:
|
| 210 |
+
"""
|
| 211 |
+
Container for batch of time series data without explicit history/future split.
|
| 212 |
+
|
| 213 |
+
This container is used for storing generated synthetic time series data where
|
| 214 |
+
the entire series is treated as a single entity, typically for further processing
|
| 215 |
+
or splitting into history/future components later.
|
| 216 |
+
|
| 217 |
+
Attributes:
|
| 218 |
+
values: np.ndarray of time series values.
|
| 219 |
+
Shape: [batch_size, seq_len, num_channels] for multivariate series
|
| 220 |
+
[batch_size, seq_len] for univariate series
|
| 221 |
+
start: List of start timestamps for each series in the batch.
|
| 222 |
+
Type: List[np.datetime64], length should match batch_size
|
| 223 |
+
frequency: List of frequency for each series in the batch.
|
| 224 |
+
Type: List[Frequency], length should match batch_size
|
| 225 |
+
"""
|
| 226 |
+
|
| 227 |
+
values: np.ndarray
|
| 228 |
+
start: List[np.datetime64]
|
| 229 |
+
frequency: List[Frequency]
|
| 230 |
+
|
| 231 |
+
def __post_init__(self):
|
| 232 |
+
"""Validate all shapes and consistency."""
|
| 233 |
+
# --- Numpy Type Checks ---
|
| 234 |
+
if not isinstance(self.values, np.ndarray):
|
| 235 |
+
raise TypeError("values must be a np.ndarray")
|
| 236 |
+
if not isinstance(self.start, list) or not all(
|
| 237 |
+
isinstance(x, np.datetime64) for x in self.start
|
| 238 |
+
):
|
| 239 |
+
raise TypeError("start must be a List[np.datetime64]")
|
| 240 |
+
if not isinstance(self.frequency, list) or not all(
|
| 241 |
+
isinstance(x, Frequency) for x in self.frequency
|
| 242 |
+
):
|
| 243 |
+
raise TypeError("frequency must be a List[Frequency]")
|
| 244 |
+
|
| 245 |
+
# --- Shape and Length Consistency Checks ---
|
| 246 |
+
if len(self.values.shape) < 2 or len(self.values.shape) > 3:
|
| 247 |
+
raise ValueError(
|
| 248 |
+
f"values must have 2 or 3 dimensions [batch_size, seq_len] or [batch_size, seq_len, num_channels], got shape {self.values.shape}"
|
| 249 |
+
)
|
| 250 |
+
|
| 251 |
+
batch_size = self.values.shape[0]
|
| 252 |
+
|
| 253 |
+
if len(self.start) != batch_size:
|
| 254 |
+
raise ValueError(
|
| 255 |
+
f"Length of start ({len(self.start)}) must match batch_size ({batch_size})"
|
| 256 |
+
)
|
| 257 |
+
if len(self.frequency) != batch_size:
|
| 258 |
+
raise ValueError(
|
| 259 |
+
f"Length of frequency ({len(self.frequency)}) must match batch_size ({batch_size})"
|
| 260 |
+
)
|
| 261 |
+
|
| 262 |
+
@property
|
| 263 |
+
def batch_size(self) -> int:
|
| 264 |
+
return self.values.shape[0]
|
| 265 |
+
|
| 266 |
+
@property
|
| 267 |
+
def seq_length(self) -> int:
|
| 268 |
+
return self.values.shape[1]
|
| 269 |
+
|
| 270 |
+
@property
|
| 271 |
+
def num_channels(self) -> int:
|
| 272 |
+
return self.values.shape[2] if len(self.values.shape) == 3 else 1
|
src/data/datasets.py
ADDED
|
@@ -0,0 +1,267 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import os
|
| 3 |
+
import random
|
| 4 |
+
from typing import List, Optional
|
| 5 |
+
|
| 6 |
+
import pyarrow.feather as feather
|
| 7 |
+
import torch
|
| 8 |
+
|
| 9 |
+
logger = logging.getLogger(__name__)
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class CyclicalBatchDataset:
|
| 13 |
+
"""
|
| 14 |
+
Dataset class that loads saved batches from continuous generation script.
|
| 15 |
+
Maintains a pointer and provides cyclical access to individual samples.
|
| 16 |
+
Includes enhanced logging to track data shard cycling during training.
|
| 17 |
+
Supports per-rank file sharding for large-scale distributed training.
|
| 18 |
+
"""
|
| 19 |
+
|
| 20 |
+
def __init__(
|
| 21 |
+
self,
|
| 22 |
+
batches_dir: str,
|
| 23 |
+
generator_type: str,
|
| 24 |
+
device: Optional[torch.device] = None,
|
| 25 |
+
prefetch_next: bool = True,
|
| 26 |
+
prefetch_threshold: int = 32,
|
| 27 |
+
rank: int = 0,
|
| 28 |
+
world_size: int = 1,
|
| 29 |
+
):
|
| 30 |
+
"""
|
| 31 |
+
Initialize the cyclical batch dataset.
|
| 32 |
+
|
| 33 |
+
Args:
|
| 34 |
+
batches_dir: Directory containing the batch arrow files
|
| 35 |
+
generator_type: Type of generator (for logging)
|
| 36 |
+
device: Device to load tensors to
|
| 37 |
+
prefetch_next: Whether to prefetch the next batch
|
| 38 |
+
prefetch_threshold: Number of remaining samples to trigger prefetching
|
| 39 |
+
rank: Rank of the current process (for file sharding)
|
| 40 |
+
world_size: Total number of processes (for file sharding)
|
| 41 |
+
"""
|
| 42 |
+
self.batches_dir = batches_dir
|
| 43 |
+
self.generator_type = generator_type
|
| 44 |
+
self.device = device
|
| 45 |
+
self.prefetch_next = prefetch_next
|
| 46 |
+
self.prefetch_threshold = prefetch_threshold
|
| 47 |
+
self.rank = rank
|
| 48 |
+
self.world_size = world_size
|
| 49 |
+
|
| 50 |
+
self.batch_files = self._find_batch_files()
|
| 51 |
+
if not self.batch_files:
|
| 52 |
+
raise ValueError(f"No batch files found in {batches_dir}")
|
| 53 |
+
|
| 54 |
+
# --- State tracking ---
|
| 55 |
+
self.current_batch_idx = 0
|
| 56 |
+
self.current_sample_idx = 0
|
| 57 |
+
self.current_batch_data = None
|
| 58 |
+
self.next_batch_data = None
|
| 59 |
+
self.prefetching_in_progress = False
|
| 60 |
+
|
| 61 |
+
# --- NEW: Logging and cycle tracking ---
|
| 62 |
+
self.visited_batch_indices = set()
|
| 63 |
+
self.full_cycles_completed = 0
|
| 64 |
+
|
| 65 |
+
# Load first batch and update tracking
|
| 66 |
+
self._load_current_batch()
|
| 67 |
+
self.visited_batch_indices.add(self.current_batch_idx)
|
| 68 |
+
|
| 69 |
+
logger.info(
|
| 70 |
+
f"Initialized '{self.generator_type}' dataset with {len(self.batch_files)} batches. "
|
| 71 |
+
f"Current batch file: '{os.path.basename(self.batch_files[self.current_batch_idx])}' "
|
| 72 |
+
f"has {len(self.current_batch_data)} samples."
|
| 73 |
+
)
|
| 74 |
+
|
| 75 |
+
def _find_batch_files(self) -> List[str]:
|
| 76 |
+
"""
|
| 77 |
+
Find and sort batch files with per-rank sharding for distributed training.
|
| 78 |
+
|
| 79 |
+
Each rank gets a disjoint subset of files to minimize I/O contention
|
| 80 |
+
when scaling to hundreds of GPUs.
|
| 81 |
+
"""
|
| 82 |
+
import glob
|
| 83 |
+
|
| 84 |
+
pattern = os.path.join(self.batches_dir, "batch_*.arrow")
|
| 85 |
+
all_files = sorted(glob.glob(pattern)) # Sort for deterministic sharding
|
| 86 |
+
|
| 87 |
+
if not all_files:
|
| 88 |
+
return []
|
| 89 |
+
|
| 90 |
+
# Shard files across ranks: each rank gets every world_size-th file
|
| 91 |
+
# Example with 4 ranks: rank0=[0,4,8,...], rank1=[1,5,9,...], etc.
|
| 92 |
+
rank_files = [
|
| 93 |
+
f for i, f in enumerate(all_files) if i % self.world_size == self.rank
|
| 94 |
+
]
|
| 95 |
+
|
| 96 |
+
# Shuffle only within this rank's shard for variety
|
| 97 |
+
random.shuffle(rank_files)
|
| 98 |
+
|
| 99 |
+
logger.info(
|
| 100 |
+
f"[Rank {self.rank}] '{self.generator_type}': Sharded {len(all_files)} files → "
|
| 101 |
+
f"{len(rank_files)} files for this rank ({len(rank_files) / len(all_files) * 100:.1f}%)"
|
| 102 |
+
)
|
| 103 |
+
|
| 104 |
+
return rank_files
|
| 105 |
+
|
| 106 |
+
def _load_batch_from_file(self, batch_file: str) -> List[dict]:
|
| 107 |
+
"""Load a batch from arrow file."""
|
| 108 |
+
try:
|
| 109 |
+
table = feather.read_table(batch_file)
|
| 110 |
+
has_num_channels = "num_channels" in table.column_names
|
| 111 |
+
batch_data = []
|
| 112 |
+
for i in range(len(table)):
|
| 113 |
+
row = {
|
| 114 |
+
"series_id": table["series_id"][i].as_py(),
|
| 115 |
+
"values": table["values"][i].as_py(),
|
| 116 |
+
"length": table["length"][i].as_py(),
|
| 117 |
+
"generator_type": table["generator_type"][i].as_py(),
|
| 118 |
+
"start": table["start"][i].as_py(),
|
| 119 |
+
"frequency": table["frequency"][i].as_py(),
|
| 120 |
+
"generation_timestamp": table["generation_timestamp"][i].as_py(),
|
| 121 |
+
}
|
| 122 |
+
if has_num_channels:
|
| 123 |
+
row["num_channels"] = table["num_channels"][i].as_py()
|
| 124 |
+
else:
|
| 125 |
+
row["num_channels"] = 1
|
| 126 |
+
batch_data.append(row)
|
| 127 |
+
return batch_data
|
| 128 |
+
except Exception as e:
|
| 129 |
+
logger.error(f"Error loading batch from {batch_file}: {e}")
|
| 130 |
+
raise
|
| 131 |
+
|
| 132 |
+
def _load_current_batch(self):
|
| 133 |
+
"""Load the current batch into memory."""
|
| 134 |
+
if hasattr(self, "current_batch_data") and self.current_batch_data is not None:
|
| 135 |
+
del self.current_batch_data
|
| 136 |
+
batch_file = self.batch_files[self.current_batch_idx]
|
| 137 |
+
self.current_batch_data = self._load_batch_from_file(batch_file)
|
| 138 |
+
self.current_sample_idx = 0
|
| 139 |
+
logger.debug(
|
| 140 |
+
f"Loaded batch {self.current_batch_idx} for {self.generator_type} "
|
| 141 |
+
f"with {len(self.current_batch_data)} samples"
|
| 142 |
+
)
|
| 143 |
+
|
| 144 |
+
def _trigger_smart_prefetch(self):
|
| 145 |
+
"""Trigger prefetching when batch is almost exhausted."""
|
| 146 |
+
if not self.prefetch_next or len(self.batch_files) <= 1:
|
| 147 |
+
return
|
| 148 |
+
remaining_samples = self.get_remaining_samples_in_current_batch()
|
| 149 |
+
should_prefetch = (
|
| 150 |
+
remaining_samples <= self.prefetch_threshold
|
| 151 |
+
and self.next_batch_data is None
|
| 152 |
+
and not self.prefetching_in_progress
|
| 153 |
+
)
|
| 154 |
+
if should_prefetch:
|
| 155 |
+
self._prefetch_next_batch()
|
| 156 |
+
|
| 157 |
+
def _prefetch_next_batch(self):
|
| 158 |
+
"""Prefetch the next batch."""
|
| 159 |
+
if self.prefetching_in_progress:
|
| 160 |
+
return
|
| 161 |
+
self.prefetching_in_progress = True
|
| 162 |
+
next_batch_idx = (self.current_batch_idx + 1) % len(self.batch_files)
|
| 163 |
+
next_batch_file = self.batch_files[next_batch_idx]
|
| 164 |
+
try:
|
| 165 |
+
self.next_batch_data = self._load_batch_from_file(next_batch_file)
|
| 166 |
+
logger.debug(
|
| 167 |
+
f"Prefetched next batch {next_batch_idx} for {self.generator_type}"
|
| 168 |
+
)
|
| 169 |
+
except Exception as e:
|
| 170 |
+
logger.warning(f"Failed to prefetch batch {next_batch_idx}: {e}")
|
| 171 |
+
self.next_batch_data = None
|
| 172 |
+
finally:
|
| 173 |
+
self.prefetching_in_progress = False
|
| 174 |
+
|
| 175 |
+
def _advance_to_next_batch(self):
|
| 176 |
+
"""Advance to the next batch and log the transition."""
|
| 177 |
+
if hasattr(self, "current_batch_data") and self.current_batch_data is not None:
|
| 178 |
+
del self.current_batch_data
|
| 179 |
+
|
| 180 |
+
previous_batch_idx = self.current_batch_idx
|
| 181 |
+
self.current_batch_idx = (self.current_batch_idx + 1) % len(self.batch_files)
|
| 182 |
+
|
| 183 |
+
if hasattr(self, "next_batch_data") and self.next_batch_data is not None:
|
| 184 |
+
self.current_batch_data = self.next_batch_data
|
| 185 |
+
self.next_batch_data = None
|
| 186 |
+
else:
|
| 187 |
+
self._load_current_batch()
|
| 188 |
+
|
| 189 |
+
self.current_sample_idx = 0
|
| 190 |
+
self.prefetching_in_progress = False
|
| 191 |
+
|
| 192 |
+
# --- NEW: Enhanced Logging Logic ---
|
| 193 |
+
self.visited_batch_indices.add(self.current_batch_idx)
|
| 194 |
+
|
| 195 |
+
# Calculate progress
|
| 196 |
+
total_files = len(self.batch_files)
|
| 197 |
+
visited_count = len(self.visited_batch_indices)
|
| 198 |
+
progress_percent = (visited_count / total_files) * 100
|
| 199 |
+
|
| 200 |
+
# Log the shard cycle event
|
| 201 |
+
logger.info(
|
| 202 |
+
f"\nDATA SHARD CYCLED for '{self.generator_type}': "
|
| 203 |
+
f"Moved from file index {previous_batch_idx} to {self.current_batch_idx}. "
|
| 204 |
+
f"Unique files visited: {visited_count}/{total_files} ({progress_percent:.1f}%)."
|
| 205 |
+
)
|
| 206 |
+
|
| 207 |
+
# Check if a full cycle has been completed
|
| 208 |
+
if visited_count == total_files:
|
| 209 |
+
self.full_cycles_completed += 1
|
| 210 |
+
logger.info(
|
| 211 |
+
f"🎉 FULL CYCLE #{self.full_cycles_completed} COMPLETED for '{self.generator_type}'! "
|
| 212 |
+
f"All {total_files} data files have been visited at least once. "
|
| 213 |
+
"Resetting visited set to track the next cycle."
|
| 214 |
+
)
|
| 215 |
+
# Reset for the next cycle count
|
| 216 |
+
self.visited_batch_indices.clear()
|
| 217 |
+
self.visited_batch_indices.add(self.current_batch_idx)
|
| 218 |
+
|
| 219 |
+
def get_sample(self) -> dict:
|
| 220 |
+
"""Get the current sample and advance pointer."""
|
| 221 |
+
if not hasattr(self, "current_batch_data") or self.current_batch_data is None:
|
| 222 |
+
self._load_current_batch()
|
| 223 |
+
if self.current_batch_data is None:
|
| 224 |
+
raise RuntimeError("No batch data loaded")
|
| 225 |
+
if self.current_sample_idx >= len(self.current_batch_data):
|
| 226 |
+
self._advance_to_next_batch()
|
| 227 |
+
self._trigger_smart_prefetch()
|
| 228 |
+
sample = self.current_batch_data[self.current_sample_idx]
|
| 229 |
+
self.current_sample_idx += 1
|
| 230 |
+
return sample
|
| 231 |
+
|
| 232 |
+
def get_samples(self, num_samples: int) -> List[dict]:
|
| 233 |
+
"""Get multiple samples."""
|
| 234 |
+
samples = []
|
| 235 |
+
for _ in range(num_samples):
|
| 236 |
+
samples.append(self.get_sample())
|
| 237 |
+
return samples
|
| 238 |
+
|
| 239 |
+
def get_total_samples_in_current_batch(self) -> int:
|
| 240 |
+
"""Get total samples in current batch."""
|
| 241 |
+
if not hasattr(self, "current_batch_data") or self.current_batch_data is None:
|
| 242 |
+
return 0
|
| 243 |
+
return len(self.current_batch_data)
|
| 244 |
+
|
| 245 |
+
def get_remaining_samples_in_current_batch(self) -> int:
|
| 246 |
+
"""Get remaining samples in current batch."""
|
| 247 |
+
if not hasattr(self, "current_batch_data") or self.current_batch_data is None:
|
| 248 |
+
return 0
|
| 249 |
+
return max(0, len(self.current_batch_data) - self.current_sample_idx)
|
| 250 |
+
|
| 251 |
+
def get_info(self) -> dict:
|
| 252 |
+
"""Get extended dataset info, including cycle progress."""
|
| 253 |
+
total_files = len(self.batch_files)
|
| 254 |
+
visited_count = len(self.visited_batch_indices)
|
| 255 |
+
return {
|
| 256 |
+
"generator_type": self.generator_type,
|
| 257 |
+
"total_batch_files": total_files,
|
| 258 |
+
"current_batch_idx": self.current_batch_idx,
|
| 259 |
+
"current_sample_idx": self.current_sample_idx,
|
| 260 |
+
"current_batch_size": self.get_total_samples_in_current_batch(),
|
| 261 |
+
"remaining_in_batch": self.get_remaining_samples_in_current_batch(),
|
| 262 |
+
"unique_files_visited": visited_count,
|
| 263 |
+
"cycle_progress_percent": (visited_count / total_files) * 100
|
| 264 |
+
if total_files > 0
|
| 265 |
+
else 0,
|
| 266 |
+
"full_cycles_completed": self.full_cycles_completed,
|
| 267 |
+
}
|
src/data/filter.py
ADDED
|
@@ -0,0 +1,73 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import torch
|
| 3 |
+
from scipy import signal
|
| 4 |
+
from statsmodels.tsa.stattools import acf
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def lempel_ziv_complexity(binary_sequence: np.ndarray) -> int:
|
| 8 |
+
"""Computes the Lempel-Ziv complexity of a binary sequence."""
|
| 9 |
+
sub_strings = set()
|
| 10 |
+
n = len(binary_sequence)
|
| 11 |
+
i = 0
|
| 12 |
+
count = 0
|
| 13 |
+
while i < n:
|
| 14 |
+
sub_str = ""
|
| 15 |
+
for j in range(i, n):
|
| 16 |
+
sub_str += str(binary_sequence[j])
|
| 17 |
+
if sub_str not in sub_strings:
|
| 18 |
+
sub_strings.add(sub_str)
|
| 19 |
+
count += 1
|
| 20 |
+
i = j + 1
|
| 21 |
+
break
|
| 22 |
+
else:
|
| 23 |
+
i += 1
|
| 24 |
+
return count
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def is_low_quality(
|
| 28 |
+
series: torch.Tensor,
|
| 29 |
+
autocorr_threshold: float = 0.2,
|
| 30 |
+
snr_threshold: float = 0.5,
|
| 31 |
+
complexity_threshold: float = 0.4,
|
| 32 |
+
) -> bool:
|
| 33 |
+
"""
|
| 34 |
+
Returns True if the series appears non-forecastable (noise-like):
|
| 35 |
+
- weak autocorrelation
|
| 36 |
+
- low SNR proxy
|
| 37 |
+
- high normalized Lempel-Ziv complexity
|
| 38 |
+
"""
|
| 39 |
+
x = series.squeeze().detach().cpu().numpy()
|
| 40 |
+
if x.size < 20:
|
| 41 |
+
return True
|
| 42 |
+
if np.var(x) < 1e-10:
|
| 43 |
+
return True
|
| 44 |
+
|
| 45 |
+
x_detrended = signal.detrend(x)
|
| 46 |
+
|
| 47 |
+
try:
|
| 48 |
+
max_lags = min(len(x_detrended) // 4, 40)
|
| 49 |
+
if max_lags < 1:
|
| 50 |
+
autocorr_strength = 0.0
|
| 51 |
+
else:
|
| 52 |
+
acf_vals = acf(x_detrended, nlags=max_lags, fft=True)[1:]
|
| 53 |
+
autocorr_strength = float(np.max(np.abs(acf_vals)))
|
| 54 |
+
except Exception:
|
| 55 |
+
autocorr_strength = 0.0
|
| 56 |
+
|
| 57 |
+
win_size = max(3, min(len(x) // 10, 15))
|
| 58 |
+
signal_est = np.convolve(x, np.ones(win_size) / win_size, mode="valid")
|
| 59 |
+
noise_est = x[win_size - 1 :] - signal_est
|
| 60 |
+
var_signal = float(np.var(signal_est))
|
| 61 |
+
var_noise = float(np.var(noise_est))
|
| 62 |
+
snr_proxy = var_signal / var_noise if var_noise > 1e-8 else 1.0
|
| 63 |
+
|
| 64 |
+
median_val = float(np.median(x_detrended))
|
| 65 |
+
binary_seq = (x_detrended > median_val).astype(np.uint8)
|
| 66 |
+
complexity_score = lempel_ziv_complexity(binary_seq)
|
| 67 |
+
normalized_complexity = complexity_score / max(1, len(binary_seq))
|
| 68 |
+
|
| 69 |
+
is_random_like = (snr_proxy < snr_threshold) and (
|
| 70 |
+
normalized_complexity > complexity_threshold
|
| 71 |
+
)
|
| 72 |
+
is_uncorrelated = autocorr_strength < autocorr_threshold
|
| 73 |
+
return bool(is_uncorrelated and is_random_like)
|
src/data/frequency.py
ADDED
|
@@ -0,0 +1,538 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Comprehensive frequency management module for time series forecasting.
|
| 3 |
+
|
| 4 |
+
This module centralizes all frequency-related functionality including:
|
| 5 |
+
- Frequency enum with helper methods
|
| 6 |
+
- Frequency parsing and validation
|
| 7 |
+
- Pandas frequency string conversion
|
| 8 |
+
- Safety checks for date ranges
|
| 9 |
+
- Frequency selection utilities
|
| 10 |
+
- All frequency constants and mappings
|
| 11 |
+
"""
|
| 12 |
+
|
| 13 |
+
import logging
|
| 14 |
+
import re
|
| 15 |
+
from enum import Enum
|
| 16 |
+
from typing import Dict, Tuple
|
| 17 |
+
|
| 18 |
+
import numpy as np
|
| 19 |
+
import pandas as pd
|
| 20 |
+
from numpy.random import Generator
|
| 21 |
+
|
| 22 |
+
from src.data.constants import BASE_END_DATE, BASE_START_DATE, MAX_YEARS
|
| 23 |
+
|
| 24 |
+
logger = logging.getLogger(__name__)
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class Frequency(Enum):
|
| 28 |
+
"""
|
| 29 |
+
Enhanced Frequency enum with comprehensive helper methods.
|
| 30 |
+
|
| 31 |
+
Each frequency includes methods for pandas conversion, safety checks,
|
| 32 |
+
and other frequency-specific operations.
|
| 33 |
+
"""
|
| 34 |
+
|
| 35 |
+
A = "A" # Annual
|
| 36 |
+
Q = "Q" # Quarterly
|
| 37 |
+
M = "M" # Monthly
|
| 38 |
+
W = "W" # Weekly
|
| 39 |
+
D = "D" # Daily
|
| 40 |
+
H = "h" # Hourly
|
| 41 |
+
S = "s" # Seconds
|
| 42 |
+
T1 = "1min" # 1 minute
|
| 43 |
+
T5 = "5min" # 5 minutes
|
| 44 |
+
T10 = "10min" # 10 minutes
|
| 45 |
+
T15 = "15min" # 15 minutes
|
| 46 |
+
T30 = "30min" # 30 minutes
|
| 47 |
+
|
| 48 |
+
def to_pandas_freq(self, for_date_range: bool = True) -> str:
|
| 49 |
+
"""
|
| 50 |
+
Convert to pandas frequency string.
|
| 51 |
+
|
| 52 |
+
Args:
|
| 53 |
+
for_date_range: If True, use strings suitable for pd.date_range().
|
| 54 |
+
If False, use strings suitable for pd.PeriodIndex().
|
| 55 |
+
|
| 56 |
+
Returns:
|
| 57 |
+
Pandas frequency string
|
| 58 |
+
"""
|
| 59 |
+
base, prefix, _ = FREQUENCY_MAPPING[self]
|
| 60 |
+
|
| 61 |
+
# Special handling for date_range vs period compatibility
|
| 62 |
+
if for_date_range:
|
| 63 |
+
# For date_range, use modern pandas frequency strings
|
| 64 |
+
if self == Frequency.M:
|
| 65 |
+
return "ME" # Month End
|
| 66 |
+
elif self == Frequency.A:
|
| 67 |
+
return "YE" # Year End
|
| 68 |
+
elif self == Frequency.Q:
|
| 69 |
+
return "QE" # Quarter End
|
| 70 |
+
else:
|
| 71 |
+
# For periods, use legacy frequency strings
|
| 72 |
+
if self == Frequency.M:
|
| 73 |
+
return "M" # Month for periods
|
| 74 |
+
elif self == Frequency.A:
|
| 75 |
+
return "Y" # Year for periods (not YE)
|
| 76 |
+
elif self == Frequency.Q:
|
| 77 |
+
return "Q" # Quarter for periods (not QE)
|
| 78 |
+
|
| 79 |
+
# Construct frequency string for other frequencies
|
| 80 |
+
if prefix:
|
| 81 |
+
return f"{prefix}{base}"
|
| 82 |
+
else:
|
| 83 |
+
return base
|
| 84 |
+
|
| 85 |
+
def to_pandas_offset(self) -> str:
|
| 86 |
+
"""Get pandas offset string for time delta calculations."""
|
| 87 |
+
return FREQUENCY_TO_OFFSET[self]
|
| 88 |
+
|
| 89 |
+
def get_days_per_period(self) -> float:
|
| 90 |
+
"""Get approximate days per period for this frequency."""
|
| 91 |
+
_, _, days = FREQUENCY_MAPPING[self]
|
| 92 |
+
return days
|
| 93 |
+
|
| 94 |
+
def get_max_safe_length(self) -> int:
|
| 95 |
+
"""Get maximum safe sequence length to prevent timestamp overflow."""
|
| 96 |
+
return ALL_FREQUENCY_MAX_LENGTHS.get(self, float("inf"))
|
| 97 |
+
|
| 98 |
+
def is_high_frequency(self) -> bool:
|
| 99 |
+
"""Check if this is a high frequency (minute/second level)."""
|
| 100 |
+
return self in [
|
| 101 |
+
Frequency.S,
|
| 102 |
+
Frequency.T1,
|
| 103 |
+
Frequency.T5,
|
| 104 |
+
Frequency.T10,
|
| 105 |
+
Frequency.T15,
|
| 106 |
+
Frequency.T30,
|
| 107 |
+
]
|
| 108 |
+
|
| 109 |
+
def is_low_frequency(self) -> bool:
|
| 110 |
+
"""Check if this is a low frequency (annual/quarterly/monthly)."""
|
| 111 |
+
return self in [Frequency.A, Frequency.Q, Frequency.M]
|
| 112 |
+
|
| 113 |
+
def get_seasonality(self) -> int:
|
| 114 |
+
"""Get typical seasonality for this frequency."""
|
| 115 |
+
seasonality_map = {
|
| 116 |
+
Frequency.S: 3600, # 1 hour of seconds
|
| 117 |
+
Frequency.T1: 60, # 1 hour of minutes
|
| 118 |
+
Frequency.T5: 12, # 1 hour of 5-minute intervals
|
| 119 |
+
Frequency.T10: 6, # 1 hour of 10-minute intervals
|
| 120 |
+
Frequency.T15: 4, # 1 hour of 15-minute intervals
|
| 121 |
+
Frequency.T30: 2, # 1 hour of 30-minute intervals
|
| 122 |
+
Frequency.H: 24, # 1 day of hours
|
| 123 |
+
Frequency.D: 7, # 1 week of days
|
| 124 |
+
Frequency.W: 52, # 1 year of weeks
|
| 125 |
+
Frequency.M: 12, # 1 year of months
|
| 126 |
+
Frequency.Q: 4, # 1 year of quarters
|
| 127 |
+
Frequency.A: 1, # No clear seasonality for annual
|
| 128 |
+
}
|
| 129 |
+
return seasonality_map.get(self, 1)
|
| 130 |
+
|
| 131 |
+
def get_gift_eval_weight(self) -> float:
|
| 132 |
+
"""Get GIFT eval dataset frequency weight."""
|
| 133 |
+
return GIFT_EVAL_FREQUENCY_WEIGHTS.get(self, 0.1)
|
| 134 |
+
|
| 135 |
+
def get_length_range(self) -> Tuple[int, int, int, int]:
|
| 136 |
+
"""Get (min_length, max_length, optimal_start, optimal_end) for this frequency."""
|
| 137 |
+
return GIFT_EVAL_LENGTH_RANGES.get(self, (50, 1000, 100, 500))
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
# ============================================================================
|
| 141 |
+
# Frequency Mappings and Constants
|
| 142 |
+
# ============================================================================
|
| 143 |
+
|
| 144 |
+
# Core frequency mapping: (pandas_base, prefix, days_per_period)
|
| 145 |
+
FREQUENCY_MAPPING: Dict[Frequency, Tuple[str, str, float]] = {
|
| 146 |
+
Frequency.A: (
|
| 147 |
+
"YE",
|
| 148 |
+
"",
|
| 149 |
+
365.25,
|
| 150 |
+
), # Average days per year (accounting for leap years)
|
| 151 |
+
Frequency.Q: ("Q", "", 91.3125), # 365.25/4 - average days per quarter
|
| 152 |
+
Frequency.M: ("M", "", 30.4375), # 365.25/12 - average days per month
|
| 153 |
+
Frequency.W: ("W", "", 7),
|
| 154 |
+
Frequency.D: ("D", "", 1),
|
| 155 |
+
Frequency.H: ("h", "", 1 / 24),
|
| 156 |
+
Frequency.S: ("s", "", 1 / 86400), # 24*60*60
|
| 157 |
+
Frequency.T1: ("min", "1", 1 / 1440), # 24*60
|
| 158 |
+
Frequency.T5: ("min", "5", 1 / 288), # 24*60/5
|
| 159 |
+
Frequency.T10: ("min", "10", 1 / 144), # 24*60/10
|
| 160 |
+
Frequency.T15: ("min", "15", 1 / 96), # 24*60/15
|
| 161 |
+
Frequency.T30: ("min", "30", 1 / 48), # 24*60/30
|
| 162 |
+
}
|
| 163 |
+
|
| 164 |
+
# Frequency to pandas offset mapping for calculating time deltas
|
| 165 |
+
FREQUENCY_TO_OFFSET: Dict[Frequency, str] = {
|
| 166 |
+
Frequency.A: "AS", # Annual start
|
| 167 |
+
Frequency.Q: "QS", # Quarter start
|
| 168 |
+
Frequency.M: "MS", # Month start
|
| 169 |
+
Frequency.W: "W", # Weekly
|
| 170 |
+
Frequency.D: "D", # Daily
|
| 171 |
+
Frequency.H: "H", # Hourly
|
| 172 |
+
Frequency.T1: "1T", # 1 minute
|
| 173 |
+
Frequency.T5: "5T", # 5 minutes
|
| 174 |
+
Frequency.T10: "10T", # 10 minutes
|
| 175 |
+
Frequency.T15: "15T", # 15 minutes
|
| 176 |
+
Frequency.T30: "30T", # 30 minutes
|
| 177 |
+
Frequency.S: "S", # Seconds
|
| 178 |
+
}
|
| 179 |
+
|
| 180 |
+
# Maximum sequence lengths to avoid pandas OutOfBoundsDatetime errors
|
| 181 |
+
SHORT_FREQUENCY_MAX_LENGTHS = {
|
| 182 |
+
Frequency.A: MAX_YEARS,
|
| 183 |
+
Frequency.Q: MAX_YEARS * 4,
|
| 184 |
+
Frequency.M: MAX_YEARS * 12,
|
| 185 |
+
Frequency.W: int(MAX_YEARS * 52.1775),
|
| 186 |
+
Frequency.D: int(MAX_YEARS * 365.2425),
|
| 187 |
+
}
|
| 188 |
+
|
| 189 |
+
HIGH_FREQUENCY_MAX_LENGTHS = {
|
| 190 |
+
Frequency.H: int(MAX_YEARS * 365.2425 * 24),
|
| 191 |
+
Frequency.S: int(MAX_YEARS * 365.2425 * 24 * 60 * 60),
|
| 192 |
+
Frequency.T1: int(MAX_YEARS * 365.2425 * 24 * 60),
|
| 193 |
+
Frequency.T5: int(MAX_YEARS * 365.2425 * 24 * 12),
|
| 194 |
+
Frequency.T10: int(MAX_YEARS * 365.2425 * 24 * 6),
|
| 195 |
+
Frequency.T15: int(MAX_YEARS * 365.2425 * 24 * 4),
|
| 196 |
+
Frequency.T30: int(MAX_YEARS * 365.2425 * 24 * 2),
|
| 197 |
+
}
|
| 198 |
+
|
| 199 |
+
# Combined max lengths for all frequencies
|
| 200 |
+
ALL_FREQUENCY_MAX_LENGTHS = {
|
| 201 |
+
**SHORT_FREQUENCY_MAX_LENGTHS,
|
| 202 |
+
**HIGH_FREQUENCY_MAX_LENGTHS,
|
| 203 |
+
}
|
| 204 |
+
|
| 205 |
+
# GIFT eval-based frequency weights from actual dataset analysis
|
| 206 |
+
GIFT_EVAL_FREQUENCY_WEIGHTS: Dict[Frequency, float] = {
|
| 207 |
+
Frequency.H: 25.0, # Hourly - most common
|
| 208 |
+
Frequency.D: 23.4, # Daily - second most common
|
| 209 |
+
Frequency.W: 12.9, # Weekly - third most common
|
| 210 |
+
Frequency.T15: 9.7, # 15-minute
|
| 211 |
+
Frequency.T5: 9.7, # 5-minute
|
| 212 |
+
Frequency.M: 7.3, # Monthly
|
| 213 |
+
Frequency.T10: 4.8, # 10-minute
|
| 214 |
+
Frequency.S: 4.8, # 10-second
|
| 215 |
+
Frequency.T1: 1.6, # 1-minute
|
| 216 |
+
Frequency.Q: 0.8, # Quarterly
|
| 217 |
+
Frequency.A: 0.8, # Annual
|
| 218 |
+
}
|
| 219 |
+
|
| 220 |
+
# GIFT eval-based length ranges derived from actual dataset analysis
|
| 221 |
+
# Format: (min_length, max_length, optimal_start, optimal_end)
|
| 222 |
+
GIFT_EVAL_LENGTH_RANGES: Dict[Frequency, Tuple[int, int, int, int]] = {
|
| 223 |
+
# Low frequency ranges (based on actual GIFT eval data + logical extensions)
|
| 224 |
+
Frequency.A: (25, 100, 30, 70),
|
| 225 |
+
Frequency.Q: (25, 150, 50, 120),
|
| 226 |
+
Frequency.M: (40, 1000, 100, 600),
|
| 227 |
+
Frequency.W: (50, 3500, 100, 1500),
|
| 228 |
+
# Medium frequency ranges
|
| 229 |
+
Frequency.D: (150, 25000, 300, 7000), # Daily: covers 1-year+ scenarios
|
| 230 |
+
Frequency.H: (600, 35000, 700, 17000),
|
| 231 |
+
# High frequency ranges (extended for shorter realistic scenarios)
|
| 232 |
+
Frequency.T1: (200, 2500, 1200, 1800), # 1-minute: day to few days
|
| 233 |
+
Frequency.S: (7500, 9500, 7900, 9000),
|
| 234 |
+
Frequency.T15: (1000, 140000, 50000, 130000),
|
| 235 |
+
Frequency.T5: (200, 105000, 20000, 95000),
|
| 236 |
+
Frequency.T10: (40000, 55000, 47000, 52000),
|
| 237 |
+
Frequency.T30: (100, 50000, 10000, 40000),
|
| 238 |
+
}
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
# ============================================================================
|
| 242 |
+
# Frequency Parsing and Validation
|
| 243 |
+
# ============================================================================
|
| 244 |
+
|
| 245 |
+
|
| 246 |
+
def parse_frequency(freq_str: str) -> Frequency:
|
| 247 |
+
"""
|
| 248 |
+
Parse frequency string to Frequency enum, robust to variations.
|
| 249 |
+
|
| 250 |
+
Handles various frequency string formats:
|
| 251 |
+
- Standard: "A", "Q", "M", "W", "D", "H", "S"
|
| 252 |
+
- Pandas-style: "A-DEC", "W-SUN", "QE-MAR"
|
| 253 |
+
- Minutes: "5T", "10min", "1T"
|
| 254 |
+
- Case variations: "a", "h", "D"
|
| 255 |
+
|
| 256 |
+
Args:
|
| 257 |
+
freq_str: The frequency string to parse (e.g., "5T", "W-SUN", "M")
|
| 258 |
+
|
| 259 |
+
Returns:
|
| 260 |
+
Corresponding Frequency enum member
|
| 261 |
+
|
| 262 |
+
Raises:
|
| 263 |
+
ValueError: If the frequency string is not supported
|
| 264 |
+
"""
|
| 265 |
+
# Handle minute-based frequencies BEFORE pandas standardization
|
| 266 |
+
# because pandas converts "5T" to just "min", losing the multiplier
|
| 267 |
+
minute_match = re.match(r"^(\d*)T$", freq_str, re.IGNORECASE) or re.match(
|
| 268 |
+
r"^(\d*)min$", freq_str, re.IGNORECASE
|
| 269 |
+
)
|
| 270 |
+
if minute_match:
|
| 271 |
+
multiplier = int(minute_match.group(1)) if minute_match.group(1) else 1
|
| 272 |
+
enum_key = f"T{multiplier}"
|
| 273 |
+
try:
|
| 274 |
+
return Frequency[enum_key]
|
| 275 |
+
except KeyError:
|
| 276 |
+
logger.warning(
|
| 277 |
+
f"Unsupported minute frequency '{freq_str}' (multiplier: {multiplier}). "
|
| 278 |
+
f"Falling back to '1min' ({Frequency.T1.value})."
|
| 279 |
+
)
|
| 280 |
+
return Frequency.T1
|
| 281 |
+
|
| 282 |
+
# Now standardize frequency string for other cases
|
| 283 |
+
try:
|
| 284 |
+
offset = pd.tseries.frequencies.to_offset(freq_str)
|
| 285 |
+
standardized_freq = offset.name
|
| 286 |
+
except Exception:
|
| 287 |
+
standardized_freq = freq_str
|
| 288 |
+
|
| 289 |
+
# Handle other frequencies by their base (e.g., 'W-SUN' -> 'W', 'A-DEC' -> 'A')
|
| 290 |
+
base_freq = standardized_freq.split("-")[0].upper()
|
| 291 |
+
|
| 292 |
+
freq_map = {
|
| 293 |
+
"A": Frequency.A,
|
| 294 |
+
"Y": Frequency.A, # Alias for Annual
|
| 295 |
+
"YE": Frequency.A, # Alias for Annual
|
| 296 |
+
"Q": Frequency.Q,
|
| 297 |
+
"QE": Frequency.Q, # Alias for Quarterly
|
| 298 |
+
"M": Frequency.M,
|
| 299 |
+
"ME": Frequency.M, # Alias for Monthly
|
| 300 |
+
"W": Frequency.W,
|
| 301 |
+
"D": Frequency.D,
|
| 302 |
+
"H": Frequency.H,
|
| 303 |
+
"S": Frequency.S,
|
| 304 |
+
}
|
| 305 |
+
|
| 306 |
+
if base_freq in freq_map:
|
| 307 |
+
return freq_map[base_freq]
|
| 308 |
+
|
| 309 |
+
raise NotImplementedError(f"Frequency '{standardized_freq}' is not supported.")
|
| 310 |
+
|
| 311 |
+
|
| 312 |
+
def validate_frequency_safety(
|
| 313 |
+
start_date: np.datetime64, total_length: int, frequency: Frequency
|
| 314 |
+
) -> bool:
|
| 315 |
+
"""
|
| 316 |
+
Check if start date and frequency combination is safe for pandas datetime operations.
|
| 317 |
+
|
| 318 |
+
This function verifies that pd.date_range(start=start_date, periods=total_length, freq=freq_str)
|
| 319 |
+
will not raise an OutOfBoundsDatetime error, accounting for pandas' datetime bounds
|
| 320 |
+
(1677-09-21 to 2262-04-11) and realistic frequency limitations.
|
| 321 |
+
|
| 322 |
+
Args:
|
| 323 |
+
start_date: The proposed start date for the time series
|
| 324 |
+
total_length: Total length of the time series
|
| 325 |
+
frequency: The frequency of the time series
|
| 326 |
+
|
| 327 |
+
Returns:
|
| 328 |
+
True if the combination is safe, False otherwise
|
| 329 |
+
"""
|
| 330 |
+
try:
|
| 331 |
+
# Get the pandas frequency string
|
| 332 |
+
freq_str = frequency.to_pandas_freq(for_date_range=True)
|
| 333 |
+
|
| 334 |
+
# Convert numpy datetime64 to pandas Timestamp for date_range
|
| 335 |
+
start_pd = pd.Timestamp(start_date)
|
| 336 |
+
|
| 337 |
+
# Check if start date is within pandas' valid datetime range
|
| 338 |
+
if start_pd < pd.Timestamp.min or start_pd > pd.Timestamp.max:
|
| 339 |
+
return False
|
| 340 |
+
|
| 341 |
+
# Check maximum length constraints
|
| 342 |
+
max_length = frequency.get_max_safe_length()
|
| 343 |
+
if total_length > max_length:
|
| 344 |
+
return False
|
| 345 |
+
|
| 346 |
+
# For low frequencies, be extra conservative
|
| 347 |
+
if frequency.is_low_frequency():
|
| 348 |
+
if frequency == Frequency.A and total_length > 500: # Max ~500 years
|
| 349 |
+
return False
|
| 350 |
+
elif frequency == Frequency.Q and total_length > 2000: # Max ~500 years
|
| 351 |
+
return False
|
| 352 |
+
elif frequency == Frequency.M and total_length > 6000: # Max ~500 years
|
| 353 |
+
return False
|
| 354 |
+
|
| 355 |
+
# Calculate approximate end date
|
| 356 |
+
days_per_period = frequency.get_days_per_period()
|
| 357 |
+
approx_days = total_length * days_per_period
|
| 358 |
+
|
| 359 |
+
# For annual/quarterly frequencies, add extra safety margin
|
| 360 |
+
if frequency in [Frequency.A, Frequency.Q]:
|
| 361 |
+
approx_days *= 1.1 # 10% safety margin
|
| 362 |
+
|
| 363 |
+
end_date = start_pd + pd.Timedelta(days=approx_days)
|
| 364 |
+
|
| 365 |
+
# Check if end date is within pandas' valid datetime range
|
| 366 |
+
if end_date < pd.Timestamp.min or end_date > pd.Timestamp.max:
|
| 367 |
+
return False
|
| 368 |
+
|
| 369 |
+
# Try to create the date range as final validation
|
| 370 |
+
pd.date_range(start=start_pd, periods=total_length, freq=freq_str)
|
| 371 |
+
return True
|
| 372 |
+
|
| 373 |
+
except (pd.errors.OutOfBoundsDatetime, OverflowError, ValueError):
|
| 374 |
+
return False
|
| 375 |
+
|
| 376 |
+
|
| 377 |
+
# ============================================================================
|
| 378 |
+
# Frequency Selection Utilities
|
| 379 |
+
# ============================================================================
|
| 380 |
+
|
| 381 |
+
|
| 382 |
+
def select_safe_random_frequency(total_length: int, rng: Generator) -> Frequency:
|
| 383 |
+
"""
|
| 384 |
+
Select a random frequency suitable for a given total length of a time series,
|
| 385 |
+
based on actual GIFT eval dataset patterns and distributions.
|
| 386 |
+
|
| 387 |
+
The selection logic:
|
| 388 |
+
1. Filters frequencies that can handle the given total_length
|
| 389 |
+
2. Applies base weights derived from actual GIFT eval frequency distribution
|
| 390 |
+
3. Strongly boosts frequencies that are in their optimal length ranges
|
| 391 |
+
4. Handles edge cases gracefully with fallbacks
|
| 392 |
+
|
| 393 |
+
Args:
|
| 394 |
+
total_length: The total length of the time series (history + future)
|
| 395 |
+
rng: A numpy random number generator instance
|
| 396 |
+
|
| 397 |
+
Returns:
|
| 398 |
+
A randomly selected frequency that matches GIFT eval patterns
|
| 399 |
+
"""
|
| 400 |
+
# Find valid frequencies and calculate weighted scores
|
| 401 |
+
valid_frequencies = []
|
| 402 |
+
frequency_scores = []
|
| 403 |
+
|
| 404 |
+
for freq in Frequency:
|
| 405 |
+
# Check basic timestamp overflow limits
|
| 406 |
+
max_allowed = freq.get_max_safe_length()
|
| 407 |
+
if total_length > max_allowed:
|
| 408 |
+
continue
|
| 409 |
+
|
| 410 |
+
# Check if frequency has defined ranges
|
| 411 |
+
min_len, max_len, optimal_start, optimal_end = freq.get_length_range()
|
| 412 |
+
|
| 413 |
+
# Must be within the frequency's realistic range
|
| 414 |
+
if total_length < min_len or total_length > max_len:
|
| 415 |
+
continue
|
| 416 |
+
|
| 417 |
+
valid_frequencies.append(freq)
|
| 418 |
+
|
| 419 |
+
# Calculate fitness score based on GIFT eval patterns
|
| 420 |
+
base_weight = freq.get_gift_eval_weight()
|
| 421 |
+
|
| 422 |
+
# Enhanced length-based fitness scoring
|
| 423 |
+
if optimal_start <= total_length <= optimal_end:
|
| 424 |
+
# In optimal range - very strong preference
|
| 425 |
+
length_multiplier = 5.0
|
| 426 |
+
else:
|
| 427 |
+
# Outside optimal but within valid range - calculate penalty
|
| 428 |
+
if total_length < optimal_start:
|
| 429 |
+
# Below optimal range
|
| 430 |
+
distance_ratio = (optimal_start - total_length) / (
|
| 431 |
+
optimal_start - min_len
|
| 432 |
+
)
|
| 433 |
+
else:
|
| 434 |
+
# Above optimal range
|
| 435 |
+
distance_ratio = (total_length - optimal_end) / (max_len - optimal_end)
|
| 436 |
+
|
| 437 |
+
# Apply graduated penalty: closer to optimal = higher score
|
| 438 |
+
length_multiplier = 0.3 + 1.2 * (1.0 - distance_ratio) # Range: 0.3-1.5
|
| 439 |
+
|
| 440 |
+
final_score = base_weight * length_multiplier
|
| 441 |
+
frequency_scores.append(final_score)
|
| 442 |
+
|
| 443 |
+
# Handle edge cases with smart fallbacks
|
| 444 |
+
if not valid_frequencies:
|
| 445 |
+
# Fallback strategy based on typical length patterns
|
| 446 |
+
if total_length <= 100:
|
| 447 |
+
# Very short series - prefer low frequencies
|
| 448 |
+
fallback_order = [
|
| 449 |
+
Frequency.A,
|
| 450 |
+
Frequency.Q,
|
| 451 |
+
Frequency.M,
|
| 452 |
+
Frequency.W,
|
| 453 |
+
Frequency.D,
|
| 454 |
+
]
|
| 455 |
+
elif total_length <= 1000:
|
| 456 |
+
# Medium short series - prefer daily/weekly
|
| 457 |
+
fallback_order = [Frequency.D, Frequency.W, Frequency.H, Frequency.M]
|
| 458 |
+
else:
|
| 459 |
+
# Longer series - prefer higher frequencies
|
| 460 |
+
fallback_order = [Frequency.H, Frequency.D, Frequency.T15, Frequency.T5]
|
| 461 |
+
|
| 462 |
+
for fallback_freq in fallback_order:
|
| 463 |
+
max_allowed = fallback_freq.get_max_safe_length()
|
| 464 |
+
if total_length <= max_allowed:
|
| 465 |
+
return fallback_freq
|
| 466 |
+
# Last resort
|
| 467 |
+
return Frequency.D
|
| 468 |
+
|
| 469 |
+
if len(valid_frequencies) == 1:
|
| 470 |
+
return valid_frequencies[0]
|
| 471 |
+
|
| 472 |
+
# Select based on weighted probabilities
|
| 473 |
+
scores = np.array(frequency_scores)
|
| 474 |
+
probabilities = scores / scores.sum()
|
| 475 |
+
|
| 476 |
+
return rng.choice(valid_frequencies, p=probabilities)
|
| 477 |
+
|
| 478 |
+
|
| 479 |
+
def select_safe_start_date(
|
| 480 |
+
total_length: int,
|
| 481 |
+
frequency: Frequency,
|
| 482 |
+
rng: Generator = np.random.default_rng(),
|
| 483 |
+
max_retries: int = 10,
|
| 484 |
+
) -> np.datetime64:
|
| 485 |
+
"""
|
| 486 |
+
Select a safe start date that ensures the entire time series (history + future)
|
| 487 |
+
will not exceed pandas' datetime bounds.
|
| 488 |
+
|
| 489 |
+
Args:
|
| 490 |
+
total_length: Total length of the time series (history + future)
|
| 491 |
+
frequency: Time series frequency
|
| 492 |
+
rng: Random number generator instance
|
| 493 |
+
max_retries: Maximum number of retry attempts
|
| 494 |
+
|
| 495 |
+
Returns:
|
| 496 |
+
A safe start date that prevents timestamp overflow
|
| 497 |
+
|
| 498 |
+
Raises:
|
| 499 |
+
ValueError: If no safe start date is found after max_retries or if the required
|
| 500 |
+
time span exceeds the available date window
|
| 501 |
+
"""
|
| 502 |
+
days_per_period = frequency.get_days_per_period()
|
| 503 |
+
|
| 504 |
+
# Calculate approximate duration in days
|
| 505 |
+
total_days = total_length * days_per_period
|
| 506 |
+
|
| 507 |
+
# Define safe bounds: ensure end date doesn't exceed BASE_END_DATE
|
| 508 |
+
latest_safe_start = BASE_END_DATE - np.timedelta64(int(total_days), "D")
|
| 509 |
+
earliest_safe_start = BASE_START_DATE
|
| 510 |
+
|
| 511 |
+
# Check if the required time span exceeds the available window
|
| 512 |
+
if latest_safe_start < earliest_safe_start:
|
| 513 |
+
available_days = (
|
| 514 |
+
(BASE_END_DATE - BASE_START_DATE).astype("timedelta64[D]").astype(int)
|
| 515 |
+
)
|
| 516 |
+
available_years = available_days / 365.25
|
| 517 |
+
required_years = total_days / 365.25
|
| 518 |
+
raise ValueError(
|
| 519 |
+
f"Required time span ({required_years:.1f} years, {total_days:.0f} days) "
|
| 520 |
+
f"exceeds available date window ({available_years:.1f} years, {available_days} days). "
|
| 521 |
+
f"Reduce total_length ({total_length}) or extend the date window."
|
| 522 |
+
)
|
| 523 |
+
|
| 524 |
+
# Convert to nanoseconds for random sampling
|
| 525 |
+
earliest_ns = earliest_safe_start.astype("datetime64[ns]").astype(np.int64)
|
| 526 |
+
latest_ns = latest_safe_start.astype("datetime64[ns]").astype(np.int64)
|
| 527 |
+
|
| 528 |
+
for _ in range(max_retries):
|
| 529 |
+
# Uniformly sample a start date within bounds
|
| 530 |
+
random_ns = rng.integers(earliest_ns, latest_ns + 1)
|
| 531 |
+
start_date = np.datetime64(int(random_ns), "ns")
|
| 532 |
+
|
| 533 |
+
# Verify safety
|
| 534 |
+
if validate_frequency_safety(start_date, total_length, frequency):
|
| 535 |
+
return start_date
|
| 536 |
+
|
| 537 |
+
# Default to base start date if no safe start date is found
|
| 538 |
+
return BASE_START_DATE
|
src/data/loaders.py
ADDED
|
@@ -0,0 +1,661 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import random
|
| 3 |
+
from typing import Dict, Iterator, List, Optional
|
| 4 |
+
|
| 5 |
+
import numpy as np
|
| 6 |
+
import pandas as pd
|
| 7 |
+
import torch
|
| 8 |
+
|
| 9 |
+
from src.data.batch_composer import BatchComposer, ComposedDataset
|
| 10 |
+
from src.data.containers import BatchTimeSeriesContainer
|
| 11 |
+
from src.data.frequency import parse_frequency
|
| 12 |
+
from src.gift_eval.constants import ALL_DATASETS
|
| 13 |
+
from src.gift_eval.data import Dataset as GiftEvalDataset
|
| 14 |
+
|
| 15 |
+
logger = logging.getLogger(__name__)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class GiftEvalDataLoader:
|
| 19 |
+
"""
|
| 20 |
+
Data loader for GIFT-eval datasets, converting them to BatchTimeSeriesContainer format.
|
| 21 |
+
Supports both training and validation modes.
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
TERMS = ["short", "medium", "long"]
|
| 25 |
+
|
| 26 |
+
def __init__(
|
| 27 |
+
self,
|
| 28 |
+
mode: str = "train",
|
| 29 |
+
batch_size: int = 32,
|
| 30 |
+
device: Optional[torch.device] = None,
|
| 31 |
+
shuffle: bool = True,
|
| 32 |
+
to_univariate: bool = False,
|
| 33 |
+
max_context_length: Optional[int] = None,
|
| 34 |
+
max_windows: int = 20,
|
| 35 |
+
skip_datasets_with_nans: bool = False,
|
| 36 |
+
datasets_to_use: Optional[List[str]] = None,
|
| 37 |
+
dataset_storage_path: Optional[str] = None,
|
| 38 |
+
):
|
| 39 |
+
"""
|
| 40 |
+
Initialize GIFT-eval data loader.
|
| 41 |
+
|
| 42 |
+
Args:
|
| 43 |
+
mode: Either "train" or "validation"
|
| 44 |
+
batch_size: Number of samples per batch
|
| 45 |
+
device: Device to load data to
|
| 46 |
+
shuffle: Whether to shuffle data
|
| 47 |
+
to_univariate: Whether to convert multivariate data to multiple univariate series
|
| 48 |
+
max_context_length: Optional maximum total window length (context + forecast) to prevent memory issues
|
| 49 |
+
max_windows: Number of windows to use for training/validation
|
| 50 |
+
skip_datasets_with_nans: Whether to skip datasets/series that contain NaN values
|
| 51 |
+
datasets_to_use: Optional list of dataset names to use. If None, uses all available datasets
|
| 52 |
+
dataset_storage_path: Path on disk where GIFT-eval HuggingFace datasets are stored
|
| 53 |
+
"""
|
| 54 |
+
# Use specified datasets or all available datasets if none specified
|
| 55 |
+
if datasets_to_use is not None and len(datasets_to_use) > 0:
|
| 56 |
+
# Validate that requested datasets are available
|
| 57 |
+
invalid_datasets = [ds for ds in datasets_to_use if ds not in ALL_DATASETS]
|
| 58 |
+
if invalid_datasets:
|
| 59 |
+
logger.warning(f"Invalid datasets requested: {invalid_datasets}")
|
| 60 |
+
logger.warning(f"Available datasets: {ALL_DATASETS}")
|
| 61 |
+
# Use only valid datasets
|
| 62 |
+
self.dataset_names = [
|
| 63 |
+
ds for ds in datasets_to_use if ds in ALL_DATASETS
|
| 64 |
+
]
|
| 65 |
+
else:
|
| 66 |
+
self.dataset_names = datasets_to_use
|
| 67 |
+
else:
|
| 68 |
+
self.dataset_names = ALL_DATASETS
|
| 69 |
+
|
| 70 |
+
# Log dataset selection
|
| 71 |
+
if datasets_to_use is not None and len(datasets_to_use) > 0:
|
| 72 |
+
logger.info(
|
| 73 |
+
f"Using subset of datasets: {len(self.dataset_names)}/{len(ALL_DATASETS)} datasets"
|
| 74 |
+
)
|
| 75 |
+
logger.info(f"Selected datasets: {self.dataset_names}")
|
| 76 |
+
else:
|
| 77 |
+
logger.info(
|
| 78 |
+
f"Using all available datasets: {len(self.dataset_names)} datasets"
|
| 79 |
+
)
|
| 80 |
+
|
| 81 |
+
self.terms = self.TERMS
|
| 82 |
+
self.mode = mode
|
| 83 |
+
self.batch_size = batch_size
|
| 84 |
+
self.device = device
|
| 85 |
+
self.shuffle = shuffle
|
| 86 |
+
self.to_univariate = to_univariate
|
| 87 |
+
self.max_context_length = max_context_length
|
| 88 |
+
self.skip_datasets_with_nans = skip_datasets_with_nans
|
| 89 |
+
|
| 90 |
+
# Window configuration based on mode
|
| 91 |
+
self.max_windows = max_windows
|
| 92 |
+
self.dataset_storage_path = dataset_storage_path
|
| 93 |
+
|
| 94 |
+
# Load all datasets and prepare data
|
| 95 |
+
self._load_datasets()
|
| 96 |
+
|
| 97 |
+
# Create iterator state
|
| 98 |
+
self._current_idx = 0
|
| 99 |
+
self._epoch_data = []
|
| 100 |
+
self._prepare_epoch_data()
|
| 101 |
+
|
| 102 |
+
def _load_datasets(self) -> None:
|
| 103 |
+
"""Load all specified GIFT-eval datasets."""
|
| 104 |
+
self.datasets = {}
|
| 105 |
+
self.dataset_prediction_lengths = {}
|
| 106 |
+
|
| 107 |
+
for dataset_name in self.dataset_names:
|
| 108 |
+
if dataset_name.startswith("m4_"):
|
| 109 |
+
max_windows = 1
|
| 110 |
+
else:
|
| 111 |
+
max_windows = self.max_windows
|
| 112 |
+
try:
|
| 113 |
+
# Determine if we need univariate conversion
|
| 114 |
+
# First check with multivariate to see target dimension
|
| 115 |
+
temp_dataset = GiftEvalDataset(
|
| 116 |
+
name=dataset_name,
|
| 117 |
+
term=self.terms[0], # Use first term to check dimensionality
|
| 118 |
+
to_univariate=False,
|
| 119 |
+
max_windows=max_windows,
|
| 120 |
+
storage_path=self.dataset_storage_path,
|
| 121 |
+
)
|
| 122 |
+
|
| 123 |
+
# Convert to univariate if needed
|
| 124 |
+
to_univariate = self.to_univariate and temp_dataset.target_dim > 1
|
| 125 |
+
|
| 126 |
+
# Load datasets for all terms
|
| 127 |
+
for term in self.terms:
|
| 128 |
+
dataset_key = f"{dataset_name}_{term}"
|
| 129 |
+
dataset = GiftEvalDataset(
|
| 130 |
+
name=dataset_name,
|
| 131 |
+
term=term,
|
| 132 |
+
to_univariate=to_univariate,
|
| 133 |
+
max_windows=max_windows,
|
| 134 |
+
storage_path=self.dataset_storage_path,
|
| 135 |
+
)
|
| 136 |
+
|
| 137 |
+
self.datasets[dataset_key] = dataset
|
| 138 |
+
self.dataset_prediction_lengths[dataset_key] = (
|
| 139 |
+
dataset.prediction_length
|
| 140 |
+
)
|
| 141 |
+
|
| 142 |
+
logger.info(
|
| 143 |
+
f"Loaded {dataset_key} - prediction_length: {dataset.prediction_length}, "
|
| 144 |
+
f"frequency: {dataset.freq}, target_dim: {dataset.target_dim}, "
|
| 145 |
+
f"min_length: {dataset._min_series_length}, windows: {dataset.windows}"
|
| 146 |
+
)
|
| 147 |
+
|
| 148 |
+
except Exception as e:
|
| 149 |
+
logger.warning(f"Failed to load dataset {dataset_name}: {str(e)}")
|
| 150 |
+
continue
|
| 151 |
+
|
| 152 |
+
def _contains_nan(self, data_entry: dict) -> bool:
|
| 153 |
+
"""Check if a data entry contains NaN values."""
|
| 154 |
+
target = data_entry.get("target")
|
| 155 |
+
if target is None:
|
| 156 |
+
return False
|
| 157 |
+
|
| 158 |
+
# Convert to numeric numpy array for robust NaN checking
|
| 159 |
+
try:
|
| 160 |
+
target_np = np.asarray(target, dtype=np.float32)
|
| 161 |
+
return np.isnan(target_np).any()
|
| 162 |
+
except Exception:
|
| 163 |
+
logger.warning(
|
| 164 |
+
"NaN check: failed to coerce target to float32; skipping entry"
|
| 165 |
+
)
|
| 166 |
+
return True
|
| 167 |
+
|
| 168 |
+
def _convert_to_container(
|
| 169 |
+
self, data_entries: List[dict], prediction_length: int, dataset_freq: str
|
| 170 |
+
) -> BatchTimeSeriesContainer:
|
| 171 |
+
"""Convert a batch of data entries to BatchTimeSeriesContainer format with fixed future length."""
|
| 172 |
+
batch_size = len(data_entries)
|
| 173 |
+
max_history_len = 0
|
| 174 |
+
|
| 175 |
+
# First pass: determine max history length after truncation
|
| 176 |
+
for entry in data_entries:
|
| 177 |
+
target = np.asarray(entry["target"], dtype=np.float32)
|
| 178 |
+
if target.ndim == 1:
|
| 179 |
+
target = target.reshape(1, -1)
|
| 180 |
+
|
| 181 |
+
_, seq_len = target.shape
|
| 182 |
+
|
| 183 |
+
# Only consider up to the last (max_context_length) values
|
| 184 |
+
effective_max_context = (
|
| 185 |
+
self.max_context_length
|
| 186 |
+
if self.max_context_length is not None
|
| 187 |
+
else seq_len
|
| 188 |
+
)
|
| 189 |
+
if seq_len > effective_max_context:
|
| 190 |
+
seq_len = effective_max_context
|
| 191 |
+
|
| 192 |
+
# History is up to (max_context_length - prediction_length)
|
| 193 |
+
history_len = max(
|
| 194 |
+
0, min(seq_len, effective_max_context) - prediction_length
|
| 195 |
+
)
|
| 196 |
+
max_history_len = max(max_history_len, history_len)
|
| 197 |
+
|
| 198 |
+
# Get number of channels from first entry
|
| 199 |
+
first_target = np.asarray(data_entries[0]["target"], dtype=np.float32)
|
| 200 |
+
if first_target.ndim == 1:
|
| 201 |
+
# Shape to [channels, time]
|
| 202 |
+
first_target = first_target.reshape(1, -1)
|
| 203 |
+
num_channels = first_target.shape[0]
|
| 204 |
+
|
| 205 |
+
# Allocate arrays
|
| 206 |
+
history_values = np.full(
|
| 207 |
+
(batch_size, max_history_len, num_channels), np.nan, dtype=np.float32
|
| 208 |
+
)
|
| 209 |
+
future_values = np.full(
|
| 210 |
+
(batch_size, prediction_length, num_channels), np.nan, dtype=np.float32
|
| 211 |
+
)
|
| 212 |
+
history_mask = np.zeros((batch_size, max_history_len), dtype=bool)
|
| 213 |
+
|
| 214 |
+
# Second pass: fill arrays
|
| 215 |
+
for i, entry in enumerate(data_entries):
|
| 216 |
+
target = np.asarray(entry["target"], dtype=np.float32)
|
| 217 |
+
if target.ndim == 1:
|
| 218 |
+
target = target.reshape(1, -1)
|
| 219 |
+
|
| 220 |
+
# Truncate to last effective_max_context points if needed
|
| 221 |
+
full_seq_len = target.shape[1]
|
| 222 |
+
total_len_allowed = (
|
| 223 |
+
self.max_context_length
|
| 224 |
+
if self.max_context_length is not None
|
| 225 |
+
else full_seq_len
|
| 226 |
+
)
|
| 227 |
+
total_len_for_entry = min(full_seq_len, total_len_allowed)
|
| 228 |
+
|
| 229 |
+
if total_len_for_entry < prediction_length + 1:
|
| 230 |
+
# Not enough length to build (history + future). Signal to caller.
|
| 231 |
+
raise ValueError(
|
| 232 |
+
"Entry too short after max_context_length truncation to form history+future window"
|
| 233 |
+
)
|
| 234 |
+
|
| 235 |
+
truncated = target[:, -total_len_for_entry:]
|
| 236 |
+
cur_history_len = total_len_for_entry - prediction_length
|
| 237 |
+
|
| 238 |
+
hist = truncated[:, :cur_history_len] # [C, H]
|
| 239 |
+
fut = truncated[
|
| 240 |
+
:, cur_history_len : cur_history_len + prediction_length
|
| 241 |
+
] # [C, P]
|
| 242 |
+
|
| 243 |
+
# Write into batch arrays with time last -> transpose to [H, C] / [P, C]
|
| 244 |
+
history_values[i, :cur_history_len, :] = hist.T
|
| 245 |
+
future_values[i, :, :] = fut.T
|
| 246 |
+
history_mask[i, :cur_history_len] = True
|
| 247 |
+
|
| 248 |
+
# Get start timestamp and frequency (replicate across batch)
|
| 249 |
+
start_timestamp = data_entries[0]["start"]
|
| 250 |
+
if hasattr(start_timestamp, "to_timestamp"):
|
| 251 |
+
start_numpy = start_timestamp.to_timestamp().to_numpy()
|
| 252 |
+
else:
|
| 253 |
+
start_numpy = pd.Timestamp(start_timestamp).to_numpy()
|
| 254 |
+
start_list = [start_numpy for _ in range(batch_size)]
|
| 255 |
+
|
| 256 |
+
# Get frequency enum and replicate across batch
|
| 257 |
+
frequency_enum = parse_frequency(dataset_freq)
|
| 258 |
+
frequency_list = [frequency_enum for _ in range(batch_size)]
|
| 259 |
+
|
| 260 |
+
# Create the container
|
| 261 |
+
return BatchTimeSeriesContainer(
|
| 262 |
+
history_values=torch.tensor(history_values, dtype=torch.float32),
|
| 263 |
+
future_values=torch.tensor(future_values, dtype=torch.float32),
|
| 264 |
+
start=start_list,
|
| 265 |
+
frequency=frequency_list,
|
| 266 |
+
history_mask=torch.tensor(history_mask, dtype=torch.bool)
|
| 267 |
+
if self.mode == "train"
|
| 268 |
+
else None,
|
| 269 |
+
)
|
| 270 |
+
|
| 271 |
+
def _prepare_epoch_data(self) -> None:
|
| 272 |
+
"""Prepare all batches for one epoch."""
|
| 273 |
+
self._epoch_data = []
|
| 274 |
+
|
| 275 |
+
for dataset_key, dataset in self.datasets.items():
|
| 276 |
+
try:
|
| 277 |
+
# Get appropriate dataset based on mode
|
| 278 |
+
if self.mode == "train":
|
| 279 |
+
data = dataset.training_dataset
|
| 280 |
+
else:
|
| 281 |
+
data = dataset.validation_dataset
|
| 282 |
+
|
| 283 |
+
# Collect all valid data entries
|
| 284 |
+
valid_entries = []
|
| 285 |
+
dataset_freq = dataset.freq
|
| 286 |
+
prediction_length = self.dataset_prediction_lengths[dataset_key]
|
| 287 |
+
|
| 288 |
+
for entry in data:
|
| 289 |
+
# Skip if contains NaN and configured to do so
|
| 290 |
+
if self.skip_datasets_with_nans and self._contains_nan(entry):
|
| 291 |
+
continue
|
| 292 |
+
|
| 293 |
+
# Check if we have enough data
|
| 294 |
+
target = np.asarray(entry["target"])
|
| 295 |
+
if target.ndim == 1:
|
| 296 |
+
seq_len = len(target)
|
| 297 |
+
else:
|
| 298 |
+
seq_len = target.shape[1]
|
| 299 |
+
|
| 300 |
+
# Need at least prediction_length + 1 for training
|
| 301 |
+
if self.mode == "train" and seq_len < prediction_length + 1:
|
| 302 |
+
continue
|
| 303 |
+
|
| 304 |
+
valid_entries.append(entry)
|
| 305 |
+
|
| 306 |
+
if not valid_entries:
|
| 307 |
+
logger.warning(f"No valid entries found for {dataset_key}")
|
| 308 |
+
continue
|
| 309 |
+
|
| 310 |
+
# Create batches
|
| 311 |
+
for i in range(0, len(valid_entries), self.batch_size):
|
| 312 |
+
batch_entries = valid_entries[i : i + self.batch_size]
|
| 313 |
+
try:
|
| 314 |
+
batch_container = self._convert_to_container(
|
| 315 |
+
batch_entries, prediction_length, dataset_freq
|
| 316 |
+
)
|
| 317 |
+
self._epoch_data.append((dataset_key, batch_container))
|
| 318 |
+
except Exception as e:
|
| 319 |
+
logger.warning(
|
| 320 |
+
f"Failed to create batch for {dataset_key}: {str(e)}"
|
| 321 |
+
)
|
| 322 |
+
continue
|
| 323 |
+
|
| 324 |
+
except Exception as e:
|
| 325 |
+
logger.warning(
|
| 326 |
+
f"Failed to process dataset {dataset_key}: {str(e)}. "
|
| 327 |
+
f"Dataset may be too short for the required offset."
|
| 328 |
+
)
|
| 329 |
+
continue
|
| 330 |
+
|
| 331 |
+
# Shuffle if in training mode
|
| 332 |
+
if self.mode == "train" and self.shuffle:
|
| 333 |
+
random.shuffle(self._epoch_data)
|
| 334 |
+
|
| 335 |
+
logger.info(f"Prepared {len(self._epoch_data)} batches for {self.mode} mode")
|
| 336 |
+
|
| 337 |
+
def __iter__(self) -> Iterator[BatchTimeSeriesContainer]:
|
| 338 |
+
"""Iterate through batches for one epoch."""
|
| 339 |
+
# Reset index at the start of each epoch
|
| 340 |
+
self._current_idx = 0
|
| 341 |
+
|
| 342 |
+
# Reshuffle data for each new epoch if in training mode
|
| 343 |
+
if self.mode == "train" and self.shuffle:
|
| 344 |
+
random.shuffle(self._epoch_data)
|
| 345 |
+
|
| 346 |
+
return self
|
| 347 |
+
|
| 348 |
+
def __next__(self) -> BatchTimeSeriesContainer:
|
| 349 |
+
"""Get next batch."""
|
| 350 |
+
if not self._epoch_data:
|
| 351 |
+
raise StopIteration("No valid data available")
|
| 352 |
+
|
| 353 |
+
# Check if we've exhausted the epoch
|
| 354 |
+
if self._current_idx >= len(self._epoch_data):
|
| 355 |
+
raise StopIteration
|
| 356 |
+
|
| 357 |
+
# Get current batch
|
| 358 |
+
dataset_key, batch = self._epoch_data[self._current_idx]
|
| 359 |
+
self._current_idx += 1
|
| 360 |
+
|
| 361 |
+
# Move to device if specified
|
| 362 |
+
if self.device is not None:
|
| 363 |
+
batch.to_device(self.device)
|
| 364 |
+
|
| 365 |
+
return batch
|
| 366 |
+
|
| 367 |
+
def __len__(self) -> int:
|
| 368 |
+
"""Return number of batches per epoch."""
|
| 369 |
+
return len(self._epoch_data)
|
| 370 |
+
|
| 371 |
+
|
| 372 |
+
class CyclicGiftEvalDataLoader:
|
| 373 |
+
"""
|
| 374 |
+
Wrapper for GiftEvalDataLoader that provides cycling behavior for training.
|
| 375 |
+
This allows training for a fixed number of iterations per epoch, cycling through
|
| 376 |
+
the available data as needed.
|
| 377 |
+
"""
|
| 378 |
+
|
| 379 |
+
def __init__(self, base_loader: GiftEvalDataLoader, num_iterations_per_epoch: int):
|
| 380 |
+
"""
|
| 381 |
+
Initialize the cyclic data loader.
|
| 382 |
+
|
| 383 |
+
Args:
|
| 384 |
+
base_loader: The underlying GiftEvalDataLoader
|
| 385 |
+
num_iterations_per_epoch: Number of iterations to run per epoch
|
| 386 |
+
"""
|
| 387 |
+
self.base_loader = base_loader
|
| 388 |
+
self.num_iterations_per_epoch = num_iterations_per_epoch
|
| 389 |
+
self.dataset_names = base_loader.dataset_names
|
| 390 |
+
self.device = base_loader.device
|
| 391 |
+
|
| 392 |
+
def __iter__(self) -> Iterator[BatchTimeSeriesContainer]:
|
| 393 |
+
"""Iterate for exactly num_iterations_per_epoch iterations."""
|
| 394 |
+
self._current_iteration = 0
|
| 395 |
+
self._base_iter = iter(self.base_loader)
|
| 396 |
+
return self
|
| 397 |
+
|
| 398 |
+
def __next__(self) -> BatchTimeSeriesContainer:
|
| 399 |
+
"""Get next batch, cycling through base loader as needed."""
|
| 400 |
+
if self._current_iteration >= self.num_iterations_per_epoch:
|
| 401 |
+
raise StopIteration
|
| 402 |
+
|
| 403 |
+
try:
|
| 404 |
+
batch = next(self._base_iter)
|
| 405 |
+
except StopIteration:
|
| 406 |
+
# Restart the base iterator when exhausted
|
| 407 |
+
self._base_iter = iter(self.base_loader)
|
| 408 |
+
batch = next(self._base_iter)
|
| 409 |
+
|
| 410 |
+
self._current_iteration += 1
|
| 411 |
+
return batch
|
| 412 |
+
|
| 413 |
+
def __len__(self) -> int:
|
| 414 |
+
"""Return the configured number of iterations per epoch."""
|
| 415 |
+
return self.num_iterations_per_epoch
|
| 416 |
+
|
| 417 |
+
|
| 418 |
+
def create_synthetic_dataloader(
|
| 419 |
+
base_data_dir: str,
|
| 420 |
+
batch_size: int = 128,
|
| 421 |
+
num_batches_per_epoch: int = 1000,
|
| 422 |
+
generator_proportions: Optional[Dict[str, float]] = None,
|
| 423 |
+
mixed_batches: bool = True,
|
| 424 |
+
augmentations: Optional[Dict[str, bool]] = None,
|
| 425 |
+
augmentation_probabilities: Optional[Dict[str, float]] = None,
|
| 426 |
+
device: Optional[torch.device] = None,
|
| 427 |
+
num_workers: int = 0,
|
| 428 |
+
pin_memory: bool = True,
|
| 429 |
+
global_seed: int = 42,
|
| 430 |
+
nan_stats_path: Optional[str] = None,
|
| 431 |
+
nan_patterns_path: Optional[str] = None,
|
| 432 |
+
chosen_scaler_name: Optional[str] = None,
|
| 433 |
+
) -> torch.utils.data.DataLoader:
|
| 434 |
+
"""
|
| 435 |
+
Create a PyTorch DataLoader for training with saved generator batches.
|
| 436 |
+
|
| 437 |
+
Args:
|
| 438 |
+
base_data_dir: Base directory containing generator subdirectories
|
| 439 |
+
batch_size: Size of each training batch
|
| 440 |
+
num_batches_per_epoch: Number of batches per epoch
|
| 441 |
+
generator_proportions: Dict mapping generator names to proportions
|
| 442 |
+
mixed_batches: Whether to create mixed or uniform batches
|
| 443 |
+
augmentations: Dict mapping augmentation names to booleans
|
| 444 |
+
augmentation_probabilities: Dict mapping augmentation names to probabilities
|
| 445 |
+
device: Target device
|
| 446 |
+
num_workers: Number of DataLoader workers
|
| 447 |
+
pin_memory: Whether to pin memory
|
| 448 |
+
global_seed: Global random seed
|
| 449 |
+
nan_stats_path: Path to nan stats file
|
| 450 |
+
chosen_scaler_name: Name of the scaler that used in training
|
| 451 |
+
|
| 452 |
+
Returns:
|
| 453 |
+
PyTorch DataLoader
|
| 454 |
+
"""
|
| 455 |
+
|
| 456 |
+
# Create batch composer
|
| 457 |
+
composer = BatchComposer(
|
| 458 |
+
base_data_dir=base_data_dir,
|
| 459 |
+
generator_proportions=generator_proportions,
|
| 460 |
+
mixed_batches=mixed_batches,
|
| 461 |
+
device=device,
|
| 462 |
+
augmentations=augmentations,
|
| 463 |
+
augmentation_probabilities=augmentation_probabilities,
|
| 464 |
+
global_seed=global_seed,
|
| 465 |
+
nan_stats_path=nan_stats_path,
|
| 466 |
+
nan_patterns_path=nan_patterns_path,
|
| 467 |
+
chosen_scaler_name=chosen_scaler_name,
|
| 468 |
+
)
|
| 469 |
+
|
| 470 |
+
# Create dataset
|
| 471 |
+
dataset = ComposedDataset(
|
| 472 |
+
batch_composer=composer,
|
| 473 |
+
num_batches_per_epoch=num_batches_per_epoch,
|
| 474 |
+
batch_size=batch_size,
|
| 475 |
+
)
|
| 476 |
+
|
| 477 |
+
# Custom collate function for BatchTimeSeriesContainer
|
| 478 |
+
def collate_fn(batch):
|
| 479 |
+
"""Custom collate function that returns a single BatchTimeSeriesContainer."""
|
| 480 |
+
# Since each item is already a BatchTimeSeriesContainer with batch_size samples,
|
| 481 |
+
# and DataLoader batch_size=1, we just return the first (and only) item
|
| 482 |
+
return batch[0]
|
| 483 |
+
|
| 484 |
+
# Create DataLoader
|
| 485 |
+
dataloader = torch.utils.data.DataLoader(
|
| 486 |
+
dataset,
|
| 487 |
+
batch_size=1, # Each dataset item is already a complete batch
|
| 488 |
+
shuffle=False,
|
| 489 |
+
num_workers=num_workers,
|
| 490 |
+
pin_memory=pin_memory,
|
| 491 |
+
collate_fn=collate_fn,
|
| 492 |
+
drop_last=False,
|
| 493 |
+
)
|
| 494 |
+
|
| 495 |
+
logger.info(
|
| 496 |
+
f"Created DataLoader with {len(dataset)} batches per epoch, "
|
| 497 |
+
f"batch_size={batch_size}, mixed_batches={mixed_batches}"
|
| 498 |
+
)
|
| 499 |
+
|
| 500 |
+
return dataloader
|
| 501 |
+
|
| 502 |
+
|
| 503 |
+
class SyntheticValidationDataset(torch.utils.data.Dataset):
|
| 504 |
+
"""
|
| 505 |
+
Fixed synthetic validation dataset that generates a small number of batches
|
| 506 |
+
using the same composition approach as training data.
|
| 507 |
+
"""
|
| 508 |
+
|
| 509 |
+
def __init__(
|
| 510 |
+
self,
|
| 511 |
+
base_data_dir: str,
|
| 512 |
+
batch_size: int = 128,
|
| 513 |
+
num_batches: int = 2,
|
| 514 |
+
future_length: int = 512,
|
| 515 |
+
generator_proportions: Optional[Dict[str, float]] = None,
|
| 516 |
+
augmentations: Optional[Dict[str, bool]] = None,
|
| 517 |
+
augmentation_probabilities: Optional[Dict[str, float]] = None,
|
| 518 |
+
device: Optional[torch.device] = None,
|
| 519 |
+
global_seed: int = 42,
|
| 520 |
+
chosen_scaler_name: Optional[str] = None,
|
| 521 |
+
nan_stats_path: Optional[str] = None,
|
| 522 |
+
nan_patterns_path: Optional[str] = None,
|
| 523 |
+
rank: int = 0,
|
| 524 |
+
world_size: int = 1,
|
| 525 |
+
):
|
| 526 |
+
"""
|
| 527 |
+
Initialize the validation dataset.
|
| 528 |
+
|
| 529 |
+
Args:
|
| 530 |
+
base_data_dir: Base directory containing generator subdirectories
|
| 531 |
+
batch_size: Size of each validation batch
|
| 532 |
+
num_batches: Number of validation batches to generate (1 or 2)
|
| 533 |
+
generator_proportions: Dict mapping generator names to proportions
|
| 534 |
+
device: Device to load tensors to
|
| 535 |
+
global_seed: Global random seed
|
| 536 |
+
chosen_scaler_name: Name of the scaler that used in training
|
| 537 |
+
"""
|
| 538 |
+
self.batch_size = batch_size
|
| 539 |
+
self.num_batches = num_batches
|
| 540 |
+
self.device = device
|
| 541 |
+
|
| 542 |
+
# Create batch composer; force validation to use max-length windows (no length shortening)
|
| 543 |
+
val_augmentations = dict(augmentations or {})
|
| 544 |
+
val_augmentations["length_shortening"] = False
|
| 545 |
+
|
| 546 |
+
self.batch_composer = BatchComposer(
|
| 547 |
+
base_data_dir=base_data_dir,
|
| 548 |
+
generator_proportions=generator_proportions,
|
| 549 |
+
mixed_batches=True, # Use mixed batches for validation
|
| 550 |
+
device=device,
|
| 551 |
+
global_seed=global_seed + 999999,
|
| 552 |
+
augmentations=val_augmentations,
|
| 553 |
+
augmentation_probabilities=augmentation_probabilities,
|
| 554 |
+
nan_stats_path=nan_stats_path,
|
| 555 |
+
nan_patterns_path=nan_patterns_path,
|
| 556 |
+
chosen_scaler_name=chosen_scaler_name,
|
| 557 |
+
rank=rank,
|
| 558 |
+
world_size=world_size,
|
| 559 |
+
)
|
| 560 |
+
|
| 561 |
+
# Pre-generate fixed validation batches
|
| 562 |
+
self.validation_batches = []
|
| 563 |
+
for i in range(num_batches):
|
| 564 |
+
batch, _ = self.batch_composer.create_batch(
|
| 565 |
+
batch_size=batch_size,
|
| 566 |
+
future_length=future_length,
|
| 567 |
+
seed=global_seed
|
| 568 |
+
+ 999999
|
| 569 |
+
+ i, # Fixed seeds for reproducible validation
|
| 570 |
+
)
|
| 571 |
+
self.validation_batches.append(batch)
|
| 572 |
+
|
| 573 |
+
logger.info(
|
| 574 |
+
f"Created {num_batches} fixed validation batches with batch_size={batch_size}"
|
| 575 |
+
)
|
| 576 |
+
|
| 577 |
+
def __len__(self) -> int:
|
| 578 |
+
return self.num_batches
|
| 579 |
+
|
| 580 |
+
def __getitem__(self, idx: int) -> BatchTimeSeriesContainer:
|
| 581 |
+
"""
|
| 582 |
+
Get a pre-generated validation batch by index.
|
| 583 |
+
|
| 584 |
+
Args:
|
| 585 |
+
idx: Batch index
|
| 586 |
+
|
| 587 |
+
Returns:
|
| 588 |
+
BatchTimeSeriesContainer
|
| 589 |
+
"""
|
| 590 |
+
if idx >= len(self.validation_batches):
|
| 591 |
+
raise IndexError(f"Batch index {idx} out of range")
|
| 592 |
+
|
| 593 |
+
batch = self.validation_batches[idx]
|
| 594 |
+
|
| 595 |
+
# Move to device if needed
|
| 596 |
+
if self.device is not None:
|
| 597 |
+
batch.to_device(self.device)
|
| 598 |
+
|
| 599 |
+
return batch
|
| 600 |
+
|
| 601 |
+
|
| 602 |
+
def create_synthetic_dataset(
|
| 603 |
+
base_data_dir: str,
|
| 604 |
+
batch_size: int = 128,
|
| 605 |
+
num_batches_per_epoch: int = 1000,
|
| 606 |
+
generator_proportions: Optional[Dict[str, float]] = None,
|
| 607 |
+
mixed_batches: bool = True,
|
| 608 |
+
augmentations: Optional[Dict[str, bool]] = None,
|
| 609 |
+
augmentation_probabilities: Optional[Dict[str, float]] = None,
|
| 610 |
+
global_seed: int = 42,
|
| 611 |
+
nan_stats_path: Optional[str] = None,
|
| 612 |
+
nan_patterns_path: Optional[str] = None,
|
| 613 |
+
chosen_scaler_name: Optional[str] = None,
|
| 614 |
+
rank: int = 0,
|
| 615 |
+
world_size: int = 1,
|
| 616 |
+
) -> ComposedDataset:
|
| 617 |
+
"""
|
| 618 |
+
Creates the ComposedDataset for training with saved generator batches.
|
| 619 |
+
|
| 620 |
+
Args:
|
| 621 |
+
base_data_dir: Base directory containing generator subdirectories.
|
| 622 |
+
batch_size: Size of each training batch.
|
| 623 |
+
num_batches_per_epoch: Number of batches per epoch.
|
| 624 |
+
generator_proportions: Dict mapping generator names to proportions.
|
| 625 |
+
mixed_batches: Whether to create mixed or uniform batches.
|
| 626 |
+
augmentations: Dict mapping augmentation names to booleans.
|
| 627 |
+
global_seed: Global random seed.
|
| 628 |
+
nan_stats_path: Path to nan stats file.
|
| 629 |
+
chosen_scaler_name: Name of the scaler to use.
|
| 630 |
+
Returns:
|
| 631 |
+
A ComposedDataset instance.
|
| 632 |
+
"""
|
| 633 |
+
# Create batch composer
|
| 634 |
+
composer = BatchComposer(
|
| 635 |
+
base_data_dir=base_data_dir,
|
| 636 |
+
generator_proportions=generator_proportions,
|
| 637 |
+
mixed_batches=mixed_batches,
|
| 638 |
+
device=None, # Device is handled in the training loop
|
| 639 |
+
augmentations=augmentations,
|
| 640 |
+
augmentation_probabilities=augmentation_probabilities,
|
| 641 |
+
global_seed=global_seed,
|
| 642 |
+
nan_stats_path=nan_stats_path,
|
| 643 |
+
nan_patterns_path=nan_patterns_path,
|
| 644 |
+
chosen_scaler_name=chosen_scaler_name,
|
| 645 |
+
rank=rank,
|
| 646 |
+
world_size=world_size,
|
| 647 |
+
)
|
| 648 |
+
|
| 649 |
+
# Create and return the dataset
|
| 650 |
+
dataset = ComposedDataset(
|
| 651 |
+
batch_composer=composer,
|
| 652 |
+
num_batches_per_epoch=num_batches_per_epoch,
|
| 653 |
+
batch_size=batch_size,
|
| 654 |
+
)
|
| 655 |
+
|
| 656 |
+
logger.info(
|
| 657 |
+
f"Created ComposedDataset with {len(dataset)} batches per epoch, "
|
| 658 |
+
f"batch_size={batch_size}, mixed_batches={mixed_batches}"
|
| 659 |
+
)
|
| 660 |
+
|
| 661 |
+
return dataset
|
src/data/scalers.py
ADDED
|
@@ -0,0 +1,360 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from abc import ABC, abstractmethod
|
| 2 |
+
from typing import Dict, Optional
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class BaseScaler(ABC):
|
| 8 |
+
"""
|
| 9 |
+
Abstract base class for time series scalers.
|
| 10 |
+
|
| 11 |
+
Defines the interface for scaling multivariate time series data with support
|
| 12 |
+
for masked values and channel-wise scaling.
|
| 13 |
+
"""
|
| 14 |
+
|
| 15 |
+
@abstractmethod
|
| 16 |
+
def compute_statistics(
|
| 17 |
+
self, history_values: torch.Tensor, history_mask: Optional[torch.Tensor] = None
|
| 18 |
+
) -> Dict[str, torch.Tensor]:
|
| 19 |
+
"""
|
| 20 |
+
Compute scaling statistics from historical data.
|
| 21 |
+
"""
|
| 22 |
+
pass
|
| 23 |
+
|
| 24 |
+
@abstractmethod
|
| 25 |
+
def scale(
|
| 26 |
+
self, data: torch.Tensor, statistics: Dict[str, torch.Tensor]
|
| 27 |
+
) -> torch.Tensor:
|
| 28 |
+
"""
|
| 29 |
+
Apply scaling transformation to data.
|
| 30 |
+
"""
|
| 31 |
+
pass
|
| 32 |
+
|
| 33 |
+
@abstractmethod
|
| 34 |
+
def inverse_scale(
|
| 35 |
+
self, scaled_data: torch.Tensor, statistics: Dict[str, torch.Tensor]
|
| 36 |
+
) -> torch.Tensor:
|
| 37 |
+
"""
|
| 38 |
+
Apply inverse scaling transformation to recover original scale.
|
| 39 |
+
"""
|
| 40 |
+
pass
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
class RobustScaler(BaseScaler):
|
| 44 |
+
"""
|
| 45 |
+
Robust scaler using median and IQR for normalization.
|
| 46 |
+
"""
|
| 47 |
+
|
| 48 |
+
def __init__(self, epsilon: float = 1e-6, min_scale: float = 1e-3):
|
| 49 |
+
if epsilon <= 0:
|
| 50 |
+
raise ValueError("epsilon must be positive")
|
| 51 |
+
if min_scale <= 0:
|
| 52 |
+
raise ValueError("min_scale must be positive")
|
| 53 |
+
self.epsilon = epsilon
|
| 54 |
+
self.min_scale = min_scale
|
| 55 |
+
|
| 56 |
+
def compute_statistics(
|
| 57 |
+
self, history_values: torch.Tensor, history_mask: Optional[torch.Tensor] = None
|
| 58 |
+
) -> Dict[str, torch.Tensor]:
|
| 59 |
+
"""
|
| 60 |
+
Compute median and IQR statistics from historical data with improved numerical stability.
|
| 61 |
+
"""
|
| 62 |
+
batch_size, seq_len, num_channels = history_values.shape
|
| 63 |
+
device = history_values.device
|
| 64 |
+
|
| 65 |
+
medians = torch.zeros(batch_size, 1, num_channels, device=device)
|
| 66 |
+
iqrs = torch.ones(batch_size, 1, num_channels, device=device)
|
| 67 |
+
|
| 68 |
+
for b in range(batch_size):
|
| 69 |
+
for c in range(num_channels):
|
| 70 |
+
channel_data = history_values[b, :, c]
|
| 71 |
+
|
| 72 |
+
if history_mask is not None:
|
| 73 |
+
mask = history_mask[b, :].bool()
|
| 74 |
+
valid_data = channel_data[mask]
|
| 75 |
+
else:
|
| 76 |
+
valid_data = channel_data
|
| 77 |
+
|
| 78 |
+
if len(valid_data) == 0:
|
| 79 |
+
continue
|
| 80 |
+
|
| 81 |
+
valid_data = valid_data[torch.isfinite(valid_data)]
|
| 82 |
+
|
| 83 |
+
if len(valid_data) == 0:
|
| 84 |
+
continue
|
| 85 |
+
|
| 86 |
+
median_val = torch.median(valid_data)
|
| 87 |
+
medians[b, 0, c] = median_val
|
| 88 |
+
|
| 89 |
+
if len(valid_data) > 1:
|
| 90 |
+
try:
|
| 91 |
+
q75 = torch.quantile(valid_data, 0.75)
|
| 92 |
+
q25 = torch.quantile(valid_data, 0.25)
|
| 93 |
+
iqr_val = q75 - q25
|
| 94 |
+
iqr_val = torch.max(
|
| 95 |
+
iqr_val, torch.tensor(self.min_scale, device=device)
|
| 96 |
+
)
|
| 97 |
+
iqrs[b, 0, c] = iqr_val
|
| 98 |
+
except Exception:
|
| 99 |
+
std_val = torch.std(valid_data)
|
| 100 |
+
iqrs[b, 0, c] = torch.max(
|
| 101 |
+
std_val, torch.tensor(self.min_scale, device=device)
|
| 102 |
+
)
|
| 103 |
+
else:
|
| 104 |
+
iqrs[b, 0, c] = self.min_scale
|
| 105 |
+
|
| 106 |
+
return {"median": medians, "iqr": iqrs}
|
| 107 |
+
|
| 108 |
+
def scale(
|
| 109 |
+
self, data: torch.Tensor, statistics: Dict[str, torch.Tensor]
|
| 110 |
+
) -> torch.Tensor:
|
| 111 |
+
"""
|
| 112 |
+
Apply robust scaling: (data - median) / (iqr + epsilon).
|
| 113 |
+
"""
|
| 114 |
+
median = statistics["median"]
|
| 115 |
+
iqr = statistics["iqr"]
|
| 116 |
+
|
| 117 |
+
denominator = torch.max(
|
| 118 |
+
iqr + self.epsilon, torch.tensor(self.min_scale, device=iqr.device)
|
| 119 |
+
)
|
| 120 |
+
scaled_data = (data - median) / denominator
|
| 121 |
+
scaled_data = torch.clamp(scaled_data, -50.0, 50.0)
|
| 122 |
+
|
| 123 |
+
return scaled_data
|
| 124 |
+
|
| 125 |
+
def inverse_scale(
|
| 126 |
+
self, scaled_data: torch.Tensor, statistics: Dict[str, torch.Tensor]
|
| 127 |
+
) -> torch.Tensor:
|
| 128 |
+
"""
|
| 129 |
+
Apply inverse robust scaling, now compatible with 3D or 4D tensors.
|
| 130 |
+
"""
|
| 131 |
+
median = statistics["median"]
|
| 132 |
+
iqr = statistics["iqr"]
|
| 133 |
+
|
| 134 |
+
denominator = torch.max(
|
| 135 |
+
iqr + self.epsilon, torch.tensor(self.min_scale, device=iqr.device)
|
| 136 |
+
)
|
| 137 |
+
|
| 138 |
+
if scaled_data.ndim == 4:
|
| 139 |
+
denominator = denominator.unsqueeze(-1)
|
| 140 |
+
median = median.unsqueeze(-1)
|
| 141 |
+
|
| 142 |
+
return scaled_data * denominator + median
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
class MinMaxScaler(BaseScaler):
|
| 146 |
+
"""
|
| 147 |
+
Min-Max scaler that normalizes data to the range [-1, 1].
|
| 148 |
+
"""
|
| 149 |
+
|
| 150 |
+
def __init__(self, epsilon: float = 1e-8):
|
| 151 |
+
if epsilon <= 0:
|
| 152 |
+
raise ValueError("epsilon must be positive")
|
| 153 |
+
self.epsilon = epsilon
|
| 154 |
+
|
| 155 |
+
def compute_statistics(
|
| 156 |
+
self, history_values: torch.Tensor, history_mask: Optional[torch.Tensor] = None
|
| 157 |
+
) -> Dict[str, torch.Tensor]:
|
| 158 |
+
"""
|
| 159 |
+
Compute min and max statistics from historical data.
|
| 160 |
+
"""
|
| 161 |
+
batch_size, seq_len, num_channels = history_values.shape
|
| 162 |
+
device = history_values.device
|
| 163 |
+
|
| 164 |
+
mins = torch.zeros(batch_size, 1, num_channels, device=device)
|
| 165 |
+
maxs = torch.ones(batch_size, 1, num_channels, device=device)
|
| 166 |
+
|
| 167 |
+
for b in range(batch_size):
|
| 168 |
+
for c in range(num_channels):
|
| 169 |
+
channel_data = history_values[b, :, c]
|
| 170 |
+
|
| 171 |
+
if history_mask is not None:
|
| 172 |
+
mask = history_mask[b, :].bool()
|
| 173 |
+
valid_data = channel_data[mask]
|
| 174 |
+
else:
|
| 175 |
+
valid_data = channel_data
|
| 176 |
+
|
| 177 |
+
if len(valid_data) == 0:
|
| 178 |
+
continue
|
| 179 |
+
|
| 180 |
+
min_val = torch.min(valid_data)
|
| 181 |
+
max_val = torch.max(valid_data)
|
| 182 |
+
|
| 183 |
+
mins[b, 0, c] = min_val
|
| 184 |
+
maxs[b, 0, c] = max_val
|
| 185 |
+
|
| 186 |
+
if torch.abs(max_val - min_val) < self.epsilon:
|
| 187 |
+
maxs[b, 0, c] = min_val + 1.0
|
| 188 |
+
|
| 189 |
+
return {"min": mins, "max": maxs}
|
| 190 |
+
|
| 191 |
+
def scale(
|
| 192 |
+
self, data: torch.Tensor, statistics: Dict[str, torch.Tensor]
|
| 193 |
+
) -> torch.Tensor:
|
| 194 |
+
"""
|
| 195 |
+
Apply min-max scaling to range [-1, 1].
|
| 196 |
+
"""
|
| 197 |
+
min_val = statistics["min"]
|
| 198 |
+
max_val = statistics["max"]
|
| 199 |
+
|
| 200 |
+
normalized = (data - min_val) / (max_val - min_val + self.epsilon)
|
| 201 |
+
return normalized * 2.0 - 1.0
|
| 202 |
+
|
| 203 |
+
def inverse_scale(
|
| 204 |
+
self, scaled_data: torch.Tensor, statistics: Dict[str, torch.Tensor]
|
| 205 |
+
) -> torch.Tensor:
|
| 206 |
+
"""
|
| 207 |
+
Apply inverse min-max scaling, now compatible with 3D or 4D tensors.
|
| 208 |
+
"""
|
| 209 |
+
min_val = statistics["min"]
|
| 210 |
+
max_val = statistics["max"]
|
| 211 |
+
|
| 212 |
+
if scaled_data.ndim == 4:
|
| 213 |
+
min_val = min_val.unsqueeze(-1)
|
| 214 |
+
max_val = max_val.unsqueeze(-1)
|
| 215 |
+
|
| 216 |
+
normalized = (scaled_data + 1.0) / 2.0
|
| 217 |
+
return normalized * (max_val - min_val + self.epsilon) + min_val
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
class MeanScaler(BaseScaler):
|
| 221 |
+
"""
|
| 222 |
+
A scaler that centers the data by subtracting the channel-wise mean.
|
| 223 |
+
|
| 224 |
+
This scaler only performs centering and does not affect the scale of the data.
|
| 225 |
+
"""
|
| 226 |
+
|
| 227 |
+
def compute_statistics(
|
| 228 |
+
self, history_values: torch.Tensor, history_mask: Optional[torch.Tensor] = None
|
| 229 |
+
) -> Dict[str, torch.Tensor]:
|
| 230 |
+
"""
|
| 231 |
+
Compute the mean for each channel from historical data.
|
| 232 |
+
"""
|
| 233 |
+
batch_size, seq_len, num_channels = history_values.shape
|
| 234 |
+
device = history_values.device
|
| 235 |
+
|
| 236 |
+
# Initialize a tensor to store the mean for each channel in each batch item
|
| 237 |
+
means = torch.zeros(batch_size, 1, num_channels, device=device)
|
| 238 |
+
|
| 239 |
+
for b in range(batch_size):
|
| 240 |
+
for c in range(num_channels):
|
| 241 |
+
channel_data = history_values[b, :, c]
|
| 242 |
+
|
| 243 |
+
# Use the mask to select only valid (observed) data points
|
| 244 |
+
if history_mask is not None:
|
| 245 |
+
mask = history_mask[b, :].bool()
|
| 246 |
+
valid_data = channel_data[mask]
|
| 247 |
+
else:
|
| 248 |
+
valid_data = channel_data
|
| 249 |
+
|
| 250 |
+
# Skip if there's no valid data for this channel
|
| 251 |
+
if len(valid_data) == 0:
|
| 252 |
+
continue
|
| 253 |
+
|
| 254 |
+
# Filter out non-finite values like NaN or Inf before computing
|
| 255 |
+
valid_data = valid_data[torch.isfinite(valid_data)]
|
| 256 |
+
|
| 257 |
+
if len(valid_data) == 0:
|
| 258 |
+
continue
|
| 259 |
+
|
| 260 |
+
# Compute the mean and store it
|
| 261 |
+
means[b, 0, c] = torch.mean(valid_data)
|
| 262 |
+
|
| 263 |
+
return {"mean": means}
|
| 264 |
+
|
| 265 |
+
def scale(
|
| 266 |
+
self, data: torch.Tensor, statistics: Dict[str, torch.Tensor]
|
| 267 |
+
) -> torch.Tensor:
|
| 268 |
+
"""
|
| 269 |
+
Apply mean centering: data - mean.
|
| 270 |
+
"""
|
| 271 |
+
mean = statistics["mean"]
|
| 272 |
+
return data - mean
|
| 273 |
+
|
| 274 |
+
def inverse_scale(
|
| 275 |
+
self, scaled_data: torch.Tensor, statistics: Dict[str, torch.Tensor]
|
| 276 |
+
) -> torch.Tensor:
|
| 277 |
+
"""
|
| 278 |
+
Apply inverse mean centering: scaled_data + mean.
|
| 279 |
+
|
| 280 |
+
Handles both 3D (e.g., training input) and 4D (e.g., model output samples) tensors.
|
| 281 |
+
"""
|
| 282 |
+
mean = statistics["mean"]
|
| 283 |
+
|
| 284 |
+
# Adjust shape for 4D tensors (batch, seq_len, channels, samples)
|
| 285 |
+
if scaled_data.ndim == 4:
|
| 286 |
+
mean = mean.unsqueeze(-1)
|
| 287 |
+
|
| 288 |
+
return scaled_data + mean
|
| 289 |
+
|
| 290 |
+
|
| 291 |
+
class MedianScaler(BaseScaler):
|
| 292 |
+
"""
|
| 293 |
+
A scaler that centers the data by subtracting the channel-wise median.
|
| 294 |
+
|
| 295 |
+
This scaler only performs centering and does not affect the scale of the data.
|
| 296 |
+
It is more robust to outliers than the MeanScaler.
|
| 297 |
+
"""
|
| 298 |
+
|
| 299 |
+
def compute_statistics(
|
| 300 |
+
self, history_values: torch.Tensor, history_mask: Optional[torch.Tensor] = None
|
| 301 |
+
) -> Dict[str, torch.Tensor]:
|
| 302 |
+
"""
|
| 303 |
+
Compute the median for each channel from historical data.
|
| 304 |
+
"""
|
| 305 |
+
batch_size, seq_len, num_channels = history_values.shape
|
| 306 |
+
device = history_values.device
|
| 307 |
+
|
| 308 |
+
# Initialize a tensor to store the median for each channel in each batch item
|
| 309 |
+
medians = torch.zeros(batch_size, 1, num_channels, device=device)
|
| 310 |
+
|
| 311 |
+
for b in range(batch_size):
|
| 312 |
+
for c in range(num_channels):
|
| 313 |
+
channel_data = history_values[b, :, c]
|
| 314 |
+
|
| 315 |
+
# Use the mask to select only valid (observed) data points
|
| 316 |
+
if history_mask is not None:
|
| 317 |
+
mask = history_mask[b, :].bool()
|
| 318 |
+
valid_data = channel_data[mask]
|
| 319 |
+
else:
|
| 320 |
+
valid_data = channel_data
|
| 321 |
+
|
| 322 |
+
# Skip if there's no valid data for this channel
|
| 323 |
+
if len(valid_data) == 0:
|
| 324 |
+
continue
|
| 325 |
+
|
| 326 |
+
# Filter out non-finite values like NaN or Inf before computing
|
| 327 |
+
valid_data = valid_data[torch.isfinite(valid_data)]
|
| 328 |
+
|
| 329 |
+
if len(valid_data) == 0:
|
| 330 |
+
continue
|
| 331 |
+
|
| 332 |
+
# Compute the median and store it
|
| 333 |
+
medians[b, 0, c] = torch.median(valid_data)
|
| 334 |
+
|
| 335 |
+
return {"median": medians}
|
| 336 |
+
|
| 337 |
+
def scale(
|
| 338 |
+
self, data: torch.Tensor, statistics: Dict[str, torch.Tensor]
|
| 339 |
+
) -> torch.Tensor:
|
| 340 |
+
"""
|
| 341 |
+
Apply median centering: data - median.
|
| 342 |
+
"""
|
| 343 |
+
median = statistics["median"]
|
| 344 |
+
return data - median
|
| 345 |
+
|
| 346 |
+
def inverse_scale(
|
| 347 |
+
self, scaled_data: torch.Tensor, statistics: Dict[str, torch.Tensor]
|
| 348 |
+
) -> torch.Tensor:
|
| 349 |
+
"""
|
| 350 |
+
Apply inverse median centering: scaled_data + median.
|
| 351 |
+
|
| 352 |
+
Handles both 3D (e.g., training input) and 4D (e.g., model output samples) tensors.
|
| 353 |
+
"""
|
| 354 |
+
median = statistics["median"]
|
| 355 |
+
|
| 356 |
+
# Adjust shape for 4D tensors (batch, seq_len, channels, samples)
|
| 357 |
+
if scaled_data.ndim == 4:
|
| 358 |
+
median = median.unsqueeze(-1)
|
| 359 |
+
|
| 360 |
+
return scaled_data + median
|
src/data/time_features.py
ADDED
|
@@ -0,0 +1,564 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
from typing import Any, Dict, List, Optional
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import pandas as pd
|
| 6 |
+
import scipy.fft as fft
|
| 7 |
+
import torch
|
| 8 |
+
from gluonts.time_feature import time_features_from_frequency_str
|
| 9 |
+
from gluonts.time_feature._base import (
|
| 10 |
+
day_of_month,
|
| 11 |
+
day_of_month_index,
|
| 12 |
+
day_of_week,
|
| 13 |
+
day_of_week_index,
|
| 14 |
+
day_of_year,
|
| 15 |
+
hour_of_day,
|
| 16 |
+
hour_of_day_index,
|
| 17 |
+
minute_of_hour,
|
| 18 |
+
minute_of_hour_index,
|
| 19 |
+
month_of_year,
|
| 20 |
+
month_of_year_index,
|
| 21 |
+
second_of_minute,
|
| 22 |
+
second_of_minute_index,
|
| 23 |
+
week_of_year,
|
| 24 |
+
week_of_year_index,
|
| 25 |
+
)
|
| 26 |
+
from gluonts.time_feature.holiday import (
|
| 27 |
+
BLACK_FRIDAY,
|
| 28 |
+
CHRISTMAS_DAY,
|
| 29 |
+
CHRISTMAS_EVE,
|
| 30 |
+
CYBER_MONDAY,
|
| 31 |
+
EASTER_MONDAY,
|
| 32 |
+
EASTER_SUNDAY,
|
| 33 |
+
GOOD_FRIDAY,
|
| 34 |
+
INDEPENDENCE_DAY,
|
| 35 |
+
LABOR_DAY,
|
| 36 |
+
MEMORIAL_DAY,
|
| 37 |
+
NEW_YEARS_DAY,
|
| 38 |
+
NEW_YEARS_EVE,
|
| 39 |
+
THANKSGIVING,
|
| 40 |
+
SpecialDateFeatureSet,
|
| 41 |
+
exponential_kernel,
|
| 42 |
+
squared_exponential_kernel,
|
| 43 |
+
)
|
| 44 |
+
from gluonts.time_feature.seasonality import get_seasonality
|
| 45 |
+
from scipy.signal import find_peaks
|
| 46 |
+
|
| 47 |
+
from src.data.constants import BASE_END_DATE, BASE_START_DATE
|
| 48 |
+
from src.data.frequency import (
|
| 49 |
+
Frequency,
|
| 50 |
+
validate_frequency_safety,
|
| 51 |
+
)
|
| 52 |
+
from src.utils.utils import device
|
| 53 |
+
|
| 54 |
+
# Configure logging
|
| 55 |
+
logging.basicConfig(
|
| 56 |
+
level=logging.DEBUG, format="%(asctime)s - %(levelname)s - %(message)s"
|
| 57 |
+
)
|
| 58 |
+
logger = logging.getLogger(__name__)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
# Enhanced feature sets for different frequencies
|
| 62 |
+
ENHANCED_TIME_FEATURES = {
|
| 63 |
+
# High-frequency features (seconds, minutes)
|
| 64 |
+
"high_freq": {
|
| 65 |
+
"normalized": [
|
| 66 |
+
second_of_minute,
|
| 67 |
+
minute_of_hour,
|
| 68 |
+
hour_of_day,
|
| 69 |
+
day_of_week,
|
| 70 |
+
day_of_month,
|
| 71 |
+
],
|
| 72 |
+
"index": [
|
| 73 |
+
second_of_minute_index,
|
| 74 |
+
minute_of_hour_index,
|
| 75 |
+
hour_of_day_index,
|
| 76 |
+
day_of_week_index,
|
| 77 |
+
],
|
| 78 |
+
},
|
| 79 |
+
# Medium-frequency features (hourly, daily)
|
| 80 |
+
"medium_freq": {
|
| 81 |
+
"normalized": [
|
| 82 |
+
hour_of_day,
|
| 83 |
+
day_of_week,
|
| 84 |
+
day_of_month,
|
| 85 |
+
day_of_year,
|
| 86 |
+
month_of_year,
|
| 87 |
+
],
|
| 88 |
+
"index": [
|
| 89 |
+
hour_of_day_index,
|
| 90 |
+
day_of_week_index,
|
| 91 |
+
day_of_month_index,
|
| 92 |
+
week_of_year_index,
|
| 93 |
+
],
|
| 94 |
+
},
|
| 95 |
+
# Low-frequency features (weekly, monthly)
|
| 96 |
+
"low_freq": {
|
| 97 |
+
"normalized": [day_of_week, day_of_month, month_of_year, week_of_year],
|
| 98 |
+
"index": [day_of_week_index, month_of_year_index, week_of_year_index],
|
| 99 |
+
},
|
| 100 |
+
}
|
| 101 |
+
|
| 102 |
+
# Holiday features for different markets/regions
|
| 103 |
+
HOLIDAY_FEATURE_SETS = {
|
| 104 |
+
"us_business": [
|
| 105 |
+
NEW_YEARS_DAY,
|
| 106 |
+
MEMORIAL_DAY,
|
| 107 |
+
INDEPENDENCE_DAY,
|
| 108 |
+
LABOR_DAY,
|
| 109 |
+
THANKSGIVING,
|
| 110 |
+
CHRISTMAS_EVE,
|
| 111 |
+
CHRISTMAS_DAY,
|
| 112 |
+
NEW_YEARS_EVE,
|
| 113 |
+
],
|
| 114 |
+
"us_retail": [
|
| 115 |
+
NEW_YEARS_DAY,
|
| 116 |
+
EASTER_SUNDAY,
|
| 117 |
+
MEMORIAL_DAY,
|
| 118 |
+
INDEPENDENCE_DAY,
|
| 119 |
+
LABOR_DAY,
|
| 120 |
+
THANKSGIVING,
|
| 121 |
+
BLACK_FRIDAY,
|
| 122 |
+
CYBER_MONDAY,
|
| 123 |
+
CHRISTMAS_EVE,
|
| 124 |
+
CHRISTMAS_DAY,
|
| 125 |
+
NEW_YEARS_EVE,
|
| 126 |
+
],
|
| 127 |
+
"christian": [
|
| 128 |
+
NEW_YEARS_DAY,
|
| 129 |
+
GOOD_FRIDAY,
|
| 130 |
+
EASTER_SUNDAY,
|
| 131 |
+
EASTER_MONDAY,
|
| 132 |
+
CHRISTMAS_EVE,
|
| 133 |
+
CHRISTMAS_DAY,
|
| 134 |
+
NEW_YEARS_EVE,
|
| 135 |
+
],
|
| 136 |
+
}
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
class TimeFeatureGenerator:
|
| 140 |
+
"""
|
| 141 |
+
Enhanced time feature generator that leverages full GluonTS capabilities.
|
| 142 |
+
"""
|
| 143 |
+
|
| 144 |
+
def __init__(
|
| 145 |
+
self,
|
| 146 |
+
use_enhanced_features: bool = True,
|
| 147 |
+
use_holiday_features: bool = True,
|
| 148 |
+
holiday_set: str = "us_business",
|
| 149 |
+
holiday_kernel: str = "exponential",
|
| 150 |
+
holiday_kernel_alpha: float = 1.0,
|
| 151 |
+
use_index_features: bool = True,
|
| 152 |
+
k_max: int = 15,
|
| 153 |
+
include_seasonality_info: bool = True,
|
| 154 |
+
use_auto_seasonality: bool = False, # New parameter
|
| 155 |
+
max_seasonal_periods: int = 3, # New parameter
|
| 156 |
+
):
|
| 157 |
+
"""
|
| 158 |
+
Initialize enhanced time feature generator.
|
| 159 |
+
|
| 160 |
+
Parameters
|
| 161 |
+
----------
|
| 162 |
+
use_enhanced_features : bool
|
| 163 |
+
Whether to use frequency-specific enhanced features
|
| 164 |
+
use_holiday_features : bool
|
| 165 |
+
Whether to include holiday features
|
| 166 |
+
holiday_set : str
|
| 167 |
+
Which holiday set to use ('us_business', 'us_retail', 'christian')
|
| 168 |
+
holiday_kernel : str
|
| 169 |
+
Holiday kernel type ('indicator', 'exponential', 'squared_exponential')
|
| 170 |
+
holiday_kernel_alpha : float
|
| 171 |
+
Kernel parameter for exponential kernels
|
| 172 |
+
use_index_features : bool
|
| 173 |
+
Whether to include index-based features alongside normalized ones
|
| 174 |
+
k_max : int
|
| 175 |
+
Maximum number of time features to pad to
|
| 176 |
+
include_seasonality_info : bool
|
| 177 |
+
Whether to include seasonality information as features
|
| 178 |
+
use_auto_seasonality : bool
|
| 179 |
+
Whether to use automatic FFT-based seasonality detection
|
| 180 |
+
max_seasonal_periods : int
|
| 181 |
+
Maximum number of seasonal periods to detect automatically
|
| 182 |
+
"""
|
| 183 |
+
self.use_enhanced_features = use_enhanced_features
|
| 184 |
+
self.use_holiday_features = use_holiday_features
|
| 185 |
+
self.holiday_set = holiday_set
|
| 186 |
+
self.use_index_features = use_index_features
|
| 187 |
+
self.k_max = k_max
|
| 188 |
+
self.include_seasonality_info = include_seasonality_info
|
| 189 |
+
self.use_auto_seasonality = use_auto_seasonality
|
| 190 |
+
self.max_seasonal_periods = max_seasonal_periods
|
| 191 |
+
|
| 192 |
+
# Initialize holiday feature set
|
| 193 |
+
self.holiday_feature_set = None
|
| 194 |
+
if use_holiday_features and holiday_set in HOLIDAY_FEATURE_SETS:
|
| 195 |
+
kernel_func = self._get_holiday_kernel(holiday_kernel, holiday_kernel_alpha)
|
| 196 |
+
self.holiday_feature_set = SpecialDateFeatureSet(
|
| 197 |
+
HOLIDAY_FEATURE_SETS[holiday_set], kernel_func
|
| 198 |
+
)
|
| 199 |
+
|
| 200 |
+
def _get_holiday_kernel(self, kernel_type: str, alpha: float):
|
| 201 |
+
"""Get holiday kernel function."""
|
| 202 |
+
if kernel_type == "exponential":
|
| 203 |
+
return exponential_kernel(alpha)
|
| 204 |
+
elif kernel_type == "squared_exponential":
|
| 205 |
+
return squared_exponential_kernel(alpha)
|
| 206 |
+
else:
|
| 207 |
+
# Default indicator kernel
|
| 208 |
+
return lambda x: float(x == 0)
|
| 209 |
+
|
| 210 |
+
def _get_feature_category(self, freq_str: str) -> str:
|
| 211 |
+
"""Determine feature category based on frequency."""
|
| 212 |
+
if freq_str in ["s", "1min", "5min", "10min", "15min"]:
|
| 213 |
+
return "high_freq"
|
| 214 |
+
elif freq_str in ["h", "D"]:
|
| 215 |
+
return "medium_freq"
|
| 216 |
+
else:
|
| 217 |
+
return "low_freq"
|
| 218 |
+
|
| 219 |
+
def _compute_enhanced_features(
|
| 220 |
+
self, period_index: pd.PeriodIndex, freq_str: str
|
| 221 |
+
) -> np.ndarray:
|
| 222 |
+
"""Compute enhanced time features based on frequency."""
|
| 223 |
+
if not self.use_enhanced_features:
|
| 224 |
+
return np.array([]).reshape(len(period_index), 0)
|
| 225 |
+
|
| 226 |
+
category = self._get_feature_category(freq_str)
|
| 227 |
+
feature_config = ENHANCED_TIME_FEATURES[category]
|
| 228 |
+
|
| 229 |
+
features = []
|
| 230 |
+
|
| 231 |
+
# Add normalized features
|
| 232 |
+
for feat_func in feature_config["normalized"]:
|
| 233 |
+
try:
|
| 234 |
+
feat_values = feat_func(period_index)
|
| 235 |
+
features.append(feat_values)
|
| 236 |
+
except Exception:
|
| 237 |
+
continue
|
| 238 |
+
|
| 239 |
+
# Add index features if enabled
|
| 240 |
+
if self.use_index_features:
|
| 241 |
+
for feat_func in feature_config["index"]:
|
| 242 |
+
try:
|
| 243 |
+
feat_values = feat_func(period_index)
|
| 244 |
+
# Normalize index features to [0, 1] range
|
| 245 |
+
if feat_values.max() > 0:
|
| 246 |
+
feat_values = feat_values / feat_values.max()
|
| 247 |
+
features.append(feat_values)
|
| 248 |
+
except Exception:
|
| 249 |
+
continue
|
| 250 |
+
|
| 251 |
+
if features:
|
| 252 |
+
return np.stack(features, axis=-1)
|
| 253 |
+
else:
|
| 254 |
+
return np.array([]).reshape(len(period_index), 0)
|
| 255 |
+
|
| 256 |
+
def _compute_holiday_features(self, date_range: pd.DatetimeIndex) -> np.ndarray:
|
| 257 |
+
"""Compute holiday features."""
|
| 258 |
+
if not self.use_holiday_features or self.holiday_feature_set is None:
|
| 259 |
+
return np.array([]).reshape(len(date_range), 0)
|
| 260 |
+
|
| 261 |
+
try:
|
| 262 |
+
holiday_features = self.holiday_feature_set(date_range)
|
| 263 |
+
return holiday_features.T # Transpose to get [time, features] shape
|
| 264 |
+
except Exception:
|
| 265 |
+
return np.array([]).reshape(len(date_range), 0)
|
| 266 |
+
|
| 267 |
+
def _detect_auto_seasonality(self, time_series_values: np.ndarray) -> list:
|
| 268 |
+
"""
|
| 269 |
+
Detect seasonal periods automatically using FFT analysis.
|
| 270 |
+
|
| 271 |
+
Parameters
|
| 272 |
+
----------
|
| 273 |
+
time_series_values : np.ndarray
|
| 274 |
+
Time series values for seasonality detection
|
| 275 |
+
|
| 276 |
+
Returns
|
| 277 |
+
-------
|
| 278 |
+
list
|
| 279 |
+
List of detected seasonal periods
|
| 280 |
+
"""
|
| 281 |
+
if not self.use_auto_seasonality or len(time_series_values) < 10:
|
| 282 |
+
return []
|
| 283 |
+
|
| 284 |
+
try:
|
| 285 |
+
# Remove NaN values
|
| 286 |
+
values = time_series_values[~np.isnan(time_series_values)]
|
| 287 |
+
if len(values) < 10:
|
| 288 |
+
return []
|
| 289 |
+
|
| 290 |
+
# Simple linear detrending
|
| 291 |
+
x = np.arange(len(values))
|
| 292 |
+
coeffs = np.polyfit(x, values, 1)
|
| 293 |
+
trend = np.polyval(coeffs, x)
|
| 294 |
+
detrended = values - trend
|
| 295 |
+
|
| 296 |
+
# Apply Hann window to reduce spectral leakage
|
| 297 |
+
window = np.hanning(len(detrended))
|
| 298 |
+
windowed = detrended * window
|
| 299 |
+
|
| 300 |
+
# Zero padding for better frequency resolution
|
| 301 |
+
padded_length = len(windowed) * 2
|
| 302 |
+
padded_values = np.zeros(padded_length)
|
| 303 |
+
padded_values[: len(windowed)] = windowed
|
| 304 |
+
|
| 305 |
+
# Compute FFT
|
| 306 |
+
fft_values = fft.rfft(padded_values)
|
| 307 |
+
fft_magnitudes = np.abs(fft_values)
|
| 308 |
+
freqs = np.fft.rfftfreq(padded_length)
|
| 309 |
+
|
| 310 |
+
# Exclude DC component
|
| 311 |
+
fft_magnitudes[0] = 0.0
|
| 312 |
+
|
| 313 |
+
# Find peaks with threshold (5% of max magnitude)
|
| 314 |
+
threshold = 0.05 * np.max(fft_magnitudes)
|
| 315 |
+
peak_indices, _ = find_peaks(fft_magnitudes, height=threshold)
|
| 316 |
+
|
| 317 |
+
if len(peak_indices) == 0:
|
| 318 |
+
return []
|
| 319 |
+
|
| 320 |
+
# Sort by magnitude and take top periods
|
| 321 |
+
sorted_indices = peak_indices[
|
| 322 |
+
np.argsort(fft_magnitudes[peak_indices])[::-1]
|
| 323 |
+
]
|
| 324 |
+
top_indices = sorted_indices[: self.max_seasonal_periods]
|
| 325 |
+
|
| 326 |
+
# Convert frequencies to periods
|
| 327 |
+
periods = []
|
| 328 |
+
for idx in top_indices:
|
| 329 |
+
if freqs[idx] > 0:
|
| 330 |
+
period = 1.0 / freqs[idx]
|
| 331 |
+
# Scale back to original length and round
|
| 332 |
+
period = round(period / 2) # Account for zero padding
|
| 333 |
+
if 2 <= period <= len(values) // 2: # Reasonable period range
|
| 334 |
+
periods.append(period)
|
| 335 |
+
|
| 336 |
+
return list(set(periods)) # Remove duplicates
|
| 337 |
+
|
| 338 |
+
except Exception:
|
| 339 |
+
return []
|
| 340 |
+
|
| 341 |
+
def _compute_seasonality_features(
|
| 342 |
+
self,
|
| 343 |
+
period_index: pd.PeriodIndex,
|
| 344 |
+
freq_str: str,
|
| 345 |
+
time_series_values: np.ndarray = None,
|
| 346 |
+
) -> np.ndarray:
|
| 347 |
+
"""Compute seasonality-aware features."""
|
| 348 |
+
if not self.include_seasonality_info:
|
| 349 |
+
return np.array([]).reshape(len(period_index), 0)
|
| 350 |
+
|
| 351 |
+
all_seasonal_features = []
|
| 352 |
+
|
| 353 |
+
# Original frequency-based seasonality
|
| 354 |
+
try:
|
| 355 |
+
seasonality = get_seasonality(freq_str)
|
| 356 |
+
if seasonality > 1:
|
| 357 |
+
positions = np.arange(len(period_index))
|
| 358 |
+
sin_feat = np.sin(2 * np.pi * positions / seasonality)
|
| 359 |
+
cos_feat = np.cos(2 * np.pi * positions / seasonality)
|
| 360 |
+
all_seasonal_features.extend([sin_feat, cos_feat])
|
| 361 |
+
except Exception:
|
| 362 |
+
pass
|
| 363 |
+
|
| 364 |
+
# Automatic seasonality detection
|
| 365 |
+
if self.use_auto_seasonality and time_series_values is not None:
|
| 366 |
+
auto_periods = self._detect_auto_seasonality(time_series_values)
|
| 367 |
+
for period in auto_periods:
|
| 368 |
+
try:
|
| 369 |
+
positions = np.arange(len(period_index))
|
| 370 |
+
sin_feat = np.sin(2 * np.pi * positions / period)
|
| 371 |
+
cos_feat = np.cos(2 * np.pi * positions / period)
|
| 372 |
+
all_seasonal_features.extend([sin_feat, cos_feat])
|
| 373 |
+
except Exception:
|
| 374 |
+
continue
|
| 375 |
+
|
| 376 |
+
if all_seasonal_features:
|
| 377 |
+
return np.stack(all_seasonal_features, axis=-1)
|
| 378 |
+
else:
|
| 379 |
+
return np.array([]).reshape(len(period_index), 0)
|
| 380 |
+
|
| 381 |
+
def compute_features(
|
| 382 |
+
self,
|
| 383 |
+
period_index: pd.PeriodIndex,
|
| 384 |
+
date_range: pd.DatetimeIndex,
|
| 385 |
+
freq_str: str,
|
| 386 |
+
time_series_values: np.ndarray = None,
|
| 387 |
+
) -> np.ndarray:
|
| 388 |
+
"""
|
| 389 |
+
Compute all time features for given period index.
|
| 390 |
+
|
| 391 |
+
Parameters
|
| 392 |
+
----------
|
| 393 |
+
period_index : pd.PeriodIndex
|
| 394 |
+
Period index for computing features
|
| 395 |
+
date_range : pd.DatetimeIndex
|
| 396 |
+
Corresponding datetime index for holiday features
|
| 397 |
+
freq_str : str
|
| 398 |
+
Frequency string
|
| 399 |
+
time_series_values : np.ndarray, optional
|
| 400 |
+
Time series values for automatic seasonality detection
|
| 401 |
+
|
| 402 |
+
Returns
|
| 403 |
+
-------
|
| 404 |
+
np.ndarray
|
| 405 |
+
Time features array of shape [time_steps, num_features]
|
| 406 |
+
"""
|
| 407 |
+
all_features = []
|
| 408 |
+
|
| 409 |
+
# Standard GluonTS features
|
| 410 |
+
try:
|
| 411 |
+
standard_features = time_features_from_frequency_str(freq_str)
|
| 412 |
+
if standard_features:
|
| 413 |
+
std_feat = np.stack(
|
| 414 |
+
[feat(period_index) for feat in standard_features], axis=-1
|
| 415 |
+
)
|
| 416 |
+
all_features.append(std_feat)
|
| 417 |
+
except Exception:
|
| 418 |
+
pass
|
| 419 |
+
|
| 420 |
+
# Enhanced features
|
| 421 |
+
enhanced_feat = self._compute_enhanced_features(period_index, freq_str)
|
| 422 |
+
if enhanced_feat.shape[1] > 0:
|
| 423 |
+
all_features.append(enhanced_feat)
|
| 424 |
+
|
| 425 |
+
# Holiday features
|
| 426 |
+
holiday_feat = self._compute_holiday_features(date_range)
|
| 427 |
+
if holiday_feat.shape[1] > 0:
|
| 428 |
+
all_features.append(holiday_feat)
|
| 429 |
+
|
| 430 |
+
# Seasonality features (including auto-detected)
|
| 431 |
+
seasonality_feat = self._compute_seasonality_features(
|
| 432 |
+
period_index, freq_str, time_series_values
|
| 433 |
+
)
|
| 434 |
+
if seasonality_feat.shape[1] > 0:
|
| 435 |
+
all_features.append(seasonality_feat)
|
| 436 |
+
|
| 437 |
+
if all_features:
|
| 438 |
+
combined_features = np.concatenate(all_features, axis=-1)
|
| 439 |
+
else:
|
| 440 |
+
combined_features = np.zeros((len(period_index), 1))
|
| 441 |
+
|
| 442 |
+
return combined_features
|
| 443 |
+
|
| 444 |
+
|
| 445 |
+
def compute_batch_time_features(
|
| 446 |
+
start: List[np.datetime64],
|
| 447 |
+
history_length: int,
|
| 448 |
+
future_length: int,
|
| 449 |
+
batch_size: int,
|
| 450 |
+
frequency: List[Frequency],
|
| 451 |
+
K_max: int = 6,
|
| 452 |
+
time_feature_config: Optional[Dict[str, Any]] = None,
|
| 453 |
+
):
|
| 454 |
+
"""
|
| 455 |
+
Compute time features from start timestamps and frequency.
|
| 456 |
+
|
| 457 |
+
Parameters
|
| 458 |
+
----------
|
| 459 |
+
start : array-like, shape (batch_size,)
|
| 460 |
+
Start timestamps for each batch item.
|
| 461 |
+
history_length : int
|
| 462 |
+
Length of history sequence.
|
| 463 |
+
future_length : int
|
| 464 |
+
Length of target sequence.
|
| 465 |
+
batch_size : int
|
| 466 |
+
Batch size.
|
| 467 |
+
frequency : array-like, shape (batch_size,)
|
| 468 |
+
Frequency of the time series.
|
| 469 |
+
K_max : int, optional
|
| 470 |
+
Maximum number of time features to pad to (default: 6).
|
| 471 |
+
time_feature_config : dict, optional
|
| 472 |
+
Configuration for enhanced time features.
|
| 473 |
+
|
| 474 |
+
Returns
|
| 475 |
+
-------
|
| 476 |
+
tuple
|
| 477 |
+
(history_time_features, target_time_features) where each is a torch.Tensor
|
| 478 |
+
of shape (batch_size, length, K_max).
|
| 479 |
+
"""
|
| 480 |
+
# Initialize enhanced feature generator
|
| 481 |
+
feature_config = time_feature_config or {}
|
| 482 |
+
feature_generator = TimeFeatureGenerator(**feature_config)
|
| 483 |
+
|
| 484 |
+
# Generate timestamps and features
|
| 485 |
+
history_features_list = []
|
| 486 |
+
future_features_list = []
|
| 487 |
+
total_length = history_length + future_length
|
| 488 |
+
for i in range(batch_size):
|
| 489 |
+
frequency_i = frequency[i]
|
| 490 |
+
freq_str = frequency_i.to_pandas_freq(for_date_range=True)
|
| 491 |
+
period_freq_str = frequency_i.to_pandas_freq(for_date_range=False)
|
| 492 |
+
|
| 493 |
+
# Validate start timestamp is within safe bounds
|
| 494 |
+
start_ts = pd.Timestamp(start[i])
|
| 495 |
+
if not validate_frequency_safety(start_ts, total_length, frequency_i):
|
| 496 |
+
logger.debug(
|
| 497 |
+
f"Start date {start_ts} not safe for total_length={total_length}, frequency={frequency_i}. "
|
| 498 |
+
f"Using BASE_START_DATE instead."
|
| 499 |
+
)
|
| 500 |
+
start_ts = BASE_START_DATE
|
| 501 |
+
|
| 502 |
+
# Create history range with bounds checking
|
| 503 |
+
history_range = pd.date_range(
|
| 504 |
+
start=start_ts, periods=history_length, freq=freq_str
|
| 505 |
+
)
|
| 506 |
+
|
| 507 |
+
# Check if history range goes beyond safe bounds
|
| 508 |
+
if history_range[-1] > BASE_END_DATE:
|
| 509 |
+
safe_start = BASE_END_DATE - pd.tseries.frequencies.to_offset(freq_str) * (
|
| 510 |
+
history_length + future_length
|
| 511 |
+
)
|
| 512 |
+
if safe_start < BASE_START_DATE:
|
| 513 |
+
safe_start = BASE_START_DATE
|
| 514 |
+
history_range = pd.date_range(
|
| 515 |
+
start=safe_start, periods=history_length, freq=freq_str
|
| 516 |
+
)
|
| 517 |
+
|
| 518 |
+
future_start = history_range[-1] + pd.tseries.frequencies.to_offset(freq_str)
|
| 519 |
+
future_range = pd.date_range(
|
| 520 |
+
start=future_start, periods=future_length, freq=freq_str
|
| 521 |
+
)
|
| 522 |
+
|
| 523 |
+
# Convert to period indices
|
| 524 |
+
history_period_idx = history_range.to_period(period_freq_str)
|
| 525 |
+
future_period_idx = future_range.to_period(period_freq_str)
|
| 526 |
+
|
| 527 |
+
# Compute enhanced features
|
| 528 |
+
history_features = feature_generator.compute_features(
|
| 529 |
+
history_period_idx, history_range, freq_str
|
| 530 |
+
)
|
| 531 |
+
future_features = feature_generator.compute_features(
|
| 532 |
+
future_period_idx, future_range, freq_str
|
| 533 |
+
)
|
| 534 |
+
|
| 535 |
+
# Pad or truncate to K_max
|
| 536 |
+
history_features = _pad_or_truncate_features(history_features, K_max)
|
| 537 |
+
future_features = _pad_or_truncate_features(future_features, K_max)
|
| 538 |
+
|
| 539 |
+
history_features_list.append(history_features)
|
| 540 |
+
future_features_list.append(future_features)
|
| 541 |
+
|
| 542 |
+
# Stack into batch tensors
|
| 543 |
+
history_time_features = np.stack(history_features_list, axis=0)
|
| 544 |
+
future_time_features = np.stack(future_features_list, axis=0)
|
| 545 |
+
|
| 546 |
+
return (
|
| 547 |
+
torch.from_numpy(history_time_features).float().to(device),
|
| 548 |
+
torch.from_numpy(future_time_features).float().to(device),
|
| 549 |
+
)
|
| 550 |
+
|
| 551 |
+
|
| 552 |
+
def _pad_or_truncate_features(features: np.ndarray, K_max: int) -> np.ndarray:
|
| 553 |
+
"""Pad with zeros or truncate features to K_max dimensions."""
|
| 554 |
+
seq_len, num_features = features.shape
|
| 555 |
+
|
| 556 |
+
if num_features < K_max:
|
| 557 |
+
# Pad with zeros
|
| 558 |
+
padding = np.zeros((seq_len, K_max - num_features))
|
| 559 |
+
features = np.concatenate([features, padding], axis=-1)
|
| 560 |
+
elif num_features > K_max:
|
| 561 |
+
# Truncate to K_max (keep most important features first)
|
| 562 |
+
features = features[:, :K_max]
|
| 563 |
+
|
| 564 |
+
return features
|
src/data/utils.py
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import random
|
| 2 |
+
from typing import Optional, Tuple, Union
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def sample_future_length(
|
| 6 |
+
range: Union[Tuple[int, int], str] = "gift_eval",
|
| 7 |
+
total_length: Optional[int] = None,
|
| 8 |
+
) -> int:
|
| 9 |
+
"""
|
| 10 |
+
Sample a forecast length.
|
| 11 |
+
|
| 12 |
+
- If `range` is a tuple, uniformly sample in [min, max]. When `total_length` is
|
| 13 |
+
provided, enforce a cap so the result is at most floor(0.45 * total_length).
|
| 14 |
+
- If `range` is "gift_eval", sample from a pre-defined weighted set. When
|
| 15 |
+
`total_length` is provided, filter out candidates greater than
|
| 16 |
+
floor(0.45 * total_length) before sampling.
|
| 17 |
+
"""
|
| 18 |
+
# Compute the cap when total_length is provided
|
| 19 |
+
cap: Optional[int] = None
|
| 20 |
+
if total_length is not None:
|
| 21 |
+
cap = max(1, int(0.45 * int(total_length)))
|
| 22 |
+
|
| 23 |
+
if isinstance(range, tuple):
|
| 24 |
+
min_len, max_len = range
|
| 25 |
+
if cap is not None:
|
| 26 |
+
effective_max_len = min(max_len, cap)
|
| 27 |
+
# Ensure valid bounds
|
| 28 |
+
if min_len > effective_max_len:
|
| 29 |
+
return effective_max_len
|
| 30 |
+
return random.randint(min_len, effective_max_len)
|
| 31 |
+
return random.randint(min_len, max_len)
|
| 32 |
+
elif range == "gift_eval":
|
| 33 |
+
# Gift eval forecast lengths with their frequencies
|
| 34 |
+
GIFT_EVAL_FORECAST_LENGTHS = {
|
| 35 |
+
48: 5,
|
| 36 |
+
720: 38,
|
| 37 |
+
480: 38,
|
| 38 |
+
30: 3,
|
| 39 |
+
300: 16,
|
| 40 |
+
8: 2,
|
| 41 |
+
120: 3,
|
| 42 |
+
450: 8,
|
| 43 |
+
80: 8,
|
| 44 |
+
12: 2,
|
| 45 |
+
900: 10,
|
| 46 |
+
180: 3,
|
| 47 |
+
600: 10,
|
| 48 |
+
60: 3,
|
| 49 |
+
210: 3,
|
| 50 |
+
195: 3,
|
| 51 |
+
140: 3,
|
| 52 |
+
130: 3,
|
| 53 |
+
14: 1,
|
| 54 |
+
18: 1,
|
| 55 |
+
13: 1,
|
| 56 |
+
6: 1,
|
| 57 |
+
}
|
| 58 |
+
|
| 59 |
+
lengths = list(GIFT_EVAL_FORECAST_LENGTHS.keys())
|
| 60 |
+
weights = list(GIFT_EVAL_FORECAST_LENGTHS.values())
|
| 61 |
+
|
| 62 |
+
if cap is not None:
|
| 63 |
+
filtered = [
|
| 64 |
+
(length_candidate, weight)
|
| 65 |
+
for length_candidate, weight in zip(lengths, weights)
|
| 66 |
+
if length_candidate <= cap
|
| 67 |
+
]
|
| 68 |
+
if filtered:
|
| 69 |
+
lengths, weights = zip(*filtered)
|
| 70 |
+
lengths = list(lengths)
|
| 71 |
+
weights = list(weights)
|
| 72 |
+
|
| 73 |
+
return random.choices(lengths, weights=weights)[0]
|
| 74 |
+
else:
|
| 75 |
+
raise ValueError(f"Invalid range: {range}")
|
src/gift_eval/__init__.py
ADDED
|
File without changes
|
src/gift_eval/aggregate_results.py
ADDED
|
@@ -0,0 +1,160 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import glob
|
| 3 |
+
import logging
|
| 4 |
+
from pathlib import Path
|
| 5 |
+
from typing import List
|
| 6 |
+
|
| 7 |
+
import pandas as pd
|
| 8 |
+
|
| 9 |
+
from src.gift_eval.constants import (
|
| 10 |
+
ALL_DATASETS,
|
| 11 |
+
DATASET_PROPERTIES,
|
| 12 |
+
MED_LONG_DATASETS,
|
| 13 |
+
PRETTY_NAMES,
|
| 14 |
+
)
|
| 15 |
+
|
| 16 |
+
logger = logging.getLogger(__name__)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def get_all_datasets_full_name() -> List[str]:
|
| 20 |
+
"""Get all possible dataset full names for validation."""
|
| 21 |
+
terms = ["short", "medium", "long"]
|
| 22 |
+
datasets_full_names: List[str] = []
|
| 23 |
+
|
| 24 |
+
for name in ALL_DATASETS:
|
| 25 |
+
for term in terms:
|
| 26 |
+
if term in ["medium", "long"] and name not in MED_LONG_DATASETS.split():
|
| 27 |
+
continue
|
| 28 |
+
|
| 29 |
+
if "/" in name:
|
| 30 |
+
ds_key, ds_freq = name.split("/")
|
| 31 |
+
ds_key = ds_key.lower()
|
| 32 |
+
ds_key = PRETTY_NAMES.get(ds_key, ds_key)
|
| 33 |
+
else:
|
| 34 |
+
ds_key = name.lower()
|
| 35 |
+
ds_key = PRETTY_NAMES.get(ds_key, ds_key)
|
| 36 |
+
ds_freq = DATASET_PROPERTIES[ds_key]["frequency"]
|
| 37 |
+
|
| 38 |
+
datasets_full_names.append(f"{ds_key}/{ds_freq}/{term}")
|
| 39 |
+
|
| 40 |
+
return datasets_full_names
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def aggregate_results(
|
| 44 |
+
result_root_dir: str | Path,
|
| 45 |
+
) -> pd.DataFrame | None:
|
| 46 |
+
"""Aggregate results from multiple CSV files.
|
| 47 |
+
|
| 48 |
+
Returns the combined dataframe. Optionally saves to
|
| 49 |
+
<result_root_dir>/all_results.csv
|
| 50 |
+
"""
|
| 51 |
+
result_root_dir = Path(result_root_dir)
|
| 52 |
+
|
| 53 |
+
logger.info(f"Aggregating results in: {result_root_dir}")
|
| 54 |
+
|
| 55 |
+
# Find all CSV result files under the provided root directory
|
| 56 |
+
# Results are written per-dataset as <result_root_dir>/<dataset_name>/results.csv
|
| 57 |
+
result_files = glob.glob(f"{result_root_dir}/**/results.csv", recursive=True)
|
| 58 |
+
|
| 59 |
+
if not result_files:
|
| 60 |
+
logger.error("No result files found!")
|
| 61 |
+
return None
|
| 62 |
+
|
| 63 |
+
# Initialize empty list to store dataframes
|
| 64 |
+
dataframes: List[pd.DataFrame] = []
|
| 65 |
+
|
| 66 |
+
# Read and combine all CSV files
|
| 67 |
+
for file in result_files:
|
| 68 |
+
try:
|
| 69 |
+
df = pd.read_csv(file)
|
| 70 |
+
if len(df) > 0:
|
| 71 |
+
dataframes.append(df)
|
| 72 |
+
else:
|
| 73 |
+
logger.warning(f"Empty file: {file}")
|
| 74 |
+
except pd.errors.EmptyDataError:
|
| 75 |
+
logger.warning(f"Skipping empty file: {file}")
|
| 76 |
+
except Exception as e:
|
| 77 |
+
logger.error(f"Error reading {file}: {str(e)}")
|
| 78 |
+
|
| 79 |
+
if dataframes:
|
| 80 |
+
# Combine all dataframes and sort by dataset
|
| 81 |
+
combined_df = pd.concat(dataframes, ignore_index=True).sort_values("dataset")
|
| 82 |
+
|
| 83 |
+
# Check for duplicates
|
| 84 |
+
if len(combined_df) != len(set(combined_df.dataset)):
|
| 85 |
+
duplicate_datasets = combined_df.dataset[
|
| 86 |
+
combined_df.dataset.duplicated()
|
| 87 |
+
].tolist()
|
| 88 |
+
logger.warning(f"Warning: Duplicate datasets found: {duplicate_datasets}")
|
| 89 |
+
# Remove duplicates, keeping the first occurrence
|
| 90 |
+
combined_df = combined_df.drop_duplicates(subset=["dataset"], keep="first")
|
| 91 |
+
logger.info(
|
| 92 |
+
f"Removed duplicates, {len(combined_df)} unique datasets remaining"
|
| 93 |
+
)
|
| 94 |
+
|
| 95 |
+
logger.info(f"Combined results: {len(combined_df)} datasets")
|
| 96 |
+
else:
|
| 97 |
+
logger.warning("No valid CSV files found to combine")
|
| 98 |
+
return None
|
| 99 |
+
|
| 100 |
+
# Get all expected datasets and compare with completed ones
|
| 101 |
+
all_datasets_full_name = get_all_datasets_full_name()
|
| 102 |
+
completed_experiments = combined_df.dataset.tolist()
|
| 103 |
+
|
| 104 |
+
completed_experiments_clean = [
|
| 105 |
+
exp for exp in completed_experiments if exp in all_datasets_full_name
|
| 106 |
+
]
|
| 107 |
+
missing_or_failed_experiments = [
|
| 108 |
+
exp for exp in all_datasets_full_name if exp not in completed_experiments_clean
|
| 109 |
+
]
|
| 110 |
+
|
| 111 |
+
logger.info("=== EXPERIMENT SUMMARY ===")
|
| 112 |
+
logger.info(f"Total expected datasets: {len(all_datasets_full_name)}")
|
| 113 |
+
logger.info(f"Completed experiments: {len(completed_experiments_clean)}")
|
| 114 |
+
logger.info(f"Missing/failed experiments: {len(missing_or_failed_experiments)}")
|
| 115 |
+
|
| 116 |
+
logger.info("Completed experiments:")
|
| 117 |
+
for i, exp in enumerate(completed_experiments_clean):
|
| 118 |
+
logger.info(f" {i + 1:3d}: {exp}")
|
| 119 |
+
|
| 120 |
+
if missing_or_failed_experiments:
|
| 121 |
+
logger.info("Missing or failed experiments:")
|
| 122 |
+
for i, exp in enumerate(missing_or_failed_experiments):
|
| 123 |
+
logger.info(f" {i + 1:3d}: {exp}")
|
| 124 |
+
|
| 125 |
+
# Calculate completion percentage
|
| 126 |
+
completion_rate = (
|
| 127 |
+
len(completed_experiments_clean) / len(all_datasets_full_name) * 100
|
| 128 |
+
)
|
| 129 |
+
logger.info(f"Completion rate: {completion_rate:.1f}%")
|
| 130 |
+
|
| 131 |
+
# Save combined results
|
| 132 |
+
output_file = result_root_dir / "all_results.csv"
|
| 133 |
+
combined_df.to_csv(output_file, index=False)
|
| 134 |
+
logger.info(f"Combined results saved to: {output_file}")
|
| 135 |
+
|
| 136 |
+
return combined_df
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
if __name__ == "__main__":
|
| 140 |
+
parser = argparse.ArgumentParser(
|
| 141 |
+
description="Aggregate GIFT-Eval results from multiple CSV files"
|
| 142 |
+
)
|
| 143 |
+
parser.add_argument(
|
| 144 |
+
"--result_root_dir",
|
| 145 |
+
type=str,
|
| 146 |
+
required=True,
|
| 147 |
+
help="Root directory containing result subdirectories",
|
| 148 |
+
)
|
| 149 |
+
|
| 150 |
+
args = parser.parse_args()
|
| 151 |
+
args.result_root_dir = Path(args.result_root_dir)
|
| 152 |
+
|
| 153 |
+
logging.basicConfig(
|
| 154 |
+
level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s"
|
| 155 |
+
)
|
| 156 |
+
logger.info(f"Searching in directory: {args.result_root_dir}")
|
| 157 |
+
|
| 158 |
+
aggregate_results(
|
| 159 |
+
result_root_dir=args.result_root_dir,
|
| 160 |
+
)
|
src/gift_eval/constants.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import logging
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
from gluonts.ev.metrics import (
|
| 6 |
+
MAE,
|
| 7 |
+
MAPE,
|
| 8 |
+
MASE,
|
| 9 |
+
MSE,
|
| 10 |
+
MSIS,
|
| 11 |
+
ND,
|
| 12 |
+
NRMSE,
|
| 13 |
+
RMSE,
|
| 14 |
+
SMAPE,
|
| 15 |
+
MeanWeightedSumQuantileLoss,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
logger = logging.getLogger(__name__)
|
| 19 |
+
|
| 20 |
+
# Environment setup
|
| 21 |
+
os.environ["CUBLAS_WORKSPACE_CONFIG"] = ":4096:8"
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
DATASET_PROPERTIES_PATH = "src/gift_eval/dataset_properties.json"
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
try:
|
| 28 |
+
with open(DATASET_PROPERTIES_PATH, "r") as f:
|
| 29 |
+
DATASET_PROPERTIES = json.load(f)
|
| 30 |
+
except Exception as e:
|
| 31 |
+
DATASET_PROPERTIES = {}
|
| 32 |
+
logger.warning(
|
| 33 |
+
f"Could not load dataset properties from {DATASET_PROPERTIES_PATH}: {e}. Domain and num_variates will fall back to defaults."
|
| 34 |
+
)
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
# Datasets
|
| 38 |
+
SHORT_DATASETS = "m4_yearly m4_quarterly m4_monthly m4_weekly m4_daily m4_hourly electricity/15T electricity/H electricity/D electricity/W solar/10T solar/H solar/D solar/W hospital covid_deaths us_births/D us_births/M us_births/W saugeenday/D saugeenday/M saugeenday/W temperature_rain_with_missing kdd_cup_2018_with_missing/H kdd_cup_2018_with_missing/D car_parts_with_missing restaurant hierarchical_sales/D hierarchical_sales/W LOOP_SEATTLE/5T LOOP_SEATTLE/H LOOP_SEATTLE/D SZ_TAXI/15T SZ_TAXI/H M_DENSE/H M_DENSE/D ett1/15T ett1/H ett1/D ett1/W ett2/15T ett2/H ett2/D ett2/W jena_weather/10T jena_weather/H jena_weather/D bitbrains_fast_storage/5T bitbrains_fast_storage/H bitbrains_rnd/5T bitbrains_rnd/H bizitobs_application bizitobs_service bizitobs_l2c/5T bizitobs_l2c/H"
|
| 39 |
+
MED_LONG_DATASETS = "electricity/15T electricity/H solar/10T solar/H kdd_cup_2018_with_missing/H LOOP_SEATTLE/5T LOOP_SEATTLE/H SZ_TAXI/15T M_DENSE/H ett1/15T ett1/H ett2/15T ett2/H jena_weather/10T jena_weather/H bitbrains_fast_storage/5T bitbrains_rnd/5T bizitobs_application bizitobs_service bizitobs_l2c/5T bizitobs_l2c/H"
|
| 40 |
+
ALL_DATASETS = list(set(SHORT_DATASETS.split() + MED_LONG_DATASETS.split()))
|
| 41 |
+
|
| 42 |
+
# Evaluation terms
|
| 43 |
+
TERMS = ["short", "medium", "long"]
|
| 44 |
+
|
| 45 |
+
# Pretty names mapping (following GIFT eval standard)
|
| 46 |
+
PRETTY_NAMES = {
|
| 47 |
+
"saugeenday": "saugeen",
|
| 48 |
+
"temperature_rain_with_missing": "temperature_rain",
|
| 49 |
+
"kdd_cup_2018_with_missing": "kdd_cup_2018",
|
| 50 |
+
"car_parts_with_missing": "car_parts",
|
| 51 |
+
}
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
METRICS = [
|
| 55 |
+
MSE(forecast_type="mean"),
|
| 56 |
+
MSE(forecast_type=0.5),
|
| 57 |
+
MAE(),
|
| 58 |
+
MASE(),
|
| 59 |
+
MAPE(),
|
| 60 |
+
SMAPE(),
|
| 61 |
+
MSIS(),
|
| 62 |
+
RMSE(),
|
| 63 |
+
NRMSE(),
|
| 64 |
+
ND(),
|
| 65 |
+
MeanWeightedSumQuantileLoss(
|
| 66 |
+
quantile_levels=[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]
|
| 67 |
+
),
|
| 68 |
+
]
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
STANDARD_METRIC_NAMES = [
|
| 72 |
+
"MSE[mean]",
|
| 73 |
+
"MSE[0.5]",
|
| 74 |
+
"MAE[0.5]",
|
| 75 |
+
"MASE[0.5]",
|
| 76 |
+
"MAPE[0.5]",
|
| 77 |
+
"sMAPE[0.5]",
|
| 78 |
+
"MSIS",
|
| 79 |
+
"RMSE[mean]",
|
| 80 |
+
"NRMSE[mean]",
|
| 81 |
+
"ND[0.5]",
|
| 82 |
+
"mean_weighted_sum_quantile_loss",
|
| 83 |
+
]
|
src/gift_eval/data.py
ADDED
|
@@ -0,0 +1,234 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023, Salesforce, Inc.
|
| 2 |
+
# SPDX-License-Identifier: Apache-2
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
|
| 16 |
+
import math
|
| 17 |
+
from collections.abc import Iterable, Iterator
|
| 18 |
+
from enum import Enum
|
| 19 |
+
from functools import cached_property
|
| 20 |
+
from pathlib import Path
|
| 21 |
+
from typing import Optional
|
| 22 |
+
|
| 23 |
+
import datasets
|
| 24 |
+
import pyarrow.compute as pc
|
| 25 |
+
from gluonts.dataset import DataEntry
|
| 26 |
+
from gluonts.dataset.common import ProcessDataEntry
|
| 27 |
+
from gluonts.dataset.split import TestData, TrainingDataset, split
|
| 28 |
+
from gluonts.itertools import Map
|
| 29 |
+
from gluonts.time_feature import norm_freq_str
|
| 30 |
+
from gluonts.transform import Transformation
|
| 31 |
+
from pandas.tseries.frequencies import to_offset
|
| 32 |
+
from toolz import compose
|
| 33 |
+
|
| 34 |
+
TEST_SPLIT = 0.1
|
| 35 |
+
MAX_WINDOW = 20
|
| 36 |
+
|
| 37 |
+
M4_PRED_LENGTH_MAP = {
|
| 38 |
+
"A": 6,
|
| 39 |
+
"Q": 8,
|
| 40 |
+
"M": 18,
|
| 41 |
+
"W": 13,
|
| 42 |
+
"D": 14,
|
| 43 |
+
"H": 48,
|
| 44 |
+
"h": 48,
|
| 45 |
+
"Y": 6,
|
| 46 |
+
}
|
| 47 |
+
|
| 48 |
+
PRED_LENGTH_MAP = {
|
| 49 |
+
"M": 12,
|
| 50 |
+
"W": 8,
|
| 51 |
+
"D": 30,
|
| 52 |
+
"H": 48,
|
| 53 |
+
"h": 48,
|
| 54 |
+
"T": 48,
|
| 55 |
+
"S": 60,
|
| 56 |
+
"s": 60,
|
| 57 |
+
"min": 48,
|
| 58 |
+
}
|
| 59 |
+
|
| 60 |
+
TFB_PRED_LENGTH_MAP = {
|
| 61 |
+
"A": 6,
|
| 62 |
+
"Y": 6,
|
| 63 |
+
"H": 48,
|
| 64 |
+
"h": 48,
|
| 65 |
+
"Q": 8,
|
| 66 |
+
"D": 14,
|
| 67 |
+
"M": 18,
|
| 68 |
+
"W": 13,
|
| 69 |
+
"U": 8,
|
| 70 |
+
"T": 8,
|
| 71 |
+
"min": 8,
|
| 72 |
+
"us": 8,
|
| 73 |
+
}
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
class Term(Enum):
|
| 77 |
+
SHORT = "short"
|
| 78 |
+
MEDIUM = "medium"
|
| 79 |
+
LONG = "long"
|
| 80 |
+
|
| 81 |
+
@property
|
| 82 |
+
def multiplier(self) -> int:
|
| 83 |
+
if self == Term.SHORT:
|
| 84 |
+
return 1
|
| 85 |
+
elif self == Term.MEDIUM:
|
| 86 |
+
return 10
|
| 87 |
+
elif self == Term.LONG:
|
| 88 |
+
return 15
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def itemize_start(data_entry: DataEntry) -> DataEntry:
|
| 92 |
+
data_entry["start"] = data_entry["start"].item()
|
| 93 |
+
return data_entry
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
class MultivariateToUnivariate(Transformation):
|
| 97 |
+
def __init__(self, field):
|
| 98 |
+
self.field = field
|
| 99 |
+
|
| 100 |
+
def __call__(
|
| 101 |
+
self, data_it: Iterable[DataEntry], is_train: bool = False
|
| 102 |
+
) -> Iterator:
|
| 103 |
+
for data_entry in data_it:
|
| 104 |
+
item_id = data_entry["item_id"]
|
| 105 |
+
val_ls = list(data_entry[self.field])
|
| 106 |
+
for id, val in enumerate(val_ls):
|
| 107 |
+
univariate_entry = data_entry.copy()
|
| 108 |
+
univariate_entry[self.field] = val
|
| 109 |
+
univariate_entry["item_id"] = item_id + "_dim" + str(id)
|
| 110 |
+
yield univariate_entry
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
class Dataset:
|
| 114 |
+
def __init__(
|
| 115 |
+
self,
|
| 116 |
+
name: str,
|
| 117 |
+
term: Term | str = Term.SHORT,
|
| 118 |
+
to_univariate: bool = False,
|
| 119 |
+
storage_path: str = None,
|
| 120 |
+
max_windows: Optional[int] = None,
|
| 121 |
+
):
|
| 122 |
+
storage_path = Path(storage_path)
|
| 123 |
+
self.hf_dataset = datasets.load_from_disk(str(storage_path / name)).with_format(
|
| 124 |
+
"numpy"
|
| 125 |
+
)
|
| 126 |
+
process = ProcessDataEntry(
|
| 127 |
+
self.freq,
|
| 128 |
+
one_dim_target=self.target_dim == 1,
|
| 129 |
+
)
|
| 130 |
+
|
| 131 |
+
self.gluonts_dataset = Map(compose(process, itemize_start), self.hf_dataset)
|
| 132 |
+
if to_univariate:
|
| 133 |
+
self.gluonts_dataset = MultivariateToUnivariate("target").apply(
|
| 134 |
+
self.gluonts_dataset
|
| 135 |
+
)
|
| 136 |
+
|
| 137 |
+
self.term = Term(term)
|
| 138 |
+
self.name = name
|
| 139 |
+
self.max_windows = max_windows if max_windows is not None else MAX_WINDOW
|
| 140 |
+
|
| 141 |
+
@cached_property
|
| 142 |
+
def prediction_length(self) -> int:
|
| 143 |
+
freq = norm_freq_str(to_offset(self.freq).name)
|
| 144 |
+
if freq.endswith("E"):
|
| 145 |
+
freq = freq[:-1]
|
| 146 |
+
pred_len = (
|
| 147 |
+
M4_PRED_LENGTH_MAP[freq] if "m4" in self.name else PRED_LENGTH_MAP[freq]
|
| 148 |
+
)
|
| 149 |
+
return self.term.multiplier * pred_len
|
| 150 |
+
|
| 151 |
+
@cached_property
|
| 152 |
+
def freq(self) -> str:
|
| 153 |
+
return self.hf_dataset[0]["freq"]
|
| 154 |
+
|
| 155 |
+
@cached_property
|
| 156 |
+
def target_dim(self) -> int:
|
| 157 |
+
return (
|
| 158 |
+
target.shape[0]
|
| 159 |
+
if len((target := self.hf_dataset[0]["target"]).shape) > 1
|
| 160 |
+
else 1
|
| 161 |
+
)
|
| 162 |
+
|
| 163 |
+
@cached_property
|
| 164 |
+
def past_feat_dynamic_real_dim(self) -> int:
|
| 165 |
+
if "past_feat_dynamic_real" not in self.hf_dataset[0]:
|
| 166 |
+
return 0
|
| 167 |
+
elif (
|
| 168 |
+
len(
|
| 169 |
+
(
|
| 170 |
+
past_feat_dynamic_real := self.hf_dataset[0][
|
| 171 |
+
"past_feat_dynamic_real"
|
| 172 |
+
]
|
| 173 |
+
).shape
|
| 174 |
+
)
|
| 175 |
+
> 1
|
| 176 |
+
):
|
| 177 |
+
return past_feat_dynamic_real.shape[0]
|
| 178 |
+
else:
|
| 179 |
+
return 1
|
| 180 |
+
|
| 181 |
+
@cached_property
|
| 182 |
+
def windows(self) -> int:
|
| 183 |
+
if "m4" in self.name:
|
| 184 |
+
return 1
|
| 185 |
+
w = math.ceil(TEST_SPLIT * self._min_series_length / self.prediction_length)
|
| 186 |
+
return min(max(1, w), self.max_windows)
|
| 187 |
+
|
| 188 |
+
@cached_property
|
| 189 |
+
def _min_series_length(self) -> int:
|
| 190 |
+
if self.hf_dataset[0]["target"].ndim > 1:
|
| 191 |
+
lengths = pc.list_value_length(
|
| 192 |
+
pc.list_flatten(
|
| 193 |
+
pc.list_slice(self.hf_dataset.data.column("target"), 0, 1)
|
| 194 |
+
)
|
| 195 |
+
)
|
| 196 |
+
else:
|
| 197 |
+
lengths = pc.list_value_length(self.hf_dataset.data.column("target"))
|
| 198 |
+
return min(lengths.to_numpy())
|
| 199 |
+
|
| 200 |
+
@cached_property
|
| 201 |
+
def sum_series_length(self) -> int:
|
| 202 |
+
if self.hf_dataset[0]["target"].ndim > 1:
|
| 203 |
+
lengths = pc.list_value_length(
|
| 204 |
+
pc.list_flatten(self.hf_dataset.data.column("target"))
|
| 205 |
+
)
|
| 206 |
+
else:
|
| 207 |
+
lengths = pc.list_value_length(self.hf_dataset.data.column("target"))
|
| 208 |
+
return sum(lengths.to_numpy())
|
| 209 |
+
|
| 210 |
+
@property
|
| 211 |
+
def training_dataset(self) -> TrainingDataset:
|
| 212 |
+
training_dataset, _ = split(
|
| 213 |
+
self.gluonts_dataset, offset=-self.prediction_length * (self.windows + 1)
|
| 214 |
+
)
|
| 215 |
+
return training_dataset
|
| 216 |
+
|
| 217 |
+
@property
|
| 218 |
+
def validation_dataset(self) -> TrainingDataset:
|
| 219 |
+
validation_dataset, _ = split(
|
| 220 |
+
self.gluonts_dataset, offset=-self.prediction_length * self.windows
|
| 221 |
+
)
|
| 222 |
+
return validation_dataset
|
| 223 |
+
|
| 224 |
+
@property
|
| 225 |
+
def test_data(self) -> TestData:
|
| 226 |
+
_, test_template = split(
|
| 227 |
+
self.gluonts_dataset, offset=-self.prediction_length * self.windows
|
| 228 |
+
)
|
| 229 |
+
test_data = test_template.generate_instances(
|
| 230 |
+
prediction_length=self.prediction_length,
|
| 231 |
+
windows=self.windows,
|
| 232 |
+
distance=self.prediction_length,
|
| 233 |
+
)
|
| 234 |
+
return test_data
|
src/gift_eval/dataset_properties.json
ADDED
|
@@ -0,0 +1,152 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"m4_yearly": {
|
| 3 |
+
"domain": "Econ/Fin",
|
| 4 |
+
"frequency": "A",
|
| 5 |
+
"num_variates": 1
|
| 6 |
+
},
|
| 7 |
+
"m4_quarterly": {
|
| 8 |
+
"domain": "Econ/Fin",
|
| 9 |
+
"frequency": "Q",
|
| 10 |
+
"num_variates": 1
|
| 11 |
+
},
|
| 12 |
+
"m4_monthly": {
|
| 13 |
+
"domain": "Econ/Fin",
|
| 14 |
+
"frequency": "M",
|
| 15 |
+
"num_variates": 1
|
| 16 |
+
},
|
| 17 |
+
"m4_weekly": {
|
| 18 |
+
"domain": "Econ/Fin",
|
| 19 |
+
"frequency": "W",
|
| 20 |
+
"num_variates": 1
|
| 21 |
+
},
|
| 22 |
+
"m4_daily": {
|
| 23 |
+
"domain": "Econ/Fin",
|
| 24 |
+
"frequency": "D",
|
| 25 |
+
"num_variates": 1
|
| 26 |
+
},
|
| 27 |
+
"m4_hourly": {
|
| 28 |
+
"domain": "Econ/Fin",
|
| 29 |
+
"frequency": "H",
|
| 30 |
+
"num_variates": 1
|
| 31 |
+
},
|
| 32 |
+
"electricity": {
|
| 33 |
+
"domain": "Energy",
|
| 34 |
+
"frequency": "W",
|
| 35 |
+
"num_variates": 1
|
| 36 |
+
},
|
| 37 |
+
"ett1": {
|
| 38 |
+
"domain": "Energy",
|
| 39 |
+
"frequency": "W",
|
| 40 |
+
"num_variates": 7
|
| 41 |
+
},
|
| 42 |
+
"ett2": {
|
| 43 |
+
"domain": "Energy",
|
| 44 |
+
"frequency": "W",
|
| 45 |
+
"num_variates": 7
|
| 46 |
+
},
|
| 47 |
+
"solar": {
|
| 48 |
+
"domain": "Energy",
|
| 49 |
+
"frequency": "W",
|
| 50 |
+
"num_variates": 1
|
| 51 |
+
},
|
| 52 |
+
"hospital": {
|
| 53 |
+
"domain": "Healthcare",
|
| 54 |
+
"frequency": "M",
|
| 55 |
+
"num_variates": 1
|
| 56 |
+
},
|
| 57 |
+
"covid_deaths": {
|
| 58 |
+
"domain": "Healthcare",
|
| 59 |
+
"frequency": "D",
|
| 60 |
+
"num_variates": 1
|
| 61 |
+
},
|
| 62 |
+
"us_births": {
|
| 63 |
+
"domain": "Healthcare",
|
| 64 |
+
"frequency": "M",
|
| 65 |
+
"num_variates": 1
|
| 66 |
+
},
|
| 67 |
+
"saugeen": {
|
| 68 |
+
"domain": "Nature",
|
| 69 |
+
"frequency": "M",
|
| 70 |
+
"num_variates": 1
|
| 71 |
+
},
|
| 72 |
+
"temperature_rain": {
|
| 73 |
+
"domain": "Nature",
|
| 74 |
+
"frequency": "D",
|
| 75 |
+
"num_variates": 1
|
| 76 |
+
},
|
| 77 |
+
"kdd_cup_2018": {
|
| 78 |
+
"domain": "Nature",
|
| 79 |
+
"frequency": "D",
|
| 80 |
+
"num_variates": 1
|
| 81 |
+
},
|
| 82 |
+
"jena_weather": {
|
| 83 |
+
"domain": "Nature",
|
| 84 |
+
"frequency": "D",
|
| 85 |
+
"num_variates": 21
|
| 86 |
+
},
|
| 87 |
+
"car_parts": {
|
| 88 |
+
"domain": "Sales",
|
| 89 |
+
"frequency": "M",
|
| 90 |
+
"num_variates": 1
|
| 91 |
+
},
|
| 92 |
+
"restaurant": {
|
| 93 |
+
"domain": "Sales",
|
| 94 |
+
"frequency": "D",
|
| 95 |
+
"num_variates": 1
|
| 96 |
+
},
|
| 97 |
+
"hierarchical_sales": {
|
| 98 |
+
"domain": "Sales",
|
| 99 |
+
"frequency": "W-WED",
|
| 100 |
+
"num_variates": 1
|
| 101 |
+
},
|
| 102 |
+
"loop_seattle": {
|
| 103 |
+
"domain": "Transport",
|
| 104 |
+
"frequency": "D",
|
| 105 |
+
"num_variates": 1
|
| 106 |
+
},
|
| 107 |
+
"sz_taxi": {
|
| 108 |
+
"domain": "Transport",
|
| 109 |
+
"frequency": "H",
|
| 110 |
+
"num_variates": 1
|
| 111 |
+
},
|
| 112 |
+
"m_dense": {
|
| 113 |
+
"domain": "Transport",
|
| 114 |
+
"frequency": "D",
|
| 115 |
+
"num_variates": 1
|
| 116 |
+
},
|
| 117 |
+
"bitbrains_fast_storage": {
|
| 118 |
+
"domain": "Web/CloudOps",
|
| 119 |
+
"frequency": "H",
|
| 120 |
+
"num_variates": 2
|
| 121 |
+
},
|
| 122 |
+
"bitbrains_rnd": {
|
| 123 |
+
"domain": "Web/CloudOps",
|
| 124 |
+
"frequency": "H",
|
| 125 |
+
"num_variates": 2
|
| 126 |
+
},
|
| 127 |
+
"bizitobs_application": {
|
| 128 |
+
"domain": "Web/CloudOps",
|
| 129 |
+
"frequency": "10S",
|
| 130 |
+
"num_variates": 2
|
| 131 |
+
},
|
| 132 |
+
"bizitobs_service": {
|
| 133 |
+
"domain": "Web/CloudOps",
|
| 134 |
+
"frequency": "10S",
|
| 135 |
+
"num_variates": 2
|
| 136 |
+
},
|
| 137 |
+
"bizitobs_l2c": {
|
| 138 |
+
"domain": "Web/CloudOps",
|
| 139 |
+
"frequency": "H",
|
| 140 |
+
"num_variates": 7
|
| 141 |
+
},
|
| 142 |
+
"dd_benchmark_short": {
|
| 143 |
+
"domain": "Web/Observability",
|
| 144 |
+
"frequency": "Short",
|
| 145 |
+
"num_variates": 32
|
| 146 |
+
},
|
| 147 |
+
"dd_benchmark_long": {
|
| 148 |
+
"domain": "Web/Observability",
|
| 149 |
+
"frequency": "Long",
|
| 150 |
+
"num_variates": 32
|
| 151 |
+
}
|
| 152 |
+
}
|
src/gift_eval/evaluate.py
ADDED
|
@@ -0,0 +1,529 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import csv
|
| 3 |
+
import logging
|
| 4 |
+
import warnings
|
| 5 |
+
from dataclasses import dataclass
|
| 6 |
+
from pathlib import Path
|
| 7 |
+
from typing import Dict, List, Optional, Tuple
|
| 8 |
+
|
| 9 |
+
import matplotlib
|
| 10 |
+
import matplotlib.pyplot as plt
|
| 11 |
+
from gluonts.model.evaluation import evaluate_model
|
| 12 |
+
from gluonts.time_feature import get_seasonality
|
| 13 |
+
from linear_operator.utils.cholesky import NumericalWarning
|
| 14 |
+
|
| 15 |
+
from src.gift_eval.constants import (
|
| 16 |
+
ALL_DATASETS,
|
| 17 |
+
DATASET_PROPERTIES,
|
| 18 |
+
MED_LONG_DATASETS,
|
| 19 |
+
METRICS,
|
| 20 |
+
PRETTY_NAMES,
|
| 21 |
+
STANDARD_METRIC_NAMES,
|
| 22 |
+
)
|
| 23 |
+
from src.gift_eval.data import Dataset
|
| 24 |
+
from src.gift_eval.model_wrapper import TimeSeriesPredictor
|
| 25 |
+
from src.plotting.gift_eval_utils import create_plots_for_dataset
|
| 26 |
+
|
| 27 |
+
logger = logging.getLogger(__name__)
|
| 28 |
+
|
| 29 |
+
# Warnings configuration
|
| 30 |
+
warnings.filterwarnings("ignore", category=NumericalWarning)
|
| 31 |
+
warnings.filterwarnings("ignore", category=FutureWarning)
|
| 32 |
+
warnings.filterwarnings("ignore", category=DeprecationWarning)
|
| 33 |
+
matplotlib.set_loglevel("WARNING")
|
| 34 |
+
logging.getLogger("matplotlib").setLevel(logging.WARNING)
|
| 35 |
+
logging.getLogger("matplotlib.font_manager").setLevel(logging.WARNING)
|
| 36 |
+
logging.getLogger("PIL").setLevel(logging.WARNING)
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
class WarningFilter(logging.Filter):
|
| 40 |
+
def __init__(self, text_to_filter: str) -> None:
|
| 41 |
+
super().__init__()
|
| 42 |
+
self.text_to_filter = text_to_filter
|
| 43 |
+
|
| 44 |
+
def filter(self, record: logging.LogRecord) -> bool:
|
| 45 |
+
return self.text_to_filter not in record.getMessage()
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
# Filter out gluonts warnings about mean predictions
|
| 49 |
+
gts_logger = logging.getLogger("gluonts.model.forecast")
|
| 50 |
+
gts_logger.addFilter(
|
| 51 |
+
WarningFilter("The mean prediction is not stored in the forecast data")
|
| 52 |
+
)
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
@dataclass
|
| 56 |
+
class DatasetMetadata:
|
| 57 |
+
full_name: str
|
| 58 |
+
key: str
|
| 59 |
+
freq: str
|
| 60 |
+
term: str
|
| 61 |
+
season_length: int
|
| 62 |
+
target_dim: int
|
| 63 |
+
to_univariate: bool
|
| 64 |
+
prediction_length: int
|
| 65 |
+
windows: int
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
@dataclass
|
| 69 |
+
class EvaluationItem:
|
| 70 |
+
dataset_metadata: DatasetMetadata
|
| 71 |
+
metrics: Dict
|
| 72 |
+
figures: List[Tuple[object, str]]
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def construct_evaluation_data(
|
| 76 |
+
dataset_name: str,
|
| 77 |
+
dataset_storage_path: str,
|
| 78 |
+
terms: List[str] = ["short", "medium", "long"],
|
| 79 |
+
max_windows: Optional[int] = None,
|
| 80 |
+
) -> List[Tuple[Dataset, DatasetMetadata]]:
|
| 81 |
+
"""Build datasets and rich metadata per term for a dataset name."""
|
| 82 |
+
sub_datasets: List[Tuple[Dataset, DatasetMetadata]] = []
|
| 83 |
+
|
| 84 |
+
if "/" in dataset_name:
|
| 85 |
+
ds_key, ds_freq = dataset_name.split("/")
|
| 86 |
+
ds_key = ds_key.lower()
|
| 87 |
+
ds_key = PRETTY_NAMES.get(ds_key, ds_key)
|
| 88 |
+
else:
|
| 89 |
+
ds_key = dataset_name.lower()
|
| 90 |
+
ds_key = PRETTY_NAMES.get(ds_key, ds_key)
|
| 91 |
+
ds_freq = DATASET_PROPERTIES[ds_key]["frequency"]
|
| 92 |
+
|
| 93 |
+
for term in terms:
|
| 94 |
+
# Skip medium/long terms for datasets that don't support them
|
| 95 |
+
if (
|
| 96 |
+
term == "medium" or term == "long"
|
| 97 |
+
) and dataset_name not in MED_LONG_DATASETS.split():
|
| 98 |
+
continue
|
| 99 |
+
|
| 100 |
+
# Probe once to determine dimensionality
|
| 101 |
+
probe_dataset = Dataset(
|
| 102 |
+
name=dataset_name,
|
| 103 |
+
term=term,
|
| 104 |
+
to_univariate=False,
|
| 105 |
+
storage_path=dataset_storage_path,
|
| 106 |
+
max_windows=max_windows,
|
| 107 |
+
)
|
| 108 |
+
|
| 109 |
+
to_univariate = probe_dataset.target_dim > 1
|
| 110 |
+
|
| 111 |
+
dataset = Dataset(
|
| 112 |
+
name=dataset_name,
|
| 113 |
+
term=term,
|
| 114 |
+
to_univariate=to_univariate,
|
| 115 |
+
storage_path=dataset_storage_path,
|
| 116 |
+
max_windows=max_windows,
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
# Compute metadata
|
| 120 |
+
season_length = get_seasonality(dataset.freq)
|
| 121 |
+
actual_freq = ds_freq if ds_freq else dataset.freq
|
| 122 |
+
metadata = DatasetMetadata(
|
| 123 |
+
full_name=f"{ds_key}/{actual_freq}/{term}",
|
| 124 |
+
key=ds_key,
|
| 125 |
+
freq=actual_freq,
|
| 126 |
+
term=term,
|
| 127 |
+
season_length=season_length,
|
| 128 |
+
target_dim=probe_dataset.target_dim,
|
| 129 |
+
to_univariate=to_univariate,
|
| 130 |
+
prediction_length=dataset.prediction_length,
|
| 131 |
+
windows=dataset.windows,
|
| 132 |
+
)
|
| 133 |
+
|
| 134 |
+
sub_datasets.append((dataset, metadata))
|
| 135 |
+
|
| 136 |
+
return sub_datasets
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
def _ensure_results_csv(csv_file_path: Path) -> None:
|
| 140 |
+
if not csv_file_path.exists():
|
| 141 |
+
csv_file_path.parent.mkdir(parents=True, exist_ok=True)
|
| 142 |
+
with open(csv_file_path, "w", newline="") as csvfile:
|
| 143 |
+
writer = csv.writer(csvfile)
|
| 144 |
+
header = (
|
| 145 |
+
["dataset", "model"]
|
| 146 |
+
+ [f"eval_metrics/{name}" for name in STANDARD_METRIC_NAMES]
|
| 147 |
+
+ [
|
| 148 |
+
"domain",
|
| 149 |
+
"num_variates",
|
| 150 |
+
]
|
| 151 |
+
)
|
| 152 |
+
writer.writerow(header)
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
def write_results_to_disk(
|
| 156 |
+
items: List[EvaluationItem],
|
| 157 |
+
dataset_name: str,
|
| 158 |
+
output_dir: Path,
|
| 159 |
+
model_name: str,
|
| 160 |
+
create_plots: bool,
|
| 161 |
+
) -> None:
|
| 162 |
+
output_dir = output_dir / dataset_name
|
| 163 |
+
output_dir.mkdir(parents=True, exist_ok=True)
|
| 164 |
+
output_csv_path = output_dir / "results.csv"
|
| 165 |
+
_ensure_results_csv(output_csv_path)
|
| 166 |
+
|
| 167 |
+
with open(output_csv_path, "a", newline="") as csvfile:
|
| 168 |
+
writer = csv.writer(csvfile)
|
| 169 |
+
for item in items:
|
| 170 |
+
md = item.dataset_metadata
|
| 171 |
+
# Extract metric values in the standard order
|
| 172 |
+
metric_values: List[Optional[float]] = []
|
| 173 |
+
for metric_name in STANDARD_METRIC_NAMES:
|
| 174 |
+
value = item.metrics.get(metric_name, None)
|
| 175 |
+
if value is None:
|
| 176 |
+
metric_values.append(None)
|
| 177 |
+
else:
|
| 178 |
+
if (
|
| 179 |
+
hasattr(value, "__len__")
|
| 180 |
+
and not isinstance(value, (str, bytes))
|
| 181 |
+
and len(value) == 1
|
| 182 |
+
):
|
| 183 |
+
value = value[0]
|
| 184 |
+
elif hasattr(value, "item"):
|
| 185 |
+
value = value.item()
|
| 186 |
+
metric_values.append(value)
|
| 187 |
+
|
| 188 |
+
# Lookup domain and num_variates from dataset properties
|
| 189 |
+
ds_key = md.key.lower()
|
| 190 |
+
props = DATASET_PROPERTIES.get(ds_key, {})
|
| 191 |
+
domain = props.get("domain", "unknown")
|
| 192 |
+
num_variates = props.get(
|
| 193 |
+
"num_variates", 1 if md.to_univariate else md.target_dim
|
| 194 |
+
)
|
| 195 |
+
|
| 196 |
+
row = [md.full_name, model_name] + metric_values + [domain, num_variates]
|
| 197 |
+
writer.writerow(row)
|
| 198 |
+
|
| 199 |
+
if create_plots and item.figures:
|
| 200 |
+
plots_dir = output_dir / "plots" / md.key / md.term
|
| 201 |
+
plots_dir.mkdir(parents=True, exist_ok=True)
|
| 202 |
+
for fig, filename in item.figures:
|
| 203 |
+
filepath = plots_dir / filename
|
| 204 |
+
fig.savefig(filepath, dpi=300, bbox_inches="tight")
|
| 205 |
+
plt.close(fig)
|
| 206 |
+
|
| 207 |
+
logger.info(
|
| 208 |
+
f"Evaluation complete for dataset '{dataset_name}'. Results saved to {output_csv_path}"
|
| 209 |
+
)
|
| 210 |
+
if create_plots:
|
| 211 |
+
logger.info(f"Plots saved under {output_dir / 'plots'}")
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
def evaluate_datasets(
|
| 215 |
+
predictor: TimeSeriesPredictor,
|
| 216 |
+
dataset: str,
|
| 217 |
+
dataset_storage_path: str,
|
| 218 |
+
terms: List[str] = ["short", "medium", "long"],
|
| 219 |
+
max_windows: Optional[int] = None,
|
| 220 |
+
batch_size: int = 48,
|
| 221 |
+
max_context_length: Optional[int] = 1024,
|
| 222 |
+
create_plots: bool = False,
|
| 223 |
+
max_plots_per_dataset: int = 10,
|
| 224 |
+
) -> List[EvaluationItem]:
|
| 225 |
+
"""Evaluate predictor on one dataset across the requested terms."""
|
| 226 |
+
sub_datasets = construct_evaluation_data(
|
| 227 |
+
dataset_name=dataset,
|
| 228 |
+
dataset_storage_path=dataset_storage_path,
|
| 229 |
+
terms=terms,
|
| 230 |
+
max_windows=max_windows,
|
| 231 |
+
)
|
| 232 |
+
|
| 233 |
+
results: List[EvaluationItem] = []
|
| 234 |
+
for i, (sub_dataset, metadata) in enumerate(sub_datasets):
|
| 235 |
+
logger.info(f"Evaluating {i + 1}/{len(sub_datasets)}: {metadata.full_name}")
|
| 236 |
+
logger.info(f" Dataset size: {len(sub_dataset.test_data)}")
|
| 237 |
+
logger.info(f" Frequency: {sub_dataset.freq}")
|
| 238 |
+
logger.info(f" Term: {metadata.term}")
|
| 239 |
+
logger.info(f" Prediction length: {sub_dataset.prediction_length}")
|
| 240 |
+
logger.info(f" Target dimensions: {sub_dataset.target_dim}")
|
| 241 |
+
logger.info(f" Windows: {sub_dataset.windows}")
|
| 242 |
+
|
| 243 |
+
# Update context on the reusable predictor
|
| 244 |
+
predictor.set_dataset_context(
|
| 245 |
+
prediction_length=sub_dataset.prediction_length,
|
| 246 |
+
freq=sub_dataset.freq,
|
| 247 |
+
batch_size=batch_size,
|
| 248 |
+
max_context_length=max_context_length,
|
| 249 |
+
)
|
| 250 |
+
|
| 251 |
+
res = evaluate_model(
|
| 252 |
+
model=predictor,
|
| 253 |
+
test_data=sub_dataset.test_data,
|
| 254 |
+
metrics=METRICS,
|
| 255 |
+
axis=None,
|
| 256 |
+
mask_invalid_label=True,
|
| 257 |
+
allow_nan_forecast=False,
|
| 258 |
+
seasonality=metadata.season_length,
|
| 259 |
+
)
|
| 260 |
+
|
| 261 |
+
figs: List[Tuple[object, str]] = []
|
| 262 |
+
if create_plots:
|
| 263 |
+
forecasts = predictor.predict(sub_dataset.test_data.input)
|
| 264 |
+
figs = create_plots_for_dataset(
|
| 265 |
+
forecasts=forecasts,
|
| 266 |
+
test_data=sub_dataset.test_data,
|
| 267 |
+
dataset_metadata=metadata,
|
| 268 |
+
max_plots=max_plots_per_dataset,
|
| 269 |
+
max_context_length=max_context_length,
|
| 270 |
+
)
|
| 271 |
+
|
| 272 |
+
results.append(
|
| 273 |
+
EvaluationItem(dataset_metadata=metadata, metrics=res, figures=figs)
|
| 274 |
+
)
|
| 275 |
+
|
| 276 |
+
return results
|
| 277 |
+
|
| 278 |
+
|
| 279 |
+
def _expand_datasets_arg(datasets: List[str] | str) -> List[str]:
|
| 280 |
+
if datasets[0] == "all":
|
| 281 |
+
return list(ALL_DATASETS)
|
| 282 |
+
if isinstance(datasets, str):
|
| 283 |
+
datasets = [datasets]
|
| 284 |
+
for dataset in datasets:
|
| 285 |
+
if dataset not in ALL_DATASETS:
|
| 286 |
+
raise ValueError(f"Invalid dataset: {dataset}. Use one of {ALL_DATASETS}")
|
| 287 |
+
return datasets
|
| 288 |
+
|
| 289 |
+
|
| 290 |
+
def _run_evaluation(
|
| 291 |
+
predictor: TimeSeriesPredictor,
|
| 292 |
+
datasets: List[str] | str,
|
| 293 |
+
terms: List[str],
|
| 294 |
+
dataset_storage_path: str,
|
| 295 |
+
max_windows: Optional[int] = None,
|
| 296 |
+
batch_size: int = 48,
|
| 297 |
+
max_context_length: Optional[int] = 1024,
|
| 298 |
+
output_dir: str = "gift_eval_results",
|
| 299 |
+
model_name: str = "TimeSeriesModel",
|
| 300 |
+
create_plots: bool = False,
|
| 301 |
+
max_plots: int = 10,
|
| 302 |
+
) -> None:
|
| 303 |
+
"""Shared evaluation workflow used by both entry points."""
|
| 304 |
+
datasets_to_run = _expand_datasets_arg(datasets)
|
| 305 |
+
results_root = Path(output_dir)
|
| 306 |
+
|
| 307 |
+
for ds_name in datasets_to_run:
|
| 308 |
+
items = evaluate_datasets(
|
| 309 |
+
predictor=predictor,
|
| 310 |
+
dataset=ds_name,
|
| 311 |
+
dataset_storage_path=dataset_storage_path,
|
| 312 |
+
terms=terms,
|
| 313 |
+
max_windows=max_windows,
|
| 314 |
+
batch_size=batch_size,
|
| 315 |
+
max_context_length=max_context_length,
|
| 316 |
+
create_plots=create_plots,
|
| 317 |
+
max_plots_per_dataset=max_plots,
|
| 318 |
+
)
|
| 319 |
+
write_results_to_disk(
|
| 320 |
+
items=items,
|
| 321 |
+
dataset_name=ds_name,
|
| 322 |
+
output_dir=results_root,
|
| 323 |
+
model_name=model_name,
|
| 324 |
+
create_plots=create_plots,
|
| 325 |
+
)
|
| 326 |
+
|
| 327 |
+
|
| 328 |
+
def evaluate_from_paths(
|
| 329 |
+
model_path: str,
|
| 330 |
+
config_path: str,
|
| 331 |
+
datasets: List[str] | str,
|
| 332 |
+
terms: List[str],
|
| 333 |
+
dataset_storage_path: str,
|
| 334 |
+
max_windows: Optional[int] = None,
|
| 335 |
+
batch_size: int = 48,
|
| 336 |
+
max_context_length: Optional[int] = 1024,
|
| 337 |
+
output_dir: str = "gift_eval_results",
|
| 338 |
+
model_name: str = "TimeSeriesModel",
|
| 339 |
+
create_plots: bool = False,
|
| 340 |
+
max_plots: int = 10,
|
| 341 |
+
) -> None:
|
| 342 |
+
"""Entry point: load model from disk and save metrics/plots to disk."""
|
| 343 |
+
# Validate inputs early
|
| 344 |
+
if not Path(model_path).exists():
|
| 345 |
+
raise FileNotFoundError(f"Model path does not exist: {model_path}")
|
| 346 |
+
if not Path(config_path).exists():
|
| 347 |
+
raise FileNotFoundError(f"Config path does not exist: {config_path}")
|
| 348 |
+
|
| 349 |
+
predictor = TimeSeriesPredictor.from_paths(
|
| 350 |
+
model_path=model_path,
|
| 351 |
+
config_path=config_path,
|
| 352 |
+
ds_prediction_length=1, # placeholder; set per dataset below
|
| 353 |
+
ds_freq="D", # placeholder; set per dataset below
|
| 354 |
+
batch_size=batch_size,
|
| 355 |
+
max_context_length=max_context_length,
|
| 356 |
+
)
|
| 357 |
+
|
| 358 |
+
_run_evaluation(
|
| 359 |
+
predictor=predictor,
|
| 360 |
+
datasets=datasets,
|
| 361 |
+
terms=terms,
|
| 362 |
+
dataset_storage_path=dataset_storage_path,
|
| 363 |
+
max_windows=max_windows,
|
| 364 |
+
batch_size=batch_size,
|
| 365 |
+
max_context_length=max_context_length,
|
| 366 |
+
output_dir=output_dir,
|
| 367 |
+
model_name=model_name,
|
| 368 |
+
create_plots=create_plots,
|
| 369 |
+
max_plots=max_plots,
|
| 370 |
+
)
|
| 371 |
+
|
| 372 |
+
|
| 373 |
+
def evaluate_in_memory(
|
| 374 |
+
model,
|
| 375 |
+
config: dict,
|
| 376 |
+
datasets: List[str] | str,
|
| 377 |
+
terms: List[str],
|
| 378 |
+
dataset_storage_path: str,
|
| 379 |
+
max_windows: Optional[int] = None,
|
| 380 |
+
batch_size: int = 48,
|
| 381 |
+
max_context_length: Optional[int] = 1024,
|
| 382 |
+
output_dir: str = "gift_eval_results",
|
| 383 |
+
model_name: str = "TimeSeriesModel",
|
| 384 |
+
create_plots: bool = False,
|
| 385 |
+
max_plots: int = 10,
|
| 386 |
+
) -> None:
|
| 387 |
+
"""Entry point: evaluate in-memory model and return results per dataset."""
|
| 388 |
+
predictor = TimeSeriesPredictor.from_model(
|
| 389 |
+
model=model,
|
| 390 |
+
config=config,
|
| 391 |
+
ds_prediction_length=1, # placeholder; set per dataset below
|
| 392 |
+
ds_freq="D", # placeholder; set per dataset below
|
| 393 |
+
batch_size=batch_size,
|
| 394 |
+
max_context_length=max_context_length,
|
| 395 |
+
)
|
| 396 |
+
|
| 397 |
+
_run_evaluation(
|
| 398 |
+
predictor=predictor,
|
| 399 |
+
datasets=datasets,
|
| 400 |
+
terms=terms,
|
| 401 |
+
dataset_storage_path=dataset_storage_path,
|
| 402 |
+
max_windows=max_windows,
|
| 403 |
+
batch_size=batch_size,
|
| 404 |
+
max_context_length=max_context_length,
|
| 405 |
+
output_dir=output_dir,
|
| 406 |
+
model_name=model_name,
|
| 407 |
+
create_plots=create_plots,
|
| 408 |
+
max_plots=max_plots,
|
| 409 |
+
)
|
| 410 |
+
|
| 411 |
+
|
| 412 |
+
def _parse_args() -> argparse.Namespace:
|
| 413 |
+
parser = argparse.ArgumentParser(
|
| 414 |
+
description="Evaluate TimeSeriesModel on GIFT-Eval datasets"
|
| 415 |
+
)
|
| 416 |
+
|
| 417 |
+
# Model configuration
|
| 418 |
+
parser.add_argument(
|
| 419 |
+
"--model_path",
|
| 420 |
+
type=str,
|
| 421 |
+
required=True,
|
| 422 |
+
help="Path to the trained model checkpoint",
|
| 423 |
+
)
|
| 424 |
+
parser.add_argument(
|
| 425 |
+
"--config_path",
|
| 426 |
+
type=str,
|
| 427 |
+
required=True,
|
| 428 |
+
help="Path to the model configuration YAML file",
|
| 429 |
+
)
|
| 430 |
+
parser.add_argument(
|
| 431 |
+
"--model_name",
|
| 432 |
+
type=str,
|
| 433 |
+
default="TimeSeriesModel",
|
| 434 |
+
help="Name identifier for the model",
|
| 435 |
+
)
|
| 436 |
+
|
| 437 |
+
# Dataset configuration
|
| 438 |
+
parser.add_argument(
|
| 439 |
+
"--datasets",
|
| 440 |
+
type=str,
|
| 441 |
+
default="all",
|
| 442 |
+
help="Comma-separated list of dataset names to evaluate (or 'all')",
|
| 443 |
+
)
|
| 444 |
+
parser.add_argument(
|
| 445 |
+
"--dataset_storage_path",
|
| 446 |
+
type=str,
|
| 447 |
+
required=True,
|
| 448 |
+
help="Path to the dataset storage directory",
|
| 449 |
+
)
|
| 450 |
+
parser.add_argument(
|
| 451 |
+
"--terms",
|
| 452 |
+
type=str,
|
| 453 |
+
default="short,medium,long",
|
| 454 |
+
help="Comma-separated list of prediction terms to evaluate",
|
| 455 |
+
)
|
| 456 |
+
parser.add_argument(
|
| 457 |
+
"--max_windows",
|
| 458 |
+
type=int,
|
| 459 |
+
default=None,
|
| 460 |
+
help="Maximum number of windows to use for evaluation",
|
| 461 |
+
)
|
| 462 |
+
|
| 463 |
+
# Inference configuration
|
| 464 |
+
parser.add_argument(
|
| 465 |
+
"--batch_size", type=int, default=48, help="Batch size for model inference"
|
| 466 |
+
)
|
| 467 |
+
parser.add_argument(
|
| 468 |
+
"--max_context_length",
|
| 469 |
+
type=int,
|
| 470 |
+
default=1024,
|
| 471 |
+
help="Maximum context length to use (None for no limit)",
|
| 472 |
+
)
|
| 473 |
+
|
| 474 |
+
# Output configuration
|
| 475 |
+
parser.add_argument(
|
| 476 |
+
"--output_dir",
|
| 477 |
+
type=str,
|
| 478 |
+
default="gift_eval_results",
|
| 479 |
+
help="Directory to save evaluation results",
|
| 480 |
+
)
|
| 481 |
+
|
| 482 |
+
# Plotting configuration
|
| 483 |
+
parser.add_argument(
|
| 484 |
+
"--create_plots",
|
| 485 |
+
action="store_true",
|
| 486 |
+
help="Create and save plots for each evaluation window",
|
| 487 |
+
)
|
| 488 |
+
parser.add_argument(
|
| 489 |
+
"--max_plots_per_dataset",
|
| 490 |
+
type=int,
|
| 491 |
+
default=10,
|
| 492 |
+
help="Maximum number of plots to create per dataset term",
|
| 493 |
+
)
|
| 494 |
+
|
| 495 |
+
args = parser.parse_args()
|
| 496 |
+
args.terms = args.terms.split(",")
|
| 497 |
+
args.datasets = args.datasets.split(",")
|
| 498 |
+
return args
|
| 499 |
+
|
| 500 |
+
|
| 501 |
+
def _configure_logging() -> None:
|
| 502 |
+
logging.basicConfig(
|
| 503 |
+
level=logging.INFO,
|
| 504 |
+
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s",
|
| 505 |
+
)
|
| 506 |
+
|
| 507 |
+
|
| 508 |
+
if __name__ == "__main__":
|
| 509 |
+
_configure_logging()
|
| 510 |
+
args = _parse_args()
|
| 511 |
+
logger.info(f"Command Line Arguments: {vars(args)}")
|
| 512 |
+
try:
|
| 513 |
+
evaluate_from_paths(
|
| 514 |
+
model_path=args.model_path,
|
| 515 |
+
config_path=args.config_path,
|
| 516 |
+
datasets=args.datasets,
|
| 517 |
+
terms=args.terms,
|
| 518 |
+
dataset_storage_path=args.dataset_storage_path,
|
| 519 |
+
max_windows=args.max_windows,
|
| 520 |
+
batch_size=args.batch_size,
|
| 521 |
+
max_context_length=args.max_context_length,
|
| 522 |
+
output_dir=args.output_dir,
|
| 523 |
+
model_name=args.model_name,
|
| 524 |
+
create_plots=args.create_plots,
|
| 525 |
+
max_plots=args.max_plots_per_dataset,
|
| 526 |
+
)
|
| 527 |
+
except Exception as e:
|
| 528 |
+
logger.error(f"Evaluation failed: {str(e)}")
|
| 529 |
+
raise
|
src/gift_eval/model_wrapper.py
ADDED
|
@@ -0,0 +1,349 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
from typing import Iterator, List, Optional
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
import yaml
|
| 7 |
+
from gluonts.itertools import batcher
|
| 8 |
+
from gluonts.model.forecast import QuantileForecast
|
| 9 |
+
from gluonts.model.predictor import Predictor
|
| 10 |
+
from torch.nn.parallel import DistributedDataParallel as DDP
|
| 11 |
+
|
| 12 |
+
from src.data.containers import BatchTimeSeriesContainer
|
| 13 |
+
from src.data.frequency import parse_frequency
|
| 14 |
+
from src.data.scalers import RobustScaler
|
| 15 |
+
from src.models.model import TimeSeriesModel
|
| 16 |
+
from src.utils.utils import device
|
| 17 |
+
|
| 18 |
+
logger = logging.getLogger(__name__)
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
class TimeSeriesPredictor(Predictor):
|
| 22 |
+
"""
|
| 23 |
+
Unified predictor for TimeSeriesModel supporting both in-memory and file-based construction.
|
| 24 |
+
|
| 25 |
+
Use classmethods `from_model` and `from_paths` to construct instances.
|
| 26 |
+
Provides `set_dataset_context` to adjust dataset-specific parameters without reloading the model.
|
| 27 |
+
"""
|
| 28 |
+
|
| 29 |
+
def __init__(
|
| 30 |
+
self,
|
| 31 |
+
model: TimeSeriesModel,
|
| 32 |
+
config: dict,
|
| 33 |
+
ds_prediction_length: int,
|
| 34 |
+
ds_freq: str,
|
| 35 |
+
batch_size: int = 32,
|
| 36 |
+
max_context_length: Optional[int] = None,
|
| 37 |
+
debug: bool = False,
|
| 38 |
+
) -> None:
|
| 39 |
+
# Dataset-specific context (can be updated per dataset/term)
|
| 40 |
+
self.ds_prediction_length = ds_prediction_length
|
| 41 |
+
self.ds_freq = ds_freq
|
| 42 |
+
self.batch_size = batch_size
|
| 43 |
+
self.max_context_length = max_context_length
|
| 44 |
+
self.debug = debug
|
| 45 |
+
|
| 46 |
+
# Persistent model/config (unwrap DDP if needed)
|
| 47 |
+
self.model = model.module if isinstance(model, DDP) else model
|
| 48 |
+
self.model.eval()
|
| 49 |
+
self.config = config
|
| 50 |
+
|
| 51 |
+
# Initialize scaler (using same type as model)
|
| 52 |
+
scaler_type = self.config.get("TimeSeriesModel", {}).get(
|
| 53 |
+
"scaler", "custom_robust"
|
| 54 |
+
)
|
| 55 |
+
epsilon = self.config.get("TimeSeriesModel", {}).get("epsilon", 1e-3)
|
| 56 |
+
if scaler_type == "custom_robust":
|
| 57 |
+
self.scaler = RobustScaler(epsilon=epsilon)
|
| 58 |
+
else:
|
| 59 |
+
raise ValueError(f"Unsupported scaler type: {scaler_type}")
|
| 60 |
+
|
| 61 |
+
def set_dataset_context(
|
| 62 |
+
self,
|
| 63 |
+
prediction_length: Optional[int] = None,
|
| 64 |
+
freq: Optional[str] = None,
|
| 65 |
+
batch_size: Optional[int] = None,
|
| 66 |
+
max_context_length: Optional[int] = None,
|
| 67 |
+
) -> None:
|
| 68 |
+
"""Update lightweight dataset-specific attributes without reloading the model."""
|
| 69 |
+
if prediction_length is not None:
|
| 70 |
+
self.ds_prediction_length = prediction_length
|
| 71 |
+
if freq is not None:
|
| 72 |
+
self.ds_freq = freq
|
| 73 |
+
if batch_size is not None:
|
| 74 |
+
self.batch_size = batch_size
|
| 75 |
+
if max_context_length is not None:
|
| 76 |
+
self.max_context_length = max_context_length
|
| 77 |
+
|
| 78 |
+
@classmethod
|
| 79 |
+
def from_model(
|
| 80 |
+
cls,
|
| 81 |
+
model: TimeSeriesModel,
|
| 82 |
+
config: dict,
|
| 83 |
+
ds_prediction_length: int,
|
| 84 |
+
ds_freq: str,
|
| 85 |
+
batch_size: int = 32,
|
| 86 |
+
max_context_length: Optional[int] = None,
|
| 87 |
+
debug: bool = False,
|
| 88 |
+
) -> "TimeSeriesPredictor":
|
| 89 |
+
return cls(
|
| 90 |
+
model=model,
|
| 91 |
+
config=config,
|
| 92 |
+
ds_prediction_length=ds_prediction_length,
|
| 93 |
+
ds_freq=ds_freq,
|
| 94 |
+
batch_size=batch_size,
|
| 95 |
+
max_context_length=max_context_length,
|
| 96 |
+
debug=debug,
|
| 97 |
+
)
|
| 98 |
+
|
| 99 |
+
@classmethod
|
| 100 |
+
def from_paths(
|
| 101 |
+
cls,
|
| 102 |
+
model_path: str,
|
| 103 |
+
config_path: str,
|
| 104 |
+
ds_prediction_length: int,
|
| 105 |
+
ds_freq: str,
|
| 106 |
+
batch_size: int = 32,
|
| 107 |
+
max_context_length: Optional[int] = None,
|
| 108 |
+
debug: bool = False,
|
| 109 |
+
) -> "TimeSeriesPredictor":
|
| 110 |
+
with open(config_path, "r") as f:
|
| 111 |
+
config = yaml.safe_load(f)
|
| 112 |
+
model = cls._load_model_from_path(config=config, model_path=model_path)
|
| 113 |
+
return cls(
|
| 114 |
+
model=model,
|
| 115 |
+
config=config,
|
| 116 |
+
ds_prediction_length=ds_prediction_length,
|
| 117 |
+
ds_freq=ds_freq,
|
| 118 |
+
batch_size=batch_size,
|
| 119 |
+
max_context_length=max_context_length,
|
| 120 |
+
debug=debug,
|
| 121 |
+
)
|
| 122 |
+
|
| 123 |
+
@staticmethod
|
| 124 |
+
def _load_model_from_path(config: dict, model_path: str) -> TimeSeriesModel:
|
| 125 |
+
try:
|
| 126 |
+
model = TimeSeriesModel(**config["TimeSeriesModel"]).to(device)
|
| 127 |
+
checkpoint = torch.load(model_path, map_location=device)
|
| 128 |
+
model.load_state_dict(checkpoint["model_state_dict"])
|
| 129 |
+
model.eval()
|
| 130 |
+
logger.info(f"Successfully loaded model from {model_path}")
|
| 131 |
+
return model
|
| 132 |
+
except Exception as e:
|
| 133 |
+
logger.error(f"Failed to load model from {model_path}: {str(e)}")
|
| 134 |
+
raise
|
| 135 |
+
|
| 136 |
+
def predict(self, test_data_input) -> Iterator[QuantileForecast]:
|
| 137 |
+
"""
|
| 138 |
+
Generate forecasts for the test data.
|
| 139 |
+
|
| 140 |
+
Args:
|
| 141 |
+
test_data_input: Iterator of gluonts DataEntry objects
|
| 142 |
+
|
| 143 |
+
Returns:
|
| 144 |
+
Iterable of QuantileForecast objects
|
| 145 |
+
"""
|
| 146 |
+
if hasattr(test_data_input, "__iter__") and not isinstance(
|
| 147 |
+
test_data_input, list
|
| 148 |
+
):
|
| 149 |
+
test_data_input = list(test_data_input)
|
| 150 |
+
logger.debug(f"Processing {len(test_data_input)} time series")
|
| 151 |
+
|
| 152 |
+
# Group series by their effective length (after optional truncation),
|
| 153 |
+
# then process each uniform-length group in sub-batches up to batch_size.
|
| 154 |
+
def _effective_length(entry) -> int:
|
| 155 |
+
target = entry["target"]
|
| 156 |
+
if target.ndim == 1:
|
| 157 |
+
seq_len = len(target)
|
| 158 |
+
else:
|
| 159 |
+
# target shape is [num_channels, seq_len]
|
| 160 |
+
seq_len = target.shape[1]
|
| 161 |
+
if self.max_context_length is not None:
|
| 162 |
+
seq_len = min(seq_len, self.max_context_length)
|
| 163 |
+
return seq_len
|
| 164 |
+
|
| 165 |
+
length_to_items: dict[int, List[tuple[int, object]]] = {}
|
| 166 |
+
for idx, entry in enumerate(test_data_input):
|
| 167 |
+
L = _effective_length(entry)
|
| 168 |
+
length_to_items.setdefault(L, []).append((idx, entry))
|
| 169 |
+
|
| 170 |
+
total = len(test_data_input)
|
| 171 |
+
ordered_results: List[Optional[QuantileForecast]] = [None] * total
|
| 172 |
+
|
| 173 |
+
for _, items in length_to_items.items():
|
| 174 |
+
for i in range(0, len(items), self.batch_size):
|
| 175 |
+
chunk = items[i : i + self.batch_size]
|
| 176 |
+
entries = [e for (_orig_idx, e) in chunk]
|
| 177 |
+
batch_forecasts = self._predict_batch(entries)
|
| 178 |
+
for f_idx, (orig_idx, _e) in enumerate(chunk):
|
| 179 |
+
ordered_results[orig_idx] = batch_forecasts[f_idx]
|
| 180 |
+
|
| 181 |
+
# All results should be populated
|
| 182 |
+
return ordered_results # type: ignore[return-value]
|
| 183 |
+
|
| 184 |
+
def _predict_batch(self, test_data_batch: List) -> List[QuantileForecast]:
|
| 185 |
+
"""Generate predictions for a batch of time series."""
|
| 186 |
+
logger.debug(f"Processing batch of size: {len(test_data_batch)}")
|
| 187 |
+
|
| 188 |
+
try:
|
| 189 |
+
# Convert gluonts data to BatchTimeSeriesContainer
|
| 190 |
+
batch_container = self._convert_to_batch_container(test_data_batch)
|
| 191 |
+
|
| 192 |
+
# Autocast only when running on CUDA
|
| 193 |
+
if isinstance(device, torch.device):
|
| 194 |
+
device_type = device.type
|
| 195 |
+
else:
|
| 196 |
+
device_type = "cuda" if "cuda" in str(device).lower() else "cpu"
|
| 197 |
+
enable_autocast = device_type == "cuda"
|
| 198 |
+
|
| 199 |
+
with torch.autocast(
|
| 200 |
+
device_type=device_type, dtype=torch.bfloat16, enabled=enable_autocast
|
| 201 |
+
):
|
| 202 |
+
with torch.no_grad():
|
| 203 |
+
model_output = self.model(batch_container, drop_enc_allow=False)
|
| 204 |
+
|
| 205 |
+
# Convert predictions to QuantileForecast objects
|
| 206 |
+
forecasts = self._convert_to_forecasts(
|
| 207 |
+
model_output, test_data_batch, batch_container
|
| 208 |
+
)
|
| 209 |
+
|
| 210 |
+
logger.debug(f"Generated {len(forecasts)} forecasts")
|
| 211 |
+
return forecasts
|
| 212 |
+
|
| 213 |
+
except Exception as e:
|
| 214 |
+
logger.error(f"Error in batch prediction: {str(e)}")
|
| 215 |
+
raise
|
| 216 |
+
|
| 217 |
+
def _convert_to_batch_container(
|
| 218 |
+
self, test_data_batch: List
|
| 219 |
+
) -> BatchTimeSeriesContainer:
|
| 220 |
+
"""Convert gluonts test data to BatchTimeSeriesContainer."""
|
| 221 |
+
batch_size = len(test_data_batch)
|
| 222 |
+
|
| 223 |
+
# Extract data from test entries (all series in this batch must have equal length)
|
| 224 |
+
history_values_list = []
|
| 225 |
+
start_dates = []
|
| 226 |
+
frequencies = []
|
| 227 |
+
|
| 228 |
+
for entry in test_data_batch:
|
| 229 |
+
target = entry["target"]
|
| 230 |
+
|
| 231 |
+
# Handle both univariate and multivariate cases
|
| 232 |
+
if target.ndim == 1:
|
| 233 |
+
# Univariate: reshape to [seq_len, 1]
|
| 234 |
+
target = target.reshape(-1, 1)
|
| 235 |
+
else:
|
| 236 |
+
# Multivariate: assume shape is [num_channels, seq_len] -> transpose to [seq_len, num_channels]
|
| 237 |
+
target = target.T
|
| 238 |
+
|
| 239 |
+
# Apply context length limit if specified
|
| 240 |
+
if (
|
| 241 |
+
self.max_context_length is not None
|
| 242 |
+
and len(target) > self.max_context_length
|
| 243 |
+
):
|
| 244 |
+
target = target[-self.max_context_length :]
|
| 245 |
+
|
| 246 |
+
history_values_list.append(target)
|
| 247 |
+
start_dates.append(entry["start"].to_timestamp().to_datetime64())
|
| 248 |
+
frequencies.append(parse_frequency(entry["freq"]))
|
| 249 |
+
|
| 250 |
+
# Stack sequences directly (no padding) -> shapes are uniform by construction
|
| 251 |
+
history_values_np = np.stack(history_values_list, axis=0)
|
| 252 |
+
num_channels = history_values_np.shape[2]
|
| 253 |
+
|
| 254 |
+
# Convert to tensors
|
| 255 |
+
history_values = torch.tensor(
|
| 256 |
+
history_values_np, dtype=torch.float32, device=device
|
| 257 |
+
)
|
| 258 |
+
|
| 259 |
+
# Create future values tensor (empty for prediction)
|
| 260 |
+
future_values = torch.zeros(
|
| 261 |
+
(batch_size, self.ds_prediction_length, num_channels),
|
| 262 |
+
dtype=torch.float32,
|
| 263 |
+
device=device,
|
| 264 |
+
)
|
| 265 |
+
|
| 266 |
+
return BatchTimeSeriesContainer(
|
| 267 |
+
history_values=history_values,
|
| 268 |
+
future_values=future_values,
|
| 269 |
+
start=start_dates,
|
| 270 |
+
frequency=frequencies,
|
| 271 |
+
)
|
| 272 |
+
|
| 273 |
+
def _convert_to_forecasts(
|
| 274 |
+
self,
|
| 275 |
+
model_output: dict,
|
| 276 |
+
test_data_batch: List,
|
| 277 |
+
batch_container: BatchTimeSeriesContainer,
|
| 278 |
+
) -> List[QuantileForecast]:
|
| 279 |
+
"""Convert model predictions to QuantileForecast objects."""
|
| 280 |
+
predictions = model_output[
|
| 281 |
+
"result"
|
| 282 |
+
] # Shape: [batch_size, pred_len, num_channels] or [batch_size, pred_len, num_channels, num_quantiles]
|
| 283 |
+
scale_statistics = model_output["scale_statistics"]
|
| 284 |
+
|
| 285 |
+
# Apply inverse scaling to get predictions in original scale
|
| 286 |
+
if predictions.ndim == 4:
|
| 287 |
+
# Quantile predictions: [batch_size, pred_len, num_channels, num_quantiles]
|
| 288 |
+
predictions_unscaled = self.scaler.inverse_scale(
|
| 289 |
+
predictions, scale_statistics
|
| 290 |
+
)
|
| 291 |
+
is_quantile = True
|
| 292 |
+
quantile_levels = self.model.quantiles
|
| 293 |
+
else:
|
| 294 |
+
# Point predictions: [batch_size, pred_len, num_channels]
|
| 295 |
+
predictions_unscaled = self.scaler.inverse_scale(
|
| 296 |
+
predictions, scale_statistics
|
| 297 |
+
)
|
| 298 |
+
is_quantile = False
|
| 299 |
+
quantile_levels = [0.5] # Treat as median forecast
|
| 300 |
+
|
| 301 |
+
forecasts: List[QuantileForecast] = []
|
| 302 |
+
for i, entry in enumerate(test_data_batch):
|
| 303 |
+
# Get prediction start date
|
| 304 |
+
history_length = int(batch_container.history_values.shape[1])
|
| 305 |
+
start_date = entry["start"]
|
| 306 |
+
forecast_start = start_date + history_length
|
| 307 |
+
|
| 308 |
+
if is_quantile:
|
| 309 |
+
# Handle quantile forecasts
|
| 310 |
+
pred_array = (
|
| 311 |
+
predictions_unscaled[i].cpu().numpy()
|
| 312 |
+
) # [pred_len, num_channels, num_quantiles]
|
| 313 |
+
|
| 314 |
+
if pred_array.shape[1] == 1:
|
| 315 |
+
# Univariate case: [pred_len, 1, num_quantiles] -> [pred_len, num_quantiles]
|
| 316 |
+
pred_array = pred_array.squeeze(1)
|
| 317 |
+
forecast_arrays = pred_array.T # [num_quantiles, pred_len]
|
| 318 |
+
else:
|
| 319 |
+
# Multivariate case: [pred_len, num_channels, num_quantiles] -> [num_quantiles, pred_len, num_channels]
|
| 320 |
+
forecast_arrays = pred_array.transpose(2, 0, 1)
|
| 321 |
+
|
| 322 |
+
forecast = QuantileForecast(
|
| 323 |
+
forecast_arrays=forecast_arrays,
|
| 324 |
+
forecast_keys=[str(q) for q in quantile_levels],
|
| 325 |
+
start_date=forecast_start,
|
| 326 |
+
)
|
| 327 |
+
else:
|
| 328 |
+
# Handle point forecasts
|
| 329 |
+
pred_array = (
|
| 330 |
+
predictions_unscaled[i].cpu().numpy()
|
| 331 |
+
) # [pred_len, num_channels]
|
| 332 |
+
|
| 333 |
+
if pred_array.shape[1] == 1:
|
| 334 |
+
# Univariate case: [pred_len, 1] -> [pred_len]
|
| 335 |
+
pred_array = pred_array.squeeze(1)
|
| 336 |
+
forecast_arrays = pred_array.reshape(1, -1) # [1, pred_len]
|
| 337 |
+
else:
|
| 338 |
+
# Multivariate case: [pred_len, num_channels] -> [1, pred_len, num_channels]
|
| 339 |
+
forecast_arrays = pred_array.reshape(1, *pred_array.shape)
|
| 340 |
+
|
| 341 |
+
forecast = QuantileForecast(
|
| 342 |
+
forecast_arrays=forecast_arrays,
|
| 343 |
+
forecast_keys=["0.5"],
|
| 344 |
+
start_date=forecast_start,
|
| 345 |
+
)
|
| 346 |
+
|
| 347 |
+
forecasts.append(forecast)
|
| 348 |
+
|
| 349 |
+
return forecasts
|
src/models/__init__.py
ADDED
|
File without changes
|
src/models/blocks.py
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
from fla.models.gated_deltaproduct import GatedDeltaProductConfig
|
| 4 |
+
from fla.models.gated_deltaproduct.modeling_gated_deltaproduct import GatedDeltaProductBlock
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class GatedDeltaProductEncoder(nn.Module):
|
| 8 |
+
"""
|
| 9 |
+
GatedDeltaNet encoder using GatedDeltaProductBlock for sequence modeling.
|
| 10 |
+
"""
|
| 11 |
+
|
| 12 |
+
def __init__(
|
| 13 |
+
self,
|
| 14 |
+
layer_idx: int,
|
| 15 |
+
token_embed_dim: int,
|
| 16 |
+
num_heads: int = 4,
|
| 17 |
+
attn_mode: str = "chunk",
|
| 18 |
+
expand_v: float = 1.0,
|
| 19 |
+
use_gate: bool = False,
|
| 20 |
+
use_short_conv: bool = True,
|
| 21 |
+
conv_size: int = 4,
|
| 22 |
+
allow_neg_eigval: bool = True,
|
| 23 |
+
use_forget_gate: bool = True,
|
| 24 |
+
num_householder: int = 1,
|
| 25 |
+
**kwargs,
|
| 26 |
+
):
|
| 27 |
+
super().__init__()
|
| 28 |
+
config = GatedDeltaProductConfig(
|
| 29 |
+
attn_mode=attn_mode,
|
| 30 |
+
hidden_size=token_embed_dim,
|
| 31 |
+
expand_v=expand_v,
|
| 32 |
+
use_gate=use_gate,
|
| 33 |
+
use_short_conv=use_short_conv,
|
| 34 |
+
conv_size=conv_size,
|
| 35 |
+
head_dim=token_embed_dim // num_heads,
|
| 36 |
+
hidden_ratio=0.5,
|
| 37 |
+
num_heads=num_heads,
|
| 38 |
+
allow_neg_eigval=allow_neg_eigval,
|
| 39 |
+
use_forget_gate=use_forget_gate,
|
| 40 |
+
num_householder=num_householder,
|
| 41 |
+
)
|
| 42 |
+
|
| 43 |
+
self.encoder_layer = GatedDeltaProductBlock(layer_idx=layer_idx, config=config)
|
| 44 |
+
|
| 45 |
+
def forward(self, x, initial_state=None):
|
| 46 |
+
"""
|
| 47 |
+
Forward pass through the GatedDeltaProductBlock.
|
| 48 |
+
|
| 49 |
+
Args:
|
| 50 |
+
x: Input tensor of shape [batch_size, seq_len, hidden_size]
|
| 51 |
+
|
| 52 |
+
Returns:
|
| 53 |
+
Output tensor of same shape as input
|
| 54 |
+
"""
|
| 55 |
+
x, last_hidden_state, _ = self.encoder_layer(
|
| 56 |
+
x, output_attentions=True, initial_state=initial_state
|
| 57 |
+
)
|
| 58 |
+
return x, last_hidden_state
|
src/models/model.py
ADDED
|
@@ -0,0 +1,427 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
from fla.modules import GatedMLP
|
| 4 |
+
|
| 5 |
+
from src.data.containers import BatchTimeSeriesContainer
|
| 6 |
+
from src.data.scalers import MinMaxScaler, RobustScaler
|
| 7 |
+
from src.data.time_features import compute_batch_time_features
|
| 8 |
+
from src.models.blocks import GatedDeltaProductEncoder
|
| 9 |
+
from src.utils.utils import device
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def create_scaler(scaler_type: str, epsilon: float = 1e-3):
|
| 13 |
+
"""Create scaler instance based on type."""
|
| 14 |
+
if scaler_type == "custom_robust":
|
| 15 |
+
return RobustScaler(epsilon=epsilon)
|
| 16 |
+
elif scaler_type == "min_max":
|
| 17 |
+
return MinMaxScaler(epsilon=epsilon)
|
| 18 |
+
else:
|
| 19 |
+
raise ValueError(f"Unknown scaler: {scaler_type}")
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def apply_channel_noise(values: torch.Tensor, noise_scale: float = 0.1):
|
| 23 |
+
"""Add noise to constant channels to prevent model instability."""
|
| 24 |
+
is_constant = torch.all(values == values[:, 0:1, :], dim=1)
|
| 25 |
+
noise = torch.randn_like(values) * noise_scale * is_constant.unsqueeze(1)
|
| 26 |
+
return values + noise
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
class TimeSeriesModel(nn.Module):
|
| 30 |
+
"""Time series forecasting model combining embedding, encoding, and prediction."""
|
| 31 |
+
|
| 32 |
+
def __init__(
|
| 33 |
+
self,
|
| 34 |
+
# Core architecture
|
| 35 |
+
embed_size: int = 128,
|
| 36 |
+
num_encoder_layers: int = 2,
|
| 37 |
+
# Scaling and preprocessing
|
| 38 |
+
scaler: str = "custom_robust",
|
| 39 |
+
epsilon: float = 1e-3,
|
| 40 |
+
scaler_clamp_value: float = None,
|
| 41 |
+
handle_constants: bool = False,
|
| 42 |
+
# Time features
|
| 43 |
+
K_max: int = 6,
|
| 44 |
+
time_feature_config: dict = None,
|
| 45 |
+
encoding_dropout: float = 0.0,
|
| 46 |
+
# Encoder configuration
|
| 47 |
+
encoder_config: dict = None,
|
| 48 |
+
# Loss configuration
|
| 49 |
+
loss_type: str = "huber", # "huber", "quantile"
|
| 50 |
+
quantiles: list[float] = None,
|
| 51 |
+
**kwargs,
|
| 52 |
+
):
|
| 53 |
+
super().__init__()
|
| 54 |
+
|
| 55 |
+
# Core parameters
|
| 56 |
+
self.embed_size = embed_size
|
| 57 |
+
self.num_encoder_layers = num_encoder_layers
|
| 58 |
+
self.epsilon = epsilon
|
| 59 |
+
self.scaler_clamp_value = scaler_clamp_value
|
| 60 |
+
self.handle_constants = handle_constants
|
| 61 |
+
self.encoding_dropout = encoding_dropout
|
| 62 |
+
self.K_max = K_max
|
| 63 |
+
self.time_feature_config = time_feature_config or {}
|
| 64 |
+
self.encoder_config = encoder_config or {}
|
| 65 |
+
|
| 66 |
+
# Store loss parameters
|
| 67 |
+
self.loss_type = loss_type
|
| 68 |
+
self.quantiles = quantiles
|
| 69 |
+
if self.loss_type == "quantile" and self.quantiles is None:
|
| 70 |
+
raise ValueError("Quantiles must be provided for quantile loss.")
|
| 71 |
+
if self.quantiles:
|
| 72 |
+
self.register_buffer(
|
| 73 |
+
"qt", torch.tensor(self.quantiles, device=device).view(1, 1, 1, -1)
|
| 74 |
+
)
|
| 75 |
+
|
| 76 |
+
# Validate configuration before initialization
|
| 77 |
+
self._validate_configuration()
|
| 78 |
+
|
| 79 |
+
# Initialize components
|
| 80 |
+
self.scaler = create_scaler(scaler, epsilon)
|
| 81 |
+
self._init_embedding_layers()
|
| 82 |
+
self._init_encoder_layers(self.encoder_config, num_encoder_layers)
|
| 83 |
+
self._init_projection_layers()
|
| 84 |
+
|
| 85 |
+
def _validate_configuration(self):
|
| 86 |
+
"""Validate essential model configuration parameters."""
|
| 87 |
+
if "num_heads" not in self.encoder_config:
|
| 88 |
+
raise ValueError("encoder_config must contain 'num_heads' parameter")
|
| 89 |
+
|
| 90 |
+
if self.embed_size % self.encoder_config["num_heads"] != 0:
|
| 91 |
+
raise ValueError(
|
| 92 |
+
f"embed_size ({self.embed_size}) must be divisible by "
|
| 93 |
+
f"num_heads ({self.encoder_config['num_heads']})"
|
| 94 |
+
)
|
| 95 |
+
|
| 96 |
+
def _init_embedding_layers(self):
|
| 97 |
+
"""Initialize value and time feature embedding layers."""
|
| 98 |
+
self.expand_values = nn.Linear(1, self.embed_size, bias=True)
|
| 99 |
+
self.nan_embedding = nn.Parameter(
|
| 100 |
+
torch.randn(1, 1, 1, self.embed_size) / self.embed_size,
|
| 101 |
+
requires_grad=True,
|
| 102 |
+
)
|
| 103 |
+
self.time_feature_projection = nn.Linear(self.K_max, self.embed_size)
|
| 104 |
+
|
| 105 |
+
def _init_encoder_layers(self, encoder_config: dict, num_encoder_layers: int):
|
| 106 |
+
"""Initialize encoder layers."""
|
| 107 |
+
self.num_encoder_layers = num_encoder_layers
|
| 108 |
+
|
| 109 |
+
# Ensure encoder_config has token_embed_dim
|
| 110 |
+
encoder_config = encoder_config.copy()
|
| 111 |
+
encoder_config["token_embed_dim"] = self.embed_size
|
| 112 |
+
self.encoder_layers = nn.ModuleList(
|
| 113 |
+
[
|
| 114 |
+
GatedDeltaProductEncoder(layer_idx=layer_idx, **encoder_config)
|
| 115 |
+
for layer_idx in range(self.num_encoder_layers)
|
| 116 |
+
]
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
def _init_projection_layers(self):
|
| 120 |
+
if self.loss_type == "quantile":
|
| 121 |
+
output_dim = len(self.quantiles)
|
| 122 |
+
else:
|
| 123 |
+
output_dim = 1
|
| 124 |
+
self.final_output_layer = nn.Linear(self.embed_size, output_dim)
|
| 125 |
+
|
| 126 |
+
self.mlp = GatedMLP(
|
| 127 |
+
hidden_size=self.embed_size,
|
| 128 |
+
hidden_ratio=4,
|
| 129 |
+
hidden_act="swish",
|
| 130 |
+
fuse_swiglu=True,
|
| 131 |
+
)
|
| 132 |
+
# Initialize learnable initial hidden state for the first encoder layer
|
| 133 |
+
# This will be expanded to match batch size during forward pass
|
| 134 |
+
head_k_dim = self.embed_size // self.encoder_config["num_heads"]
|
| 135 |
+
|
| 136 |
+
# Get expand_v from encoder_config, default to 1.0 if not present
|
| 137 |
+
expand_v = self.encoder_config.get("expand_v", 1.0)
|
| 138 |
+
head_v_dim = int(head_k_dim * expand_v)
|
| 139 |
+
|
| 140 |
+
num_initial_hidden_states = self.num_encoder_layers
|
| 141 |
+
self.initial_hidden_state = nn.ParameterList(
|
| 142 |
+
[
|
| 143 |
+
nn.Parameter(
|
| 144 |
+
torch.randn(
|
| 145 |
+
1, self.encoder_config["num_heads"], head_k_dim, head_v_dim
|
| 146 |
+
)
|
| 147 |
+
/ head_k_dim,
|
| 148 |
+
requires_grad=True,
|
| 149 |
+
)
|
| 150 |
+
for _ in range(num_initial_hidden_states)
|
| 151 |
+
]
|
| 152 |
+
)
|
| 153 |
+
|
| 154 |
+
def _preprocess_data(self, data_container: BatchTimeSeriesContainer):
|
| 155 |
+
"""Extract data shapes and handle constants without padding."""
|
| 156 |
+
history_values = data_container.history_values
|
| 157 |
+
future_values = data_container.future_values
|
| 158 |
+
history_mask = data_container.history_mask
|
| 159 |
+
|
| 160 |
+
batch_size, history_length, num_channels = history_values.shape
|
| 161 |
+
future_length = future_values.shape[1] if future_values is not None else 0
|
| 162 |
+
|
| 163 |
+
# Handle constants
|
| 164 |
+
if self.handle_constants:
|
| 165 |
+
history_values = apply_channel_noise(history_values)
|
| 166 |
+
|
| 167 |
+
return {
|
| 168 |
+
"history_values": history_values,
|
| 169 |
+
"future_values": future_values,
|
| 170 |
+
"history_mask": history_mask,
|
| 171 |
+
"num_channels": num_channels,
|
| 172 |
+
"history_length": history_length,
|
| 173 |
+
"future_length": future_length,
|
| 174 |
+
"batch_size": batch_size,
|
| 175 |
+
}
|
| 176 |
+
|
| 177 |
+
def _compute_scaling(
|
| 178 |
+
self, history_values: torch.Tensor, history_mask: torch.Tensor = None
|
| 179 |
+
):
|
| 180 |
+
"""Compute scaling statistics and apply scaling."""
|
| 181 |
+
scale_statistics = self.scaler.compute_statistics(history_values, history_mask)
|
| 182 |
+
return scale_statistics
|
| 183 |
+
|
| 184 |
+
def _apply_scaling_and_masking(
|
| 185 |
+
self, values: torch.Tensor, scale_statistics: dict, mask: torch.Tensor = None
|
| 186 |
+
):
|
| 187 |
+
"""Apply scaling and optional masking to values."""
|
| 188 |
+
scaled_values = self.scaler.scale(values, scale_statistics)
|
| 189 |
+
|
| 190 |
+
if mask is not None:
|
| 191 |
+
scaled_values = scaled_values * mask.unsqueeze(-1).float()
|
| 192 |
+
|
| 193 |
+
if self.scaler_clamp_value is not None:
|
| 194 |
+
scaled_values = torch.clamp(
|
| 195 |
+
scaled_values, -self.scaler_clamp_value, self.scaler_clamp_value
|
| 196 |
+
)
|
| 197 |
+
|
| 198 |
+
return scaled_values
|
| 199 |
+
|
| 200 |
+
def _get_positional_embeddings(
|
| 201 |
+
self,
|
| 202 |
+
time_features: torch.Tensor,
|
| 203 |
+
num_channels: int,
|
| 204 |
+
batch_size: int,
|
| 205 |
+
drop_enc_allow: bool = False,
|
| 206 |
+
):
|
| 207 |
+
"""Generate positional embeddings from time features."""
|
| 208 |
+
seq_len = time_features.shape[1]
|
| 209 |
+
|
| 210 |
+
if (torch.rand(1).item() < self.encoding_dropout) and drop_enc_allow:
|
| 211 |
+
return torch.zeros(
|
| 212 |
+
batch_size, seq_len, num_channels, self.embed_size, device=device
|
| 213 |
+
).to(torch.float32)
|
| 214 |
+
|
| 215 |
+
pos_embed = self.time_feature_projection(time_features)
|
| 216 |
+
return pos_embed.unsqueeze(2).expand(-1, -1, num_channels, -1)
|
| 217 |
+
|
| 218 |
+
def _compute_embeddings(
|
| 219 |
+
self,
|
| 220 |
+
scaled_history: torch.Tensor,
|
| 221 |
+
history_pos_embed: torch.Tensor,
|
| 222 |
+
history_mask: torch.Tensor | None = None,
|
| 223 |
+
):
|
| 224 |
+
"""Compute value embeddings and combine with positional embeddings."""
|
| 225 |
+
|
| 226 |
+
nan_mask = torch.isnan(scaled_history)
|
| 227 |
+
history_for_embedding = torch.nan_to_num(scaled_history, nan=0.0)
|
| 228 |
+
channel_embeddings = self.expand_values(history_for_embedding.unsqueeze(-1))
|
| 229 |
+
channel_embeddings[nan_mask] = self.nan_embedding.to(channel_embeddings.dtype)
|
| 230 |
+
channel_embeddings = channel_embeddings + history_pos_embed
|
| 231 |
+
|
| 232 |
+
# Suppress padded time steps completely so padding is a pure batching artifact
|
| 233 |
+
# history_mask: [B, S] -> broadcast to [B, S, 1, 1]
|
| 234 |
+
if history_mask is not None:
|
| 235 |
+
mask_broadcast = (
|
| 236 |
+
history_mask.unsqueeze(-1).unsqueeze(-1).to(channel_embeddings.dtype)
|
| 237 |
+
)
|
| 238 |
+
channel_embeddings = channel_embeddings * mask_broadcast
|
| 239 |
+
|
| 240 |
+
batch_size, seq_len = scaled_history.shape[:2]
|
| 241 |
+
all_channels_embedded = channel_embeddings.view(batch_size, seq_len, -1)
|
| 242 |
+
|
| 243 |
+
return all_channels_embedded
|
| 244 |
+
|
| 245 |
+
def _generate_predictions(
|
| 246 |
+
self,
|
| 247 |
+
embedded: torch.Tensor,
|
| 248 |
+
target_pos_embed: torch.Tensor,
|
| 249 |
+
prediction_length: int,
|
| 250 |
+
num_channels: int,
|
| 251 |
+
history_mask: torch.Tensor = None,
|
| 252 |
+
):
|
| 253 |
+
"""
|
| 254 |
+
Generate predictions for all channels using vectorized operations.
|
| 255 |
+
"""
|
| 256 |
+
batch_size, seq_len, _ = embedded.shape
|
| 257 |
+
# embedded shape: [B, S, N*E] -> Reshape to [B, S, N, E]
|
| 258 |
+
embedded = embedded.view(batch_size, seq_len, num_channels, self.embed_size)
|
| 259 |
+
|
| 260 |
+
# Vectorize across channels by merging the batch and channel dimensions.
|
| 261 |
+
# [B, S, N, E] -> [B*N, S, E]
|
| 262 |
+
channel_embedded = (
|
| 263 |
+
embedded.permute(0, 2, 1, 3)
|
| 264 |
+
.contiguous()
|
| 265 |
+
.view(batch_size * num_channels, seq_len, self.embed_size)
|
| 266 |
+
)
|
| 267 |
+
|
| 268 |
+
# Reshape target positional embeddings similarly: [B, P, N, E] -> [B*N, P, E]
|
| 269 |
+
target_pos_embed = (
|
| 270 |
+
target_pos_embed.permute(0, 2, 1, 3)
|
| 271 |
+
.contiguous()
|
| 272 |
+
.view(batch_size * num_channels, prediction_length, self.embed_size)
|
| 273 |
+
)
|
| 274 |
+
x = channel_embedded
|
| 275 |
+
target_repr = target_pos_embed
|
| 276 |
+
x = torch.concatenate([x, target_repr], dim=1)
|
| 277 |
+
if self.encoder_config.get("weaving", True):
|
| 278 |
+
# initial hidden state is learnable
|
| 279 |
+
hidden_state = torch.zeros_like(
|
| 280 |
+
self.initial_hidden_state[0].repeat(batch_size * num_channels, 1, 1, 1)
|
| 281 |
+
)
|
| 282 |
+
for layer_idx, encoder_layer in enumerate(self.encoder_layers):
|
| 283 |
+
x, hidden_state = encoder_layer(
|
| 284 |
+
x,
|
| 285 |
+
hidden_state
|
| 286 |
+
+ self.initial_hidden_state[layer_idx].repeat(
|
| 287 |
+
batch_size * num_channels, 1, 1, 1
|
| 288 |
+
),
|
| 289 |
+
)
|
| 290 |
+
else:
|
| 291 |
+
# initial hidden state is separately learnable for each layer
|
| 292 |
+
for layer_idx, encoder_layer in enumerate(self.encoder_layers):
|
| 293 |
+
initial_hidden_state = self.initial_hidden_state[layer_idx].repeat(
|
| 294 |
+
batch_size * num_channels, 1, 1, 1
|
| 295 |
+
)
|
| 296 |
+
x, _ = encoder_layer(x, initial_hidden_state)
|
| 297 |
+
|
| 298 |
+
# Use the last prediction_length positions
|
| 299 |
+
prediction_embeddings = x[:, -prediction_length:, :]
|
| 300 |
+
|
| 301 |
+
predictions = self.final_output_layer(self.mlp(prediction_embeddings))
|
| 302 |
+
|
| 303 |
+
# Reshape output to handle quantiles
|
| 304 |
+
# Original shape: [B*N, P, Q] where Q is num_quantiles or 1
|
| 305 |
+
# Reshape the output back to [B, P, N, Q]
|
| 306 |
+
output_dim = len(self.quantiles) if self.loss_type == "quantile" else 1
|
| 307 |
+
predictions = predictions.view(
|
| 308 |
+
batch_size, num_channels, prediction_length, output_dim
|
| 309 |
+
)
|
| 310 |
+
predictions = predictions.permute(0, 2, 1, 3) # [B, P, N, Q]
|
| 311 |
+
# Squeeze the last dimension if not in quantile mode for backward compatibility
|
| 312 |
+
if self.loss_type != "quantile":
|
| 313 |
+
predictions = predictions.squeeze(-1) # [B, P, N]
|
| 314 |
+
return predictions
|
| 315 |
+
|
| 316 |
+
def forward(
|
| 317 |
+
self, data_container: BatchTimeSeriesContainer, drop_enc_allow: bool = False
|
| 318 |
+
):
|
| 319 |
+
"""Main forward pass."""
|
| 320 |
+
# Preprocess data
|
| 321 |
+
preprocessed = self._preprocess_data(data_container)
|
| 322 |
+
|
| 323 |
+
# Compute time features dynamically based on actual lengths
|
| 324 |
+
history_time_features, target_time_features = compute_batch_time_features(
|
| 325 |
+
start=data_container.start,
|
| 326 |
+
history_length=preprocessed["history_length"],
|
| 327 |
+
future_length=preprocessed["future_length"],
|
| 328 |
+
batch_size=preprocessed["batch_size"],
|
| 329 |
+
frequency=data_container.frequency,
|
| 330 |
+
K_max=self.K_max,
|
| 331 |
+
time_feature_config=self.time_feature_config,
|
| 332 |
+
)
|
| 333 |
+
|
| 334 |
+
# Compute scaling
|
| 335 |
+
scale_statistics = self._compute_scaling(
|
| 336 |
+
preprocessed["history_values"], preprocessed["history_mask"]
|
| 337 |
+
)
|
| 338 |
+
|
| 339 |
+
# Apply scaling
|
| 340 |
+
history_scaled = self._apply_scaling_and_masking(
|
| 341 |
+
preprocessed["history_values"],
|
| 342 |
+
scale_statistics,
|
| 343 |
+
preprocessed["history_mask"],
|
| 344 |
+
)
|
| 345 |
+
|
| 346 |
+
# Scale future values if present
|
| 347 |
+
future_scaled = None
|
| 348 |
+
if preprocessed["future_values"] is not None:
|
| 349 |
+
future_scaled = self.scaler.scale(
|
| 350 |
+
preprocessed["future_values"], scale_statistics
|
| 351 |
+
)
|
| 352 |
+
|
| 353 |
+
# Get positional embeddings
|
| 354 |
+
history_pos_embed = self._get_positional_embeddings(
|
| 355 |
+
history_time_features,
|
| 356 |
+
preprocessed["num_channels"],
|
| 357 |
+
preprocessed["batch_size"],
|
| 358 |
+
drop_enc_allow,
|
| 359 |
+
)
|
| 360 |
+
target_pos_embed = self._get_positional_embeddings(
|
| 361 |
+
target_time_features,
|
| 362 |
+
preprocessed["num_channels"],
|
| 363 |
+
preprocessed["batch_size"],
|
| 364 |
+
drop_enc_allow,
|
| 365 |
+
)
|
| 366 |
+
|
| 367 |
+
# Compute embeddings
|
| 368 |
+
history_embed = self._compute_embeddings(
|
| 369 |
+
history_scaled, history_pos_embed, preprocessed["history_mask"]
|
| 370 |
+
)
|
| 371 |
+
|
| 372 |
+
# Generate predictions
|
| 373 |
+
predictions = self._generate_predictions(
|
| 374 |
+
history_embed,
|
| 375 |
+
target_pos_embed,
|
| 376 |
+
preprocessed["future_length"],
|
| 377 |
+
preprocessed["num_channels"],
|
| 378 |
+
preprocessed["history_mask"],
|
| 379 |
+
)
|
| 380 |
+
|
| 381 |
+
return {
|
| 382 |
+
"result": predictions,
|
| 383 |
+
"scale_statistics": scale_statistics,
|
| 384 |
+
"future_scaled": future_scaled,
|
| 385 |
+
"history_length": preprocessed["history_length"],
|
| 386 |
+
"future_length": preprocessed["future_length"],
|
| 387 |
+
}
|
| 388 |
+
|
| 389 |
+
def _quantile_loss(self, y_true: torch.Tensor, y_pred: torch.Tensor):
|
| 390 |
+
"""
|
| 391 |
+
Compute the quantile loss.
|
| 392 |
+
y_true: [B, P, N]
|
| 393 |
+
y_pred: [B, P, N, Q]
|
| 394 |
+
"""
|
| 395 |
+
# Add a dimension to y_true to match y_pred: [B, P, N] -> [B, P, N, 1]
|
| 396 |
+
y_true = y_true.unsqueeze(-1)
|
| 397 |
+
|
| 398 |
+
# Calculate errors
|
| 399 |
+
errors = y_true - y_pred
|
| 400 |
+
|
| 401 |
+
# Calculate quantile loss
|
| 402 |
+
# The max operator implements the two cases of the quantile loss formula
|
| 403 |
+
loss = torch.max((self.qt - 1) * errors, self.qt * errors)
|
| 404 |
+
|
| 405 |
+
# Average the loss across all dimensions
|
| 406 |
+
return loss.mean()
|
| 407 |
+
|
| 408 |
+
def compute_loss(self, y_true: torch.Tensor, y_pred: dict):
|
| 409 |
+
"""Compute loss between predictions and scaled ground truth."""
|
| 410 |
+
predictions = y_pred["result"]
|
| 411 |
+
scale_statistics = y_pred["scale_statistics"]
|
| 412 |
+
|
| 413 |
+
if y_true is None:
|
| 414 |
+
return torch.tensor(0.0, device=predictions.device)
|
| 415 |
+
|
| 416 |
+
future_scaled = self.scaler.scale(y_true, scale_statistics)
|
| 417 |
+
|
| 418 |
+
if self.loss_type == "huber":
|
| 419 |
+
if predictions.shape != future_scaled.shape:
|
| 420 |
+
raise ValueError(
|
| 421 |
+
f"Shape mismatch for Huber loss: predictions {predictions.shape} vs future_scaled {future_scaled.shape}"
|
| 422 |
+
)
|
| 423 |
+
return nn.functional.huber_loss(predictions, future_scaled)
|
| 424 |
+
elif self.loss_type == "quantile":
|
| 425 |
+
return self._quantile_loss(future_scaled, predictions)
|
| 426 |
+
else:
|
| 427 |
+
raise ValueError(f"Unknown loss type: {self.loss_type}")
|
src/optim/lr_scheduler.py
ADDED
|
@@ -0,0 +1,360 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# src/utils/lr_scheduler.py
|
| 2 |
+
|
| 3 |
+
import math
|
| 4 |
+
from enum import Enum
|
| 5 |
+
from functools import partial
|
| 6 |
+
from typing import Optional
|
| 7 |
+
|
| 8 |
+
from torch.optim import Optimizer
|
| 9 |
+
from torch.optim.lr_scheduler import LambdaLR
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class SchedulerType(Enum):
|
| 13 |
+
"""Enumeration of available learning rate schedulers."""
|
| 14 |
+
|
| 15 |
+
COSINE = "cosine"
|
| 16 |
+
COSINE_WITH_WARMUP = "cosine_with_warmup"
|
| 17 |
+
COSINE_WITH_RESTARTS = "cosine_with_restarts"
|
| 18 |
+
WARMUP_STABLE_DECAY = "warmup_stable_decay"
|
| 19 |
+
POLYNOMIAL_WITH_WARMUP = "polynomial_with_warmup"
|
| 20 |
+
LINEAR_WITH_WARMUP = "linear_with_warmup"
|
| 21 |
+
CONSTANT_WITH_WARMUP = "constant_with_warmup"
|
| 22 |
+
INVERSE_SQRT = "inverse_sqrt"
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def _get_warmup_stable_decay_lr_lambda(
|
| 26 |
+
current_step: int,
|
| 27 |
+
*,
|
| 28 |
+
num_warmup_steps: int,
|
| 29 |
+
num_stable_steps: int,
|
| 30 |
+
num_training_steps: int,
|
| 31 |
+
min_lr_ratio: float = 0.001,
|
| 32 |
+
decay_type: str = "cosine",
|
| 33 |
+
):
|
| 34 |
+
"""
|
| 35 |
+
Learning rate lambda function for Warmup-Stable-Decay (WSD) schedule.
|
| 36 |
+
|
| 37 |
+
This scheduler implements three phases:
|
| 38 |
+
1. Warmup: Linear increase from 0 to peak learning rate
|
| 39 |
+
2. Stable: Constant learning rate for majority of training
|
| 40 |
+
3. Decay: Gradual decrease using cosine or linear decay
|
| 41 |
+
|
| 42 |
+
Args:
|
| 43 |
+
current_step: Current training step
|
| 44 |
+
num_warmup_steps: Number of warmup steps
|
| 45 |
+
num_stable_steps: Number of stable learning rate steps
|
| 46 |
+
num_training_steps: Total number of training steps
|
| 47 |
+
min_lr_ratio: Minimum learning rate as ratio of peak learning rate
|
| 48 |
+
decay_type: Type of decay schedule ("cosine" or "linear")
|
| 49 |
+
"""
|
| 50 |
+
if current_step < num_warmup_steps:
|
| 51 |
+
# Warmup phase: linear increase
|
| 52 |
+
return float(current_step) / float(max(1, num_warmup_steps))
|
| 53 |
+
|
| 54 |
+
elif current_step < num_warmup_steps + num_stable_steps:
|
| 55 |
+
# Stable phase: constant learning rate
|
| 56 |
+
return 1.0
|
| 57 |
+
|
| 58 |
+
else:
|
| 59 |
+
# Decay phase
|
| 60 |
+
decay_steps = num_training_steps - num_warmup_steps - num_stable_steps
|
| 61 |
+
if decay_steps <= 0:
|
| 62 |
+
return max(min_lr_ratio, 1.0)
|
| 63 |
+
|
| 64 |
+
progress = (current_step - num_warmup_steps - num_stable_steps) / decay_steps
|
| 65 |
+
progress = min(progress, 1.0) # Clamp to [0, 1]
|
| 66 |
+
|
| 67 |
+
if decay_type == "cosine":
|
| 68 |
+
# Cosine decay
|
| 69 |
+
decay_factor = 0.5 * (1.0 + math.cos(math.pi * progress))
|
| 70 |
+
return max(min_lr_ratio, decay_factor)
|
| 71 |
+
elif decay_type == "linear":
|
| 72 |
+
# Linear decay
|
| 73 |
+
decay_factor = 1.0 - progress
|
| 74 |
+
return max(min_lr_ratio, decay_factor)
|
| 75 |
+
else:
|
| 76 |
+
raise ValueError(f"Unknown decay_type: {decay_type}")
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
def get_warmup_stable_decay_schedule(
|
| 80 |
+
optimizer: Optimizer,
|
| 81 |
+
num_warmup_steps: int,
|
| 82 |
+
num_stable_steps: int,
|
| 83 |
+
num_training_steps: int,
|
| 84 |
+
min_lr_ratio: float = 0.01,
|
| 85 |
+
decay_type: str = "cosine",
|
| 86 |
+
last_epoch: int = -1,
|
| 87 |
+
):
|
| 88 |
+
"""
|
| 89 |
+
Create a Warmup-Stable-Decay learning rate schedule.
|
| 90 |
+
|
| 91 |
+
This scheduler is particularly well-suited for foundation model training as it:
|
| 92 |
+
- Provides stable learning during the majority of training
|
| 93 |
+
- Doesn't require pre-committing to exact training duration
|
| 94 |
+
- Allows for extended training without aggressive decay
|
| 95 |
+
|
| 96 |
+
Args:
|
| 97 |
+
optimizer: The optimizer for which to schedule the learning rate
|
| 98 |
+
num_warmup_steps: Number of steps for warmup phase
|
| 99 |
+
num_stable_steps: Number of steps for stable learning rate phase
|
| 100 |
+
num_training_steps: Total number of training steps
|
| 101 |
+
min_lr_ratio: Minimum learning rate as fraction of peak learning rate
|
| 102 |
+
decay_type: Type of decay ("cosine" or "linear")
|
| 103 |
+
last_epoch: The index of the last epoch when resuming training
|
| 104 |
+
|
| 105 |
+
Returns:
|
| 106 |
+
torch.optim.lr_scheduler.LambdaLR with the WSD schedule
|
| 107 |
+
"""
|
| 108 |
+
lr_lambda = partial(
|
| 109 |
+
_get_warmup_stable_decay_lr_lambda,
|
| 110 |
+
num_warmup_steps=num_warmup_steps,
|
| 111 |
+
num_stable_steps=num_stable_steps,
|
| 112 |
+
num_training_steps=num_training_steps,
|
| 113 |
+
min_lr_ratio=min_lr_ratio,
|
| 114 |
+
decay_type=decay_type,
|
| 115 |
+
)
|
| 116 |
+
return LambdaLR(optimizer, lr_lambda, last_epoch=last_epoch)
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
def _get_cosine_schedule_with_warmup_lr_lambda(
|
| 120 |
+
current_step: int,
|
| 121 |
+
*,
|
| 122 |
+
num_warmup_steps: int,
|
| 123 |
+
num_training_steps: int,
|
| 124 |
+
num_cycles: float = 0.5,
|
| 125 |
+
min_lr_ratio: float = 0.0,
|
| 126 |
+
):
|
| 127 |
+
"""Enhanced cosine schedule with configurable minimum learning rate."""
|
| 128 |
+
if current_step < num_warmup_steps:
|
| 129 |
+
return float(current_step) / float(max(1, num_warmup_steps))
|
| 130 |
+
|
| 131 |
+
progress = float(current_step - num_warmup_steps) / float(
|
| 132 |
+
max(1, num_training_steps - num_warmup_steps)
|
| 133 |
+
)
|
| 134 |
+
cosine_factor = 0.5 * (1.0 + math.cos(math.pi * float(num_cycles) * 2.0 * progress))
|
| 135 |
+
return max(min_lr_ratio, cosine_factor)
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
def get_enhanced_cosine_schedule_with_warmup(
|
| 139 |
+
optimizer: Optimizer,
|
| 140 |
+
num_warmup_steps: int,
|
| 141 |
+
num_training_steps: int,
|
| 142 |
+
num_cycles: float = 0.5,
|
| 143 |
+
min_lr_ratio: float = 0.01,
|
| 144 |
+
last_epoch: int = -1,
|
| 145 |
+
):
|
| 146 |
+
"""
|
| 147 |
+
Enhanced cosine schedule with warmup and configurable minimum learning rate.
|
| 148 |
+
|
| 149 |
+
Args:
|
| 150 |
+
optimizer: The optimizer for which to schedule the learning rate
|
| 151 |
+
num_warmup_steps: Number of steps for warmup phase
|
| 152 |
+
num_training_steps: Total number of training steps
|
| 153 |
+
num_cycles: Number of cosine cycles (0.5 = half cosine)
|
| 154 |
+
min_lr_ratio: Minimum learning rate as fraction of peak learning rate
|
| 155 |
+
last_epoch: The index of the last epoch when resuming training
|
| 156 |
+
"""
|
| 157 |
+
lr_lambda = partial(
|
| 158 |
+
_get_cosine_schedule_with_warmup_lr_lambda,
|
| 159 |
+
num_warmup_steps=num_warmup_steps,
|
| 160 |
+
num_training_steps=num_training_steps,
|
| 161 |
+
num_cycles=num_cycles,
|
| 162 |
+
min_lr_ratio=min_lr_ratio,
|
| 163 |
+
)
|
| 164 |
+
return LambdaLR(optimizer, lr_lambda, last_epoch=last_epoch)
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
def _get_cosine_with_restarts_lr_lambda(
|
| 168 |
+
current_step: int,
|
| 169 |
+
*,
|
| 170 |
+
num_warmup_steps: int,
|
| 171 |
+
num_training_steps: int,
|
| 172 |
+
num_cycles: int = 1,
|
| 173 |
+
min_lr_ratio: float = 0.0,
|
| 174 |
+
):
|
| 175 |
+
"""Cosine schedule with hard restarts and configurable minimum learning rate."""
|
| 176 |
+
if current_step < num_warmup_steps:
|
| 177 |
+
return float(current_step) / float(max(1, num_warmup_steps))
|
| 178 |
+
|
| 179 |
+
progress = float(current_step - num_warmup_steps) / float(
|
| 180 |
+
max(1, num_training_steps - num_warmup_steps)
|
| 181 |
+
)
|
| 182 |
+
if progress >= 1.0:
|
| 183 |
+
return min_lr_ratio
|
| 184 |
+
|
| 185 |
+
cosine_factor = 0.5 * (
|
| 186 |
+
1.0 + math.cos(math.pi * ((float(num_cycles) * progress) % 1.0))
|
| 187 |
+
)
|
| 188 |
+
return max(min_lr_ratio, cosine_factor)
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
def get_cosine_with_restarts_schedule(
|
| 192 |
+
optimizer: Optimizer,
|
| 193 |
+
num_warmup_steps: int,
|
| 194 |
+
num_training_steps: int,
|
| 195 |
+
num_cycles: int = 4,
|
| 196 |
+
min_lr_ratio: float = 0.01,
|
| 197 |
+
last_epoch: int = -1,
|
| 198 |
+
):
|
| 199 |
+
"""
|
| 200 |
+
Cosine schedule with hard restarts.
|
| 201 |
+
|
| 202 |
+
Args:
|
| 203 |
+
optimizer: The optimizer for which to schedule the learning rate
|
| 204 |
+
num_warmup_steps: Number of steps for warmup phase
|
| 205 |
+
num_training_steps: Total number of training steps
|
| 206 |
+
num_cycles: Number of restart cycles
|
| 207 |
+
min_lr_ratio: Minimum learning rate as fraction of peak learning rate
|
| 208 |
+
last_epoch: The index of the last epoch when resuming training
|
| 209 |
+
"""
|
| 210 |
+
lr_lambda = partial(
|
| 211 |
+
_get_cosine_with_restarts_lr_lambda,
|
| 212 |
+
num_warmup_steps=num_warmup_steps,
|
| 213 |
+
num_training_steps=num_training_steps,
|
| 214 |
+
num_cycles=num_cycles,
|
| 215 |
+
min_lr_ratio=min_lr_ratio,
|
| 216 |
+
)
|
| 217 |
+
return LambdaLR(optimizer, lr_lambda, last_epoch=last_epoch)
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
# Scheduler registry for easy lookup
|
| 221 |
+
SCHEDULER_REGISTRY = {
|
| 222 |
+
SchedulerType.WARMUP_STABLE_DECAY: get_warmup_stable_decay_schedule,
|
| 223 |
+
SchedulerType.COSINE_WITH_WARMUP: get_enhanced_cosine_schedule_with_warmup,
|
| 224 |
+
SchedulerType.COSINE_WITH_RESTARTS: get_cosine_with_restarts_schedule,
|
| 225 |
+
}
|
| 226 |
+
|
| 227 |
+
|
| 228 |
+
def get_scheduler(
|
| 229 |
+
scheduler_type: str | SchedulerType,
|
| 230 |
+
optimizer: Optimizer,
|
| 231 |
+
num_warmup_steps: int,
|
| 232 |
+
num_training_steps: int,
|
| 233 |
+
scheduler_kwargs: Optional[dict] = None,
|
| 234 |
+
):
|
| 235 |
+
"""
|
| 236 |
+
Unified interface to create learning rate schedulers.
|
| 237 |
+
|
| 238 |
+
Args:
|
| 239 |
+
scheduler_type: Type of scheduler to create
|
| 240 |
+
optimizer: The optimizer to schedule
|
| 241 |
+
num_warmup_steps: Number of warmup steps
|
| 242 |
+
num_training_steps: Total training steps
|
| 243 |
+
scheduler_kwargs: Additional scheduler-specific parameters
|
| 244 |
+
|
| 245 |
+
Returns:
|
| 246 |
+
Configured learning rate scheduler
|
| 247 |
+
"""
|
| 248 |
+
if isinstance(scheduler_type, str):
|
| 249 |
+
scheduler_type = SchedulerType(scheduler_type)
|
| 250 |
+
|
| 251 |
+
if scheduler_kwargs is None:
|
| 252 |
+
scheduler_kwargs = {}
|
| 253 |
+
|
| 254 |
+
if scheduler_type not in SCHEDULER_REGISTRY:
|
| 255 |
+
raise ValueError(f"Unsupported scheduler type: {scheduler_type}")
|
| 256 |
+
|
| 257 |
+
scheduler_func = SCHEDULER_REGISTRY[scheduler_type]
|
| 258 |
+
return scheduler_func(
|
| 259 |
+
optimizer=optimizer,
|
| 260 |
+
num_warmup_steps=num_warmup_steps,
|
| 261 |
+
num_training_steps=num_training_steps,
|
| 262 |
+
**scheduler_kwargs,
|
| 263 |
+
)
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
class WarmupStableDecayScheduler:
|
| 267 |
+
"""
|
| 268 |
+
Alternative implementation as a standalone scheduler class.
|
| 269 |
+
|
| 270 |
+
This provides more flexibility and better state management for
|
| 271 |
+
complex training scenarios with checkpointing.
|
| 272 |
+
"""
|
| 273 |
+
|
| 274 |
+
def __init__(
|
| 275 |
+
self,
|
| 276 |
+
optimizer: Optimizer,
|
| 277 |
+
num_warmup_steps: int,
|
| 278 |
+
num_stable_steps: int,
|
| 279 |
+
total_steps: int,
|
| 280 |
+
min_lr_ratio: float = 0.01,
|
| 281 |
+
decay_type: str = "cosine",
|
| 282 |
+
verbose: bool = False,
|
| 283 |
+
):
|
| 284 |
+
self.optimizer = optimizer
|
| 285 |
+
self.num_warmup_steps = num_warmup_steps
|
| 286 |
+
self.num_stable_steps = num_stable_steps
|
| 287 |
+
self.total_steps = total_steps
|
| 288 |
+
self.min_lr_ratio = min_lr_ratio
|
| 289 |
+
self.decay_type = decay_type
|
| 290 |
+
self.verbose = verbose
|
| 291 |
+
|
| 292 |
+
# Store initial learning rates
|
| 293 |
+
self.base_lrs = [group["lr"] for group in optimizer.param_groups]
|
| 294 |
+
self.current_step = 0
|
| 295 |
+
|
| 296 |
+
def get_lr_factor(self, step: int) -> float:
|
| 297 |
+
"""Calculate the learning rate multiplication factor for given step."""
|
| 298 |
+
if step < self.num_warmup_steps:
|
| 299 |
+
# Warmup phase
|
| 300 |
+
return step / max(1, self.num_warmup_steps)
|
| 301 |
+
elif step < self.num_warmup_steps + self.num_stable_steps:
|
| 302 |
+
# Stable phase
|
| 303 |
+
return 1.0
|
| 304 |
+
else:
|
| 305 |
+
# Decay phase
|
| 306 |
+
decay_steps = (
|
| 307 |
+
self.total_steps - self.num_warmup_steps - self.num_stable_steps
|
| 308 |
+
)
|
| 309 |
+
if decay_steps <= 0:
|
| 310 |
+
return max(self.min_lr_ratio, 1.0)
|
| 311 |
+
|
| 312 |
+
progress = (
|
| 313 |
+
step - self.num_warmup_steps - self.num_stable_steps
|
| 314 |
+
) / decay_steps
|
| 315 |
+
progress = min(progress, 1.0)
|
| 316 |
+
|
| 317 |
+
if self.decay_type == "cosine":
|
| 318 |
+
decay_factor = 0.5 * (1.0 + math.cos(math.pi * progress))
|
| 319 |
+
elif self.decay_type == "linear":
|
| 320 |
+
decay_factor = 1.0 - progress
|
| 321 |
+
else:
|
| 322 |
+
raise ValueError(f"Unknown decay_type: {self.decay_type}")
|
| 323 |
+
|
| 324 |
+
return max(self.min_lr_ratio, decay_factor)
|
| 325 |
+
|
| 326 |
+
def step(self):
|
| 327 |
+
"""Update learning rates for all parameter groups."""
|
| 328 |
+
lr_factor = self.get_lr_factor(self.current_step)
|
| 329 |
+
|
| 330 |
+
for param_group, base_lr in zip(self.optimizer.param_groups, self.base_lrs):
|
| 331 |
+
param_group["lr"] = base_lr * lr_factor
|
| 332 |
+
|
| 333 |
+
if self.verbose and self.current_step % 1000 == 0:
|
| 334 |
+
phase = self.get_phase()
|
| 335 |
+
print(
|
| 336 |
+
f"Step {self.current_step}: LR factor = {lr_factor:.6f}, Phase = {phase}"
|
| 337 |
+
)
|
| 338 |
+
|
| 339 |
+
self.current_step += 1
|
| 340 |
+
|
| 341 |
+
def get_phase(self) -> str:
|
| 342 |
+
"""Get current training phase."""
|
| 343 |
+
if self.current_step < self.num_warmup_steps:
|
| 344 |
+
return "warmup"
|
| 345 |
+
elif self.current_step < self.num_warmup_steps + self.num_stable_steps:
|
| 346 |
+
return "stable"
|
| 347 |
+
else:
|
| 348 |
+
return "decay"
|
| 349 |
+
|
| 350 |
+
def state_dict(self) -> dict:
|
| 351 |
+
"""Return scheduler state for checkpointing."""
|
| 352 |
+
return {
|
| 353 |
+
"current_step": self.current_step,
|
| 354 |
+
"base_lrs": self.base_lrs,
|
| 355 |
+
}
|
| 356 |
+
|
| 357 |
+
def load_state_dict(self, state_dict: dict):
|
| 358 |
+
"""Load scheduler state from checkpoint."""
|
| 359 |
+
self.current_step = state_dict["current_step"]
|
| 360 |
+
self.base_lrs = state_dict["base_lrs"]
|
src/plotting/__init__.py
ADDED
|
File without changes
|
src/plotting/gift_eval_utils.py
ADDED
|
@@ -0,0 +1,215 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
from typing import List, Optional, Tuple
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import pandas as pd
|
| 6 |
+
from gluonts.model.forecast import QuantileForecast
|
| 7 |
+
|
| 8 |
+
from src.data.frequency import parse_frequency
|
| 9 |
+
from src.plotting.plot_multivariate_timeseries import (
|
| 10 |
+
plot_multivariate_timeseries,
|
| 11 |
+
)
|
| 12 |
+
|
| 13 |
+
logger = logging.getLogger(__name__)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def _prepare_data_for_plotting(
|
| 17 |
+
input_data: dict, label_data: dict, max_context_length: int
|
| 18 |
+
):
|
| 19 |
+
history_values = np.asarray(input_data["target"], dtype=np.float32)
|
| 20 |
+
future_values = np.asarray(label_data["target"], dtype=np.float32)
|
| 21 |
+
start_period = input_data["start"]
|
| 22 |
+
|
| 23 |
+
def ensure_time_first(arr: np.ndarray) -> np.ndarray:
|
| 24 |
+
if arr.ndim == 1:
|
| 25 |
+
return arr.reshape(-1, 1)
|
| 26 |
+
elif arr.ndim == 2:
|
| 27 |
+
if arr.shape[0] < arr.shape[1]:
|
| 28 |
+
return arr.T
|
| 29 |
+
return arr
|
| 30 |
+
else:
|
| 31 |
+
return arr.reshape(arr.shape[-1], -1).T
|
| 32 |
+
|
| 33 |
+
history_values = ensure_time_first(history_values)
|
| 34 |
+
future_values = ensure_time_first(future_values)
|
| 35 |
+
|
| 36 |
+
if max_context_length is not None and history_values.shape[0] > max_context_length:
|
| 37 |
+
history_values = history_values[-max_context_length:]
|
| 38 |
+
|
| 39 |
+
# Convert Period to Timestamp if needed
|
| 40 |
+
start_timestamp = (
|
| 41 |
+
start_period.to_timestamp()
|
| 42 |
+
if hasattr(start_period, "to_timestamp")
|
| 43 |
+
else pd.Timestamp(start_period)
|
| 44 |
+
)
|
| 45 |
+
return history_values, future_values, start_timestamp
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def _extract_quantile_predictions(
|
| 49 |
+
forecast,
|
| 50 |
+
) -> Tuple[Optional[np.ndarray], Optional[np.ndarray], Optional[np.ndarray]]:
|
| 51 |
+
def ensure_2d_time_first(arr):
|
| 52 |
+
if arr is None:
|
| 53 |
+
return None
|
| 54 |
+
arr = np.asarray(arr)
|
| 55 |
+
if arr.ndim == 1:
|
| 56 |
+
return arr.reshape(-1, 1)
|
| 57 |
+
elif arr.ndim == 2:
|
| 58 |
+
return arr
|
| 59 |
+
else:
|
| 60 |
+
return arr.reshape(arr.shape[0], -1)
|
| 61 |
+
|
| 62 |
+
if isinstance(forecast, QuantileForecast):
|
| 63 |
+
try:
|
| 64 |
+
median_pred = forecast.quantile(0.5)
|
| 65 |
+
try:
|
| 66 |
+
lower_bound = forecast.quantile(0.1)
|
| 67 |
+
upper_bound = forecast.quantile(0.9)
|
| 68 |
+
except (KeyError, ValueError):
|
| 69 |
+
lower_bound = None
|
| 70 |
+
upper_bound = None
|
| 71 |
+
median_pred = ensure_2d_time_first(median_pred)
|
| 72 |
+
lower_bound = ensure_2d_time_first(lower_bound)
|
| 73 |
+
upper_bound = ensure_2d_time_first(upper_bound)
|
| 74 |
+
return median_pred, lower_bound, upper_bound
|
| 75 |
+
except Exception:
|
| 76 |
+
try:
|
| 77 |
+
median_pred = forecast.quantile(0.5)
|
| 78 |
+
median_pred = ensure_2d_time_first(median_pred)
|
| 79 |
+
return median_pred, None, None
|
| 80 |
+
except Exception:
|
| 81 |
+
return None, None, None
|
| 82 |
+
else:
|
| 83 |
+
try:
|
| 84 |
+
samples = forecast.samples
|
| 85 |
+
if samples.ndim == 1:
|
| 86 |
+
median_pred = samples
|
| 87 |
+
elif samples.ndim == 2:
|
| 88 |
+
if samples.shape[0] == 1:
|
| 89 |
+
median_pred = samples[0]
|
| 90 |
+
else:
|
| 91 |
+
median_pred = np.median(samples, axis=0)
|
| 92 |
+
elif samples.ndim == 3:
|
| 93 |
+
median_pred = np.median(samples, axis=0)
|
| 94 |
+
else:
|
| 95 |
+
median_pred = samples[0] if len(samples) > 0 else samples
|
| 96 |
+
median_pred = ensure_2d_time_first(median_pred)
|
| 97 |
+
return median_pred, None, None
|
| 98 |
+
except Exception:
|
| 99 |
+
return None, None, None
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def _create_plot(
|
| 103 |
+
input_data: dict,
|
| 104 |
+
label_data: dict,
|
| 105 |
+
forecast,
|
| 106 |
+
dataset_full_name: str,
|
| 107 |
+
dataset_freq: str,
|
| 108 |
+
max_context_length: int,
|
| 109 |
+
title: Optional[str] = None,
|
| 110 |
+
):
|
| 111 |
+
try:
|
| 112 |
+
history_values, future_values, start_timestamp = _prepare_data_for_plotting(
|
| 113 |
+
input_data, label_data, max_context_length
|
| 114 |
+
)
|
| 115 |
+
median_pred, lower_bound, upper_bound = _extract_quantile_predictions(forecast)
|
| 116 |
+
if median_pred is None:
|
| 117 |
+
logger.warning(f"Could not extract predictions for {dataset_full_name}")
|
| 118 |
+
return None
|
| 119 |
+
|
| 120 |
+
def ensure_compatible_shape(pred_arr, target_arr):
|
| 121 |
+
if pred_arr is None:
|
| 122 |
+
return None
|
| 123 |
+
pred_arr = np.asarray(pred_arr)
|
| 124 |
+
target_arr = np.asarray(target_arr)
|
| 125 |
+
if pred_arr.ndim == 1:
|
| 126 |
+
pred_arr = pred_arr.reshape(-1, 1)
|
| 127 |
+
if target_arr.ndim == 1:
|
| 128 |
+
target_arr = target_arr.reshape(-1, 1)
|
| 129 |
+
if pred_arr.shape != target_arr.shape:
|
| 130 |
+
if pred_arr.shape[0] == target_arr.shape[0]:
|
| 131 |
+
if pred_arr.shape[1] == 1 and target_arr.shape[1] > 1:
|
| 132 |
+
pred_arr = np.broadcast_to(pred_arr, target_arr.shape)
|
| 133 |
+
elif pred_arr.shape[1] > 1 and target_arr.shape[1] == 1:
|
| 134 |
+
pred_arr = pred_arr[:, :1]
|
| 135 |
+
elif pred_arr.shape[1] == target_arr.shape[1]:
|
| 136 |
+
min_time = min(pred_arr.shape[0], target_arr.shape[0])
|
| 137 |
+
pred_arr = pred_arr[:min_time]
|
| 138 |
+
else:
|
| 139 |
+
if pred_arr.T.shape == target_arr.shape:
|
| 140 |
+
pred_arr = pred_arr.T
|
| 141 |
+
else:
|
| 142 |
+
if pred_arr.size >= target_arr.shape[0]:
|
| 143 |
+
pred_arr = pred_arr.flatten()[
|
| 144 |
+
: target_arr.shape[0]
|
| 145 |
+
].reshape(-1, 1)
|
| 146 |
+
if target_arr.shape[1] > 1:
|
| 147 |
+
pred_arr = np.broadcast_to(pred_arr, target_arr.shape)
|
| 148 |
+
return pred_arr
|
| 149 |
+
|
| 150 |
+
median_pred = ensure_compatible_shape(median_pred, future_values)
|
| 151 |
+
lower_bound = ensure_compatible_shape(lower_bound, future_values)
|
| 152 |
+
upper_bound = ensure_compatible_shape(upper_bound, future_values)
|
| 153 |
+
|
| 154 |
+
title = title or f"GIFT-Eval: {dataset_full_name}"
|
| 155 |
+
frequency = parse_frequency(dataset_freq)
|
| 156 |
+
fig = plot_multivariate_timeseries(
|
| 157 |
+
history_values=history_values,
|
| 158 |
+
future_values=future_values,
|
| 159 |
+
predicted_values=median_pred,
|
| 160 |
+
lower_bound=lower_bound,
|
| 161 |
+
upper_bound=upper_bound,
|
| 162 |
+
start=start_timestamp,
|
| 163 |
+
frequency=frequency,
|
| 164 |
+
title=title,
|
| 165 |
+
show=False,
|
| 166 |
+
)
|
| 167 |
+
return fig
|
| 168 |
+
except Exception as e:
|
| 169 |
+
logger.warning(f"Failed to create plot for {dataset_full_name}: {e}")
|
| 170 |
+
return None
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
def create_plots_for_dataset(
|
| 174 |
+
forecasts: List,
|
| 175 |
+
test_data,
|
| 176 |
+
dataset_metadata,
|
| 177 |
+
max_plots: int,
|
| 178 |
+
max_context_length: int,
|
| 179 |
+
) -> List[Tuple[object, str]]:
|
| 180 |
+
input_data_list = list(test_data.input)
|
| 181 |
+
label_data_list = list(test_data.label)
|
| 182 |
+
num_plots = min(len(forecasts), max_plots)
|
| 183 |
+
logger.info(
|
| 184 |
+
f"Creating {num_plots} plots for {getattr(dataset_metadata, 'full_name', str(dataset_metadata))}"
|
| 185 |
+
)
|
| 186 |
+
|
| 187 |
+
figures_with_names: List[Tuple[object, str]] = []
|
| 188 |
+
for i in range(num_plots):
|
| 189 |
+
try:
|
| 190 |
+
forecast = forecasts[i]
|
| 191 |
+
input_data = input_data_list[i]
|
| 192 |
+
label_data = label_data_list[i]
|
| 193 |
+
title = (
|
| 194 |
+
f"GIFT-Eval: {dataset_metadata.full_name} - Window {i + 1}/{num_plots}"
|
| 195 |
+
if hasattr(dataset_metadata, "full_name")
|
| 196 |
+
else f"Window {i + 1}/{num_plots}"
|
| 197 |
+
)
|
| 198 |
+
fig = _create_plot(
|
| 199 |
+
input_data=input_data,
|
| 200 |
+
label_data=label_data,
|
| 201 |
+
forecast=forecast,
|
| 202 |
+
dataset_full_name=getattr(dataset_metadata, "full_name", "dataset"),
|
| 203 |
+
dataset_freq=getattr(dataset_metadata, "freq", "D"),
|
| 204 |
+
max_context_length=max_context_length,
|
| 205 |
+
title=title,
|
| 206 |
+
)
|
| 207 |
+
if fig is not None:
|
| 208 |
+
filename = (
|
| 209 |
+
f"{getattr(dataset_metadata, 'freq', 'D')}_window_{i + 1:03d}.png"
|
| 210 |
+
)
|
| 211 |
+
figures_with_names.append((fig, filename))
|
| 212 |
+
except Exception as e:
|
| 213 |
+
logger.warning(f"Error creating plot for window {i + 1}: {e}")
|
| 214 |
+
continue
|
| 215 |
+
return figures_with_names
|
src/plotting/plot_timeseries.py
ADDED
|
@@ -0,0 +1,292 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
from typing import List, Optional, Tuple, Union
|
| 3 |
+
|
| 4 |
+
import matplotlib.pyplot as plt
|
| 5 |
+
import numpy as np
|
| 6 |
+
import pandas as pd
|
| 7 |
+
import torch
|
| 8 |
+
import torchmetrics
|
| 9 |
+
from matplotlib.figure import Figure
|
| 10 |
+
|
| 11 |
+
from src.data.containers import BatchTimeSeriesContainer
|
| 12 |
+
from src.data.frequency import Frequency
|
| 13 |
+
|
| 14 |
+
logger = logging.getLogger(__name__)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def calculate_smape(y_true: np.ndarray, y_pred: np.ndarray) -> float:
|
| 18 |
+
"""Calculate Symmetric Mean Absolute Percentage Error (SMAPE)."""
|
| 19 |
+
pred_tensor = torch.from_numpy(y_pred).float()
|
| 20 |
+
true_tensor = torch.from_numpy(y_true).float()
|
| 21 |
+
return torchmetrics.SymmetricMeanAbsolutePercentageError()(
|
| 22 |
+
pred_tensor, true_tensor
|
| 23 |
+
).item()
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def _create_date_ranges(
|
| 27 |
+
start: Optional[Union[np.datetime64, pd.Timestamp]],
|
| 28 |
+
frequency: Optional[Union[Frequency, str]],
|
| 29 |
+
history_length: int,
|
| 30 |
+
prediction_length: int,
|
| 31 |
+
) -> Tuple[pd.DatetimeIndex, pd.DatetimeIndex]:
|
| 32 |
+
"""Create date ranges for history and future periods."""
|
| 33 |
+
if start is not None and frequency is not None:
|
| 34 |
+
start_timestamp = pd.Timestamp(start)
|
| 35 |
+
pandas_freq = frequency.to_pandas_freq(for_date_range=True)
|
| 36 |
+
|
| 37 |
+
history_dates = pd.date_range(
|
| 38 |
+
start=start_timestamp, periods=history_length, freq=pandas_freq
|
| 39 |
+
)
|
| 40 |
+
|
| 41 |
+
if prediction_length > 0:
|
| 42 |
+
next_timestamp = history_dates[-1] + pd.tseries.frequencies.to_offset(
|
| 43 |
+
pandas_freq
|
| 44 |
+
)
|
| 45 |
+
future_dates = pd.date_range(
|
| 46 |
+
start=next_timestamp, periods=prediction_length, freq=pandas_freq
|
| 47 |
+
)
|
| 48 |
+
else:
|
| 49 |
+
future_dates = pd.DatetimeIndex([])
|
| 50 |
+
else:
|
| 51 |
+
# Fallback to default daily frequency
|
| 52 |
+
history_dates = pd.date_range(
|
| 53 |
+
end=pd.Timestamp.now(), periods=history_length, freq="D"
|
| 54 |
+
)
|
| 55 |
+
|
| 56 |
+
if prediction_length > 0:
|
| 57 |
+
future_dates = pd.date_range(
|
| 58 |
+
start=history_dates[-1] + pd.Timedelta(days=1),
|
| 59 |
+
periods=prediction_length,
|
| 60 |
+
freq="D",
|
| 61 |
+
)
|
| 62 |
+
else:
|
| 63 |
+
future_dates = pd.DatetimeIndex([])
|
| 64 |
+
|
| 65 |
+
return history_dates, future_dates
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def _plot_single_channel(
|
| 69 |
+
ax: plt.Axes,
|
| 70 |
+
channel_idx: int,
|
| 71 |
+
history_dates: pd.DatetimeIndex,
|
| 72 |
+
future_dates: pd.DatetimeIndex,
|
| 73 |
+
history_values: np.ndarray,
|
| 74 |
+
future_values: Optional[np.ndarray] = None,
|
| 75 |
+
predicted_values: Optional[np.ndarray] = None,
|
| 76 |
+
lower_bound: Optional[np.ndarray] = None,
|
| 77 |
+
upper_bound: Optional[np.ndarray] = None,
|
| 78 |
+
) -> None:
|
| 79 |
+
"""Plot a single channel's time series data."""
|
| 80 |
+
# Plot history
|
| 81 |
+
ax.plot(
|
| 82 |
+
history_dates, history_values[:, channel_idx], color="black", label="History"
|
| 83 |
+
)
|
| 84 |
+
|
| 85 |
+
# Plot ground truth future
|
| 86 |
+
if future_values is not None:
|
| 87 |
+
ax.plot(
|
| 88 |
+
future_dates,
|
| 89 |
+
future_values[:, channel_idx],
|
| 90 |
+
color="blue",
|
| 91 |
+
label="Ground Truth",
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
# Plot predictions
|
| 95 |
+
if predicted_values is not None:
|
| 96 |
+
ax.plot(
|
| 97 |
+
future_dates,
|
| 98 |
+
predicted_values[:, channel_idx],
|
| 99 |
+
color="orange",
|
| 100 |
+
linestyle="--",
|
| 101 |
+
label="Prediction (Median)",
|
| 102 |
+
)
|
| 103 |
+
|
| 104 |
+
# Plot uncertainty band
|
| 105 |
+
if lower_bound is not None and upper_bound is not None:
|
| 106 |
+
ax.fill_between(
|
| 107 |
+
future_dates,
|
| 108 |
+
lower_bound[:, channel_idx],
|
| 109 |
+
upper_bound[:, channel_idx],
|
| 110 |
+
color="orange",
|
| 111 |
+
alpha=0.2,
|
| 112 |
+
label="Uncertainty Band",
|
| 113 |
+
)
|
| 114 |
+
|
| 115 |
+
ax.set_title(f"Channel {channel_idx + 1}")
|
| 116 |
+
ax.grid(True, which="both", linestyle="--", linewidth=0.5)
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
def _setup_figure(num_channels: int) -> Tuple[Figure, List[plt.Axes]]:
|
| 120 |
+
"""Create and configure the matplotlib figure and axes."""
|
| 121 |
+
fig, axes = plt.subplots(
|
| 122 |
+
num_channels, 1, figsize=(15, 3 * num_channels), sharex=True
|
| 123 |
+
)
|
| 124 |
+
if num_channels == 1:
|
| 125 |
+
axes = [axes]
|
| 126 |
+
return fig, axes
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
def _finalize_plot(
|
| 130 |
+
fig: Figure,
|
| 131 |
+
axes: List[plt.Axes],
|
| 132 |
+
title: Optional[str] = None,
|
| 133 |
+
smape_value: Optional[float] = None,
|
| 134 |
+
output_file: Optional[str] = None,
|
| 135 |
+
show: bool = True,
|
| 136 |
+
) -> None:
|
| 137 |
+
"""Add legend, title, and save/show the plot."""
|
| 138 |
+
# Create legend from first axis
|
| 139 |
+
handles, labels = axes[0].get_legend_handles_labels()
|
| 140 |
+
fig.legend(handles, labels, loc="upper right")
|
| 141 |
+
|
| 142 |
+
# Set title with optional SMAPE
|
| 143 |
+
if title:
|
| 144 |
+
if smape_value is not None:
|
| 145 |
+
title = f"{title} | SMAPE: {smape_value:.4f}"
|
| 146 |
+
fig.suptitle(title, fontsize=16)
|
| 147 |
+
|
| 148 |
+
# Adjust layout
|
| 149 |
+
plt.tight_layout(rect=[0, 0.03, 1, 0.95] if title else None)
|
| 150 |
+
|
| 151 |
+
# Save and/or show
|
| 152 |
+
if output_file:
|
| 153 |
+
plt.savefig(output_file, dpi=300)
|
| 154 |
+
if show:
|
| 155 |
+
plt.show()
|
| 156 |
+
else:
|
| 157 |
+
plt.close(fig)
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
def plot_multivariate_timeseries(
|
| 161 |
+
history_values: np.ndarray,
|
| 162 |
+
future_values: Optional[np.ndarray] = None,
|
| 163 |
+
predicted_values: Optional[np.ndarray] = None,
|
| 164 |
+
start: Optional[Union[np.datetime64, pd.Timestamp]] = None,
|
| 165 |
+
frequency: Optional[Union[Frequency, str]] = None,
|
| 166 |
+
title: Optional[str] = None,
|
| 167 |
+
output_file: Optional[str] = None,
|
| 168 |
+
show: bool = True,
|
| 169 |
+
lower_bound: Optional[np.ndarray] = None,
|
| 170 |
+
upper_bound: Optional[np.ndarray] = None,
|
| 171 |
+
) -> Figure:
|
| 172 |
+
"""Plot a multivariate time series with history, future, predictions, and uncertainty bands."""
|
| 173 |
+
# Calculate SMAPE if both predicted and true values are available
|
| 174 |
+
smape_value = None
|
| 175 |
+
if predicted_values is not None and future_values is not None:
|
| 176 |
+
try:
|
| 177 |
+
smape_value = calculate_smape(future_values, predicted_values)
|
| 178 |
+
except Exception as e:
|
| 179 |
+
logger.warning(f"Failed to calculate SMAPE: {str(e)}")
|
| 180 |
+
|
| 181 |
+
# Extract dimensions
|
| 182 |
+
num_channels = history_values.shape[1]
|
| 183 |
+
history_length = history_values.shape[0]
|
| 184 |
+
prediction_length = (
|
| 185 |
+
predicted_values.shape[0]
|
| 186 |
+
if predicted_values is not None
|
| 187 |
+
else (future_values.shape[0] if future_values is not None else 0)
|
| 188 |
+
)
|
| 189 |
+
|
| 190 |
+
# Create date ranges
|
| 191 |
+
history_dates, future_dates = _create_date_ranges(
|
| 192 |
+
start, frequency, history_length, prediction_length
|
| 193 |
+
)
|
| 194 |
+
|
| 195 |
+
# Setup figure
|
| 196 |
+
fig, axes = _setup_figure(num_channels)
|
| 197 |
+
|
| 198 |
+
# Plot each channel
|
| 199 |
+
for i in range(num_channels):
|
| 200 |
+
_plot_single_channel(
|
| 201 |
+
ax=axes[i],
|
| 202 |
+
channel_idx=i,
|
| 203 |
+
history_dates=history_dates,
|
| 204 |
+
future_dates=future_dates,
|
| 205 |
+
history_values=history_values,
|
| 206 |
+
future_values=future_values,
|
| 207 |
+
predicted_values=predicted_values,
|
| 208 |
+
lower_bound=lower_bound,
|
| 209 |
+
upper_bound=upper_bound,
|
| 210 |
+
)
|
| 211 |
+
|
| 212 |
+
# Finalize plot
|
| 213 |
+
_finalize_plot(fig, axes, title, smape_value, output_file, show)
|
| 214 |
+
|
| 215 |
+
return fig
|
| 216 |
+
|
| 217 |
+
|
| 218 |
+
def _extract_quantile_predictions(
|
| 219 |
+
predicted_values: np.ndarray,
|
| 220 |
+
model_quantiles: List[float],
|
| 221 |
+
) -> Tuple[Optional[np.ndarray], Optional[np.ndarray], Optional[np.ndarray]]:
|
| 222 |
+
"""Extract median, lower, and upper bound predictions from quantile output."""
|
| 223 |
+
try:
|
| 224 |
+
median_idx = model_quantiles.index(0.5)
|
| 225 |
+
lower_idx = model_quantiles.index(0.1)
|
| 226 |
+
upper_idx = model_quantiles.index(0.9)
|
| 227 |
+
|
| 228 |
+
median_preds = predicted_values[..., median_idx]
|
| 229 |
+
lower_bound = predicted_values[..., lower_idx]
|
| 230 |
+
upper_bound = predicted_values[..., upper_idx]
|
| 231 |
+
|
| 232 |
+
return median_preds, lower_bound, upper_bound
|
| 233 |
+
except (ValueError, IndexError):
|
| 234 |
+
logger.warning(
|
| 235 |
+
"Could not find 0.1, 0.5, 0.9 quantiles for plotting. Using median of available quantiles."
|
| 236 |
+
)
|
| 237 |
+
median_preds = predicted_values[..., predicted_values.shape[-1] // 2]
|
| 238 |
+
return median_preds, None, None
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
def plot_from_container(
|
| 242 |
+
batch: BatchTimeSeriesContainer,
|
| 243 |
+
sample_idx: int,
|
| 244 |
+
predicted_values: Optional[np.ndarray] = None,
|
| 245 |
+
model_quantiles: Optional[List[float]] = None,
|
| 246 |
+
title: Optional[str] = None,
|
| 247 |
+
output_file: Optional[str] = None,
|
| 248 |
+
show: bool = True,
|
| 249 |
+
) -> Figure:
|
| 250 |
+
"""Plot a single sample from a BatchTimeSeriesContainer with proper quantile handling."""
|
| 251 |
+
# Extract data for the specific sample
|
| 252 |
+
history_values = batch.history_values[sample_idx].cpu().numpy()
|
| 253 |
+
future_values = batch.future_values[sample_idx].cpu().numpy()
|
| 254 |
+
|
| 255 |
+
# Process predictions
|
| 256 |
+
if predicted_values is not None:
|
| 257 |
+
# Handle batch vs single sample predictions
|
| 258 |
+
if predicted_values.ndim >= 3 or (
|
| 259 |
+
predicted_values.ndim == 2
|
| 260 |
+
and predicted_values.shape[0] > future_values.shape[0]
|
| 261 |
+
):
|
| 262 |
+
sample_preds = predicted_values[sample_idx]
|
| 263 |
+
else:
|
| 264 |
+
sample_preds = predicted_values
|
| 265 |
+
|
| 266 |
+
# Extract quantile information if available
|
| 267 |
+
if model_quantiles:
|
| 268 |
+
median_preds, lower_bound, upper_bound = _extract_quantile_predictions(
|
| 269 |
+
sample_preds, model_quantiles
|
| 270 |
+
)
|
| 271 |
+
else:
|
| 272 |
+
median_preds = sample_preds
|
| 273 |
+
lower_bound = None
|
| 274 |
+
upper_bound = None
|
| 275 |
+
else:
|
| 276 |
+
median_preds = None
|
| 277 |
+
lower_bound = None
|
| 278 |
+
upper_bound = None
|
| 279 |
+
|
| 280 |
+
# Create the plot
|
| 281 |
+
return plot_multivariate_timeseries(
|
| 282 |
+
history_values=history_values,
|
| 283 |
+
future_values=future_values,
|
| 284 |
+
predicted_values=median_preds,
|
| 285 |
+
start=batch.start[sample_idx],
|
| 286 |
+
frequency=batch.frequency[sample_idx],
|
| 287 |
+
title=title,
|
| 288 |
+
output_file=output_file,
|
| 289 |
+
show=show,
|
| 290 |
+
lower_bound=lower_bound,
|
| 291 |
+
upper_bound=upper_bound,
|
| 292 |
+
)
|
src/synthetic_generation/__init__.py
ADDED
|
File without changes
|
src/synthetic_generation/abstract_classes.py
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from abc import ABC, abstractmethod
|
| 2 |
+
from typing import Any, Dict, Optional
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
|
| 7 |
+
from src.data.containers import TimeSeriesContainer
|
| 8 |
+
from src.data.frequency import (
|
| 9 |
+
select_safe_random_frequency,
|
| 10 |
+
select_safe_start_date,
|
| 11 |
+
)
|
| 12 |
+
from src.synthetic_generation.generator_params import GeneratorParams
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class AbstractTimeSeriesGenerator(ABC):
|
| 16 |
+
"""
|
| 17 |
+
Abstract base class for synthetic time series generators.
|
| 18 |
+
"""
|
| 19 |
+
|
| 20 |
+
@abstractmethod
|
| 21 |
+
def generate_time_series(self, random_seed: Optional[int] = None) -> np.ndarray:
|
| 22 |
+
"""
|
| 23 |
+
Generate synthetic time series data.
|
| 24 |
+
|
| 25 |
+
Parameters
|
| 26 |
+
----------
|
| 27 |
+
random_seed : int, optional
|
| 28 |
+
Random seed for reproducibility.
|
| 29 |
+
|
| 30 |
+
Returns
|
| 31 |
+
-------
|
| 32 |
+
np.ndarray
|
| 33 |
+
Time series values of shape (length,) for univariate or
|
| 34 |
+
(length, num_channels) for multivariate time series.
|
| 35 |
+
"""
|
| 36 |
+
pass
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
class GeneratorWrapper:
|
| 40 |
+
"""
|
| 41 |
+
Unified base class for all generator wrappers, using a GeneratorParams dataclass
|
| 42 |
+
for configuration. Provides parameter sampling, validation, and batch formatting utilities.
|
| 43 |
+
"""
|
| 44 |
+
|
| 45 |
+
def __init__(self, params: GeneratorParams):
|
| 46 |
+
"""
|
| 47 |
+
Initialize the GeneratorWrapper with a GeneratorParams dataclass.
|
| 48 |
+
|
| 49 |
+
Parameters
|
| 50 |
+
----------
|
| 51 |
+
params : GeneratorParams
|
| 52 |
+
Dataclass instance containing all generator configuration parameters.
|
| 53 |
+
"""
|
| 54 |
+
self.params = params
|
| 55 |
+
self._set_random_seeds(self.params.global_seed)
|
| 56 |
+
|
| 57 |
+
def _set_random_seeds(self, seed: int) -> None:
|
| 58 |
+
# For parameter sampling, we want diversity across batches even with similar seeds
|
| 59 |
+
# Use a hash of the generator class name to ensure different generators get different parameter sequences
|
| 60 |
+
param_seed = seed + hash(self.__class__.__name__) % 2**31
|
| 61 |
+
self.rng = np.random.default_rng(param_seed)
|
| 62 |
+
|
| 63 |
+
# Set global numpy and torch seeds for deterministic behavior in underlying generators
|
| 64 |
+
np.random.seed(seed)
|
| 65 |
+
torch.manual_seed(seed)
|
| 66 |
+
|
| 67 |
+
def _sample_parameters(self, batch_size: int) -> Dict[str, Any]:
|
| 68 |
+
"""
|
| 69 |
+
Sample parameters with total_length fixed and history_length calculated.
|
| 70 |
+
|
| 71 |
+
Returns
|
| 72 |
+
-------
|
| 73 |
+
Dict[str, Any]
|
| 74 |
+
Dictionary containing sampled parameter values where
|
| 75 |
+
history_length = total_length - future_length.
|
| 76 |
+
"""
|
| 77 |
+
|
| 78 |
+
# Select a suitable frequency based on the total length
|
| 79 |
+
frequency = [
|
| 80 |
+
select_safe_random_frequency(self.params.length, self.rng)
|
| 81 |
+
for _ in range(batch_size)
|
| 82 |
+
]
|
| 83 |
+
start = [
|
| 84 |
+
select_safe_start_date(self.params.length, frequency[i], self.rng)
|
| 85 |
+
for i in range(batch_size)
|
| 86 |
+
]
|
| 87 |
+
|
| 88 |
+
return {
|
| 89 |
+
"frequency": frequency,
|
| 90 |
+
"start": start,
|
| 91 |
+
}
|
| 92 |
+
|
| 93 |
+
@abstractmethod
|
| 94 |
+
def generate_batch(
|
| 95 |
+
self, batch_size: int, seed: Optional[int] = None, **kwargs
|
| 96 |
+
) -> TimeSeriesContainer:
|
| 97 |
+
raise NotImplementedError("Subclasses must implement generate_batch()")
|
src/synthetic_generation/anomalies/anomaly_generator.py
ADDED
|
@@ -0,0 +1,293 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List, Optional, Set
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
|
| 5 |
+
from src.synthetic_generation.abstract_classes import AbstractTimeSeriesGenerator
|
| 6 |
+
from src.synthetic_generation.generator_params import (
|
| 7 |
+
AnomalyGeneratorParams,
|
| 8 |
+
AnomalyType,
|
| 9 |
+
MagnitudePattern,
|
| 10 |
+
)
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class AnomalyGenerator(AbstractTimeSeriesGenerator):
|
| 14 |
+
"""
|
| 15 |
+
Generator for synthetic time series with realistic spike anomalies.
|
| 16 |
+
|
| 17 |
+
Creates clean constant baseline signals with periodic spike patterns that
|
| 18 |
+
resemble real-world time series behavior, including clustering and magnitude patterns.
|
| 19 |
+
"""
|
| 20 |
+
|
| 21 |
+
def __init__(self, params: AnomalyGeneratorParams):
|
| 22 |
+
"""
|
| 23 |
+
Initialize the AnomalyGenerator.
|
| 24 |
+
|
| 25 |
+
Parameters
|
| 26 |
+
----------
|
| 27 |
+
params : AnomalyGeneratorParams
|
| 28 |
+
Configuration parameters for anomaly generation.
|
| 29 |
+
"""
|
| 30 |
+
self.params = params
|
| 31 |
+
|
| 32 |
+
def _determine_spike_direction(self) -> AnomalyType:
|
| 33 |
+
"""
|
| 34 |
+
Determine if this series will have only up or only down spikes.
|
| 35 |
+
|
| 36 |
+
Returns
|
| 37 |
+
-------
|
| 38 |
+
AnomalyType
|
| 39 |
+
Either SPIKE_UP or SPIKE_DOWN for the entire series.
|
| 40 |
+
"""
|
| 41 |
+
if np.random.random() < self.params.spike_direction_probability:
|
| 42 |
+
return AnomalyType.SPIKE_UP
|
| 43 |
+
else:
|
| 44 |
+
return AnomalyType.SPIKE_DOWN
|
| 45 |
+
|
| 46 |
+
def _generate_spike_positions(self) -> List[List[int]]:
|
| 47 |
+
"""
|
| 48 |
+
Generate spike positions:
|
| 49 |
+
- Always create uniformly spaced single spikes (base schedule)
|
| 50 |
+
- With 25% probability: add clusters (1-3 extra spikes) near a fraction of base spikes
|
| 51 |
+
- With 25% probability: add single random spikes across the series
|
| 52 |
+
|
| 53 |
+
Returns
|
| 54 |
+
-------
|
| 55 |
+
List[List[int]]
|
| 56 |
+
List of spike events, where each event is a list of positions
|
| 57 |
+
(single spike = [pos], cluster = [pos, pos+offset, ...]).
|
| 58 |
+
"""
|
| 59 |
+
# Base uniform schedule (no jitter/variance)
|
| 60 |
+
base_period = np.random.randint(*self.params.base_period_range)
|
| 61 |
+
start_position = base_period // 2
|
| 62 |
+
base_positions = list(range(start_position, self.params.length, base_period))
|
| 63 |
+
|
| 64 |
+
# Start with single-spike events at base positions
|
| 65 |
+
spike_events: List[List[int]] = [[pos] for pos in base_positions]
|
| 66 |
+
|
| 67 |
+
if not base_positions:
|
| 68 |
+
return spike_events
|
| 69 |
+
|
| 70 |
+
# Decide series type
|
| 71 |
+
series_draw = np.random.random()
|
| 72 |
+
|
| 73 |
+
# 25%: augment with clusters near some base spikes
|
| 74 |
+
if series_draw < self.params.cluster_series_probability:
|
| 75 |
+
num_base_events = len(base_positions)
|
| 76 |
+
num_to_augment = max(
|
| 77 |
+
1, int(round(self.params.cluster_event_fraction * num_base_events))
|
| 78 |
+
)
|
| 79 |
+
num_to_augment = min(num_to_augment, num_base_events)
|
| 80 |
+
|
| 81 |
+
chosen_indices = (
|
| 82 |
+
np.random.choice(num_base_events, size=num_to_augment, replace=False)
|
| 83 |
+
if num_to_augment > 0
|
| 84 |
+
else np.array([], dtype=int)
|
| 85 |
+
)
|
| 86 |
+
|
| 87 |
+
for idx in chosen_indices:
|
| 88 |
+
base_pos = base_positions[int(idx)]
|
| 89 |
+
# Number of additional spikes (1..3) per selected event
|
| 90 |
+
num_additional = np.random.randint(
|
| 91 |
+
*self.params.cluster_additional_spikes_range
|
| 92 |
+
)
|
| 93 |
+
if num_additional <= 0:
|
| 94 |
+
continue
|
| 95 |
+
|
| 96 |
+
# Draw offsets around base spike and exclude zero to avoid duplicates
|
| 97 |
+
offsets = np.random.randint(
|
| 98 |
+
self.params.cluster_offset_range[0],
|
| 99 |
+
self.params.cluster_offset_range[1],
|
| 100 |
+
size=num_additional,
|
| 101 |
+
)
|
| 102 |
+
offsets = [int(off) for off in offsets if off != 0]
|
| 103 |
+
|
| 104 |
+
cluster_positions: Set[int] = set([base_pos])
|
| 105 |
+
for off in offsets:
|
| 106 |
+
pos = base_pos + off
|
| 107 |
+
if 0 <= pos < self.params.length:
|
| 108 |
+
cluster_positions.add(pos)
|
| 109 |
+
|
| 110 |
+
spike_events[int(idx)] = sorted(cluster_positions)
|
| 111 |
+
|
| 112 |
+
# Next 25%: add random single spikes across the series
|
| 113 |
+
elif series_draw < (
|
| 114 |
+
self.params.cluster_series_probability
|
| 115 |
+
+ self.params.random_series_probability
|
| 116 |
+
):
|
| 117 |
+
num_base_events = len(base_positions)
|
| 118 |
+
num_random = int(
|
| 119 |
+
round(self.params.random_spike_fraction_of_base * num_base_events)
|
| 120 |
+
)
|
| 121 |
+
if num_random > 0:
|
| 122 |
+
all_indices = np.arange(self.params.length)
|
| 123 |
+
base_array = np.array(base_positions, dtype=int)
|
| 124 |
+
candidates = np.setdiff1d(all_indices, base_array, assume_unique=False)
|
| 125 |
+
if candidates.size > 0:
|
| 126 |
+
choose_n = min(num_random, candidates.size)
|
| 127 |
+
rand_positions = np.random.choice(
|
| 128 |
+
candidates, size=choose_n, replace=False
|
| 129 |
+
)
|
| 130 |
+
for pos in rand_positions:
|
| 131 |
+
spike_events.append([int(pos)])
|
| 132 |
+
|
| 133 |
+
# Else: 50% clean series (uniform singles only)
|
| 134 |
+
|
| 135 |
+
return spike_events
|
| 136 |
+
|
| 137 |
+
def _generate_spike_magnitudes(self, total_spikes: int) -> np.ndarray:
|
| 138 |
+
"""
|
| 139 |
+
Generate spike magnitudes based on the configured pattern.
|
| 140 |
+
|
| 141 |
+
Parameters
|
| 142 |
+
----------
|
| 143 |
+
total_spikes : int
|
| 144 |
+
Total number of individual spikes to generate magnitudes for.
|
| 145 |
+
|
| 146 |
+
Returns
|
| 147 |
+
-------
|
| 148 |
+
np.ndarray
|
| 149 |
+
Array of spike magnitudes.
|
| 150 |
+
"""
|
| 151 |
+
base_magnitude = np.random.uniform(*self.params.base_magnitude_range)
|
| 152 |
+
magnitudes = np.zeros(total_spikes)
|
| 153 |
+
|
| 154 |
+
if self.params.magnitude_pattern == MagnitudePattern.CONSTANT:
|
| 155 |
+
# All spikes have similar magnitude with small noise
|
| 156 |
+
magnitudes = np.full(total_spikes, base_magnitude)
|
| 157 |
+
noise = np.random.normal(
|
| 158 |
+
0, self.params.magnitude_noise * base_magnitude, total_spikes
|
| 159 |
+
)
|
| 160 |
+
magnitudes += noise
|
| 161 |
+
|
| 162 |
+
elif self.params.magnitude_pattern == MagnitudePattern.INCREASING:
|
| 163 |
+
# Magnitude increases over time
|
| 164 |
+
trend = np.linspace(
|
| 165 |
+
0,
|
| 166 |
+
self.params.magnitude_trend_strength * base_magnitude * total_spikes,
|
| 167 |
+
total_spikes,
|
| 168 |
+
)
|
| 169 |
+
magnitudes = base_magnitude + trend
|
| 170 |
+
|
| 171 |
+
elif self.params.magnitude_pattern == MagnitudePattern.DECREASING:
|
| 172 |
+
# Magnitude decreases over time
|
| 173 |
+
trend = np.linspace(
|
| 174 |
+
0,
|
| 175 |
+
-self.params.magnitude_trend_strength * base_magnitude * total_spikes,
|
| 176 |
+
total_spikes,
|
| 177 |
+
)
|
| 178 |
+
magnitudes = base_magnitude + trend
|
| 179 |
+
|
| 180 |
+
elif self.params.magnitude_pattern == MagnitudePattern.CYCLICAL:
|
| 181 |
+
# Cyclical magnitude pattern
|
| 182 |
+
cycle_length = int(total_spikes * self.params.cyclical_period_ratio)
|
| 183 |
+
if cycle_length == 0:
|
| 184 |
+
cycle_length = max(1, total_spikes // 4)
|
| 185 |
+
|
| 186 |
+
phase = np.linspace(
|
| 187 |
+
0, 2 * np.pi * total_spikes / cycle_length, total_spikes
|
| 188 |
+
)
|
| 189 |
+
cyclical_component = 0.3 * base_magnitude * np.sin(phase)
|
| 190 |
+
magnitudes = base_magnitude + cyclical_component
|
| 191 |
+
|
| 192 |
+
elif self.params.magnitude_pattern == MagnitudePattern.RANDOM_BOUNDED:
|
| 193 |
+
# Random with correlation between consecutive spikes
|
| 194 |
+
magnitudes[0] = base_magnitude
|
| 195 |
+
|
| 196 |
+
for i in range(1, total_spikes):
|
| 197 |
+
# Correlated random walk
|
| 198 |
+
prev_magnitude = magnitudes[i - 1]
|
| 199 |
+
random_component = np.random.normal(0, 0.2 * base_magnitude)
|
| 200 |
+
|
| 201 |
+
magnitudes[i] = (
|
| 202 |
+
self.params.magnitude_correlation * prev_magnitude
|
| 203 |
+
+ (1 - self.params.magnitude_correlation) * base_magnitude
|
| 204 |
+
+ random_component
|
| 205 |
+
)
|
| 206 |
+
|
| 207 |
+
# Add noise to all patterns
|
| 208 |
+
noise = np.random.normal(
|
| 209 |
+
0, self.params.magnitude_noise * base_magnitude, total_spikes
|
| 210 |
+
)
|
| 211 |
+
magnitudes += noise
|
| 212 |
+
|
| 213 |
+
# Ensure magnitudes are positive and within reasonable bounds
|
| 214 |
+
min_magnitude = 0.1 * base_magnitude
|
| 215 |
+
max_magnitude = 3.0 * base_magnitude
|
| 216 |
+
magnitudes = np.clip(magnitudes, min_magnitude, max_magnitude)
|
| 217 |
+
|
| 218 |
+
return magnitudes
|
| 219 |
+
|
| 220 |
+
def _inject_spike_anomalies(
|
| 221 |
+
self, signal: np.ndarray, spike_direction: AnomalyType
|
| 222 |
+
) -> np.ndarray:
|
| 223 |
+
"""
|
| 224 |
+
Inject spike anomalies into the clean signal using realistic patterns.
|
| 225 |
+
|
| 226 |
+
Parameters
|
| 227 |
+
----------
|
| 228 |
+
signal : np.ndarray
|
| 229 |
+
Clean baseline signal to inject spikes into.
|
| 230 |
+
spike_direction : AnomalyType
|
| 231 |
+
Direction of spikes for this series (all up or all down).
|
| 232 |
+
|
| 233 |
+
Returns
|
| 234 |
+
-------
|
| 235 |
+
np.ndarray
|
| 236 |
+
Signal with injected spike anomalies.
|
| 237 |
+
"""
|
| 238 |
+
anomalous_signal = signal.copy()
|
| 239 |
+
|
| 240 |
+
# Generate spike positions based on pattern
|
| 241 |
+
spike_events = self._generate_spike_positions()
|
| 242 |
+
|
| 243 |
+
# Flatten spike events to get total number of individual spikes
|
| 244 |
+
all_positions = []
|
| 245 |
+
for event in spike_events:
|
| 246 |
+
all_positions.extend(event)
|
| 247 |
+
|
| 248 |
+
if not all_positions:
|
| 249 |
+
return anomalous_signal
|
| 250 |
+
|
| 251 |
+
# Generate magnitudes for all spikes
|
| 252 |
+
magnitudes = self._generate_spike_magnitudes(len(all_positions))
|
| 253 |
+
|
| 254 |
+
# Inject spikes
|
| 255 |
+
for i, position in enumerate(all_positions):
|
| 256 |
+
if position < len(anomalous_signal):
|
| 257 |
+
magnitude = magnitudes[i]
|
| 258 |
+
|
| 259 |
+
if spike_direction == AnomalyType.SPIKE_UP:
|
| 260 |
+
anomalous_signal[position] += magnitude
|
| 261 |
+
else: # SPIKE_DOWN
|
| 262 |
+
anomalous_signal[position] -= magnitude
|
| 263 |
+
|
| 264 |
+
return anomalous_signal
|
| 265 |
+
|
| 266 |
+
def generate_time_series(self, random_seed: Optional[int] = None) -> np.ndarray:
|
| 267 |
+
"""
|
| 268 |
+
Generate a synthetic time series with realistic spike anomalies.
|
| 269 |
+
|
| 270 |
+
Parameters
|
| 271 |
+
----------
|
| 272 |
+
random_seed : int, optional
|
| 273 |
+
Random seed for reproducibility.
|
| 274 |
+
|
| 275 |
+
Returns
|
| 276 |
+
-------
|
| 277 |
+
np.ndarray
|
| 278 |
+
Generated time series of shape (length,) - clean baseline with periodic spikes.
|
| 279 |
+
"""
|
| 280 |
+
if random_seed is not None:
|
| 281 |
+
np.random.seed(random_seed)
|
| 282 |
+
|
| 283 |
+
# Generate clean baseline signal (constant level)
|
| 284 |
+
baseline_level = np.random.uniform(*self.params.base_level_range)
|
| 285 |
+
signal = np.full(self.params.length, baseline_level)
|
| 286 |
+
|
| 287 |
+
# Determine spike direction for this series (all up or all down)
|
| 288 |
+
spike_direction = self._determine_spike_direction()
|
| 289 |
+
|
| 290 |
+
# Inject spike anomalies with realistic patterns
|
| 291 |
+
anomalous_signal = self._inject_spike_anomalies(signal, spike_direction)
|
| 292 |
+
|
| 293 |
+
return anomalous_signal
|
src/synthetic_generation/anomalies/anomaly_generator_wrapper.py
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Optional
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
|
| 5 |
+
from src.data.containers import TimeSeriesContainer
|
| 6 |
+
from src.synthetic_generation.abstract_classes import GeneratorWrapper
|
| 7 |
+
from src.synthetic_generation.anomalies.anomaly_generator import AnomalyGenerator
|
| 8 |
+
from src.synthetic_generation.generator_params import AnomalyGeneratorParams
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class AnomalyGeneratorWrapper(GeneratorWrapper):
|
| 12 |
+
"""
|
| 13 |
+
Wrapper for AnomalyGenerator that handles batch generation and formatting.
|
| 14 |
+
"""
|
| 15 |
+
|
| 16 |
+
def __init__(self, params: AnomalyGeneratorParams):
|
| 17 |
+
"""
|
| 18 |
+
Initialize the AnomalyGeneratorWrapper.
|
| 19 |
+
|
| 20 |
+
Parameters
|
| 21 |
+
----------
|
| 22 |
+
params : AnomalyGeneratorParams
|
| 23 |
+
Parameters for the anomaly generator.
|
| 24 |
+
"""
|
| 25 |
+
super().__init__(params)
|
| 26 |
+
self.generator = AnomalyGenerator(params)
|
| 27 |
+
|
| 28 |
+
def generate_batch(
|
| 29 |
+
self, batch_size: int, seed: Optional[int] = None
|
| 30 |
+
) -> TimeSeriesContainer:
|
| 31 |
+
"""
|
| 32 |
+
Generate a batch of anomaly time series.
|
| 33 |
+
|
| 34 |
+
Parameters
|
| 35 |
+
----------
|
| 36 |
+
batch_size : int
|
| 37 |
+
Number of time series to generate.
|
| 38 |
+
seed : int, optional
|
| 39 |
+
Random seed for reproducibility.
|
| 40 |
+
|
| 41 |
+
Returns
|
| 42 |
+
-------
|
| 43 |
+
TimeSeriesContainer
|
| 44 |
+
TimeSeriesContainer containing the generated time series.
|
| 45 |
+
"""
|
| 46 |
+
if seed is not None:
|
| 47 |
+
self._set_random_seeds(seed)
|
| 48 |
+
|
| 49 |
+
# Sample parameters for the batch
|
| 50 |
+
sampled_params = self._sample_parameters(batch_size)
|
| 51 |
+
|
| 52 |
+
# Generate time series
|
| 53 |
+
values = []
|
| 54 |
+
for i in range(batch_size):
|
| 55 |
+
# Use a different seed for each series in the batch
|
| 56 |
+
series_seed = (seed + i) if seed is not None else None
|
| 57 |
+
series = self.generator.generate_time_series(series_seed)
|
| 58 |
+
values.append(series)
|
| 59 |
+
|
| 60 |
+
return TimeSeriesContainer(
|
| 61 |
+
values=np.array(values),
|
| 62 |
+
start=sampled_params["start"],
|
| 63 |
+
frequency=sampled_params["frequency"],
|
| 64 |
+
)
|
src/synthetic_generation/audio_generators/financial_volatility_generator.py
ADDED
|
@@ -0,0 +1,103 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Optional
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
from pyo import LFO, BrownNoise, Follower, Metro, Mix, Sine, TrigExpseg
|
| 5 |
+
|
| 6 |
+
from src.synthetic_generation.abstract_classes import AbstractTimeSeriesGenerator
|
| 7 |
+
from src.synthetic_generation.audio_generators.utils import (
|
| 8 |
+
normalize_waveform,
|
| 9 |
+
run_offline_pyo,
|
| 10 |
+
)
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class FinancialVolatilityAudioGenerator(AbstractTimeSeriesGenerator):
|
| 14 |
+
"""
|
| 15 |
+
Generate synthetic univariate time series that mimics financial market
|
| 16 |
+
behavior with volatility clustering and occasional jumps.
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
def __init__(
|
| 20 |
+
self,
|
| 21 |
+
length: int,
|
| 22 |
+
server_duration: float,
|
| 23 |
+
sample_rate: int,
|
| 24 |
+
normalize_output: bool,
|
| 25 |
+
# Trend LFO
|
| 26 |
+
trend_lfo_freq_range: tuple[float, float],
|
| 27 |
+
trend_lfo_mul_range: tuple[float, float],
|
| 28 |
+
# Volatility clustering
|
| 29 |
+
volatility_carrier_freq_range: tuple[float, float],
|
| 30 |
+
follower_freq_range: tuple[float, float],
|
| 31 |
+
volatility_range: tuple[float, float],
|
| 32 |
+
# Jumps
|
| 33 |
+
jump_metro_time_range: tuple[float, float],
|
| 34 |
+
jump_env_start_range: tuple[float, float],
|
| 35 |
+
jump_env_decay_time_range: tuple[float, float],
|
| 36 |
+
jump_freq_range: tuple[float, float],
|
| 37 |
+
jump_direction_up_probability: float,
|
| 38 |
+
random_seed: Optional[int] = None,
|
| 39 |
+
):
|
| 40 |
+
self.length = length
|
| 41 |
+
self.server_duration = server_duration
|
| 42 |
+
self.sample_rate = sample_rate
|
| 43 |
+
self.normalize_output = normalize_output
|
| 44 |
+
|
| 45 |
+
self.trend_lfo_freq_range = trend_lfo_freq_range
|
| 46 |
+
self.trend_lfo_mul_range = trend_lfo_mul_range
|
| 47 |
+
self.volatility_carrier_freq_range = volatility_carrier_freq_range
|
| 48 |
+
self.follower_freq_range = follower_freq_range
|
| 49 |
+
self.volatility_range = volatility_range
|
| 50 |
+
self.jump_metro_time_range = jump_metro_time_range
|
| 51 |
+
self.jump_env_start_range = jump_env_start_range
|
| 52 |
+
self.jump_env_decay_time_range = jump_env_decay_time_range
|
| 53 |
+
self.jump_freq_range = jump_freq_range
|
| 54 |
+
self.jump_direction_up_probability = jump_direction_up_probability
|
| 55 |
+
|
| 56 |
+
self.rng = np.random.default_rng(random_seed)
|
| 57 |
+
|
| 58 |
+
def _build_synth(self):
|
| 59 |
+
# Trend
|
| 60 |
+
trend_freq = self.rng.uniform(*self.trend_lfo_freq_range)
|
| 61 |
+
trend_mul = self.rng.uniform(*self.trend_lfo_mul_range)
|
| 62 |
+
trend = LFO(freq=trend_freq, type=0, mul=trend_mul)
|
| 63 |
+
|
| 64 |
+
# Volatility clustering
|
| 65 |
+
carrier_freq = self.rng.uniform(*self.volatility_carrier_freq_range)
|
| 66 |
+
follower_freq = self.rng.uniform(*self.follower_freq_range)
|
| 67 |
+
volatility_min, volatility_max = self.volatility_range
|
| 68 |
+
volatility_osc = Sine(freq=carrier_freq)
|
| 69 |
+
volatility = Follower(volatility_osc, freq=follower_freq).range(
|
| 70 |
+
volatility_min, volatility_max
|
| 71 |
+
)
|
| 72 |
+
market_noise = BrownNoise(mul=volatility)
|
| 73 |
+
|
| 74 |
+
# Jumps
|
| 75 |
+
jump_time = self.rng.uniform(*self.jump_metro_time_range)
|
| 76 |
+
jump_env_start = self.rng.uniform(*self.jump_env_start_range)
|
| 77 |
+
jump_env_decay = self.rng.uniform(*self.jump_env_decay_time_range)
|
| 78 |
+
jump_freq = self.rng.uniform(*self.jump_freq_range)
|
| 79 |
+
direction = (
|
| 80 |
+
1.0 if self.rng.random() < self.jump_direction_up_probability else -1.0
|
| 81 |
+
)
|
| 82 |
+
|
| 83 |
+
jump_trigger = Metro(time=jump_time).play()
|
| 84 |
+
jump_env = TrigExpseg(
|
| 85 |
+
jump_trigger, list=[(0.0, jump_env_start), (jump_env_decay, 0.0)]
|
| 86 |
+
)
|
| 87 |
+
jumps = Sine(freq=jump_freq, mul=jump_env * direction)
|
| 88 |
+
|
| 89 |
+
return Mix([trend, market_noise, jumps], voices=1)
|
| 90 |
+
|
| 91 |
+
def generate_time_series(self, random_seed: Optional[int] = None) -> np.ndarray:
|
| 92 |
+
if random_seed is not None:
|
| 93 |
+
self.rng = np.random.default_rng(random_seed)
|
| 94 |
+
|
| 95 |
+
waveform = run_offline_pyo(
|
| 96 |
+
synth_builder=self._build_synth,
|
| 97 |
+
server_duration=self.server_duration,
|
| 98 |
+
sample_rate=self.sample_rate,
|
| 99 |
+
length=self.length,
|
| 100 |
+
)
|
| 101 |
+
if self.normalize_output:
|
| 102 |
+
waveform = normalize_waveform(waveform)
|
| 103 |
+
return waveform
|
src/synthetic_generation/audio_generators/financial_volatility_wrapper.py
ADDED
|
@@ -0,0 +1,91 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Any, Dict, Optional
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
|
| 5 |
+
from src.data.containers import TimeSeriesContainer
|
| 6 |
+
from src.synthetic_generation.abstract_classes import GeneratorWrapper
|
| 7 |
+
from src.synthetic_generation.audio_generators.financial_volatility_generator import (
|
| 8 |
+
FinancialVolatilityAudioGenerator,
|
| 9 |
+
)
|
| 10 |
+
from src.synthetic_generation.generator_params import FinancialVolatilityAudioParams
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class FinancialVolatilityAudioWrapper(GeneratorWrapper):
|
| 14 |
+
def __init__(self, params: FinancialVolatilityAudioParams):
|
| 15 |
+
super().__init__(params)
|
| 16 |
+
self.params: FinancialVolatilityAudioParams = params
|
| 17 |
+
|
| 18 |
+
def _sample_parameters(self, batch_size: int) -> Dict[str, Any]:
|
| 19 |
+
params = super()._sample_parameters(batch_size)
|
| 20 |
+
params.update(
|
| 21 |
+
{
|
| 22 |
+
"length": self.params.length,
|
| 23 |
+
"server_duration": self.params.server_duration,
|
| 24 |
+
"sample_rate": self.params.sample_rate,
|
| 25 |
+
"normalize_output": self.params.normalize_output,
|
| 26 |
+
# Trend LFO
|
| 27 |
+
"trend_lfo_freq_range": self.params.trend_lfo_freq_range,
|
| 28 |
+
"trend_lfo_mul_range": self.params.trend_lfo_mul_range,
|
| 29 |
+
# Volatility clustering
|
| 30 |
+
"volatility_carrier_freq_range": self.params.volatility_carrier_freq_range,
|
| 31 |
+
"follower_freq_range": self.params.follower_freq_range,
|
| 32 |
+
"volatility_range": self.params.volatility_range,
|
| 33 |
+
# Jumps
|
| 34 |
+
"jump_metro_time_range": self.params.jump_metro_time_range,
|
| 35 |
+
"jump_env_start_range": self.params.jump_env_start_range,
|
| 36 |
+
"jump_env_decay_time_range": self.params.jump_env_decay_time_range,
|
| 37 |
+
"jump_freq_range": self.params.jump_freq_range,
|
| 38 |
+
"jump_direction_up_probability": self.params.jump_direction_up_probability,
|
| 39 |
+
}
|
| 40 |
+
)
|
| 41 |
+
return params
|
| 42 |
+
|
| 43 |
+
def generate_batch(
|
| 44 |
+
self,
|
| 45 |
+
batch_size: int,
|
| 46 |
+
seed: Optional[int] = None,
|
| 47 |
+
params: Optional[Dict[str, Any]] = None,
|
| 48 |
+
) -> TimeSeriesContainer:
|
| 49 |
+
if seed is not None:
|
| 50 |
+
self._set_random_seeds(seed)
|
| 51 |
+
if params is None:
|
| 52 |
+
params = self._sample_parameters(batch_size)
|
| 53 |
+
|
| 54 |
+
generator = FinancialVolatilityAudioGenerator(
|
| 55 |
+
length=params["length"],
|
| 56 |
+
server_duration=params["server_duration"],
|
| 57 |
+
sample_rate=params["sample_rate"],
|
| 58 |
+
normalize_output=params["normalize_output"],
|
| 59 |
+
trend_lfo_freq_range=params["trend_lfo_freq_range"],
|
| 60 |
+
trend_lfo_mul_range=params["trend_lfo_mul_range"],
|
| 61 |
+
volatility_carrier_freq_range=params["volatility_carrier_freq_range"],
|
| 62 |
+
follower_freq_range=params["follower_freq_range"],
|
| 63 |
+
volatility_range=params["volatility_range"],
|
| 64 |
+
jump_metro_time_range=params["jump_metro_time_range"],
|
| 65 |
+
jump_env_start_range=params["jump_env_start_range"],
|
| 66 |
+
jump_env_decay_time_range=params["jump_env_decay_time_range"],
|
| 67 |
+
jump_freq_range=params["jump_freq_range"],
|
| 68 |
+
jump_direction_up_probability=params["jump_direction_up_probability"],
|
| 69 |
+
random_seed=seed,
|
| 70 |
+
)
|
| 71 |
+
|
| 72 |
+
def _derive_series_seed(base_seed: int, index: int) -> int:
|
| 73 |
+
# Mix base seed with index and class hash to decorrelate adjacent seeds
|
| 74 |
+
mixed = (
|
| 75 |
+
(base_seed & 0x7FFFFFFF)
|
| 76 |
+
^ ((index * 0x9E3779B1) & 0x7FFFFFFF)
|
| 77 |
+
^ (hash(self.__class__.__name__) & 0x7FFFFFFF)
|
| 78 |
+
)
|
| 79 |
+
return int(mixed)
|
| 80 |
+
|
| 81 |
+
batch_values = []
|
| 82 |
+
for i in range(batch_size):
|
| 83 |
+
series_seed = None if seed is None else _derive_series_seed(seed, i)
|
| 84 |
+
values = generator.generate_time_series(random_seed=series_seed)
|
| 85 |
+
batch_values.append(values)
|
| 86 |
+
|
| 87 |
+
return TimeSeriesContainer(
|
| 88 |
+
values=np.array(batch_values),
|
| 89 |
+
start=params["start"],
|
| 90 |
+
frequency=params["frequency"],
|
| 91 |
+
)
|
src/synthetic_generation/audio_generators/multi_scale_fractal_generator.py
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Optional
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
from pyo import Biquad, BrownNoise, Mix
|
| 5 |
+
|
| 6 |
+
from src.synthetic_generation.abstract_classes import AbstractTimeSeriesGenerator
|
| 7 |
+
from src.synthetic_generation.audio_generators.utils import (
|
| 8 |
+
normalize_waveform,
|
| 9 |
+
run_offline_pyo,
|
| 10 |
+
)
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class MultiScaleFractalAudioGenerator(AbstractTimeSeriesGenerator):
|
| 14 |
+
"""
|
| 15 |
+
Generate multi-scale fractal-like patterns by filtering noise at
|
| 16 |
+
multiple frequency bands with varying Q and attenuation per scale.
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
def __init__(
|
| 20 |
+
self,
|
| 21 |
+
length: int,
|
| 22 |
+
server_duration: float,
|
| 23 |
+
sample_rate: int,
|
| 24 |
+
normalize_output: bool,
|
| 25 |
+
base_noise_mul_range: tuple[float, float],
|
| 26 |
+
num_scales_range: tuple[int, int],
|
| 27 |
+
scale_freq_base_range: tuple[float, float],
|
| 28 |
+
q_factor_range: tuple[float, float],
|
| 29 |
+
per_scale_attenuation_range: tuple[float, float],
|
| 30 |
+
random_seed: Optional[int] = None,
|
| 31 |
+
):
|
| 32 |
+
self.length = length
|
| 33 |
+
self.server_duration = server_duration
|
| 34 |
+
self.sample_rate = sample_rate
|
| 35 |
+
self.normalize_output = normalize_output
|
| 36 |
+
|
| 37 |
+
self.base_noise_mul_range = base_noise_mul_range
|
| 38 |
+
self.num_scales_range = num_scales_range
|
| 39 |
+
self.scale_freq_base_range = scale_freq_base_range
|
| 40 |
+
self.q_factor_range = q_factor_range
|
| 41 |
+
self.per_scale_attenuation_range = per_scale_attenuation_range
|
| 42 |
+
|
| 43 |
+
self.rng = np.random.default_rng(random_seed)
|
| 44 |
+
|
| 45 |
+
def _build_synth(self):
|
| 46 |
+
base_mul = self.rng.uniform(*self.base_noise_mul_range)
|
| 47 |
+
base = BrownNoise(mul=base_mul)
|
| 48 |
+
|
| 49 |
+
num_scales = int(
|
| 50 |
+
self.rng.integers(self.num_scales_range[0], self.num_scales_range[1] + 1)
|
| 51 |
+
)
|
| 52 |
+
|
| 53 |
+
scales = []
|
| 54 |
+
for i in range(num_scales):
|
| 55 |
+
scale_freq = self.rng.uniform(*self.scale_freq_base_range) * (0.5**i)
|
| 56 |
+
q_factor = self.rng.uniform(*self.q_factor_range)
|
| 57 |
+
per_scale_att = self.rng.uniform(*self.per_scale_attenuation_range)
|
| 58 |
+
filtered = Biquad(base, freq=scale_freq, q=q_factor, type=0)
|
| 59 |
+
scales.append(filtered * (per_scale_att**i))
|
| 60 |
+
|
| 61 |
+
return Mix(scales, voices=1)
|
| 62 |
+
|
| 63 |
+
def generate_time_series(self, random_seed: Optional[int] = None) -> np.ndarray:
|
| 64 |
+
if random_seed is not None:
|
| 65 |
+
self.rng = np.random.default_rng(random_seed)
|
| 66 |
+
|
| 67 |
+
waveform = run_offline_pyo(
|
| 68 |
+
synth_builder=self._build_synth,
|
| 69 |
+
server_duration=self.server_duration,
|
| 70 |
+
sample_rate=self.sample_rate,
|
| 71 |
+
length=self.length,
|
| 72 |
+
)
|
| 73 |
+
if self.normalize_output:
|
| 74 |
+
waveform = normalize_waveform(waveform)
|
| 75 |
+
return waveform
|
src/synthetic_generation/audio_generators/multi_scale_fractal_wrapper.py
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Any, Dict, Optional
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
|
| 5 |
+
from src.data.containers import TimeSeriesContainer
|
| 6 |
+
from src.synthetic_generation.abstract_classes import GeneratorWrapper
|
| 7 |
+
from src.synthetic_generation.audio_generators.multi_scale_fractal_generator import (
|
| 8 |
+
MultiScaleFractalAudioGenerator,
|
| 9 |
+
)
|
| 10 |
+
from src.synthetic_generation.generator_params import MultiScaleFractalAudioParams
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class MultiScaleFractalAudioWrapper(GeneratorWrapper):
|
| 14 |
+
def __init__(self, params: MultiScaleFractalAudioParams):
|
| 15 |
+
super().__init__(params)
|
| 16 |
+
self.params: MultiScaleFractalAudioParams = params
|
| 17 |
+
|
| 18 |
+
def _sample_parameters(self, batch_size: int) -> Dict[str, Any]:
|
| 19 |
+
params = super()._sample_parameters(batch_size)
|
| 20 |
+
params.update(
|
| 21 |
+
{
|
| 22 |
+
"length": self.params.length,
|
| 23 |
+
"server_duration": self.params.server_duration,
|
| 24 |
+
"sample_rate": self.params.sample_rate,
|
| 25 |
+
"normalize_output": self.params.normalize_output,
|
| 26 |
+
"base_noise_mul_range": self.params.base_noise_mul_range,
|
| 27 |
+
"num_scales_range": self.params.num_scales_range,
|
| 28 |
+
"scale_freq_base_range": self.params.scale_freq_base_range,
|
| 29 |
+
"q_factor_range": self.params.q_factor_range,
|
| 30 |
+
"per_scale_attenuation_range": self.params.per_scale_attenuation_range,
|
| 31 |
+
}
|
| 32 |
+
)
|
| 33 |
+
return params
|
| 34 |
+
|
| 35 |
+
def generate_batch(
|
| 36 |
+
self,
|
| 37 |
+
batch_size: int,
|
| 38 |
+
seed: Optional[int] = None,
|
| 39 |
+
params: Optional[Dict[str, Any]] = None,
|
| 40 |
+
) -> TimeSeriesContainer:
|
| 41 |
+
if seed is not None:
|
| 42 |
+
self._set_random_seeds(seed)
|
| 43 |
+
if params is None:
|
| 44 |
+
params = self._sample_parameters(batch_size)
|
| 45 |
+
|
| 46 |
+
generator = MultiScaleFractalAudioGenerator(
|
| 47 |
+
length=params["length"],
|
| 48 |
+
server_duration=params["server_duration"],
|
| 49 |
+
sample_rate=params["sample_rate"],
|
| 50 |
+
normalize_output=params["normalize_output"],
|
| 51 |
+
base_noise_mul_range=params["base_noise_mul_range"],
|
| 52 |
+
num_scales_range=params["num_scales_range"],
|
| 53 |
+
scale_freq_base_range=params["scale_freq_base_range"],
|
| 54 |
+
q_factor_range=params["q_factor_range"],
|
| 55 |
+
per_scale_attenuation_range=params["per_scale_attenuation_range"],
|
| 56 |
+
random_seed=seed,
|
| 57 |
+
)
|
| 58 |
+
|
| 59 |
+
def _derive_series_seed(base_seed: int, index: int) -> int:
|
| 60 |
+
mixed = (
|
| 61 |
+
(base_seed & 0x7FFFFFFF)
|
| 62 |
+
^ ((index * 0x9E3779B1) & 0x7FFFFFFF)
|
| 63 |
+
^ (hash(self.__class__.__name__) & 0x7FFFFFFF)
|
| 64 |
+
)
|
| 65 |
+
return int(mixed)
|
| 66 |
+
|
| 67 |
+
batch_values = []
|
| 68 |
+
for i in range(batch_size):
|
| 69 |
+
series_seed = None if seed is None else _derive_series_seed(seed, i)
|
| 70 |
+
values = generator.generate_time_series(random_seed=series_seed)
|
| 71 |
+
batch_values.append(values)
|
| 72 |
+
|
| 73 |
+
return TimeSeriesContainer(
|
| 74 |
+
values=np.array(batch_values),
|
| 75 |
+
start=params["start"],
|
| 76 |
+
frequency=params["frequency"],
|
| 77 |
+
)
|
src/synthetic_generation/audio_generators/network_topology_generator.py
ADDED
|
@@ -0,0 +1,113 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Optional, Tuple
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
from pyo import LFO, BrownNoise, Metro, Mix, Noise, TrigExpseg
|
| 5 |
+
|
| 6 |
+
from src.synthetic_generation.abstract_classes import AbstractTimeSeriesGenerator
|
| 7 |
+
from src.synthetic_generation.audio_generators.utils import (
|
| 8 |
+
normalize_waveform,
|
| 9 |
+
run_offline_pyo,
|
| 10 |
+
)
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class NetworkTopologyAudioGenerator(AbstractTimeSeriesGenerator):
|
| 14 |
+
"""
|
| 15 |
+
Simulate network traffic with base flow, packet bursts, periodic congestion,
|
| 16 |
+
protocol overhead, and DDoS-like attacks. Parameters are sampled per series.
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
def __init__(
|
| 20 |
+
self,
|
| 21 |
+
length: int,
|
| 22 |
+
server_duration: float,
|
| 23 |
+
sample_rate: int,
|
| 24 |
+
normalize_output: bool,
|
| 25 |
+
traffic_lfo_freq_range: tuple[float, float],
|
| 26 |
+
traffic_lfo_mul_range: tuple[float, float],
|
| 27 |
+
burst_rate_hz_range: tuple[float, float],
|
| 28 |
+
burst_duration_range: tuple[float, float],
|
| 29 |
+
burst_mul_range: tuple[float, float],
|
| 30 |
+
congestion_period_range: tuple[float, float],
|
| 31 |
+
congestion_depth_range: tuple[float, float],
|
| 32 |
+
congestion_release_time_range: tuple[float, float],
|
| 33 |
+
overhead_lfo_freq_range: tuple[float, float],
|
| 34 |
+
overhead_mul_range: tuple[float, float],
|
| 35 |
+
attack_period_range: tuple[float, float],
|
| 36 |
+
attack_env_points: Tuple[
|
| 37 |
+
Tuple[float, float], Tuple[float, float], Tuple[float, float]
|
| 38 |
+
],
|
| 39 |
+
attack_mul_range: tuple[float, float],
|
| 40 |
+
random_seed: Optional[int] = None,
|
| 41 |
+
):
|
| 42 |
+
self.length = length
|
| 43 |
+
self.server_duration = server_duration
|
| 44 |
+
self.sample_rate = sample_rate
|
| 45 |
+
self.normalize_output = normalize_output
|
| 46 |
+
|
| 47 |
+
self.traffic_lfo_freq_range = traffic_lfo_freq_range
|
| 48 |
+
self.traffic_lfo_mul_range = traffic_lfo_mul_range
|
| 49 |
+
self.burst_rate_hz_range = burst_rate_hz_range
|
| 50 |
+
self.burst_duration_range = burst_duration_range
|
| 51 |
+
self.burst_mul_range = burst_mul_range
|
| 52 |
+
self.congestion_period_range = congestion_period_range
|
| 53 |
+
self.congestion_depth_range = congestion_depth_range
|
| 54 |
+
self.congestion_release_time_range = congestion_release_time_range
|
| 55 |
+
self.overhead_lfo_freq_range = overhead_lfo_freq_range
|
| 56 |
+
self.overhead_mul_range = overhead_mul_range
|
| 57 |
+
self.attack_period_range = attack_period_range
|
| 58 |
+
self.attack_env_points = attack_env_points
|
| 59 |
+
self.attack_mul_range = attack_mul_range
|
| 60 |
+
|
| 61 |
+
self.rng = np.random.default_rng(random_seed)
|
| 62 |
+
|
| 63 |
+
def _build_synth(self):
|
| 64 |
+
# Base traffic flow
|
| 65 |
+
traffic_freq = self.rng.uniform(*self.traffic_lfo_freq_range)
|
| 66 |
+
traffic_mul = self.rng.uniform(*self.traffic_lfo_mul_range)
|
| 67 |
+
traffic_base = LFO(freq=traffic_freq, type=0, mul=traffic_mul)
|
| 68 |
+
|
| 69 |
+
# Packet bursts
|
| 70 |
+
burst_rate = self.rng.uniform(*self.burst_rate_hz_range)
|
| 71 |
+
burst_trigger = Metro(time=1.0 / burst_rate).play()
|
| 72 |
+
burst_duration = self.rng.uniform(*self.burst_duration_range)
|
| 73 |
+
burst_env = TrigExpseg(burst_trigger, list=[(0.0, 0.8), (burst_duration, 0.0)])
|
| 74 |
+
burst_mul = self.rng.uniform(*self.burst_mul_range)
|
| 75 |
+
bursts = Noise(mul=burst_env * burst_mul)
|
| 76 |
+
|
| 77 |
+
# Periodic congestion (negative amplitude dip)
|
| 78 |
+
congestion_period = self.rng.uniform(*self.congestion_period_range)
|
| 79 |
+
congestion_trigger = Metro(time=congestion_period).play()
|
| 80 |
+
congestion_depth = self.rng.uniform(*self.congestion_depth_range) # negative
|
| 81 |
+
congestion_release = self.rng.uniform(*self.congestion_release_time_range)
|
| 82 |
+
congestion_env = TrigExpseg(
|
| 83 |
+
congestion_trigger,
|
| 84 |
+
list=[(0.0, congestion_depth), (congestion_release, 0.0)],
|
| 85 |
+
)
|
| 86 |
+
|
| 87 |
+
# Protocol overhead
|
| 88 |
+
overhead_freq = self.rng.uniform(*self.overhead_lfo_freq_range)
|
| 89 |
+
overhead_mul = self.rng.uniform(*self.overhead_mul_range)
|
| 90 |
+
overhead = LFO(freq=overhead_freq, type=1, mul=overhead_mul)
|
| 91 |
+
|
| 92 |
+
# DDoS-like attacks
|
| 93 |
+
attack_period = self.rng.uniform(*self.attack_period_range)
|
| 94 |
+
attack_trigger = Metro(time=attack_period).play()
|
| 95 |
+
attack_env = TrigExpseg(attack_trigger, list=list(self.attack_env_points))
|
| 96 |
+
attack_mul = self.rng.uniform(*self.attack_mul_range)
|
| 97 |
+
attacks = BrownNoise(mul=attack_env * attack_mul)
|
| 98 |
+
|
| 99 |
+
return Mix([traffic_base, bursts, congestion_env, overhead, attacks], voices=1)
|
| 100 |
+
|
| 101 |
+
def generate_time_series(self, random_seed: Optional[int] = None) -> np.ndarray:
|
| 102 |
+
if random_seed is not None:
|
| 103 |
+
self.rng = np.random.default_rng(random_seed)
|
| 104 |
+
|
| 105 |
+
waveform = run_offline_pyo(
|
| 106 |
+
synth_builder=self._build_synth,
|
| 107 |
+
server_duration=self.server_duration,
|
| 108 |
+
sample_rate=self.sample_rate,
|
| 109 |
+
length=self.length,
|
| 110 |
+
)
|
| 111 |
+
if self.normalize_output:
|
| 112 |
+
waveform = normalize_waveform(waveform)
|
| 113 |
+
return waveform
|
src/synthetic_generation/audio_generators/network_topology_wrapper.py
ADDED
|
@@ -0,0 +1,93 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Any, Dict, Optional
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
|
| 5 |
+
from src.data.containers import TimeSeriesContainer
|
| 6 |
+
from src.synthetic_generation.abstract_classes import GeneratorWrapper
|
| 7 |
+
from src.synthetic_generation.audio_generators.network_topology_generator import (
|
| 8 |
+
NetworkTopologyAudioGenerator,
|
| 9 |
+
)
|
| 10 |
+
from src.synthetic_generation.generator_params import NetworkTopologyAudioParams
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class NetworkTopologyAudioWrapper(GeneratorWrapper):
|
| 14 |
+
def __init__(self, params: NetworkTopologyAudioParams):
|
| 15 |
+
super().__init__(params)
|
| 16 |
+
self.params: NetworkTopologyAudioParams = params
|
| 17 |
+
|
| 18 |
+
def _sample_parameters(self, batch_size: int) -> Dict[str, Any]:
|
| 19 |
+
params = super()._sample_parameters(batch_size)
|
| 20 |
+
params.update(
|
| 21 |
+
{
|
| 22 |
+
"length": self.params.length,
|
| 23 |
+
"server_duration": self.params.server_duration,
|
| 24 |
+
"sample_rate": self.params.sample_rate,
|
| 25 |
+
"normalize_output": self.params.normalize_output,
|
| 26 |
+
"traffic_lfo_freq_range": self.params.traffic_lfo_freq_range,
|
| 27 |
+
"traffic_lfo_mul_range": self.params.traffic_lfo_mul_range,
|
| 28 |
+
"burst_rate_hz_range": self.params.burst_rate_hz_range,
|
| 29 |
+
"burst_duration_range": self.params.burst_duration_range,
|
| 30 |
+
"burst_mul_range": self.params.burst_mul_range,
|
| 31 |
+
"congestion_period_range": self.params.congestion_period_range,
|
| 32 |
+
"congestion_depth_range": self.params.congestion_depth_range,
|
| 33 |
+
"congestion_release_time_range": self.params.congestion_release_time_range,
|
| 34 |
+
"overhead_lfo_freq_range": self.params.overhead_lfo_freq_range,
|
| 35 |
+
"overhead_mul_range": self.params.overhead_mul_range,
|
| 36 |
+
"attack_period_range": self.params.attack_period_range,
|
| 37 |
+
"attack_env_points": self.params.attack_env_points,
|
| 38 |
+
"attack_mul_range": self.params.attack_mul_range,
|
| 39 |
+
}
|
| 40 |
+
)
|
| 41 |
+
return params
|
| 42 |
+
|
| 43 |
+
def generate_batch(
|
| 44 |
+
self,
|
| 45 |
+
batch_size: int,
|
| 46 |
+
seed: Optional[int] = None,
|
| 47 |
+
params: Optional[Dict[str, Any]] = None,
|
| 48 |
+
) -> TimeSeriesContainer:
|
| 49 |
+
if seed is not None:
|
| 50 |
+
self._set_random_seeds(seed)
|
| 51 |
+
if params is None:
|
| 52 |
+
params = self._sample_parameters(batch_size)
|
| 53 |
+
|
| 54 |
+
generator = NetworkTopologyAudioGenerator(
|
| 55 |
+
length=params["length"],
|
| 56 |
+
server_duration=params["server_duration"],
|
| 57 |
+
sample_rate=params["sample_rate"],
|
| 58 |
+
normalize_output=params["normalize_output"],
|
| 59 |
+
traffic_lfo_freq_range=params["traffic_lfo_freq_range"],
|
| 60 |
+
traffic_lfo_mul_range=params["traffic_lfo_mul_range"],
|
| 61 |
+
burst_rate_hz_range=params["burst_rate_hz_range"],
|
| 62 |
+
burst_duration_range=params["burst_duration_range"],
|
| 63 |
+
burst_mul_range=params["burst_mul_range"],
|
| 64 |
+
congestion_period_range=params["congestion_period_range"],
|
| 65 |
+
congestion_depth_range=params["congestion_depth_range"],
|
| 66 |
+
congestion_release_time_range=params["congestion_release_time_range"],
|
| 67 |
+
overhead_lfo_freq_range=params["overhead_lfo_freq_range"],
|
| 68 |
+
overhead_mul_range=params["overhead_mul_range"],
|
| 69 |
+
attack_period_range=params["attack_period_range"],
|
| 70 |
+
attack_env_points=params["attack_env_points"],
|
| 71 |
+
attack_mul_range=params["attack_mul_range"],
|
| 72 |
+
random_seed=seed,
|
| 73 |
+
)
|
| 74 |
+
|
| 75 |
+
def _derive_series_seed(base_seed: int, index: int) -> int:
|
| 76 |
+
mixed = (
|
| 77 |
+
(base_seed & 0x7FFFFFFF)
|
| 78 |
+
^ ((index * 0x9E3779B1) & 0x7FFFFFFF)
|
| 79 |
+
^ (hash(self.__class__.__name__) & 0x7FFFFFFF)
|
| 80 |
+
)
|
| 81 |
+
return int(mixed)
|
| 82 |
+
|
| 83 |
+
batch_values = []
|
| 84 |
+
for i in range(batch_size):
|
| 85 |
+
series_seed = None if seed is None else _derive_series_seed(seed, i)
|
| 86 |
+
values = generator.generate_time_series(random_seed=series_seed)
|
| 87 |
+
batch_values.append(values)
|
| 88 |
+
|
| 89 |
+
return TimeSeriesContainer(
|
| 90 |
+
values=np.array(batch_values),
|
| 91 |
+
start=params["start"],
|
| 92 |
+
frequency=params["frequency"],
|
| 93 |
+
)
|
src/synthetic_generation/audio_generators/stochastic_rhythm_generator.py
ADDED
|
@@ -0,0 +1,86 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Optional
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
from pyo import Metro, Mix, Sine, TrigExpseg
|
| 5 |
+
|
| 6 |
+
from src.synthetic_generation.abstract_classes import AbstractTimeSeriesGenerator
|
| 7 |
+
from src.synthetic_generation.audio_generators.utils import (
|
| 8 |
+
normalize_waveform,
|
| 9 |
+
run_offline_pyo,
|
| 10 |
+
)
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class StochasticRhythmAudioGenerator(AbstractTimeSeriesGenerator):
|
| 14 |
+
"""
|
| 15 |
+
Generate rhythmic patterns with layered triggers, per-layer envelopes
|
| 16 |
+
and tones. Parameters are sampled per series for diversity.
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
def __init__(
|
| 20 |
+
self,
|
| 21 |
+
length: int,
|
| 22 |
+
server_duration: float,
|
| 23 |
+
sample_rate: int,
|
| 24 |
+
normalize_output: bool,
|
| 25 |
+
base_tempo_hz_range: tuple[float, float],
|
| 26 |
+
num_layers_range: tuple[int, int],
|
| 27 |
+
subdivisions: tuple[int, ...],
|
| 28 |
+
attack_range: tuple[float, float],
|
| 29 |
+
decay_range: tuple[float, float],
|
| 30 |
+
tone_freq_range: tuple[float, float],
|
| 31 |
+
tone_mul_range: tuple[float, float],
|
| 32 |
+
random_seed: Optional[int] = None,
|
| 33 |
+
):
|
| 34 |
+
self.length = length
|
| 35 |
+
self.server_duration = server_duration
|
| 36 |
+
self.sample_rate = sample_rate
|
| 37 |
+
self.normalize_output = normalize_output
|
| 38 |
+
|
| 39 |
+
self.base_tempo_hz_range = base_tempo_hz_range
|
| 40 |
+
self.num_layers_range = num_layers_range
|
| 41 |
+
self.subdivisions = subdivisions
|
| 42 |
+
self.attack_range = attack_range
|
| 43 |
+
self.decay_range = decay_range
|
| 44 |
+
self.tone_freq_range = tone_freq_range
|
| 45 |
+
self.tone_mul_range = tone_mul_range
|
| 46 |
+
|
| 47 |
+
self.rng = np.random.default_rng(random_seed)
|
| 48 |
+
|
| 49 |
+
def _build_synth(self):
|
| 50 |
+
base_tempo = self.rng.uniform(*self.base_tempo_hz_range)
|
| 51 |
+
num_layers = int(
|
| 52 |
+
self.rng.integers(self.num_layers_range[0], self.num_layers_range[1] + 1)
|
| 53 |
+
)
|
| 54 |
+
|
| 55 |
+
layers = []
|
| 56 |
+
for _ in range(num_layers):
|
| 57 |
+
subdivision = self.subdivisions[
|
| 58 |
+
int(self.rng.integers(0, len(self.subdivisions)))
|
| 59 |
+
]
|
| 60 |
+
rhythm_freq = base_tempo * subdivision
|
| 61 |
+
trigger = Metro(time=1.0 / rhythm_freq).play()
|
| 62 |
+
|
| 63 |
+
attack = self.rng.uniform(*self.attack_range)
|
| 64 |
+
decay = self.rng.uniform(*self.decay_range)
|
| 65 |
+
env = TrigExpseg(trigger, list=[(0.0, 1.0), (attack, 0.8), (decay, 0.0)])
|
| 66 |
+
|
| 67 |
+
tone_freq = self.rng.uniform(*self.tone_freq_range)
|
| 68 |
+
tone_mul = self.rng.uniform(*self.tone_mul_range)
|
| 69 |
+
tone = Sine(freq=tone_freq, mul=env * tone_mul)
|
| 70 |
+
layers.append(tone)
|
| 71 |
+
|
| 72 |
+
return Mix(layers, voices=1)
|
| 73 |
+
|
| 74 |
+
def generate_time_series(self, random_seed: Optional[int] = None) -> np.ndarray:
|
| 75 |
+
if random_seed is not None:
|
| 76 |
+
self.rng = np.random.default_rng(random_seed)
|
| 77 |
+
|
| 78 |
+
waveform = run_offline_pyo(
|
| 79 |
+
synth_builder=self._build_synth,
|
| 80 |
+
server_duration=self.server_duration,
|
| 81 |
+
sample_rate=self.sample_rate,
|
| 82 |
+
length=self.length,
|
| 83 |
+
)
|
| 84 |
+
if self.normalize_output:
|
| 85 |
+
waveform = normalize_waveform(waveform)
|
| 86 |
+
return waveform
|
src/synthetic_generation/audio_generators/stochastic_rhythm_wrapper.py
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Any, Dict, Optional
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
|
| 5 |
+
from src.data.containers import TimeSeriesContainer
|
| 6 |
+
from src.synthetic_generation.abstract_classes import GeneratorWrapper
|
| 7 |
+
from src.synthetic_generation.audio_generators.stochastic_rhythm_generator import (
|
| 8 |
+
StochasticRhythmAudioGenerator,
|
| 9 |
+
)
|
| 10 |
+
from src.synthetic_generation.generator_params import StochasticRhythmAudioParams
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class StochasticRhythmAudioWrapper(GeneratorWrapper):
|
| 14 |
+
def __init__(self, params: StochasticRhythmAudioParams):
|
| 15 |
+
super().__init__(params)
|
| 16 |
+
self.params: StochasticRhythmAudioParams = params
|
| 17 |
+
|
| 18 |
+
def _sample_parameters(self, batch_size: int) -> Dict[str, Any]:
|
| 19 |
+
params = super()._sample_parameters(batch_size)
|
| 20 |
+
params.update(
|
| 21 |
+
{
|
| 22 |
+
"length": self.params.length,
|
| 23 |
+
"server_duration": self.params.server_duration,
|
| 24 |
+
"sample_rate": self.params.sample_rate,
|
| 25 |
+
"normalize_output": self.params.normalize_output,
|
| 26 |
+
"base_tempo_hz_range": self.params.base_tempo_hz_range,
|
| 27 |
+
"num_layers_range": self.params.num_layers_range,
|
| 28 |
+
"subdivisions": self.params.subdivisions,
|
| 29 |
+
"attack_range": self.params.attack_range,
|
| 30 |
+
"decay_range": self.params.decay_range,
|
| 31 |
+
"tone_freq_range": self.params.tone_freq_range,
|
| 32 |
+
"tone_mul_range": self.params.tone_mul_range,
|
| 33 |
+
}
|
| 34 |
+
)
|
| 35 |
+
return params
|
| 36 |
+
|
| 37 |
+
def generate_batch(
|
| 38 |
+
self,
|
| 39 |
+
batch_size: int,
|
| 40 |
+
seed: Optional[int] = None,
|
| 41 |
+
params: Optional[Dict[str, Any]] = None,
|
| 42 |
+
) -> TimeSeriesContainer:
|
| 43 |
+
if seed is not None:
|
| 44 |
+
self._set_random_seeds(seed)
|
| 45 |
+
if params is None:
|
| 46 |
+
params = self._sample_parameters(batch_size)
|
| 47 |
+
|
| 48 |
+
generator = StochasticRhythmAudioGenerator(
|
| 49 |
+
length=params["length"],
|
| 50 |
+
server_duration=params["server_duration"],
|
| 51 |
+
sample_rate=params["sample_rate"],
|
| 52 |
+
normalize_output=params["normalize_output"],
|
| 53 |
+
base_tempo_hz_range=params["base_tempo_hz_range"],
|
| 54 |
+
num_layers_range=params["num_layers_range"],
|
| 55 |
+
subdivisions=params["subdivisions"],
|
| 56 |
+
attack_range=params["attack_range"],
|
| 57 |
+
decay_range=params["decay_range"],
|
| 58 |
+
tone_freq_range=params["tone_freq_range"],
|
| 59 |
+
tone_mul_range=params["tone_mul_range"],
|
| 60 |
+
random_seed=seed,
|
| 61 |
+
)
|
| 62 |
+
|
| 63 |
+
def _derive_series_seed(base_seed: int, index: int) -> int:
|
| 64 |
+
mixed = (
|
| 65 |
+
(base_seed & 0x7FFFFFFF)
|
| 66 |
+
^ ((index * 0x9E3779B1) & 0x7FFFFFFF)
|
| 67 |
+
^ (hash(self.__class__.__name__) & 0x7FFFFFFF)
|
| 68 |
+
)
|
| 69 |
+
return int(mixed)
|
| 70 |
+
|
| 71 |
+
batch_values = []
|
| 72 |
+
for i in range(batch_size):
|
| 73 |
+
series_seed = None if seed is None else _derive_series_seed(seed, i)
|
| 74 |
+
values = generator.generate_time_series(random_seed=series_seed)
|
| 75 |
+
batch_values.append(values)
|
| 76 |
+
|
| 77 |
+
return TimeSeriesContainer(
|
| 78 |
+
values=np.array(batch_values),
|
| 79 |
+
start=params["start"],
|
| 80 |
+
frequency=params["frequency"],
|
| 81 |
+
)
|