
Vladyslav Moroshan
commited on
Commit
·
c4b87d2
1
Parent(s):
5af912c
Initial upload of TempoPFN model, code, and weights
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .vscode/settings.json +2 -0
- LICENSE +201 -0
- README.md +151 -3
- configs/example.yaml +119 -0
- data/dataset_properties.json +152 -0
- data/nan_stats.json +0 -0
- examples/generate_synthetic_data.py +204 -0
- examples/gift_eval/gift_eval_runner.py +251 -0
- examples/gift_eval/gift_eval_submission.ipynb +1439 -0
- examples/quick_start_tempo_pfn.ipynb +280 -0
- examples/quick_start_tempo_pfn.py +101 -0
- examples/utils.py +115 -0
- gitignore +167 -0
- models/checkpoint_38M.pth +3 -0
- pyproject.toml +62 -0
- requirements.txt +25 -0
- src/__init__.py +0 -0
- src/data/__init__.py +0 -0
- src/data/augmentations.py +1318 -0
- src/data/batch_composer.py +705 -0
- src/data/constants.py +25 -0
- src/data/containers.py +204 -0
- src/data/datasets.py +267 -0
- src/data/filter.py +73 -0
- src/data/frequency.py +538 -0
- src/data/loaders.py +661 -0
- src/data/scalers.py +360 -0
- src/data/time_features.py +564 -0
- src/data/utils.py +75 -0
- src/gift_eval/__init__.py +15 -0
- src/gift_eval/constants.py +186 -0
- src/gift_eval/core.py +64 -0
- src/gift_eval/data.py +234 -0
- src/gift_eval/evaluate.py +421 -0
- src/gift_eval/predictor.py +318 -0
- src/gift_eval/results.py +243 -0
- src/models/__init__.py +0 -0
- src/models/blocks.py +62 -0
- src/models/gated_deltaproduct/README.md +344 -0
- src/models/gated_deltaproduct/__init__.py +11 -0
- src/models/gated_deltaproduct/configuration_gated_deltaproduct.py +108 -0
- src/models/gated_deltaproduct/gated_deltaproduct.py +351 -0
- src/models/gated_deltaproduct/modeling_gated_deltaproduct.py +105 -0
- src/models/model.py +427 -0
- src/optim/lr_scheduler.py +360 -0
- src/plotting/__init__.py +0 -0
- src/plotting/gift_eval_utils.py +215 -0
- src/plotting/plot_timeseries.py +292 -0
- src/synthetic_generation/__init__.py +0 -0
- src/synthetic_generation/abstract_classes.py +97 -0
.vscode/settings.json
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
}
|
LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
README.md
CHANGED
|
@@ -1,3 +1,151 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: apache-2.0
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
library_name: tempo-pfn
|
| 4 |
+
tags:
|
| 5 |
+
- time-series-forecasting
|
| 6 |
+
- zero-shot
|
| 7 |
+
- rnn
|
| 8 |
+
- linear-rnn
|
| 9 |
+
- synthetic-data
|
| 10 |
+
- foundation-model
|
| 11 |
+
- automl
|
| 12 |
+
arxiv: 2510.25502
|
| 13 |
+
---
|
| 14 |
+
|
| 15 |
+
# TempoPFN: Synthetic Pre-Training of Linear RNNs for Zero-Shot Time Series Forecasting
|
| 16 |
+
|
| 17 |
+
[](https://arxiv.org/abs/2510.25502) [](https://github.com/automl/TempoPFN/blob/main/LICENSE)
|
| 18 |
+
|
| 19 |
+
---
|
| 20 |
+
|
| 21 |
+
**TempoPFN** introduced in [TempoPFN: Synthetic Pre-Training of Linear RNNs for Zero-Shot Time Series Forecasting](https://arxiv.org/abs/2510.25502), is a univariate time series foundation model pretrained **entirely on synthetic data**. It delivers top-tier zero-shot forecasting accuracy while remaining fully reproducible and free from real-data leakage.
|
| 22 |
+
|
| 23 |
+
Built on a **Linear RNN (GatedDeltaProduct)** backbone, TempoPFN performs end-to-end forecasting without patching or windowing. Its design enables fully parallelizable training and inference while maintaining stable temporal state-tracking across long sequences. The GatedDeltaProduct architecture is based on [DeltaProduct](https://arxiv.org/html/2502.10297v3), extended with state-weaving for time series forecasting. For detailed information about the architecture and custom modifications, see [`src/models/gated_deltaproduct/README.md`](src/models/gated_deltaproduct/README.md).
|
| 24 |
+
|
| 25 |
+
This repository includes the **pretrained 38M parameter model** (`models/checkpoint_38M.pth`), all training and inference code, and the **complete synthetic data generation pipeline** used for pretraining.
|
| 26 |
+
|
| 27 |
+
## ✨ Why TempoPFN?
|
| 28 |
+
|
| 29 |
+
* **High Performance, No Real Data:** Achieves top-tier competitive results on **GIFT-Eval, outperforming all existing synthetic-only approaches** and **surpassing the vast majority of models trained on real-world data**. This ensures full reproducibility and eliminates benchmark leakage.
|
| 30 |
+
* **Parallel and Efficient:** The linear recurrence design enables full-sequence parallelization. This gives us the best of both worlds: the linear efficiency of an RNN, but with the training parallelism of a Transformer.
|
| 31 |
+
* **Open and Reproducible:** Includes the full synthetic data pipeline, configurations, and scripts to reproduce training from scratch.
|
| 32 |
+
* **State-Tracking Stability:** The GatedDeltaProduct recurrence and *state-weaving* mechanism preserve temporal continuity and information flow across long horizons, improving robustness without non-linear recurrence.
|
| 33 |
+
|
| 34 |
+
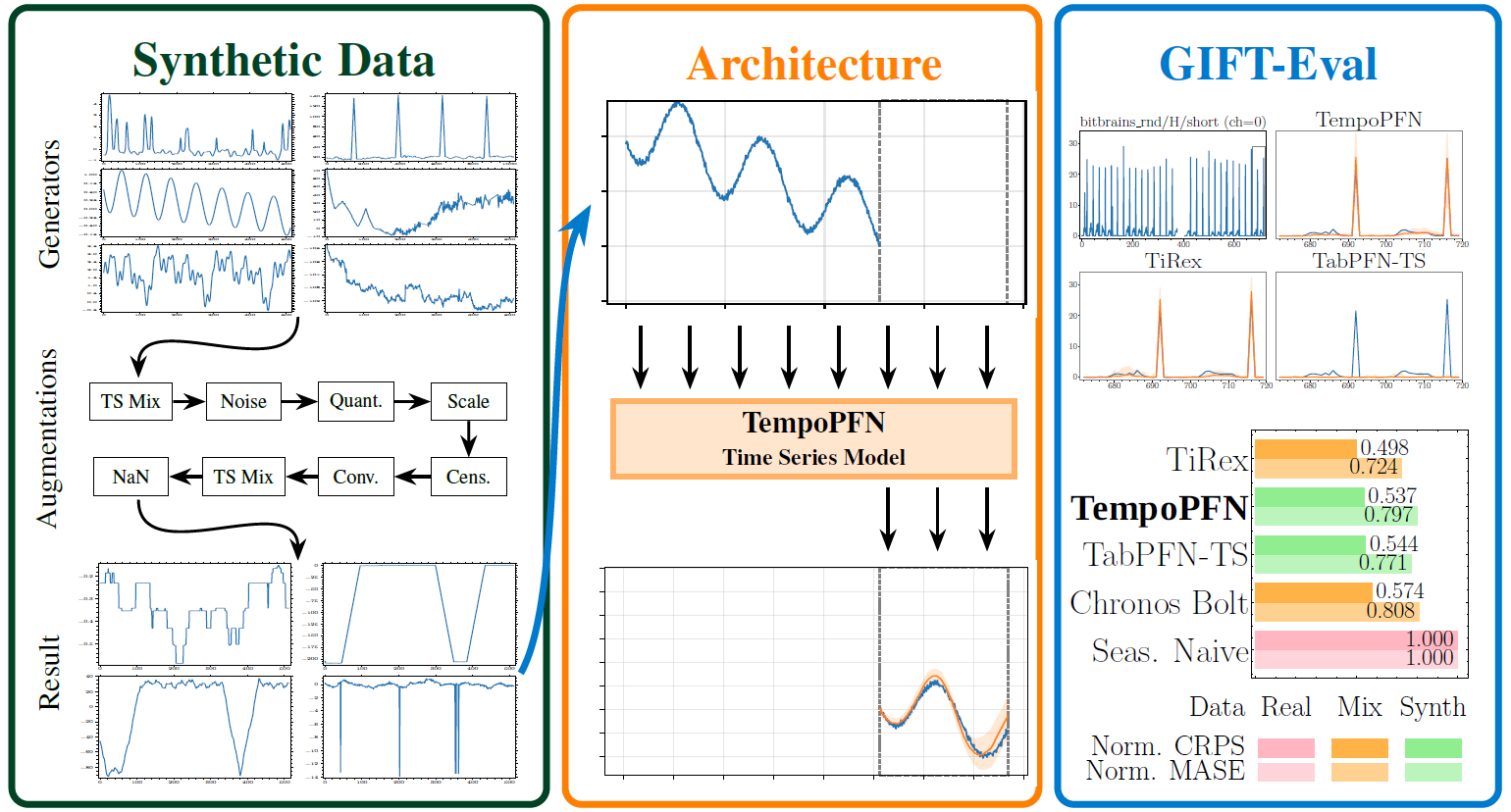
|
| 35 |
+
|
| 36 |
+
## ⚙️ Installation
|
| 37 |
+
|
| 38 |
+
> **Note on Model Weights:** This repository uses [Git LFS](https://git-lfs.github.com/) to store the model checkpoint (`.pth` file). You **must** have Git LFS installed to clone the repository correctly.
|
| 39 |
+
>
|
| 40 |
+
> ```bash
|
| 41 |
+
> # Install Git LFS (e.g., on Ubuntu)
|
| 42 |
+
> sudo apt-get install git-lfs
|
| 43 |
+
> git lfs install
|
| 44 |
+
> ```
|
| 45 |
+
|
| 46 |
+
1. **Clone the repository:**
|
| 47 |
+
```bash
|
| 48 |
+
git clone https://huggingface.co/AutoML-org/TempoPFN
|
| 49 |
+
cd TempoPFN
|
| 50 |
+
```
|
| 51 |
+
|
| 52 |
+
2. **Set up the environment:**
|
| 53 |
+
```bash
|
| 54 |
+
python -m venv venv && source venv/bin/activate
|
| 55 |
+
|
| 56 |
+
# 1. Install PyTorch version matching your CUDA version
|
| 57 |
+
# Example for CUDA 12.8:
|
| 58 |
+
pip install torch --index-url https://download.pytorch.org/whl/cu128
|
| 59 |
+
|
| 60 |
+
# 2. Install TempoPFN and all other dependencies
|
| 61 |
+
pip install -r requirements.txt
|
| 62 |
+
export PYTHONPATH=$PWD
|
| 63 |
+
```
|
| 64 |
+
|
| 65 |
+
## 🚀 Quick Start: Run the Demo
|
| 66 |
+
|
| 67 |
+
**Prerequisites:**
|
| 68 |
+
* You must have a **CUDA-capable GPU** with a matching PyTorch version installed.
|
| 69 |
+
* You have run `export PYTHONPATH=$PWD` from the repo's root directory (see Installation).
|
| 70 |
+
|
| 71 |
+
### 1. Run the Quick Start Script
|
| 72 |
+
|
| 73 |
+
Run a demo forecast on a synthetic sine wave. This script will automatically find and load the `models/checkpoint_38M.pth` file included in this repository.
|
| 74 |
+
```bash
|
| 75 |
+
python examples/quick_start_tempo_pfn.py
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
### 2. Run with a Different Checkpoint (Optional)
|
| 79 |
+
|
| 80 |
+
If you have trained your own model, you can point the script to it:
|
| 81 |
+
```bash
|
| 82 |
+
python examples/quick_start_tempo_pfn.py --checkpoint /path/to/your/checkpoint.pth
|
| 83 |
+
```
|
| 84 |
+
|
| 85 |
+
### 3. Run the Notebook version
|
| 86 |
+
```bash
|
| 87 |
+
jupyter notebook examples/quick_start_tempo_pfn.ipynb
|
| 88 |
+
```
|
| 89 |
+
|
| 90 |
+
### Hardware & Performance Tips
|
| 91 |
+
|
| 92 |
+
**GPU Required:** Inference requires a CUDA-capable GPU. Tested on NVIDIA A100/H100.
|
| 93 |
+
|
| 94 |
+
**First Inference May Be Slow:** Initial calls for unseen sequence lengths trigger Triton kernel compilation. Subsequent runs are cached and fast.
|
| 95 |
+
|
| 96 |
+
**Triton Caches:** To prevent slowdowns from writing caches to a network filesystem, route caches to a local directory (like `/tmp`) before running:
|
| 97 |
+
```bash
|
| 98 |
+
LOCAL_CACHE_BASE="${TMPDIR:-/tmp}/tsf-$(date +%s)"
|
| 99 |
+
mkdir -p "${LOCAL_CACHE_BASE}/triton" "${LOCAL_CACHE_BASE}/torchinductor"
|
| 100 |
+
export TRITON_CACHE_DIR="${LOCAL_CACHE_BASE}/triton"
|
| 101 |
+
export TORCHINDUCTOR_CACHE_DIR="${LOCAL_CACHE_BASE}/torchinductor"
|
| 102 |
+
|
| 103 |
+
python examples/quick_start_tempo_pfn.py
|
| 104 |
+
```
|
| 105 |
+
|
| 106 |
+
## 🚂 Training
|
| 107 |
+
|
| 108 |
+
### Single-GPU Training (for debugging)
|
| 109 |
+
```bash
|
| 110 |
+
torchrun --standalone --nproc_per_node=1 src/training/trainer_dist.py --config ./configs/train.yaml
|
| 111 |
+
```
|
| 112 |
+
|
| 113 |
+
### Multi-GPU Training (Single-Node)
|
| 114 |
+
|
| 115 |
+
This example uses 8 GPUs. The training script uses PyTorch DistributedDataParallel (DDP).
|
| 116 |
+
```bash
|
| 117 |
+
torchrun --standalone --nproc_per_node=8 src/training/trainer_dist.py --config ./configs/train.yaml
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
### Configuration
|
| 121 |
+
|
| 122 |
+
All training and model parameters are controlled via YAML files in `configs/` (architecture, optimizers, paths).
|
| 123 |
+
|
| 124 |
+
## 💾 Synthetic Data Generation
|
| 125 |
+
|
| 126 |
+
A core contribution of this work is our open-source synthetic data pipeline, located in `src/synthetic_generation/`. It combines diverse generators with a powerful augmentation cascade.
|
| 127 |
+
|
| 128 |
+
**Generators Used:**
|
| 129 |
+
|
| 130 |
+
* **Adapted Priors:** ForecastPFN, KernelSynth, GaussianProcess (GP), and CauKer (Structural Causal Models).
|
| 131 |
+
* **Novel Priors:** SDE (a flexible regime-switching Ornstein-Uhlenbeck process), Sawtooth, StepFunction, Anomaly, Spikes, SineWave, and Audio-Inspired generators (Stochastic Rhythms, Financial Volatility, Network Topology, Multi-Scale Fractals).
|
| 132 |
+
|
| 133 |
+
You can easily generate your own data by installing the development dependencies and instantiating a generator wrapper. See `examples/generate_synthetic_data.py` for a minimal script, or inspect the generator code in `src/synthetic_generation/`.
|
| 134 |
+
|
| 135 |
+
## 🤝 License
|
| 136 |
+
|
| 137 |
+
This project is licensed under the Apache 2.0 License. See the LICENSE file for details. This permissive license allows for both academic and commercial use.
|
| 138 |
+
|
| 139 |
+
## 📚 Citation
|
| 140 |
+
|
| 141 |
+
If you find TempoPFN useful in your research, please consider citing our paper:
|
| 142 |
+
```bibtex
|
| 143 |
+
@misc{moroshan2025tempopfn,
|
| 144 |
+
title={TempoPFN: Synthetic Pre-training of Linear RNNs for Zero-Shot Time Series Forecasting},
|
| 145 |
+
author={Vladyslav Moroshan and Julien Siems and Arber Zela and Timur Carstensen and Frank Hutter},
|
| 146 |
+
year={2025},
|
| 147 |
+
eprint={2510.25502},
|
| 148 |
+
archivePrefix={arXiv},
|
| 149 |
+
primaryClass={cs.LG}
|
| 150 |
+
}
|
| 151 |
+
```
|
configs/example.yaml
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
train_data_path: null # Replace with the path to root of the training data directory with subdirectories for each generator (e.g. gp, kernel, etc.)
|
| 2 |
+
model_path: ./models # Path where the model will be saved
|
| 3 |
+
model_name: TempoPFN
|
| 4 |
+
continue_training: false
|
| 5 |
+
checkpoint_path: null # Replace with the path to the checkpoint file
|
| 6 |
+
seed: 2025
|
| 7 |
+
wandb: true # whether to log to wandb
|
| 8 |
+
wandb_project_name: TempoPFNTraining
|
| 9 |
+
wandb_entity: university-of-freiburg-2024
|
| 10 |
+
wandb_plots: false
|
| 11 |
+
|
| 12 |
+
batch_size: 40
|
| 13 |
+
num_training_iterations: 1000000 # 1M
|
| 14 |
+
validation_batch_size: 64
|
| 15 |
+
num_validation_batches: 1
|
| 16 |
+
num_workers: 4
|
| 17 |
+
gradient_accumulation_enabled: true
|
| 18 |
+
accumulation_steps: 5 # Number of batches to accumulate before updating (effective batch size = batch_size * accumulation_steps)
|
| 19 |
+
log_interval: 2048
|
| 20 |
+
save_every: 100000
|
| 21 |
+
|
| 22 |
+
generator_proportions:
|
| 23 |
+
forecast_pfn: 1.0
|
| 24 |
+
gp: 1.0
|
| 25 |
+
kernel: 1.0
|
| 26 |
+
sawtooth: 1.0
|
| 27 |
+
sinewave: 1.0
|
| 28 |
+
step: 1.0
|
| 29 |
+
anomaly: 1.0
|
| 30 |
+
spike: 1.0
|
| 31 |
+
cauker_univariate: 1.0
|
| 32 |
+
ou_process: 3.0
|
| 33 |
+
audio_financial_volatility: 0.1
|
| 34 |
+
audio_multi_scale_fractal: 0.1
|
| 35 |
+
audio_network_topology: 0.5
|
| 36 |
+
audio_stochastic_rhythm: 0.5
|
| 37 |
+
augmented_per_sample_2048: 2.0
|
| 38 |
+
augmented_temp_batch_2048: 2.0
|
| 39 |
+
|
| 40 |
+
# Learning Rate Scheduler Configuration
|
| 41 |
+
lr_scheduler: cosine # Options: "warmup_stable_decay", "cosine_with_warmup", "cosine_with_restarts", "cosine"
|
| 42 |
+
|
| 43 |
+
# Learning Rate Parameters
|
| 44 |
+
peak_lr: 0.0002 # 2e-4 - Peak learning rate
|
| 45 |
+
min_lr_ratio: 0.01 # Minimum LR as fraction of peak LR
|
| 46 |
+
|
| 47 |
+
# WSD Scheduler Specific Parameters
|
| 48 |
+
warmup_ratio: 0.003 # 0.3% of total steps for warmup
|
| 49 |
+
stable_ratio: 0.90 # 90% of total steps at stable learning rate
|
| 50 |
+
decay_type: cosine # Type of decay: "cosine" or "linear"
|
| 51 |
+
|
| 52 |
+
# Alternative Scheduler Parameters (if using different schedulers)
|
| 53 |
+
num_cycles: 0.5 # For cosine_with_warmup: 0.5 = half cosine wave
|
| 54 |
+
num_restart_cycles: 4 # For cosine_with_restarts: number of restart cycles
|
| 55 |
+
|
| 56 |
+
# Optimizer Configuration
|
| 57 |
+
weight_decay: 0.01 # Weight decay for AdamW
|
| 58 |
+
beta1: 0.9 # Adam beta1 parameter
|
| 59 |
+
beta2: 0.98 # Adam beta2 parameter (optimized for transformers)
|
| 60 |
+
optimizer_eps: 1e-6 # Adam epsilon
|
| 61 |
+
|
| 62 |
+
# Training Stability
|
| 63 |
+
gradient_clip_val: 100.0
|
| 64 |
+
scaler: custom_robust
|
| 65 |
+
|
| 66 |
+
gift_eval:
|
| 67 |
+
evaluate_on_gift_eval: false
|
| 68 |
+
max_context_length: 3072
|
| 69 |
+
create_plots: false
|
| 70 |
+
max_plots: 5
|
| 71 |
+
dataset_storage_path: null # Replace with the path to the dataset storage path
|
| 72 |
+
|
| 73 |
+
data_augmentation:
|
| 74 |
+
nan_augmentation: true
|
| 75 |
+
scaler_augmentation: false
|
| 76 |
+
length_shortening: true
|
| 77 |
+
nan_stats_path: ./data/nan_stats.json
|
| 78 |
+
|
| 79 |
+
augmentation_probabilities:
|
| 80 |
+
scaler_augmentation: 0.5
|
| 81 |
+
|
| 82 |
+
TimeSeriesModel:
|
| 83 |
+
# Core architecture
|
| 84 |
+
embed_size: 512
|
| 85 |
+
num_encoder_layers: 10
|
| 86 |
+
|
| 87 |
+
# Scaling and preprocessing
|
| 88 |
+
scaler: custom_robust
|
| 89 |
+
epsilon: 0.00001
|
| 90 |
+
scaler_clamp_value: null
|
| 91 |
+
handle_constants: false
|
| 92 |
+
|
| 93 |
+
# Time features
|
| 94 |
+
K_max: 25
|
| 95 |
+
time_feature_config:
|
| 96 |
+
use_enhanced_features: true
|
| 97 |
+
use_holiday_features: false
|
| 98 |
+
use_index_features: true
|
| 99 |
+
include_seasonality_info: true
|
| 100 |
+
|
| 101 |
+
drop_enc_allow: false
|
| 102 |
+
encoding_dropout: 0.0
|
| 103 |
+
|
| 104 |
+
# Encoder configuration
|
| 105 |
+
encoder_config:
|
| 106 |
+
attn_mode: chunk
|
| 107 |
+
num_heads: 4
|
| 108 |
+
expand_v: 1.0
|
| 109 |
+
use_short_conv: true
|
| 110 |
+
conv_size: 32
|
| 111 |
+
allow_neg_eigval: true
|
| 112 |
+
hidden_ratio: 1.0
|
| 113 |
+
use_gate: true
|
| 114 |
+
use_forget_gate: true
|
| 115 |
+
num_householder: 4
|
| 116 |
+
weaving: true
|
| 117 |
+
|
| 118 |
+
loss_type: 'quantile'
|
| 119 |
+
quantiles: [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]
|
data/dataset_properties.json
ADDED
|
@@ -0,0 +1,152 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"m4_yearly": {
|
| 3 |
+
"domain": "Econ/Fin",
|
| 4 |
+
"frequency": "A",
|
| 5 |
+
"num_variates": 1
|
| 6 |
+
},
|
| 7 |
+
"m4_quarterly": {
|
| 8 |
+
"domain": "Econ/Fin",
|
| 9 |
+
"frequency": "Q",
|
| 10 |
+
"num_variates": 1
|
| 11 |
+
},
|
| 12 |
+
"m4_monthly": {
|
| 13 |
+
"domain": "Econ/Fin",
|
| 14 |
+
"frequency": "M",
|
| 15 |
+
"num_variates": 1
|
| 16 |
+
},
|
| 17 |
+
"m4_weekly": {
|
| 18 |
+
"domain": "Econ/Fin",
|
| 19 |
+
"frequency": "W",
|
| 20 |
+
"num_variates": 1
|
| 21 |
+
},
|
| 22 |
+
"m4_daily": {
|
| 23 |
+
"domain": "Econ/Fin",
|
| 24 |
+
"frequency": "D",
|
| 25 |
+
"num_variates": 1
|
| 26 |
+
},
|
| 27 |
+
"m4_hourly": {
|
| 28 |
+
"domain": "Econ/Fin",
|
| 29 |
+
"frequency": "H",
|
| 30 |
+
"num_variates": 1
|
| 31 |
+
},
|
| 32 |
+
"electricity": {
|
| 33 |
+
"domain": "Energy",
|
| 34 |
+
"frequency": "W",
|
| 35 |
+
"num_variates": 1
|
| 36 |
+
},
|
| 37 |
+
"ett1": {
|
| 38 |
+
"domain": "Energy",
|
| 39 |
+
"frequency": "W",
|
| 40 |
+
"num_variates": 7
|
| 41 |
+
},
|
| 42 |
+
"ett2": {
|
| 43 |
+
"domain": "Energy",
|
| 44 |
+
"frequency": "W",
|
| 45 |
+
"num_variates": 7
|
| 46 |
+
},
|
| 47 |
+
"solar": {
|
| 48 |
+
"domain": "Energy",
|
| 49 |
+
"frequency": "W",
|
| 50 |
+
"num_variates": 1
|
| 51 |
+
},
|
| 52 |
+
"hospital": {
|
| 53 |
+
"domain": "Healthcare",
|
| 54 |
+
"frequency": "M",
|
| 55 |
+
"num_variates": 1
|
| 56 |
+
},
|
| 57 |
+
"covid_deaths": {
|
| 58 |
+
"domain": "Healthcare",
|
| 59 |
+
"frequency": "D",
|
| 60 |
+
"num_variates": 1
|
| 61 |
+
},
|
| 62 |
+
"us_births": {
|
| 63 |
+
"domain": "Healthcare",
|
| 64 |
+
"frequency": "M",
|
| 65 |
+
"num_variates": 1
|
| 66 |
+
},
|
| 67 |
+
"saugeen": {
|
| 68 |
+
"domain": "Nature",
|
| 69 |
+
"frequency": "M",
|
| 70 |
+
"num_variates": 1
|
| 71 |
+
},
|
| 72 |
+
"temperature_rain": {
|
| 73 |
+
"domain": "Nature",
|
| 74 |
+
"frequency": "D",
|
| 75 |
+
"num_variates": 1
|
| 76 |
+
},
|
| 77 |
+
"kdd_cup_2018": {
|
| 78 |
+
"domain": "Nature",
|
| 79 |
+
"frequency": "D",
|
| 80 |
+
"num_variates": 1
|
| 81 |
+
},
|
| 82 |
+
"jena_weather": {
|
| 83 |
+
"domain": "Nature",
|
| 84 |
+
"frequency": "D",
|
| 85 |
+
"num_variates": 21
|
| 86 |
+
},
|
| 87 |
+
"car_parts": {
|
| 88 |
+
"domain": "Sales",
|
| 89 |
+
"frequency": "M",
|
| 90 |
+
"num_variates": 1
|
| 91 |
+
},
|
| 92 |
+
"restaurant": {
|
| 93 |
+
"domain": "Sales",
|
| 94 |
+
"frequency": "D",
|
| 95 |
+
"num_variates": 1
|
| 96 |
+
},
|
| 97 |
+
"hierarchical_sales": {
|
| 98 |
+
"domain": "Sales",
|
| 99 |
+
"frequency": "W-WED",
|
| 100 |
+
"num_variates": 1
|
| 101 |
+
},
|
| 102 |
+
"loop_seattle": {
|
| 103 |
+
"domain": "Transport",
|
| 104 |
+
"frequency": "D",
|
| 105 |
+
"num_variates": 1
|
| 106 |
+
},
|
| 107 |
+
"sz_taxi": {
|
| 108 |
+
"domain": "Transport",
|
| 109 |
+
"frequency": "H",
|
| 110 |
+
"num_variates": 1
|
| 111 |
+
},
|
| 112 |
+
"m_dense": {
|
| 113 |
+
"domain": "Transport",
|
| 114 |
+
"frequency": "D",
|
| 115 |
+
"num_variates": 1
|
| 116 |
+
},
|
| 117 |
+
"bitbrains_fast_storage": {
|
| 118 |
+
"domain": "Web/CloudOps",
|
| 119 |
+
"frequency": "H",
|
| 120 |
+
"num_variates": 2
|
| 121 |
+
},
|
| 122 |
+
"bitbrains_rnd": {
|
| 123 |
+
"domain": "Web/CloudOps",
|
| 124 |
+
"frequency": "H",
|
| 125 |
+
"num_variates": 2
|
| 126 |
+
},
|
| 127 |
+
"bizitobs_application": {
|
| 128 |
+
"domain": "Web/CloudOps",
|
| 129 |
+
"frequency": "10S",
|
| 130 |
+
"num_variates": 2
|
| 131 |
+
},
|
| 132 |
+
"bizitobs_service": {
|
| 133 |
+
"domain": "Web/CloudOps",
|
| 134 |
+
"frequency": "10S",
|
| 135 |
+
"num_variates": 2
|
| 136 |
+
},
|
| 137 |
+
"bizitobs_l2c": {
|
| 138 |
+
"domain": "Web/CloudOps",
|
| 139 |
+
"frequency": "H",
|
| 140 |
+
"num_variates": 7
|
| 141 |
+
},
|
| 142 |
+
"dd_benchmark_short": {
|
| 143 |
+
"domain": "Web/Observability",
|
| 144 |
+
"frequency": "Short",
|
| 145 |
+
"num_variates": 32
|
| 146 |
+
},
|
| 147 |
+
"dd_benchmark_long": {
|
| 148 |
+
"domain": "Web/Observability",
|
| 149 |
+
"frequency": "Long",
|
| 150 |
+
"num_variates": 32
|
| 151 |
+
}
|
| 152 |
+
}
|
data/nan_stats.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
examples/generate_synthetic_data.py
ADDED
|
@@ -0,0 +1,204 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import os
|
| 3 |
+
from typing import List, Optional
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
|
| 7 |
+
from src.data.containers import BatchTimeSeriesContainer
|
| 8 |
+
from src.data.utils import sample_future_length
|
| 9 |
+
from src.plotting.plot_timeseries import plot_from_container
|
| 10 |
+
from src.synthetic_generation.anomalies.anomaly_generator_wrapper import (
|
| 11 |
+
AnomalyGeneratorWrapper,
|
| 12 |
+
)
|
| 13 |
+
from src.synthetic_generation.cauker.cauker_generator_wrapper import (
|
| 14 |
+
CauKerGeneratorWrapper,
|
| 15 |
+
)
|
| 16 |
+
from src.synthetic_generation.forecast_pfn_prior.forecast_pfn_generator_wrapper import (
|
| 17 |
+
ForecastPFNGeneratorWrapper,
|
| 18 |
+
)
|
| 19 |
+
from src.synthetic_generation.generator_params import (
|
| 20 |
+
AnomalyGeneratorParams,
|
| 21 |
+
CauKerGeneratorParams,
|
| 22 |
+
FinancialVolatilityAudioParams,
|
| 23 |
+
ForecastPFNGeneratorParams,
|
| 24 |
+
GPGeneratorParams,
|
| 25 |
+
KernelGeneratorParams,
|
| 26 |
+
MultiScaleFractalAudioParams,
|
| 27 |
+
NetworkTopologyAudioParams,
|
| 28 |
+
OrnsteinUhlenbeckProcessGeneratorParams,
|
| 29 |
+
SawToothGeneratorParams,
|
| 30 |
+
SineWaveGeneratorParams,
|
| 31 |
+
SpikesGeneratorParams,
|
| 32 |
+
StepGeneratorParams,
|
| 33 |
+
StochasticRhythmAudioParams,
|
| 34 |
+
)
|
| 35 |
+
from src.synthetic_generation.gp_prior.gp_generator_wrapper import GPGeneratorWrapper
|
| 36 |
+
from src.synthetic_generation.kernel_synth.kernel_generator_wrapper import (
|
| 37 |
+
KernelGeneratorWrapper,
|
| 38 |
+
)
|
| 39 |
+
from src.synthetic_generation.ornstein_uhlenbeck_process.ou_generator_wrapper import (
|
| 40 |
+
OrnsteinUhlenbeckProcessGeneratorWrapper,
|
| 41 |
+
)
|
| 42 |
+
from src.synthetic_generation.sawtooth.sawtooth_generator_wrapper import (
|
| 43 |
+
SawToothGeneratorWrapper,
|
| 44 |
+
)
|
| 45 |
+
from src.synthetic_generation.sine_waves.sine_wave_generator_wrapper import (
|
| 46 |
+
SineWaveGeneratorWrapper,
|
| 47 |
+
)
|
| 48 |
+
from src.synthetic_generation.spikes.spikes_generator_wrapper import (
|
| 49 |
+
SpikesGeneratorWrapper,
|
| 50 |
+
)
|
| 51 |
+
from src.synthetic_generation.steps.step_generator_wrapper import StepGeneratorWrapper
|
| 52 |
+
|
| 53 |
+
PYO_AVAILABLE = True
|
| 54 |
+
try:
|
| 55 |
+
import pyo # requires portaudio to be installed
|
| 56 |
+
except (ImportError, OSError):
|
| 57 |
+
PYO_AVAILABLE = False
|
| 58 |
+
else:
|
| 59 |
+
from src.synthetic_generation.audio_generators.financial_volatility_wrapper import (
|
| 60 |
+
FinancialVolatilityAudioWrapper,
|
| 61 |
+
)
|
| 62 |
+
from src.synthetic_generation.audio_generators.multi_scale_fractal_wrapper import (
|
| 63 |
+
MultiScaleFractalAudioWrapper,
|
| 64 |
+
)
|
| 65 |
+
from src.synthetic_generation.audio_generators.network_topology_wrapper import (
|
| 66 |
+
NetworkTopologyAudioWrapper,
|
| 67 |
+
)
|
| 68 |
+
from src.synthetic_generation.audio_generators.stochastic_rhythm_wrapper import (
|
| 69 |
+
StochasticRhythmAudioWrapper,
|
| 70 |
+
)
|
| 71 |
+
|
| 72 |
+
logging.basicConfig(
|
| 73 |
+
level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s"
|
| 74 |
+
)
|
| 75 |
+
logger = logging.getLogger(__name__)
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def visualize_batch_sample(
|
| 79 |
+
generator,
|
| 80 |
+
batch_size: int = 8,
|
| 81 |
+
output_dir: str = "outputs/plots",
|
| 82 |
+
sample_idx: Optional[int] = None,
|
| 83 |
+
prefix: str = "",
|
| 84 |
+
seed: Optional[int] = None,
|
| 85 |
+
) -> None:
|
| 86 |
+
os.makedirs(output_dir, exist_ok=True)
|
| 87 |
+
name = generator.__class__.__name__
|
| 88 |
+
logger.info(f"[{name}] Generating batch of size {batch_size}")
|
| 89 |
+
|
| 90 |
+
batch = generator.generate_batch(batch_size=batch_size, seed=seed)
|
| 91 |
+
values = torch.from_numpy(batch.values)
|
| 92 |
+
if values.ndim == 2:
|
| 93 |
+
values = values.unsqueeze(-1)
|
| 94 |
+
|
| 95 |
+
future_length = sample_future_length(range="gift_eval")
|
| 96 |
+
history_values = values[:, :-future_length, :]
|
| 97 |
+
future_values = values[:, -future_length:, :]
|
| 98 |
+
|
| 99 |
+
container = BatchTimeSeriesContainer(
|
| 100 |
+
history_values=history_values,
|
| 101 |
+
future_values=future_values,
|
| 102 |
+
start=batch.start,
|
| 103 |
+
frequency=batch.frequency,
|
| 104 |
+
)
|
| 105 |
+
|
| 106 |
+
indices = [sample_idx] if sample_idx is not None else range(batch_size)
|
| 107 |
+
for i in indices:
|
| 108 |
+
filename = (
|
| 109 |
+
f"{prefix}_{name.lower().replace('generatorwrapper', '')}_sample_{i}.png"
|
| 110 |
+
)
|
| 111 |
+
output_file = os.path.join(output_dir, filename)
|
| 112 |
+
title = f"{prefix.capitalize()} {name.replace('GeneratorWrapper', '')} Synthetic Series (Sample {i})"
|
| 113 |
+
plot_from_container(
|
| 114 |
+
container, sample_idx=i, output_file=output_file, show=False, title=title
|
| 115 |
+
)
|
| 116 |
+
logger.info(f"[{name}] Saved plot to {output_file}")
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
def generator_factory(global_seed: int, total_length: int) -> List:
|
| 120 |
+
generators = [
|
| 121 |
+
KernelGeneratorWrapper(
|
| 122 |
+
KernelGeneratorParams(global_seed=global_seed, length=total_length)
|
| 123 |
+
),
|
| 124 |
+
GPGeneratorWrapper(
|
| 125 |
+
GPGeneratorParams(global_seed=global_seed, length=total_length)
|
| 126 |
+
),
|
| 127 |
+
ForecastPFNGeneratorWrapper(
|
| 128 |
+
ForecastPFNGeneratorParams(global_seed=global_seed, length=total_length)
|
| 129 |
+
),
|
| 130 |
+
SineWaveGeneratorWrapper(
|
| 131 |
+
SineWaveGeneratorParams(global_seed=global_seed, length=total_length)
|
| 132 |
+
),
|
| 133 |
+
SawToothGeneratorWrapper(
|
| 134 |
+
SawToothGeneratorParams(global_seed=global_seed, length=total_length)
|
| 135 |
+
),
|
| 136 |
+
StepGeneratorWrapper(
|
| 137 |
+
StepGeneratorParams(global_seed=global_seed, length=total_length)
|
| 138 |
+
),
|
| 139 |
+
AnomalyGeneratorWrapper(
|
| 140 |
+
AnomalyGeneratorParams(global_seed=global_seed, length=total_length)
|
| 141 |
+
),
|
| 142 |
+
SpikesGeneratorWrapper(
|
| 143 |
+
SpikesGeneratorParams(global_seed=global_seed, length=total_length)
|
| 144 |
+
),
|
| 145 |
+
CauKerGeneratorWrapper(
|
| 146 |
+
CauKerGeneratorParams(
|
| 147 |
+
global_seed=global_seed, length=total_length, num_channels=5
|
| 148 |
+
)
|
| 149 |
+
),
|
| 150 |
+
OrnsteinUhlenbeckProcessGeneratorWrapper(
|
| 151 |
+
OrnsteinUhlenbeckProcessGeneratorParams(
|
| 152 |
+
global_seed=global_seed, length=total_length
|
| 153 |
+
)
|
| 154 |
+
),
|
| 155 |
+
]
|
| 156 |
+
|
| 157 |
+
if PYO_AVAILABLE:
|
| 158 |
+
generators.extend(
|
| 159 |
+
[
|
| 160 |
+
StochasticRhythmAudioWrapper(
|
| 161 |
+
StochasticRhythmAudioParams(
|
| 162 |
+
global_seed=global_seed, length=total_length
|
| 163 |
+
)
|
| 164 |
+
),
|
| 165 |
+
FinancialVolatilityAudioWrapper(
|
| 166 |
+
FinancialVolatilityAudioParams(
|
| 167 |
+
global_seed=global_seed, length=total_length
|
| 168 |
+
)
|
| 169 |
+
),
|
| 170 |
+
MultiScaleFractalAudioWrapper(
|
| 171 |
+
MultiScaleFractalAudioParams(
|
| 172 |
+
global_seed=global_seed, length=total_length
|
| 173 |
+
)
|
| 174 |
+
),
|
| 175 |
+
NetworkTopologyAudioWrapper(
|
| 176 |
+
NetworkTopologyAudioParams(
|
| 177 |
+
global_seed=global_seed, length=total_length
|
| 178 |
+
)
|
| 179 |
+
),
|
| 180 |
+
]
|
| 181 |
+
)
|
| 182 |
+
else:
|
| 183 |
+
logger.warning("Audio generators skipped (pyo not available)")
|
| 184 |
+
|
| 185 |
+
return generators
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
if __name__ == "__main__":
|
| 189 |
+
batch_size = 2
|
| 190 |
+
total_length = 2048
|
| 191 |
+
output_dir = "outputs/plots"
|
| 192 |
+
global_seed = 2025
|
| 193 |
+
|
| 194 |
+
logger.info(f"Saving plots to {output_dir}")
|
| 195 |
+
|
| 196 |
+
for gen in generator_factory(global_seed, total_length):
|
| 197 |
+
prefix = "multivariate" if getattr(gen.params, "num_channels", 1) > 1 else ""
|
| 198 |
+
visualize_batch_sample(
|
| 199 |
+
gen,
|
| 200 |
+
batch_size=batch_size,
|
| 201 |
+
output_dir=output_dir,
|
| 202 |
+
prefix=prefix,
|
| 203 |
+
seed=global_seed,
|
| 204 |
+
)
|
examples/gift_eval/gift_eval_runner.py
ADDED
|
@@ -0,0 +1,251 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
"""
|
| 3 |
+
GIFT-Eval Runner Script
|
| 4 |
+
|
| 5 |
+
This script evaluates the Time Series model on GIFT-Eval datasets using the `src/gift_eval` pipeline.
|
| 6 |
+
|
| 7 |
+
- Uses `src/gift_eval/data.py` for dataset handling.
|
| 8 |
+
- Uses `src/gift_eval/predictor.TimeSeriesPredictor` for inference.
|
| 9 |
+
- Loads a model from a checkpoint.
|
| 10 |
+
- Writes per-dataset CSV metrics to `output_dir` without creating plots.
|
| 11 |
+
"""
|
| 12 |
+
|
| 13 |
+
import argparse
|
| 14 |
+
import logging
|
| 15 |
+
from pathlib import Path
|
| 16 |
+
from typing import List, Optional
|
| 17 |
+
|
| 18 |
+
from examples.utils import download_checkpoint_if_needed
|
| 19 |
+
from src.gift_eval.constants import ALL_DATASETS
|
| 20 |
+
from src.gift_eval.evaluate import evaluate_datasets
|
| 21 |
+
from src.gift_eval.predictor import TimeSeriesPredictor
|
| 22 |
+
from src.gift_eval.results import aggregate_results, write_results_to_disk
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
# Configure logging
|
| 26 |
+
logging.basicConfig(
|
| 27 |
+
level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s"
|
| 28 |
+
)
|
| 29 |
+
logging.getLogger("matplotlib").setLevel(logging.WARNING)
|
| 30 |
+
logging.getLogger("matplotlib.font_manager").setLevel(logging.WARNING)
|
| 31 |
+
logger = logging.getLogger("gift_eval_runner")
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def _expand_datasets_arg(datasets_arg: List[str] | str) -> List[str]:
|
| 35 |
+
"""Expand dataset argument to list of dataset names."""
|
| 36 |
+
if isinstance(datasets_arg, str):
|
| 37 |
+
if datasets_arg == "all":
|
| 38 |
+
return list(ALL_DATASETS)
|
| 39 |
+
datasets_list = [datasets_arg]
|
| 40 |
+
else:
|
| 41 |
+
datasets_list = datasets_arg
|
| 42 |
+
if datasets_list and datasets_list[0] == "all":
|
| 43 |
+
return list(ALL_DATASETS)
|
| 44 |
+
|
| 45 |
+
for ds in datasets_list:
|
| 46 |
+
if ds not in ALL_DATASETS:
|
| 47 |
+
raise ValueError(f"Invalid dataset: {ds}. Use one of {ALL_DATASETS}")
|
| 48 |
+
return datasets_list
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def run_evaluation(
|
| 52 |
+
predictor: TimeSeriesPredictor,
|
| 53 |
+
datasets_arg: List[str] | str,
|
| 54 |
+
terms_arg: List[str],
|
| 55 |
+
dataset_storage_path: str,
|
| 56 |
+
max_windows_arg: Optional[int],
|
| 57 |
+
batch_size_arg: int,
|
| 58 |
+
max_context_length_arg: Optional[int],
|
| 59 |
+
output_dir_arg: str,
|
| 60 |
+
model_name_arg: str,
|
| 61 |
+
after_each_dataset_flush: bool = True,
|
| 62 |
+
) -> None:
|
| 63 |
+
"""Run evaluation on specified datasets."""
|
| 64 |
+
datasets_to_run = _expand_datasets_arg(datasets_arg)
|
| 65 |
+
results_root = Path(output_dir_arg)
|
| 66 |
+
|
| 67 |
+
for ds_name in datasets_to_run:
|
| 68 |
+
items = evaluate_datasets(
|
| 69 |
+
predictor=predictor,
|
| 70 |
+
dataset=ds_name,
|
| 71 |
+
dataset_storage_path=dataset_storage_path,
|
| 72 |
+
terms=terms_arg,
|
| 73 |
+
max_windows=max_windows_arg,
|
| 74 |
+
batch_size=batch_size_arg,
|
| 75 |
+
max_context_length=max_context_length_arg,
|
| 76 |
+
create_plots=False,
|
| 77 |
+
max_plots_per_dataset=0,
|
| 78 |
+
)
|
| 79 |
+
write_results_to_disk(
|
| 80 |
+
items=items,
|
| 81 |
+
dataset_name=ds_name,
|
| 82 |
+
output_dir=results_root,
|
| 83 |
+
model_name=model_name_arg,
|
| 84 |
+
create_plots=False,
|
| 85 |
+
)
|
| 86 |
+
if after_each_dataset_flush:
|
| 87 |
+
logger.info("Flushed results for %s", ds_name)
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
def main():
|
| 91 |
+
"""Main execution function."""
|
| 92 |
+
parser = argparse.ArgumentParser(
|
| 93 |
+
description="GIFT-Eval Runner: Evaluate TimeSeriesModel on GIFT-Eval datasets"
|
| 94 |
+
)
|
| 95 |
+
|
| 96 |
+
# Model configuration
|
| 97 |
+
parser.add_argument(
|
| 98 |
+
"--model_path",
|
| 99 |
+
type=str,
|
| 100 |
+
default=None,
|
| 101 |
+
help="Path to model checkpoint. If not provided, will download from checkpoint_url.",
|
| 102 |
+
)
|
| 103 |
+
parser.add_argument(
|
| 104 |
+
"--config_path",
|
| 105 |
+
type=str,
|
| 106 |
+
default="configs/example.yaml",
|
| 107 |
+
help="Path to model config YAML (default: configs/example.yaml)",
|
| 108 |
+
)
|
| 109 |
+
parser.add_argument(
|
| 110 |
+
"--checkpoint_url",
|
| 111 |
+
type=str,
|
| 112 |
+
default="https://www.dropbox.com/scl/fi/mqsni5lehooyaw93y3uzq/checkpoint_38M.pth?rlkey=3uyehvmtted02xkha24zgpzb6&st=seevsbkn&dl=0",
|
| 113 |
+
help="URL to download checkpoint from if model_path is not provided",
|
| 114 |
+
)
|
| 115 |
+
parser.add_argument(
|
| 116 |
+
"--download_dir",
|
| 117 |
+
type=str,
|
| 118 |
+
default="models",
|
| 119 |
+
help="Directory to download checkpoint to (default: models)",
|
| 120 |
+
)
|
| 121 |
+
|
| 122 |
+
# Dataset configuration
|
| 123 |
+
parser.add_argument(
|
| 124 |
+
"--datasets",
|
| 125 |
+
type=str,
|
| 126 |
+
nargs="+",
|
| 127 |
+
default=["all"],
|
| 128 |
+
help='List of dataset names or ["all"] (default: all)',
|
| 129 |
+
)
|
| 130 |
+
parser.add_argument(
|
| 131 |
+
"--terms",
|
| 132 |
+
type=str,
|
| 133 |
+
nargs="+",
|
| 134 |
+
default=["short", "medium", "long"],
|
| 135 |
+
help="Prediction terms to evaluate (default: short medium long)",
|
| 136 |
+
)
|
| 137 |
+
parser.add_argument(
|
| 138 |
+
"--dataset_storage_path",
|
| 139 |
+
type=str,
|
| 140 |
+
default="/work/dlclarge2/moroshav-GiftEvalPretrain/gift_eval",
|
| 141 |
+
# required=True,
|
| 142 |
+
help="Path to the root of the gift eval datasets storage directory",
|
| 143 |
+
)
|
| 144 |
+
parser.add_argument(
|
| 145 |
+
"--max_windows",
|
| 146 |
+
type=int,
|
| 147 |
+
default=20,
|
| 148 |
+
help="Maximum number of windows to use for evaluation (default: 20)",
|
| 149 |
+
)
|
| 150 |
+
|
| 151 |
+
# Inference configuration
|
| 152 |
+
parser.add_argument(
|
| 153 |
+
"--batch_size",
|
| 154 |
+
type=int,
|
| 155 |
+
default=64,
|
| 156 |
+
help="Batch size for inference (default: 128)",
|
| 157 |
+
)
|
| 158 |
+
parser.add_argument(
|
| 159 |
+
"--max_context_length",
|
| 160 |
+
type=int,
|
| 161 |
+
default=3072,
|
| 162 |
+
help="Maximum context length (default: 3072)",
|
| 163 |
+
)
|
| 164 |
+
|
| 165 |
+
# Output configuration
|
| 166 |
+
parser.add_argument(
|
| 167 |
+
"--output_dir",
|
| 168 |
+
type=str,
|
| 169 |
+
default="gift_eval_results",
|
| 170 |
+
help="Output directory for results (default: gift_eval_results)",
|
| 171 |
+
)
|
| 172 |
+
parser.add_argument(
|
| 173 |
+
"--model_name",
|
| 174 |
+
type=str,
|
| 175 |
+
default="TempoPFN",
|
| 176 |
+
help="Model name identifier for results (default: TempoPFN)",
|
| 177 |
+
)
|
| 178 |
+
parser.add_argument(
|
| 179 |
+
"--no_flush",
|
| 180 |
+
action="store_true",
|
| 181 |
+
help="Disable flushing results after each dataset",
|
| 182 |
+
)
|
| 183 |
+
|
| 184 |
+
args = parser.parse_args()
|
| 185 |
+
|
| 186 |
+
# Resolve paths
|
| 187 |
+
config_path = Path(args.config_path)
|
| 188 |
+
download_dir = Path(args.download_dir)
|
| 189 |
+
output_dir = Path(args.output_dir)
|
| 190 |
+
|
| 191 |
+
# Determine model path
|
| 192 |
+
resolved_model_path = None
|
| 193 |
+
if args.model_path:
|
| 194 |
+
resolved_model_path = args.model_path
|
| 195 |
+
elif args.checkpoint_url:
|
| 196 |
+
resolved_model_path = download_checkpoint_if_needed(
|
| 197 |
+
args.checkpoint_url, target_dir=download_dir
|
| 198 |
+
)
|
| 199 |
+
|
| 200 |
+
if not resolved_model_path:
|
| 201 |
+
raise FileNotFoundError(
|
| 202 |
+
"No model checkpoint provided. Set --model_path or --checkpoint_url."
|
| 203 |
+
)
|
| 204 |
+
|
| 205 |
+
if not config_path.exists():
|
| 206 |
+
raise FileNotFoundError(f"Config not found: {config_path}")
|
| 207 |
+
|
| 208 |
+
logger.info("Loading predictor from checkpoint: %s", resolved_model_path)
|
| 209 |
+
predictor = TimeSeriesPredictor.from_paths(
|
| 210 |
+
model_path=resolved_model_path,
|
| 211 |
+
config_path=str(config_path),
|
| 212 |
+
ds_prediction_length=1, # placeholder; set per dataset
|
| 213 |
+
ds_freq="D", # placeholder; set per dataset
|
| 214 |
+
batch_size=args.batch_size,
|
| 215 |
+
max_context_length=args.max_context_length,
|
| 216 |
+
)
|
| 217 |
+
|
| 218 |
+
logger.info("Starting evaluation...")
|
| 219 |
+
logger.info(" Datasets: %s", args.datasets)
|
| 220 |
+
logger.info(" Terms: %s", args.terms)
|
| 221 |
+
logger.info(" Output directory: %s", output_dir)
|
| 222 |
+
|
| 223 |
+
# Run evaluation
|
| 224 |
+
run_evaluation(
|
| 225 |
+
predictor=predictor,
|
| 226 |
+
datasets_arg=args.datasets,
|
| 227 |
+
terms_arg=args.terms,
|
| 228 |
+
dataset_storage_path=args.dataset_storage_path,
|
| 229 |
+
max_windows_arg=args.max_windows,
|
| 230 |
+
batch_size_arg=args.batch_size,
|
| 231 |
+
max_context_length_arg=args.max_context_length,
|
| 232 |
+
output_dir_arg=str(output_dir),
|
| 233 |
+
model_name_arg=args.model_name,
|
| 234 |
+
after_each_dataset_flush=not args.no_flush,
|
| 235 |
+
)
|
| 236 |
+
|
| 237 |
+
logger.info("Evaluation complete. See results under: %s", output_dir)
|
| 238 |
+
|
| 239 |
+
# Aggregate all results into a single CSV file
|
| 240 |
+
logger.info("Aggregating results from all datasets...")
|
| 241 |
+
combined_df = aggregate_results(result_root_dir=output_dir)
|
| 242 |
+
|
| 243 |
+
if combined_df is not None:
|
| 244 |
+
logger.info("Successfully created aggregated results file: %s/all_results.csv", output_dir)
|
| 245 |
+
else:
|
| 246 |
+
logger.warning("No results to aggregate. Check that evaluation completed successfully.")
|
| 247 |
+
|
| 248 |
+
|
| 249 |
+
if __name__ == "__main__":
|
| 250 |
+
main()
|
| 251 |
+
|
examples/gift_eval/gift_eval_submission.ipynb
ADDED
|
@@ -0,0 +1,1439 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "e8a9f0b1",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"# Running TempoPFN on GIFT-Eval Benchmark\n",
|
| 9 |
+
"\n",
|
| 10 |
+
"This notebook evaluates the **TempoPFN** model on the GIFT-Eval benchmark. \n",
|
| 11 |
+
"\n",
|
| 12 |
+
"Make sure you download the gift-eval benchmark and set the `GIFT_EVAL_DATASET_STORAGE_PATH` environment variable correctly before running this notebook."
|
| 13 |
+
]
|
| 14 |
+
},
|
| 15 |
+
{
|
| 16 |
+
"cell_type": "markdown",
|
| 17 |
+
"id": "f1d2e3c4",
|
| 18 |
+
"metadata": {},
|
| 19 |
+
"source": [
|
| 20 |
+
"## 1. Setup and Dependencies\n",
|
| 21 |
+
"\n",
|
| 22 |
+
"First, install the required packages. \n",
|
| 23 |
+
"\n",
|
| 24 |
+
"**Note:** This notebook assumes that the core `TempoPFN` model code (e.g., `src.models.model`, `src.data.containers`) and dependencies are installed as a Python package or are otherwise available in the `PYTHONPATH`."
|
| 25 |
+
]
|
| 26 |
+
},
|
| 27 |
+
{
|
| 28 |
+
"cell_type": "markdown",
|
| 29 |
+
"id": "b9c8d7e6",
|
| 30 |
+
"metadata": {},
|
| 31 |
+
"source": [
|
| 32 |
+
"## 2. Imports\n",
|
| 33 |
+
"\n",
|
| 34 |
+
"Import all necessary libraries. "
|
| 35 |
+
]
|
| 36 |
+
},
|
| 37 |
+
{
|
| 38 |
+
"cell_type": "code",
|
| 39 |
+
"execution_count": null,
|
| 40 |
+
"id": "c7d8e9f0",
|
| 41 |
+
"metadata": {},
|
| 42 |
+
"outputs": [],
|
| 43 |
+
"source": [
|
| 44 |
+
"import json\n",
|
| 45 |
+
"import logging\n",
|
| 46 |
+
"import os\n",
|
| 47 |
+
"import math\n",
|
| 48 |
+
"import csv\n",
|
| 49 |
+
"import glob\n",
|
| 50 |
+
"import argparse\n",
|
| 51 |
+
"import warnings\n",
|
| 52 |
+
"import yaml\n",
|
| 53 |
+
"from pathlib import Path\n",
|
| 54 |
+
"from typing import List, Optional, Dict, Tuple, Union, Iterator, Iterable, Any\n",
|
| 55 |
+
"from functools import cached_property\n",
|
| 56 |
+
"from enum import Enum\n",
|
| 57 |
+
"from dataclasses import dataclass\n",
|
| 58 |
+
"\n",
|
| 59 |
+
"import pandas as pd\n",
|
| 60 |
+
"import numpy as np\n",
|
| 61 |
+
"import torch\n",
|
| 62 |
+
"from torch.nn.parallel import DistributedDataParallel as DDP\n",
|
| 63 |
+
"from dotenv import load_dotenv\n",
|
| 64 |
+
"\n",
|
| 65 |
+
"# GluonTS and Data Handling\n",
|
| 66 |
+
"import datasets\n",
|
| 67 |
+
"import pyarrow.compute as pc\n",
|
| 68 |
+
"from gluonts.dataset import DataEntry\n",
|
| 69 |
+
"from gluonts.dataset.common import ProcessDataEntry\n",
|
| 70 |
+
"from gluonts.dataset.split import TestData, TrainingDataset, split\n",
|
| 71 |
+
"from gluonts.itertools import Map\n",
|
| 72 |
+
"from gluonts.time_feature import norm_freq_str, get_seasonality\n",
|
| 73 |
+
"from gluonts.transform import Transformation\n",
|
| 74 |
+
"from pandas.tseries.frequencies import to_offset\n",
|
| 75 |
+
"from toolz import compose\n",
|
| 76 |
+
"\n",
|
| 77 |
+
"# GluonTS Evaluation\n",
|
| 78 |
+
"from gluonts.ev.metrics import (\n",
|
| 79 |
+
" MAE,\n",
|
| 80 |
+
" MAPE,\n",
|
| 81 |
+
" MASE,\n",
|
| 82 |
+
" MSE,\n",
|
| 83 |
+
" MSIS,\n",
|
| 84 |
+
" ND,\n",
|
| 85 |
+
" NRMSE,\n",
|
| 86 |
+
" RMSE,\n",
|
| 87 |
+
" SMAPE,\n",
|
| 88 |
+
" MeanWeightedSumQuantileLoss,\n",
|
| 89 |
+
")\n",
|
| 90 |
+
"from gluonts.model.evaluation import evaluate_model\n",
|
| 91 |
+
"from gluonts.model.forecast import QuantileForecast\n",
|
| 92 |
+
"from gluonts.model.predictor import Predictor\n",
|
| 93 |
+
"\n",
|
| 94 |
+
"# Plotting and Warnings\n",
|
| 95 |
+
"import matplotlib\n",
|
| 96 |
+
"import matplotlib.pyplot as plt\n",
|
| 97 |
+
"from linear_operator.utils.cholesky import NumericalWarning\n",
|
| 98 |
+
"\n",
|
| 99 |
+
"# --- TempoPFN Core Model Imports ---\n",
|
| 100 |
+
"# These are assumed to be installed or in the PYTHONPATH\n",
|
| 101 |
+
"from src.data.containers import BatchTimeSeriesContainer\n",
|
| 102 |
+
"from src.data.frequency import parse_frequency\n",
|
| 103 |
+
"from src.data.scalers import RobustScaler\n",
|
| 104 |
+
"from src.models.model import TimeSeriesModel\n",
|
| 105 |
+
"from src.utils.utils import device\n",
|
| 106 |
+
"\n",
|
| 107 |
+
"# --- Setup Logging ---\n",
|
| 108 |
+
"logging.basicConfig(level=logging.INFO, format=\"%(asctime)s - %(levelname)s - %(message)s\")\n",
|
| 109 |
+
"logging.getLogger(\"matplotlib\").setLevel(logging.WARNING)\n",
|
| 110 |
+
"logging.getLogger(\"matplotlib.font_manager\").setLevel(logging.WARNING)\n",
|
| 111 |
+
"logging.getLogger(\"PIL\").setLevel(logging.WARNING)\n",
|
| 112 |
+
"logger = logging.getLogger(\"gift_eval_runner\")\n",
|
| 113 |
+
"\n",
|
| 114 |
+
"# Filter out specific gluonts warnings\n",
|
| 115 |
+
"class WarningFilter(logging.Filter):\n",
|
| 116 |
+
" def __init__(self, text_to_filter: str) -> None:\n",
|
| 117 |
+
" super().__init__()\n",
|
| 118 |
+
" self.text_to_filter = text_to_filter\n",
|
| 119 |
+
"\n",
|
| 120 |
+
" def filter(self, record: logging.LogRecord) -> bool:\n",
|
| 121 |
+
" return self.text_to_filter not in record.getMessage()\n",
|
| 122 |
+
"\n",
|
| 123 |
+
"gts_logger = logging.getLogger(\"gluonts.model.forecast\")\n",
|
| 124 |
+
"gts_logger.addFilter(\n",
|
| 125 |
+
" WarningFilter(\"The mean prediction is not stored in the forecast data\")\n",
|
| 126 |
+
")\n",
|
| 127 |
+
"\n",
|
| 128 |
+
"# Filter out numerical warnings\n",
|
| 129 |
+
"warnings.filterwarnings(\"ignore\", category=NumericalWarning)\n",
|
| 130 |
+
"warnings.filterwarnings(\"ignore\", category=FutureWarning)\n",
|
| 131 |
+
"warnings.filterwarnings(\"ignore\", category=DeprecationWarning)\n",
|
| 132 |
+
"\n",
|
| 133 |
+
"# Load environment variables (e.g., GIFT_EVAL_DATASET_STORAGE_PATH)\n",
|
| 134 |
+
"load_dotenv()"
|
| 135 |
+
]
|
| 136 |
+
},
|
| 137 |
+
{
|
| 138 |
+
"cell_type": "markdown",
|
| 139 |
+
"id": "d6e7f8a1",
|
| 140 |
+
"metadata": {},
|
| 141 |
+
"source": [
|
| 142 |
+
"## 3. Constants and Configuration\n",
|
| 143 |
+
"\n",
|
| 144 |
+
"Define dataset lists, metrics, and other constants following GIFT-Eval standards."
|
| 145 |
+
]
|
| 146 |
+
},
|
| 147 |
+
{
|
| 148 |
+
"cell_type": "markdown",
|
| 149 |
+
"id": "g4h5j6k7",
|
| 150 |
+
"metadata": {},
|
| 151 |
+
"source": [
|
| 152 |
+
"### 3.1. Constants "
|
| 153 |
+
]
|
| 154 |
+
},
|
| 155 |
+
{
|
| 156 |
+
"cell_type": "code",
|
| 157 |
+
"execution_count": null,
|
| 158 |
+
"id": "h5j6k7l8",
|
| 159 |
+
"metadata": {},
|
| 160 |
+
"outputs": [],
|
| 161 |
+
"source": [
|
| 162 |
+
"# Environment setup\n",
|
| 163 |
+
"os.environ[\"CUBLAS_WORKSPACE_CONFIG\"] = \":4096:8\"\n",
|
| 164 |
+
"\n",
|
| 165 |
+
"# Use absolute path relative to the project root\n",
|
| 166 |
+
"_MODULE_DIR = Path.cwd().parent.parent # Assumes notebook is in `examples/gift_eval/`\n",
|
| 167 |
+
"DATASET_PROPERTIES_PATH = _MODULE_DIR / \"data\" / \"dataset_properties.json\"\n",
|
| 168 |
+
"\n",
|
| 169 |
+
"try:\n",
|
| 170 |
+
" with open(DATASET_PROPERTIES_PATH, \"r\") as f:\n",
|
| 171 |
+
" DATASET_PROPERTIES = json.load(f)\n",
|
| 172 |
+
"except Exception as exc: # pragma: no cover - logging path\n",
|
| 173 |
+
" DATASET_PROPERTIES = {}\n",
|
| 174 |
+
" logger.warning(\n",
|
| 175 |
+
" \"Could not load dataset properties from %s: %s. Domain and num_variates will fall back to defaults.\",\n",
|
| 176 |
+
" DATASET_PROPERTIES_PATH,\n",
|
| 177 |
+
" exc,\n",
|
| 178 |
+
" )\n",
|
| 179 |
+
"\n",
|
| 180 |
+
"# Datasets\n",
|
| 181 |
+
"SHORT_DATASETS = (\n",
|
| 182 |
+
" \"m4_yearly\",\n",
|
| 183 |
+
" \"m4_quarterly\",\n",
|
| 184 |
+
" \"m4_monthly\",\n",
|
| 185 |
+
" \"m4_weekly\",\n",
|
| 186 |
+
" \"m4_daily\",\n",
|
| 187 |
+
" \"m4_hourly\",\n",
|
| 188 |
+
" \"electricity/15T\",\n",
|
| 189 |
+
" \"electricity/H\",\n",
|
| 190 |
+
" \"electricity/D\",\n",
|
| 191 |
+
" \"electricity/W\",\n",
|
| 192 |
+
" \"solar/10T\",\n",
|
| 193 |
+
" \"solar/H\",\n",
|
| 194 |
+
" \"solar/D\",\n",
|
| 195 |
+
" \"solar/W\",\n",
|
| 196 |
+
" \"hospital\",\n",
|
| 197 |
+
" \"covid_deaths\",\n",
|
| 198 |
+
" \"us_births/D\",\n",
|
| 199 |
+
" \"us_births/M\",\n",
|
| 200 |
+
" \"us_births/W\",\n",
|
| 201 |
+
" \"saugeenday/D\",\n",
|
| 202 |
+
" \"saugeenday/M\",\n",
|
| 203 |
+
" \"saugeenday/W\",\n",
|
| 204 |
+
" \"temperature_rain_with_missing\",\n",
|
| 205 |
+
" \"kdd_cup_2018_with_missing/H\",\n",
|
| 206 |
+
" \"kdd_cup_2018_with_missing/D\",\n",
|
| 207 |
+
" \"car_parts_with_missing\",\n",
|
| 208 |
+
" \"restaurant\",\n",
|
| 209 |
+
" \"hierarchical_sales/D\",\n",
|
| 210 |
+
" \"hierarchical_sales/W\",\n",
|
| 211 |
+
" \"LOOP_SEATTLE/5T\",\n",
|
| 212 |
+
" \"LOOP_SEATTLE/H\",\n",
|
| 213 |
+
" \"LOOP_SEATTLE/D\",\n",
|
| 214 |
+
" \"SZ_TAXI/15T\",\n",
|
| 215 |
+
" \"SZ_TAXI/H\",\n",
|
| 216 |
+
" \"M_DENSE/H\",\n",
|
| 217 |
+
" \"M_DENSE/D\",\n",
|
| 218 |
+
" \"ett1/15T\",\n",
|
| 219 |
+
" \"ett1/H\",\n",
|
| 220 |
+
" \"ett1/D\",\n",
|
| 221 |
+
" \"ett1/W\",\n",
|
| 222 |
+
" \"ett2/15T\",\n",
|
| 223 |
+
" \"ett2/H\",\n",
|
| 224 |
+
" \"ett2/D\",\n",
|
| 225 |
+
" \"ett2/W\",\n",
|
| 226 |
+
" \"jena_weather/10T\",\n",
|
| 227 |
+
" \"jena_weather/H\",\n",
|
| 228 |
+
" \"jena_weather/D\",\n",
|
| 229 |
+
" \"bitbrains_fast_storage/5T\",\n",
|
| 230 |
+
" \"bitbrains_fast_storage/H\",\n",
|
| 231 |
+
" \"bitbrains_rnd/5T\",\n",
|
| 232 |
+
" \"bitbrains_rnd/H\",\n",
|
| 233 |
+
" \"bizitobs_application\",\n",
|
| 234 |
+
" \"bizitobs_service\",\n",
|
| 235 |
+
" \"bizitobs_l2c/5T\",\n",
|
| 236 |
+
" \"bizitobs_l2c/H\",\n",
|
| 237 |
+
")\n",
|
| 238 |
+
"\n",
|
| 239 |
+
"MED_LONG_DATASETS = (\n",
|
| 240 |
+
" \"electricity/15T\",\n",
|
| 241 |
+
" \"electricity/H\",\n",
|
| 242 |
+
" \"solar/10T\",\n",
|
| 243 |
+
" \"solar/H\",\n",
|
| 244 |
+
" \"kdd_cup_2018_with_missing/H\",\n",
|
| 245 |
+
" \"LOOP_SEATTLE/5T\",\n",
|
| 246 |
+
" \"LOOP_SEATTLE/H\",\n",
|
| 247 |
+
" \"SZ_TAXI/15T\",\n",
|
| 248 |
+
" \"M_DENSE/H\",\n",
|
| 249 |
+
" \"ett1/15T\",\n",
|
| 250 |
+
" \"ett1/H\",\n",
|
| 251 |
+
" \"ett2/15T\",\n",
|
| 252 |
+
" \"ett2/H\",\n",
|
| 253 |
+
" \"jena_weather/10T\",\n",
|
| 254 |
+
" \"jena_weather/H\",\n",
|
| 255 |
+
" \"bitbrains_fast_storage/5T\",\n",
|
| 256 |
+
" \"bitbrains_rnd/5T\",\n",
|
| 257 |
+
" \"bizitobs_application\",\n",
|
| 258 |
+
" \"bizitobs_service\",\n",
|
| 259 |
+
" \"bizitobs_l2c/5T\",\n",
|
| 260 |
+
" \"bizitobs_l2c/H\",\n",
|
| 261 |
+
")\n",
|
| 262 |
+
"\n",
|
| 263 |
+
"# Preserve insertion order\n",
|
| 264 |
+
"ALL_DATASETS = list(dict.fromkeys(SHORT_DATASETS + MED_LONG_DATASETS))\n",
|
| 265 |
+
"\n",
|
| 266 |
+
"# Evaluation terms\n",
|
| 267 |
+
"TERMS = (\"short\", \"medium\", \"long\")\n",
|
| 268 |
+
"\n",
|
| 269 |
+
"# Pretty names mapping\n",
|
| 270 |
+
"PRETTY_NAMES = {\n",
|
| 271 |
+
" \"saugeenday\": \"saugeen\",\n",
|
| 272 |
+
" \"temperature_rain_with_missing\": \"temperature_rain\",\n",
|
| 273 |
+
" \"kdd_cup_2018_with_missing\": \"kdd_cup_2018\",\n",
|
| 274 |
+
" \"car_parts_with_missing\": \"car_parts\",\n",
|
| 275 |
+
"}\n",
|
| 276 |
+
"\n",
|
| 277 |
+
"# Metrics\n",
|
| 278 |
+
"METRICS = (\n",
|
| 279 |
+
" MSE(forecast_type=\"mean\"),\n",
|
| 280 |
+
" MSE(forecast_type=0.5),\n",
|
| 281 |
+
" MAE(),\n",
|
| 282 |
+
" MASE(),\n",
|
| 283 |
+
" MAPE(),\n",
|
| 284 |
+
" SMAPE(),\n",
|
| 285 |
+
" MSIS(),\n",
|
| 286 |
+
" RMSE(),\n",
|
| 287 |
+
" NRMSE(),\n",
|
| 288 |
+
" ND(),\n",
|
| 289 |
+
" MeanWeightedSumQuantileLoss(\n",
|
| 290 |
+
" quantile_levels=[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]\n",
|
| 291 |
+
" ),\n",
|
| 292 |
+
")\n",
|
| 293 |
+
"\n",
|
| 294 |
+
"# Standard metric names for CSV header\n",
|
| 295 |
+
"STANDARD_METRIC_NAMES = (\n",
|
| 296 |
+
" \"MSE[mean]\",\n",
|
| 297 |
+
" \"MSE[0.5]\",\n",
|
| 298 |
+
" \"MAE[0.5]\",\n",
|
| 299 |
+
" \"MASE[0.5]\",\n",
|
| 300 |
+
" \"MAPE[0.5]\",\n",
|
| 301 |
+
" \"sMAPE[0.5]\",\n",
|
| 302 |
+
" \"MSIS\",\n",
|
| 303 |
+
" \"RMSE[mean]\",\n",
|
| 304 |
+
" \"NRMSE[mean]\",\n",
|
| 305 |
+
" \"ND[0.5]\",\n",
|
| 306 |
+
" \"mean_weighted_sum_quantile_loss\",\n",
|
| 307 |
+
")"
|
| 308 |
+
]
|
| 309 |
+
},
|
| 310 |
+
{
|
| 311 |
+
"cell_type": "markdown",
|
| 312 |
+
"id": "i7j8k9l0",
|
| 313 |
+
"metadata": {},
|
| 314 |
+
"source": [
|
| 315 |
+
"### 3.2. Core Data Structures "
|
| 316 |
+
]
|
| 317 |
+
},
|
| 318 |
+
{
|
| 319 |
+
"cell_type": "code",
|
| 320 |
+
"execution_count": null,
|
| 321 |
+
"id": "j8k9l0m1",
|
| 322 |
+
"metadata": {},
|
| 323 |
+
"outputs": [],
|
| 324 |
+
"source": [
|
| 325 |
+
"@dataclass\n",
|
| 326 |
+
"class DatasetMetadata:\n",
|
| 327 |
+
" \"\"\"Structured description of a dataset/term combination.\"\"\"\n",
|
| 328 |
+
"\n",
|
| 329 |
+
" full_name: str\n",
|
| 330 |
+
" key: str\n",
|
| 331 |
+
" freq: str\n",
|
| 332 |
+
" term: str\n",
|
| 333 |
+
" season_length: int\n",
|
| 334 |
+
" target_dim: int\n",
|
| 335 |
+
" to_univariate: bool\n",
|
| 336 |
+
" prediction_length: int\n",
|
| 337 |
+
" windows: int\n",
|
| 338 |
+
"\n",
|
| 339 |
+
"\n",
|
| 340 |
+
"@dataclass\n",
|
| 341 |
+
"class EvaluationItem:\n",
|
| 342 |
+
" \"\"\"Container for evaluation results and optional figures.\"\"\"\n",
|
| 343 |
+
"\n",
|
| 344 |
+
" dataset_metadata: DatasetMetadata\n",
|
| 345 |
+
" metrics: Dict\n",
|
| 346 |
+
" figures: List[Tuple[object, str]]\n",
|
| 347 |
+
"\n",
|
| 348 |
+
"\n",
|
| 349 |
+
"DatasetSelection = Union[List[str], Tuple[str, ...], str]\n",
|
| 350 |
+
"\n",
|
| 351 |
+
"\n",
|
| 352 |
+
"def expand_datasets_arg(datasets: DatasetSelection) -> List[str]:\n",
|
| 353 |
+
" \"\"\"Normalize dataset selection strings to explicit lists.\"\"\"\n",
|
| 354 |
+
"\n",
|
| 355 |
+
" if isinstance(datasets, str):\n",
|
| 356 |
+
" dataset_list = [datasets]\n",
|
| 357 |
+
" else:\n",
|
| 358 |
+
" dataset_list = list(datasets)\n",
|
| 359 |
+
"\n",
|
| 360 |
+
" if not dataset_list:\n",
|
| 361 |
+
" return []\n",
|
| 362 |
+
"\n",
|
| 363 |
+
" if dataset_list[0] == \"all\":\n",
|
| 364 |
+
" return list(ALL_DATASETS)\n",
|
| 365 |
+
"\n",
|
| 366 |
+
" for dataset in dataset_list:\n",
|
| 367 |
+
" if dataset not in ALL_DATASETS:\n",
|
| 368 |
+
" raise ValueError(f\"Invalid dataset: {dataset}. Use one of {ALL_DATASETS}\")\n",
|
| 369 |
+
"\n",
|
| 370 |
+
" return dataset_list"
|
| 371 |
+
]
|
| 372 |
+
},
|
| 373 |
+
{
|
| 374 |
+
"cell_type": "markdown",
|
| 375 |
+
"id": "k9l0m1n2",
|
| 376 |
+
"metadata": {},
|
| 377 |
+
"source": [
|
| 378 |
+
"### 3.3. GIFT-Eval Dataset Class (`data.py`)\n",
|
| 379 |
+
"\n",
|
| 380 |
+
"The `Dataset` class handles loading and preprocessing GIFT-Eval benchmark datasets. This implementation is adapted from the official GIFT-Eval repository."
|
| 381 |
+
]
|
| 382 |
+
},
|
| 383 |
+
{
|
| 384 |
+
"cell_type": "code",
|
| 385 |
+
"execution_count": null,
|
| 386 |
+
"id": "l0m1n2o3",
|
| 387 |
+
"metadata": {},
|
| 388 |
+
"outputs": [],
|
| 389 |
+
"source": [
|
| 390 |
+
"TEST_SPLIT = 0.1\n",
|
| 391 |
+
"MAX_WINDOW = 20\n",
|
| 392 |
+
"\n",
|
| 393 |
+
"M4_PRED_LENGTH_MAP = {\n",
|
| 394 |
+
" \"A\": 6,\n",
|
| 395 |
+
" \"Q\": 8,\n",
|
| 396 |
+
" \"M\": 18,\n",
|
| 397 |
+
" \"W\": 13,\n",
|
| 398 |
+
" \"D\": 14,\n",
|
| 399 |
+
" \"H\": 48,\n",
|
| 400 |
+
" \"h\": 48,\n",
|
| 401 |
+
" \"Y\": 6,\n",
|
| 402 |
+
"}\n",
|
| 403 |
+
"\n",
|
| 404 |
+
"PRED_LENGTH_MAP = {\n",
|
| 405 |
+
" \"M\": 12,\n",
|
| 406 |
+
" \"W\": 8,\n",
|
| 407 |
+
" \"D\": 30,\n",
|
| 408 |
+
" \"H\": 48,\n",
|
| 409 |
+
" \"h\": 48,\n",
|
| 410 |
+
" \"T\": 48,\n",
|
| 411 |
+
" \"S\": 60,\n",
|
| 412 |
+
" \"s\": 60,\n",
|
| 413 |
+
" \"min\": 48,\n",
|
| 414 |
+
"}\n",
|
| 415 |
+
"\n",
|
| 416 |
+
"TFB_PRED_LENGTH_MAP = {\n",
|
| 417 |
+
" \"A\": 6,\n",
|
| 418 |
+
" \"Y\": 6,\n",
|
| 419 |
+
" \"H\": 48,\n",
|
| 420 |
+
" \"h\": 48,\n",
|
| 421 |
+
" \"Q\": 8,\n",
|
| 422 |
+
" \"D\": 14,\n",
|
| 423 |
+
" \"M\": 18,\n",
|
| 424 |
+
" \"W\": 13,\n",
|
| 425 |
+
" \"U\": 8,\n",
|
| 426 |
+
" \"T\": 8,\n",
|
| 427 |
+
" \"min\": 8,\n",
|
| 428 |
+
" \"us\": 8,\n",
|
| 429 |
+
"}\n",
|
| 430 |
+
"\n",
|
| 431 |
+
"\n",
|
| 432 |
+
"class Term(Enum):\n",
|
| 433 |
+
" SHORT = \"short\"\n",
|
| 434 |
+
" MEDIUM = \"medium\"\n",
|
| 435 |
+
" LONG = \"long\"\n",
|
| 436 |
+
"\n",
|
| 437 |
+
" @property\n",
|
| 438 |
+
" def multiplier(self) -> int:\n",
|
| 439 |
+
" if self == Term.SHORT:\n",
|
| 440 |
+
" return 1\n",
|
| 441 |
+
" elif self == Term.MEDIUM:\n",
|
| 442 |
+
" return 10\n",
|
| 443 |
+
" elif self == Term.LONG:\n",
|
| 444 |
+
" return 15\n",
|
| 445 |
+
"\n",
|
| 446 |
+
"\n",
|
| 447 |
+
"def itemize_start(data_entry: DataEntry) -> DataEntry:\n",
|
| 448 |
+
" data_entry[\"start\"] = data_entry[\"start\"].item()\n",
|
| 449 |
+
" return data_entry\n",
|
| 450 |
+
"\n",
|
| 451 |
+
"\n",
|
| 452 |
+
"class MultivariateToUnivariate(Transformation):\n",
|
| 453 |
+
" def __init__(self, field):\n",
|
| 454 |
+
" self.field = field\n",
|
| 455 |
+
"\n",
|
| 456 |
+
" def __call__(\n",
|
| 457 |
+
" self, data_it: Iterable[DataEntry], is_train: bool = False\n",
|
| 458 |
+
" ) -> Iterator:\n",
|
| 459 |
+
" for data_entry in data_it:\n",
|
| 460 |
+
" item_id = data_entry[\"item_id\"]\n",
|
| 461 |
+
" val_ls = list(data_entry[self.field])\n",
|
| 462 |
+
" for id, val in enumerate(val_ls):\n",
|
| 463 |
+
" univariate_entry = data_entry.copy()\n",
|
| 464 |
+
" univariate_entry[self.field] = val\n",
|
| 465 |
+
" univariate_entry[\"item_id\"] = item_id + \"_dim\" + str(id)\n",
|
| 466 |
+
" yield univariate_entry\n",
|
| 467 |
+
"\n",
|
| 468 |
+
"\n",
|
| 469 |
+
"class Dataset:\n",
|
| 470 |
+
" def __init__(\n",
|
| 471 |
+
" self,\n",
|
| 472 |
+
" name: str,\n",
|
| 473 |
+
" term: Term | str = Term.SHORT,\n",
|
| 474 |
+
" to_univariate: bool = False,\n",
|
| 475 |
+
" storage_path: str = None,\n",
|
| 476 |
+
" max_windows: Optional[int] = None,\n",
|
| 477 |
+
" ):\n",
|
| 478 |
+
" storage_path = Path(storage_path)\n",
|
| 479 |
+
" self.hf_dataset = datasets.load_from_disk(str(storage_path / name)).with_format(\n",
|
| 480 |
+
" \"numpy\"\n",
|
| 481 |
+
" )\n",
|
| 482 |
+
" process = ProcessDataEntry(\n",
|
| 483 |
+
" self.freq,\n",
|
| 484 |
+
" one_dim_target=self.target_dim == 1,\n",
|
| 485 |
+
" )\n",
|
| 486 |
+
"\n",
|
| 487 |
+
" self.gluonts_dataset = Map(compose(process, itemize_start), self.hf_dataset)\n",
|
| 488 |
+
" if to_univariate:\n",
|
| 489 |
+
" self.gluonts_dataset = MultivariateToUnivariate(\"target\").apply(\n",
|
| 490 |
+
" self.gluonts_dataset\n",
|
| 491 |
+
" )\n",
|
| 492 |
+
"\n",
|
| 493 |
+
" self.term = Term(term)\n",
|
| 494 |
+
" self.name = name\n",
|
| 495 |
+
" self.max_windows = max_windows if max_windows is not None else MAX_WINDOW\n",
|
| 496 |
+
"\n",
|
| 497 |
+
" @cached_property\n",
|
| 498 |
+
" def prediction_length(self) -> int:\n",
|
| 499 |
+
" freq = norm_freq_str(to_offset(self.freq).name)\n",
|
| 500 |
+
" if freq.endswith(\"E\"):\n",
|
| 501 |
+
" freq = freq[:-1]\n",
|
| 502 |
+
" pred_len = (\n",
|
| 503 |
+
" M4_PRED_LENGTH_MAP[freq] if \"m4\" in self.name else PRED_LENGTH_MAP[freq]\n",
|
| 504 |
+
" )\n",
|
| 505 |
+
" return self.term.multiplier * pred_len\n",
|
| 506 |
+
"\n",
|
| 507 |
+
" @cached_property\n",
|
| 508 |
+
" def freq(self) -> str:\n",
|
| 509 |
+
" return self.hf_dataset[0][\"freq\"]\n",
|
| 510 |
+
"\n",
|
| 511 |
+
" @cached_property\n",
|
| 512 |
+
" def target_dim(self) -> int:\n",
|
| 513 |
+
" return (\n",
|
| 514 |
+
" target.shape[0]\n",
|
| 515 |
+
" if len((target := self.hf_dataset[0][\"target\"]).shape) > 1\n",
|
| 516 |
+
" else 1\n",
|
| 517 |
+
" )\n",
|
| 518 |
+
"\n",
|
| 519 |
+
" @cached_property\n",
|
| 520 |
+
" def past_feat_dynamic_real_dim(self) -> int:\n",
|
| 521 |
+
" if \"past_feat_dynamic_real\" not in self.hf_dataset[0]:\n",
|
| 522 |
+
" return 0\n",
|
| 523 |
+
" elif (\n",
|
| 524 |
+
" len(\n",
|
| 525 |
+
" (\n",
|
| 526 |
+
" past_feat_dynamic_real := self.hf_dataset[0][\n",
|
| 527 |
+
" \"past_feat_dynamic_real\"\n",
|
| 528 |
+
" ]\n",
|
| 529 |
+
" ).shape\n",
|
| 530 |
+
" )\n",
|
| 531 |
+
" > 1\n",
|
| 532 |
+
" ):\n",
|
| 533 |
+
" return past_feat_dynamic_real.shape[0]\n",
|
| 534 |
+
" else:\n",
|
| 535 |
+
" return 1\n",
|
| 536 |
+
"\n",
|
| 537 |
+
" @cached_property\n",
|
| 538 |
+
" def windows(self) -> int:\n",
|
| 539 |
+
" if \"m4\" in self.name:\n",
|
| 540 |
+
" return 1\n",
|
| 541 |
+
" w = math.ceil(TEST_SPLIT * self._min_series_length / self.prediction_length)\n",
|
| 542 |
+
" return min(max(1, w), self.max_windows)\n",
|
| 543 |
+
"\n",
|
| 544 |
+
" @cached_property\n",
|
| 545 |
+
" def _min_series_length(self) -> int:\n",
|
| 546 |
+
" if self.hf_dataset[0][\"target\"].ndim > 1:\n",
|
| 547 |
+
" lengths = pc.list_value_length(\n",
|
| 548 |
+
" pc.list_flatten(\n",
|
| 549 |
+
" pc.list_slice(self.hf_dataset.data.column(\"target\"), 0, 1)\n",
|
| 550 |
+
" )\n",
|
| 551 |
+
" )\n",
|
| 552 |
+
" else:\n",
|
| 553 |
+
" lengths = pc.list_value_length(self.hf_dataset.data.column(\"target\"))\n",
|
| 554 |
+
" return min(lengths.to_numpy())\n",
|
| 555 |
+
"\n",
|
| 556 |
+
" @cached_property\n",
|
| 557 |
+
" def sum_series_length(self) -> int:\n",
|
| 558 |
+
" if self.hf_dataset[0][\"target\"].ndim > 1:\n",
|
| 559 |
+
" lengths = pc.list_value_length(\n",
|
| 560 |
+
" pc.list_flatten(self.hf_dataset.data.column(\"target\"))\n",
|
| 561 |
+
" )\n",
|
| 562 |
+
" else:\n",
|
| 563 |
+
" lengths = pc.list_value_length(self.hf_dataset.data.column(\"target\"))\n",
|
| 564 |
+
" return sum(lengths.to_numpy())\n",
|
| 565 |
+
"\n",
|
| 566 |
+
" @property\n",
|
| 567 |
+
" def training_dataset(self) -> TrainingDataset:\n",
|
| 568 |
+
" training_dataset, _ = split(\n",
|
| 569 |
+
" self.gluonts_dataset, offset=-self.prediction_length * (self.windows + 1)\n",
|
| 570 |
+
" )\n",
|
| 571 |
+
" return training_dataset\n",
|
| 572 |
+
"\n",
|
| 573 |
+
" @property\n",
|
| 574 |
+
" def validation_dataset(self) -> TrainingDataset:\n",
|
| 575 |
+
" validation_dataset, _ = split(\n",
|
| 576 |
+
" self.gluonts_dataset, offset=-self.prediction_length * self.windows\n",
|
| 577 |
+
" )\n",
|
| 578 |
+
" return validation_dataset\n",
|
| 579 |
+
"\n",
|
| 580 |
+
" @property\n",
|
| 581 |
+
" def test_data(self) -> TestData:\n",
|
| 582 |
+
" _, test_template = split(\n",
|
| 583 |
+
" self.gluonts_dataset, offset=-self.prediction_length * self.windows\n",
|
| 584 |
+
" )\n",
|
| 585 |
+
" test_data = test_template.generate_instances(\n",
|
| 586 |
+
" prediction_length=self.prediction_length,\n",
|
| 587 |
+
" windows=self.windows,\n",
|
| 588 |
+
" distance=self.prediction_length,\n",
|
| 589 |
+
" )\n",
|
| 590 |
+
" return test_data"
|
| 591 |
+
]
|
| 592 |
+
},
|
| 593 |
+
{
|
| 594 |
+
"cell_type": "markdown",
|
| 595 |
+
"id": "m1n2o3p4",
|
| 596 |
+
"metadata": {},
|
| 597 |
+
"source": [
|
| 598 |
+
"### 3.4. Predictor Wrapper (`predictor.py`)\n",
|
| 599 |
+
"\n",
|
| 600 |
+
"This is the model-specific `TimeSeriesPredictor` class for `TempoPFN`. It wraps the core `TimeSeriesModel` and adapts it to the `gluonts`-style `Predictor` interface, which expects a `.predict()` method."
|
| 601 |
+
]
|
| 602 |
+
},
|
| 603 |
+
{
|
| 604 |
+
"cell_type": "code",
|
| 605 |
+
"execution_count": null,
|
| 606 |
+
"id": "n2o3p4q5",
|
| 607 |
+
"metadata": {},
|
| 608 |
+
"outputs": [],
|
| 609 |
+
"source": [
|
| 610 |
+
"class TimeSeriesPredictor(Predictor):\n",
|
| 611 |
+
" \"\"\"Unified predictor for TimeSeriesModel supporting flexible construction.\"\"\"\n",
|
| 612 |
+
"\n",
|
| 613 |
+
" def __init__(\n",
|
| 614 |
+
" self,\n",
|
| 615 |
+
" model: TimeSeriesModel,\n",
|
| 616 |
+
" config: dict,\n",
|
| 617 |
+
" ds_prediction_length: int,\n",
|
| 618 |
+
" ds_freq: str,\n",
|
| 619 |
+
" batch_size: int = 32,\n",
|
| 620 |
+
" max_context_length: Optional[int] = None,\n",
|
| 621 |
+
" debug: bool = False,\n",
|
| 622 |
+
" ) -> None:\n",
|
| 623 |
+
" # Dataset-specific context (can be updated per dataset/term)\n",
|
| 624 |
+
" self.ds_prediction_length = ds_prediction_length\n",
|
| 625 |
+
" self.ds_freq = ds_freq\n",
|
| 626 |
+
" self.batch_size = batch_size\n",
|
| 627 |
+
" self.max_context_length = max_context_length\n",
|
| 628 |
+
" self.debug = debug\n",
|
| 629 |
+
"\n",
|
| 630 |
+
" # Persistent model/config (unwrap DDP if needed)\n",
|
| 631 |
+
" self.model = model.module if isinstance(model, DDP) else model\n",
|
| 632 |
+
" self.model.eval()\n",
|
| 633 |
+
" self.config = config\n",
|
| 634 |
+
"\n",
|
| 635 |
+
" # Initialize scaler (using same type as model)\n",
|
| 636 |
+
" scaler_type = self.config.get(\"TimeSeriesModel\", {}).get(\n",
|
| 637 |
+
" \"scaler\", \"custom_robust\"\n",
|
| 638 |
+
" )\n",
|
| 639 |
+
" epsilon = self.config.get(\"TimeSeriesModel\", {}).get(\"epsilon\", 1e-3)\n",
|
| 640 |
+
" if scaler_type == \"custom_robust\":\n",
|
| 641 |
+
" self.scaler = RobustScaler(epsilon=epsilon)\n",
|
| 642 |
+
" else:\n",
|
| 643 |
+
" raise ValueError(f\"Unsupported scaler type: {scaler_type}\")\n",
|
| 644 |
+
"\n",
|
| 645 |
+
" def set_dataset_context(\n",
|
| 646 |
+
" self,\n",
|
| 647 |
+
" prediction_length: Optional[int] = None,\n",
|
| 648 |
+
" freq: Optional[str] = None,\n",
|
| 649 |
+
" batch_size: Optional[int] = None,\n",
|
| 650 |
+
" max_context_length: Optional[int] = None,\n",
|
| 651 |
+
" ) -> None:\n",
|
| 652 |
+
" \"\"\"Update lightweight dataset-specific attributes without reloading the model.\"\"\"\n",
|
| 653 |
+
"\n",
|
| 654 |
+
" if prediction_length is not None:\n",
|
| 655 |
+
" self.ds_prediction_length = prediction_length\n",
|
| 656 |
+
" if freq is not None:\n",
|
| 657 |
+
" self.ds_freq = freq\n",
|
| 658 |
+
" if batch_size is not None:\n",
|
| 659 |
+
" self.batch_size = batch_size\n",
|
| 660 |
+
" if max_context_length is not None:\n",
|
| 661 |
+
" self.max_context_length = max_context_length\n",
|
| 662 |
+
"\n",
|
| 663 |
+
" @classmethod\n",
|
| 664 |
+
" def from_model(\n",
|
| 665 |
+
" cls,\n",
|
| 666 |
+
" model: TimeSeriesModel,\n",
|
| 667 |
+
" config: dict,\n",
|
| 668 |
+
" ds_prediction_length: int,\n",
|
| 669 |
+
" ds_freq: str,\n",
|
| 670 |
+
" batch_size: int = 32,\n",
|
| 671 |
+
" max_context_length: Optional[int] = None,\n",
|
| 672 |
+
" debug: bool = False,\n",
|
| 673 |
+
" ) -> \"TimeSeriesPredictor\":\n",
|
| 674 |
+
" return cls(\n",
|
| 675 |
+
" model=model,\n",
|
| 676 |
+
" config=config,\n",
|
| 677 |
+
" ds_prediction_length=ds_prediction_length,\n",
|
| 678 |
+
" ds_freq=ds_freq,\n",
|
| 679 |
+
" batch_size=batch_size,\n",
|
| 680 |
+
" max_context_length=max_context_length,\n",
|
| 681 |
+
" debug=debug,\n",
|
| 682 |
+
" )\n",
|
| 683 |
+
"\n",
|
| 684 |
+
" @classmethod\n",
|
| 685 |
+
" def from_paths(\n",
|
| 686 |
+
" cls,\n",
|
| 687 |
+
" model_path: str,\n",
|
| 688 |
+
" config_path: str,\n",
|
| 689 |
+
" ds_prediction_length: int,\n",
|
| 690 |
+
" ds_freq: str,\n",
|
| 691 |
+
" batch_size: int = 32,\n",
|
| 692 |
+
" max_context_length: Optional[int] = None,\n",
|
| 693 |
+
" debug: bool = False,\n",
|
| 694 |
+
" ) -> \"TimeSeriesPredictor\":\n",
|
| 695 |
+
" with open(config_path, \"r\") as f:\n",
|
| 696 |
+
" config = yaml.safe_load(f)\n",
|
| 697 |
+
" model = cls._load_model_from_path(config=config, model_path=model_path)\n",
|
| 698 |
+
" return cls(\n",
|
| 699 |
+
" model=model,\n",
|
| 700 |
+
" config=config,\n",
|
| 701 |
+
" ds_prediction_length=ds_prediction_length,\n",
|
| 702 |
+
" ds_freq=ds_freq,\n",
|
| 703 |
+
" batch_size=batch_size,\n",
|
| 704 |
+
" max_context_length=max_context_length,\n",
|
| 705 |
+
" debug=debug,\n",
|
| 706 |
+
" )\n",
|
| 707 |
+
"\n",
|
| 708 |
+
" @staticmethod\n",
|
| 709 |
+
" def _load_model_from_path(config: dict, model_path: str) -> TimeSeriesModel:\n",
|
| 710 |
+
" try:\n",
|
| 711 |
+
" model = TimeSeriesModel(**config[\"TimeSeriesModel\"]).to(device)\n",
|
| 712 |
+
" checkpoint = torch.load(model_path, map_location=device)\n",
|
| 713 |
+
" model.load_state_dict(checkpoint[\"model_state_dict\"])\n",
|
| 714 |
+
" model.eval()\n",
|
| 715 |
+
" logger.info(f\"Successfully loaded model from {model_path}\")\n",
|
| 716 |
+
" return model\n",
|
| 717 |
+
" except Exception as exc: # pragma: no cover - logging path\n",
|
| 718 |
+
" logger.error(f\"Failed to load model from {model_path}: {exc}\")\n",
|
| 719 |
+
" raise\n",
|
| 720 |
+
"\n",
|
| 721 |
+
" def predict(self, test_data_input) -> Iterator[QuantileForecast]:\n",
|
| 722 |
+
" \"\"\"Generate forecasts for the test data.\"\"\"\n",
|
| 723 |
+
"\n",
|
| 724 |
+
" if hasattr(test_data_input, \"__iter__\") and not isinstance(test_data_input, list):\n",
|
| 725 |
+
" test_data_input = list(test_data_input)\n",
|
| 726 |
+
" logger.debug(f\"Processing {len(test_data_input)} time series\")\n",
|
| 727 |
+
"\n",
|
| 728 |
+
" # Group series by their effective length (after optional truncation),\n",
|
| 729 |
+
" # then process each uniform-length group in sub-batches up to batch_size.\n",
|
| 730 |
+
" def _effective_length(entry) -> int:\n",
|
| 731 |
+
" target = entry[\"target\"]\n",
|
| 732 |
+
" if target.ndim == 1:\n",
|
| 733 |
+
" seq_len = len(target)\n",
|
| 734 |
+
" else:\n",
|
| 735 |
+
" # target shape is [num_channels, seq_len]\n",
|
| 736 |
+
" seq_len = target.shape[1]\n",
|
| 737 |
+
" if self.max_context_length is not None:\n",
|
| 738 |
+
" seq_len = min(seq_len, self.max_context_length)\n",
|
| 739 |
+
" return seq_len\n",
|
| 740 |
+
"\n",
|
| 741 |
+
" length_to_items: dict[int, List[tuple[int, object]]] = {}\n",
|
| 742 |
+
" for idx, entry in enumerate(test_data_input):\n",
|
| 743 |
+
" seq_len = _effective_length(entry)\n",
|
| 744 |
+
" length_to_items.setdefault(seq_len, []).append((idx, entry))\n",
|
| 745 |
+
"\n",
|
| 746 |
+
" total = len(test_data_input)\n",
|
| 747 |
+
" ordered_results: List[Optional[QuantileForecast]] = [None] * total\n",
|
| 748 |
+
"\n",
|
| 749 |
+
" for _, items in length_to_items.items():\n",
|
| 750 |
+
" for i in range(0, len(items), self.batch_size):\n",
|
| 751 |
+
" chunk = items[i : i + self.batch_size]\n",
|
| 752 |
+
" entries = [entry for (_orig_idx, entry) in chunk]\n",
|
| 753 |
+
" batch_forecasts = self._predict_batch(entries)\n",
|
| 754 |
+
" for forecast_idx, (orig_idx, _entry) in enumerate(chunk):\n",
|
| 755 |
+
" ordered_results[orig_idx] = batch_forecasts[forecast_idx]\n",
|
| 756 |
+
"\n",
|
| 757 |
+
" return ordered_results # type: ignore[return-value]\n",
|
| 758 |
+
"\n",
|
| 759 |
+
" def _predict_batch(self, test_data_batch: List) -> List[QuantileForecast]:\n",
|
| 760 |
+
" \"\"\"Generate predictions for a batch of time series.\"\"\"\n",
|
| 761 |
+
"\n",
|
| 762 |
+
" logger.debug(f\"Processing batch of size: {len(test_data_batch)}\")\n",
|
| 763 |
+
"\n",
|
| 764 |
+
" try:\n",
|
| 765 |
+
" batch_container = self._convert_to_batch_container(test_data_batch)\n",
|
| 766 |
+
"\n",
|
| 767 |
+
" if isinstance(device, torch.device):\n",
|
| 768 |
+
" device_type = device.type\n",
|
| 769 |
+
" else:\n",
|
| 770 |
+
" device_type = \"cuda\" if \"cuda\" in str(device).lower() else \"cpu\"\n",
|
| 771 |
+
" enable_autocast = device_type == \"cuda\"\n",
|
| 772 |
+
"\n",
|
| 773 |
+
" with torch.autocast(\n",
|
| 774 |
+
" device_type=device_type,\n",
|
| 775 |
+
" dtype=torch.bfloat16,\n",
|
| 776 |
+
" enabled=enable_autocast,\n",
|
| 777 |
+
" ):\n",
|
| 778 |
+
" with torch.no_grad():\n",
|
| 779 |
+
" model_output = self.model(batch_container, drop_enc_allow=False)\n",
|
| 780 |
+
"\n",
|
| 781 |
+
" forecasts = self._convert_to_forecasts(\n",
|
| 782 |
+
" model_output, test_data_batch, batch_container\n",
|
| 783 |
+
" )\n",
|
| 784 |
+
"\n",
|
| 785 |
+
" logger.debug(f\"Generated {len(forecasts)} forecasts\")\n",
|
| 786 |
+
" return forecasts\n",
|
| 787 |
+
" except Exception as exc: # pragma: no cover - logging path\n",
|
| 788 |
+
" logger.error(f\"Error in batch prediction: {exc}\")\n",
|
| 789 |
+
" raise\n",
|
| 790 |
+
"\n",
|
| 791 |
+
" def _convert_to_batch_container(\n",
|
| 792 |
+
" self, test_data_batch: List\n",
|
| 793 |
+
" ) -> BatchTimeSeriesContainer:\n",
|
| 794 |
+
" \"\"\"Convert gluonts test data to BatchTimeSeriesContainer.\"\"\"\n",
|
| 795 |
+
"\n",
|
| 796 |
+
" batch_size = len(test_data_batch)\n",
|
| 797 |
+
" history_values_list = []\n",
|
| 798 |
+
" start_dates = []\n",
|
| 799 |
+
" frequencies = []\n",
|
| 800 |
+
"\n",
|
| 801 |
+
" for entry in test_data_batch:\n",
|
| 802 |
+
" target = entry[\"target\"]\n",
|
| 803 |
+
"\n",
|
| 804 |
+
" if target.ndim == 1:\n",
|
| 805 |
+
" target = target.reshape(-1, 1)\n",
|
| 806 |
+
" else:\n",
|
| 807 |
+
" target = target.T\n",
|
| 808 |
+
"\n",
|
| 809 |
+
" if (\n",
|
| 810 |
+
" self.max_context_length is not None\n",
|
| 811 |
+
" and len(target) > self.max_context_length\n",
|
| 812 |
+
" ):\n",
|
| 813 |
+
" target = target[-self.max_context_length :]\n",
|
| 814 |
+
"\n",
|
| 815 |
+
" history_values_list.append(target)\n",
|
| 816 |
+
" start_dates.append(entry[\"start\"].to_timestamp().to_datetime64())\n",
|
| 817 |
+
" frequencies.append(parse_frequency(entry[\"freq\"]))\n",
|
| 818 |
+
"\n",
|
| 819 |
+
" history_values_np = np.stack(history_values_list, axis=0)\n",
|
| 820 |
+
" num_channels = history_values_np.shape[2]\n",
|
| 821 |
+
"\n",
|
| 822 |
+
" history_values = torch.tensor(\n",
|
| 823 |
+
" history_values_np, dtype=torch.float32, device=device\n",
|
| 824 |
+
" )\n",
|
| 825 |
+
"\n",
|
| 826 |
+
" future_values = torch.zeros(\n",
|
| 827 |
+
" (batch_size, self.ds_prediction_length, num_channels),\n",
|
| 828 |
+
" dtype=torch.float32,\n",
|
| 829 |
+
" device=device,\n",
|
| 830 |
+
" )\n",
|
| 831 |
+
"\n",
|
| 832 |
+
" return BatchTimeSeriesContainer(\n",
|
| 833 |
+
" history_values=history_values,\n",
|
| 834 |
+
" future_values=future_values,\n",
|
| 835 |
+
" start=start_dates,\n",
|
| 836 |
+
" frequency=frequencies,\n",
|
| 837 |
+
" )\n",
|
| 838 |
+
"\n",
|
| 839 |
+
" def _convert_to_forecasts(\n",
|
| 840 |
+
" self,\n",
|
| 841 |
+
" model_output: dict,\n",
|
| 842 |
+
" test_data_batch: List,\n",
|
| 843 |
+
" batch_container: BatchTimeSeriesContainer,\n",
|
| 844 |
+
" ) -> List[QuantileForecast]:\n",
|
| 845 |
+
" \"\"\"Convert model predictions to QuantileForecast objects.\"\"\"\n",
|
| 846 |
+
"\n",
|
| 847 |
+
" predictions = model_output[\"result\"]\n",
|
| 848 |
+
" scale_statistics = model_output[\"scale_statistics\"]\n",
|
| 849 |
+
"\n",
|
| 850 |
+
" if predictions.ndim == 4:\n",
|
| 851 |
+
" predictions_unscaled = self.scaler.inverse_scale(\n",
|
| 852 |
+
" predictions, scale_statistics\n",
|
| 853 |
+
" )\n",
|
| 854 |
+
" is_quantile = True\n",
|
| 855 |
+
" quantile_levels = self.model.quantiles\n",
|
| 856 |
+
" else:\n",
|
| 857 |
+
" predictions_unscaled = self.scaler.inverse_scale(\n",
|
| 858 |
+
" predictions, scale_statistics\n",
|
| 859 |
+
" )\n",
|
| 860 |
+
" is_quantile = False\n",
|
| 861 |
+
" quantile_levels = [0.5]\n",
|
| 862 |
+
"\n",
|
| 863 |
+
" forecasts: List[QuantileForecast] = []\n",
|
| 864 |
+
" for idx, entry in enumerate(test_data_batch):\n",
|
| 865 |
+
" history_length = int(batch_container.history_values.shape[1])\n",
|
| 866 |
+
" start_date = entry[\"start\"]\n",
|
| 867 |
+
" forecast_start = start_date + history_length\n",
|
| 868 |
+
"\n",
|
| 869 |
+
" if is_quantile:\n",
|
| 870 |
+
" pred_array = predictions_unscaled[idx].cpu().numpy()\n",
|
| 871 |
+
"\n",
|
| 872 |
+
" if pred_array.shape[1] == 1:\n",
|
| 873 |
+
" pred_array = pred_array.squeeze(1)\n",
|
| 874 |
+
" forecast_arrays = pred_array.T\n",
|
| 875 |
+
" else:\n",
|
| 876 |
+
" forecast_arrays = pred_array.transpose(2, 0, 1)\n",
|
| 877 |
+
"\n",
|
| 878 |
+
" forecast = QuantileForecast(\n",
|
| 879 |
+
" forecast_arrays=forecast_arrays,\n",
|
| 880 |
+
" forecast_keys=[str(q) for q in quantile_levels],\n",
|
| 881 |
+
" start_date=forecast_start,\n",
|
| 882 |
+
" )\n",
|
| 883 |
+
" else:\n",
|
| 884 |
+
" pred_array = predictions_unscaled[idx].cpu().numpy()\n",
|
| 885 |
+
"\n",
|
| 886 |
+
" if pred_array.shape[1] == 1:\n",
|
| 887 |
+
" pred_array = pred_array.squeeze(1)\n",
|
| 888 |
+
" forecast_arrays = pred_array.reshape(1, -1)\n",
|
| 889 |
+
" else:\n",
|
| 890 |
+
" forecast_arrays = pred_array.reshape(1, *pred_array.shape)\n",
|
| 891 |
+
"\n",
|
| 892 |
+
" forecast = QuantileForecast(\n",
|
| 893 |
+
" forecast_arrays=forecast_arrays,\n",
|
| 894 |
+
" forecast_keys=[\"0.5\"],\n",
|
| 895 |
+
" start_date=forecast_start,\n",
|
| 896 |
+
" )\n",
|
| 897 |
+
"\n",
|
| 898 |
+
" forecasts.append(forecast)\n",
|
| 899 |
+
"\n",
|
| 900 |
+
" return forecasts"
|
| 901 |
+
]
|
| 902 |
+
},
|
| 903 |
+
{
|
| 904 |
+
"cell_type": "markdown",
|
| 905 |
+
"id": "o3p4q5r6",
|
| 906 |
+
"metadata": {},
|
| 907 |
+
"source": [
|
| 908 |
+
"### 3.5. Result Handling \n",
|
| 909 |
+
"\n",
|
| 910 |
+
"These functions handle writing the per-dataset metrics to CSV files and aggregating all results into a single `all_results.csv` at the end."
|
| 911 |
+
]
|
| 912 |
+
},
|
| 913 |
+
{
|
| 914 |
+
"cell_type": "code",
|
| 915 |
+
"execution_count": null,
|
| 916 |
+
"id": "p4q5r6s7",
|
| 917 |
+
"metadata": {},
|
| 918 |
+
"outputs": [],
|
| 919 |
+
"source": [
|
| 920 |
+
"def _ensure_results_csv(csv_file_path: Path) -> None:\n",
|
| 921 |
+
" if not csv_file_path.exists():\n",
|
| 922 |
+
" csv_file_path.parent.mkdir(parents=True, exist_ok=True)\n",
|
| 923 |
+
" with open(csv_file_path, \"w\", newline=\"\") as csvfile:\n",
|
| 924 |
+
" writer = csv.writer(csvfile)\n",
|
| 925 |
+
" header = (\n",
|
| 926 |
+
" [\"dataset\", \"model\"]\n",
|
| 927 |
+
" + [f\"eval_metrics/{name}\" for name in STANDARD_METRIC_NAMES]\n",
|
| 928 |
+
" + [\"domain\", \"num_variates\"]\n",
|
| 929 |
+
" )\n",
|
| 930 |
+
" writer.writerow(header)\n",
|
| 931 |
+
"\n",
|
| 932 |
+
"\n",
|
| 933 |
+
"def write_results_to_disk(\n",
|
| 934 |
+
" items: List[EvaluationItem],\n",
|
| 935 |
+
" dataset_name: str,\n",
|
| 936 |
+
" output_dir: Path,\n",
|
| 937 |
+
" model_name: str,\n",
|
| 938 |
+
" create_plots: bool,\n",
|
| 939 |
+
") -> None:\n",
|
| 940 |
+
" output_dir = output_dir / dataset_name\n",
|
| 941 |
+
" output_dir.mkdir(parents=True, exist_ok=True)\n",
|
| 942 |
+
" output_csv_path = output_dir / \"results.csv\"\n",
|
| 943 |
+
" _ensure_results_csv(output_csv_path)\n",
|
| 944 |
+
"\n",
|
| 945 |
+
" with open(output_csv_path, \"a\", newline=\"\") as csvfile:\n",
|
| 946 |
+
" writer = csv.writer(csvfile)\n",
|
| 947 |
+
" for item in items:\n",
|
| 948 |
+
" md: DatasetMetadata = item.dataset_metadata\n",
|
| 949 |
+
" metric_values: List[Optional[float]] = []\n",
|
| 950 |
+
" for metric_name in STANDARD_METRIC_NAMES:\n",
|
| 951 |
+
" value = item.metrics.get(metric_name, None)\n",
|
| 952 |
+
" if value is None:\n",
|
| 953 |
+
" metric_values.append(None)\n",
|
| 954 |
+
" else:\n",
|
| 955 |
+
" if (\n",
|
| 956 |
+
" hasattr(value, \"__len__\")\n",
|
| 957 |
+
" and not isinstance(value, (str, bytes))\n",
|
| 958 |
+
" and len(value) == 1\n",
|
| 959 |
+
" ):\n",
|
| 960 |
+
" value = value[0]\n",
|
| 961 |
+
" elif hasattr(value, \"item\"):\n",
|
| 962 |
+
" value = value.item()\n",
|
| 963 |
+
" metric_values.append(value)\n",
|
| 964 |
+
"\n",
|
| 965 |
+
" ds_key = md.key.lower()\n",
|
| 966 |
+
" props = DATASET_PROPERTIES.get(ds_key, {})\n",
|
| 967 |
+
" domain = props.get(\"domain\", \"unknown\")\n",
|
| 968 |
+
" num_variates = props.get(\n",
|
| 969 |
+
" \"num_variates\", 1 if md.to_univariate else md.target_dim\n",
|
| 970 |
+
" )\n",
|
| 971 |
+
"\n",
|
| 972 |
+
" row = [md.full_name, model_name] + metric_values + [domain, num_variates]\n",
|
| 973 |
+
" writer.writerow(row)\n",
|
| 974 |
+
"\n",
|
| 975 |
+
" if create_plots and item.figures and plt is not None:\n",
|
| 976 |
+
" plots_dir = output_dir / \"plots\" / md.key / md.term\n",
|
| 977 |
+
" plots_dir.mkdir(parents=True, exist_ok=True)\n",
|
| 978 |
+
" for fig, filename in item.figures:\n",
|
| 979 |
+
" filepath = plots_dir / filename\n",
|
| 980 |
+
" fig.savefig(filepath, dpi=300, bbox_inches=\"tight\")\n",
|
| 981 |
+
" plt.close(fig)\n",
|
| 982 |
+
"\n",
|
| 983 |
+
" logger.info(\n",
|
| 984 |
+
" \"Evaluation complete for dataset '%s'. Results saved to %s\",\n",
|
| 985 |
+
" dataset_name,\n",
|
| 986 |
+
" output_csv_path,\n",
|
| 987 |
+
" )\n",
|
| 988 |
+
" if create_plots:\n",
|
| 989 |
+
" logger.info(\"Plots saved under %s\", output_dir / \"plots\")\n",
|
| 990 |
+
"\n",
|
| 991 |
+
"\n",
|
| 992 |
+
"def get_all_datasets_full_name() -> List[str]:\n",
|
| 993 |
+
" \"\"\"Get all possible dataset full names for validation.\"\"\"\n",
|
| 994 |
+
"\n",
|
| 995 |
+
" terms = [\"short\", \"medium\", \"long\"]\n",
|
| 996 |
+
" datasets_full_names: List[str] = []\n",
|
| 997 |
+
"\n",
|
| 998 |
+
" for name in ALL_DATASETS:\n",
|
| 999 |
+
" for term in terms:\n",
|
| 1000 |
+
" if term in [\"medium\", \"long\"] and name not in MED_LONG_DATASETS:\n",
|
| 1001 |
+
" continue\n",
|
| 1002 |
+
"\n",
|
| 1003 |
+
" if \"/\" in name:\n",
|
| 1004 |
+
" ds_key, ds_freq = name.split(\"/\")\n",
|
| 1005 |
+
" ds_key = ds_key.lower()\n",
|
| 1006 |
+
" ds_key = PRETTY_NAMES.get(ds_key, ds_key)\n",
|
| 1007 |
+
" else:\n",
|
| 1008 |
+
" ds_key = name.lower()\n",
|
| 1009 |
+
" ds_key = PRETTY_NAMES.get(ds_key, ds_key)\n",
|
| 1010 |
+
" ds_freq = DATASET_PROPERTIES.get(ds_key, {}).get(\"frequency\")\n",
|
| 1011 |
+
"\n",
|
| 1012 |
+
" datasets_full_names.append(\n",
|
| 1013 |
+
" f\"{ds_key}/{ds_freq if ds_freq else 'unknown'}/{term}\"\n",
|
| 1014 |
+
" )\n",
|
| 1015 |
+
"\n",
|
| 1016 |
+
" return datasets_full_names\n",
|
| 1017 |
+
"\n",
|
| 1018 |
+
"\n",
|
| 1019 |
+
"def aggregate_results(result_root_dir: str | Path) -> pd.DataFrame | None:\n",
|
| 1020 |
+
" \"\"\"Aggregate results from multiple CSV files into a single dataframe.\"\"\"\n",
|
| 1021 |
+
"\n",
|
| 1022 |
+
" result_root = Path(result_root_dir)\n",
|
| 1023 |
+
"\n",
|
| 1024 |
+
" logger.info(\"Aggregating results in: %s\", result_root)\n",
|
| 1025 |
+
"\n",
|
| 1026 |
+
" result_files = glob.glob(f\"{result_root}/**/results.csv\", recursive=True)\n",
|
| 1027 |
+
"\n",
|
| 1028 |
+
" if not result_files:\n",
|
| 1029 |
+
" logger.error(\"No result files found!\")\n",
|
| 1030 |
+
" return None\n",
|
| 1031 |
+
"\n",
|
| 1032 |
+
" dataframes: List[pd.DataFrame] = []\n",
|
| 1033 |
+
" for file in result_files:\n",
|
| 1034 |
+
" try:\n",
|
| 1035 |
+
" df = pd.read_csv(file)\n",
|
| 1036 |
+
" if len(df) > 0:\n",
|
| 1037 |
+
" dataframes.append(df)\n",
|
| 1038 |
+
" else:\n",
|
| 1039 |
+
" logger.warning(\"Empty file: %s\", file)\n",
|
| 1040 |
+
" except pd.errors.EmptyDataError:\n",
|
| 1041 |
+
" logger.warning(\"Skipping empty file: %s\", file)\n",
|
| 1042 |
+
" except Exception as exc:\n",
|
| 1043 |
+
" logger.error(\"Error reading %s: %s\", file, exc)\n",
|
| 1044 |
+
"\n",
|
| 1045 |
+
" if not dataframes:\n",
|
| 1046 |
+
" logger.warning(\"No valid CSV files found to combine\")\n",
|
| 1047 |
+
" return None\n",
|
| 1048 |
+
"\n",
|
| 1049 |
+
" combined_df = pd.concat(dataframes, ignore_index=True).sort_values(\"dataset\")\n",
|
| 1050 |
+
"\n",
|
| 1051 |
+
" if len(combined_df) != len(set(combined_df.dataset)):\n",
|
| 1052 |
+
" duplicate_datasets = combined_df.dataset[\n",
|
| 1053 |
+
" combined_df.dataset.duplicated()\n",
|
| 1054 |
+
" ].tolist()\n",
|
| 1055 |
+
" logger.warning(\"Warning: Duplicate datasets found: %s\", duplicate_datasets)\n",
|
| 1056 |
+
" combined_df = combined_df.drop_duplicates(subset=[\"dataset\"], keep=\"first\")\n",
|
| 1057 |
+
" logger.info(\n",
|
| 1058 |
+
" \"Removed duplicates, %s unique datasets remaining\", len(combined_df)\n",
|
| 1059 |
+
" )\n",
|
| 1060 |
+
"\n",
|
| 1061 |
+
" logger.info(\"Combined results: %s datasets\", len(combined_df))\n",
|
| 1062 |
+
"\n",
|
| 1063 |
+
" all_datasets_full_name = get_all_datasets_full_name()\n",
|
| 1064 |
+
" completed_experiments = combined_df.dataset.tolist()\n",
|
| 1065 |
+
"\n",
|
| 1066 |
+
" completed_experiments_clean = [\n",
|
| 1067 |
+
" exp for exp in completed_experiments if exp in all_datasets_full_name\n",
|
| 1068 |
+
" ]\n",
|
| 1069 |
+
" missing_or_failed_experiments = [\n",
|
| 1070 |
+
" exp for exp in all_datasets_full_name if exp not in completed_experiments_clean\n",
|
| 1071 |
+
" ]\n",
|
| 1072 |
+
"\n",
|
| 1073 |
+
" logger.info(\"=== EXPERIMENT SUMMARY ===\")\n",
|
| 1074 |
+
" logger.info(\"Total expected datasets: %s\", len(all_datasets_full_name))\n",
|
| 1075 |
+
" logger.info(\"Completed experiments: %s\", len(completed_experiments_clean))\n",
|
| 1076 |
+
" logger.info(\"Missing/failed experiments: %s\", len(missing_or_failed_experiments))\n",
|
| 1077 |
+
"\n",
|
| 1078 |
+
" output_file = result_root / \"all_results.csv\"\n",
|
| 1079 |
+
" combined_df.to_csv(output_file, index=False)\n",
|
| 1080 |
+
" logger.info(\"Combined results saved to: %s\", output_file)\n",
|
| 1081 |
+
"\n",
|
| 1082 |
+
" return combined_df"
|
| 1083 |
+
]
|
| 1084 |
+
},
|
| 1085 |
+
{
|
| 1086 |
+
"cell_type": "markdown",
|
| 1087 |
+
"id": "q5r6s7t8",
|
| 1088 |
+
"metadata": {},
|
| 1089 |
+
"source": [
|
| 1090 |
+
"### 3.6. Evaluation Harness (`evaluate.py`)\n",
|
| 1091 |
+
"\n",
|
| 1092 |
+
"This is the main evaluation logic that iterates over dataset terms, prepares the data, calls the predictor, and gathers metrics."
|
| 1093 |
+
]
|
| 1094 |
+
},
|
| 1095 |
+
{
|
| 1096 |
+
"cell_type": "code",
|
| 1097 |
+
"execution_count": null,
|
| 1098 |
+
"id": "r6s7t8u9",
|
| 1099 |
+
"metadata": {},
|
| 1100 |
+
"outputs": [],
|
| 1101 |
+
"source": [
|
| 1102 |
+
"def construct_evaluation_data(\n",
|
| 1103 |
+
" dataset_name: str,\n",
|
| 1104 |
+
" dataset_storage_path: str,\n",
|
| 1105 |
+
" terms: List[str] = [\"short\", \"medium\", \"long\"],\n",
|
| 1106 |
+
" max_windows: Optional[int] = None,\n",
|
| 1107 |
+
") -> List[Tuple[Dataset, DatasetMetadata]]:\n",
|
| 1108 |
+
" \"\"\"Build datasets and rich metadata per term for a dataset name.\"\"\"\n",
|
| 1109 |
+
" sub_datasets: List[Tuple[Dataset, DatasetMetadata]] = []\n",
|
| 1110 |
+
"\n",
|
| 1111 |
+
" if \"/\" in dataset_name:\n",
|
| 1112 |
+
" ds_key, ds_freq = dataset_name.split(\"/\")\n",
|
| 1113 |
+
" ds_key = ds_key.lower()\n",
|
| 1114 |
+
" ds_key = PRETTY_NAMES.get(ds_key, ds_key)\n",
|
| 1115 |
+
" else:\n",
|
| 1116 |
+
" ds_key = dataset_name.lower()\n",
|
| 1117 |
+
" ds_key = PRETTY_NAMES.get(ds_key, ds_key)\n",
|
| 1118 |
+
" ds_freq = DATASET_PROPERTIES.get(ds_key, {}).get(\"frequency\")\n",
|
| 1119 |
+
"\n",
|
| 1120 |
+
" for term in terms:\n",
|
| 1121 |
+
" # Skip medium/long terms for datasets that don't support them\n",
|
| 1122 |
+
" if (\n",
|
| 1123 |
+
" term == \"medium\" or term == \"long\"\n",
|
| 1124 |
+
" ) and dataset_name not in MED_LONG_DATASETS:\n",
|
| 1125 |
+
" continue\n",
|
| 1126 |
+
"\n",
|
| 1127 |
+
" # Probe once to determine dimensionality\n",
|
| 1128 |
+
" probe_dataset = Dataset(\n",
|
| 1129 |
+
" name=dataset_name,\n",
|
| 1130 |
+
" term=term,\n",
|
| 1131 |
+
" to_univariate=False,\n",
|
| 1132 |
+
" storage_path=dataset_storage_path,\n",
|
| 1133 |
+
" max_windows=max_windows,\n",
|
| 1134 |
+
" )\n",
|
| 1135 |
+
"\n",
|
| 1136 |
+
" to_univariate = probe_dataset.target_dim > 1\n",
|
| 1137 |
+
"\n",
|
| 1138 |
+
" dataset = Dataset(\n",
|
| 1139 |
+
" name=dataset_name,\n",
|
| 1140 |
+
" term=term,\n",
|
| 1141 |
+
" to_univariate=to_univariate,\n",
|
| 1142 |
+
" storage_path=dataset_storage_path,\n",
|
| 1143 |
+
" max_windows=max_windows,\n",
|
| 1144 |
+
" )\n",
|
| 1145 |
+
"\n",
|
| 1146 |
+
" # Compute metadata\n",
|
| 1147 |
+
" season_length = get_seasonality(dataset.freq)\n",
|
| 1148 |
+
" actual_freq = ds_freq if ds_freq else dataset.freq\n",
|
| 1149 |
+
" \n",
|
| 1150 |
+
" metadata = DatasetMetadata(\n",
|
| 1151 |
+
" full_name=f\"{ds_key}/{actual_freq}/{term}\",\n",
|
| 1152 |
+
" key=ds_key,\n",
|
| 1153 |
+
" freq=actual_freq,\n",
|
| 1154 |
+
" term=term,\n",
|
| 1155 |
+
" season_length=season_length,\n",
|
| 1156 |
+
" target_dim=probe_dataset.target_dim,\n",
|
| 1157 |
+
" to_univariate=to_univariate,\n",
|
| 1158 |
+
" prediction_length=dataset.prediction_length,\n",
|
| 1159 |
+
" windows=dataset.windows,\n",
|
| 1160 |
+
" )\n",
|
| 1161 |
+
"\n",
|
| 1162 |
+
" sub_datasets.append((dataset, metadata))\n",
|
| 1163 |
+
"\n",
|
| 1164 |
+
" return sub_datasets\n",
|
| 1165 |
+
"\n",
|
| 1166 |
+
"\n",
|
| 1167 |
+
"def evaluate_datasets(\n",
|
| 1168 |
+
" predictor: TimeSeriesPredictor,\n",
|
| 1169 |
+
" dataset: str,\n",
|
| 1170 |
+
" dataset_storage_path: str,\n",
|
| 1171 |
+
" terms: List[str] = [\"short\", \"medium\", \"long\"],\n",
|
| 1172 |
+
" max_windows: Optional[int] = None,\n",
|
| 1173 |
+
" batch_size: int = 48,\n",
|
| 1174 |
+
" max_context_length: Optional[int] = 1024,\n",
|
| 1175 |
+
" create_plots: bool = False,\n",
|
| 1176 |
+
" max_plots_per_dataset: int = 10,\n",
|
| 1177 |
+
") -> List[EvaluationItem]:\n",
|
| 1178 |
+
" \"\"\"Evaluate predictor on one dataset across the requested terms.\"\"\"\n",
|
| 1179 |
+
" sub_datasets = construct_evaluation_data(\n",
|
| 1180 |
+
" dataset_name=dataset,\n",
|
| 1181 |
+
" dataset_storage_path=dataset_storage_path,\n",
|
| 1182 |
+
" terms=terms,\n",
|
| 1183 |
+
" max_windows=max_windows,\n",
|
| 1184 |
+
" )\n",
|
| 1185 |
+
"\n",
|
| 1186 |
+
" results: List[EvaluationItem] = []\n",
|
| 1187 |
+
" for i, (sub_dataset, metadata) in enumerate(sub_datasets):\n",
|
| 1188 |
+
" logger.info(f\"Evaluating {i + 1}/{len(sub_datasets)}: {metadata.full_name}\")\n",
|
| 1189 |
+
" logger.info(f\" Dataset size: {len(sub_dataset.test_data)}\")\n",
|
| 1190 |
+
" logger.info(f\" Frequency: {sub_dataset.freq}\")\n",
|
| 1191 |
+
" logger.info(f\" Term: {metadata.term}\")\n",
|
| 1192 |
+
" logger.info(f\" Prediction length: {sub_dataset.prediction_length}\")\n",
|
| 1193 |
+
" logger.info(f\" Target dimensions: {sub_dataset.target_dim}\")\n",
|
| 1194 |
+
" logger.info(f\" Windows: {sub_dataset.windows}\")\n",
|
| 1195 |
+
"\n",
|
| 1196 |
+
" # Update context on the reusable predictor\n",
|
| 1197 |
+
" predictor.set_dataset_context(\n",
|
| 1198 |
+
" prediction_length=sub_dataset.prediction_length,\n",
|
| 1199 |
+
" freq=sub_dataset.freq,\n",
|
| 1200 |
+
" batch_size=batch_size,\n",
|
| 1201 |
+
" max_context_length=max_context_length,\n",
|
| 1202 |
+
" )\n",
|
| 1203 |
+
"\n",
|
| 1204 |
+
" res = evaluate_model(\n",
|
| 1205 |
+
" model=predictor,\n",
|
| 1206 |
+
" test_data=sub_dataset.test_data,\n",
|
| 1207 |
+
" metrics=METRICS,\n",
|
| 1208 |
+
" axis=None,\n",
|
| 1209 |
+
" mask_invalid_label=True,\n",
|
| 1210 |
+
" allow_nan_forecast=False,\n",
|
| 1211 |
+
" seasonality=metadata.season_length,\n",
|
| 1212 |
+
" )\n",
|
| 1213 |
+
"\n",
|
| 1214 |
+
" figs: List[Tuple[object, str]] = []\n",
|
| 1215 |
+
" if create_plots:\n",
|
| 1216 |
+
" # We are missing `src.plotting.gift_eval_utils.create_plots_for_dataset`\n",
|
| 1217 |
+
" # As this was not provided, plotting will be skipped.\n",
|
| 1218 |
+
" logger.warning(\"Plotting is enabled but `create_plots_for_dataset` is not defined. Skipping plot generation.\")\n",
|
| 1219 |
+
" pass\n",
|
| 1220 |
+
"\n",
|
| 1221 |
+
" results.append(\n",
|
| 1222 |
+
" EvaluationItem(dataset_metadata=metadata, metrics=res, figures=figs)\n",
|
| 1223 |
+
" )\n",
|
| 1224 |
+
"\n",
|
| 1225 |
+
" return results"
|
| 1226 |
+
]
|
| 1227 |
+
},
|
| 1228 |
+
{
|
| 1229 |
+
"cell_type": "markdown",
|
| 1230 |
+
"id": "s7t8u9v0",
|
| 1231 |
+
"metadata": {},
|
| 1232 |
+
"source": [
|
| 1233 |
+
"## 4. Configuration\n",
|
| 1234 |
+
"\n",
|
| 1235 |
+
"Set the parameters for the evaluation run. Update `config_path` and `checkpoint_url` to point to your model's files."
|
| 1236 |
+
]
|
| 1237 |
+
},
|
| 1238 |
+
{
|
| 1239 |
+
"cell_type": "code",
|
| 1240 |
+
"execution_count": null,
|
| 1241 |
+
"id": "t8u9v0w1",
|
| 1242 |
+
"metadata": {},
|
| 1243 |
+
"outputs": [],
|
| 1244 |
+
"source": [
|
| 1245 |
+
"# --- Parameters ---\n",
|
| 1246 |
+
"model_path = None # e.g., \"/path/to/checkpoint.pth\"; if None, try checkpoint_url\n",
|
| 1247 |
+
"config_path = Path.cwd().parent.parent / \"configs/example.yaml\" \n",
|
| 1248 |
+
"checkpoint_url = \"https://www.dropbox.com/scl/fi/mqsni5lehooyaw93y3uzq/checkpoint_38M.pth?rlkey=3uyehvmtted02xkha24zgpzb6&st=seevsbkn&dl=0\" \n",
|
| 1249 |
+
"\n",
|
| 1250 |
+
"# --- Datasets and evaluation controls ---\n",
|
| 1251 |
+
"# Use a small subset for testing, e.g., [\"m4_weekly\"]\n",
|
| 1252 |
+
"datasets_arg = [\"all\"] # list of dataset names or [\"all\"]. \n",
|
| 1253 |
+
"terms = [\"short\", \"medium\", \"long\"]\n",
|
| 1254 |
+
"dataset_storage_path = os.getenv(\"GIFT_EVAL_DATASET_STORAGE_PATH\")\n",
|
| 1255 |
+
"max_windows = 20\n",
|
| 1256 |
+
"batch_size = 64\n",
|
| 1257 |
+
"max_context_length = 3072 \n",
|
| 1258 |
+
"\n",
|
| 1259 |
+
"# --- Output ---\n",
|
| 1260 |
+
"after_each_dataset_flush = True # write CSV as each dataset completes\n",
|
| 1261 |
+
"model_name = \"TempoPFN\"\n",
|
| 1262 |
+
"download_dir = Path.cwd().parent / \"models\"\n",
|
| 1263 |
+
"output_dir = Path.cwd().parent / \"gift_eval_results\" / model_name\n",
|
| 1264 |
+
"\n",
|
| 1265 |
+
"# --- Helper Functions ---\n",
|
| 1266 |
+
"\n",
|
| 1267 |
+
"def download_checkpoint_if_needed(url: str, target_dir: Path, target_filename: str = \"checkpoint.pth\") -> Path:\n",
|
| 1268 |
+
" \"\"\"Downloads a file from a URL if it doesn't exist.\"\"\"\n",
|
| 1269 |
+
" try:\n",
|
| 1270 |
+
" import requests\n",
|
| 1271 |
+
" except ImportError:\n",
|
| 1272 |
+
" logger.error(\"requests package not found. Please install it: pip install requests\")\n",
|
| 1273 |
+
" raise\n",
|
| 1274 |
+
" \n",
|
| 1275 |
+
" target_dir.mkdir(parents=True, exist_ok=True)\n",
|
| 1276 |
+
" target_file_path = target_dir / target_filename\n",
|
| 1277 |
+
" \n",
|
| 1278 |
+
" if target_file_path.exists():\n",
|
| 1279 |
+
" logger.info(f\"Checkpoint already exists: {target_file_path}\")\n",
|
| 1280 |
+
" return target_file_path\n",
|
| 1281 |
+
" \n",
|
| 1282 |
+
" logger.info(f\"Downloading checkpoint from {url} to {target_file_path}...\")\n",
|
| 1283 |
+
" \n",
|
| 1284 |
+
" # Handle Dropbox links\n",
|
| 1285 |
+
" if \"dropbox.com\" in url:\n",
|
| 1286 |
+
" url = url.replace(\"dl=0\", \"dl=1\").replace(\"st=\", \"dl=1&st=\")\n",
|
| 1287 |
+
" \n",
|
| 1288 |
+
" try:\n",
|
| 1289 |
+
" with requests.get(url, stream=True) as r:\n",
|
| 1290 |
+
" r.raise_for_status()\n",
|
| 1291 |
+
" with open(target_file_path, 'wb') as f:\n",
|
| 1292 |
+
" for chunk in r.iter_content(chunk_size=8192):\n",
|
| 1293 |
+
" f.write(chunk)\n",
|
| 1294 |
+
" logger.info(\"Download complete.\")\n",
|
| 1295 |
+
" return target_file_path\n",
|
| 1296 |
+
" except Exception as e:\n",
|
| 1297 |
+
" logger.error(f\"Failed to download checkpoint: {e}\")\n",
|
| 1298 |
+
" if target_file_path.exists():\n",
|
| 1299 |
+
" os.remove(target_file_path) # Clean up partial download\n",
|
| 1300 |
+
" raise\n",
|
| 1301 |
+
"\n",
|
| 1302 |
+
"def _load_yaml(path: str) -> dict:\n",
|
| 1303 |
+
" with open(path, \"r\") as f:\n",
|
| 1304 |
+
" return yaml.safe_load(f)"
|
| 1305 |
+
]
|
| 1306 |
+
},
|
| 1307 |
+
{
|
| 1308 |
+
"cell_type": "markdown",
|
| 1309 |
+
"id": "u9v0w1x2",
|
| 1310 |
+
"metadata": {},
|
| 1311 |
+
"source": [
|
| 1312 |
+
"## 5. Main Evaluation Loop\n",
|
| 1313 |
+
"\n",
|
| 1314 |
+
"This cell sets up the predictor and runs the main evaluation loop over all specified datasets."
|
| 1315 |
+
]
|
| 1316 |
+
},
|
| 1317 |
+
{
|
| 1318 |
+
"cell_type": "code",
|
| 1319 |
+
"execution_count": null,
|
| 1320 |
+
"id": "v0w1x2y3",
|
| 1321 |
+
"metadata": {},
|
| 1322 |
+
"outputs": [],
|
| 1323 |
+
"source": [
|
| 1324 |
+
"logger.info(\"Starting evaluation for model: %s\", model_name)\n",
|
| 1325 |
+
"\n",
|
| 1326 |
+
"# 1. Build predictor from a checkpoint\n",
|
| 1327 |
+
"resolved_model_path = None\n",
|
| 1328 |
+
"if model_path:\n",
|
| 1329 |
+
" resolved_model_path = model_path\n",
|
| 1330 |
+
"elif checkpoint_url:\n",
|
| 1331 |
+
" resolved_model_path = download_checkpoint_if_needed(\n",
|
| 1332 |
+
" checkpoint_url, \n",
|
| 1333 |
+
" target_dir=download_dir,\n",
|
| 1334 |
+
" target_filename=f\"{model_name}_checkpoint.pth\"\n",
|
| 1335 |
+
" )\n",
|
| 1336 |
+
"\n",
|
| 1337 |
+
"if not resolved_model_path or not Path(resolved_model_path).exists():\n",
|
| 1338 |
+
" raise FileNotFoundError(\n",
|
| 1339 |
+
" f\"No model checkpoint found. Set `model_path` or `checkpoint_url`. Tried: {resolved_model_path}\"\n",
|
| 1340 |
+
" )\n",
|
| 1341 |
+
"\n",
|
| 1342 |
+
"assert Path(config_path).exists(), f\"Config not found: {config_path}\"\n",
|
| 1343 |
+
"logger.info(\"Loading predictor from checkpoint: %s\", resolved_model_path)\n",
|
| 1344 |
+
"\n",
|
| 1345 |
+
"predictor = TimeSeriesPredictor.from_paths(\n",
|
| 1346 |
+
" model_path=resolved_model_path,\n",
|
| 1347 |
+
" config_path=config_path,\n",
|
| 1348 |
+
" ds_prediction_length=1, # placeholder; set per dataset\n",
|
| 1349 |
+
" ds_freq=\"D\", # placeholder; set per dataset\n",
|
| 1350 |
+
" batch_size=batch_size,\n",
|
| 1351 |
+
" max_context_length=max_context_length,\n",
|
| 1352 |
+
")\n",
|
| 1353 |
+
"\n",
|
| 1354 |
+
"# 2. Run evaluation loop\n",
|
| 1355 |
+
"datasets_to_run = expand_datasets_arg(datasets_arg)\n",
|
| 1356 |
+
"results_root = Path(output_dir)\n",
|
| 1357 |
+
"\n",
|
| 1358 |
+
"for ds_name in datasets_to_run:\n",
|
| 1359 |
+
" try:\n",
|
| 1360 |
+
" items = evaluate_datasets(\n",
|
| 1361 |
+
" predictor=predictor,\n",
|
| 1362 |
+
" dataset=ds_name,\n",
|
| 1363 |
+
" dataset_storage_path=dataset_storage_path,\n",
|
| 1364 |
+
" terms=terms,\n",
|
| 1365 |
+
" max_windows=max_windows,\n",
|
| 1366 |
+
" batch_size=batch_size,\n",
|
| 1367 |
+
" max_context_length=max_context_length,\n",
|
| 1368 |
+
" create_plots=False, # Set to True if you implement plotting\n",
|
| 1369 |
+
" max_plots_per_dataset=0,\n",
|
| 1370 |
+
" )\n",
|
| 1371 |
+
" write_results_to_disk(\n",
|
| 1372 |
+
" items=items,\n",
|
| 1373 |
+
" dataset_name=ds_name,\n",
|
| 1374 |
+
" output_dir=results_root,\n",
|
| 1375 |
+
" model_name=model_name,\n",
|
| 1376 |
+
" create_plots=False,\n",
|
| 1377 |
+
" )\n",
|
| 1378 |
+
" if after_each_dataset_flush:\n",
|
| 1379 |
+
" logger.info(\"Flushed results for %s\", ds_name)\n",
|
| 1380 |
+
" except Exception as e:\n",
|
| 1381 |
+
" logger.error(f\"FAILED evaluation for dataset: {ds_name}. Error: {e} !!!\")\n",
|
| 1382 |
+
" logger.exception(e)\n",
|
| 1383 |
+
" continue # Continue to the next dataset\n",
|
| 1384 |
+
"\n",
|
| 1385 |
+
"print(f\"\\nEvaluation complete. See results under: {output_dir}\")"
|
| 1386 |
+
]
|
| 1387 |
+
},
|
| 1388 |
+
{
|
| 1389 |
+
"cell_type": "markdown",
|
| 1390 |
+
"id": "w1x2y3z4",
|
| 1391 |
+
"metadata": {},
|
| 1392 |
+
"source": [
|
| 1393 |
+
"## 6. Aggregate Results\n",
|
| 1394 |
+
"\n",
|
| 1395 |
+
"Finally, we'll aggregate the individual CSV files into a single `all_results.csv` file for easy analysis, following the `gift-eval` convention."
|
| 1396 |
+
]
|
| 1397 |
+
},
|
| 1398 |
+
{
|
| 1399 |
+
"cell_type": "code",
|
| 1400 |
+
"execution_count": null,
|
| 1401 |
+
"id": "x2y3z4a5",
|
| 1402 |
+
"metadata": {},
|
| 1403 |
+
"outputs": [],
|
| 1404 |
+
"source": [
|
| 1405 |
+
"logger.info(\"Aggregating results from all datasets...\")\n",
|
| 1406 |
+
"combined_df = aggregate_results(result_root_dir=output_dir)\n",
|
| 1407 |
+
"\n",
|
| 1408 |
+
"if combined_df is not None:\n",
|
| 1409 |
+
" agg_path = Path(output_dir) / \"all_results.csv\"\n",
|
| 1410 |
+
" logger.info(\"Successfully created aggregated results file: %s\", agg_path)\n",
|
| 1411 |
+
" print(f\"\\n✅ Aggregated results saved to: {agg_path}\")\n",
|
| 1412 |
+
" print(combined_df.head())\n",
|
| 1413 |
+
"else:\n",
|
| 1414 |
+
" logger.warning(\"No results to aggregate. Check that evaluation completed successfully.\")"
|
| 1415 |
+
]
|
| 1416 |
+
}
|
| 1417 |
+
],
|
| 1418 |
+
"metadata": {
|
| 1419 |
+
"kernelspec": {
|
| 1420 |
+
"display_name": "Python 3 (ipykernel)",
|
| 1421 |
+
"language": "python",
|
| 1422 |
+
"name": "python3"
|
| 1423 |
+
},
|
| 1424 |
+
"language_info": {
|
| 1425 |
+
"codemirror_mode": {
|
| 1426 |
+
"name": "ipython",
|
| 1427 |
+
"version": 3
|
| 1428 |
+
},
|
| 1429 |
+
"file_extension": ".py",
|
| 1430 |
+
"mimetype": "text/x-python",
|
| 1431 |
+
"name": "python",
|
| 1432 |
+
"nbconvert_exporter": "python",
|
| 1433 |
+
"pygments_lexer": "ipython3",
|
| 1434 |
+
"version": "3.12.9"
|
| 1435 |
+
}
|
| 1436 |
+
},
|
| 1437 |
+
"nbformat": 4,
|
| 1438 |
+
"nbformat_minor": 5
|
| 1439 |
+
}
|
examples/quick_start_tempo_pfn.ipynb
ADDED
|
@@ -0,0 +1,280 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "231c6227",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"# Quick Start: Univariate Quantile Forecasting (CUDA, bfloat16)\n",
|
| 9 |
+
"\n",
|
| 10 |
+
"This notebook demonstrates how to:\n",
|
| 11 |
+
"- Generate synthetic sine wave time series data\n",
|
| 12 |
+
"- Pack data into `BatchTimeSeriesContainer`\n",
|
| 13 |
+
"- Load a pretrained model (from Dropbox)\n",
|
| 14 |
+
"- Run inference with bfloat16 on CUDA\n",
|
| 15 |
+
"- Visualize predictions\n"
|
| 16 |
+
]
|
| 17 |
+
},
|
| 18 |
+
{
|
| 19 |
+
"cell_type": "markdown",
|
| 20 |
+
"id": "bb6c5424-1c63-4cb0-a818-45d4199914e5",
|
| 21 |
+
"metadata": {},
|
| 22 |
+
"source": [
|
| 23 |
+
"## 1) Setup"
|
| 24 |
+
]
|
| 25 |
+
},
|
| 26 |
+
{
|
| 27 |
+
"cell_type": "code",
|
| 28 |
+
"execution_count": null,
|
| 29 |
+
"id": "612a78e8",
|
| 30 |
+
"metadata": {},
|
| 31 |
+
"outputs": [],
|
| 32 |
+
"source": [
|
| 33 |
+
"import urllib.request\n",
|
| 34 |
+
"import torch\n",
|
| 35 |
+
"import numpy as np\n",
|
| 36 |
+
"from pathlib import Path\n",
|
| 37 |
+
"\n",
|
| 38 |
+
"# Ensure CUDA is available\n",
|
| 39 |
+
"if not torch.cuda.is_available():\n",
|
| 40 |
+
" raise RuntimeError(\"CUDA is required to run this demo. No CUDA device detected.\")\n",
|
| 41 |
+
"\n",
|
| 42 |
+
"device = torch.device(\"cuda:0\")\n",
|
| 43 |
+
"\n",
|
| 44 |
+
"# Resolve repository root to be robust to running from subdirectories (e.g., examples/)\n",
|
| 45 |
+
"repo_root = Path.cwd()\n",
|
| 46 |
+
"if not (repo_root / \"configs\").exists():\n",
|
| 47 |
+
" repo_root = repo_root.parent\n",
|
| 48 |
+
"\n",
|
| 49 |
+
"# Inline plotting\n",
|
| 50 |
+
"%matplotlib inline\n"
|
| 51 |
+
]
|
| 52 |
+
},
|
| 53 |
+
{
|
| 54 |
+
"cell_type": "markdown",
|
| 55 |
+
"id": "3facf37d-0a77-4222-8464-6e42182547f8",
|
| 56 |
+
"metadata": {},
|
| 57 |
+
"source": [
|
| 58 |
+
"## 2) Define Checkpoint Path"
|
| 59 |
+
]
|
| 60 |
+
},
|
| 61 |
+
{
|
| 62 |
+
"cell_type": "code",
|
| 63 |
+
"execution_count": null,
|
| 64 |
+
"id": "16dcb883",
|
| 65 |
+
"metadata": {},
|
| 66 |
+
"outputs": [],
|
| 67 |
+
"source": [
|
| 68 |
+
"CHECKPOINT_DIR = repo_root / \"models\"\n",
|
| 69 |
+
"CHECKPOINT_NAME = \"checkpoint_38M.pth\" \n",
|
| 70 |
+
"CHECKPOINT_PATH = CHECKPOINT_DIR / CHECKPOINT_NAME\n",
|
| 71 |
+
"\n",
|
| 72 |
+
"# Ensure the models directory exists\n",
|
| 73 |
+
"CHECKPOINT_DIR.mkdir(parents=True, exist_ok=True) \n",
|
| 74 |
+
"\n",
|
| 75 |
+
"if not CHECKPOINT_PATH.exists():\n",
|
| 76 |
+
" print(f\"--- WARNING: Checkpoint not found at: {CHECKPOINT_PATH} ---\")\n",
|
| 77 |
+
" print(\"Please ensure 'checkpoint_38M.pth' is in the 'models/' directory.\")\n",
|
| 78 |
+
" print(\"If you cloned from Hugging Face, you may need to run 'git lfs pull'.\")\n",
|
| 79 |
+
" raise FileNotFoundError(f\"Model checkpoint not found at {CHECKPOINT_PATH}\")\n",
|
| 80 |
+
"else:\n",
|
| 81 |
+
" print(f\"Using existing checkpoint at {CHECKPOINT_PATH}\")"
|
| 82 |
+
]
|
| 83 |
+
},
|
| 84 |
+
{
|
| 85 |
+
"cell_type": "markdown",
|
| 86 |
+
"id": "9be77e34-0c7a-4056-822f-ed2e3e090c40",
|
| 87 |
+
"metadata": {},
|
| 88 |
+
"source": [
|
| 89 |
+
"## 3) Generate synthetic sine wave data"
|
| 90 |
+
]
|
| 91 |
+
},
|
| 92 |
+
{
|
| 93 |
+
"cell_type": "code",
|
| 94 |
+
"execution_count": null,
|
| 95 |
+
"id": "1127526c",
|
| 96 |
+
"metadata": {},
|
| 97 |
+
"outputs": [],
|
| 98 |
+
"source": [
|
| 99 |
+
"from src.synthetic_generation.generator_params import SineWaveGeneratorParams\n",
|
| 100 |
+
"from src.synthetic_generation.sine_waves.sine_wave_generator_wrapper import (\n",
|
| 101 |
+
" SineWaveGeneratorWrapper,\n",
|
| 102 |
+
")\n",
|
| 103 |
+
"\n",
|
| 104 |
+
"batch_size = 3\n",
|
| 105 |
+
"total_length = 1024\n",
|
| 106 |
+
"seed = 2025\n",
|
| 107 |
+
"\n",
|
| 108 |
+
"sine_params = SineWaveGeneratorParams(global_seed=seed, length=total_length)\n",
|
| 109 |
+
"wrapper = SineWaveGeneratorWrapper(sine_params)\n",
|
| 110 |
+
"\n",
|
| 111 |
+
"batch = wrapper.generate_batch(batch_size=batch_size, seed=seed)\n",
|
| 112 |
+
"values = torch.from_numpy(batch.values).to(torch.float32)\n",
|
| 113 |
+
"if values.ndim == 2:\n",
|
| 114 |
+
" values = values.unsqueeze(-1) # [B, S, 1]\n",
|
| 115 |
+
"\n",
|
| 116 |
+
"future_length = 256\n",
|
| 117 |
+
"history_values = values[:, :-future_length, :]\n",
|
| 118 |
+
"future_values = values[:, -future_length:, :]\n",
|
| 119 |
+
"\n",
|
| 120 |
+
"print(\"History:\", history_values.shape, \"Future:\", future_values.shape)"
|
| 121 |
+
]
|
| 122 |
+
},
|
| 123 |
+
{
|
| 124 |
+
"cell_type": "markdown",
|
| 125 |
+
"id": "a8844488-e51c-4805-baa9-491bfc67e8ca",
|
| 126 |
+
"metadata": {},
|
| 127 |
+
"source": [
|
| 128 |
+
"## 4) Build BatchTimeSeriesContainer"
|
| 129 |
+
]
|
| 130 |
+
},
|
| 131 |
+
{
|
| 132 |
+
"cell_type": "code",
|
| 133 |
+
"execution_count": null,
|
| 134 |
+
"id": "f3b4d361",
|
| 135 |
+
"metadata": {},
|
| 136 |
+
"outputs": [],
|
| 137 |
+
"source": [
|
| 138 |
+
"from src.data.containers import BatchTimeSeriesContainer\n",
|
| 139 |
+
"\n",
|
| 140 |
+
"container = BatchTimeSeriesContainer(\n",
|
| 141 |
+
" history_values=history_values.to(device),\n",
|
| 142 |
+
" future_values=future_values.to(device),\n",
|
| 143 |
+
" start=batch.start,\n",
|
| 144 |
+
" frequency=batch.frequency,\n",
|
| 145 |
+
")\n",
|
| 146 |
+
"\n",
|
| 147 |
+
"container.batch_size, container.history_length, container.future_length"
|
| 148 |
+
]
|
| 149 |
+
},
|
| 150 |
+
{
|
| 151 |
+
"cell_type": "markdown",
|
| 152 |
+
"id": "b5e7e790-a9aa-49c2-9d45-2dc823036883",
|
| 153 |
+
"metadata": {},
|
| 154 |
+
"source": [
|
| 155 |
+
"## 5) Load model and run inference"
|
| 156 |
+
]
|
| 157 |
+
},
|
| 158 |
+
{
|
| 159 |
+
"cell_type": "code",
|
| 160 |
+
"execution_count": null,
|
| 161 |
+
"id": "1dd4e0e4",
|
| 162 |
+
"metadata": {},
|
| 163 |
+
"outputs": [],
|
| 164 |
+
"source": [
|
| 165 |
+
"import yaml\n",
|
| 166 |
+
"from src.models.model import TimeSeriesModel\n",
|
| 167 |
+
"\n",
|
| 168 |
+
"with open(repo_root / \"configs/example.yaml\", \"r\") as f:\n",
|
| 169 |
+
" config = yaml.safe_load(f)\n",
|
| 170 |
+
"\n",
|
| 171 |
+
"model = TimeSeriesModel(**config[\"TimeSeriesModel\"]).to(device)\n",
|
| 172 |
+
"ckpt = torch.load(CHECKPOINT_PATH, map_location=device)\n",
|
| 173 |
+
"model.load_state_dict(ckpt[\"model_state_dict\"])\n",
|
| 174 |
+
"model.eval()\n",
|
| 175 |
+
"\n",
|
| 176 |
+
"# bfloat16 autocast on CUDA\n",
|
| 177 |
+
"with (\n",
|
| 178 |
+
" torch.no_grad(),\n",
|
| 179 |
+
" torch.autocast(device_type=\"cuda\", dtype=torch.bfloat16, enabled=True),\n",
|
| 180 |
+
"):\n",
|
| 181 |
+
" output = model(container)\n",
|
| 182 |
+
"\n",
|
| 183 |
+
"preds = output[\"result\"].to(torch.float32)\n",
|
| 184 |
+
"if hasattr(model, \"scaler\") and \"scale_statistics\" in output:\n",
|
| 185 |
+
" preds = model.scaler.inverse_scale(preds, output[\"scale_statistics\"])\n",
|
| 186 |
+
"\n",
|
| 187 |
+
"preds.shape"
|
| 188 |
+
]
|
| 189 |
+
},
|
| 190 |
+
{
|
| 191 |
+
"cell_type": "markdown",
|
| 192 |
+
"id": "ba16120f-27c8-4462-91cb-c9b3e0630a9d",
|
| 193 |
+
"metadata": {},
|
| 194 |
+
"source": [
|
| 195 |
+
"## 6) Plot predictions"
|
| 196 |
+
]
|
| 197 |
+
},
|
| 198 |
+
{
|
| 199 |
+
"cell_type": "code",
|
| 200 |
+
"execution_count": null,
|
| 201 |
+
"id": "9bf02a0b",
|
| 202 |
+
"metadata": {},
|
| 203 |
+
"outputs": [],
|
| 204 |
+
"source": [
|
| 205 |
+
"import matplotlib.pyplot as plt\n",
|
| 206 |
+
"\n",
|
| 207 |
+
"plt.set_loglevel(\"error\")\n",
|
| 208 |
+
"\n",
|
| 209 |
+
"# preds: [B, P, N, Q] for quantiles (univariate -> N=1)\n",
|
| 210 |
+
"preds_np = preds.cpu().numpy()\n",
|
| 211 |
+
"\n",
|
| 212 |
+
"batch_size = preds_np.shape[0]\n",
|
| 213 |
+
"prediction_length = preds_np.shape[1]\n",
|
| 214 |
+
"num_quantiles = preds_np.shape[-1]\n",
|
| 215 |
+
"\n",
|
| 216 |
+
"for i in range(batch_size):\n",
|
| 217 |
+
" fig, ax = plt.subplots(figsize=(12, 4))\n",
|
| 218 |
+
"\n",
|
| 219 |
+
" history = container.history_values[i, :, 0].detach().cpu().numpy()\n",
|
| 220 |
+
" future = container.future_values[i, :, 0].detach().cpu().numpy()\n",
|
| 221 |
+
"\n",
|
| 222 |
+
" # Time axes\n",
|
| 223 |
+
" hist_t = np.arange(len(history))\n",
|
| 224 |
+
" fut_t = np.arange(len(history), len(history) + len(future))\n",
|
| 225 |
+
"\n",
|
| 226 |
+
" # Plot history and ground truth future\n",
|
| 227 |
+
" ax.plot(hist_t, history, label=\"History\", color=\"black\")\n",
|
| 228 |
+
" ax.plot(fut_t, future, label=\"Ground Truth\", color=\"blue\")\n",
|
| 229 |
+
"\n",
|
| 230 |
+
" # Plot quantiles\n",
|
| 231 |
+
" median_idx = num_quantiles // 2\n",
|
| 232 |
+
" ax.plot(\n",
|
| 233 |
+
" fut_t,\n",
|
| 234 |
+
" preds_np[i, :, 0, median_idx],\n",
|
| 235 |
+
" label=\"Prediction (Median)\",\n",
|
| 236 |
+
" color=\"orange\",\n",
|
| 237 |
+
" linestyle=\"--\",\n",
|
| 238 |
+
" )\n",
|
| 239 |
+
" if num_quantiles >= 3:\n",
|
| 240 |
+
" ax.fill_between(\n",
|
| 241 |
+
" fut_t,\n",
|
| 242 |
+
" preds_np[i, :, 0, 0],\n",
|
| 243 |
+
" preds_np[i, :, 0, -1],\n",
|
| 244 |
+
" color=\"orange\",\n",
|
| 245 |
+
" alpha=0.2,\n",
|
| 246 |
+
" label=\"Prediction Interval\",\n",
|
| 247 |
+
" )\n",
|
| 248 |
+
"\n",
|
| 249 |
+
" ax.axvline(x=len(history), color=\"k\", linestyle=\":\", alpha=0.7)\n",
|
| 250 |
+
" ax.set_xlabel(\"Time Steps\")\n",
|
| 251 |
+
" ax.set_ylabel(\"Value\")\n",
|
| 252 |
+
" ax.set.title(f\"Sample {i + 1}\")\n",
|
| 253 |
+
" ax.legend()\n",
|
| 254 |
+
" ax.grid(True, alpha=0.3)\n",
|
| 255 |
+
" plt.show()"
|
| 256 |
+
]
|
| 257 |
+
}
|
| 258 |
+
],
|
| 259 |
+
"metadata": {
|
| 260 |
+
"kernelspec": {
|
| 261 |
+
"display_name": "Python 3 (ipykernel)",
|
| 262 |
+
"language": "python",
|
| 263 |
+
"name": "python3"
|
| 264 |
+
},
|
| 265 |
+
"language_info": {
|
| 266 |
+
"codemirror_mode": {
|
| 267 |
+
"name": "ipython",
|
| 268 |
+
"version": 3
|
| 269 |
+
},
|
| 270 |
+
"file_extension": ".py",
|
| 271 |
+
"mimetype": "text/x-python",
|
| 272 |
+
"name": "python",
|
| 273 |
+
"nbconvert_exporter": "python",
|
| 274 |
+
"pygments_lexer": "ipython3",
|
| 275 |
+
"version": "3.12.9"
|
| 276 |
+
}
|
| 277 |
+
},
|
| 278 |
+
"nbformat": 4,
|
| 279 |
+
"nbformat_minor": 5
|
| 280 |
+
}
|
examples/quick_start_tempo_pfn.py
ADDED
|
@@ -0,0 +1,101 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import logging
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
|
| 7 |
+
from examples.utils import (
|
| 8 |
+
load_model,
|
| 9 |
+
run_inference_and_plot,
|
| 10 |
+
)
|
| 11 |
+
from src.data.containers import BatchTimeSeriesContainer
|
| 12 |
+
from src.synthetic_generation.generator_params import SineWaveGeneratorParams
|
| 13 |
+
from src.synthetic_generation.sine_waves.sine_wave_generator_wrapper import (
|
| 14 |
+
SineWaveGeneratorWrapper,
|
| 15 |
+
)
|
| 16 |
+
|
| 17 |
+
# Configure logging
|
| 18 |
+
logging.basicConfig(
|
| 19 |
+
level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s"
|
| 20 |
+
)
|
| 21 |
+
logger = logging.getLogger(__name__)
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def main():
|
| 25 |
+
"""Main execution function."""
|
| 26 |
+
# CLI
|
| 27 |
+
parser = argparse.ArgumentParser(description="Quick start demo for TimeSeriesModel")
|
| 28 |
+
parser.add_argument(
|
| 29 |
+
"--config",
|
| 30 |
+
default="configs/example.yaml",
|
| 31 |
+
help="Path to model config YAML (default: configs/example.yaml)",
|
| 32 |
+
)
|
| 33 |
+
parser.add_argument(
|
| 34 |
+
"--checkpoint",
|
| 35 |
+
default="models/checkpoint_38M.pth",
|
| 36 |
+
help="Path to model checkpoint file (default: models/checkpoint_38M.pth)",
|
| 37 |
+
)
|
| 38 |
+
parser.add_argument("--batch_size", type=int, default=3)
|
| 39 |
+
parser.add_argument("--total_length", type=int, default=2048)
|
| 40 |
+
parser.add_argument("--seed", type=int, default=42)
|
| 41 |
+
parser.add_argument("--output_dir", default="outputs")
|
| 42 |
+
args = parser.parse_args()
|
| 43 |
+
|
| 44 |
+
# Configuration
|
| 45 |
+
batch_size = args.batch_size
|
| 46 |
+
total_length = args.total_length
|
| 47 |
+
output_dir = args.output_dir
|
| 48 |
+
seed = args.seed
|
| 49 |
+
config_path = args.config
|
| 50 |
+
model_path = args.checkpoint
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
# Check if the checkpoint file exists
|
| 54 |
+
if not os.path.exists(model_path):
|
| 55 |
+
logger.error(f"Checkpoint file not found at: {model_path}")
|
| 56 |
+
logger.error(
|
| 57 |
+
"Please ensure 'checkpoint_38M.pth' is in the root directory"
|
| 58 |
+
" (or that you've cloned the repo with Git LFS)."
|
| 59 |
+
)
|
| 60 |
+
logger.error("You can also specify a different path using --checkpoint.")
|
| 61 |
+
return # Exit if no model
|
| 62 |
+
|
| 63 |
+
logger.info("=== Time Series Model Demo (Univariate Quantile) ===")
|
| 64 |
+
|
| 65 |
+
# 1) Generate synthetic sine wave data
|
| 66 |
+
sine_params = SineWaveGeneratorParams(global_seed=seed, length=total_length)
|
| 67 |
+
sine_generator = SineWaveGeneratorWrapper(sine_params)
|
| 68 |
+
batch = sine_generator.generate_batch(batch_size=batch_size, seed=seed)
|
| 69 |
+
values = torch.from_numpy(batch.values).to(torch.float32)
|
| 70 |
+
if values.ndim == 2:
|
| 71 |
+
values = values.unsqueeze(-1) # Ensure [B, S, 1] for univariate
|
| 72 |
+
future_length = 256
|
| 73 |
+
history_values = values[:, :-future_length, :]
|
| 74 |
+
future_values = values[:, -future_length:, :]
|
| 75 |
+
|
| 76 |
+
# 2) Load the pretrained model (CUDA-only). This demo requires a CUDA GPU.
|
| 77 |
+
if not torch.cuda.is_available():
|
| 78 |
+
raise RuntimeError(
|
| 79 |
+
"CUDA is required to run this demo. No CUDA device detected."
|
| 80 |
+
)
|
| 81 |
+
device = torch.device("cuda:0")
|
| 82 |
+
model = load_model(config_path=config_path, model_path=model_path, device=device)
|
| 83 |
+
|
| 84 |
+
# 3) Pack tensors into the model's input container
|
| 85 |
+
container = BatchTimeSeriesContainer(
|
| 86 |
+
history_values=history_values.to(device),
|
| 87 |
+
future_values=future_values.to(device),
|
| 88 |
+
start=batch.start,
|
| 89 |
+
frequency=batch.frequency,
|
| 90 |
+
)
|
| 91 |
+
|
| 92 |
+
# 4) Run inference (bfloat16 on CUDA) and plot results
|
| 93 |
+
run_inference_and_plot(
|
| 94 |
+
model=model, container=container, output_dir=output_dir, use_bfloat16=True
|
| 95 |
+
)
|
| 96 |
+
|
| 97 |
+
logger.info("=== Demo completed successfully! ===")
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
if __name__ == "__main__":
|
| 101 |
+
main()
|
examples/utils.py
ADDED
|
@@ -0,0 +1,115 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import os
|
| 3 |
+
import urllib.request
|
| 4 |
+
from typing import List
|
| 5 |
+
|
| 6 |
+
import numpy as np
|
| 7 |
+
import torch
|
| 8 |
+
import yaml
|
| 9 |
+
|
| 10 |
+
from src.data.containers import BatchTimeSeriesContainer
|
| 11 |
+
from src.models.model import TimeSeriesModel
|
| 12 |
+
from src.plotting.plot_timeseries import plot_from_container
|
| 13 |
+
|
| 14 |
+
logger = logging.getLogger(__name__)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def load_model(
|
| 18 |
+
config_path: str, model_path: str, device: torch.device
|
| 19 |
+
) -> TimeSeriesModel:
|
| 20 |
+
"""Load the TimeSeriesModel from config and checkpoint."""
|
| 21 |
+
with open(config_path, "r") as f:
|
| 22 |
+
config = yaml.safe_load(f)
|
| 23 |
+
|
| 24 |
+
model = TimeSeriesModel(**config["TimeSeriesModel"]).to(device)
|
| 25 |
+
checkpoint = torch.load(model_path, map_location=device)
|
| 26 |
+
model.load_state_dict(checkpoint["model_state_dict"])
|
| 27 |
+
model.eval()
|
| 28 |
+
logger.info(f"Successfully loaded TimeSeriesModel from {model_path} on {device}")
|
| 29 |
+
return model
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def download_checkpoint_if_needed(url: str, target_dir: str = "models") -> str:
|
| 33 |
+
"""Download checkpoint from URL into target_dir if not present and return its path.
|
| 34 |
+
|
| 35 |
+
Ensures direct download for Dropbox links by forcing dl=1.
|
| 36 |
+
"""
|
| 37 |
+
os.makedirs(target_dir, exist_ok=True)
|
| 38 |
+
target_path = os.path.join(target_dir, "checkpoint.pth")
|
| 39 |
+
|
| 40 |
+
# Normalize Dropbox URL to force direct download
|
| 41 |
+
if "dropbox.com" in url and "dl=0" in url:
|
| 42 |
+
url = url.replace("dl=0", "dl=1")
|
| 43 |
+
|
| 44 |
+
if not os.path.exists(target_path):
|
| 45 |
+
logger.info(f"Downloading checkpoint from {url} to {target_path}...")
|
| 46 |
+
urllib.request.urlretrieve(url, target_path)
|
| 47 |
+
logger.info("Checkpoint downloaded successfully.")
|
| 48 |
+
else:
|
| 49 |
+
logger.info(f"Using existing checkpoint at {target_path}")
|
| 50 |
+
|
| 51 |
+
return target_path
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def plot_with_library(
|
| 55 |
+
container: BatchTimeSeriesContainer,
|
| 56 |
+
predictions_np: np.ndarray, # [B, P, N, Q]
|
| 57 |
+
model_quantiles: List[float] | None,
|
| 58 |
+
output_dir: str = "outputs",
|
| 59 |
+
show_plots: bool = True,
|
| 60 |
+
save_plots: bool = True,
|
| 61 |
+
):
|
| 62 |
+
os.makedirs(output_dir, exist_ok=True)
|
| 63 |
+
batch_size = container.batch_size
|
| 64 |
+
for i in range(batch_size):
|
| 65 |
+
output_file = (
|
| 66 |
+
os.path.join(output_dir, f"sine_wave_prediction_sample_{i + 1}.png")
|
| 67 |
+
if save_plots
|
| 68 |
+
else None
|
| 69 |
+
)
|
| 70 |
+
plot_from_container(
|
| 71 |
+
batch=container,
|
| 72 |
+
sample_idx=i,
|
| 73 |
+
predicted_values=predictions_np,
|
| 74 |
+
model_quantiles=model_quantiles,
|
| 75 |
+
title=f"Sine Wave Time Series Prediction - Sample {i + 1}",
|
| 76 |
+
output_file=output_file,
|
| 77 |
+
show=show_plots,
|
| 78 |
+
)
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
def run_inference_and_plot(
|
| 82 |
+
model: TimeSeriesModel,
|
| 83 |
+
container: BatchTimeSeriesContainer,
|
| 84 |
+
output_dir: str = "outputs",
|
| 85 |
+
use_bfloat16: bool = True,
|
| 86 |
+
) -> None:
|
| 87 |
+
"""Run model inference with optional bfloat16 and plot using shared utilities."""
|
| 88 |
+
device_type = "cuda" if (container.history_values.device.type == "cuda") else "cpu"
|
| 89 |
+
autocast_enabled = use_bfloat16 and device_type == "cuda"
|
| 90 |
+
with (
|
| 91 |
+
torch.no_grad(),
|
| 92 |
+
torch.autocast(
|
| 93 |
+
device_type=device_type, dtype=torch.bfloat16, enabled=autocast_enabled
|
| 94 |
+
),
|
| 95 |
+
):
|
| 96 |
+
model_output = model(container)
|
| 97 |
+
|
| 98 |
+
preds_full = model_output["result"].to(torch.float32)
|
| 99 |
+
if hasattr(model, "scaler") and "scale_statistics" in model_output:
|
| 100 |
+
preds_full = model.scaler.inverse_scale(
|
| 101 |
+
preds_full, model_output["scale_statistics"]
|
| 102 |
+
)
|
| 103 |
+
|
| 104 |
+
preds_np = preds_full.detach().cpu().numpy()
|
| 105 |
+
model_quantiles = (
|
| 106 |
+
model.quantiles if getattr(model, "loss_type", None) == "quantile" else None
|
| 107 |
+
)
|
| 108 |
+
plot_with_library(
|
| 109 |
+
container=container,
|
| 110 |
+
predictions_np=preds_np,
|
| 111 |
+
model_quantiles=model_quantiles,
|
| 112 |
+
output_dir=output_dir,
|
| 113 |
+
show_plots=True,
|
| 114 |
+
save_plots=True,
|
| 115 |
+
)
|
gitignore
ADDED
|
@@ -0,0 +1,167 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
logs/
|
| 2 |
+
*.png
|
| 3 |
+
*.pth
|
| 4 |
+
# *.sh
|
| 5 |
+
*.slurm
|
| 6 |
+
*.pkl
|
| 7 |
+
|
| 8 |
+
wandb/
|
| 9 |
+
AutogluonModels/
|
| 10 |
+
.vscode/
|
| 11 |
+
|
| 12 |
+
# Byte-compiled / optimized / DLL files
|
| 13 |
+
__pycache__/
|
| 14 |
+
*.py[cod]
|
| 15 |
+
*$py.class
|
| 16 |
+
|
| 17 |
+
# C extensions
|
| 18 |
+
*.so
|
| 19 |
+
|
| 20 |
+
# Distribution / packaging
|
| 21 |
+
.Python
|
| 22 |
+
build/
|
| 23 |
+
develop-eggs/
|
| 24 |
+
dist/
|
| 25 |
+
downloads/
|
| 26 |
+
eggs/
|
| 27 |
+
.eggs/
|
| 28 |
+
lib/
|
| 29 |
+
lib64/
|
| 30 |
+
parts/
|
| 31 |
+
sdist/
|
| 32 |
+
var/
|
| 33 |
+
wheels/
|
| 34 |
+
share/python-wheels/
|
| 35 |
+
*.egg-info/
|
| 36 |
+
.installed.cfg
|
| 37 |
+
*.egg
|
| 38 |
+
MANIFEST
|
| 39 |
+
|
| 40 |
+
# PyInstaller
|
| 41 |
+
# Usually these files are written by a python script from a template
|
| 42 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 43 |
+
*.manifest
|
| 44 |
+
*.spec
|
| 45 |
+
|
| 46 |
+
# Installer logs
|
| 47 |
+
pip-log.txt
|
| 48 |
+
pip-delete-this-directory.txt
|
| 49 |
+
|
| 50 |
+
# Unit test / coverage reports
|
| 51 |
+
htmlcov/
|
| 52 |
+
.tox/
|
| 53 |
+
.nox/
|
| 54 |
+
.coverage
|
| 55 |
+
.coverage.*
|
| 56 |
+
.cache
|
| 57 |
+
nosetests.xml
|
| 58 |
+
coverage.xml
|
| 59 |
+
*.cover
|
| 60 |
+
*.py,cover
|
| 61 |
+
.hypothesis/
|
| 62 |
+
.pytest_cache/
|
| 63 |
+
cover/
|
| 64 |
+
|
| 65 |
+
# PyBuilder
|
| 66 |
+
.pybuilder/
|
| 67 |
+
target/
|
| 68 |
+
|
| 69 |
+
# Jupyter Notebook
|
| 70 |
+
.ipynb_checkpoints
|
| 71 |
+
|
| 72 |
+
# IPython
|
| 73 |
+
profile_default/
|
| 74 |
+
ipython_config.py
|
| 75 |
+
|
| 76 |
+
# pyenv
|
| 77 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 78 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 79 |
+
# .python-version
|
| 80 |
+
|
| 81 |
+
# pipenv
|
| 82 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 83 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 84 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 85 |
+
# install all needed dependencies.
|
| 86 |
+
#Pipfile.lock
|
| 87 |
+
|
| 88 |
+
# UV
|
| 89 |
+
# Similar to Pipfile.lock, it is generally recommended to include uv.lock in version control.
|
| 90 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 91 |
+
# commonly ignored for libraries.
|
| 92 |
+
#uv.lock
|
| 93 |
+
|
| 94 |
+
# poetry
|
| 95 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 96 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 97 |
+
# commonly ignored for libraries.
|
| 98 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 99 |
+
#poetry.lock
|
| 100 |
+
|
| 101 |
+
# pdm
|
| 102 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 103 |
+
#pdm.lock
|
| 104 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 105 |
+
# in version control.
|
| 106 |
+
# https://pdm.fming.dev/latest/usage/project/#working-with-version-control
|
| 107 |
+
.pdm.toml
|
| 108 |
+
.pdm-python
|
| 109 |
+
.pdm-build/
|
| 110 |
+
|
| 111 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 112 |
+
__pypackages__/
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
# SageMath parsed files
|
| 116 |
+
*.sage.py
|
| 117 |
+
|
| 118 |
+
# Environments
|
| 119 |
+
.env
|
| 120 |
+
.venv
|
| 121 |
+
env/
|
| 122 |
+
venv/
|
| 123 |
+
ENV/
|
| 124 |
+
env.bak/
|
| 125 |
+
venv.bak/
|
| 126 |
+
|
| 127 |
+
# Spyder project settings
|
| 128 |
+
.spyderproject
|
| 129 |
+
.spyproject
|
| 130 |
+
|
| 131 |
+
# Rope project settings
|
| 132 |
+
.ropeproject
|
| 133 |
+
|
| 134 |
+
# mkdocs documentation
|
| 135 |
+
/site
|
| 136 |
+
|
| 137 |
+
# mypy
|
| 138 |
+
.mypy_cache/
|
| 139 |
+
.dmypy.json
|
| 140 |
+
dmypy.json
|
| 141 |
+
|
| 142 |
+
# Pyre type checker
|
| 143 |
+
.pyre/
|
| 144 |
+
|
| 145 |
+
# pytype static type analyzer
|
| 146 |
+
.pytype/
|
| 147 |
+
|
| 148 |
+
# Cython debug symbols
|
| 149 |
+
cython_debug/
|
| 150 |
+
|
| 151 |
+
.idea/
|
| 152 |
+
|
| 153 |
+
# Ruff stuff:
|
| 154 |
+
.ruff_cache/
|
| 155 |
+
|
| 156 |
+
# PyPI configuration file
|
| 157 |
+
.pypirc
|
| 158 |
+
|
| 159 |
+
# Datasets, logs, plots, etc.
|
| 160 |
+
outputs/
|
| 161 |
+
|
| 162 |
+
*.arrow
|
| 163 |
+
*.csv
|
| 164 |
+
*.png
|
| 165 |
+
*.pdf
|
| 166 |
+
*.gif
|
| 167 |
+
.DS_Store
|
models/checkpoint_38M.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a520c07e6f4dc6583b25a7129251c81eef15f168003766adf6ae4983db7b575b
|
| 3 |
+
size 498752361
|
pyproject.toml
ADDED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[project]
|
| 2 |
+
name = "TempoPFN"
|
| 3 |
+
version = "0.1.0"
|
| 4 |
+
description = "Univariate Time Series Forecasting Using Linear RNNs"
|
| 5 |
+
authors = [
|
| 6 |
+
{ name = "Vladyslav Moroshan" },
|
| 7 |
+
{ name = "Julien Siems" },
|
| 8 |
+
]
|
| 9 |
+
readme = "README.md"
|
| 10 |
+
license = { file = "LICENSE" }
|
| 11 |
+
requires-python = ">=3.10,<3.13"
|
| 12 |
+
|
| 13 |
+
dependencies = [
|
| 14 |
+
"torch>=2.5.0",
|
| 15 |
+
"torchmetrics",
|
| 16 |
+
"triton==3.2.0",
|
| 17 |
+
"numpy",
|
| 18 |
+
"pandas",
|
| 19 |
+
"matplotlib",
|
| 20 |
+
"gpytorch",
|
| 21 |
+
"flash-linear-attention @ git+https://github.com/fla-org/flash-linear-attention@main",
|
| 22 |
+
"scikit-learn",
|
| 23 |
+
"gluonts",
|
| 24 |
+
"notebook",
|
| 25 |
+
"datasets",
|
| 26 |
+
"ujson",
|
| 27 |
+
]
|
| 28 |
+
|
| 29 |
+
classifiers = [
|
| 30 |
+
"Intended Audience :: Science/Research",
|
| 31 |
+
"Intended Audience :: Developers",
|
| 32 |
+
"License :: OSI Approved :: Apache Software License",
|
| 33 |
+
"Programming Language :: Python",
|
| 34 |
+
"Topic :: Software Development",
|
| 35 |
+
"Topic :: Scientific/Engineering",
|
| 36 |
+
"Operating System :: POSIX",
|
| 37 |
+
"Operating System :: Unix",
|
| 38 |
+
"Operating System :: MacOS",
|
| 39 |
+
"Programming Language :: Python :: 3.9",
|
| 40 |
+
"Programming Language :: Python :: 3.10",
|
| 41 |
+
"Programming Language :: Python :: 3.11",
|
| 42 |
+
]
|
| 43 |
+
|
| 44 |
+
[project.optional-dependencies]
|
| 45 |
+
dev = [
|
| 46 |
+
"wandb",
|
| 47 |
+
"build",
|
| 48 |
+
"pre-commit",
|
| 49 |
+
"ruff",
|
| 50 |
+
"mypy",
|
| 51 |
+
"commitizen",
|
| 52 |
+
"black",
|
| 53 |
+
"cupy-cuda12x",
|
| 54 |
+
"statsmodels",
|
| 55 |
+
"pyo", # Requires portaudio
|
| 56 |
+
]
|
| 57 |
+
|
| 58 |
+
[build-system]
|
| 59 |
+
requires = ["setuptools>=68.2.2", "wheel>=0.41.2"]
|
| 60 |
+
build-backend = "setuptools.build_meta"
|
| 61 |
+
|
| 62 |
+
package-dir = {"" = "src"}
|
requirements.txt
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 'torch' must be installed separately first, using the command
|
| 2 |
+
# from the README.md to match your specific CUDA version.
|
| 3 |
+
|
| 4 |
+
torchmetrics
|
| 5 |
+
triton==3.2.0
|
| 6 |
+
numpy
|
| 7 |
+
pandas
|
| 8 |
+
matplotlib
|
| 9 |
+
flash-linear-attention @ git+https://github.com/fla-org/flash-linear-attention@main
|
| 10 |
+
scikit-learn
|
| 11 |
+
gluonts
|
| 12 |
+
notebook
|
| 13 |
+
datasets
|
| 14 |
+
ujson
|
| 15 |
+
pyyaml
|
| 16 |
+
wandb
|
| 17 |
+
build
|
| 18 |
+
pre-commit
|
| 19 |
+
ruff
|
| 20 |
+
mypy
|
| 21 |
+
commitizen
|
| 22 |
+
black
|
| 23 |
+
cupy-cuda12x
|
| 24 |
+
statsmodels
|
| 25 |
+
pyo # Requires portaudio
|
src/__init__.py
ADDED
|
File without changes
|
src/data/__init__.py
ADDED
|
File without changes
|
src/data/augmentations.py
ADDED
|
@@ -0,0 +1,1318 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import math
|
| 3 |
+
from collections import Counter
|
| 4 |
+
from pathlib import Path
|
| 5 |
+
from typing import Dict, List, Optional, Tuple
|
| 6 |
+
|
| 7 |
+
import numpy as np
|
| 8 |
+
import torch
|
| 9 |
+
import torch.nn as nn
|
| 10 |
+
from joblib import Parallel, delayed
|
| 11 |
+
from torch.quasirandom import SobolEngine
|
| 12 |
+
import torch.nn.functional as F
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
from src.gift_eval.data import Dataset
|
| 16 |
+
|
| 17 |
+
logger = logging.getLogger(__name__)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def find_consecutive_nan_lengths(series: np.ndarray) -> list[int]:
|
| 21 |
+
"""Finds the lengths of all consecutive NaN blocks in a 1D array."""
|
| 22 |
+
if series.ndim > 1:
|
| 23 |
+
# For multivariate series, flatten to treat it as one long sequence
|
| 24 |
+
series = series.flatten()
|
| 25 |
+
|
| 26 |
+
is_nan = np.isnan(series)
|
| 27 |
+
padded_is_nan = np.concatenate(([False], is_nan, [False]))
|
| 28 |
+
diffs = np.diff(padded_is_nan.astype(int))
|
| 29 |
+
|
| 30 |
+
start_indices = np.where(diffs == 1)[0]
|
| 31 |
+
end_indices = np.where(diffs == -1)[0]
|
| 32 |
+
|
| 33 |
+
return (end_indices - start_indices).tolist()
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def analyze_datasets_for_augmentation(gift_eval_path_str: str) -> dict:
|
| 37 |
+
"""
|
| 38 |
+
Analyzes all datasets to derive statistics needed for NaN augmentation.
|
| 39 |
+
This version collects the full distribution of NaN ratios.
|
| 40 |
+
"""
|
| 41 |
+
logger.info(
|
| 42 |
+
"--- Starting Dataset Analysis for Augmentation (Full Distribution) ---"
|
| 43 |
+
)
|
| 44 |
+
path = Path(gift_eval_path_str)
|
| 45 |
+
if not path.exists():
|
| 46 |
+
raise FileNotFoundError(
|
| 47 |
+
f"Provided raw data path for augmentation analysis does not exist: {gift_eval_path_str}"
|
| 48 |
+
)
|
| 49 |
+
|
| 50 |
+
dataset_names = []
|
| 51 |
+
for dataset_dir in path.iterdir():
|
| 52 |
+
if dataset_dir.name.startswith(".") or not dataset_dir.is_dir():
|
| 53 |
+
continue
|
| 54 |
+
freq_dirs = [d for d in dataset_dir.iterdir() if d.is_dir()]
|
| 55 |
+
if freq_dirs:
|
| 56 |
+
for freq_dir in freq_dirs:
|
| 57 |
+
dataset_names.append(f"{dataset_dir.name}/{freq_dir.name}")
|
| 58 |
+
else:
|
| 59 |
+
dataset_names.append(dataset_dir.name)
|
| 60 |
+
|
| 61 |
+
total_series_count = 0
|
| 62 |
+
series_with_nans_count = 0
|
| 63 |
+
nan_ratio_distribution = []
|
| 64 |
+
all_consecutive_nan_lengths = Counter()
|
| 65 |
+
|
| 66 |
+
for ds_name in sorted(dataset_names):
|
| 67 |
+
try:
|
| 68 |
+
ds = Dataset(name=ds_name, term="short", to_univariate=False)
|
| 69 |
+
for series_data in ds.training_dataset:
|
| 70 |
+
total_series_count += 1
|
| 71 |
+
target = np.atleast_1d(series_data["target"])
|
| 72 |
+
num_nans = np.isnan(target).sum()
|
| 73 |
+
|
| 74 |
+
if num_nans > 0:
|
| 75 |
+
series_with_nans_count += 1
|
| 76 |
+
nan_ratio = num_nans / target.size
|
| 77 |
+
nan_ratio_distribution.append(float(nan_ratio))
|
| 78 |
+
|
| 79 |
+
nan_lengths = find_consecutive_nan_lengths(target)
|
| 80 |
+
all_consecutive_nan_lengths.update(nan_lengths)
|
| 81 |
+
except Exception as e:
|
| 82 |
+
logger.warning(
|
| 83 |
+
f"Could not process {ds_name} for augmentation analysis: {e}"
|
| 84 |
+
)
|
| 85 |
+
|
| 86 |
+
if total_series_count == 0:
|
| 87 |
+
raise ValueError(
|
| 88 |
+
"No series were found during augmentation analysis. Check dataset path."
|
| 89 |
+
)
|
| 90 |
+
|
| 91 |
+
p_series_has_nan = (
|
| 92 |
+
series_with_nans_count / total_series_count if total_series_count > 0 else 0
|
| 93 |
+
)
|
| 94 |
+
|
| 95 |
+
logger.info("--- Augmentation Analysis Complete ---")
|
| 96 |
+
# Print summary statistics
|
| 97 |
+
logger.info(f"Total series analyzed: {total_series_count}")
|
| 98 |
+
logger.info(f"Series with NaNs: {series_with_nans_count} ({p_series_has_nan:.4f})")
|
| 99 |
+
logger.info(f"NaN ratio distribution: {Counter(nan_ratio_distribution)}")
|
| 100 |
+
logger.info(f"Consecutive NaN lengths distribution: {all_consecutive_nan_lengths}")
|
| 101 |
+
logger.info("--- End of Dataset Analysis for Augmentation ---")
|
| 102 |
+
return {
|
| 103 |
+
"p_series_has_nan": p_series_has_nan,
|
| 104 |
+
"nan_ratio_distribution": nan_ratio_distribution,
|
| 105 |
+
"nan_length_distribution": all_consecutive_nan_lengths,
|
| 106 |
+
}
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
class NanAugmenter:
|
| 110 |
+
"""
|
| 111 |
+
Applies realistic NaN augmentation by generating and caching NaN patterns on-demand
|
| 112 |
+
during the first transform call for a given data shape.
|
| 113 |
+
"""
|
| 114 |
+
|
| 115 |
+
def __init__(
|
| 116 |
+
self,
|
| 117 |
+
p_series_has_nan: float,
|
| 118 |
+
nan_ratio_distribution: List[float],
|
| 119 |
+
nan_length_distribution: Counter,
|
| 120 |
+
num_patterns: int = 100000,
|
| 121 |
+
n_jobs: int = -1,
|
| 122 |
+
nan_patterns_path: Optional[str] = None,
|
| 123 |
+
):
|
| 124 |
+
"""
|
| 125 |
+
Initializes the augmenter. NaN patterns are not generated at this stage.
|
| 126 |
+
|
| 127 |
+
Args:
|
| 128 |
+
p_series_has_nan (float): Probability that a series in a batch will be augmented.
|
| 129 |
+
nan_ratio_distribution (List[float]): A list of NaN ratios observed in the dataset.
|
| 130 |
+
nan_length_distribution (Counter): A Counter of consecutive NaN block lengths.
|
| 131 |
+
num_patterns (int): The number of unique NaN patterns to generate per data shape.
|
| 132 |
+
n_jobs (int): The number of CPU cores to use for parallel pattern generation (-1 for all cores).
|
| 133 |
+
"""
|
| 134 |
+
self.p_series_has_nan = p_series_has_nan
|
| 135 |
+
self.nan_ratio_distribution = nan_ratio_distribution
|
| 136 |
+
self.num_patterns = num_patterns
|
| 137 |
+
self.n_jobs = n_jobs
|
| 138 |
+
self.max_length = 2048
|
| 139 |
+
self.nan_patterns_path = nan_patterns_path
|
| 140 |
+
# Cache to store patterns: Dict[shape_tuple -> pattern_tensor]
|
| 141 |
+
self.pattern_cache: Dict[Tuple[int, ...], torch.BoolTensor] = {}
|
| 142 |
+
|
| 143 |
+
if not nan_length_distribution or sum(nan_length_distribution.values()) == 0:
|
| 144 |
+
self._has_block_distribution = False
|
| 145 |
+
logger.warning("NaN length distribution is empty. Augmentation disabled.")
|
| 146 |
+
else:
|
| 147 |
+
self._has_block_distribution = True
|
| 148 |
+
total_blocks = sum(nan_length_distribution.values())
|
| 149 |
+
self.dist_lengths = list(int(i) for i in nan_length_distribution.keys())
|
| 150 |
+
self.dist_probs = [
|
| 151 |
+
count / total_blocks for count in nan_length_distribution.values()
|
| 152 |
+
]
|
| 153 |
+
|
| 154 |
+
if not self.nan_ratio_distribution:
|
| 155 |
+
logger.warning("NaN ratio distribution is empty. Augmentation disabled.")
|
| 156 |
+
|
| 157 |
+
# Try to load existing patterns from disk
|
| 158 |
+
self._load_existing_patterns()
|
| 159 |
+
|
| 160 |
+
def _load_existing_patterns(self):
|
| 161 |
+
"""Load existing NaN patterns from disk if they exist."""
|
| 162 |
+
# Determine where to look for patterns
|
| 163 |
+
explicit_path: Optional[Path] = (
|
| 164 |
+
Path(self.nan_patterns_path).resolve()
|
| 165 |
+
if self.nan_patterns_path is not None
|
| 166 |
+
else None
|
| 167 |
+
)
|
| 168 |
+
|
| 169 |
+
candidate_files: List[Path] = []
|
| 170 |
+
if explicit_path is not None:
|
| 171 |
+
# If the explicit path exists, use it directly
|
| 172 |
+
if explicit_path.is_file():
|
| 173 |
+
candidate_files.append(explicit_path)
|
| 174 |
+
# Also search the directory of the explicit path for matching files
|
| 175 |
+
explicit_dir = explicit_path.parent
|
| 176 |
+
explicit_dir.mkdir(exist_ok=True, parents=True)
|
| 177 |
+
candidate_files.extend(
|
| 178 |
+
list(explicit_dir.glob(f"nan_patterns_{self.max_length}_*.pt"))
|
| 179 |
+
)
|
| 180 |
+
else:
|
| 181 |
+
# Default to the ./data directory
|
| 182 |
+
data_dir = Path("data")
|
| 183 |
+
data_dir.mkdir(exist_ok=True)
|
| 184 |
+
candidate_files.extend(
|
| 185 |
+
list(data_dir.glob(f"nan_patterns_{self.max_length}_*.pt"))
|
| 186 |
+
)
|
| 187 |
+
|
| 188 |
+
# De-duplicate candidate files while preserving order
|
| 189 |
+
seen: set[str] = set()
|
| 190 |
+
unique_candidates: List[Path] = []
|
| 191 |
+
for f in candidate_files:
|
| 192 |
+
key = str(f.resolve())
|
| 193 |
+
if key not in seen:
|
| 194 |
+
seen.add(key)
|
| 195 |
+
unique_candidates.append(f)
|
| 196 |
+
|
| 197 |
+
for pattern_file in unique_candidates:
|
| 198 |
+
try:
|
| 199 |
+
# Extract num_channels from filename
|
| 200 |
+
filename = pattern_file.stem
|
| 201 |
+
parts = filename.split("_")
|
| 202 |
+
if len(parts) >= 4:
|
| 203 |
+
num_channels = int(parts[-1])
|
| 204 |
+
|
| 205 |
+
# Load patterns
|
| 206 |
+
patterns = torch.load(pattern_file, map_location="cpu")
|
| 207 |
+
cache_key = (self.max_length, num_channels)
|
| 208 |
+
self.pattern_cache[cache_key] = patterns
|
| 209 |
+
|
| 210 |
+
logger.info(
|
| 211 |
+
f"Loaded {patterns.shape[0]} patterns for shape {cache_key} from {pattern_file}"
|
| 212 |
+
)
|
| 213 |
+
except (ValueError, RuntimeError, FileNotFoundError) as e:
|
| 214 |
+
logger.warning(f"Failed to load patterns from {pattern_file}: {e}")
|
| 215 |
+
|
| 216 |
+
def _get_pattern_file_path(self, num_channels: int) -> Path:
|
| 217 |
+
"""Resolve the target file path for storing/loading patterns for a given channel count."""
|
| 218 |
+
# If user provided a file path, use its directory as the base directory
|
| 219 |
+
if self.nan_patterns_path is not None:
|
| 220 |
+
base_dir = Path(self.nan_patterns_path).resolve().parent
|
| 221 |
+
base_dir.mkdir(exist_ok=True, parents=True)
|
| 222 |
+
else:
|
| 223 |
+
base_dir = Path("data").resolve()
|
| 224 |
+
base_dir.mkdir(exist_ok=True, parents=True)
|
| 225 |
+
|
| 226 |
+
return base_dir / f"nan_patterns_{self.max_length}_{num_channels}.pt"
|
| 227 |
+
|
| 228 |
+
def _generate_nan_mask(self, series_shape: Tuple[int, ...]) -> np.ndarray:
|
| 229 |
+
"""Generates a single boolean NaN mask for a given series shape."""
|
| 230 |
+
series_size = int(np.prod(series_shape))
|
| 231 |
+
sampled_ratio = np.random.choice(self.nan_ratio_distribution)
|
| 232 |
+
n_nans_to_add = int(round(series_size * sampled_ratio))
|
| 233 |
+
|
| 234 |
+
if n_nans_to_add == 0:
|
| 235 |
+
return np.zeros(series_shape, dtype=bool)
|
| 236 |
+
|
| 237 |
+
mask_flat = np.zeros(series_size, dtype=bool)
|
| 238 |
+
nans_added = 0
|
| 239 |
+
max_attempts = n_nans_to_add * 2
|
| 240 |
+
attempts = 0
|
| 241 |
+
while nans_added < n_nans_to_add and attempts < max_attempts:
|
| 242 |
+
attempts += 1
|
| 243 |
+
block_length = np.random.choice(self.dist_lengths, p=self.dist_probs)
|
| 244 |
+
|
| 245 |
+
if nans_added + block_length > n_nans_to_add:
|
| 246 |
+
block_length = n_nans_to_add - nans_added
|
| 247 |
+
if block_length <= 0:
|
| 248 |
+
break
|
| 249 |
+
|
| 250 |
+
nan_counts_in_window = np.convolve(
|
| 251 |
+
mask_flat, np.ones(block_length), mode="valid"
|
| 252 |
+
)
|
| 253 |
+
valid_starts = np.where(nan_counts_in_window == 0)[0]
|
| 254 |
+
|
| 255 |
+
if valid_starts.size == 0:
|
| 256 |
+
continue
|
| 257 |
+
|
| 258 |
+
start_pos = np.random.choice(valid_starts)
|
| 259 |
+
mask_flat[start_pos : start_pos + block_length] = True
|
| 260 |
+
nans_added += block_length
|
| 261 |
+
|
| 262 |
+
return mask_flat.reshape(series_shape)
|
| 263 |
+
|
| 264 |
+
def _pregenerate_patterns(self, series_shape: Tuple[int, ...]) -> torch.BoolTensor:
|
| 265 |
+
"""Uses joblib to parallelize the generation of NaN masks for a given shape."""
|
| 266 |
+
if not self._has_block_distribution or not self.nan_ratio_distribution:
|
| 267 |
+
return torch.empty(0, *series_shape, dtype=torch.bool)
|
| 268 |
+
|
| 269 |
+
logger.info(
|
| 270 |
+
f"Generating {self.num_patterns} NaN patterns for shape {series_shape}..."
|
| 271 |
+
)
|
| 272 |
+
|
| 273 |
+
with Parallel(n_jobs=self.n_jobs, backend="loky") as parallel:
|
| 274 |
+
masks_list = parallel(
|
| 275 |
+
delayed(self._generate_nan_mask)(series_shape)
|
| 276 |
+
for _ in range(self.num_patterns)
|
| 277 |
+
)
|
| 278 |
+
|
| 279 |
+
logger.info(f"Pattern generation complete for shape {series_shape}.")
|
| 280 |
+
return torch.from_numpy(np.stack(masks_list)).bool()
|
| 281 |
+
|
| 282 |
+
def transform(self, time_series_batch: torch.Tensor) -> torch.Tensor:
|
| 283 |
+
"""
|
| 284 |
+
Applies NaN patterns to a batch, generating them on-demand if the shape is new.
|
| 285 |
+
"""
|
| 286 |
+
if self.p_series_has_nan == 0:
|
| 287 |
+
return time_series_batch
|
| 288 |
+
|
| 289 |
+
history_length, num_channels = time_series_batch.shape[1:]
|
| 290 |
+
assert history_length <= self.max_length, (
|
| 291 |
+
f"History length {history_length} exceeds maximum allowed {self.max_length}."
|
| 292 |
+
)
|
| 293 |
+
|
| 294 |
+
# 1. Check cache and generate patterns if the shape is new
|
| 295 |
+
if (
|
| 296 |
+
self.max_length,
|
| 297 |
+
num_channels,
|
| 298 |
+
) not in self.pattern_cache:
|
| 299 |
+
# Try loading from a resolved file path if available
|
| 300 |
+
target_file = self._get_pattern_file_path(num_channels)
|
| 301 |
+
if target_file.exists():
|
| 302 |
+
try:
|
| 303 |
+
patterns = torch.load(target_file, map_location="cpu")
|
| 304 |
+
self.pattern_cache[(self.max_length, num_channels)] = patterns
|
| 305 |
+
logger.info(
|
| 306 |
+
f"Loaded NaN patterns from {target_file} for shape {(self.max_length, num_channels)}"
|
| 307 |
+
)
|
| 308 |
+
except (RuntimeError, FileNotFoundError):
|
| 309 |
+
# Fall back to generating if loading fails
|
| 310 |
+
patterns = self._pregenerate_patterns(
|
| 311 |
+
(self.max_length, num_channels)
|
| 312 |
+
)
|
| 313 |
+
torch.save(patterns, target_file)
|
| 314 |
+
self.pattern_cache[(self.max_length, num_channels)] = patterns
|
| 315 |
+
logger.info(
|
| 316 |
+
f"Generated and saved {patterns.shape[0]} NaN patterns to {target_file}"
|
| 317 |
+
)
|
| 318 |
+
else:
|
| 319 |
+
patterns = self._pregenerate_patterns((self.max_length, num_channels))
|
| 320 |
+
torch.save(patterns, target_file)
|
| 321 |
+
self.pattern_cache[(self.max_length, num_channels)] = patterns
|
| 322 |
+
logger.info(
|
| 323 |
+
f"Generated and saved {patterns.shape[0]} NaN patterns to {target_file}"
|
| 324 |
+
)
|
| 325 |
+
patterns = self.pattern_cache[(self.max_length, num_channels)][
|
| 326 |
+
:, :history_length, :
|
| 327 |
+
]
|
| 328 |
+
|
| 329 |
+
# Early exit if patterns are empty (e.g., generation failed or was disabled)
|
| 330 |
+
if patterns.numel() == 0:
|
| 331 |
+
return time_series_batch
|
| 332 |
+
|
| 333 |
+
batch_size = time_series_batch.shape[0]
|
| 334 |
+
device = time_series_batch.device
|
| 335 |
+
|
| 336 |
+
# 2. Vectorized decision on which series to augment
|
| 337 |
+
augment_mask = torch.rand(batch_size, device=device) < self.p_series_has_nan
|
| 338 |
+
indices_to_augment = torch.where(augment_mask)[0]
|
| 339 |
+
num_to_augment = indices_to_augment.numel()
|
| 340 |
+
|
| 341 |
+
if num_to_augment == 0:
|
| 342 |
+
return time_series_batch
|
| 343 |
+
|
| 344 |
+
# 3. Randomly sample patterns for each series being augmented
|
| 345 |
+
pattern_indices = torch.randint(
|
| 346 |
+
0, patterns.shape[0], (num_to_augment,), device=device
|
| 347 |
+
)
|
| 348 |
+
# 4. Select patterns and apply them in a single vectorized operation
|
| 349 |
+
selected_patterns = patterns[pattern_indices].to(device)
|
| 350 |
+
|
| 351 |
+
time_series_batch[indices_to_augment] = time_series_batch[
|
| 352 |
+
indices_to_augment
|
| 353 |
+
].masked_fill(selected_patterns, float("nan"))
|
| 354 |
+
|
| 355 |
+
return time_series_batch
|
| 356 |
+
|
| 357 |
+
|
| 358 |
+
class CensorAugmenter:
|
| 359 |
+
"""
|
| 360 |
+
Applies censor augmentation by clipping values from above, below, or both.
|
| 361 |
+
"""
|
| 362 |
+
|
| 363 |
+
def __init__(self):
|
| 364 |
+
"""Initializes the CensorAugmenter."""
|
| 365 |
+
pass
|
| 366 |
+
|
| 367 |
+
def transform(self, time_series_batch: torch.Tensor) -> torch.Tensor:
|
| 368 |
+
"""
|
| 369 |
+
Applies a vectorized censor augmentation to a batch of time series.
|
| 370 |
+
"""
|
| 371 |
+
batch_size, seq_len, num_channels = time_series_batch.shape
|
| 372 |
+
assert num_channels == 1
|
| 373 |
+
time_series_batch = time_series_batch.squeeze(-1)
|
| 374 |
+
with torch.no_grad():
|
| 375 |
+
batch_size, seq_len = time_series_batch.shape
|
| 376 |
+
device = time_series_batch.device
|
| 377 |
+
|
| 378 |
+
# Step 1: Choose an op mode for each series
|
| 379 |
+
op_mode = torch.randint(0, 3, (batch_size, 1), device=device)
|
| 380 |
+
|
| 381 |
+
# Step 2: Calculate potential thresholds for all series
|
| 382 |
+
q1 = torch.rand(batch_size, device=device)
|
| 383 |
+
q2 = torch.rand(batch_size, device=device)
|
| 384 |
+
q_low = torch.minimum(q1, q2)
|
| 385 |
+
q_high = torch.maximum(q1, q2)
|
| 386 |
+
|
| 387 |
+
sorted_series = torch.sort(time_series_batch, dim=1).values
|
| 388 |
+
indices_low = (q_low * (seq_len - 1)).long()
|
| 389 |
+
indices_high = (q_high * (seq_len - 1)).long()
|
| 390 |
+
|
| 391 |
+
c_low = torch.gather(sorted_series, 1, indices_low.unsqueeze(1))
|
| 392 |
+
c_high = torch.gather(sorted_series, 1, indices_high.unsqueeze(1))
|
| 393 |
+
|
| 394 |
+
# Step 3: Compute results for all possible clipping operations
|
| 395 |
+
clip_above = torch.minimum(time_series_batch, c_high)
|
| 396 |
+
clip_below = torch.maximum(time_series_batch, c_low)
|
| 397 |
+
|
| 398 |
+
# Step 4: Select the final result based on the op_mode
|
| 399 |
+
result = torch.where(
|
| 400 |
+
op_mode == 1,
|
| 401 |
+
clip_above,
|
| 402 |
+
torch.where(op_mode == 2, clip_below, time_series_batch),
|
| 403 |
+
)
|
| 404 |
+
augmented_batch = torch.where(
|
| 405 |
+
op_mode == 0,
|
| 406 |
+
time_series_batch,
|
| 407 |
+
result,
|
| 408 |
+
)
|
| 409 |
+
|
| 410 |
+
return augmented_batch.unsqueeze(-1)
|
| 411 |
+
|
| 412 |
+
|
| 413 |
+
class QuantizationAugmenter:
|
| 414 |
+
"""
|
| 415 |
+
Applies non-equidistant quantization using a Sobol sequence to generate
|
| 416 |
+
uniformly distributed levels. This implementation is fully vectorized.
|
| 417 |
+
"""
|
| 418 |
+
|
| 419 |
+
def __init__(
|
| 420 |
+
self,
|
| 421 |
+
p_quantize: float,
|
| 422 |
+
level_range: Tuple[int, int],
|
| 423 |
+
seed: Optional[int] = None,
|
| 424 |
+
):
|
| 425 |
+
"""
|
| 426 |
+
Initializes the augmenter.
|
| 427 |
+
|
| 428 |
+
Args:
|
| 429 |
+
p_quantize (float): Probability of applying quantization to a series.
|
| 430 |
+
level_range (Tuple[int, int]): Inclusive range [min, max] to sample the
|
| 431 |
+
number of quantization levels from.
|
| 432 |
+
seed (Optional[int]): Seed for the Sobol sequence generator for reproducibility.
|
| 433 |
+
"""
|
| 434 |
+
assert 0.0 <= p_quantize <= 1.0, "Probability must be between 0 and 1."
|
| 435 |
+
assert level_range[0] >= 2, "Minimum number of levels must be at least 2."
|
| 436 |
+
assert level_range[0] <= level_range[1], (
|
| 437 |
+
"Min levels cannot be greater than max."
|
| 438 |
+
)
|
| 439 |
+
|
| 440 |
+
self.p_quantize = p_quantize
|
| 441 |
+
self.level_range = level_range
|
| 442 |
+
|
| 443 |
+
# Initialize a SobolEngine. The dimension is the max number of random
|
| 444 |
+
# levels we might need to generate for a single series.
|
| 445 |
+
max_intermediate_levels = self.level_range[1] - 2
|
| 446 |
+
if max_intermediate_levels > 0:
|
| 447 |
+
# SobolEngine must be created on CPU
|
| 448 |
+
self.sobol_engine = SobolEngine(
|
| 449 |
+
dimension=max_intermediate_levels, scramble=True, seed=seed
|
| 450 |
+
)
|
| 451 |
+
else:
|
| 452 |
+
self.sobol_engine = None
|
| 453 |
+
|
| 454 |
+
def transform(self, time_series_batch: torch.Tensor) -> torch.Tensor:
|
| 455 |
+
"""
|
| 456 |
+
Applies augmentation in a fully vectorized way on the batch's device.
|
| 457 |
+
Handles input shape (batch, length, 1).
|
| 458 |
+
"""
|
| 459 |
+
# Handle input shape (batch, length, 1)
|
| 460 |
+
if time_series_batch.dim() == 3 and time_series_batch.shape[2] == 1:
|
| 461 |
+
is_3d = True
|
| 462 |
+
time_series_squeezed = time_series_batch.squeeze(-1)
|
| 463 |
+
else:
|
| 464 |
+
is_3d = False
|
| 465 |
+
time_series_squeezed = time_series_batch
|
| 466 |
+
|
| 467 |
+
if self.p_quantize == 0 or self.sobol_engine is None:
|
| 468 |
+
return time_series_batch
|
| 469 |
+
|
| 470 |
+
n_series, _ = time_series_squeezed.shape
|
| 471 |
+
device = time_series_squeezed.device
|
| 472 |
+
|
| 473 |
+
# 1. Decide which series to augment
|
| 474 |
+
augment_mask = torch.rand(n_series, device=device) < self.p_quantize
|
| 475 |
+
n_augment = torch.sum(augment_mask)
|
| 476 |
+
if n_augment == 0:
|
| 477 |
+
return time_series_batch
|
| 478 |
+
|
| 479 |
+
series_to_augment = time_series_squeezed[augment_mask]
|
| 480 |
+
|
| 481 |
+
# 2. Determine a variable n_levels for EACH series
|
| 482 |
+
min_l, max_l = self.level_range
|
| 483 |
+
n_levels_per_series = torch.randint(
|
| 484 |
+
min_l, max_l + 1, size=(n_augment,), device=device
|
| 485 |
+
)
|
| 486 |
+
max_levels_in_batch = n_levels_per_series.max().item()
|
| 487 |
+
|
| 488 |
+
# 3. Find min/max for each series
|
| 489 |
+
min_vals = torch.amin(series_to_augment, dim=1, keepdim=True)
|
| 490 |
+
max_vals = torch.amax(series_to_augment, dim=1, keepdim=True)
|
| 491 |
+
value_range = max_vals - min_vals
|
| 492 |
+
is_flat = value_range == 0
|
| 493 |
+
|
| 494 |
+
# 4. Generate quasi-random levels using the Sobol sequence
|
| 495 |
+
num_intermediate_levels = max_levels_in_batch - 2
|
| 496 |
+
if num_intermediate_levels > 0:
|
| 497 |
+
# Draw points from the Sobol engine (on CPU) and move to target device
|
| 498 |
+
sobol_points = self.sobol_engine.draw(n_augment).to(device)
|
| 499 |
+
# We only need the first `num_intermediate_levels` dimensions
|
| 500 |
+
quasi_rand_points = sobol_points[:, :num_intermediate_levels]
|
| 501 |
+
else:
|
| 502 |
+
# Handle case where max_levels_in_batch is 2 (no intermediate points needed)
|
| 503 |
+
quasi_rand_points = torch.empty(n_augment, 0, device=device)
|
| 504 |
+
|
| 505 |
+
scaled_quasi_rand_levels = min_vals + value_range * quasi_rand_points
|
| 506 |
+
level_values = torch.cat([min_vals, max_vals, scaled_quasi_rand_levels], dim=1)
|
| 507 |
+
level_values, _ = torch.sort(level_values, dim=1)
|
| 508 |
+
|
| 509 |
+
# 5. Find the closest level using a mask to ignore padded values
|
| 510 |
+
series_expanded = series_to_augment.unsqueeze(2)
|
| 511 |
+
levels_expanded = level_values.unsqueeze(1)
|
| 512 |
+
diff = torch.abs(series_expanded - levels_expanded)
|
| 513 |
+
|
| 514 |
+
arange_mask = torch.arange(max_levels_in_batch, device=device).unsqueeze(0)
|
| 515 |
+
valid_levels_mask = arange_mask < n_levels_per_series.unsqueeze(1)
|
| 516 |
+
masked_diff = torch.where(valid_levels_mask.unsqueeze(1), diff, float("inf"))
|
| 517 |
+
closest_level_indices = torch.argmin(masked_diff, dim=2)
|
| 518 |
+
|
| 519 |
+
# 6. Gather the results from the original level values
|
| 520 |
+
quantized_subset = torch.gather(level_values, 1, closest_level_indices)
|
| 521 |
+
|
| 522 |
+
# 7. For flat series, revert to their original values
|
| 523 |
+
final_subset = torch.where(is_flat, series_to_augment, quantized_subset)
|
| 524 |
+
|
| 525 |
+
# 8. Place augmented data back into a copy of the original batch
|
| 526 |
+
augmented_batch_squeezed = time_series_squeezed.clone()
|
| 527 |
+
augmented_batch_squeezed[augment_mask] = final_subset
|
| 528 |
+
|
| 529 |
+
# Restore original shape before returning
|
| 530 |
+
if is_3d:
|
| 531 |
+
return augmented_batch_squeezed.unsqueeze(-1)
|
| 532 |
+
else:
|
| 533 |
+
return augmented_batch_squeezed
|
| 534 |
+
|
| 535 |
+
|
| 536 |
+
class MixUpAugmenter:
|
| 537 |
+
"""
|
| 538 |
+
Applies mixup augmentation by creating a weighted average of multiple time series.
|
| 539 |
+
|
| 540 |
+
This version includes an option for time-dependent mixup using Simplex Path
|
| 541 |
+
Interpolation, creating a smooth transition between different mixing weights.
|
| 542 |
+
"""
|
| 543 |
+
|
| 544 |
+
def __init__(
|
| 545 |
+
self,
|
| 546 |
+
max_n_series_to_combine: int = 10,
|
| 547 |
+
p_combine: float = 0.4,
|
| 548 |
+
p_time_dependent: float = 0.5,
|
| 549 |
+
randomize_k_per_series: bool = True,
|
| 550 |
+
dirichlet_alpha_range: Tuple[float, float] = (0.1, 5.0),
|
| 551 |
+
):
|
| 552 |
+
"""
|
| 553 |
+
Initializes the augmenter.
|
| 554 |
+
|
| 555 |
+
Args:
|
| 556 |
+
max_n_series_to_combine (int): The maximum number of series to combine.
|
| 557 |
+
The actual number k will be sampled from [2, max].
|
| 558 |
+
p_combine (float): The probability of replacing a series with a combination.
|
| 559 |
+
p_time_dependent (float): The probability of using the time-dependent
|
| 560 |
+
simplex path method for a given mixup operation. Defaults to 0.5.
|
| 561 |
+
randomize_k_per_series (bool): If True, each augmented series will be a
|
| 562 |
+
combination of a different number of series (k).
|
| 563 |
+
If False, one k is chosen for the whole batch.
|
| 564 |
+
dirichlet_alpha_range (Tuple[float, float]): The [min, max] range to sample the
|
| 565 |
+
Dirichlet 'alpha' from. A smaller alpha (e.g., 0.2) creates mixes
|
| 566 |
+
dominated by one series. A larger alpha (e.g., 5.0) creates
|
| 567 |
+
more uniform weights.
|
| 568 |
+
"""
|
| 569 |
+
assert max_n_series_to_combine >= 2, "Must combine at least 2 series."
|
| 570 |
+
assert 0.0 <= p_combine <= 1.0, "p_combine must be between 0 and 1."
|
| 571 |
+
assert 0.0 <= p_time_dependent <= 1.0, (
|
| 572 |
+
"p_time_dependent must be between 0 and 1."
|
| 573 |
+
)
|
| 574 |
+
assert (
|
| 575 |
+
dirichlet_alpha_range[0] > 0
|
| 576 |
+
and dirichlet_alpha_range[0] <= dirichlet_alpha_range[1]
|
| 577 |
+
)
|
| 578 |
+
self.max_k = max_n_series_to_combine
|
| 579 |
+
self.p_combine = p_combine
|
| 580 |
+
self.p_time_dependent = p_time_dependent
|
| 581 |
+
self.randomize_k = randomize_k_per_series
|
| 582 |
+
self.alpha_range = dirichlet_alpha_range
|
| 583 |
+
|
| 584 |
+
def _sample_alpha(self) -> float:
|
| 585 |
+
log_alpha_min = math.log10(self.alpha_range[0])
|
| 586 |
+
log_alpha_max = math.log10(self.alpha_range[1])
|
| 587 |
+
log_alpha = log_alpha_min + np.random.rand() * (log_alpha_max - log_alpha_min)
|
| 588 |
+
return float(10**log_alpha)
|
| 589 |
+
|
| 590 |
+
def _sample_k(self) -> int:
|
| 591 |
+
return int(torch.randint(2, self.max_k + 1, (1,)).item())
|
| 592 |
+
|
| 593 |
+
def _static_mix(
|
| 594 |
+
self,
|
| 595 |
+
source_series: torch.Tensor,
|
| 596 |
+
alpha: float,
|
| 597 |
+
return_weights: bool = False,
|
| 598 |
+
):
|
| 599 |
+
"""Mixes k source series using a single, static set of Dirichlet weights."""
|
| 600 |
+
k = int(source_series.shape[0])
|
| 601 |
+
device = source_series.device
|
| 602 |
+
concentration = torch.full((k,), float(alpha), device=device)
|
| 603 |
+
weights = torch.distributions.Dirichlet(concentration).sample()
|
| 604 |
+
weights_view = weights.view(k, 1, 1)
|
| 605 |
+
mixed_series = (source_series * weights_view).sum(dim=0, keepdim=True)
|
| 606 |
+
if return_weights:
|
| 607 |
+
return mixed_series, weights
|
| 608 |
+
return mixed_series
|
| 609 |
+
|
| 610 |
+
def _simplex_path_mix(
|
| 611 |
+
self,
|
| 612 |
+
source_series: torch.Tensor,
|
| 613 |
+
alpha: float,
|
| 614 |
+
return_weights: bool = False,
|
| 615 |
+
):
|
| 616 |
+
"""Mixes k series using time-varying weights interpolated along a simplex path."""
|
| 617 |
+
k, length, _ = source_series.shape
|
| 618 |
+
device = source_series.device
|
| 619 |
+
|
| 620 |
+
# 1. Sample two endpoint weight vectors from the Dirichlet distribution
|
| 621 |
+
concentration = torch.full((k,), float(alpha), device=device)
|
| 622 |
+
dirichlet_dist = torch.distributions.Dirichlet(concentration)
|
| 623 |
+
w_start = dirichlet_dist.sample()
|
| 624 |
+
w_end = dirichlet_dist.sample()
|
| 625 |
+
|
| 626 |
+
# 2. Create a linear ramp from 0 to 1
|
| 627 |
+
alpha_ramp = torch.linspace(0, 1, length, device=device)
|
| 628 |
+
|
| 629 |
+
# 3. Interpolate between the endpoint weights over time
|
| 630 |
+
# Reshape for broadcasting: w vectors become [k, 1], ramp becomes [1, length]
|
| 631 |
+
time_varying_weights = w_start.unsqueeze(1) * (
|
| 632 |
+
1 - alpha_ramp.unsqueeze(0)
|
| 633 |
+
) + w_end.unsqueeze(1) * alpha_ramp.unsqueeze(0)
|
| 634 |
+
# The result `time_varying_weights` has shape [k, length]
|
| 635 |
+
|
| 636 |
+
# 4. Apply the time-varying weights
|
| 637 |
+
weights_view = time_varying_weights.unsqueeze(-1) # Shape: [k, length, 1]
|
| 638 |
+
mixed_series = (source_series * weights_view).sum(dim=0, keepdim=True)
|
| 639 |
+
|
| 640 |
+
if return_weights:
|
| 641 |
+
return mixed_series, time_varying_weights
|
| 642 |
+
return mixed_series
|
| 643 |
+
|
| 644 |
+
def transform(
|
| 645 |
+
self, time_series_batch: torch.Tensor, return_debug_info: bool = False
|
| 646 |
+
):
|
| 647 |
+
"""
|
| 648 |
+
Applies the mixup augmentation, randomly choosing between static and
|
| 649 |
+
time-dependent mixing methods.
|
| 650 |
+
"""
|
| 651 |
+
with torch.no_grad():
|
| 652 |
+
if self.p_combine == 0:
|
| 653 |
+
return (
|
| 654 |
+
(time_series_batch, {}) if return_debug_info else time_series_batch
|
| 655 |
+
)
|
| 656 |
+
|
| 657 |
+
batch_size, _, _ = time_series_batch.shape
|
| 658 |
+
device = time_series_batch.device
|
| 659 |
+
|
| 660 |
+
if batch_size <= self.max_k:
|
| 661 |
+
return (
|
| 662 |
+
(time_series_batch, {}) if return_debug_info else time_series_batch
|
| 663 |
+
)
|
| 664 |
+
|
| 665 |
+
# 1. Decide which series to replace
|
| 666 |
+
augment_mask = torch.rand(batch_size, device=device) < self.p_combine
|
| 667 |
+
indices_to_replace = torch.where(augment_mask)[0]
|
| 668 |
+
n_augment = indices_to_replace.numel()
|
| 669 |
+
|
| 670 |
+
if n_augment == 0:
|
| 671 |
+
return (
|
| 672 |
+
(time_series_batch, {}) if return_debug_info else time_series_batch
|
| 673 |
+
)
|
| 674 |
+
|
| 675 |
+
# 2. Determine k for each series to augment
|
| 676 |
+
if self.randomize_k:
|
| 677 |
+
k_values = torch.randint(2, self.max_k + 1, (n_augment,), device=device)
|
| 678 |
+
else:
|
| 679 |
+
k = self._sample_k()
|
| 680 |
+
k_values = torch.full((n_augment,), k, device=device)
|
| 681 |
+
|
| 682 |
+
# 3. Augment series one by one
|
| 683 |
+
new_series_list = []
|
| 684 |
+
all_batch_indices = torch.arange(batch_size, device=device)
|
| 685 |
+
debug_info = {}
|
| 686 |
+
|
| 687 |
+
for i, target_idx in enumerate(indices_to_replace):
|
| 688 |
+
current_k = k_values[i].item()
|
| 689 |
+
|
| 690 |
+
# Sample source indices
|
| 691 |
+
candidate_mask = all_batch_indices != target_idx
|
| 692 |
+
candidates = all_batch_indices[candidate_mask]
|
| 693 |
+
perm = torch.randperm(candidates.shape[0], device=device)
|
| 694 |
+
source_indices = candidates[perm[:current_k]]
|
| 695 |
+
source_series = time_series_batch[source_indices]
|
| 696 |
+
|
| 697 |
+
alpha = self._sample_alpha()
|
| 698 |
+
mix_type = "static"
|
| 699 |
+
|
| 700 |
+
# Randomly choose between static and time-dependent mixup
|
| 701 |
+
if torch.rand(1).item() < self.p_time_dependent:
|
| 702 |
+
mixed_series, weights = self._simplex_path_mix(
|
| 703 |
+
source_series, alpha=alpha, return_weights=True
|
| 704 |
+
)
|
| 705 |
+
mix_type = "simplex"
|
| 706 |
+
else:
|
| 707 |
+
mixed_series, weights = self._static_mix(
|
| 708 |
+
source_series, alpha=alpha, return_weights=True
|
| 709 |
+
)
|
| 710 |
+
|
| 711 |
+
new_series_list.append(mixed_series)
|
| 712 |
+
|
| 713 |
+
if return_debug_info:
|
| 714 |
+
debug_info[target_idx.item()] = {
|
| 715 |
+
"source_indices": source_indices.cpu().numpy(),
|
| 716 |
+
"weights": weights.cpu().numpy(),
|
| 717 |
+
"alpha": alpha,
|
| 718 |
+
"k": current_k,
|
| 719 |
+
"mix_type": mix_type,
|
| 720 |
+
}
|
| 721 |
+
|
| 722 |
+
# 4. Place augmented series back into a clone of the original batch
|
| 723 |
+
augmented_batch = time_series_batch.clone()
|
| 724 |
+
if new_series_list:
|
| 725 |
+
new_series_tensor = torch.cat(new_series_list, dim=0)
|
| 726 |
+
augmented_batch[indices_to_replace] = new_series_tensor
|
| 727 |
+
|
| 728 |
+
if return_debug_info:
|
| 729 |
+
return augmented_batch.detach(), debug_info
|
| 730 |
+
return augmented_batch.detach()
|
| 731 |
+
|
| 732 |
+
|
| 733 |
+
class TimeFlipAugmenter:
|
| 734 |
+
"""
|
| 735 |
+
Applies time-reversal augmentation to a random subset of time series in a batch.
|
| 736 |
+
"""
|
| 737 |
+
|
| 738 |
+
def __init__(self, p_flip: float = 0.5):
|
| 739 |
+
"""
|
| 740 |
+
Initializes the TimeFlipAugmenter.
|
| 741 |
+
|
| 742 |
+
Args:
|
| 743 |
+
p_flip (float): The probability of flipping a single time series in the batch.
|
| 744 |
+
Defaults to 0.5.
|
| 745 |
+
"""
|
| 746 |
+
assert 0.0 <= p_flip <= 1.0, "Probability must be between 0 and 1."
|
| 747 |
+
self.p_flip = p_flip
|
| 748 |
+
|
| 749 |
+
def transform(self, time_series_batch: torch.Tensor) -> torch.Tensor:
|
| 750 |
+
"""
|
| 751 |
+
Applies time-reversal augmentation to a batch of time series.
|
| 752 |
+
|
| 753 |
+
Args:
|
| 754 |
+
time_series_batch (torch.Tensor): The input batch of time series with
|
| 755 |
+
shape (batch_size, seq_len, num_channels).
|
| 756 |
+
|
| 757 |
+
Returns:
|
| 758 |
+
torch.Tensor: The batch with some series potentially flipped.
|
| 759 |
+
"""
|
| 760 |
+
with torch.no_grad():
|
| 761 |
+
if self.p_flip == 0:
|
| 762 |
+
return time_series_batch
|
| 763 |
+
|
| 764 |
+
batch_size = time_series_batch.shape[0]
|
| 765 |
+
device = time_series_batch.device
|
| 766 |
+
|
| 767 |
+
# 1. Decide which series in the batch to flip
|
| 768 |
+
flip_mask = torch.rand(batch_size, device=device) < self.p_flip
|
| 769 |
+
indices_to_flip = torch.where(flip_mask)[0]
|
| 770 |
+
|
| 771 |
+
if indices_to_flip.numel() == 0:
|
| 772 |
+
return time_series_batch
|
| 773 |
+
|
| 774 |
+
# 2. Select the series to be flipped
|
| 775 |
+
series_to_flip = time_series_batch[indices_to_flip]
|
| 776 |
+
|
| 777 |
+
# 3. Flip them along the time dimension (dim=1)
|
| 778 |
+
flipped_series = torch.flip(series_to_flip, dims=[1])
|
| 779 |
+
|
| 780 |
+
# 4. Create a copy of the batch and place the flipped series into it
|
| 781 |
+
augmented_batch = time_series_batch.clone()
|
| 782 |
+
augmented_batch[indices_to_flip] = flipped_series
|
| 783 |
+
|
| 784 |
+
return augmented_batch
|
| 785 |
+
|
| 786 |
+
|
| 787 |
+
class YFlipAugmenter:
|
| 788 |
+
"""
|
| 789 |
+
Applies y-reversal augmentation to a random subset of time series in a batch.
|
| 790 |
+
"""
|
| 791 |
+
|
| 792 |
+
def __init__(self, p_flip: float = 0.5):
|
| 793 |
+
"""
|
| 794 |
+
Initializes the TimeFlipAugmenter.
|
| 795 |
+
|
| 796 |
+
Args:
|
| 797 |
+
p_flip (float): The probability of flipping a single time series in the batch.
|
| 798 |
+
Defaults to 0.5.
|
| 799 |
+
"""
|
| 800 |
+
assert 0.0 <= p_flip <= 1.0, "Probability must be between 0 and 1."
|
| 801 |
+
self.p_flip = p_flip
|
| 802 |
+
|
| 803 |
+
def transform(self, time_series_batch: torch.Tensor) -> torch.Tensor:
|
| 804 |
+
"""
|
| 805 |
+
Applies time-reversal augmentation to a batch of time series.
|
| 806 |
+
|
| 807 |
+
Args:
|
| 808 |
+
time_series_batch (torch.Tensor): The input batch of time series with
|
| 809 |
+
shape (batch_size, seq_len, num_channels).
|
| 810 |
+
|
| 811 |
+
Returns:
|
| 812 |
+
torch.Tensor: The batch with some series potentially flipped.
|
| 813 |
+
"""
|
| 814 |
+
with torch.no_grad():
|
| 815 |
+
if self.p_flip == 0:
|
| 816 |
+
return time_series_batch
|
| 817 |
+
|
| 818 |
+
batch_size = time_series_batch.shape[0]
|
| 819 |
+
device = time_series_batch.device
|
| 820 |
+
|
| 821 |
+
# 1. Decide which series in the batch to flip
|
| 822 |
+
flip_mask = torch.rand(batch_size, device=device) < self.p_flip
|
| 823 |
+
indices_to_flip = torch.where(flip_mask)[0]
|
| 824 |
+
|
| 825 |
+
if indices_to_flip.numel() == 0:
|
| 826 |
+
return time_series_batch
|
| 827 |
+
|
| 828 |
+
# 2. Select the series to be flipped
|
| 829 |
+
series_to_flip = time_series_batch[indices_to_flip]
|
| 830 |
+
|
| 831 |
+
# 3. Flip them along the time dimension (dim=1)
|
| 832 |
+
flipped_series = -series_to_flip
|
| 833 |
+
|
| 834 |
+
# 4. Create a copy of the batch and place the flipped series into it
|
| 835 |
+
augmented_batch = time_series_batch.clone()
|
| 836 |
+
augmented_batch[indices_to_flip] = flipped_series
|
| 837 |
+
|
| 838 |
+
return augmented_batch
|
| 839 |
+
|
| 840 |
+
|
| 841 |
+
class DifferentialAugmenter:
|
| 842 |
+
"""
|
| 843 |
+
Applies calculus-inspired augmentations. This version includes up to the
|
| 844 |
+
fourth derivative and uses nn.Conv1d with built-in 'reflect' padding for
|
| 845 |
+
cleaner and more efficient convolutions.
|
| 846 |
+
|
| 847 |
+
The Gaussian kernel size and sigma for the initial smoothing are randomly
|
| 848 |
+
sampled at every transform() call from user-defined ranges.
|
| 849 |
+
"""
|
| 850 |
+
|
| 851 |
+
def __init__(
|
| 852 |
+
self,
|
| 853 |
+
p_transform: float,
|
| 854 |
+
gaussian_kernel_size_range: Tuple[int, int] = (5, 51),
|
| 855 |
+
gaussian_sigma_range: Tuple[float, float] = (2.0, 20.0),
|
| 856 |
+
):
|
| 857 |
+
"""
|
| 858 |
+
Initializes the augmenter.
|
| 859 |
+
|
| 860 |
+
Args:
|
| 861 |
+
p_transform (float): The probability of applying an augmentation to any given
|
| 862 |
+
time series in a batch.
|
| 863 |
+
gaussian_kernel_size_range (Tuple[int, int]): The [min, max] inclusive range
|
| 864 |
+
for the Gaussian kernel size.
|
| 865 |
+
Sizes will be forced to be odd.
|
| 866 |
+
gaussian_sigma_range (Tuple[float, float]): The [min, max] inclusive range
|
| 867 |
+
for the Gaussian sigma.
|
| 868 |
+
"""
|
| 869 |
+
self.p_transform = p_transform
|
| 870 |
+
self.kernel_size_range = gaussian_kernel_size_range
|
| 871 |
+
self.sigma_range = gaussian_sigma_range
|
| 872 |
+
|
| 873 |
+
# Validate ranges
|
| 874 |
+
if not (
|
| 875 |
+
self.kernel_size_range[0] <= self.kernel_size_range[1]
|
| 876 |
+
and self.kernel_size_range[0] >= 3
|
| 877 |
+
):
|
| 878 |
+
raise ValueError(
|
| 879 |
+
"Invalid kernel size range. Ensure min <= max and min >= 3."
|
| 880 |
+
)
|
| 881 |
+
if not (self.sigma_range[0] <= self.sigma_range[1] and self.sigma_range[0] > 0):
|
| 882 |
+
raise ValueError("Invalid sigma range. Ensure min <= max and min > 0.")
|
| 883 |
+
|
| 884 |
+
# Cache for fixed-kernel convolution layers (Sobel, Laplace, etc.)
|
| 885 |
+
self.conv_cache: Dict[Tuple[int, torch.device], Dict[str, nn.Module]] = {}
|
| 886 |
+
|
| 887 |
+
def _create_fixed_kernel_layers(
|
| 888 |
+
self, num_channels: int, device: torch.device
|
| 889 |
+
) -> dict:
|
| 890 |
+
"""
|
| 891 |
+
Creates and configures nn.Conv1d layers for fixed-kernel derivative operations.
|
| 892 |
+
These layers are cached to improve performance.
|
| 893 |
+
"""
|
| 894 |
+
sobel_conv = nn.Conv1d(
|
| 895 |
+
in_channels=num_channels,
|
| 896 |
+
out_channels=num_channels,
|
| 897 |
+
kernel_size=3,
|
| 898 |
+
padding="same",
|
| 899 |
+
padding_mode="reflect",
|
| 900 |
+
groups=num_channels,
|
| 901 |
+
bias=False,
|
| 902 |
+
device=device,
|
| 903 |
+
)
|
| 904 |
+
laplace_conv = nn.Conv1d(
|
| 905 |
+
in_channels=num_channels,
|
| 906 |
+
out_channels=num_channels,
|
| 907 |
+
kernel_size=3,
|
| 908 |
+
padding="same",
|
| 909 |
+
padding_mode="reflect",
|
| 910 |
+
groups=num_channels,
|
| 911 |
+
bias=False,
|
| 912 |
+
device=device,
|
| 913 |
+
)
|
| 914 |
+
d3_conv = nn.Conv1d(
|
| 915 |
+
in_channels=num_channels,
|
| 916 |
+
out_channels=num_channels,
|
| 917 |
+
kernel_size=5,
|
| 918 |
+
padding="same",
|
| 919 |
+
padding_mode="reflect",
|
| 920 |
+
groups=num_channels,
|
| 921 |
+
bias=False,
|
| 922 |
+
device=device,
|
| 923 |
+
)
|
| 924 |
+
d4_conv = nn.Conv1d(
|
| 925 |
+
in_channels=num_channels,
|
| 926 |
+
out_channels=num_channels,
|
| 927 |
+
kernel_size=5,
|
| 928 |
+
padding="same",
|
| 929 |
+
padding_mode="reflect",
|
| 930 |
+
groups=num_channels,
|
| 931 |
+
bias=False,
|
| 932 |
+
device=device,
|
| 933 |
+
)
|
| 934 |
+
|
| 935 |
+
sobel_kernel = (
|
| 936 |
+
torch.tensor([-1, 0, 1], device=device, dtype=torch.float32)
|
| 937 |
+
.view(1, 1, -1)
|
| 938 |
+
.repeat(num_channels, 1, 1)
|
| 939 |
+
)
|
| 940 |
+
laplace_kernel = (
|
| 941 |
+
torch.tensor([1, -2, 1], device=device, dtype=torch.float32)
|
| 942 |
+
.view(1, 1, -1)
|
| 943 |
+
.repeat(num_channels, 1, 1)
|
| 944 |
+
)
|
| 945 |
+
d3_kernel = (
|
| 946 |
+
torch.tensor([-1, 2, 0, -2, 1], device=device, dtype=torch.float32)
|
| 947 |
+
.view(1, 1, -1)
|
| 948 |
+
.repeat(num_channels, 1, 1)
|
| 949 |
+
)
|
| 950 |
+
d4_kernel = (
|
| 951 |
+
torch.tensor([1, -4, 6, -4, 1], device=device, dtype=torch.float32)
|
| 952 |
+
.view(1, 1, -1)
|
| 953 |
+
.repeat(num_channels, 1, 1)
|
| 954 |
+
)
|
| 955 |
+
|
| 956 |
+
sobel_conv.weight.data = sobel_kernel
|
| 957 |
+
laplace_conv.weight.data = laplace_kernel
|
| 958 |
+
d3_conv.weight.data = d3_kernel
|
| 959 |
+
d4_conv.weight.data = d4_kernel
|
| 960 |
+
|
| 961 |
+
for layer in [sobel_conv, laplace_conv, d3_conv, d4_conv]:
|
| 962 |
+
layer.weight.requires_grad = False
|
| 963 |
+
|
| 964 |
+
return {
|
| 965 |
+
"sobel": sobel_conv,
|
| 966 |
+
"laplace": laplace_conv,
|
| 967 |
+
"d3": d3_conv,
|
| 968 |
+
"d4": d4_conv,
|
| 969 |
+
}
|
| 970 |
+
|
| 971 |
+
def _create_gaussian_layer(
|
| 972 |
+
self, kernel_size: int, sigma: float, num_channels: int, device: torch.device
|
| 973 |
+
) -> nn.Module:
|
| 974 |
+
"""Creates a single Gaussian convolution layer with the given dynamic parameters."""
|
| 975 |
+
gauss_conv = nn.Conv1d(
|
| 976 |
+
in_channels=num_channels,
|
| 977 |
+
out_channels=num_channels,
|
| 978 |
+
kernel_size=kernel_size,
|
| 979 |
+
padding="same",
|
| 980 |
+
padding_mode="reflect",
|
| 981 |
+
groups=num_channels,
|
| 982 |
+
bias=False,
|
| 983 |
+
device=device,
|
| 984 |
+
)
|
| 985 |
+
ax = torch.arange(
|
| 986 |
+
-(kernel_size // 2),
|
| 987 |
+
kernel_size // 2 + 1,
|
| 988 |
+
device=device,
|
| 989 |
+
dtype=torch.float32,
|
| 990 |
+
)
|
| 991 |
+
gauss_kernel = torch.exp(-0.5 * (ax / sigma) ** 2)
|
| 992 |
+
gauss_kernel /= gauss_kernel.sum()
|
| 993 |
+
gauss_kernel = gauss_kernel.view(1, 1, -1).repeat(num_channels, 1, 1)
|
| 994 |
+
gauss_conv.weight.data = gauss_kernel
|
| 995 |
+
gauss_conv.weight.requires_grad = False
|
| 996 |
+
return gauss_conv
|
| 997 |
+
|
| 998 |
+
def _rescale_signal(
|
| 999 |
+
self, processed_signal: torch.Tensor, original_signal: torch.Tensor
|
| 1000 |
+
) -> torch.Tensor:
|
| 1001 |
+
"""Rescales the processed signal to match the min/max range of the original."""
|
| 1002 |
+
original_min = torch.amin(original_signal, dim=2, keepdim=True)
|
| 1003 |
+
original_max = torch.amax(original_signal, dim=2, keepdim=True)
|
| 1004 |
+
processed_min = torch.amin(processed_signal, dim=2, keepdim=True)
|
| 1005 |
+
processed_max = torch.amax(processed_signal, dim=2, keepdim=True)
|
| 1006 |
+
|
| 1007 |
+
original_range = original_max - original_min
|
| 1008 |
+
processed_range = processed_max - processed_min
|
| 1009 |
+
epsilon = 1e-8
|
| 1010 |
+
rescaled_signal = (
|
| 1011 |
+
(processed_signal - processed_min) / (processed_range + epsilon)
|
| 1012 |
+
) * original_range + original_min
|
| 1013 |
+
return torch.where(original_range < epsilon, original_signal, rescaled_signal)
|
| 1014 |
+
|
| 1015 |
+
def transform(self, time_series_batch: torch.Tensor) -> torch.Tensor:
|
| 1016 |
+
"""Applies a random augmentation to a subset of the batch."""
|
| 1017 |
+
with torch.no_grad():
|
| 1018 |
+
if self.p_transform == 0:
|
| 1019 |
+
return time_series_batch
|
| 1020 |
+
|
| 1021 |
+
batch_size, seq_len, num_channels = time_series_batch.shape
|
| 1022 |
+
device = time_series_batch.device
|
| 1023 |
+
|
| 1024 |
+
augment_mask = torch.rand(batch_size, device=device) < self.p_transform
|
| 1025 |
+
indices_to_augment = torch.where(augment_mask)[0]
|
| 1026 |
+
num_to_augment = indices_to_augment.numel()
|
| 1027 |
+
|
| 1028 |
+
if num_to_augment == 0:
|
| 1029 |
+
return time_series_batch
|
| 1030 |
+
|
| 1031 |
+
# --- 🎲 Randomly sample Gaussian parameters for this call ---
|
| 1032 |
+
min_k, max_k = self.kernel_size_range
|
| 1033 |
+
kernel_size = torch.randint(min_k, max_k + 1, (1,)).item()
|
| 1034 |
+
kernel_size = kernel_size // 2 * 2 + 1 # Ensure kernel size is odd
|
| 1035 |
+
|
| 1036 |
+
min_s, max_s = self.sigma_range
|
| 1037 |
+
sigma = (min_s + (max_s - min_s) * torch.rand(1)).item()
|
| 1038 |
+
|
| 1039 |
+
# --- Get/Create Convolution Layers ---
|
| 1040 |
+
gauss_conv = self._create_gaussian_layer(
|
| 1041 |
+
kernel_size, sigma, num_channels, device
|
| 1042 |
+
)
|
| 1043 |
+
|
| 1044 |
+
cache_key = (num_channels, device)
|
| 1045 |
+
if cache_key not in self.conv_cache:
|
| 1046 |
+
self.conv_cache[cache_key] = self._create_fixed_kernel_layers(
|
| 1047 |
+
num_channels, device
|
| 1048 |
+
)
|
| 1049 |
+
fixed_layers = self.conv_cache[cache_key]
|
| 1050 |
+
|
| 1051 |
+
# --- Apply Augmentations ---
|
| 1052 |
+
subset_to_augment = time_series_batch[indices_to_augment]
|
| 1053 |
+
subset_permuted = subset_to_augment.permute(0, 2, 1)
|
| 1054 |
+
|
| 1055 |
+
op_choices = torch.randint(0, 6, (num_to_augment,), device=device)
|
| 1056 |
+
|
| 1057 |
+
smoothed_subset = gauss_conv(subset_permuted)
|
| 1058 |
+
sobel_on_smoothed = fixed_layers["sobel"](smoothed_subset)
|
| 1059 |
+
laplace_on_smoothed = fixed_layers["laplace"](smoothed_subset)
|
| 1060 |
+
d3_on_smoothed = fixed_layers["d3"](smoothed_subset)
|
| 1061 |
+
d4_on_smoothed = fixed_layers["d4"](smoothed_subset)
|
| 1062 |
+
|
| 1063 |
+
gauss_result = self._rescale_signal(smoothed_subset, subset_permuted)
|
| 1064 |
+
sobel_result = self._rescale_signal(sobel_on_smoothed, subset_permuted)
|
| 1065 |
+
laplace_result = self._rescale_signal(laplace_on_smoothed, subset_permuted)
|
| 1066 |
+
d3_result = self._rescale_signal(d3_on_smoothed, subset_permuted)
|
| 1067 |
+
d4_result = self._rescale_signal(d4_on_smoothed, subset_permuted)
|
| 1068 |
+
|
| 1069 |
+
use_right_integral = torch.rand(num_to_augment, 1, 1, device=device) > 0.5
|
| 1070 |
+
flipped_subset = torch.flip(subset_permuted, dims=[2])
|
| 1071 |
+
right_integral = torch.flip(torch.cumsum(flipped_subset, dim=2), dims=[2])
|
| 1072 |
+
left_integral = torch.cumsum(subset_permuted, dim=2)
|
| 1073 |
+
integral_result = torch.where(
|
| 1074 |
+
use_right_integral, right_integral, left_integral
|
| 1075 |
+
)
|
| 1076 |
+
integral_result_normalized = self._rescale_signal(
|
| 1077 |
+
integral_result, subset_permuted
|
| 1078 |
+
)
|
| 1079 |
+
|
| 1080 |
+
# --- Assemble the results based on op_choices ---
|
| 1081 |
+
op_choices_view = op_choices.view(-1, 1, 1)
|
| 1082 |
+
augmented_subset = torch.where(
|
| 1083 |
+
op_choices_view == 0, gauss_result, subset_permuted
|
| 1084 |
+
)
|
| 1085 |
+
augmented_subset = torch.where(
|
| 1086 |
+
op_choices_view == 1, sobel_result, augmented_subset
|
| 1087 |
+
)
|
| 1088 |
+
augmented_subset = torch.where(
|
| 1089 |
+
op_choices_view == 2, laplace_result, augmented_subset
|
| 1090 |
+
)
|
| 1091 |
+
augmented_subset = torch.where(
|
| 1092 |
+
op_choices_view == 3, integral_result_normalized, augmented_subset
|
| 1093 |
+
)
|
| 1094 |
+
augmented_subset = torch.where(
|
| 1095 |
+
op_choices_view == 4, d3_result, augmented_subset
|
| 1096 |
+
)
|
| 1097 |
+
augmented_subset = torch.where(
|
| 1098 |
+
op_choices_view == 5, d4_result, augmented_subset
|
| 1099 |
+
)
|
| 1100 |
+
|
| 1101 |
+
augmented_subset_final = augmented_subset.permute(0, 2, 1)
|
| 1102 |
+
augmented_batch = time_series_batch.clone()
|
| 1103 |
+
augmented_batch[indices_to_augment] = augmented_subset_final
|
| 1104 |
+
|
| 1105 |
+
return augmented_batch
|
| 1106 |
+
|
| 1107 |
+
|
| 1108 |
+
class RandomConvAugmenter:
|
| 1109 |
+
"""
|
| 1110 |
+
Applies a stack of 1-to-N random 1D convolutions to a time series batch.
|
| 1111 |
+
|
| 1112 |
+
This augmenter is inspired by the principles of ROCKET and RandConv,
|
| 1113 |
+
randomizing nearly every aspect of the convolution process to create a
|
| 1114 |
+
highly diverse set of transformations. This version includes multiple
|
| 1115 |
+
kernel generation strategies, random padding modes, and optional non-linearities.
|
| 1116 |
+
"""
|
| 1117 |
+
|
| 1118 |
+
def __init__(
|
| 1119 |
+
self,
|
| 1120 |
+
p_transform: float = 0.5,
|
| 1121 |
+
kernel_size_range: Tuple[int, int] = (3, 31),
|
| 1122 |
+
dilation_range: Tuple[int, int] = (1, 8),
|
| 1123 |
+
layer_range: Tuple[int, int] = (1, 3),
|
| 1124 |
+
sigma_range: Tuple[float, float] = (0.5, 5.0),
|
| 1125 |
+
bias_range: Tuple[float, float] = (-0.5, 0.5),
|
| 1126 |
+
):
|
| 1127 |
+
"""
|
| 1128 |
+
Initializes the augmenter.
|
| 1129 |
+
|
| 1130 |
+
Args:
|
| 1131 |
+
p_transform (float): Probability of applying the augmentation to a series.
|
| 1132 |
+
kernel_size_range (Tuple[int, int]): [min, max] range for kernel sizes.
|
| 1133 |
+
Must be odd numbers.
|
| 1134 |
+
dilation_range (Tuple[int, int]): [min, max] range for dilation factors.
|
| 1135 |
+
layer_range (Tuple[int, int]): [min, max] range for the number of
|
| 1136 |
+
stacked convolution layers.
|
| 1137 |
+
sigma_range (Tuple[float, float]): [min, max] range for the sigma of
|
| 1138 |
+
Gaussian kernels.
|
| 1139 |
+
bias_range (Tuple[float, float]): [min, max] range for the bias term.
|
| 1140 |
+
"""
|
| 1141 |
+
assert kernel_size_range[0] % 2 == 1 and kernel_size_range[1] % 2 == 1, (
|
| 1142 |
+
"Kernel sizes must be odd."
|
| 1143 |
+
)
|
| 1144 |
+
|
| 1145 |
+
self.p_transform = p_transform
|
| 1146 |
+
self.kernel_size_range = kernel_size_range
|
| 1147 |
+
self.dilation_range = dilation_range
|
| 1148 |
+
self.layer_range = layer_range
|
| 1149 |
+
self.sigma_range = sigma_range
|
| 1150 |
+
self.bias_range = bias_range
|
| 1151 |
+
self.padding_modes = ["reflect", "replicate", "circular"]
|
| 1152 |
+
|
| 1153 |
+
def _rescale_signal(
|
| 1154 |
+
self, processed_signal: torch.Tensor, original_signal: torch.Tensor
|
| 1155 |
+
) -> torch.Tensor:
|
| 1156 |
+
"""Rescales the processed signal to match the min/max range of the original."""
|
| 1157 |
+
original_min = torch.amin(original_signal, dim=-1, keepdim=True)
|
| 1158 |
+
original_max = torch.amax(original_signal, dim=-1, keepdim=True)
|
| 1159 |
+
processed_min = torch.amin(processed_signal, dim=-1, keepdim=True)
|
| 1160 |
+
processed_max = torch.amax(processed_signal, dim=-1, keepdim=True)
|
| 1161 |
+
|
| 1162 |
+
original_range = original_max - original_min
|
| 1163 |
+
processed_range = processed_max - processed_min
|
| 1164 |
+
epsilon = 1e-8
|
| 1165 |
+
|
| 1166 |
+
is_flat = processed_range < epsilon
|
| 1167 |
+
|
| 1168 |
+
rescaled_signal = (
|
| 1169 |
+
(processed_signal - processed_min) / (processed_range + epsilon)
|
| 1170 |
+
) * original_range + original_min
|
| 1171 |
+
|
| 1172 |
+
original_mean = torch.mean(original_signal, dim=-1, keepdim=True)
|
| 1173 |
+
flat_rescaled = original_mean.expand_as(original_signal)
|
| 1174 |
+
|
| 1175 |
+
return torch.where(is_flat, flat_rescaled, rescaled_signal)
|
| 1176 |
+
|
| 1177 |
+
def _apply_random_conv_stack(self, series: torch.Tensor) -> torch.Tensor:
|
| 1178 |
+
"""
|
| 1179 |
+
Applies a randomly configured stack of convolutions to a single time series.
|
| 1180 |
+
|
| 1181 |
+
Args:
|
| 1182 |
+
series (torch.Tensor): A single time series of shape (1, num_channels, seq_len).
|
| 1183 |
+
|
| 1184 |
+
Returns:
|
| 1185 |
+
torch.Tensor: The augmented time series.
|
| 1186 |
+
"""
|
| 1187 |
+
num_channels = series.shape[1]
|
| 1188 |
+
device = series.device
|
| 1189 |
+
|
| 1190 |
+
num_layers = torch.randint(
|
| 1191 |
+
self.layer_range[0], self.layer_range[1] + 1, (1,)
|
| 1192 |
+
).item()
|
| 1193 |
+
|
| 1194 |
+
processed_series = series
|
| 1195 |
+
for i in range(num_layers):
|
| 1196 |
+
# 1. Sample kernel size
|
| 1197 |
+
k_min, k_max = self.kernel_size_range
|
| 1198 |
+
kernel_size = torch.randint(k_min // 2, k_max // 2 + 1, (1,)).item() * 2 + 1
|
| 1199 |
+
|
| 1200 |
+
# 2. Sample dilation
|
| 1201 |
+
d_min, d_max = self.dilation_range
|
| 1202 |
+
dilation = torch.randint(d_min, d_max + 1, (1,)).item()
|
| 1203 |
+
|
| 1204 |
+
# 3. Sample bias
|
| 1205 |
+
b_min, b_max = self.bias_range
|
| 1206 |
+
bias_val = (b_min + (b_max - b_min) * torch.rand(1)).item()
|
| 1207 |
+
|
| 1208 |
+
# 4. Sample padding mode
|
| 1209 |
+
padding_mode = np.random.choice(self.padding_modes)
|
| 1210 |
+
|
| 1211 |
+
conv_layer = nn.Conv1d(
|
| 1212 |
+
in_channels=num_channels,
|
| 1213 |
+
out_channels=num_channels,
|
| 1214 |
+
kernel_size=kernel_size,
|
| 1215 |
+
dilation=dilation,
|
| 1216 |
+
padding="same", # Let PyTorch handle padding calculation
|
| 1217 |
+
padding_mode=padding_mode,
|
| 1218 |
+
groups=num_channels,
|
| 1219 |
+
bias=True,
|
| 1220 |
+
device=device,
|
| 1221 |
+
)
|
| 1222 |
+
|
| 1223 |
+
# 5. Sample kernel weights from a wider variety of types
|
| 1224 |
+
weight_type = torch.randint(0, 4, (1,)).item()
|
| 1225 |
+
if weight_type == 0: # Gaussian kernel
|
| 1226 |
+
s_min, s_max = self.sigma_range
|
| 1227 |
+
sigma = (s_min + (s_max - s_min) * torch.rand(1)).item()
|
| 1228 |
+
ax = torch.arange(
|
| 1229 |
+
-(kernel_size // 2),
|
| 1230 |
+
kernel_size // 2 + 1,
|
| 1231 |
+
device=device,
|
| 1232 |
+
dtype=torch.float32,
|
| 1233 |
+
)
|
| 1234 |
+
kernel = torch.exp(-0.5 * (ax / sigma) ** 2)
|
| 1235 |
+
elif weight_type == 1: # Standard normal kernel
|
| 1236 |
+
kernel = torch.randn(kernel_size, device=device)
|
| 1237 |
+
elif weight_type == 2: # Polynomial kernel
|
| 1238 |
+
coeffs = torch.randn(3, device=device) # a, b, c for ax^2+bx+c
|
| 1239 |
+
x_vals = torch.linspace(-1, 1, kernel_size, device=device)
|
| 1240 |
+
kernel = coeffs[0] * x_vals**2 + coeffs[1] * x_vals + coeffs[2]
|
| 1241 |
+
else: # Noisy Sobel kernel
|
| 1242 |
+
# Ensure kernel is large enough for a Sobel filter
|
| 1243 |
+
actual_kernel_size = 3 if kernel_size < 3 else kernel_size
|
| 1244 |
+
sobel_base = torch.tensor(
|
| 1245 |
+
[-1, 0, 1], dtype=torch.float32, device=device
|
| 1246 |
+
)
|
| 1247 |
+
noise = torch.randn(3, device=device) * 0.1
|
| 1248 |
+
noisy_sobel = sobel_base + noise
|
| 1249 |
+
# Pad if the random kernel size is larger than 3
|
| 1250 |
+
pad_total = actual_kernel_size - 3
|
| 1251 |
+
pad_left = pad_total // 2
|
| 1252 |
+
pad_right = pad_total - pad_left
|
| 1253 |
+
kernel = F.pad(noisy_sobel, (pad_left, pad_right), "constant", 0)
|
| 1254 |
+
|
| 1255 |
+
# 6. Probabilistic normalization
|
| 1256 |
+
if torch.rand(1).item() < 0.8: # 80% chance to normalize
|
| 1257 |
+
kernel /= torch.sum(torch.abs(kernel)) + 1e-8
|
| 1258 |
+
|
| 1259 |
+
kernel = kernel.view(1, 1, -1).repeat(num_channels, 1, 1)
|
| 1260 |
+
|
| 1261 |
+
conv_layer.weight.data = kernel
|
| 1262 |
+
conv_layer.bias.data.fill_(bias_val)
|
| 1263 |
+
conv_layer.weight.requires_grad = False
|
| 1264 |
+
conv_layer.bias.requires_grad = False
|
| 1265 |
+
|
| 1266 |
+
# Apply convolution
|
| 1267 |
+
processed_series = conv_layer(processed_series)
|
| 1268 |
+
|
| 1269 |
+
# 7. Optional non-linearity (not on the last layer)
|
| 1270 |
+
if i < num_layers - 1:
|
| 1271 |
+
activation_type = torch.randint(0, 3, (1,)).item()
|
| 1272 |
+
if activation_type == 1:
|
| 1273 |
+
processed_series = F.relu(processed_series)
|
| 1274 |
+
elif activation_type == 2:
|
| 1275 |
+
processed_series = torch.tanh(processed_series)
|
| 1276 |
+
# if 0, do nothing (linear)
|
| 1277 |
+
|
| 1278 |
+
return processed_series
|
| 1279 |
+
|
| 1280 |
+
def transform(self, time_series_batch: torch.Tensor) -> torch.Tensor:
|
| 1281 |
+
"""Applies a random augmentation to a subset of the batch."""
|
| 1282 |
+
with torch.no_grad():
|
| 1283 |
+
if self.p_transform == 0:
|
| 1284 |
+
return time_series_batch
|
| 1285 |
+
|
| 1286 |
+
batch_size, seq_len, num_channels = time_series_batch.shape
|
| 1287 |
+
device = time_series_batch.device
|
| 1288 |
+
|
| 1289 |
+
augment_mask = torch.rand(batch_size, device=device) < self.p_transform
|
| 1290 |
+
indices_to_augment = torch.where(augment_mask)[0]
|
| 1291 |
+
num_to_augment = indices_to_augment.numel()
|
| 1292 |
+
|
| 1293 |
+
if num_to_augment == 0:
|
| 1294 |
+
return time_series_batch
|
| 1295 |
+
|
| 1296 |
+
subset_to_augment = time_series_batch[indices_to_augment]
|
| 1297 |
+
|
| 1298 |
+
subset_permuted = subset_to_augment.permute(0, 2, 1)
|
| 1299 |
+
|
| 1300 |
+
augmented_subset_list = []
|
| 1301 |
+
for i in range(num_to_augment):
|
| 1302 |
+
original_series = subset_permuted[i : i + 1]
|
| 1303 |
+
augmented_series = self._apply_random_conv_stack(original_series)
|
| 1304 |
+
|
| 1305 |
+
rescaled_series = self._rescale_signal(
|
| 1306 |
+
augmented_series.squeeze(0), original_series.squeeze(0)
|
| 1307 |
+
)
|
| 1308 |
+
augmented_subset_list.append(rescaled_series.unsqueeze(0))
|
| 1309 |
+
|
| 1310 |
+
if augmented_subset_list:
|
| 1311 |
+
augmented_subset = torch.cat(augmented_subset_list, dim=0)
|
| 1312 |
+
augmented_subset_final = augmented_subset.permute(0, 2, 1)
|
| 1313 |
+
|
| 1314 |
+
augmented_batch = time_series_batch.clone()
|
| 1315 |
+
augmented_batch[indices_to_augment] = augmented_subset_final
|
| 1316 |
+
return augmented_batch
|
| 1317 |
+
else:
|
| 1318 |
+
return time_series_batch
|
src/data/batch_composer.py
ADDED
|
@@ -0,0 +1,705 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import logging
|
| 3 |
+
import random
|
| 4 |
+
from typing import Dict, Optional, Tuple
|
| 5 |
+
|
| 6 |
+
import numpy as np
|
| 7 |
+
import pandas as pd
|
| 8 |
+
import torch
|
| 9 |
+
|
| 10 |
+
from src.data.augmentations import (
|
| 11 |
+
NanAugmenter,
|
| 12 |
+
)
|
| 13 |
+
from src.data.constants import DEFAULT_NAN_STATS_PATH, LENGTH_CHOICES, LENGTH_WEIGHTS
|
| 14 |
+
from src.data.containers import BatchTimeSeriesContainer
|
| 15 |
+
from src.data.datasets import CyclicalBatchDataset
|
| 16 |
+
from src.data.frequency import Frequency
|
| 17 |
+
from src.data.scalers import MeanScaler, MedianScaler, MinMaxScaler, RobustScaler
|
| 18 |
+
from src.data.utils import sample_future_length
|
| 19 |
+
|
| 20 |
+
logging.basicConfig(level=logging.INFO)
|
| 21 |
+
logger = logging.getLogger(__name__)
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
class BatchComposer:
|
| 25 |
+
"""
|
| 26 |
+
Composes batches from saved generator data according to specified proportions.
|
| 27 |
+
Manages multiple CyclicalBatchDataset instances and creates uniform or mixed batches.
|
| 28 |
+
"""
|
| 29 |
+
|
| 30 |
+
def __init__(
|
| 31 |
+
self,
|
| 32 |
+
base_data_dir: str,
|
| 33 |
+
generator_proportions: Optional[Dict[str, float]] = None,
|
| 34 |
+
mixed_batches: bool = True,
|
| 35 |
+
device: Optional[torch.device] = None,
|
| 36 |
+
augmentations: Optional[Dict[str, bool]] = None,
|
| 37 |
+
augmentation_probabilities: Optional[Dict[str, float]] = None,
|
| 38 |
+
nan_stats_path: Optional[str] = None,
|
| 39 |
+
nan_patterns_path: Optional[str] = None,
|
| 40 |
+
global_seed: int = 42,
|
| 41 |
+
chosen_scaler_name: Optional[str] = None,
|
| 42 |
+
rank: int = 0,
|
| 43 |
+
world_size: int = 1,
|
| 44 |
+
):
|
| 45 |
+
"""
|
| 46 |
+
Initialize the BatchComposer.
|
| 47 |
+
|
| 48 |
+
Args:
|
| 49 |
+
base_data_dir: Base directory containing generator subdirectories
|
| 50 |
+
generator_proportions: Dict mapping generator names to proportions
|
| 51 |
+
mixed_batches: If True, create mixed batches; if False, uniform batches
|
| 52 |
+
device: Device to load tensors to
|
| 53 |
+
augmentations: Dict mapping augmentation names to booleans
|
| 54 |
+
augmentation_probabilities: Dict mapping augmentation names to probabilities
|
| 55 |
+
global_seed: Global random seed
|
| 56 |
+
chosen_scaler_name: Name of the scaler that used in training
|
| 57 |
+
rank: Rank of current process for distributed data loading
|
| 58 |
+
world_size: Total number of processes for distributed data loading
|
| 59 |
+
"""
|
| 60 |
+
self.base_data_dir = base_data_dir
|
| 61 |
+
self.mixed_batches = mixed_batches
|
| 62 |
+
self.device = device
|
| 63 |
+
self.global_seed = global_seed
|
| 64 |
+
self.nan_stats_path = nan_stats_path
|
| 65 |
+
self.nan_patterns_path = nan_patterns_path
|
| 66 |
+
self.rank = rank
|
| 67 |
+
self.world_size = world_size
|
| 68 |
+
self.augmentation_probabilities = augmentation_probabilities or {
|
| 69 |
+
"noise_augmentation": 0.3,
|
| 70 |
+
"scaler_augmentation": 0.5,
|
| 71 |
+
}
|
| 72 |
+
# Optional preferred scaler name provided by training config
|
| 73 |
+
self.chosen_scaler_name = (
|
| 74 |
+
chosen_scaler_name.lower() if chosen_scaler_name is not None else None
|
| 75 |
+
)
|
| 76 |
+
|
| 77 |
+
# Setup random state
|
| 78 |
+
self.rng = np.random.default_rng(global_seed)
|
| 79 |
+
random.seed(global_seed)
|
| 80 |
+
torch.manual_seed(global_seed)
|
| 81 |
+
|
| 82 |
+
# Setup augmentations
|
| 83 |
+
self._setup_augmentations(augmentations)
|
| 84 |
+
|
| 85 |
+
# Setup generator proportions
|
| 86 |
+
self._setup_proportions(generator_proportions)
|
| 87 |
+
|
| 88 |
+
# Initialize datasets
|
| 89 |
+
self.datasets = self._initialize_datasets()
|
| 90 |
+
|
| 91 |
+
logger.info(
|
| 92 |
+
f"Initialized BatchComposer with {len(self.datasets)} generators, "
|
| 93 |
+
f"mixed_batches={mixed_batches}, proportions={self.generator_proportions}, "
|
| 94 |
+
f"augmentations={self.augmentations}, "
|
| 95 |
+
f"augmentation_probabilities={self.augmentation_probabilities}"
|
| 96 |
+
)
|
| 97 |
+
|
| 98 |
+
def _setup_augmentations(self, augmentations: Optional[Dict[str, bool]]):
|
| 99 |
+
"""Setup only the augmentations that should remain online (NaN)."""
|
| 100 |
+
default_augmentations = {
|
| 101 |
+
"nan_augmentation": False,
|
| 102 |
+
"scaler_augmentation": False,
|
| 103 |
+
"length_shortening": False,
|
| 104 |
+
}
|
| 105 |
+
|
| 106 |
+
self.augmentations = augmentations or default_augmentations
|
| 107 |
+
|
| 108 |
+
# Initialize NaN augmenter if needed
|
| 109 |
+
self.nan_augmenter = None
|
| 110 |
+
if self.augmentations.get("nan_augmentation", False):
|
| 111 |
+
stats_path_to_use = self.nan_stats_path or DEFAULT_NAN_STATS_PATH
|
| 112 |
+
stats = json.load(open(stats_path_to_use, "r"))
|
| 113 |
+
self.nan_augmenter = NanAugmenter(
|
| 114 |
+
p_series_has_nan=stats["p_series_has_nan"],
|
| 115 |
+
nan_ratio_distribution=stats["nan_ratio_distribution"],
|
| 116 |
+
nan_length_distribution=stats["nan_length_distribution"],
|
| 117 |
+
nan_patterns_path=self.nan_patterns_path,
|
| 118 |
+
)
|
| 119 |
+
|
| 120 |
+
def _should_apply_scaler_augmentation(self) -> bool:
|
| 121 |
+
"""
|
| 122 |
+
Decide whether to apply scaler augmentation for a single series based on
|
| 123 |
+
the boolean toggle and probability from the configuration.
|
| 124 |
+
"""
|
| 125 |
+
if not self.augmentations.get("scaler_augmentation", False):
|
| 126 |
+
return False
|
| 127 |
+
probability = float(
|
| 128 |
+
self.augmentation_probabilities.get("scaler_augmentation", 0.0)
|
| 129 |
+
)
|
| 130 |
+
probability = max(0.0, min(1.0, probability))
|
| 131 |
+
return bool(self.rng.random() < probability)
|
| 132 |
+
|
| 133 |
+
def _choose_random_scaler(self) -> Optional[object]:
|
| 134 |
+
"""
|
| 135 |
+
Choose a random scaler for augmentation, explicitly avoiding the one that
|
| 136 |
+
is already selected in the training configuration (if any).
|
| 137 |
+
|
| 138 |
+
Returns an instance of the selected scaler or None when no valid option exists.
|
| 139 |
+
"""
|
| 140 |
+
chosen: Optional[str] = None
|
| 141 |
+
if self.chosen_scaler_name is not None:
|
| 142 |
+
chosen = self.chosen_scaler_name.strip().lower()
|
| 143 |
+
|
| 144 |
+
candidates = ["custom_robust", "minmax", "median", "mean"]
|
| 145 |
+
|
| 146 |
+
# Remove the chosen scaler from the candidates
|
| 147 |
+
if chosen in candidates:
|
| 148 |
+
candidates = [c for c in candidates if c != chosen]
|
| 149 |
+
if not candidates:
|
| 150 |
+
return None
|
| 151 |
+
|
| 152 |
+
pick = str(self.rng.choice(candidates))
|
| 153 |
+
if pick == "custom_robust":
|
| 154 |
+
return RobustScaler()
|
| 155 |
+
if pick == "minmax":
|
| 156 |
+
return MinMaxScaler()
|
| 157 |
+
if pick == "median":
|
| 158 |
+
return MedianScaler()
|
| 159 |
+
if pick == "mean":
|
| 160 |
+
return MeanScaler()
|
| 161 |
+
return None
|
| 162 |
+
|
| 163 |
+
def _setup_proportions(self, generator_proportions):
|
| 164 |
+
"""Setup default or custom generator proportions."""
|
| 165 |
+
default_proportions = {
|
| 166 |
+
"forecast_pfn": 1.0,
|
| 167 |
+
"gp": 1.0,
|
| 168 |
+
"kernel": 1.0,
|
| 169 |
+
"sinewave": 1.0,
|
| 170 |
+
"sawtooth": 1.0,
|
| 171 |
+
"step": 0.1,
|
| 172 |
+
"anomaly": 1.0,
|
| 173 |
+
"spike": 2.0,
|
| 174 |
+
"cauker_univariate": 2.0,
|
| 175 |
+
"cauker_multivariate": 0.00,
|
| 176 |
+
"lmc": 0.00, # multivariate
|
| 177 |
+
"ou_process": 1.0,
|
| 178 |
+
"audio_financial_volatility": 0.1,
|
| 179 |
+
"audio_multi_scale_fractal": 0.1,
|
| 180 |
+
"audio_network_topology": 0.5,
|
| 181 |
+
"audio_stochastic_rhythm": 1.0,
|
| 182 |
+
"augmented_per_sample_2048": 3.0,
|
| 183 |
+
"augmented_temp_batch_2048": 3.0,
|
| 184 |
+
}
|
| 185 |
+
self.generator_proportions = generator_proportions or default_proportions
|
| 186 |
+
|
| 187 |
+
# Normalize proportions
|
| 188 |
+
total = sum(self.generator_proportions.values())
|
| 189 |
+
if total <= 0:
|
| 190 |
+
raise ValueError("Total generator proportions must be positive")
|
| 191 |
+
self.generator_proportions = {
|
| 192 |
+
k: v / total for k, v in self.generator_proportions.items()
|
| 193 |
+
}
|
| 194 |
+
|
| 195 |
+
def _initialize_datasets(self) -> Dict[str, CyclicalBatchDataset]:
|
| 196 |
+
"""Initialize CyclicalBatchDataset for each generator with proportion > 0."""
|
| 197 |
+
datasets = {}
|
| 198 |
+
|
| 199 |
+
for generator_name, proportion in self.generator_proportions.items():
|
| 200 |
+
# Only initialize datasets for generators with positive proportion
|
| 201 |
+
if proportion <= 0:
|
| 202 |
+
logger.info(f"Skipping {generator_name} (proportion = {proportion})")
|
| 203 |
+
continue
|
| 204 |
+
|
| 205 |
+
batches_dir = f"{self.base_data_dir}/{generator_name}"
|
| 206 |
+
|
| 207 |
+
try:
|
| 208 |
+
dataset = CyclicalBatchDataset(
|
| 209 |
+
batches_dir=batches_dir,
|
| 210 |
+
generator_type=generator_name,
|
| 211 |
+
device=None,
|
| 212 |
+
prefetch_next=True,
|
| 213 |
+
prefetch_threshold=32,
|
| 214 |
+
rank=self.rank,
|
| 215 |
+
world_size=self.world_size,
|
| 216 |
+
)
|
| 217 |
+
datasets[generator_name] = dataset
|
| 218 |
+
logger.info(
|
| 219 |
+
f"Loaded dataset for {generator_name} (proportion = {proportion})"
|
| 220 |
+
)
|
| 221 |
+
|
| 222 |
+
except Exception as e:
|
| 223 |
+
logger.warning(f"Failed to load dataset for {generator_name}: {e}")
|
| 224 |
+
continue
|
| 225 |
+
|
| 226 |
+
if not datasets:
|
| 227 |
+
raise ValueError(
|
| 228 |
+
f"No valid datasets found in {self.base_data_dir} or all generators have proportion <= 0"
|
| 229 |
+
)
|
| 230 |
+
|
| 231 |
+
return datasets
|
| 232 |
+
|
| 233 |
+
def _convert_sample_to_tensors(
|
| 234 |
+
self, sample: dict, future_length: Optional[int] = None
|
| 235 |
+
) -> Tuple[torch.Tensor, np.datetime64, Frequency]:
|
| 236 |
+
"""
|
| 237 |
+
Convert a sample dict to tensors and metadata.
|
| 238 |
+
|
| 239 |
+
Args:
|
| 240 |
+
sample: Sample dict from CyclicalBatchDataset
|
| 241 |
+
future_length: Desired future length (if None, use default split)
|
| 242 |
+
|
| 243 |
+
Returns:
|
| 244 |
+
Tuple of (history_values, future_values, start, frequency)
|
| 245 |
+
"""
|
| 246 |
+
# Handle both old and new data formats
|
| 247 |
+
num_channels = sample.get("num_channels", 1)
|
| 248 |
+
values_data = sample["values"]
|
| 249 |
+
generator_type = sample.get("generator_type", "unknown")
|
| 250 |
+
|
| 251 |
+
if num_channels == 1:
|
| 252 |
+
# Univariate data
|
| 253 |
+
if isinstance(values_data[0], list):
|
| 254 |
+
# New format: [[channel_values]]
|
| 255 |
+
values = torch.tensor(values_data[0], dtype=torch.float32)
|
| 256 |
+
logger.debug(
|
| 257 |
+
f"{generator_type}: Using new univariate format, shape: {values.shape}"
|
| 258 |
+
)
|
| 259 |
+
else:
|
| 260 |
+
# Old format: [values]
|
| 261 |
+
values = torch.tensor(values_data, dtype=torch.float32)
|
| 262 |
+
values = values.unsqueeze(0).unsqueeze(-1) # Shape: [1, seq_len, 1]
|
| 263 |
+
else:
|
| 264 |
+
# Multivariate data (LMC) - new format: [[ch1_values], [ch2_values], ...]
|
| 265 |
+
channel_tensors = []
|
| 266 |
+
for channel_values in values_data:
|
| 267 |
+
channel_tensor = torch.tensor(channel_values, dtype=torch.float32)
|
| 268 |
+
channel_tensors.append(channel_tensor)
|
| 269 |
+
|
| 270 |
+
# Stack channels: [1, seq_len, num_channels]
|
| 271 |
+
values = torch.stack(channel_tensors, dim=-1).unsqueeze(0)
|
| 272 |
+
logger.debug(
|
| 273 |
+
f"{generator_type}: Using multivariate format, {num_channels} channels, shape: {values.shape}"
|
| 274 |
+
)
|
| 275 |
+
|
| 276 |
+
# Handle frequency conversion
|
| 277 |
+
freq_str = sample["frequency"]
|
| 278 |
+
try:
|
| 279 |
+
frequency = Frequency(freq_str)
|
| 280 |
+
except ValueError:
|
| 281 |
+
# Map common frequency strings to Frequency enum
|
| 282 |
+
freq_mapping = {
|
| 283 |
+
"h": Frequency.H,
|
| 284 |
+
"D": Frequency.D,
|
| 285 |
+
"W": Frequency.W,
|
| 286 |
+
"M": Frequency.M,
|
| 287 |
+
"Q": Frequency.Q,
|
| 288 |
+
"A": Frequency.A,
|
| 289 |
+
"Y": Frequency.A, # Annual
|
| 290 |
+
"1min": Frequency.T1,
|
| 291 |
+
"5min": Frequency.T5,
|
| 292 |
+
"10min": Frequency.T10,
|
| 293 |
+
"15min": Frequency.T15,
|
| 294 |
+
"30min": Frequency.T30,
|
| 295 |
+
"s": Frequency.S,
|
| 296 |
+
}
|
| 297 |
+
frequency = freq_mapping.get(freq_str, Frequency.H) # Default to hourly
|
| 298 |
+
|
| 299 |
+
# Handle start timestamp
|
| 300 |
+
if isinstance(sample["start"], pd.Timestamp):
|
| 301 |
+
start = sample["start"].to_numpy()
|
| 302 |
+
else:
|
| 303 |
+
start = np.datetime64(sample["start"])
|
| 304 |
+
|
| 305 |
+
return values, start, frequency
|
| 306 |
+
|
| 307 |
+
def _effective_proportions_for_length(
|
| 308 |
+
self, total_length_for_batch: int
|
| 309 |
+
) -> Dict[str, float]:
|
| 310 |
+
"""
|
| 311 |
+
Build a simple, length-aware proportion map for the current batch.
|
| 312 |
+
|
| 313 |
+
Rules:
|
| 314 |
+
- For generators named 'augmented{L}', keep only the one matching the
|
| 315 |
+
chosen length L; zero out others.
|
| 316 |
+
- Keep non-augmented generators as-is.
|
| 317 |
+
- Drop generators that are unavailable (not loaded) or zero-weight.
|
| 318 |
+
- If nothing remains, fall back to 'augmented{L}' if available, else any dataset.
|
| 319 |
+
- Normalize the final map to sum to 1.
|
| 320 |
+
"""
|
| 321 |
+
|
| 322 |
+
def augmented_length_from_name(name: str) -> Optional[int]:
|
| 323 |
+
if not name.startswith("augmented"):
|
| 324 |
+
return None
|
| 325 |
+
suffix = name[len("augmented") :]
|
| 326 |
+
if not suffix:
|
| 327 |
+
return None
|
| 328 |
+
try:
|
| 329 |
+
return int(suffix)
|
| 330 |
+
except ValueError:
|
| 331 |
+
return None
|
| 332 |
+
|
| 333 |
+
# 1) Adjust proportions with the length-aware rule
|
| 334 |
+
adjusted: Dict[str, float] = {}
|
| 335 |
+
for name, proportion in self.generator_proportions.items():
|
| 336 |
+
aug_len = augmented_length_from_name(name)
|
| 337 |
+
if aug_len is None:
|
| 338 |
+
adjusted[name] = proportion
|
| 339 |
+
else:
|
| 340 |
+
adjusted[name] = (
|
| 341 |
+
proportion if aug_len == total_length_for_batch else 0.0
|
| 342 |
+
)
|
| 343 |
+
|
| 344 |
+
# 2) Keep only available, positive-weight datasets
|
| 345 |
+
adjusted = {
|
| 346 |
+
name: p for name, p in adjusted.items() if name in self.datasets and p > 0.0
|
| 347 |
+
}
|
| 348 |
+
|
| 349 |
+
# 3) Fallback if empty
|
| 350 |
+
if not adjusted:
|
| 351 |
+
preferred = f"augmented{total_length_for_batch}"
|
| 352 |
+
if preferred in self.datasets:
|
| 353 |
+
adjusted = {preferred: 1.0}
|
| 354 |
+
elif self.datasets:
|
| 355 |
+
# Choose any available dataset deterministically (first key)
|
| 356 |
+
first_key = next(iter(self.datasets.keys()))
|
| 357 |
+
adjusted = {first_key: 1.0}
|
| 358 |
+
else:
|
| 359 |
+
raise ValueError("No datasets available to create batch")
|
| 360 |
+
|
| 361 |
+
# 4) Normalize
|
| 362 |
+
total = sum(adjusted.values())
|
| 363 |
+
return {name: p / total for name, p in adjusted.items()}
|
| 364 |
+
|
| 365 |
+
def _compute_sample_counts_for_batch(
|
| 366 |
+
self, proportions: Dict[str, float], batch_size: int
|
| 367 |
+
) -> Dict[str, int]:
|
| 368 |
+
"""
|
| 369 |
+
Convert a proportion map into integer sample counts that sum to batch_size.
|
| 370 |
+
|
| 371 |
+
Strategy: allocate floor(batch_size * p) to each generator in order, and let the
|
| 372 |
+
last generator absorb any remainder to ensure the total matches exactly.
|
| 373 |
+
"""
|
| 374 |
+
counts: Dict[str, int] = {}
|
| 375 |
+
remaining = batch_size
|
| 376 |
+
names = list(proportions.keys())
|
| 377 |
+
values = list(proportions.values())
|
| 378 |
+
for index, (name, p) in enumerate(zip(names, values)):
|
| 379 |
+
if index == len(names) - 1:
|
| 380 |
+
counts[name] = remaining
|
| 381 |
+
else:
|
| 382 |
+
n = int(batch_size * p)
|
| 383 |
+
counts[name] = n
|
| 384 |
+
remaining -= n
|
| 385 |
+
return counts
|
| 386 |
+
|
| 387 |
+
def _calculate_generator_samples(self, batch_size: int) -> Dict[str, int]:
|
| 388 |
+
"""
|
| 389 |
+
Calculate the number of samples each generator should contribute.
|
| 390 |
+
|
| 391 |
+
Args:
|
| 392 |
+
batch_size: Total batch size
|
| 393 |
+
|
| 394 |
+
Returns:
|
| 395 |
+
Dict mapping generator names to sample counts
|
| 396 |
+
"""
|
| 397 |
+
generator_samples = {}
|
| 398 |
+
remaining_samples = batch_size
|
| 399 |
+
|
| 400 |
+
generators = list(self.generator_proportions.keys())
|
| 401 |
+
proportions = list(self.generator_proportions.values())
|
| 402 |
+
|
| 403 |
+
# Calculate base samples for each generator
|
| 404 |
+
for i, (generator, proportion) in enumerate(zip(generators, proportions)):
|
| 405 |
+
if generator not in self.datasets:
|
| 406 |
+
continue
|
| 407 |
+
|
| 408 |
+
if i == len(generators) - 1: # Last generator gets remaining samples
|
| 409 |
+
samples = remaining_samples
|
| 410 |
+
else:
|
| 411 |
+
samples = int(batch_size * proportion)
|
| 412 |
+
remaining_samples -= samples
|
| 413 |
+
generator_samples[generator] = samples
|
| 414 |
+
|
| 415 |
+
return generator_samples
|
| 416 |
+
|
| 417 |
+
def create_batch(
|
| 418 |
+
self,
|
| 419 |
+
batch_size: int = 128,
|
| 420 |
+
seed: Optional[int] = None,
|
| 421 |
+
future_length: Optional[int] = None,
|
| 422 |
+
) -> Tuple[BatchTimeSeriesContainer, str]:
|
| 423 |
+
"""
|
| 424 |
+
Create a batch of the specified size.
|
| 425 |
+
|
| 426 |
+
Args:
|
| 427 |
+
batch_size: Size of the batch to create
|
| 428 |
+
seed: Random seed for this batch
|
| 429 |
+
future_length: Fixed future length to use. If None, samples from gift_eval range
|
| 430 |
+
|
| 431 |
+
Returns:
|
| 432 |
+
Tuple of (batch_container, generator_info)
|
| 433 |
+
"""
|
| 434 |
+
if seed is not None:
|
| 435 |
+
batch_rng = np.random.default_rng(seed)
|
| 436 |
+
random.seed(seed)
|
| 437 |
+
else:
|
| 438 |
+
batch_rng = self.rng
|
| 439 |
+
|
| 440 |
+
if self.mixed_batches:
|
| 441 |
+
return self._create_mixed_batch(batch_size, future_length)
|
| 442 |
+
else:
|
| 443 |
+
return self._create_uniform_batch(batch_size, batch_rng, future_length)
|
| 444 |
+
|
| 445 |
+
def _create_mixed_batch(
|
| 446 |
+
self, batch_size: int, future_length: Optional[int] = None
|
| 447 |
+
) -> Tuple[BatchTimeSeriesContainer, str]:
|
| 448 |
+
"""Create a mixed batch with samples from multiple generators, rejecting NaNs."""
|
| 449 |
+
|
| 450 |
+
# Choose total length for this batch; respect length_shortening flag.
|
| 451 |
+
# When disabled, always use the maximum to avoid shortening.
|
| 452 |
+
if self.augmentations.get("length_shortening", False):
|
| 453 |
+
lengths = list(LENGTH_WEIGHTS.keys())
|
| 454 |
+
probs = list(LENGTH_WEIGHTS.values())
|
| 455 |
+
total_length_for_batch = int(self.rng.choice(lengths, p=probs))
|
| 456 |
+
else:
|
| 457 |
+
total_length_for_batch = int(max(LENGTH_CHOICES))
|
| 458 |
+
|
| 459 |
+
if future_length is None:
|
| 460 |
+
prediction_length = int(
|
| 461 |
+
sample_future_length(
|
| 462 |
+
range="gift_eval", total_length=total_length_for_batch
|
| 463 |
+
)
|
| 464 |
+
)
|
| 465 |
+
else:
|
| 466 |
+
prediction_length = future_length
|
| 467 |
+
|
| 468 |
+
history_length = total_length_for_batch - prediction_length
|
| 469 |
+
|
| 470 |
+
# Calculate samples per generator using simple, per-batch length-aware proportions
|
| 471 |
+
effective_props = self._effective_proportions_for_length(total_length_for_batch)
|
| 472 |
+
generator_samples = self._compute_sample_counts_for_batch(
|
| 473 |
+
effective_props, batch_size
|
| 474 |
+
)
|
| 475 |
+
|
| 476 |
+
all_values = []
|
| 477 |
+
all_starts = []
|
| 478 |
+
all_frequencies = []
|
| 479 |
+
actual_proportions = {}
|
| 480 |
+
|
| 481 |
+
# Collect valid samples from each generator using batched fetches to reduce I/O overhead
|
| 482 |
+
for generator_name, num_samples in generator_samples.items():
|
| 483 |
+
if num_samples == 0 or generator_name not in self.datasets:
|
| 484 |
+
continue
|
| 485 |
+
|
| 486 |
+
dataset = self.datasets[generator_name]
|
| 487 |
+
|
| 488 |
+
# Lists to hold valid samples for the current generator
|
| 489 |
+
generator_values = []
|
| 490 |
+
generator_starts = []
|
| 491 |
+
generator_frequencies = []
|
| 492 |
+
|
| 493 |
+
# Loop until we have collected the required number of VALID samples
|
| 494 |
+
max_attempts = 50
|
| 495 |
+
attempts = 0
|
| 496 |
+
while len(generator_values) < num_samples and attempts < max_attempts:
|
| 497 |
+
attempts += 1
|
| 498 |
+
# Fetch a batch larger than needed to reduce round-trips
|
| 499 |
+
need = num_samples - len(generator_values)
|
| 500 |
+
fetch_n = max(need * 2, 8)
|
| 501 |
+
samples = dataset.get_samples(fetch_n)
|
| 502 |
+
|
| 503 |
+
for sample in samples:
|
| 504 |
+
if len(generator_values) >= num_samples:
|
| 505 |
+
break
|
| 506 |
+
|
| 507 |
+
values, sample_start, sample_freq = self._convert_sample_to_tensors(
|
| 508 |
+
sample, future_length
|
| 509 |
+
)
|
| 510 |
+
|
| 511 |
+
# Skip if NaNs exist (we inject NaNs later in history only)
|
| 512 |
+
if torch.isnan(values).any():
|
| 513 |
+
continue
|
| 514 |
+
|
| 515 |
+
# Resize to target batch length when longer
|
| 516 |
+
if total_length_for_batch < values.shape[1]:
|
| 517 |
+
strategy = self.rng.choice(["cut", "subsample"]) # 50/50
|
| 518 |
+
if strategy == "cut":
|
| 519 |
+
max_start_idx = values.shape[1] - total_length_for_batch
|
| 520 |
+
start_idx = int(self.rng.integers(0, max_start_idx + 1))
|
| 521 |
+
values = values[
|
| 522 |
+
:, start_idx : start_idx + total_length_for_batch, :
|
| 523 |
+
]
|
| 524 |
+
else:
|
| 525 |
+
indices = np.linspace(
|
| 526 |
+
0,
|
| 527 |
+
values.shape[1] - 1,
|
| 528 |
+
total_length_for_batch,
|
| 529 |
+
dtype=int,
|
| 530 |
+
)
|
| 531 |
+
values = values[:, indices, :]
|
| 532 |
+
|
| 533 |
+
# Optionally apply scaler augmentation according to configuration
|
| 534 |
+
if self._should_apply_scaler_augmentation():
|
| 535 |
+
scaler = self._choose_random_scaler()
|
| 536 |
+
if scaler is not None:
|
| 537 |
+
values = scaler.scale(
|
| 538 |
+
values, scaler.compute_statistics(values)
|
| 539 |
+
)
|
| 540 |
+
|
| 541 |
+
generator_values.append(values)
|
| 542 |
+
generator_starts.append(sample_start)
|
| 543 |
+
generator_frequencies.append(sample_freq)
|
| 544 |
+
|
| 545 |
+
if len(generator_values) < num_samples:
|
| 546 |
+
logger.warning(
|
| 547 |
+
f"Generator {generator_name}: collected {len(generator_values)}/{num_samples} after {attempts} attempts"
|
| 548 |
+
)
|
| 549 |
+
|
| 550 |
+
# Add the collected valid samples to the main batch lists
|
| 551 |
+
if generator_values:
|
| 552 |
+
all_values.extend(generator_values)
|
| 553 |
+
all_starts.extend(generator_starts)
|
| 554 |
+
all_frequencies.extend(generator_frequencies)
|
| 555 |
+
actual_proportions[generator_name] = len(generator_values)
|
| 556 |
+
|
| 557 |
+
if not all_values:
|
| 558 |
+
raise RuntimeError(
|
| 559 |
+
"No valid samples could be collected from any generator."
|
| 560 |
+
)
|
| 561 |
+
|
| 562 |
+
combined_values = torch.cat(all_values, dim=0)
|
| 563 |
+
# Split into history and future
|
| 564 |
+
combined_history = combined_values[:, :history_length, :]
|
| 565 |
+
combined_future = combined_values[
|
| 566 |
+
:, history_length : history_length + prediction_length, :
|
| 567 |
+
]
|
| 568 |
+
|
| 569 |
+
if self.nan_augmenter is not None:
|
| 570 |
+
combined_history = self.nan_augmenter.transform(combined_history)
|
| 571 |
+
|
| 572 |
+
# Create container
|
| 573 |
+
container = BatchTimeSeriesContainer(
|
| 574 |
+
history_values=combined_history,
|
| 575 |
+
future_values=combined_future,
|
| 576 |
+
start=all_starts,
|
| 577 |
+
frequency=all_frequencies,
|
| 578 |
+
)
|
| 579 |
+
|
| 580 |
+
return container, "MixedBatch"
|
| 581 |
+
|
| 582 |
+
def _create_uniform_batch(
|
| 583 |
+
self,
|
| 584 |
+
batch_size: int,
|
| 585 |
+
batch_rng: np.random.Generator,
|
| 586 |
+
future_length: Optional[int] = None,
|
| 587 |
+
) -> Tuple[BatchTimeSeriesContainer, str]:
|
| 588 |
+
"""Create a uniform batch with samples from a single generator."""
|
| 589 |
+
|
| 590 |
+
# Select generator based on proportions
|
| 591 |
+
generators = list(self.datasets.keys())
|
| 592 |
+
proportions = [self.generator_proportions[gen] for gen in generators]
|
| 593 |
+
selected_generator = batch_rng.choice(generators, p=proportions)
|
| 594 |
+
|
| 595 |
+
# Sample future length
|
| 596 |
+
if future_length is None:
|
| 597 |
+
future_length = sample_future_length(range="gift_eval")
|
| 598 |
+
|
| 599 |
+
# Get samples from selected generator
|
| 600 |
+
dataset = self.datasets[selected_generator]
|
| 601 |
+
samples = dataset.get_samples(batch_size)
|
| 602 |
+
|
| 603 |
+
all_history_values = []
|
| 604 |
+
all_future_values = []
|
| 605 |
+
all_starts = []
|
| 606 |
+
all_frequencies = []
|
| 607 |
+
|
| 608 |
+
for sample in samples:
|
| 609 |
+
values, sample_start, sample_freq = self._convert_sample_to_tensors(
|
| 610 |
+
sample, future_length
|
| 611 |
+
)
|
| 612 |
+
|
| 613 |
+
total_length = values.shape[1]
|
| 614 |
+
history_length = max(1, total_length - future_length)
|
| 615 |
+
|
| 616 |
+
# Optionally apply scaler augmentation according to configuration
|
| 617 |
+
if self._should_apply_scaler_augmentation():
|
| 618 |
+
scaler = self._choose_random_scaler()
|
| 619 |
+
if scaler is not None:
|
| 620 |
+
values = scaler.scale(values, scaler.compute_statistics(values))
|
| 621 |
+
|
| 622 |
+
# Reshape to [1, seq_len, 1] for single sample
|
| 623 |
+
hist_vals = values[:, :history_length, :]
|
| 624 |
+
fut_vals = values[:, history_length : history_length + future_length, :]
|
| 625 |
+
|
| 626 |
+
all_history_values.append(hist_vals)
|
| 627 |
+
all_future_values.append(fut_vals)
|
| 628 |
+
all_starts.append(sample_start)
|
| 629 |
+
all_frequencies.append(sample_freq)
|
| 630 |
+
|
| 631 |
+
# Combine samples
|
| 632 |
+
combined_history = torch.cat(all_history_values, dim=0)
|
| 633 |
+
combined_future = torch.cat(all_future_values, dim=0)
|
| 634 |
+
|
| 635 |
+
# Create container
|
| 636 |
+
container = BatchTimeSeriesContainer(
|
| 637 |
+
history_values=combined_history,
|
| 638 |
+
future_values=combined_future,
|
| 639 |
+
start=all_starts,
|
| 640 |
+
frequency=all_frequencies,
|
| 641 |
+
)
|
| 642 |
+
|
| 643 |
+
return container, selected_generator
|
| 644 |
+
|
| 645 |
+
def get_dataset_info(self) -> Dict[str, dict]:
|
| 646 |
+
"""Get information about all datasets."""
|
| 647 |
+
info = {}
|
| 648 |
+
for name, dataset in self.datasets.items():
|
| 649 |
+
info[name] = dataset.get_info()
|
| 650 |
+
return info
|
| 651 |
+
|
| 652 |
+
def get_generator_info(self) -> Dict[str, any]:
|
| 653 |
+
"""Get information about the composer configuration."""
|
| 654 |
+
return {
|
| 655 |
+
"mixed_batches": self.mixed_batches,
|
| 656 |
+
"generator_proportions": self.generator_proportions,
|
| 657 |
+
"active_generators": list(self.datasets.keys()),
|
| 658 |
+
"total_generators": len(self.datasets),
|
| 659 |
+
"augmentations": self.augmentations,
|
| 660 |
+
"augmentation_probabilities": self.augmentation_probabilities,
|
| 661 |
+
"nan_augmenter_enabled": self.nan_augmenter is not None,
|
| 662 |
+
}
|
| 663 |
+
|
| 664 |
+
|
| 665 |
+
class ComposedDataset(torch.utils.data.Dataset):
|
| 666 |
+
"""
|
| 667 |
+
PyTorch Dataset wrapper around BatchComposer for training pipeline integration.
|
| 668 |
+
"""
|
| 669 |
+
|
| 670 |
+
def __init__(
|
| 671 |
+
self,
|
| 672 |
+
batch_composer: BatchComposer,
|
| 673 |
+
num_batches_per_epoch: int = 100,
|
| 674 |
+
batch_size: int = 128,
|
| 675 |
+
):
|
| 676 |
+
"""
|
| 677 |
+
Initialize the dataset.
|
| 678 |
+
|
| 679 |
+
Args:
|
| 680 |
+
batch_composer: The BatchComposer instance
|
| 681 |
+
num_batches_per_epoch: Number of batches to generate per epoch
|
| 682 |
+
batch_size: Size of each batch
|
| 683 |
+
"""
|
| 684 |
+
self.batch_composer = batch_composer
|
| 685 |
+
self.num_batches_per_epoch = num_batches_per_epoch
|
| 686 |
+
self.batch_size = batch_size
|
| 687 |
+
|
| 688 |
+
def __len__(self) -> int:
|
| 689 |
+
return self.num_batches_per_epoch
|
| 690 |
+
|
| 691 |
+
def __getitem__(self, idx: int) -> BatchTimeSeriesContainer:
|
| 692 |
+
"""
|
| 693 |
+
Get a batch by index.
|
| 694 |
+
|
| 695 |
+
Args:
|
| 696 |
+
idx: Batch index (used as seed for reproducibility)
|
| 697 |
+
|
| 698 |
+
Returns:
|
| 699 |
+
BatchTimeSeriesContainer
|
| 700 |
+
"""
|
| 701 |
+
# Use index as seed for reproducible batches
|
| 702 |
+
batch, _ = self.batch_composer.create_batch(
|
| 703 |
+
batch_size=self.batch_size, seed=self.batch_composer.global_seed + idx
|
| 704 |
+
)
|
| 705 |
+
return batch
|
src/data/constants.py
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from datetime import date
|
| 2 |
+
from typing import Dict
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
|
| 6 |
+
DEFAULT_START_DATE = date(1700, 1, 1)
|
| 7 |
+
DEFAULT_END_DATE = date(2200, 1, 1)
|
| 8 |
+
BASE_START_DATE = np.datetime64(DEFAULT_START_DATE)
|
| 9 |
+
BASE_END_DATE = np.datetime64(DEFAULT_END_DATE)
|
| 10 |
+
|
| 11 |
+
# Maximum years to prevent timestamp overflow
|
| 12 |
+
MAX_YEARS = 500
|
| 13 |
+
|
| 14 |
+
LENGTH_CHOICES = [128, 256, 512, 1024, 1536, 2048]
|
| 15 |
+
|
| 16 |
+
DEFAULT_NAN_STATS_PATH: str = "./data/nan_stats.json"
|
| 17 |
+
|
| 18 |
+
LENGTH_WEIGHTS: Dict[int, float] = {
|
| 19 |
+
128: 0.05,
|
| 20 |
+
256: 0.10,
|
| 21 |
+
512: 0.10,
|
| 22 |
+
1024: 0.10,
|
| 23 |
+
1536: 0.15,
|
| 24 |
+
2048: 0.50,
|
| 25 |
+
}
|
src/data/containers.py
ADDED
|
@@ -0,0 +1,204 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dataclasses import dataclass
|
| 2 |
+
from typing import List, Optional
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
|
| 7 |
+
from src.data.frequency import Frequency
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
@dataclass
|
| 11 |
+
class BatchTimeSeriesContainer:
|
| 12 |
+
"""
|
| 13 |
+
Container for a batch of multivariate time series data and their associated features.
|
| 14 |
+
|
| 15 |
+
Attributes:
|
| 16 |
+
history_values: Tensor of historical observations.
|
| 17 |
+
Shape: [batch_size, seq_len, num_channels]
|
| 18 |
+
future_values: Tensor of future observations to predict.
|
| 19 |
+
Shape: [batch_size, pred_len, num_channels]
|
| 20 |
+
start: Timestamp of the first history value.
|
| 21 |
+
Type: List[np.datetime64]
|
| 22 |
+
frequency: Frequency of the time series.
|
| 23 |
+
Type: List[Frequency]
|
| 24 |
+
history_mask: Optional boolean/float tensor indicating missing entries in history_values across channels.
|
| 25 |
+
Shape: [batch_size, seq_len]
|
| 26 |
+
future_mask: Optional boolean/float tensor indicating missing entries in future_values across channels.
|
| 27 |
+
Shape: [batch_size, pred_len]
|
| 28 |
+
"""
|
| 29 |
+
|
| 30 |
+
history_values: torch.Tensor
|
| 31 |
+
future_values: torch.Tensor
|
| 32 |
+
start: List[np.datetime64]
|
| 33 |
+
frequency: List[Frequency]
|
| 34 |
+
|
| 35 |
+
history_mask: Optional[torch.Tensor] = None
|
| 36 |
+
future_mask: Optional[torch.Tensor] = None
|
| 37 |
+
|
| 38 |
+
def __post_init__(self):
|
| 39 |
+
"""Validate all tensor shapes and consistency."""
|
| 40 |
+
# --- Tensor Type Checks ---
|
| 41 |
+
if not isinstance(self.history_values, torch.Tensor):
|
| 42 |
+
raise TypeError("history_values must be a torch.Tensor")
|
| 43 |
+
if not isinstance(self.future_values, torch.Tensor):
|
| 44 |
+
raise TypeError("future_values must be a torch.Tensor")
|
| 45 |
+
if not isinstance(self.start, list) or not all(
|
| 46 |
+
isinstance(x, np.datetime64) for x in self.start
|
| 47 |
+
):
|
| 48 |
+
raise TypeError("start must be a List[np.datetime64]")
|
| 49 |
+
if not isinstance(self.frequency, list) or not all(
|
| 50 |
+
isinstance(x, Frequency) for x in self.frequency
|
| 51 |
+
):
|
| 52 |
+
raise TypeError("frequency must be a List[Frequency]")
|
| 53 |
+
|
| 54 |
+
batch_size, seq_len, num_channels = self.history_values.shape
|
| 55 |
+
pred_len = self.future_values.shape[1]
|
| 56 |
+
|
| 57 |
+
# --- Core Shape Checks ---
|
| 58 |
+
if self.future_values.shape[0] != batch_size:
|
| 59 |
+
raise ValueError("Batch size mismatch between history and future_values")
|
| 60 |
+
if self.future_values.shape[2] != num_channels:
|
| 61 |
+
raise ValueError("Channel size mismatch between history and future_values")
|
| 62 |
+
|
| 63 |
+
# --- Optional Mask Checks ---
|
| 64 |
+
if self.history_mask is not None:
|
| 65 |
+
if not isinstance(self.history_mask, torch.Tensor):
|
| 66 |
+
raise TypeError("history_mask must be a Tensor or None")
|
| 67 |
+
if self.history_mask.shape[:2] != (batch_size, seq_len):
|
| 68 |
+
raise ValueError(
|
| 69 |
+
f"Shape mismatch in history_mask: {self.history_mask.shape[:2]} vs {(batch_size, seq_len)}"
|
| 70 |
+
)
|
| 71 |
+
|
| 72 |
+
if self.future_mask is not None:
|
| 73 |
+
if not isinstance(self.future_mask, torch.Tensor):
|
| 74 |
+
raise TypeError("future_mask must be a Tensor or None")
|
| 75 |
+
if not (
|
| 76 |
+
self.future_mask.shape == (batch_size, pred_len)
|
| 77 |
+
or self.future_mask.shape == self.future_values.shape
|
| 78 |
+
):
|
| 79 |
+
raise ValueError(
|
| 80 |
+
f"Shape mismatch in future_mask: expected {(batch_size, pred_len)} or {self.future_values.shape}, got {self.future_mask.shape}"
|
| 81 |
+
)
|
| 82 |
+
|
| 83 |
+
def to_device(
|
| 84 |
+
self, device: torch.device, attributes: Optional[List[str]] = None
|
| 85 |
+
) -> None:
|
| 86 |
+
"""
|
| 87 |
+
Move specified tensors to the target device in place.
|
| 88 |
+
|
| 89 |
+
Args:
|
| 90 |
+
device: Target device (e.g., 'cpu', 'cuda').
|
| 91 |
+
attributes: Optional list of attribute names to move. If None, move all tensors.
|
| 92 |
+
|
| 93 |
+
Raises:
|
| 94 |
+
ValueError: If an invalid attribute is specified or device transfer fails.
|
| 95 |
+
"""
|
| 96 |
+
all_tensors = {
|
| 97 |
+
"history_values": self.history_values,
|
| 98 |
+
"future_values": self.future_values,
|
| 99 |
+
"history_mask": self.history_mask,
|
| 100 |
+
"future_mask": self.future_mask,
|
| 101 |
+
}
|
| 102 |
+
|
| 103 |
+
if attributes is None:
|
| 104 |
+
attributes = [k for k, v in all_tensors.items() if v is not None]
|
| 105 |
+
|
| 106 |
+
for attr in attributes:
|
| 107 |
+
if attr not in all_tensors:
|
| 108 |
+
raise ValueError(f"Invalid attribute: {attr}")
|
| 109 |
+
if all_tensors[attr] is not None:
|
| 110 |
+
setattr(self, attr, all_tensors[attr].to(device))
|
| 111 |
+
|
| 112 |
+
def to(self, device: torch.device, attributes: Optional[List[str]] = None):
|
| 113 |
+
"""
|
| 114 |
+
Alias for to_device method for consistency with PyTorch conventions.
|
| 115 |
+
|
| 116 |
+
Args:
|
| 117 |
+
device: Target device (e.g., 'cpu', 'cuda').
|
| 118 |
+
attributes: Optional list of attribute names to move. If None, move all tensors.
|
| 119 |
+
"""
|
| 120 |
+
self.to_device(device, attributes)
|
| 121 |
+
return self
|
| 122 |
+
|
| 123 |
+
@property
|
| 124 |
+
def batch_size(self) -> int:
|
| 125 |
+
return self.history_values.shape[0]
|
| 126 |
+
|
| 127 |
+
@property
|
| 128 |
+
def history_length(self) -> int:
|
| 129 |
+
return self.history_values.shape[1]
|
| 130 |
+
|
| 131 |
+
@property
|
| 132 |
+
def future_length(self) -> int:
|
| 133 |
+
return self.future_values.shape[1]
|
| 134 |
+
|
| 135 |
+
@property
|
| 136 |
+
def num_channels(self) -> int:
|
| 137 |
+
return self.history_values.shape[2]
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
@dataclass
|
| 141 |
+
class TimeSeriesContainer:
|
| 142 |
+
"""
|
| 143 |
+
Container for batch of time series data without explicit history/future split.
|
| 144 |
+
|
| 145 |
+
This container is used for storing generated synthetic time series data where
|
| 146 |
+
the entire series is treated as a single entity, typically for further processing
|
| 147 |
+
or splitting into history/future components later.
|
| 148 |
+
|
| 149 |
+
Attributes:
|
| 150 |
+
values: np.ndarray of time series values.
|
| 151 |
+
Shape: [batch_size, seq_len, num_channels] for multivariate series
|
| 152 |
+
[batch_size, seq_len] for univariate series
|
| 153 |
+
start: List of start timestamps for each series in the batch.
|
| 154 |
+
Type: List[np.datetime64], length should match batch_size
|
| 155 |
+
frequency: List of frequency for each series in the batch.
|
| 156 |
+
Type: List[Frequency], length should match batch_size
|
| 157 |
+
"""
|
| 158 |
+
|
| 159 |
+
values: np.ndarray
|
| 160 |
+
start: List[np.datetime64]
|
| 161 |
+
frequency: List[Frequency]
|
| 162 |
+
|
| 163 |
+
def __post_init__(self):
|
| 164 |
+
"""Validate all shapes and consistency."""
|
| 165 |
+
# --- Numpy Type Checks ---
|
| 166 |
+
if not isinstance(self.values, np.ndarray):
|
| 167 |
+
raise TypeError("values must be a np.ndarray")
|
| 168 |
+
if not isinstance(self.start, list) or not all(
|
| 169 |
+
isinstance(x, np.datetime64) for x in self.start
|
| 170 |
+
):
|
| 171 |
+
raise TypeError("start must be a List[np.datetime64]")
|
| 172 |
+
if not isinstance(self.frequency, list) or not all(
|
| 173 |
+
isinstance(x, Frequency) for x in self.frequency
|
| 174 |
+
):
|
| 175 |
+
raise TypeError("frequency must be a List[Frequency]")
|
| 176 |
+
|
| 177 |
+
# --- Shape and Length Consistency Checks ---
|
| 178 |
+
if len(self.values.shape) < 2 or len(self.values.shape) > 3:
|
| 179 |
+
raise ValueError(
|
| 180 |
+
f"values must have 2 or 3 dimensions [batch_size, seq_len] or [batch_size, seq_len, num_channels], got shape {self.values.shape}"
|
| 181 |
+
)
|
| 182 |
+
|
| 183 |
+
batch_size = self.values.shape[0]
|
| 184 |
+
|
| 185 |
+
if len(self.start) != batch_size:
|
| 186 |
+
raise ValueError(
|
| 187 |
+
f"Length of start ({len(self.start)}) must match batch_size ({batch_size})"
|
| 188 |
+
)
|
| 189 |
+
if len(self.frequency) != batch_size:
|
| 190 |
+
raise ValueError(
|
| 191 |
+
f"Length of frequency ({len(self.frequency)}) must match batch_size ({batch_size})"
|
| 192 |
+
)
|
| 193 |
+
|
| 194 |
+
@property
|
| 195 |
+
def batch_size(self) -> int:
|
| 196 |
+
return self.values.shape[0]
|
| 197 |
+
|
| 198 |
+
@property
|
| 199 |
+
def seq_length(self) -> int:
|
| 200 |
+
return self.values.shape[1]
|
| 201 |
+
|
| 202 |
+
@property
|
| 203 |
+
def num_channels(self) -> int:
|
| 204 |
+
return self.values.shape[2] if len(self.values.shape) == 3 else 1
|
src/data/datasets.py
ADDED
|
@@ -0,0 +1,267 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import os
|
| 3 |
+
import random
|
| 4 |
+
from typing import List, Optional
|
| 5 |
+
|
| 6 |
+
import pyarrow.feather as feather
|
| 7 |
+
import torch
|
| 8 |
+
|
| 9 |
+
logger = logging.getLogger(__name__)
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class CyclicalBatchDataset:
|
| 13 |
+
"""
|
| 14 |
+
Dataset class that loads saved batches from continuous generation script.
|
| 15 |
+
Maintains a pointer and provides cyclical access to individual samples.
|
| 16 |
+
Includes enhanced logging to track data shard cycling during training.
|
| 17 |
+
Supports per-rank file sharding for large-scale distributed training.
|
| 18 |
+
"""
|
| 19 |
+
|
| 20 |
+
def __init__(
|
| 21 |
+
self,
|
| 22 |
+
batches_dir: str,
|
| 23 |
+
generator_type: str,
|
| 24 |
+
device: Optional[torch.device] = None,
|
| 25 |
+
prefetch_next: bool = True,
|
| 26 |
+
prefetch_threshold: int = 32,
|
| 27 |
+
rank: int = 0,
|
| 28 |
+
world_size: int = 1,
|
| 29 |
+
):
|
| 30 |
+
"""
|
| 31 |
+
Initialize the cyclical batch dataset.
|
| 32 |
+
|
| 33 |
+
Args:
|
| 34 |
+
batches_dir: Directory containing the batch arrow files
|
| 35 |
+
generator_type: Type of generator (for logging)
|
| 36 |
+
device: Device to load tensors to
|
| 37 |
+
prefetch_next: Whether to prefetch the next batch
|
| 38 |
+
prefetch_threshold: Number of remaining samples to trigger prefetching
|
| 39 |
+
rank: Rank of the current process (for file sharding)
|
| 40 |
+
world_size: Total number of processes (for file sharding)
|
| 41 |
+
"""
|
| 42 |
+
self.batches_dir = batches_dir
|
| 43 |
+
self.generator_type = generator_type
|
| 44 |
+
self.device = device
|
| 45 |
+
self.prefetch_next = prefetch_next
|
| 46 |
+
self.prefetch_threshold = prefetch_threshold
|
| 47 |
+
self.rank = rank
|
| 48 |
+
self.world_size = world_size
|
| 49 |
+
|
| 50 |
+
self.batch_files = self._find_batch_files()
|
| 51 |
+
if not self.batch_files:
|
| 52 |
+
raise ValueError(f"No batch files found in {batches_dir}")
|
| 53 |
+
|
| 54 |
+
# --- State tracking ---
|
| 55 |
+
self.current_batch_idx = 0
|
| 56 |
+
self.current_sample_idx = 0
|
| 57 |
+
self.current_batch_data = None
|
| 58 |
+
self.next_batch_data = None
|
| 59 |
+
self.prefetching_in_progress = False
|
| 60 |
+
|
| 61 |
+
# --- NEW: Logging and cycle tracking ---
|
| 62 |
+
self.visited_batch_indices = set()
|
| 63 |
+
self.full_cycles_completed = 0
|
| 64 |
+
|
| 65 |
+
# Load first batch and update tracking
|
| 66 |
+
self._load_current_batch()
|
| 67 |
+
self.visited_batch_indices.add(self.current_batch_idx)
|
| 68 |
+
|
| 69 |
+
logger.info(
|
| 70 |
+
f"Initialized '{self.generator_type}' dataset with {len(self.batch_files)} batches. "
|
| 71 |
+
f"Current batch file: '{os.path.basename(self.batch_files[self.current_batch_idx])}' "
|
| 72 |
+
f"has {len(self.current_batch_data)} samples."
|
| 73 |
+
)
|
| 74 |
+
|
| 75 |
+
def _find_batch_files(self) -> List[str]:
|
| 76 |
+
"""
|
| 77 |
+
Find and sort batch files with per-rank sharding for distributed training.
|
| 78 |
+
|
| 79 |
+
Each rank gets a disjoint subset of files to minimize I/O contention
|
| 80 |
+
when scaling to hundreds of GPUs.
|
| 81 |
+
"""
|
| 82 |
+
import glob
|
| 83 |
+
|
| 84 |
+
pattern = os.path.join(self.batches_dir, "batch_*.arrow")
|
| 85 |
+
all_files = sorted(glob.glob(pattern)) # Sort for deterministic sharding
|
| 86 |
+
|
| 87 |
+
if not all_files:
|
| 88 |
+
return []
|
| 89 |
+
|
| 90 |
+
# Shard files across ranks: each rank gets every world_size-th file
|
| 91 |
+
# Example with 4 ranks: rank0=[0,4,8,...], rank1=[1,5,9,...], etc.
|
| 92 |
+
rank_files = [
|
| 93 |
+
f for i, f in enumerate(all_files) if i % self.world_size == self.rank
|
| 94 |
+
]
|
| 95 |
+
|
| 96 |
+
# Shuffle only within this rank's shard for variety
|
| 97 |
+
random.shuffle(rank_files)
|
| 98 |
+
|
| 99 |
+
logger.info(
|
| 100 |
+
f"[Rank {self.rank}] '{self.generator_type}': Sharded {len(all_files)} files → "
|
| 101 |
+
f"{len(rank_files)} files for this rank ({len(rank_files) / len(all_files) * 100:.1f}%)"
|
| 102 |
+
)
|
| 103 |
+
|
| 104 |
+
return rank_files
|
| 105 |
+
|
| 106 |
+
def _load_batch_from_file(self, batch_file: str) -> List[dict]:
|
| 107 |
+
"""Load a batch from arrow file."""
|
| 108 |
+
try:
|
| 109 |
+
table = feather.read_table(batch_file)
|
| 110 |
+
has_num_channels = "num_channels" in table.column_names
|
| 111 |
+
batch_data = []
|
| 112 |
+
for i in range(len(table)):
|
| 113 |
+
row = {
|
| 114 |
+
"series_id": table["series_id"][i].as_py(),
|
| 115 |
+
"values": table["values"][i].as_py(),
|
| 116 |
+
"length": table["length"][i].as_py(),
|
| 117 |
+
"generator_type": table["generator_type"][i].as_py(),
|
| 118 |
+
"start": table["start"][i].as_py(),
|
| 119 |
+
"frequency": table["frequency"][i].as_py(),
|
| 120 |
+
"generation_timestamp": table["generation_timestamp"][i].as_py(),
|
| 121 |
+
}
|
| 122 |
+
if has_num_channels:
|
| 123 |
+
row["num_channels"] = table["num_channels"][i].as_py()
|
| 124 |
+
else:
|
| 125 |
+
row["num_channels"] = 1
|
| 126 |
+
batch_data.append(row)
|
| 127 |
+
return batch_data
|
| 128 |
+
except Exception as e:
|
| 129 |
+
logger.error(f"Error loading batch from {batch_file}: {e}")
|
| 130 |
+
raise
|
| 131 |
+
|
| 132 |
+
def _load_current_batch(self):
|
| 133 |
+
"""Load the current batch into memory."""
|
| 134 |
+
if hasattr(self, "current_batch_data") and self.current_batch_data is not None:
|
| 135 |
+
del self.current_batch_data
|
| 136 |
+
batch_file = self.batch_files[self.current_batch_idx]
|
| 137 |
+
self.current_batch_data = self._load_batch_from_file(batch_file)
|
| 138 |
+
self.current_sample_idx = 0
|
| 139 |
+
logger.debug(
|
| 140 |
+
f"Loaded batch {self.current_batch_idx} for {self.generator_type} "
|
| 141 |
+
f"with {len(self.current_batch_data)} samples"
|
| 142 |
+
)
|
| 143 |
+
|
| 144 |
+
def _trigger_smart_prefetch(self):
|
| 145 |
+
"""Trigger prefetching when batch is almost exhausted."""
|
| 146 |
+
if not self.prefetch_next or len(self.batch_files) <= 1:
|
| 147 |
+
return
|
| 148 |
+
remaining_samples = self.get_remaining_samples_in_current_batch()
|
| 149 |
+
should_prefetch = (
|
| 150 |
+
remaining_samples <= self.prefetch_threshold
|
| 151 |
+
and self.next_batch_data is None
|
| 152 |
+
and not self.prefetching_in_progress
|
| 153 |
+
)
|
| 154 |
+
if should_prefetch:
|
| 155 |
+
self._prefetch_next_batch()
|
| 156 |
+
|
| 157 |
+
def _prefetch_next_batch(self):
|
| 158 |
+
"""Prefetch the next batch."""
|
| 159 |
+
if self.prefetching_in_progress:
|
| 160 |
+
return
|
| 161 |
+
self.prefetching_in_progress = True
|
| 162 |
+
next_batch_idx = (self.current_batch_idx + 1) % len(self.batch_files)
|
| 163 |
+
next_batch_file = self.batch_files[next_batch_idx]
|
| 164 |
+
try:
|
| 165 |
+
self.next_batch_data = self._load_batch_from_file(next_batch_file)
|
| 166 |
+
logger.debug(
|
| 167 |
+
f"Prefetched next batch {next_batch_idx} for {self.generator_type}"
|
| 168 |
+
)
|
| 169 |
+
except Exception as e:
|
| 170 |
+
logger.warning(f"Failed to prefetch batch {next_batch_idx}: {e}")
|
| 171 |
+
self.next_batch_data = None
|
| 172 |
+
finally:
|
| 173 |
+
self.prefetching_in_progress = False
|
| 174 |
+
|
| 175 |
+
def _advance_to_next_batch(self):
|
| 176 |
+
"""Advance to the next batch and log the transition."""
|
| 177 |
+
if hasattr(self, "current_batch_data") and self.current_batch_data is not None:
|
| 178 |
+
del self.current_batch_data
|
| 179 |
+
|
| 180 |
+
previous_batch_idx = self.current_batch_idx
|
| 181 |
+
self.current_batch_idx = (self.current_batch_idx + 1) % len(self.batch_files)
|
| 182 |
+
|
| 183 |
+
if hasattr(self, "next_batch_data") and self.next_batch_data is not None:
|
| 184 |
+
self.current_batch_data = self.next_batch_data
|
| 185 |
+
self.next_batch_data = None
|
| 186 |
+
else:
|
| 187 |
+
self._load_current_batch()
|
| 188 |
+
|
| 189 |
+
self.current_sample_idx = 0
|
| 190 |
+
self.prefetching_in_progress = False
|
| 191 |
+
|
| 192 |
+
# --- NEW: Enhanced Logging Logic ---
|
| 193 |
+
self.visited_batch_indices.add(self.current_batch_idx)
|
| 194 |
+
|
| 195 |
+
# Calculate progress
|
| 196 |
+
total_files = len(self.batch_files)
|
| 197 |
+
visited_count = len(self.visited_batch_indices)
|
| 198 |
+
progress_percent = (visited_count / total_files) * 100
|
| 199 |
+
|
| 200 |
+
# Log the shard cycle event
|
| 201 |
+
logger.info(
|
| 202 |
+
f"\nDATA SHARD CYCLED for '{self.generator_type}': "
|
| 203 |
+
f"Moved from file index {previous_batch_idx} to {self.current_batch_idx}. "
|
| 204 |
+
f"Unique files visited: {visited_count}/{total_files} ({progress_percent:.1f}%)."
|
| 205 |
+
)
|
| 206 |
+
|
| 207 |
+
# Check if a full cycle has been completed
|
| 208 |
+
if visited_count == total_files:
|
| 209 |
+
self.full_cycles_completed += 1
|
| 210 |
+
logger.info(
|
| 211 |
+
f"🎉 FULL CYCLE #{self.full_cycles_completed} COMPLETED for '{self.generator_type}'! "
|
| 212 |
+
f"All {total_files} data files have been visited at least once. "
|
| 213 |
+
"Resetting visited set to track the next cycle."
|
| 214 |
+
)
|
| 215 |
+
# Reset for the next cycle count
|
| 216 |
+
self.visited_batch_indices.clear()
|
| 217 |
+
self.visited_batch_indices.add(self.current_batch_idx)
|
| 218 |
+
|
| 219 |
+
def get_sample(self) -> dict:
|
| 220 |
+
"""Get the current sample and advance pointer."""
|
| 221 |
+
if not hasattr(self, "current_batch_data") or self.current_batch_data is None:
|
| 222 |
+
self._load_current_batch()
|
| 223 |
+
if self.current_batch_data is None:
|
| 224 |
+
raise RuntimeError("No batch data loaded")
|
| 225 |
+
if self.current_sample_idx >= len(self.current_batch_data):
|
| 226 |
+
self._advance_to_next_batch()
|
| 227 |
+
self._trigger_smart_prefetch()
|
| 228 |
+
sample = self.current_batch_data[self.current_sample_idx]
|
| 229 |
+
self.current_sample_idx += 1
|
| 230 |
+
return sample
|
| 231 |
+
|
| 232 |
+
def get_samples(self, num_samples: int) -> List[dict]:
|
| 233 |
+
"""Get multiple samples."""
|
| 234 |
+
samples = []
|
| 235 |
+
for _ in range(num_samples):
|
| 236 |
+
samples.append(self.get_sample())
|
| 237 |
+
return samples
|
| 238 |
+
|
| 239 |
+
def get_total_samples_in_current_batch(self) -> int:
|
| 240 |
+
"""Get total samples in current batch."""
|
| 241 |
+
if not hasattr(self, "current_batch_data") or self.current_batch_data is None:
|
| 242 |
+
return 0
|
| 243 |
+
return len(self.current_batch_data)
|
| 244 |
+
|
| 245 |
+
def get_remaining_samples_in_current_batch(self) -> int:
|
| 246 |
+
"""Get remaining samples in current batch."""
|
| 247 |
+
if not hasattr(self, "current_batch_data") or self.current_batch_data is None:
|
| 248 |
+
return 0
|
| 249 |
+
return max(0, len(self.current_batch_data) - self.current_sample_idx)
|
| 250 |
+
|
| 251 |
+
def get_info(self) -> dict:
|
| 252 |
+
"""Get extended dataset info, including cycle progress."""
|
| 253 |
+
total_files = len(self.batch_files)
|
| 254 |
+
visited_count = len(self.visited_batch_indices)
|
| 255 |
+
return {
|
| 256 |
+
"generator_type": self.generator_type,
|
| 257 |
+
"total_batch_files": total_files,
|
| 258 |
+
"current_batch_idx": self.current_batch_idx,
|
| 259 |
+
"current_sample_idx": self.current_sample_idx,
|
| 260 |
+
"current_batch_size": self.get_total_samples_in_current_batch(),
|
| 261 |
+
"remaining_in_batch": self.get_remaining_samples_in_current_batch(),
|
| 262 |
+
"unique_files_visited": visited_count,
|
| 263 |
+
"cycle_progress_percent": (visited_count / total_files) * 100
|
| 264 |
+
if total_files > 0
|
| 265 |
+
else 0,
|
| 266 |
+
"full_cycles_completed": self.full_cycles_completed,
|
| 267 |
+
}
|
src/data/filter.py
ADDED
|
@@ -0,0 +1,73 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import torch
|
| 3 |
+
from scipy import signal
|
| 4 |
+
from statsmodels.tsa.stattools import acf
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def lempel_ziv_complexity(binary_sequence: np.ndarray) -> int:
|
| 8 |
+
"""Computes the Lempel-Ziv complexity of a binary sequence."""
|
| 9 |
+
sub_strings = set()
|
| 10 |
+
n = len(binary_sequence)
|
| 11 |
+
i = 0
|
| 12 |
+
count = 0
|
| 13 |
+
while i < n:
|
| 14 |
+
sub_str = ""
|
| 15 |
+
for j in range(i, n):
|
| 16 |
+
sub_str += str(binary_sequence[j])
|
| 17 |
+
if sub_str not in sub_strings:
|
| 18 |
+
sub_strings.add(sub_str)
|
| 19 |
+
count += 1
|
| 20 |
+
i = j + 1
|
| 21 |
+
break
|
| 22 |
+
else:
|
| 23 |
+
i += 1
|
| 24 |
+
return count
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def is_low_quality(
|
| 28 |
+
series: torch.Tensor,
|
| 29 |
+
autocorr_threshold: float = 0.2,
|
| 30 |
+
snr_threshold: float = 0.5,
|
| 31 |
+
complexity_threshold: float = 0.4,
|
| 32 |
+
) -> bool:
|
| 33 |
+
"""
|
| 34 |
+
Returns True if the series appears non-forecastable (noise-like):
|
| 35 |
+
- weak autocorrelation
|
| 36 |
+
- low SNR proxy
|
| 37 |
+
- high normalized Lempel-Ziv complexity
|
| 38 |
+
"""
|
| 39 |
+
x = series.squeeze().detach().cpu().numpy()
|
| 40 |
+
if x.size < 20:
|
| 41 |
+
return True
|
| 42 |
+
if np.var(x) < 1e-10:
|
| 43 |
+
return True
|
| 44 |
+
|
| 45 |
+
x_detrended = signal.detrend(x)
|
| 46 |
+
|
| 47 |
+
try:
|
| 48 |
+
max_lags = min(len(x_detrended) // 4, 40)
|
| 49 |
+
if max_lags < 1:
|
| 50 |
+
autocorr_strength = 0.0
|
| 51 |
+
else:
|
| 52 |
+
acf_vals = acf(x_detrended, nlags=max_lags, fft=True)[1:]
|
| 53 |
+
autocorr_strength = float(np.max(np.abs(acf_vals)))
|
| 54 |
+
except Exception:
|
| 55 |
+
autocorr_strength = 0.0
|
| 56 |
+
|
| 57 |
+
win_size = max(3, min(len(x) // 10, 15))
|
| 58 |
+
signal_est = np.convolve(x, np.ones(win_size) / win_size, mode="valid")
|
| 59 |
+
noise_est = x[win_size - 1 :] - signal_est
|
| 60 |
+
var_signal = float(np.var(signal_est))
|
| 61 |
+
var_noise = float(np.var(noise_est))
|
| 62 |
+
snr_proxy = var_signal / var_noise if var_noise > 1e-8 else 1.0
|
| 63 |
+
|
| 64 |
+
median_val = float(np.median(x_detrended))
|
| 65 |
+
binary_seq = (x_detrended > median_val).astype(np.uint8)
|
| 66 |
+
complexity_score = lempel_ziv_complexity(binary_seq)
|
| 67 |
+
normalized_complexity = complexity_score / max(1, len(binary_seq))
|
| 68 |
+
|
| 69 |
+
is_random_like = (snr_proxy < snr_threshold) and (
|
| 70 |
+
normalized_complexity > complexity_threshold
|
| 71 |
+
)
|
| 72 |
+
is_uncorrelated = autocorr_strength < autocorr_threshold
|
| 73 |
+
return bool(is_uncorrelated and is_random_like)
|
src/data/frequency.py
ADDED
|
@@ -0,0 +1,538 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Comprehensive frequency management module for time series forecasting.
|
| 3 |
+
|
| 4 |
+
This module centralizes all frequency-related functionality including:
|
| 5 |
+
- Frequency enum with helper methods
|
| 6 |
+
- Frequency parsing and validation
|
| 7 |
+
- Pandas frequency string conversion
|
| 8 |
+
- Safety checks for date ranges
|
| 9 |
+
- Frequency selection utilities
|
| 10 |
+
- All frequency constants and mappings
|
| 11 |
+
"""
|
| 12 |
+
|
| 13 |
+
import logging
|
| 14 |
+
import re
|
| 15 |
+
from enum import Enum
|
| 16 |
+
from typing import Dict, Tuple
|
| 17 |
+
|
| 18 |
+
import numpy as np
|
| 19 |
+
import pandas as pd
|
| 20 |
+
from numpy.random import Generator
|
| 21 |
+
|
| 22 |
+
from src.data.constants import BASE_END_DATE, BASE_START_DATE, MAX_YEARS
|
| 23 |
+
|
| 24 |
+
logger = logging.getLogger(__name__)
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class Frequency(Enum):
|
| 28 |
+
"""
|
| 29 |
+
Enhanced Frequency enum with comprehensive helper methods.
|
| 30 |
+
|
| 31 |
+
Each frequency includes methods for pandas conversion, safety checks,
|
| 32 |
+
and other frequency-specific operations.
|
| 33 |
+
"""
|
| 34 |
+
|
| 35 |
+
A = "A" # Annual
|
| 36 |
+
Q = "Q" # Quarterly
|
| 37 |
+
M = "M" # Monthly
|
| 38 |
+
W = "W" # Weekly
|
| 39 |
+
D = "D" # Daily
|
| 40 |
+
H = "h" # Hourly
|
| 41 |
+
S = "s" # Seconds
|
| 42 |
+
T1 = "1min" # 1 minute
|
| 43 |
+
T5 = "5min" # 5 minutes
|
| 44 |
+
T10 = "10min" # 10 minutes
|
| 45 |
+
T15 = "15min" # 15 minutes
|
| 46 |
+
T30 = "30min" # 30 minutes
|
| 47 |
+
|
| 48 |
+
def to_pandas_freq(self, for_date_range: bool = True) -> str:
|
| 49 |
+
"""
|
| 50 |
+
Convert to pandas frequency string.
|
| 51 |
+
|
| 52 |
+
Args:
|
| 53 |
+
for_date_range: If True, use strings suitable for pd.date_range().
|
| 54 |
+
If False, use strings suitable for pd.PeriodIndex().
|
| 55 |
+
|
| 56 |
+
Returns:
|
| 57 |
+
Pandas frequency string
|
| 58 |
+
"""
|
| 59 |
+
base, prefix, _ = FREQUENCY_MAPPING[self]
|
| 60 |
+
|
| 61 |
+
# Special handling for date_range vs period compatibility
|
| 62 |
+
if for_date_range:
|
| 63 |
+
# For date_range, use modern pandas frequency strings
|
| 64 |
+
if self == Frequency.M:
|
| 65 |
+
return "ME" # Month End
|
| 66 |
+
elif self == Frequency.A:
|
| 67 |
+
return "YE" # Year End
|
| 68 |
+
elif self == Frequency.Q:
|
| 69 |
+
return "QE" # Quarter End
|
| 70 |
+
else:
|
| 71 |
+
# For periods, use legacy frequency strings
|
| 72 |
+
if self == Frequency.M:
|
| 73 |
+
return "M" # Month for periods
|
| 74 |
+
elif self == Frequency.A:
|
| 75 |
+
return "Y" # Year for periods (not YE)
|
| 76 |
+
elif self == Frequency.Q:
|
| 77 |
+
return "Q" # Quarter for periods (not QE)
|
| 78 |
+
|
| 79 |
+
# Construct frequency string for other frequencies
|
| 80 |
+
if prefix:
|
| 81 |
+
return f"{prefix}{base}"
|
| 82 |
+
else:
|
| 83 |
+
return base
|
| 84 |
+
|
| 85 |
+
def to_pandas_offset(self) -> str:
|
| 86 |
+
"""Get pandas offset string for time delta calculations."""
|
| 87 |
+
return FREQUENCY_TO_OFFSET[self]
|
| 88 |
+
|
| 89 |
+
def get_days_per_period(self) -> float:
|
| 90 |
+
"""Get approximate days per period for this frequency."""
|
| 91 |
+
_, _, days = FREQUENCY_MAPPING[self]
|
| 92 |
+
return days
|
| 93 |
+
|
| 94 |
+
def get_max_safe_length(self) -> int:
|
| 95 |
+
"""Get maximum safe sequence length to prevent timestamp overflow."""
|
| 96 |
+
return ALL_FREQUENCY_MAX_LENGTHS.get(self, float("inf"))
|
| 97 |
+
|
| 98 |
+
def is_high_frequency(self) -> bool:
|
| 99 |
+
"""Check if this is a high frequency (minute/second level)."""
|
| 100 |
+
return self in [
|
| 101 |
+
Frequency.S,
|
| 102 |
+
Frequency.T1,
|
| 103 |
+
Frequency.T5,
|
| 104 |
+
Frequency.T10,
|
| 105 |
+
Frequency.T15,
|
| 106 |
+
Frequency.T30,
|
| 107 |
+
]
|
| 108 |
+
|
| 109 |
+
def is_low_frequency(self) -> bool:
|
| 110 |
+
"""Check if this is a low frequency (annual/quarterly/monthly)."""
|
| 111 |
+
return self in [Frequency.A, Frequency.Q, Frequency.M]
|
| 112 |
+
|
| 113 |
+
def get_seasonality(self) -> int:
|
| 114 |
+
"""Get typical seasonality for this frequency."""
|
| 115 |
+
seasonality_map = {
|
| 116 |
+
Frequency.S: 3600, # 1 hour of seconds
|
| 117 |
+
Frequency.T1: 60, # 1 hour of minutes
|
| 118 |
+
Frequency.T5: 12, # 1 hour of 5-minute intervals
|
| 119 |
+
Frequency.T10: 6, # 1 hour of 10-minute intervals
|
| 120 |
+
Frequency.T15: 4, # 1 hour of 15-minute intervals
|
| 121 |
+
Frequency.T30: 2, # 1 hour of 30-minute intervals
|
| 122 |
+
Frequency.H: 24, # 1 day of hours
|
| 123 |
+
Frequency.D: 7, # 1 week of days
|
| 124 |
+
Frequency.W: 52, # 1 year of weeks
|
| 125 |
+
Frequency.M: 12, # 1 year of months
|
| 126 |
+
Frequency.Q: 4, # 1 year of quarters
|
| 127 |
+
Frequency.A: 1, # No clear seasonality for annual
|
| 128 |
+
}
|
| 129 |
+
return seasonality_map.get(self, 1)
|
| 130 |
+
|
| 131 |
+
def get_gift_eval_weight(self) -> float:
|
| 132 |
+
"""Get GIFT eval dataset frequency weight."""
|
| 133 |
+
return GIFT_EVAL_FREQUENCY_WEIGHTS.get(self, 0.1)
|
| 134 |
+
|
| 135 |
+
def get_length_range(self) -> Tuple[int, int, int, int]:
|
| 136 |
+
"""Get (min_length, max_length, optimal_start, optimal_end) for this frequency."""
|
| 137 |
+
return GIFT_EVAL_LENGTH_RANGES.get(self, (50, 1000, 100, 500))
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
# ============================================================================
|
| 141 |
+
# Frequency Mappings and Constants
|
| 142 |
+
# ============================================================================
|
| 143 |
+
|
| 144 |
+
# Core frequency mapping: (pandas_base, prefix, days_per_period)
|
| 145 |
+
FREQUENCY_MAPPING: Dict[Frequency, Tuple[str, str, float]] = {
|
| 146 |
+
Frequency.A: (
|
| 147 |
+
"YE",
|
| 148 |
+
"",
|
| 149 |
+
365.25,
|
| 150 |
+
), # Average days per year (accounting for leap years)
|
| 151 |
+
Frequency.Q: ("Q", "", 91.3125), # 365.25/4 - average days per quarter
|
| 152 |
+
Frequency.M: ("M", "", 30.4375), # 365.25/12 - average days per month
|
| 153 |
+
Frequency.W: ("W", "", 7),
|
| 154 |
+
Frequency.D: ("D", "", 1),
|
| 155 |
+
Frequency.H: ("h", "", 1 / 24),
|
| 156 |
+
Frequency.S: ("s", "", 1 / 86400), # 24*60*60
|
| 157 |
+
Frequency.T1: ("min", "1", 1 / 1440), # 24*60
|
| 158 |
+
Frequency.T5: ("min", "5", 1 / 288), # 24*60/5
|
| 159 |
+
Frequency.T10: ("min", "10", 1 / 144), # 24*60/10
|
| 160 |
+
Frequency.T15: ("min", "15", 1 / 96), # 24*60/15
|
| 161 |
+
Frequency.T30: ("min", "30", 1 / 48), # 24*60/30
|
| 162 |
+
}
|
| 163 |
+
|
| 164 |
+
# Frequency to pandas offset mapping for calculating time deltas
|
| 165 |
+
FREQUENCY_TO_OFFSET: Dict[Frequency, str] = {
|
| 166 |
+
Frequency.A: "AS", # Annual start
|
| 167 |
+
Frequency.Q: "QS", # Quarter start
|
| 168 |
+
Frequency.M: "MS", # Month start
|
| 169 |
+
Frequency.W: "W", # Weekly
|
| 170 |
+
Frequency.D: "D", # Daily
|
| 171 |
+
Frequency.H: "H", # Hourly
|
| 172 |
+
Frequency.T1: "1T", # 1 minute
|
| 173 |
+
Frequency.T5: "5T", # 5 minutes
|
| 174 |
+
Frequency.T10: "10T", # 10 minutes
|
| 175 |
+
Frequency.T15: "15T", # 15 minutes
|
| 176 |
+
Frequency.T30: "30T", # 30 minutes
|
| 177 |
+
Frequency.S: "S", # Seconds
|
| 178 |
+
}
|
| 179 |
+
|
| 180 |
+
# Maximum sequence lengths to avoid pandas OutOfBoundsDatetime errors
|
| 181 |
+
SHORT_FREQUENCY_MAX_LENGTHS = {
|
| 182 |
+
Frequency.A: MAX_YEARS,
|
| 183 |
+
Frequency.Q: MAX_YEARS * 4,
|
| 184 |
+
Frequency.M: MAX_YEARS * 12,
|
| 185 |
+
Frequency.W: int(MAX_YEARS * 52.1775),
|
| 186 |
+
Frequency.D: int(MAX_YEARS * 365.2425),
|
| 187 |
+
}
|
| 188 |
+
|
| 189 |
+
HIGH_FREQUENCY_MAX_LENGTHS = {
|
| 190 |
+
Frequency.H: int(MAX_YEARS * 365.2425 * 24),
|
| 191 |
+
Frequency.S: int(MAX_YEARS * 365.2425 * 24 * 60 * 60),
|
| 192 |
+
Frequency.T1: int(MAX_YEARS * 365.2425 * 24 * 60),
|
| 193 |
+
Frequency.T5: int(MAX_YEARS * 365.2425 * 24 * 12),
|
| 194 |
+
Frequency.T10: int(MAX_YEARS * 365.2425 * 24 * 6),
|
| 195 |
+
Frequency.T15: int(MAX_YEARS * 365.2425 * 24 * 4),
|
| 196 |
+
Frequency.T30: int(MAX_YEARS * 365.2425 * 24 * 2),
|
| 197 |
+
}
|
| 198 |
+
|
| 199 |
+
# Combined max lengths for all frequencies
|
| 200 |
+
ALL_FREQUENCY_MAX_LENGTHS = {
|
| 201 |
+
**SHORT_FREQUENCY_MAX_LENGTHS,
|
| 202 |
+
**HIGH_FREQUENCY_MAX_LENGTHS,
|
| 203 |
+
}
|
| 204 |
+
|
| 205 |
+
# GIFT eval-based frequency weights from actual dataset analysis
|
| 206 |
+
GIFT_EVAL_FREQUENCY_WEIGHTS: Dict[Frequency, float] = {
|
| 207 |
+
Frequency.H: 25.0, # Hourly - most common
|
| 208 |
+
Frequency.D: 23.4, # Daily - second most common
|
| 209 |
+
Frequency.W: 12.9, # Weekly - third most common
|
| 210 |
+
Frequency.T15: 9.7, # 15-minute
|
| 211 |
+
Frequency.T5: 9.7, # 5-minute
|
| 212 |
+
Frequency.M: 7.3, # Monthly
|
| 213 |
+
Frequency.T10: 4.8, # 10-minute
|
| 214 |
+
Frequency.S: 4.8, # 10-second
|
| 215 |
+
Frequency.T1: 1.6, # 1-minute
|
| 216 |
+
Frequency.Q: 0.8, # Quarterly
|
| 217 |
+
Frequency.A: 0.8, # Annual
|
| 218 |
+
}
|
| 219 |
+
|
| 220 |
+
# GIFT eval-based length ranges derived from actual dataset analysis
|
| 221 |
+
# Format: (min_length, max_length, optimal_start, optimal_end)
|
| 222 |
+
GIFT_EVAL_LENGTH_RANGES: Dict[Frequency, Tuple[int, int, int, int]] = {
|
| 223 |
+
# Low frequency ranges (based on actual GIFT eval data + logical extensions)
|
| 224 |
+
Frequency.A: (25, 100, 30, 70),
|
| 225 |
+
Frequency.Q: (25, 150, 50, 120),
|
| 226 |
+
Frequency.M: (40, 1000, 100, 600),
|
| 227 |
+
Frequency.W: (50, 3500, 100, 1500),
|
| 228 |
+
# Medium frequency ranges
|
| 229 |
+
Frequency.D: (150, 25000, 300, 7000), # Daily: covers 1-year+ scenarios
|
| 230 |
+
Frequency.H: (600, 35000, 700, 17000),
|
| 231 |
+
# High frequency ranges (extended for shorter realistic scenarios)
|
| 232 |
+
Frequency.T1: (200, 2500, 1200, 1800), # 1-minute: day to few days
|
| 233 |
+
Frequency.S: (7500, 9500, 7900, 9000),
|
| 234 |
+
Frequency.T15: (1000, 140000, 50000, 130000),
|
| 235 |
+
Frequency.T5: (200, 105000, 20000, 95000),
|
| 236 |
+
Frequency.T10: (40000, 55000, 47000, 52000),
|
| 237 |
+
Frequency.T30: (100, 50000, 10000, 40000),
|
| 238 |
+
}
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
# ============================================================================
|
| 242 |
+
# Frequency Parsing and Validation
|
| 243 |
+
# ============================================================================
|
| 244 |
+
|
| 245 |
+
|
| 246 |
+
def parse_frequency(freq_str: str) -> Frequency:
|
| 247 |
+
"""
|
| 248 |
+
Parse frequency string to Frequency enum, robust to variations.
|
| 249 |
+
|
| 250 |
+
Handles various frequency string formats:
|
| 251 |
+
- Standard: "A", "Q", "M", "W", "D", "H", "S"
|
| 252 |
+
- Pandas-style: "A-DEC", "W-SUN", "QE-MAR"
|
| 253 |
+
- Minutes: "5T", "10min", "1T"
|
| 254 |
+
- Case variations: "a", "h", "D"
|
| 255 |
+
|
| 256 |
+
Args:
|
| 257 |
+
freq_str: The frequency string to parse (e.g., "5T", "W-SUN", "M")
|
| 258 |
+
|
| 259 |
+
Returns:
|
| 260 |
+
Corresponding Frequency enum member
|
| 261 |
+
|
| 262 |
+
Raises:
|
| 263 |
+
ValueError: If the frequency string is not supported
|
| 264 |
+
"""
|
| 265 |
+
# Handle minute-based frequencies BEFORE pandas standardization
|
| 266 |
+
# because pandas converts "5T" to just "min", losing the multiplier
|
| 267 |
+
minute_match = re.match(r"^(\d*)T$", freq_str, re.IGNORECASE) or re.match(
|
| 268 |
+
r"^(\d*)min$", freq_str, re.IGNORECASE
|
| 269 |
+
)
|
| 270 |
+
if minute_match:
|
| 271 |
+
multiplier = int(minute_match.group(1)) if minute_match.group(1) else 1
|
| 272 |
+
enum_key = f"T{multiplier}"
|
| 273 |
+
try:
|
| 274 |
+
return Frequency[enum_key]
|
| 275 |
+
except KeyError:
|
| 276 |
+
logger.warning(
|
| 277 |
+
f"Unsupported minute frequency '{freq_str}' (multiplier: {multiplier}). "
|
| 278 |
+
f"Falling back to '1min' ({Frequency.T1.value})."
|
| 279 |
+
)
|
| 280 |
+
return Frequency.T1
|
| 281 |
+
|
| 282 |
+
# Now standardize frequency string for other cases
|
| 283 |
+
try:
|
| 284 |
+
offset = pd.tseries.frequencies.to_offset(freq_str)
|
| 285 |
+
standardized_freq = offset.name
|
| 286 |
+
except Exception:
|
| 287 |
+
standardized_freq = freq_str
|
| 288 |
+
|
| 289 |
+
# Handle other frequencies by their base (e.g., 'W-SUN' -> 'W', 'A-DEC' -> 'A')
|
| 290 |
+
base_freq = standardized_freq.split("-")[0].upper()
|
| 291 |
+
|
| 292 |
+
freq_map = {
|
| 293 |
+
"A": Frequency.A,
|
| 294 |
+
"Y": Frequency.A, # Alias for Annual
|
| 295 |
+
"YE": Frequency.A, # Alias for Annual
|
| 296 |
+
"Q": Frequency.Q,
|
| 297 |
+
"QE": Frequency.Q, # Alias for Quarterly
|
| 298 |
+
"M": Frequency.M,
|
| 299 |
+
"ME": Frequency.M, # Alias for Monthly
|
| 300 |
+
"W": Frequency.W,
|
| 301 |
+
"D": Frequency.D,
|
| 302 |
+
"H": Frequency.H,
|
| 303 |
+
"S": Frequency.S,
|
| 304 |
+
}
|
| 305 |
+
|
| 306 |
+
if base_freq in freq_map:
|
| 307 |
+
return freq_map[base_freq]
|
| 308 |
+
|
| 309 |
+
raise NotImplementedError(f"Frequency '{standardized_freq}' is not supported.")
|
| 310 |
+
|
| 311 |
+
|
| 312 |
+
def validate_frequency_safety(
|
| 313 |
+
start_date: np.datetime64, total_length: int, frequency: Frequency
|
| 314 |
+
) -> bool:
|
| 315 |
+
"""
|
| 316 |
+
Check if start date and frequency combination is safe for pandas datetime operations.
|
| 317 |
+
|
| 318 |
+
This function verifies that pd.date_range(start=start_date, periods=total_length, freq=freq_str)
|
| 319 |
+
will not raise an OutOfBoundsDatetime error, accounting for pandas' datetime bounds
|
| 320 |
+
(1677-09-21 to 2262-04-11) and realistic frequency limitations.
|
| 321 |
+
|
| 322 |
+
Args:
|
| 323 |
+
start_date: The proposed start date for the time series
|
| 324 |
+
total_length: Total length of the time series
|
| 325 |
+
frequency: The frequency of the time series
|
| 326 |
+
|
| 327 |
+
Returns:
|
| 328 |
+
True if the combination is safe, False otherwise
|
| 329 |
+
"""
|
| 330 |
+
try:
|
| 331 |
+
# Get the pandas frequency string
|
| 332 |
+
freq_str = frequency.to_pandas_freq(for_date_range=True)
|
| 333 |
+
|
| 334 |
+
# Convert numpy datetime64 to pandas Timestamp for date_range
|
| 335 |
+
start_pd = pd.Timestamp(start_date)
|
| 336 |
+
|
| 337 |
+
# Check if start date is within pandas' valid datetime range
|
| 338 |
+
if start_pd < pd.Timestamp.min or start_pd > pd.Timestamp.max:
|
| 339 |
+
return False
|
| 340 |
+
|
| 341 |
+
# Check maximum length constraints
|
| 342 |
+
max_length = frequency.get_max_safe_length()
|
| 343 |
+
if total_length > max_length:
|
| 344 |
+
return False
|
| 345 |
+
|
| 346 |
+
# For low frequencies, be extra conservative
|
| 347 |
+
if frequency.is_low_frequency():
|
| 348 |
+
if frequency == Frequency.A and total_length > 500: # Max ~500 years
|
| 349 |
+
return False
|
| 350 |
+
elif frequency == Frequency.Q and total_length > 2000: # Max ~500 years
|
| 351 |
+
return False
|
| 352 |
+
elif frequency == Frequency.M and total_length > 6000: # Max ~500 years
|
| 353 |
+
return False
|
| 354 |
+
|
| 355 |
+
# Calculate approximate end date
|
| 356 |
+
days_per_period = frequency.get_days_per_period()
|
| 357 |
+
approx_days = total_length * days_per_period
|
| 358 |
+
|
| 359 |
+
# For annual/quarterly frequencies, add extra safety margin
|
| 360 |
+
if frequency in [Frequency.A, Frequency.Q]:
|
| 361 |
+
approx_days *= 1.1 # 10% safety margin
|
| 362 |
+
|
| 363 |
+
end_date = start_pd + pd.Timedelta(days=approx_days)
|
| 364 |
+
|
| 365 |
+
# Check if end date is within pandas' valid datetime range
|
| 366 |
+
if end_date < pd.Timestamp.min or end_date > pd.Timestamp.max:
|
| 367 |
+
return False
|
| 368 |
+
|
| 369 |
+
# Try to create the date range as final validation
|
| 370 |
+
pd.date_range(start=start_pd, periods=total_length, freq=freq_str)
|
| 371 |
+
return True
|
| 372 |
+
|
| 373 |
+
except (pd.errors.OutOfBoundsDatetime, OverflowError, ValueError):
|
| 374 |
+
return False
|
| 375 |
+
|
| 376 |
+
|
| 377 |
+
# ============================================================================
|
| 378 |
+
# Frequency Selection Utilities
|
| 379 |
+
# ============================================================================
|
| 380 |
+
|
| 381 |
+
|
| 382 |
+
def select_safe_random_frequency(total_length: int, rng: Generator) -> Frequency:
|
| 383 |
+
"""
|
| 384 |
+
Select a random frequency suitable for a given total length of a time series,
|
| 385 |
+
based on actual GIFT eval dataset patterns and distributions.
|
| 386 |
+
|
| 387 |
+
The selection logic:
|
| 388 |
+
1. Filters frequencies that can handle the given total_length
|
| 389 |
+
2. Applies base weights derived from actual GIFT eval frequency distribution
|
| 390 |
+
3. Strongly boosts frequencies that are in their optimal length ranges
|
| 391 |
+
4. Handles edge cases gracefully with fallbacks
|
| 392 |
+
|
| 393 |
+
Args:
|
| 394 |
+
total_length: The total length of the time series (history + future)
|
| 395 |
+
rng: A numpy random number generator instance
|
| 396 |
+
|
| 397 |
+
Returns:
|
| 398 |
+
A randomly selected frequency that matches GIFT eval patterns
|
| 399 |
+
"""
|
| 400 |
+
# Find valid frequencies and calculate weighted scores
|
| 401 |
+
valid_frequencies = []
|
| 402 |
+
frequency_scores = []
|
| 403 |
+
|
| 404 |
+
for freq in Frequency:
|
| 405 |
+
# Check basic timestamp overflow limits
|
| 406 |
+
max_allowed = freq.get_max_safe_length()
|
| 407 |
+
if total_length > max_allowed:
|
| 408 |
+
continue
|
| 409 |
+
|
| 410 |
+
# Check if frequency has defined ranges
|
| 411 |
+
min_len, max_len, optimal_start, optimal_end = freq.get_length_range()
|
| 412 |
+
|
| 413 |
+
# Must be within the frequency's realistic range
|
| 414 |
+
if total_length < min_len or total_length > max_len:
|
| 415 |
+
continue
|
| 416 |
+
|
| 417 |
+
valid_frequencies.append(freq)
|
| 418 |
+
|
| 419 |
+
# Calculate fitness score based on GIFT eval patterns
|
| 420 |
+
base_weight = freq.get_gift_eval_weight()
|
| 421 |
+
|
| 422 |
+
# Enhanced length-based fitness scoring
|
| 423 |
+
if optimal_start <= total_length <= optimal_end:
|
| 424 |
+
# In optimal range - very strong preference
|
| 425 |
+
length_multiplier = 5.0
|
| 426 |
+
else:
|
| 427 |
+
# Outside optimal but within valid range - calculate penalty
|
| 428 |
+
if total_length < optimal_start:
|
| 429 |
+
# Below optimal range
|
| 430 |
+
distance_ratio = (optimal_start - total_length) / (
|
| 431 |
+
optimal_start - min_len
|
| 432 |
+
)
|
| 433 |
+
else:
|
| 434 |
+
# Above optimal range
|
| 435 |
+
distance_ratio = (total_length - optimal_end) / (max_len - optimal_end)
|
| 436 |
+
|
| 437 |
+
# Apply graduated penalty: closer to optimal = higher score
|
| 438 |
+
length_multiplier = 0.3 + 1.2 * (1.0 - distance_ratio) # Range: 0.3-1.5
|
| 439 |
+
|
| 440 |
+
final_score = base_weight * length_multiplier
|
| 441 |
+
frequency_scores.append(final_score)
|
| 442 |
+
|
| 443 |
+
# Handle edge cases with smart fallbacks
|
| 444 |
+
if not valid_frequencies:
|
| 445 |
+
# Fallback strategy based on typical length patterns
|
| 446 |
+
if total_length <= 100:
|
| 447 |
+
# Very short series - prefer low frequencies
|
| 448 |
+
fallback_order = [
|
| 449 |
+
Frequency.A,
|
| 450 |
+
Frequency.Q,
|
| 451 |
+
Frequency.M,
|
| 452 |
+
Frequency.W,
|
| 453 |
+
Frequency.D,
|
| 454 |
+
]
|
| 455 |
+
elif total_length <= 1000:
|
| 456 |
+
# Medium short series - prefer daily/weekly
|
| 457 |
+
fallback_order = [Frequency.D, Frequency.W, Frequency.H, Frequency.M]
|
| 458 |
+
else:
|
| 459 |
+
# Longer series - prefer higher frequencies
|
| 460 |
+
fallback_order = [Frequency.H, Frequency.D, Frequency.T15, Frequency.T5]
|
| 461 |
+
|
| 462 |
+
for fallback_freq in fallback_order:
|
| 463 |
+
max_allowed = fallback_freq.get_max_safe_length()
|
| 464 |
+
if total_length <= max_allowed:
|
| 465 |
+
return fallback_freq
|
| 466 |
+
# Last resort
|
| 467 |
+
return Frequency.D
|
| 468 |
+
|
| 469 |
+
if len(valid_frequencies) == 1:
|
| 470 |
+
return valid_frequencies[0]
|
| 471 |
+
|
| 472 |
+
# Select based on weighted probabilities
|
| 473 |
+
scores = np.array(frequency_scores)
|
| 474 |
+
probabilities = scores / scores.sum()
|
| 475 |
+
|
| 476 |
+
return rng.choice(valid_frequencies, p=probabilities)
|
| 477 |
+
|
| 478 |
+
|
| 479 |
+
def select_safe_start_date(
|
| 480 |
+
total_length: int,
|
| 481 |
+
frequency: Frequency,
|
| 482 |
+
rng: Generator = np.random.default_rng(),
|
| 483 |
+
max_retries: int = 10,
|
| 484 |
+
) -> np.datetime64:
|
| 485 |
+
"""
|
| 486 |
+
Select a safe start date that ensures the entire time series (history + future)
|
| 487 |
+
will not exceed pandas' datetime bounds.
|
| 488 |
+
|
| 489 |
+
Args:
|
| 490 |
+
total_length: Total length of the time series (history + future)
|
| 491 |
+
frequency: Time series frequency
|
| 492 |
+
rng: Random number generator instance
|
| 493 |
+
max_retries: Maximum number of retry attempts
|
| 494 |
+
|
| 495 |
+
Returns:
|
| 496 |
+
A safe start date that prevents timestamp overflow
|
| 497 |
+
|
| 498 |
+
Raises:
|
| 499 |
+
ValueError: If no safe start date is found after max_retries or if the required
|
| 500 |
+
time span exceeds the available date window
|
| 501 |
+
"""
|
| 502 |
+
days_per_period = frequency.get_days_per_period()
|
| 503 |
+
|
| 504 |
+
# Calculate approximate duration in days
|
| 505 |
+
total_days = total_length * days_per_period
|
| 506 |
+
|
| 507 |
+
# Define safe bounds: ensure end date doesn't exceed BASE_END_DATE
|
| 508 |
+
latest_safe_start = BASE_END_DATE - np.timedelta64(int(total_days), "D")
|
| 509 |
+
earliest_safe_start = BASE_START_DATE
|
| 510 |
+
|
| 511 |
+
# Check if the required time span exceeds the available window
|
| 512 |
+
if latest_safe_start < earliest_safe_start:
|
| 513 |
+
available_days = (
|
| 514 |
+
(BASE_END_DATE - BASE_START_DATE).astype("timedelta64[D]").astype(int)
|
| 515 |
+
)
|
| 516 |
+
available_years = available_days / 365.25
|
| 517 |
+
required_years = total_days / 365.25
|
| 518 |
+
raise ValueError(
|
| 519 |
+
f"Required time span ({required_years:.1f} years, {total_days:.0f} days) "
|
| 520 |
+
f"exceeds available date window ({available_years:.1f} years, {available_days} days). "
|
| 521 |
+
f"Reduce total_length ({total_length}) or extend the date window."
|
| 522 |
+
)
|
| 523 |
+
|
| 524 |
+
# Convert to nanoseconds for random sampling
|
| 525 |
+
earliest_ns = earliest_safe_start.astype("datetime64[ns]").astype(np.int64)
|
| 526 |
+
latest_ns = latest_safe_start.astype("datetime64[ns]").astype(np.int64)
|
| 527 |
+
|
| 528 |
+
for _ in range(max_retries):
|
| 529 |
+
# Uniformly sample a start date within bounds
|
| 530 |
+
random_ns = rng.integers(earliest_ns, latest_ns + 1)
|
| 531 |
+
start_date = np.datetime64(int(random_ns), "ns")
|
| 532 |
+
|
| 533 |
+
# Verify safety
|
| 534 |
+
if validate_frequency_safety(start_date, total_length, frequency):
|
| 535 |
+
return start_date
|
| 536 |
+
|
| 537 |
+
# Default to base start date if no safe start date is found
|
| 538 |
+
return BASE_START_DATE
|
src/data/loaders.py
ADDED
|
@@ -0,0 +1,661 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import random
|
| 3 |
+
from typing import Dict, Iterator, List, Optional
|
| 4 |
+
|
| 5 |
+
import numpy as np
|
| 6 |
+
import pandas as pd
|
| 7 |
+
import torch
|
| 8 |
+
|
| 9 |
+
from src.data.batch_composer import BatchComposer, ComposedDataset
|
| 10 |
+
from src.data.containers import BatchTimeSeriesContainer
|
| 11 |
+
from src.data.frequency import parse_frequency
|
| 12 |
+
from src.gift_eval.constants import ALL_DATASETS
|
| 13 |
+
from src.gift_eval.data import Dataset as GiftEvalDataset
|
| 14 |
+
|
| 15 |
+
logger = logging.getLogger(__name__)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class GiftEvalDataLoader:
|
| 19 |
+
"""
|
| 20 |
+
Data loader for GIFT-eval datasets, converting them to BatchTimeSeriesContainer format.
|
| 21 |
+
Supports both training and validation modes.
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
TERMS = ["short", "medium", "long"]
|
| 25 |
+
|
| 26 |
+
def __init__(
|
| 27 |
+
self,
|
| 28 |
+
mode: str = "train",
|
| 29 |
+
batch_size: int = 32,
|
| 30 |
+
device: Optional[torch.device] = None,
|
| 31 |
+
shuffle: bool = True,
|
| 32 |
+
to_univariate: bool = False,
|
| 33 |
+
max_context_length: Optional[int] = None,
|
| 34 |
+
max_windows: int = 20,
|
| 35 |
+
skip_datasets_with_nans: bool = False,
|
| 36 |
+
datasets_to_use: Optional[List[str]] = None,
|
| 37 |
+
dataset_storage_path: Optional[str] = None,
|
| 38 |
+
):
|
| 39 |
+
"""
|
| 40 |
+
Initialize GIFT-eval data loader.
|
| 41 |
+
|
| 42 |
+
Args:
|
| 43 |
+
mode: Either "train" or "validation"
|
| 44 |
+
batch_size: Number of samples per batch
|
| 45 |
+
device: Device to load data to
|
| 46 |
+
shuffle: Whether to shuffle data
|
| 47 |
+
to_univariate: Whether to convert multivariate data to multiple univariate series
|
| 48 |
+
max_context_length: Optional maximum total window length (context + forecast) to prevent memory issues
|
| 49 |
+
max_windows: Number of windows to use for training/validation
|
| 50 |
+
skip_datasets_with_nans: Whether to skip datasets/series that contain NaN values
|
| 51 |
+
datasets_to_use: Optional list of dataset names to use. If None, uses all available datasets
|
| 52 |
+
dataset_storage_path: Path on disk where GIFT-eval HuggingFace datasets are stored
|
| 53 |
+
"""
|
| 54 |
+
# Use specified datasets or all available datasets if none specified
|
| 55 |
+
if datasets_to_use is not None and len(datasets_to_use) > 0:
|
| 56 |
+
# Validate that requested datasets are available
|
| 57 |
+
invalid_datasets = [ds for ds in datasets_to_use if ds not in ALL_DATASETS]
|
| 58 |
+
if invalid_datasets:
|
| 59 |
+
logger.warning(f"Invalid datasets requested: {invalid_datasets}")
|
| 60 |
+
logger.warning(f"Available datasets: {ALL_DATASETS}")
|
| 61 |
+
# Use only valid datasets
|
| 62 |
+
self.dataset_names = [
|
| 63 |
+
ds for ds in datasets_to_use if ds in ALL_DATASETS
|
| 64 |
+
]
|
| 65 |
+
else:
|
| 66 |
+
self.dataset_names = datasets_to_use
|
| 67 |
+
else:
|
| 68 |
+
self.dataset_names = ALL_DATASETS
|
| 69 |
+
|
| 70 |
+
# Log dataset selection
|
| 71 |
+
if datasets_to_use is not None and len(datasets_to_use) > 0:
|
| 72 |
+
logger.info(
|
| 73 |
+
f"Using subset of datasets: {len(self.dataset_names)}/{len(ALL_DATASETS)} datasets"
|
| 74 |
+
)
|
| 75 |
+
logger.info(f"Selected datasets: {self.dataset_names}")
|
| 76 |
+
else:
|
| 77 |
+
logger.info(
|
| 78 |
+
f"Using all available datasets: {len(self.dataset_names)} datasets"
|
| 79 |
+
)
|
| 80 |
+
|
| 81 |
+
self.terms = self.TERMS
|
| 82 |
+
self.mode = mode
|
| 83 |
+
self.batch_size = batch_size
|
| 84 |
+
self.device = device
|
| 85 |
+
self.shuffle = shuffle
|
| 86 |
+
self.to_univariate = to_univariate
|
| 87 |
+
self.max_context_length = max_context_length
|
| 88 |
+
self.skip_datasets_with_nans = skip_datasets_with_nans
|
| 89 |
+
|
| 90 |
+
# Window configuration based on mode
|
| 91 |
+
self.max_windows = max_windows
|
| 92 |
+
self.dataset_storage_path = dataset_storage_path
|
| 93 |
+
|
| 94 |
+
# Load all datasets and prepare data
|
| 95 |
+
self._load_datasets()
|
| 96 |
+
|
| 97 |
+
# Create iterator state
|
| 98 |
+
self._current_idx = 0
|
| 99 |
+
self._epoch_data = []
|
| 100 |
+
self._prepare_epoch_data()
|
| 101 |
+
|
| 102 |
+
def _load_datasets(self) -> None:
|
| 103 |
+
"""Load all specified GIFT-eval datasets."""
|
| 104 |
+
self.datasets = {}
|
| 105 |
+
self.dataset_prediction_lengths = {}
|
| 106 |
+
|
| 107 |
+
for dataset_name in self.dataset_names:
|
| 108 |
+
if dataset_name.startswith("m4_"):
|
| 109 |
+
max_windows = 1
|
| 110 |
+
else:
|
| 111 |
+
max_windows = self.max_windows
|
| 112 |
+
try:
|
| 113 |
+
# Determine if we need univariate conversion
|
| 114 |
+
# First check with multivariate to see target dimension
|
| 115 |
+
temp_dataset = GiftEvalDataset(
|
| 116 |
+
name=dataset_name,
|
| 117 |
+
term=self.terms[0], # Use first term to check dimensionality
|
| 118 |
+
to_univariate=False,
|
| 119 |
+
max_windows=max_windows,
|
| 120 |
+
storage_path=self.dataset_storage_path,
|
| 121 |
+
)
|
| 122 |
+
|
| 123 |
+
# Convert to univariate if needed
|
| 124 |
+
to_univariate = self.to_univariate and temp_dataset.target_dim > 1
|
| 125 |
+
|
| 126 |
+
# Load datasets for all terms
|
| 127 |
+
for term in self.terms:
|
| 128 |
+
dataset_key = f"{dataset_name}_{term}"
|
| 129 |
+
dataset = GiftEvalDataset(
|
| 130 |
+
name=dataset_name,
|
| 131 |
+
term=term,
|
| 132 |
+
to_univariate=to_univariate,
|
| 133 |
+
max_windows=max_windows,
|
| 134 |
+
storage_path=self.dataset_storage_path,
|
| 135 |
+
)
|
| 136 |
+
|
| 137 |
+
self.datasets[dataset_key] = dataset
|
| 138 |
+
self.dataset_prediction_lengths[dataset_key] = (
|
| 139 |
+
dataset.prediction_length
|
| 140 |
+
)
|
| 141 |
+
|
| 142 |
+
logger.info(
|
| 143 |
+
f"Loaded {dataset_key} - prediction_length: {dataset.prediction_length}, "
|
| 144 |
+
f"frequency: {dataset.freq}, target_dim: {dataset.target_dim}, "
|
| 145 |
+
f"min_length: {dataset._min_series_length}, windows: {dataset.windows}"
|
| 146 |
+
)
|
| 147 |
+
|
| 148 |
+
except Exception as e:
|
| 149 |
+
logger.warning(f"Failed to load dataset {dataset_name}: {str(e)}")
|
| 150 |
+
continue
|
| 151 |
+
|
| 152 |
+
def _contains_nan(self, data_entry: dict) -> bool:
|
| 153 |
+
"""Check if a data entry contains NaN values."""
|
| 154 |
+
target = data_entry.get("target")
|
| 155 |
+
if target is None:
|
| 156 |
+
return False
|
| 157 |
+
|
| 158 |
+
# Convert to numeric numpy array for robust NaN checking
|
| 159 |
+
try:
|
| 160 |
+
target_np = np.asarray(target, dtype=np.float32)
|
| 161 |
+
return np.isnan(target_np).any()
|
| 162 |
+
except Exception:
|
| 163 |
+
logger.warning(
|
| 164 |
+
"NaN check: failed to coerce target to float32; skipping entry"
|
| 165 |
+
)
|
| 166 |
+
return True
|
| 167 |
+
|
| 168 |
+
def _convert_to_container(
|
| 169 |
+
self, data_entries: List[dict], prediction_length: int, dataset_freq: str
|
| 170 |
+
) -> BatchTimeSeriesContainer:
|
| 171 |
+
"""Convert a batch of data entries to BatchTimeSeriesContainer format with fixed future length."""
|
| 172 |
+
batch_size = len(data_entries)
|
| 173 |
+
max_history_len = 0
|
| 174 |
+
|
| 175 |
+
# First pass: determine max history length after truncation
|
| 176 |
+
for entry in data_entries:
|
| 177 |
+
target = np.asarray(entry["target"], dtype=np.float32)
|
| 178 |
+
if target.ndim == 1:
|
| 179 |
+
target = target.reshape(1, -1)
|
| 180 |
+
|
| 181 |
+
_, seq_len = target.shape
|
| 182 |
+
|
| 183 |
+
# Only consider up to the last (max_context_length) values
|
| 184 |
+
effective_max_context = (
|
| 185 |
+
self.max_context_length
|
| 186 |
+
if self.max_context_length is not None
|
| 187 |
+
else seq_len
|
| 188 |
+
)
|
| 189 |
+
if seq_len > effective_max_context:
|
| 190 |
+
seq_len = effective_max_context
|
| 191 |
+
|
| 192 |
+
# History is up to (max_context_length - prediction_length)
|
| 193 |
+
history_len = max(
|
| 194 |
+
0, min(seq_len, effective_max_context) - prediction_length
|
| 195 |
+
)
|
| 196 |
+
max_history_len = max(max_history_len, history_len)
|
| 197 |
+
|
| 198 |
+
# Get number of channels from first entry
|
| 199 |
+
first_target = np.asarray(data_entries[0]["target"], dtype=np.float32)
|
| 200 |
+
if first_target.ndim == 1:
|
| 201 |
+
# Shape to [channels, time]
|
| 202 |
+
first_target = first_target.reshape(1, -1)
|
| 203 |
+
num_channels = first_target.shape[0]
|
| 204 |
+
|
| 205 |
+
# Allocate arrays
|
| 206 |
+
history_values = np.full(
|
| 207 |
+
(batch_size, max_history_len, num_channels), np.nan, dtype=np.float32
|
| 208 |
+
)
|
| 209 |
+
future_values = np.full(
|
| 210 |
+
(batch_size, prediction_length, num_channels), np.nan, dtype=np.float32
|
| 211 |
+
)
|
| 212 |
+
history_mask = np.zeros((batch_size, max_history_len), dtype=bool)
|
| 213 |
+
|
| 214 |
+
# Second pass: fill arrays
|
| 215 |
+
for i, entry in enumerate(data_entries):
|
| 216 |
+
target = np.asarray(entry["target"], dtype=np.float32)
|
| 217 |
+
if target.ndim == 1:
|
| 218 |
+
target = target.reshape(1, -1)
|
| 219 |
+
|
| 220 |
+
# Truncate to last effective_max_context points if needed
|
| 221 |
+
full_seq_len = target.shape[1]
|
| 222 |
+
total_len_allowed = (
|
| 223 |
+
self.max_context_length
|
| 224 |
+
if self.max_context_length is not None
|
| 225 |
+
else full_seq_len
|
| 226 |
+
)
|
| 227 |
+
total_len_for_entry = min(full_seq_len, total_len_allowed)
|
| 228 |
+
|
| 229 |
+
if total_len_for_entry < prediction_length + 1:
|
| 230 |
+
# Not enough length to build (history + future). Signal to caller.
|
| 231 |
+
raise ValueError(
|
| 232 |
+
"Entry too short after max_context_length truncation to form history+future window"
|
| 233 |
+
)
|
| 234 |
+
|
| 235 |
+
truncated = target[:, -total_len_for_entry:]
|
| 236 |
+
cur_history_len = total_len_for_entry - prediction_length
|
| 237 |
+
|
| 238 |
+
hist = truncated[:, :cur_history_len] # [C, H]
|
| 239 |
+
fut = truncated[
|
| 240 |
+
:, cur_history_len : cur_history_len + prediction_length
|
| 241 |
+
] # [C, P]
|
| 242 |
+
|
| 243 |
+
# Write into batch arrays with time last -> transpose to [H, C] / [P, C]
|
| 244 |
+
history_values[i, :cur_history_len, :] = hist.T
|
| 245 |
+
future_values[i, :, :] = fut.T
|
| 246 |
+
history_mask[i, :cur_history_len] = True
|
| 247 |
+
|
| 248 |
+
# Get start timestamp and frequency (replicate across batch)
|
| 249 |
+
start_timestamp = data_entries[0]["start"]
|
| 250 |
+
if hasattr(start_timestamp, "to_timestamp"):
|
| 251 |
+
start_numpy = start_timestamp.to_timestamp().to_numpy()
|
| 252 |
+
else:
|
| 253 |
+
start_numpy = pd.Timestamp(start_timestamp).to_numpy()
|
| 254 |
+
start_list = [start_numpy for _ in range(batch_size)]
|
| 255 |
+
|
| 256 |
+
# Get frequency enum and replicate across batch
|
| 257 |
+
frequency_enum = parse_frequency(dataset_freq)
|
| 258 |
+
frequency_list = [frequency_enum for _ in range(batch_size)]
|
| 259 |
+
|
| 260 |
+
# Create the container
|
| 261 |
+
return BatchTimeSeriesContainer(
|
| 262 |
+
history_values=torch.tensor(history_values, dtype=torch.float32),
|
| 263 |
+
future_values=torch.tensor(future_values, dtype=torch.float32),
|
| 264 |
+
start=start_list,
|
| 265 |
+
frequency=frequency_list,
|
| 266 |
+
history_mask=torch.tensor(history_mask, dtype=torch.bool)
|
| 267 |
+
if self.mode == "train"
|
| 268 |
+
else None,
|
| 269 |
+
)
|
| 270 |
+
|
| 271 |
+
def _prepare_epoch_data(self) -> None:
|
| 272 |
+
"""Prepare all batches for one epoch."""
|
| 273 |
+
self._epoch_data = []
|
| 274 |
+
|
| 275 |
+
for dataset_key, dataset in self.datasets.items():
|
| 276 |
+
try:
|
| 277 |
+
# Get appropriate dataset based on mode
|
| 278 |
+
if self.mode == "train":
|
| 279 |
+
data = dataset.training_dataset
|
| 280 |
+
else:
|
| 281 |
+
data = dataset.validation_dataset
|
| 282 |
+
|
| 283 |
+
# Collect all valid data entries
|
| 284 |
+
valid_entries = []
|
| 285 |
+
dataset_freq = dataset.freq
|
| 286 |
+
prediction_length = self.dataset_prediction_lengths[dataset_key]
|
| 287 |
+
|
| 288 |
+
for entry in data:
|
| 289 |
+
# Skip if contains NaN and configured to do so
|
| 290 |
+
if self.skip_datasets_with_nans and self._contains_nan(entry):
|
| 291 |
+
continue
|
| 292 |
+
|
| 293 |
+
# Check if we have enough data
|
| 294 |
+
target = np.asarray(entry["target"])
|
| 295 |
+
if target.ndim == 1:
|
| 296 |
+
seq_len = len(target)
|
| 297 |
+
else:
|
| 298 |
+
seq_len = target.shape[1]
|
| 299 |
+
|
| 300 |
+
# Need at least prediction_length + 1 for training
|
| 301 |
+
if self.mode == "train" and seq_len < prediction_length + 1:
|
| 302 |
+
continue
|
| 303 |
+
|
| 304 |
+
valid_entries.append(entry)
|
| 305 |
+
|
| 306 |
+
if not valid_entries:
|
| 307 |
+
logger.warning(f"No valid entries found for {dataset_key}")
|
| 308 |
+
continue
|
| 309 |
+
|
| 310 |
+
# Create batches
|
| 311 |
+
for i in range(0, len(valid_entries), self.batch_size):
|
| 312 |
+
batch_entries = valid_entries[i : i + self.batch_size]
|
| 313 |
+
try:
|
| 314 |
+
batch_container = self._convert_to_container(
|
| 315 |
+
batch_entries, prediction_length, dataset_freq
|
| 316 |
+
)
|
| 317 |
+
self._epoch_data.append((dataset_key, batch_container))
|
| 318 |
+
except Exception as e:
|
| 319 |
+
logger.warning(
|
| 320 |
+
f"Failed to create batch for {dataset_key}: {str(e)}"
|
| 321 |
+
)
|
| 322 |
+
continue
|
| 323 |
+
|
| 324 |
+
except Exception as e:
|
| 325 |
+
logger.warning(
|
| 326 |
+
f"Failed to process dataset {dataset_key}: {str(e)}. "
|
| 327 |
+
f"Dataset may be too short for the required offset."
|
| 328 |
+
)
|
| 329 |
+
continue
|
| 330 |
+
|
| 331 |
+
# Shuffle if in training mode
|
| 332 |
+
if self.mode == "train" and self.shuffle:
|
| 333 |
+
random.shuffle(self._epoch_data)
|
| 334 |
+
|
| 335 |
+
logger.info(f"Prepared {len(self._epoch_data)} batches for {self.mode} mode")
|
| 336 |
+
|
| 337 |
+
def __iter__(self) -> Iterator[BatchTimeSeriesContainer]:
|
| 338 |
+
"""Iterate through batches for one epoch."""
|
| 339 |
+
# Reset index at the start of each epoch
|
| 340 |
+
self._current_idx = 0
|
| 341 |
+
|
| 342 |
+
# Reshuffle data for each new epoch if in training mode
|
| 343 |
+
if self.mode == "train" and self.shuffle:
|
| 344 |
+
random.shuffle(self._epoch_data)
|
| 345 |
+
|
| 346 |
+
return self
|
| 347 |
+
|
| 348 |
+
def __next__(self) -> BatchTimeSeriesContainer:
|
| 349 |
+
"""Get next batch."""
|
| 350 |
+
if not self._epoch_data:
|
| 351 |
+
raise StopIteration("No valid data available")
|
| 352 |
+
|
| 353 |
+
# Check if we've exhausted the epoch
|
| 354 |
+
if self._current_idx >= len(self._epoch_data):
|
| 355 |
+
raise StopIteration
|
| 356 |
+
|
| 357 |
+
# Get current batch
|
| 358 |
+
dataset_key, batch = self._epoch_data[self._current_idx]
|
| 359 |
+
self._current_idx += 1
|
| 360 |
+
|
| 361 |
+
# Move to device if specified
|
| 362 |
+
if self.device is not None:
|
| 363 |
+
batch.to_device(self.device)
|
| 364 |
+
|
| 365 |
+
return batch
|
| 366 |
+
|
| 367 |
+
def __len__(self) -> int:
|
| 368 |
+
"""Return number of batches per epoch."""
|
| 369 |
+
return len(self._epoch_data)
|
| 370 |
+
|
| 371 |
+
|
| 372 |
+
class CyclicGiftEvalDataLoader:
|
| 373 |
+
"""
|
| 374 |
+
Wrapper for GiftEvalDataLoader that provides cycling behavior for training.
|
| 375 |
+
This allows training for a fixed number of iterations per epoch, cycling through
|
| 376 |
+
the available data as needed.
|
| 377 |
+
"""
|
| 378 |
+
|
| 379 |
+
def __init__(self, base_loader: GiftEvalDataLoader, num_iterations_per_epoch: int):
|
| 380 |
+
"""
|
| 381 |
+
Initialize the cyclic data loader.
|
| 382 |
+
|
| 383 |
+
Args:
|
| 384 |
+
base_loader: The underlying GiftEvalDataLoader
|
| 385 |
+
num_iterations_per_epoch: Number of iterations to run per epoch
|
| 386 |
+
"""
|
| 387 |
+
self.base_loader = base_loader
|
| 388 |
+
self.num_iterations_per_epoch = num_iterations_per_epoch
|
| 389 |
+
self.dataset_names = base_loader.dataset_names
|
| 390 |
+
self.device = base_loader.device
|
| 391 |
+
|
| 392 |
+
def __iter__(self) -> Iterator[BatchTimeSeriesContainer]:
|
| 393 |
+
"""Iterate for exactly num_iterations_per_epoch iterations."""
|
| 394 |
+
self._current_iteration = 0
|
| 395 |
+
self._base_iter = iter(self.base_loader)
|
| 396 |
+
return self
|
| 397 |
+
|
| 398 |
+
def __next__(self) -> BatchTimeSeriesContainer:
|
| 399 |
+
"""Get next batch, cycling through base loader as needed."""
|
| 400 |
+
if self._current_iteration >= self.num_iterations_per_epoch:
|
| 401 |
+
raise StopIteration
|
| 402 |
+
|
| 403 |
+
try:
|
| 404 |
+
batch = next(self._base_iter)
|
| 405 |
+
except StopIteration:
|
| 406 |
+
# Restart the base iterator when exhausted
|
| 407 |
+
self._base_iter = iter(self.base_loader)
|
| 408 |
+
batch = next(self._base_iter)
|
| 409 |
+
|
| 410 |
+
self._current_iteration += 1
|
| 411 |
+
return batch
|
| 412 |
+
|
| 413 |
+
def __len__(self) -> int:
|
| 414 |
+
"""Return the configured number of iterations per epoch."""
|
| 415 |
+
return self.num_iterations_per_epoch
|
| 416 |
+
|
| 417 |
+
|
| 418 |
+
def create_synthetic_dataloader(
|
| 419 |
+
base_data_dir: str,
|
| 420 |
+
batch_size: int = 128,
|
| 421 |
+
num_batches_per_epoch: int = 1000,
|
| 422 |
+
generator_proportions: Optional[Dict[str, float]] = None,
|
| 423 |
+
mixed_batches: bool = True,
|
| 424 |
+
augmentations: Optional[Dict[str, bool]] = None,
|
| 425 |
+
augmentation_probabilities: Optional[Dict[str, float]] = None,
|
| 426 |
+
device: Optional[torch.device] = None,
|
| 427 |
+
num_workers: int = 0,
|
| 428 |
+
pin_memory: bool = True,
|
| 429 |
+
global_seed: int = 42,
|
| 430 |
+
nan_stats_path: Optional[str] = None,
|
| 431 |
+
nan_patterns_path: Optional[str] = None,
|
| 432 |
+
chosen_scaler_name: Optional[str] = None,
|
| 433 |
+
) -> torch.utils.data.DataLoader:
|
| 434 |
+
"""
|
| 435 |
+
Create a PyTorch DataLoader for training with saved generator batches.
|
| 436 |
+
|
| 437 |
+
Args:
|
| 438 |
+
base_data_dir: Base directory containing generator subdirectories
|
| 439 |
+
batch_size: Size of each training batch
|
| 440 |
+
num_batches_per_epoch: Number of batches per epoch
|
| 441 |
+
generator_proportions: Dict mapping generator names to proportions
|
| 442 |
+
mixed_batches: Whether to create mixed or uniform batches
|
| 443 |
+
augmentations: Dict mapping augmentation names to booleans
|
| 444 |
+
augmentation_probabilities: Dict mapping augmentation names to probabilities
|
| 445 |
+
device: Target device
|
| 446 |
+
num_workers: Number of DataLoader workers
|
| 447 |
+
pin_memory: Whether to pin memory
|
| 448 |
+
global_seed: Global random seed
|
| 449 |
+
nan_stats_path: Path to nan stats file
|
| 450 |
+
chosen_scaler_name: Name of the scaler that used in training
|
| 451 |
+
|
| 452 |
+
Returns:
|
| 453 |
+
PyTorch DataLoader
|
| 454 |
+
"""
|
| 455 |
+
|
| 456 |
+
# Create batch composer
|
| 457 |
+
composer = BatchComposer(
|
| 458 |
+
base_data_dir=base_data_dir,
|
| 459 |
+
generator_proportions=generator_proportions,
|
| 460 |
+
mixed_batches=mixed_batches,
|
| 461 |
+
device=device,
|
| 462 |
+
augmentations=augmentations,
|
| 463 |
+
augmentation_probabilities=augmentation_probabilities,
|
| 464 |
+
global_seed=global_seed,
|
| 465 |
+
nan_stats_path=nan_stats_path,
|
| 466 |
+
nan_patterns_path=nan_patterns_path,
|
| 467 |
+
chosen_scaler_name=chosen_scaler_name,
|
| 468 |
+
)
|
| 469 |
+
|
| 470 |
+
# Create dataset
|
| 471 |
+
dataset = ComposedDataset(
|
| 472 |
+
batch_composer=composer,
|
| 473 |
+
num_batches_per_epoch=num_batches_per_epoch,
|
| 474 |
+
batch_size=batch_size,
|
| 475 |
+
)
|
| 476 |
+
|
| 477 |
+
# Custom collate function for BatchTimeSeriesContainer
|
| 478 |
+
def collate_fn(batch):
|
| 479 |
+
"""Custom collate function that returns a single BatchTimeSeriesContainer."""
|
| 480 |
+
# Since each item is already a BatchTimeSeriesContainer with batch_size samples,
|
| 481 |
+
# and DataLoader batch_size=1, we just return the first (and only) item
|
| 482 |
+
return batch[0]
|
| 483 |
+
|
| 484 |
+
# Create DataLoader
|
| 485 |
+
dataloader = torch.utils.data.DataLoader(
|
| 486 |
+
dataset,
|
| 487 |
+
batch_size=1, # Each dataset item is already a complete batch
|
| 488 |
+
shuffle=False,
|
| 489 |
+
num_workers=num_workers,
|
| 490 |
+
pin_memory=pin_memory,
|
| 491 |
+
collate_fn=collate_fn,
|
| 492 |
+
drop_last=False,
|
| 493 |
+
)
|
| 494 |
+
|
| 495 |
+
logger.info(
|
| 496 |
+
f"Created DataLoader with {len(dataset)} batches per epoch, "
|
| 497 |
+
f"batch_size={batch_size}, mixed_batches={mixed_batches}"
|
| 498 |
+
)
|
| 499 |
+
|
| 500 |
+
return dataloader
|
| 501 |
+
|
| 502 |
+
|
| 503 |
+
class SyntheticValidationDataset(torch.utils.data.Dataset):
|
| 504 |
+
"""
|
| 505 |
+
Fixed synthetic validation dataset that generates a small number of batches
|
| 506 |
+
using the same composition approach as training data.
|
| 507 |
+
"""
|
| 508 |
+
|
| 509 |
+
def __init__(
|
| 510 |
+
self,
|
| 511 |
+
base_data_dir: str,
|
| 512 |
+
batch_size: int = 128,
|
| 513 |
+
num_batches: int = 2,
|
| 514 |
+
future_length: int = 512,
|
| 515 |
+
generator_proportions: Optional[Dict[str, float]] = None,
|
| 516 |
+
augmentations: Optional[Dict[str, bool]] = None,
|
| 517 |
+
augmentation_probabilities: Optional[Dict[str, float]] = None,
|
| 518 |
+
device: Optional[torch.device] = None,
|
| 519 |
+
global_seed: int = 42,
|
| 520 |
+
chosen_scaler_name: Optional[str] = None,
|
| 521 |
+
nan_stats_path: Optional[str] = None,
|
| 522 |
+
nan_patterns_path: Optional[str] = None,
|
| 523 |
+
rank: int = 0,
|
| 524 |
+
world_size: int = 1,
|
| 525 |
+
):
|
| 526 |
+
"""
|
| 527 |
+
Initialize the validation dataset.
|
| 528 |
+
|
| 529 |
+
Args:
|
| 530 |
+
base_data_dir: Base directory containing generator subdirectories
|
| 531 |
+
batch_size: Size of each validation batch
|
| 532 |
+
num_batches: Number of validation batches to generate (1 or 2)
|
| 533 |
+
generator_proportions: Dict mapping generator names to proportions
|
| 534 |
+
device: Device to load tensors to
|
| 535 |
+
global_seed: Global random seed
|
| 536 |
+
chosen_scaler_name: Name of the scaler that used in training
|
| 537 |
+
"""
|
| 538 |
+
self.batch_size = batch_size
|
| 539 |
+
self.num_batches = num_batches
|
| 540 |
+
self.device = device
|
| 541 |
+
|
| 542 |
+
# Create batch composer; force validation to use max-length windows (no length shortening)
|
| 543 |
+
val_augmentations = dict(augmentations or {})
|
| 544 |
+
val_augmentations["length_shortening"] = False
|
| 545 |
+
|
| 546 |
+
self.batch_composer = BatchComposer(
|
| 547 |
+
base_data_dir=base_data_dir,
|
| 548 |
+
generator_proportions=generator_proportions,
|
| 549 |
+
mixed_batches=True, # Use mixed batches for validation
|
| 550 |
+
device=device,
|
| 551 |
+
global_seed=global_seed + 999999,
|
| 552 |
+
augmentations=val_augmentations,
|
| 553 |
+
augmentation_probabilities=augmentation_probabilities,
|
| 554 |
+
nan_stats_path=nan_stats_path,
|
| 555 |
+
nan_patterns_path=nan_patterns_path,
|
| 556 |
+
chosen_scaler_name=chosen_scaler_name,
|
| 557 |
+
rank=rank,
|
| 558 |
+
world_size=world_size,
|
| 559 |
+
)
|
| 560 |
+
|
| 561 |
+
# Pre-generate fixed validation batches
|
| 562 |
+
self.validation_batches = []
|
| 563 |
+
for i in range(num_batches):
|
| 564 |
+
batch, _ = self.batch_composer.create_batch(
|
| 565 |
+
batch_size=batch_size,
|
| 566 |
+
future_length=future_length,
|
| 567 |
+
seed=global_seed
|
| 568 |
+
+ 999999
|
| 569 |
+
+ i, # Fixed seeds for reproducible validation
|
| 570 |
+
)
|
| 571 |
+
self.validation_batches.append(batch)
|
| 572 |
+
|
| 573 |
+
logger.info(
|
| 574 |
+
f"Created {num_batches} fixed validation batches with batch_size={batch_size}"
|
| 575 |
+
)
|
| 576 |
+
|
| 577 |
+
def __len__(self) -> int:
|
| 578 |
+
return self.num_batches
|
| 579 |
+
|
| 580 |
+
def __getitem__(self, idx: int) -> BatchTimeSeriesContainer:
|
| 581 |
+
"""
|
| 582 |
+
Get a pre-generated validation batch by index.
|
| 583 |
+
|
| 584 |
+
Args:
|
| 585 |
+
idx: Batch index
|
| 586 |
+
|
| 587 |
+
Returns:
|
| 588 |
+
BatchTimeSeriesContainer
|
| 589 |
+
"""
|
| 590 |
+
if idx >= len(self.validation_batches):
|
| 591 |
+
raise IndexError(f"Batch index {idx} out of range")
|
| 592 |
+
|
| 593 |
+
batch = self.validation_batches[idx]
|
| 594 |
+
|
| 595 |
+
# Move to device if needed
|
| 596 |
+
if self.device is not None:
|
| 597 |
+
batch.to_device(self.device)
|
| 598 |
+
|
| 599 |
+
return batch
|
| 600 |
+
|
| 601 |
+
|
| 602 |
+
def create_synthetic_dataset(
|
| 603 |
+
base_data_dir: str,
|
| 604 |
+
batch_size: int = 128,
|
| 605 |
+
num_batches_per_epoch: int = 1000,
|
| 606 |
+
generator_proportions: Optional[Dict[str, float]] = None,
|
| 607 |
+
mixed_batches: bool = True,
|
| 608 |
+
augmentations: Optional[Dict[str, bool]] = None,
|
| 609 |
+
augmentation_probabilities: Optional[Dict[str, float]] = None,
|
| 610 |
+
global_seed: int = 42,
|
| 611 |
+
nan_stats_path: Optional[str] = None,
|
| 612 |
+
nan_patterns_path: Optional[str] = None,
|
| 613 |
+
chosen_scaler_name: Optional[str] = None,
|
| 614 |
+
rank: int = 0,
|
| 615 |
+
world_size: int = 1,
|
| 616 |
+
) -> ComposedDataset:
|
| 617 |
+
"""
|
| 618 |
+
Creates the ComposedDataset for training with saved generator batches.
|
| 619 |
+
|
| 620 |
+
Args:
|
| 621 |
+
base_data_dir: Base directory containing generator subdirectories.
|
| 622 |
+
batch_size: Size of each training batch.
|
| 623 |
+
num_batches_per_epoch: Number of batches per epoch.
|
| 624 |
+
generator_proportions: Dict mapping generator names to proportions.
|
| 625 |
+
mixed_batches: Whether to create mixed or uniform batches.
|
| 626 |
+
augmentations: Dict mapping augmentation names to booleans.
|
| 627 |
+
global_seed: Global random seed.
|
| 628 |
+
nan_stats_path: Path to nan stats file.
|
| 629 |
+
chosen_scaler_name: Name of the scaler to use.
|
| 630 |
+
Returns:
|
| 631 |
+
A ComposedDataset instance.
|
| 632 |
+
"""
|
| 633 |
+
# Create batch composer
|
| 634 |
+
composer = BatchComposer(
|
| 635 |
+
base_data_dir=base_data_dir,
|
| 636 |
+
generator_proportions=generator_proportions,
|
| 637 |
+
mixed_batches=mixed_batches,
|
| 638 |
+
device=None, # Device is handled in the training loop
|
| 639 |
+
augmentations=augmentations,
|
| 640 |
+
augmentation_probabilities=augmentation_probabilities,
|
| 641 |
+
global_seed=global_seed,
|
| 642 |
+
nan_stats_path=nan_stats_path,
|
| 643 |
+
nan_patterns_path=nan_patterns_path,
|
| 644 |
+
chosen_scaler_name=chosen_scaler_name,
|
| 645 |
+
rank=rank,
|
| 646 |
+
world_size=world_size,
|
| 647 |
+
)
|
| 648 |
+
|
| 649 |
+
# Create and return the dataset
|
| 650 |
+
dataset = ComposedDataset(
|
| 651 |
+
batch_composer=composer,
|
| 652 |
+
num_batches_per_epoch=num_batches_per_epoch,
|
| 653 |
+
batch_size=batch_size,
|
| 654 |
+
)
|
| 655 |
+
|
| 656 |
+
logger.info(
|
| 657 |
+
f"Created ComposedDataset with {len(dataset)} batches per epoch, "
|
| 658 |
+
f"batch_size={batch_size}, mixed_batches={mixed_batches}"
|
| 659 |
+
)
|
| 660 |
+
|
| 661 |
+
return dataset
|
src/data/scalers.py
ADDED
|
@@ -0,0 +1,360 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from abc import ABC, abstractmethod
|
| 2 |
+
from typing import Dict, Optional
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class BaseScaler(ABC):
|
| 8 |
+
"""
|
| 9 |
+
Abstract base class for time series scalers.
|
| 10 |
+
|
| 11 |
+
Defines the interface for scaling multivariate time series data with support
|
| 12 |
+
for masked values and channel-wise scaling.
|
| 13 |
+
"""
|
| 14 |
+
|
| 15 |
+
@abstractmethod
|
| 16 |
+
def compute_statistics(
|
| 17 |
+
self, history_values: torch.Tensor, history_mask: Optional[torch.Tensor] = None
|
| 18 |
+
) -> Dict[str, torch.Tensor]:
|
| 19 |
+
"""
|
| 20 |
+
Compute scaling statistics from historical data.
|
| 21 |
+
"""
|
| 22 |
+
pass
|
| 23 |
+
|
| 24 |
+
@abstractmethod
|
| 25 |
+
def scale(
|
| 26 |
+
self, data: torch.Tensor, statistics: Dict[str, torch.Tensor]
|
| 27 |
+
) -> torch.Tensor:
|
| 28 |
+
"""
|
| 29 |
+
Apply scaling transformation to data.
|
| 30 |
+
"""
|
| 31 |
+
pass
|
| 32 |
+
|
| 33 |
+
@abstractmethod
|
| 34 |
+
def inverse_scale(
|
| 35 |
+
self, scaled_data: torch.Tensor, statistics: Dict[str, torch.Tensor]
|
| 36 |
+
) -> torch.Tensor:
|
| 37 |
+
"""
|
| 38 |
+
Apply inverse scaling transformation to recover original scale.
|
| 39 |
+
"""
|
| 40 |
+
pass
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
class RobustScaler(BaseScaler):
|
| 44 |
+
"""
|
| 45 |
+
Robust scaler using median and IQR for normalization.
|
| 46 |
+
"""
|
| 47 |
+
|
| 48 |
+
def __init__(self, epsilon: float = 1e-6, min_scale: float = 1e-3):
|
| 49 |
+
if epsilon <= 0:
|
| 50 |
+
raise ValueError("epsilon must be positive")
|
| 51 |
+
if min_scale <= 0:
|
| 52 |
+
raise ValueError("min_scale must be positive")
|
| 53 |
+
self.epsilon = epsilon
|
| 54 |
+
self.min_scale = min_scale
|
| 55 |
+
|
| 56 |
+
def compute_statistics(
|
| 57 |
+
self, history_values: torch.Tensor, history_mask: Optional[torch.Tensor] = None
|
| 58 |
+
) -> Dict[str, torch.Tensor]:
|
| 59 |
+
"""
|
| 60 |
+
Compute median and IQR statistics from historical data with improved numerical stability.
|
| 61 |
+
"""
|
| 62 |
+
batch_size, seq_len, num_channels = history_values.shape
|
| 63 |
+
device = history_values.device
|
| 64 |
+
|
| 65 |
+
medians = torch.zeros(batch_size, 1, num_channels, device=device)
|
| 66 |
+
iqrs = torch.ones(batch_size, 1, num_channels, device=device)
|
| 67 |
+
|
| 68 |
+
for b in range(batch_size):
|
| 69 |
+
for c in range(num_channels):
|
| 70 |
+
channel_data = history_values[b, :, c]
|
| 71 |
+
|
| 72 |
+
if history_mask is not None:
|
| 73 |
+
mask = history_mask[b, :].bool()
|
| 74 |
+
valid_data = channel_data[mask]
|
| 75 |
+
else:
|
| 76 |
+
valid_data = channel_data
|
| 77 |
+
|
| 78 |
+
if len(valid_data) == 0:
|
| 79 |
+
continue
|
| 80 |
+
|
| 81 |
+
valid_data = valid_data[torch.isfinite(valid_data)]
|
| 82 |
+
|
| 83 |
+
if len(valid_data) == 0:
|
| 84 |
+
continue
|
| 85 |
+
|
| 86 |
+
median_val = torch.median(valid_data)
|
| 87 |
+
medians[b, 0, c] = median_val
|
| 88 |
+
|
| 89 |
+
if len(valid_data) > 1:
|
| 90 |
+
try:
|
| 91 |
+
q75 = torch.quantile(valid_data, 0.75)
|
| 92 |
+
q25 = torch.quantile(valid_data, 0.25)
|
| 93 |
+
iqr_val = q75 - q25
|
| 94 |
+
iqr_val = torch.max(
|
| 95 |
+
iqr_val, torch.tensor(self.min_scale, device=device)
|
| 96 |
+
)
|
| 97 |
+
iqrs[b, 0, c] = iqr_val
|
| 98 |
+
except Exception:
|
| 99 |
+
std_val = torch.std(valid_data)
|
| 100 |
+
iqrs[b, 0, c] = torch.max(
|
| 101 |
+
std_val, torch.tensor(self.min_scale, device=device)
|
| 102 |
+
)
|
| 103 |
+
else:
|
| 104 |
+
iqrs[b, 0, c] = self.min_scale
|
| 105 |
+
|
| 106 |
+
return {"median": medians, "iqr": iqrs}
|
| 107 |
+
|
| 108 |
+
def scale(
|
| 109 |
+
self, data: torch.Tensor, statistics: Dict[str, torch.Tensor]
|
| 110 |
+
) -> torch.Tensor:
|
| 111 |
+
"""
|
| 112 |
+
Apply robust scaling: (data - median) / (iqr + epsilon).
|
| 113 |
+
"""
|
| 114 |
+
median = statistics["median"]
|
| 115 |
+
iqr = statistics["iqr"]
|
| 116 |
+
|
| 117 |
+
denominator = torch.max(
|
| 118 |
+
iqr + self.epsilon, torch.tensor(self.min_scale, device=iqr.device)
|
| 119 |
+
)
|
| 120 |
+
scaled_data = (data - median) / denominator
|
| 121 |
+
scaled_data = torch.clamp(scaled_data, -50.0, 50.0)
|
| 122 |
+
|
| 123 |
+
return scaled_data
|
| 124 |
+
|
| 125 |
+
def inverse_scale(
|
| 126 |
+
self, scaled_data: torch.Tensor, statistics: Dict[str, torch.Tensor]
|
| 127 |
+
) -> torch.Tensor:
|
| 128 |
+
"""
|
| 129 |
+
Apply inverse robust scaling, now compatible with 3D or 4D tensors.
|
| 130 |
+
"""
|
| 131 |
+
median = statistics["median"]
|
| 132 |
+
iqr = statistics["iqr"]
|
| 133 |
+
|
| 134 |
+
denominator = torch.max(
|
| 135 |
+
iqr + self.epsilon, torch.tensor(self.min_scale, device=iqr.device)
|
| 136 |
+
)
|
| 137 |
+
|
| 138 |
+
if scaled_data.ndim == 4:
|
| 139 |
+
denominator = denominator.unsqueeze(-1)
|
| 140 |
+
median = median.unsqueeze(-1)
|
| 141 |
+
|
| 142 |
+
return scaled_data * denominator + median
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
class MinMaxScaler(BaseScaler):
|
| 146 |
+
"""
|
| 147 |
+
Min-Max scaler that normalizes data to the range [-1, 1].
|
| 148 |
+
"""
|
| 149 |
+
|
| 150 |
+
def __init__(self, epsilon: float = 1e-8):
|
| 151 |
+
if epsilon <= 0:
|
| 152 |
+
raise ValueError("epsilon must be positive")
|
| 153 |
+
self.epsilon = epsilon
|
| 154 |
+
|
| 155 |
+
def compute_statistics(
|
| 156 |
+
self, history_values: torch.Tensor, history_mask: Optional[torch.Tensor] = None
|
| 157 |
+
) -> Dict[str, torch.Tensor]:
|
| 158 |
+
"""
|
| 159 |
+
Compute min and max statistics from historical data.
|
| 160 |
+
"""
|
| 161 |
+
batch_size, seq_len, num_channels = history_values.shape
|
| 162 |
+
device = history_values.device
|
| 163 |
+
|
| 164 |
+
mins = torch.zeros(batch_size, 1, num_channels, device=device)
|
| 165 |
+
maxs = torch.ones(batch_size, 1, num_channels, device=device)
|
| 166 |
+
|
| 167 |
+
for b in range(batch_size):
|
| 168 |
+
for c in range(num_channels):
|
| 169 |
+
channel_data = history_values[b, :, c]
|
| 170 |
+
|
| 171 |
+
if history_mask is not None:
|
| 172 |
+
mask = history_mask[b, :].bool()
|
| 173 |
+
valid_data = channel_data[mask]
|
| 174 |
+
else:
|
| 175 |
+
valid_data = channel_data
|
| 176 |
+
|
| 177 |
+
if len(valid_data) == 0:
|
| 178 |
+
continue
|
| 179 |
+
|
| 180 |
+
min_val = torch.min(valid_data)
|
| 181 |
+
max_val = torch.max(valid_data)
|
| 182 |
+
|
| 183 |
+
mins[b, 0, c] = min_val
|
| 184 |
+
maxs[b, 0, c] = max_val
|
| 185 |
+
|
| 186 |
+
if torch.abs(max_val - min_val) < self.epsilon:
|
| 187 |
+
maxs[b, 0, c] = min_val + 1.0
|
| 188 |
+
|
| 189 |
+
return {"min": mins, "max": maxs}
|
| 190 |
+
|
| 191 |
+
def scale(
|
| 192 |
+
self, data: torch.Tensor, statistics: Dict[str, torch.Tensor]
|
| 193 |
+
) -> torch.Tensor:
|
| 194 |
+
"""
|
| 195 |
+
Apply min-max scaling to range [-1, 1].
|
| 196 |
+
"""
|
| 197 |
+
min_val = statistics["min"]
|
| 198 |
+
max_val = statistics["max"]
|
| 199 |
+
|
| 200 |
+
normalized = (data - min_val) / (max_val - min_val + self.epsilon)
|
| 201 |
+
return normalized * 2.0 - 1.0
|
| 202 |
+
|
| 203 |
+
def inverse_scale(
|
| 204 |
+
self, scaled_data: torch.Tensor, statistics: Dict[str, torch.Tensor]
|
| 205 |
+
) -> torch.Tensor:
|
| 206 |
+
"""
|
| 207 |
+
Apply inverse min-max scaling, now compatible with 3D or 4D tensors.
|
| 208 |
+
"""
|
| 209 |
+
min_val = statistics["min"]
|
| 210 |
+
max_val = statistics["max"]
|
| 211 |
+
|
| 212 |
+
if scaled_data.ndim == 4:
|
| 213 |
+
min_val = min_val.unsqueeze(-1)
|
| 214 |
+
max_val = max_val.unsqueeze(-1)
|
| 215 |
+
|
| 216 |
+
normalized = (scaled_data + 1.0) / 2.0
|
| 217 |
+
return normalized * (max_val - min_val + self.epsilon) + min_val
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
class MeanScaler(BaseScaler):
|
| 221 |
+
"""
|
| 222 |
+
A scaler that centers the data by subtracting the channel-wise mean.
|
| 223 |
+
|
| 224 |
+
This scaler only performs centering and does not affect the scale of the data.
|
| 225 |
+
"""
|
| 226 |
+
|
| 227 |
+
def compute_statistics(
|
| 228 |
+
self, history_values: torch.Tensor, history_mask: Optional[torch.Tensor] = None
|
| 229 |
+
) -> Dict[str, torch.Tensor]:
|
| 230 |
+
"""
|
| 231 |
+
Compute the mean for each channel from historical data.
|
| 232 |
+
"""
|
| 233 |
+
batch_size, seq_len, num_channels = history_values.shape
|
| 234 |
+
device = history_values.device
|
| 235 |
+
|
| 236 |
+
# Initialize a tensor to store the mean for each channel in each batch item
|
| 237 |
+
means = torch.zeros(batch_size, 1, num_channels, device=device)
|
| 238 |
+
|
| 239 |
+
for b in range(batch_size):
|
| 240 |
+
for c in range(num_channels):
|
| 241 |
+
channel_data = history_values[b, :, c]
|
| 242 |
+
|
| 243 |
+
# Use the mask to select only valid (observed) data points
|
| 244 |
+
if history_mask is not None:
|
| 245 |
+
mask = history_mask[b, :].bool()
|
| 246 |
+
valid_data = channel_data[mask]
|
| 247 |
+
else:
|
| 248 |
+
valid_data = channel_data
|
| 249 |
+
|
| 250 |
+
# Skip if there's no valid data for this channel
|
| 251 |
+
if len(valid_data) == 0:
|
| 252 |
+
continue
|
| 253 |
+
|
| 254 |
+
# Filter out non-finite values like NaN or Inf before computing
|
| 255 |
+
valid_data = valid_data[torch.isfinite(valid_data)]
|
| 256 |
+
|
| 257 |
+
if len(valid_data) == 0:
|
| 258 |
+
continue
|
| 259 |
+
|
| 260 |
+
# Compute the mean and store it
|
| 261 |
+
means[b, 0, c] = torch.mean(valid_data)
|
| 262 |
+
|
| 263 |
+
return {"mean": means}
|
| 264 |
+
|
| 265 |
+
def scale(
|
| 266 |
+
self, data: torch.Tensor, statistics: Dict[str, torch.Tensor]
|
| 267 |
+
) -> torch.Tensor:
|
| 268 |
+
"""
|
| 269 |
+
Apply mean centering: data - mean.
|
| 270 |
+
"""
|
| 271 |
+
mean = statistics["mean"]
|
| 272 |
+
return data - mean
|
| 273 |
+
|
| 274 |
+
def inverse_scale(
|
| 275 |
+
self, scaled_data: torch.Tensor, statistics: Dict[str, torch.Tensor]
|
| 276 |
+
) -> torch.Tensor:
|
| 277 |
+
"""
|
| 278 |
+
Apply inverse mean centering: scaled_data + mean.
|
| 279 |
+
|
| 280 |
+
Handles both 3D (e.g., training input) and 4D (e.g., model output samples) tensors.
|
| 281 |
+
"""
|
| 282 |
+
mean = statistics["mean"]
|
| 283 |
+
|
| 284 |
+
# Adjust shape for 4D tensors (batch, seq_len, channels, samples)
|
| 285 |
+
if scaled_data.ndim == 4:
|
| 286 |
+
mean = mean.unsqueeze(-1)
|
| 287 |
+
|
| 288 |
+
return scaled_data + mean
|
| 289 |
+
|
| 290 |
+
|
| 291 |
+
class MedianScaler(BaseScaler):
|
| 292 |
+
"""
|
| 293 |
+
A scaler that centers the data by subtracting the channel-wise median.
|
| 294 |
+
|
| 295 |
+
This scaler only performs centering and does not affect the scale of the data.
|
| 296 |
+
It is more robust to outliers than the MeanScaler.
|
| 297 |
+
"""
|
| 298 |
+
|
| 299 |
+
def compute_statistics(
|
| 300 |
+
self, history_values: torch.Tensor, history_mask: Optional[torch.Tensor] = None
|
| 301 |
+
) -> Dict[str, torch.Tensor]:
|
| 302 |
+
"""
|
| 303 |
+
Compute the median for each channel from historical data.
|
| 304 |
+
"""
|
| 305 |
+
batch_size, seq_len, num_channels = history_values.shape
|
| 306 |
+
device = history_values.device
|
| 307 |
+
|
| 308 |
+
# Initialize a tensor to store the median for each channel in each batch item
|
| 309 |
+
medians = torch.zeros(batch_size, 1, num_channels, device=device)
|
| 310 |
+
|
| 311 |
+
for b in range(batch_size):
|
| 312 |
+
for c in range(num_channels):
|
| 313 |
+
channel_data = history_values[b, :, c]
|
| 314 |
+
|
| 315 |
+
# Use the mask to select only valid (observed) data points
|
| 316 |
+
if history_mask is not None:
|
| 317 |
+
mask = history_mask[b, :].bool()
|
| 318 |
+
valid_data = channel_data[mask]
|
| 319 |
+
else:
|
| 320 |
+
valid_data = channel_data
|
| 321 |
+
|
| 322 |
+
# Skip if there's no valid data for this channel
|
| 323 |
+
if len(valid_data) == 0:
|
| 324 |
+
continue
|
| 325 |
+
|
| 326 |
+
# Filter out non-finite values like NaN or Inf before computing
|
| 327 |
+
valid_data = valid_data[torch.isfinite(valid_data)]
|
| 328 |
+
|
| 329 |
+
if len(valid_data) == 0:
|
| 330 |
+
continue
|
| 331 |
+
|
| 332 |
+
# Compute the median and store it
|
| 333 |
+
medians[b, 0, c] = torch.median(valid_data)
|
| 334 |
+
|
| 335 |
+
return {"median": medians}
|
| 336 |
+
|
| 337 |
+
def scale(
|
| 338 |
+
self, data: torch.Tensor, statistics: Dict[str, torch.Tensor]
|
| 339 |
+
) -> torch.Tensor:
|
| 340 |
+
"""
|
| 341 |
+
Apply median centering: data - median.
|
| 342 |
+
"""
|
| 343 |
+
median = statistics["median"]
|
| 344 |
+
return data - median
|
| 345 |
+
|
| 346 |
+
def inverse_scale(
|
| 347 |
+
self, scaled_data: torch.Tensor, statistics: Dict[str, torch.Tensor]
|
| 348 |
+
) -> torch.Tensor:
|
| 349 |
+
"""
|
| 350 |
+
Apply inverse median centering: scaled_data + median.
|
| 351 |
+
|
| 352 |
+
Handles both 3D (e.g., training input) and 4D (e.g., model output samples) tensors.
|
| 353 |
+
"""
|
| 354 |
+
median = statistics["median"]
|
| 355 |
+
|
| 356 |
+
# Adjust shape for 4D tensors (batch, seq_len, channels, samples)
|
| 357 |
+
if scaled_data.ndim == 4:
|
| 358 |
+
median = median.unsqueeze(-1)
|
| 359 |
+
|
| 360 |
+
return scaled_data + median
|
src/data/time_features.py
ADDED
|
@@ -0,0 +1,564 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
from typing import Any, Dict, List, Optional
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import pandas as pd
|
| 6 |
+
import scipy.fft as fft
|
| 7 |
+
import torch
|
| 8 |
+
from gluonts.time_feature import time_features_from_frequency_str
|
| 9 |
+
from gluonts.time_feature._base import (
|
| 10 |
+
day_of_month,
|
| 11 |
+
day_of_month_index,
|
| 12 |
+
day_of_week,
|
| 13 |
+
day_of_week_index,
|
| 14 |
+
day_of_year,
|
| 15 |
+
hour_of_day,
|
| 16 |
+
hour_of_day_index,
|
| 17 |
+
minute_of_hour,
|
| 18 |
+
minute_of_hour_index,
|
| 19 |
+
month_of_year,
|
| 20 |
+
month_of_year_index,
|
| 21 |
+
second_of_minute,
|
| 22 |
+
second_of_minute_index,
|
| 23 |
+
week_of_year,
|
| 24 |
+
week_of_year_index,
|
| 25 |
+
)
|
| 26 |
+
from gluonts.time_feature.holiday import (
|
| 27 |
+
BLACK_FRIDAY,
|
| 28 |
+
CHRISTMAS_DAY,
|
| 29 |
+
CHRISTMAS_EVE,
|
| 30 |
+
CYBER_MONDAY,
|
| 31 |
+
EASTER_MONDAY,
|
| 32 |
+
EASTER_SUNDAY,
|
| 33 |
+
GOOD_FRIDAY,
|
| 34 |
+
INDEPENDENCE_DAY,
|
| 35 |
+
LABOR_DAY,
|
| 36 |
+
MEMORIAL_DAY,
|
| 37 |
+
NEW_YEARS_DAY,
|
| 38 |
+
NEW_YEARS_EVE,
|
| 39 |
+
THANKSGIVING,
|
| 40 |
+
SpecialDateFeatureSet,
|
| 41 |
+
exponential_kernel,
|
| 42 |
+
squared_exponential_kernel,
|
| 43 |
+
)
|
| 44 |
+
from gluonts.time_feature.seasonality import get_seasonality
|
| 45 |
+
from scipy.signal import find_peaks
|
| 46 |
+
|
| 47 |
+
from src.data.constants import BASE_END_DATE, BASE_START_DATE
|
| 48 |
+
from src.data.frequency import (
|
| 49 |
+
Frequency,
|
| 50 |
+
validate_frequency_safety,
|
| 51 |
+
)
|
| 52 |
+
from src.utils.utils import device
|
| 53 |
+
|
| 54 |
+
# Configure logging
|
| 55 |
+
logging.basicConfig(
|
| 56 |
+
level=logging.DEBUG, format="%(asctime)s - %(levelname)s - %(message)s"
|
| 57 |
+
)
|
| 58 |
+
logger = logging.getLogger(__name__)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
# Enhanced feature sets for different frequencies
|
| 62 |
+
ENHANCED_TIME_FEATURES = {
|
| 63 |
+
# High-frequency features (seconds, minutes)
|
| 64 |
+
"high_freq": {
|
| 65 |
+
"normalized": [
|
| 66 |
+
second_of_minute,
|
| 67 |
+
minute_of_hour,
|
| 68 |
+
hour_of_day,
|
| 69 |
+
day_of_week,
|
| 70 |
+
day_of_month,
|
| 71 |
+
],
|
| 72 |
+
"index": [
|
| 73 |
+
second_of_minute_index,
|
| 74 |
+
minute_of_hour_index,
|
| 75 |
+
hour_of_day_index,
|
| 76 |
+
day_of_week_index,
|
| 77 |
+
],
|
| 78 |
+
},
|
| 79 |
+
# Medium-frequency features (hourly, daily)
|
| 80 |
+
"medium_freq": {
|
| 81 |
+
"normalized": [
|
| 82 |
+
hour_of_day,
|
| 83 |
+
day_of_week,
|
| 84 |
+
day_of_month,
|
| 85 |
+
day_of_year,
|
| 86 |
+
month_of_year,
|
| 87 |
+
],
|
| 88 |
+
"index": [
|
| 89 |
+
hour_of_day_index,
|
| 90 |
+
day_of_week_index,
|
| 91 |
+
day_of_month_index,
|
| 92 |
+
week_of_year_index,
|
| 93 |
+
],
|
| 94 |
+
},
|
| 95 |
+
# Low-frequency features (weekly, monthly)
|
| 96 |
+
"low_freq": {
|
| 97 |
+
"normalized": [day_of_week, day_of_month, month_of_year, week_of_year],
|
| 98 |
+
"index": [day_of_week_index, month_of_year_index, week_of_year_index],
|
| 99 |
+
},
|
| 100 |
+
}
|
| 101 |
+
|
| 102 |
+
# Holiday features for different markets/regions
|
| 103 |
+
HOLIDAY_FEATURE_SETS = {
|
| 104 |
+
"us_business": [
|
| 105 |
+
NEW_YEARS_DAY,
|
| 106 |
+
MEMORIAL_DAY,
|
| 107 |
+
INDEPENDENCE_DAY,
|
| 108 |
+
LABOR_DAY,
|
| 109 |
+
THANKSGIVING,
|
| 110 |
+
CHRISTMAS_EVE,
|
| 111 |
+
CHRISTMAS_DAY,
|
| 112 |
+
NEW_YEARS_EVE,
|
| 113 |
+
],
|
| 114 |
+
"us_retail": [
|
| 115 |
+
NEW_YEARS_DAY,
|
| 116 |
+
EASTER_SUNDAY,
|
| 117 |
+
MEMORIAL_DAY,
|
| 118 |
+
INDEPENDENCE_DAY,
|
| 119 |
+
LABOR_DAY,
|
| 120 |
+
THANKSGIVING,
|
| 121 |
+
BLACK_FRIDAY,
|
| 122 |
+
CYBER_MONDAY,
|
| 123 |
+
CHRISTMAS_EVE,
|
| 124 |
+
CHRISTMAS_DAY,
|
| 125 |
+
NEW_YEARS_EVE,
|
| 126 |
+
],
|
| 127 |
+
"christian": [
|
| 128 |
+
NEW_YEARS_DAY,
|
| 129 |
+
GOOD_FRIDAY,
|
| 130 |
+
EASTER_SUNDAY,
|
| 131 |
+
EASTER_MONDAY,
|
| 132 |
+
CHRISTMAS_EVE,
|
| 133 |
+
CHRISTMAS_DAY,
|
| 134 |
+
NEW_YEARS_EVE,
|
| 135 |
+
],
|
| 136 |
+
}
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
class TimeFeatureGenerator:
|
| 140 |
+
"""
|
| 141 |
+
Enhanced time feature generator that leverages full GluonTS capabilities.
|
| 142 |
+
"""
|
| 143 |
+
|
| 144 |
+
def __init__(
|
| 145 |
+
self,
|
| 146 |
+
use_enhanced_features: bool = True,
|
| 147 |
+
use_holiday_features: bool = True,
|
| 148 |
+
holiday_set: str = "us_business",
|
| 149 |
+
holiday_kernel: str = "exponential",
|
| 150 |
+
holiday_kernel_alpha: float = 1.0,
|
| 151 |
+
use_index_features: bool = True,
|
| 152 |
+
k_max: int = 15,
|
| 153 |
+
include_seasonality_info: bool = True,
|
| 154 |
+
use_auto_seasonality: bool = False, # New parameter
|
| 155 |
+
max_seasonal_periods: int = 3, # New parameter
|
| 156 |
+
):
|
| 157 |
+
"""
|
| 158 |
+
Initialize enhanced time feature generator.
|
| 159 |
+
|
| 160 |
+
Parameters
|
| 161 |
+
----------
|
| 162 |
+
use_enhanced_features : bool
|
| 163 |
+
Whether to use frequency-specific enhanced features
|
| 164 |
+
use_holiday_features : bool
|
| 165 |
+
Whether to include holiday features
|
| 166 |
+
holiday_set : str
|
| 167 |
+
Which holiday set to use ('us_business', 'us_retail', 'christian')
|
| 168 |
+
holiday_kernel : str
|
| 169 |
+
Holiday kernel type ('indicator', 'exponential', 'squared_exponential')
|
| 170 |
+
holiday_kernel_alpha : float
|
| 171 |
+
Kernel parameter for exponential kernels
|
| 172 |
+
use_index_features : bool
|
| 173 |
+
Whether to include index-based features alongside normalized ones
|
| 174 |
+
k_max : int
|
| 175 |
+
Maximum number of time features to pad to
|
| 176 |
+
include_seasonality_info : bool
|
| 177 |
+
Whether to include seasonality information as features
|
| 178 |
+
use_auto_seasonality : bool
|
| 179 |
+
Whether to use automatic FFT-based seasonality detection
|
| 180 |
+
max_seasonal_periods : int
|
| 181 |
+
Maximum number of seasonal periods to detect automatically
|
| 182 |
+
"""
|
| 183 |
+
self.use_enhanced_features = use_enhanced_features
|
| 184 |
+
self.use_holiday_features = use_holiday_features
|
| 185 |
+
self.holiday_set = holiday_set
|
| 186 |
+
self.use_index_features = use_index_features
|
| 187 |
+
self.k_max = k_max
|
| 188 |
+
self.include_seasonality_info = include_seasonality_info
|
| 189 |
+
self.use_auto_seasonality = use_auto_seasonality
|
| 190 |
+
self.max_seasonal_periods = max_seasonal_periods
|
| 191 |
+
|
| 192 |
+
# Initialize holiday feature set
|
| 193 |
+
self.holiday_feature_set = None
|
| 194 |
+
if use_holiday_features and holiday_set in HOLIDAY_FEATURE_SETS:
|
| 195 |
+
kernel_func = self._get_holiday_kernel(holiday_kernel, holiday_kernel_alpha)
|
| 196 |
+
self.holiday_feature_set = SpecialDateFeatureSet(
|
| 197 |
+
HOLIDAY_FEATURE_SETS[holiday_set], kernel_func
|
| 198 |
+
)
|
| 199 |
+
|
| 200 |
+
def _get_holiday_kernel(self, kernel_type: str, alpha: float):
|
| 201 |
+
"""Get holiday kernel function."""
|
| 202 |
+
if kernel_type == "exponential":
|
| 203 |
+
return exponential_kernel(alpha)
|
| 204 |
+
elif kernel_type == "squared_exponential":
|
| 205 |
+
return squared_exponential_kernel(alpha)
|
| 206 |
+
else:
|
| 207 |
+
# Default indicator kernel
|
| 208 |
+
return lambda x: float(x == 0)
|
| 209 |
+
|
| 210 |
+
def _get_feature_category(self, freq_str: str) -> str:
|
| 211 |
+
"""Determine feature category based on frequency."""
|
| 212 |
+
if freq_str in ["s", "1min", "5min", "10min", "15min"]:
|
| 213 |
+
return "high_freq"
|
| 214 |
+
elif freq_str in ["h", "D"]:
|
| 215 |
+
return "medium_freq"
|
| 216 |
+
else:
|
| 217 |
+
return "low_freq"
|
| 218 |
+
|
| 219 |
+
def _compute_enhanced_features(
|
| 220 |
+
self, period_index: pd.PeriodIndex, freq_str: str
|
| 221 |
+
) -> np.ndarray:
|
| 222 |
+
"""Compute enhanced time features based on frequency."""
|
| 223 |
+
if not self.use_enhanced_features:
|
| 224 |
+
return np.array([]).reshape(len(period_index), 0)
|
| 225 |
+
|
| 226 |
+
category = self._get_feature_category(freq_str)
|
| 227 |
+
feature_config = ENHANCED_TIME_FEATURES[category]
|
| 228 |
+
|
| 229 |
+
features = []
|
| 230 |
+
|
| 231 |
+
# Add normalized features
|
| 232 |
+
for feat_func in feature_config["normalized"]:
|
| 233 |
+
try:
|
| 234 |
+
feat_values = feat_func(period_index)
|
| 235 |
+
features.append(feat_values)
|
| 236 |
+
except Exception:
|
| 237 |
+
continue
|
| 238 |
+
|
| 239 |
+
# Add index features if enabled
|
| 240 |
+
if self.use_index_features:
|
| 241 |
+
for feat_func in feature_config["index"]:
|
| 242 |
+
try:
|
| 243 |
+
feat_values = feat_func(period_index)
|
| 244 |
+
# Normalize index features to [0, 1] range
|
| 245 |
+
if feat_values.max() > 0:
|
| 246 |
+
feat_values = feat_values / feat_values.max()
|
| 247 |
+
features.append(feat_values)
|
| 248 |
+
except Exception:
|
| 249 |
+
continue
|
| 250 |
+
|
| 251 |
+
if features:
|
| 252 |
+
return np.stack(features, axis=-1)
|
| 253 |
+
else:
|
| 254 |
+
return np.array([]).reshape(len(period_index), 0)
|
| 255 |
+
|
| 256 |
+
def _compute_holiday_features(self, date_range: pd.DatetimeIndex) -> np.ndarray:
|
| 257 |
+
"""Compute holiday features."""
|
| 258 |
+
if not self.use_holiday_features or self.holiday_feature_set is None:
|
| 259 |
+
return np.array([]).reshape(len(date_range), 0)
|
| 260 |
+
|
| 261 |
+
try:
|
| 262 |
+
holiday_features = self.holiday_feature_set(date_range)
|
| 263 |
+
return holiday_features.T # Transpose to get [time, features] shape
|
| 264 |
+
except Exception:
|
| 265 |
+
return np.array([]).reshape(len(date_range), 0)
|
| 266 |
+
|
| 267 |
+
def _detect_auto_seasonality(self, time_series_values: np.ndarray) -> list:
|
| 268 |
+
"""
|
| 269 |
+
Detect seasonal periods automatically using FFT analysis.
|
| 270 |
+
|
| 271 |
+
Parameters
|
| 272 |
+
----------
|
| 273 |
+
time_series_values : np.ndarray
|
| 274 |
+
Time series values for seasonality detection
|
| 275 |
+
|
| 276 |
+
Returns
|
| 277 |
+
-------
|
| 278 |
+
list
|
| 279 |
+
List of detected seasonal periods
|
| 280 |
+
"""
|
| 281 |
+
if not self.use_auto_seasonality or len(time_series_values) < 10:
|
| 282 |
+
return []
|
| 283 |
+
|
| 284 |
+
try:
|
| 285 |
+
# Remove NaN values
|
| 286 |
+
values = time_series_values[~np.isnan(time_series_values)]
|
| 287 |
+
if len(values) < 10:
|
| 288 |
+
return []
|
| 289 |
+
|
| 290 |
+
# Simple linear detrending
|
| 291 |
+
x = np.arange(len(values))
|
| 292 |
+
coeffs = np.polyfit(x, values, 1)
|
| 293 |
+
trend = np.polyval(coeffs, x)
|
| 294 |
+
detrended = values - trend
|
| 295 |
+
|
| 296 |
+
# Apply Hann window to reduce spectral leakage
|
| 297 |
+
window = np.hanning(len(detrended))
|
| 298 |
+
windowed = detrended * window
|
| 299 |
+
|
| 300 |
+
# Zero padding for better frequency resolution
|
| 301 |
+
padded_length = len(windowed) * 2
|
| 302 |
+
padded_values = np.zeros(padded_length)
|
| 303 |
+
padded_values[: len(windowed)] = windowed
|
| 304 |
+
|
| 305 |
+
# Compute FFT
|
| 306 |
+
fft_values = fft.rfft(padded_values)
|
| 307 |
+
fft_magnitudes = np.abs(fft_values)
|
| 308 |
+
freqs = np.fft.rfftfreq(padded_length)
|
| 309 |
+
|
| 310 |
+
# Exclude DC component
|
| 311 |
+
fft_magnitudes[0] = 0.0
|
| 312 |
+
|
| 313 |
+
# Find peaks with threshold (5% of max magnitude)
|
| 314 |
+
threshold = 0.05 * np.max(fft_magnitudes)
|
| 315 |
+
peak_indices, _ = find_peaks(fft_magnitudes, height=threshold)
|
| 316 |
+
|
| 317 |
+
if len(peak_indices) == 0:
|
| 318 |
+
return []
|
| 319 |
+
|
| 320 |
+
# Sort by magnitude and take top periods
|
| 321 |
+
sorted_indices = peak_indices[
|
| 322 |
+
np.argsort(fft_magnitudes[peak_indices])[::-1]
|
| 323 |
+
]
|
| 324 |
+
top_indices = sorted_indices[: self.max_seasonal_periods]
|
| 325 |
+
|
| 326 |
+
# Convert frequencies to periods
|
| 327 |
+
periods = []
|
| 328 |
+
for idx in top_indices:
|
| 329 |
+
if freqs[idx] > 0:
|
| 330 |
+
period = 1.0 / freqs[idx]
|
| 331 |
+
# Scale back to original length and round
|
| 332 |
+
period = round(period / 2) # Account for zero padding
|
| 333 |
+
if 2 <= period <= len(values) // 2: # Reasonable period range
|
| 334 |
+
periods.append(period)
|
| 335 |
+
|
| 336 |
+
return list(set(periods)) # Remove duplicates
|
| 337 |
+
|
| 338 |
+
except Exception:
|
| 339 |
+
return []
|
| 340 |
+
|
| 341 |
+
def _compute_seasonality_features(
|
| 342 |
+
self,
|
| 343 |
+
period_index: pd.PeriodIndex,
|
| 344 |
+
freq_str: str,
|
| 345 |
+
time_series_values: np.ndarray = None,
|
| 346 |
+
) -> np.ndarray:
|
| 347 |
+
"""Compute seasonality-aware features."""
|
| 348 |
+
if not self.include_seasonality_info:
|
| 349 |
+
return np.array([]).reshape(len(period_index), 0)
|
| 350 |
+
|
| 351 |
+
all_seasonal_features = []
|
| 352 |
+
|
| 353 |
+
# Original frequency-based seasonality
|
| 354 |
+
try:
|
| 355 |
+
seasonality = get_seasonality(freq_str)
|
| 356 |
+
if seasonality > 1:
|
| 357 |
+
positions = np.arange(len(period_index))
|
| 358 |
+
sin_feat = np.sin(2 * np.pi * positions / seasonality)
|
| 359 |
+
cos_feat = np.cos(2 * np.pi * positions / seasonality)
|
| 360 |
+
all_seasonal_features.extend([sin_feat, cos_feat])
|
| 361 |
+
except Exception:
|
| 362 |
+
pass
|
| 363 |
+
|
| 364 |
+
# Automatic seasonality detection
|
| 365 |
+
if self.use_auto_seasonality and time_series_values is not None:
|
| 366 |
+
auto_periods = self._detect_auto_seasonality(time_series_values)
|
| 367 |
+
for period in auto_periods:
|
| 368 |
+
try:
|
| 369 |
+
positions = np.arange(len(period_index))
|
| 370 |
+
sin_feat = np.sin(2 * np.pi * positions / period)
|
| 371 |
+
cos_feat = np.cos(2 * np.pi * positions / period)
|
| 372 |
+
all_seasonal_features.extend([sin_feat, cos_feat])
|
| 373 |
+
except Exception:
|
| 374 |
+
continue
|
| 375 |
+
|
| 376 |
+
if all_seasonal_features:
|
| 377 |
+
return np.stack(all_seasonal_features, axis=-1)
|
| 378 |
+
else:
|
| 379 |
+
return np.array([]).reshape(len(period_index), 0)
|
| 380 |
+
|
| 381 |
+
def compute_features(
|
| 382 |
+
self,
|
| 383 |
+
period_index: pd.PeriodIndex,
|
| 384 |
+
date_range: pd.DatetimeIndex,
|
| 385 |
+
freq_str: str,
|
| 386 |
+
time_series_values: np.ndarray = None,
|
| 387 |
+
) -> np.ndarray:
|
| 388 |
+
"""
|
| 389 |
+
Compute all time features for given period index.
|
| 390 |
+
|
| 391 |
+
Parameters
|
| 392 |
+
----------
|
| 393 |
+
period_index : pd.PeriodIndex
|
| 394 |
+
Period index for computing features
|
| 395 |
+
date_range : pd.DatetimeIndex
|
| 396 |
+
Corresponding datetime index for holiday features
|
| 397 |
+
freq_str : str
|
| 398 |
+
Frequency string
|
| 399 |
+
time_series_values : np.ndarray, optional
|
| 400 |
+
Time series values for automatic seasonality detection
|
| 401 |
+
|
| 402 |
+
Returns
|
| 403 |
+
-------
|
| 404 |
+
np.ndarray
|
| 405 |
+
Time features array of shape [time_steps, num_features]
|
| 406 |
+
"""
|
| 407 |
+
all_features = []
|
| 408 |
+
|
| 409 |
+
# Standard GluonTS features
|
| 410 |
+
try:
|
| 411 |
+
standard_features = time_features_from_frequency_str(freq_str)
|
| 412 |
+
if standard_features:
|
| 413 |
+
std_feat = np.stack(
|
| 414 |
+
[feat(period_index) for feat in standard_features], axis=-1
|
| 415 |
+
)
|
| 416 |
+
all_features.append(std_feat)
|
| 417 |
+
except Exception:
|
| 418 |
+
pass
|
| 419 |
+
|
| 420 |
+
# Enhanced features
|
| 421 |
+
enhanced_feat = self._compute_enhanced_features(period_index, freq_str)
|
| 422 |
+
if enhanced_feat.shape[1] > 0:
|
| 423 |
+
all_features.append(enhanced_feat)
|
| 424 |
+
|
| 425 |
+
# Holiday features
|
| 426 |
+
holiday_feat = self._compute_holiday_features(date_range)
|
| 427 |
+
if holiday_feat.shape[1] > 0:
|
| 428 |
+
all_features.append(holiday_feat)
|
| 429 |
+
|
| 430 |
+
# Seasonality features (including auto-detected)
|
| 431 |
+
seasonality_feat = self._compute_seasonality_features(
|
| 432 |
+
period_index, freq_str, time_series_values
|
| 433 |
+
)
|
| 434 |
+
if seasonality_feat.shape[1] > 0:
|
| 435 |
+
all_features.append(seasonality_feat)
|
| 436 |
+
|
| 437 |
+
if all_features:
|
| 438 |
+
combined_features = np.concatenate(all_features, axis=-1)
|
| 439 |
+
else:
|
| 440 |
+
combined_features = np.zeros((len(period_index), 1))
|
| 441 |
+
|
| 442 |
+
return combined_features
|
| 443 |
+
|
| 444 |
+
|
| 445 |
+
def compute_batch_time_features(
|
| 446 |
+
start: List[np.datetime64],
|
| 447 |
+
history_length: int,
|
| 448 |
+
future_length: int,
|
| 449 |
+
batch_size: int,
|
| 450 |
+
frequency: List[Frequency],
|
| 451 |
+
K_max: int = 6,
|
| 452 |
+
time_feature_config: Optional[Dict[str, Any]] = None,
|
| 453 |
+
):
|
| 454 |
+
"""
|
| 455 |
+
Compute time features from start timestamps and frequency.
|
| 456 |
+
|
| 457 |
+
Parameters
|
| 458 |
+
----------
|
| 459 |
+
start : array-like, shape (batch_size,)
|
| 460 |
+
Start timestamps for each batch item.
|
| 461 |
+
history_length : int
|
| 462 |
+
Length of history sequence.
|
| 463 |
+
future_length : int
|
| 464 |
+
Length of target sequence.
|
| 465 |
+
batch_size : int
|
| 466 |
+
Batch size.
|
| 467 |
+
frequency : array-like, shape (batch_size,)
|
| 468 |
+
Frequency of the time series.
|
| 469 |
+
K_max : int, optional
|
| 470 |
+
Maximum number of time features to pad to (default: 6).
|
| 471 |
+
time_feature_config : dict, optional
|
| 472 |
+
Configuration for enhanced time features.
|
| 473 |
+
|
| 474 |
+
Returns
|
| 475 |
+
-------
|
| 476 |
+
tuple
|
| 477 |
+
(history_time_features, target_time_features) where each is a torch.Tensor
|
| 478 |
+
of shape (batch_size, length, K_max).
|
| 479 |
+
"""
|
| 480 |
+
# Initialize enhanced feature generator
|
| 481 |
+
feature_config = time_feature_config or {}
|
| 482 |
+
feature_generator = TimeFeatureGenerator(**feature_config)
|
| 483 |
+
|
| 484 |
+
# Generate timestamps and features
|
| 485 |
+
history_features_list = []
|
| 486 |
+
future_features_list = []
|
| 487 |
+
total_length = history_length + future_length
|
| 488 |
+
for i in range(batch_size):
|
| 489 |
+
frequency_i = frequency[i]
|
| 490 |
+
freq_str = frequency_i.to_pandas_freq(for_date_range=True)
|
| 491 |
+
period_freq_str = frequency_i.to_pandas_freq(for_date_range=False)
|
| 492 |
+
|
| 493 |
+
# Validate start timestamp is within safe bounds
|
| 494 |
+
start_ts = pd.Timestamp(start[i])
|
| 495 |
+
if not validate_frequency_safety(start_ts, total_length, frequency_i):
|
| 496 |
+
logger.debug(
|
| 497 |
+
f"Start date {start_ts} not safe for total_length={total_length}, frequency={frequency_i}. "
|
| 498 |
+
f"Using BASE_START_DATE instead."
|
| 499 |
+
)
|
| 500 |
+
start_ts = BASE_START_DATE
|
| 501 |
+
|
| 502 |
+
# Create history range with bounds checking
|
| 503 |
+
history_range = pd.date_range(
|
| 504 |
+
start=start_ts, periods=history_length, freq=freq_str
|
| 505 |
+
)
|
| 506 |
+
|
| 507 |
+
# Check if history range goes beyond safe bounds
|
| 508 |
+
if history_range[-1] > BASE_END_DATE:
|
| 509 |
+
safe_start = BASE_END_DATE - pd.tseries.frequencies.to_offset(freq_str) * (
|
| 510 |
+
history_length + future_length
|
| 511 |
+
)
|
| 512 |
+
if safe_start < BASE_START_DATE:
|
| 513 |
+
safe_start = BASE_START_DATE
|
| 514 |
+
history_range = pd.date_range(
|
| 515 |
+
start=safe_start, periods=history_length, freq=freq_str
|
| 516 |
+
)
|
| 517 |
+
|
| 518 |
+
future_start = history_range[-1] + pd.tseries.frequencies.to_offset(freq_str)
|
| 519 |
+
future_range = pd.date_range(
|
| 520 |
+
start=future_start, periods=future_length, freq=freq_str
|
| 521 |
+
)
|
| 522 |
+
|
| 523 |
+
# Convert to period indices
|
| 524 |
+
history_period_idx = history_range.to_period(period_freq_str)
|
| 525 |
+
future_period_idx = future_range.to_period(period_freq_str)
|
| 526 |
+
|
| 527 |
+
# Compute enhanced features
|
| 528 |
+
history_features = feature_generator.compute_features(
|
| 529 |
+
history_period_idx, history_range, freq_str
|
| 530 |
+
)
|
| 531 |
+
future_features = feature_generator.compute_features(
|
| 532 |
+
future_period_idx, future_range, freq_str
|
| 533 |
+
)
|
| 534 |
+
|
| 535 |
+
# Pad or truncate to K_max
|
| 536 |
+
history_features = _pad_or_truncate_features(history_features, K_max)
|
| 537 |
+
future_features = _pad_or_truncate_features(future_features, K_max)
|
| 538 |
+
|
| 539 |
+
history_features_list.append(history_features)
|
| 540 |
+
future_features_list.append(future_features)
|
| 541 |
+
|
| 542 |
+
# Stack into batch tensors
|
| 543 |
+
history_time_features = np.stack(history_features_list, axis=0)
|
| 544 |
+
future_time_features = np.stack(future_features_list, axis=0)
|
| 545 |
+
|
| 546 |
+
return (
|
| 547 |
+
torch.from_numpy(history_time_features).float().to(device),
|
| 548 |
+
torch.from_numpy(future_time_features).float().to(device),
|
| 549 |
+
)
|
| 550 |
+
|
| 551 |
+
|
| 552 |
+
def _pad_or_truncate_features(features: np.ndarray, K_max: int) -> np.ndarray:
|
| 553 |
+
"""Pad with zeros or truncate features to K_max dimensions."""
|
| 554 |
+
seq_len, num_features = features.shape
|
| 555 |
+
|
| 556 |
+
if num_features < K_max:
|
| 557 |
+
# Pad with zeros
|
| 558 |
+
padding = np.zeros((seq_len, K_max - num_features))
|
| 559 |
+
features = np.concatenate([features, padding], axis=-1)
|
| 560 |
+
elif num_features > K_max:
|
| 561 |
+
# Truncate to K_max (keep most important features first)
|
| 562 |
+
features = features[:, :K_max]
|
| 563 |
+
|
| 564 |
+
return features
|
src/data/utils.py
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import random
|
| 2 |
+
from typing import Optional, Tuple, Union
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def sample_future_length(
|
| 6 |
+
range: Union[Tuple[int, int], str] = "gift_eval",
|
| 7 |
+
total_length: Optional[int] = None,
|
| 8 |
+
) -> int:
|
| 9 |
+
"""
|
| 10 |
+
Sample a forecast length.
|
| 11 |
+
|
| 12 |
+
- If `range` is a tuple, uniformly sample in [min, max]. When `total_length` is
|
| 13 |
+
provided, enforce a cap so the result is at most floor(0.45 * total_length).
|
| 14 |
+
- If `range` is "gift_eval", sample from a pre-defined weighted set. When
|
| 15 |
+
`total_length` is provided, filter out candidates greater than
|
| 16 |
+
floor(0.45 * total_length) before sampling.
|
| 17 |
+
"""
|
| 18 |
+
# Compute the cap when total_length is provided
|
| 19 |
+
cap: Optional[int] = None
|
| 20 |
+
if total_length is not None:
|
| 21 |
+
cap = max(1, int(0.45 * int(total_length)))
|
| 22 |
+
|
| 23 |
+
if isinstance(range, tuple):
|
| 24 |
+
min_len, max_len = range
|
| 25 |
+
if cap is not None:
|
| 26 |
+
effective_max_len = min(max_len, cap)
|
| 27 |
+
# Ensure valid bounds
|
| 28 |
+
if min_len > effective_max_len:
|
| 29 |
+
return effective_max_len
|
| 30 |
+
return random.randint(min_len, effective_max_len)
|
| 31 |
+
return random.randint(min_len, max_len)
|
| 32 |
+
elif range == "gift_eval":
|
| 33 |
+
# Gift eval forecast lengths with their frequencies
|
| 34 |
+
GIFT_EVAL_FORECAST_LENGTHS = {
|
| 35 |
+
48: 5,
|
| 36 |
+
720: 38,
|
| 37 |
+
480: 38,
|
| 38 |
+
30: 3,
|
| 39 |
+
300: 16,
|
| 40 |
+
8: 2,
|
| 41 |
+
120: 3,
|
| 42 |
+
450: 8,
|
| 43 |
+
80: 8,
|
| 44 |
+
12: 2,
|
| 45 |
+
900: 10,
|
| 46 |
+
180: 3,
|
| 47 |
+
600: 10,
|
| 48 |
+
60: 3,
|
| 49 |
+
210: 3,
|
| 50 |
+
195: 3,
|
| 51 |
+
140: 3,
|
| 52 |
+
130: 3,
|
| 53 |
+
14: 1,
|
| 54 |
+
18: 1,
|
| 55 |
+
13: 1,
|
| 56 |
+
6: 1,
|
| 57 |
+
}
|
| 58 |
+
|
| 59 |
+
lengths = list(GIFT_EVAL_FORECAST_LENGTHS.keys())
|
| 60 |
+
weights = list(GIFT_EVAL_FORECAST_LENGTHS.values())
|
| 61 |
+
|
| 62 |
+
if cap is not None:
|
| 63 |
+
filtered = [
|
| 64 |
+
(length_candidate, weight)
|
| 65 |
+
for length_candidate, weight in zip(lengths, weights)
|
| 66 |
+
if length_candidate <= cap
|
| 67 |
+
]
|
| 68 |
+
if filtered:
|
| 69 |
+
lengths, weights = zip(*filtered)
|
| 70 |
+
lengths = list(lengths)
|
| 71 |
+
weights = list(weights)
|
| 72 |
+
|
| 73 |
+
return random.choices(lengths, weights=weights)[0]
|
| 74 |
+
else:
|
| 75 |
+
raise ValueError(f"Invalid range: {range}")
|
src/gift_eval/__init__.py
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Public API for the GIFT-Eval utilities."""
|
| 2 |
+
|
| 3 |
+
from .core import DatasetMetadata, EvaluationItem, expand_datasets_arg
|
| 4 |
+
from .predictor import TimeSeriesPredictor
|
| 5 |
+
from .results import aggregate_results, get_all_datasets_full_name, write_results_to_disk
|
| 6 |
+
|
| 7 |
+
__all__ = [
|
| 8 |
+
"DatasetMetadata",
|
| 9 |
+
"EvaluationItem",
|
| 10 |
+
"TimeSeriesPredictor",
|
| 11 |
+
"aggregate_results",
|
| 12 |
+
"expand_datasets_arg",
|
| 13 |
+
"get_all_datasets_full_name",
|
| 14 |
+
"write_results_to_disk",
|
| 15 |
+
]
|
src/gift_eval/constants.py
ADDED
|
@@ -0,0 +1,186 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import logging
|
| 3 |
+
import os
|
| 4 |
+
from pathlib import Path
|
| 5 |
+
|
| 6 |
+
from gluonts.ev.metrics import (
|
| 7 |
+
MAE,
|
| 8 |
+
MAPE,
|
| 9 |
+
MASE,
|
| 10 |
+
MSE,
|
| 11 |
+
MSIS,
|
| 12 |
+
ND,
|
| 13 |
+
NRMSE,
|
| 14 |
+
RMSE,
|
| 15 |
+
SMAPE,
|
| 16 |
+
MeanWeightedSumQuantileLoss,
|
| 17 |
+
)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
logger = logging.getLogger(__name__)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
# Environment setup
|
| 24 |
+
os.environ["CUBLAS_WORKSPACE_CONFIG"] = ":4096:8"
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
# Use absolute path relative to the project root
|
| 28 |
+
_MODULE_DIR = Path(__file__).parent.parent.parent # Goes to project root
|
| 29 |
+
DATASET_PROPERTIES_PATH = _MODULE_DIR / "data" / "dataset_properties.json"
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
try:
|
| 33 |
+
with open(DATASET_PROPERTIES_PATH, "r") as f:
|
| 34 |
+
DATASET_PROPERTIES = json.load(f)
|
| 35 |
+
except Exception as exc: # pragma: no cover - logging path
|
| 36 |
+
DATASET_PROPERTIES = {}
|
| 37 |
+
logger.warning(
|
| 38 |
+
"Could not load dataset properties from %s: %s. Domain and num_variates will fall back to defaults.",
|
| 39 |
+
DATASET_PROPERTIES_PATH,
|
| 40 |
+
exc,
|
| 41 |
+
)
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
# Datasets
|
| 45 |
+
SHORT_DATASETS = (
|
| 46 |
+
"m4_yearly",
|
| 47 |
+
"m4_quarterly",
|
| 48 |
+
"m4_monthly",
|
| 49 |
+
"m4_weekly",
|
| 50 |
+
"m4_daily",
|
| 51 |
+
"m4_hourly",
|
| 52 |
+
"electricity/15T",
|
| 53 |
+
"electricity/H",
|
| 54 |
+
"electricity/D",
|
| 55 |
+
"electricity/W",
|
| 56 |
+
"solar/10T",
|
| 57 |
+
"solar/H",
|
| 58 |
+
"solar/D",
|
| 59 |
+
"solar/W",
|
| 60 |
+
"hospital",
|
| 61 |
+
"covid_deaths",
|
| 62 |
+
"us_births/D",
|
| 63 |
+
"us_births/M",
|
| 64 |
+
"us_births/W",
|
| 65 |
+
"saugeenday/D",
|
| 66 |
+
"saugeenday/M",
|
| 67 |
+
"saugeenday/W",
|
| 68 |
+
"temperature_rain_with_missing",
|
| 69 |
+
"kdd_cup_2018_with_missing/H",
|
| 70 |
+
"kdd_cup_2018_with_missing/D",
|
| 71 |
+
"car_parts_with_missing",
|
| 72 |
+
"restaurant",
|
| 73 |
+
"hierarchical_sales/D",
|
| 74 |
+
"hierarchical_sales/W",
|
| 75 |
+
"LOOP_SEATTLE/5T",
|
| 76 |
+
"LOOP_SEATTLE/H",
|
| 77 |
+
"LOOP_SEATTLE/D",
|
| 78 |
+
"SZ_TAXI/15T",
|
| 79 |
+
"SZ_TAXI/H",
|
| 80 |
+
"M_DENSE/H",
|
| 81 |
+
"M_DENSE/D",
|
| 82 |
+
"ett1/15T",
|
| 83 |
+
"ett1/H",
|
| 84 |
+
"ett1/D",
|
| 85 |
+
"ett1/W",
|
| 86 |
+
"ett2/15T",
|
| 87 |
+
"ett2/H",
|
| 88 |
+
"ett2/D",
|
| 89 |
+
"ett2/W",
|
| 90 |
+
"jena_weather/10T",
|
| 91 |
+
"jena_weather/H",
|
| 92 |
+
"jena_weather/D",
|
| 93 |
+
"bitbrains_fast_storage/5T",
|
| 94 |
+
"bitbrains_fast_storage/H",
|
| 95 |
+
"bitbrains_rnd/5T",
|
| 96 |
+
"bitbrains_rnd/H",
|
| 97 |
+
"bizitobs_application",
|
| 98 |
+
"bizitobs_service",
|
| 99 |
+
"bizitobs_l2c/5T",
|
| 100 |
+
"bizitobs_l2c/H",
|
| 101 |
+
)
|
| 102 |
+
|
| 103 |
+
MED_LONG_DATASETS = (
|
| 104 |
+
"electricity/15T",
|
| 105 |
+
"electricity/H",
|
| 106 |
+
"solar/10T",
|
| 107 |
+
"solar/H",
|
| 108 |
+
"kdd_cup_2018_with_missing/H",
|
| 109 |
+
"LOOP_SEATTLE/5T",
|
| 110 |
+
"LOOP_SEATTLE/H",
|
| 111 |
+
"SZ_TAXI/15T",
|
| 112 |
+
"M_DENSE/H",
|
| 113 |
+
"ett1/15T",
|
| 114 |
+
"ett1/H",
|
| 115 |
+
"ett2/15T",
|
| 116 |
+
"ett2/H",
|
| 117 |
+
"jena_weather/10T",
|
| 118 |
+
"jena_weather/H",
|
| 119 |
+
"bitbrains_fast_storage/5T",
|
| 120 |
+
"bitbrains_rnd/5T",
|
| 121 |
+
"bizitobs_application",
|
| 122 |
+
"bizitobs_service",
|
| 123 |
+
"bizitobs_l2c/5T",
|
| 124 |
+
"bizitobs_l2c/H",
|
| 125 |
+
)
|
| 126 |
+
|
| 127 |
+
# Preserve insertion order from SHORT_DATASETS followed by MED_LONG_DATASETS
|
| 128 |
+
ALL_DATASETS = list(dict.fromkeys(SHORT_DATASETS + MED_LONG_DATASETS))
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
# Evaluation terms
|
| 132 |
+
TERMS = ("short", "medium", "long")
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
# Pretty names mapping (following GIFT eval standard)
|
| 136 |
+
PRETTY_NAMES = {
|
| 137 |
+
"saugeenday": "saugeen",
|
| 138 |
+
"temperature_rain_with_missing": "temperature_rain",
|
| 139 |
+
"kdd_cup_2018_with_missing": "kdd_cup_2018",
|
| 140 |
+
"car_parts_with_missing": "car_parts",
|
| 141 |
+
}
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
METRICS = (
|
| 145 |
+
MSE(forecast_type="mean"),
|
| 146 |
+
MSE(forecast_type=0.5),
|
| 147 |
+
MAE(),
|
| 148 |
+
MASE(),
|
| 149 |
+
MAPE(),
|
| 150 |
+
SMAPE(),
|
| 151 |
+
MSIS(),
|
| 152 |
+
RMSE(),
|
| 153 |
+
NRMSE(),
|
| 154 |
+
ND(),
|
| 155 |
+
MeanWeightedSumQuantileLoss(
|
| 156 |
+
quantile_levels=[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]
|
| 157 |
+
),
|
| 158 |
+
)
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
STANDARD_METRIC_NAMES = (
|
| 162 |
+
"MSE[mean]",
|
| 163 |
+
"MSE[0.5]",
|
| 164 |
+
"MAE[0.5]",
|
| 165 |
+
"MASE[0.5]",
|
| 166 |
+
"MAPE[0.5]",
|
| 167 |
+
"sMAPE[0.5]",
|
| 168 |
+
"MSIS",
|
| 169 |
+
"RMSE[mean]",
|
| 170 |
+
"NRMSE[mean]",
|
| 171 |
+
"ND[0.5]",
|
| 172 |
+
"mean_weighted_sum_quantile_loss",
|
| 173 |
+
)
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
__all__ = [
|
| 177 |
+
"ALL_DATASETS",
|
| 178 |
+
"DATASET_PROPERTIES",
|
| 179 |
+
"DATASET_PROPERTIES_PATH",
|
| 180 |
+
"MED_LONG_DATASETS",
|
| 181 |
+
"METRICS",
|
| 182 |
+
"PRETTY_NAMES",
|
| 183 |
+
"SHORT_DATASETS",
|
| 184 |
+
"STANDARD_METRIC_NAMES",
|
| 185 |
+
"TERMS",
|
| 186 |
+
]
|
src/gift_eval/core.py
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Core data structures and helpers shared across GIFT-Eval modules."""
|
| 2 |
+
|
| 3 |
+
from dataclasses import dataclass
|
| 4 |
+
from typing import Dict, List, Optional, Tuple, Union
|
| 5 |
+
|
| 6 |
+
from src.gift_eval.constants import ALL_DATASETS
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
@dataclass
|
| 10 |
+
class DatasetMetadata:
|
| 11 |
+
"""Structured description of a dataset/term combination."""
|
| 12 |
+
|
| 13 |
+
full_name: str
|
| 14 |
+
key: str
|
| 15 |
+
freq: str
|
| 16 |
+
term: str
|
| 17 |
+
season_length: int
|
| 18 |
+
target_dim: int
|
| 19 |
+
to_univariate: bool
|
| 20 |
+
prediction_length: int
|
| 21 |
+
windows: int
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
@dataclass
|
| 25 |
+
class EvaluationItem:
|
| 26 |
+
"""Container for evaluation results and optional figures."""
|
| 27 |
+
|
| 28 |
+
dataset_metadata: DatasetMetadata
|
| 29 |
+
metrics: Dict
|
| 30 |
+
figures: List[Tuple[object, str]]
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
DatasetSelection = Union[List[str], Tuple[str, ...], str]
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def expand_datasets_arg(datasets: DatasetSelection) -> List[str]:
|
| 37 |
+
"""Normalize dataset selection strings to explicit lists."""
|
| 38 |
+
|
| 39 |
+
if isinstance(datasets, str):
|
| 40 |
+
dataset_list = [datasets]
|
| 41 |
+
else:
|
| 42 |
+
dataset_list = list(datasets)
|
| 43 |
+
|
| 44 |
+
if not dataset_list:
|
| 45 |
+
return []
|
| 46 |
+
|
| 47 |
+
if dataset_list[0] == "all":
|
| 48 |
+
return list(ALL_DATASETS)
|
| 49 |
+
|
| 50 |
+
for dataset in dataset_list:
|
| 51 |
+
if dataset not in ALL_DATASETS:
|
| 52 |
+
raise ValueError(f"Invalid dataset: {dataset}. Use one of {ALL_DATASETS}")
|
| 53 |
+
|
| 54 |
+
return dataset_list
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
__all__ = [
|
| 58 |
+
"DatasetMetadata",
|
| 59 |
+
"EvaluationItem",
|
| 60 |
+
"DatasetSelection",
|
| 61 |
+
"expand_datasets_arg",
|
| 62 |
+
]
|
| 63 |
+
|
| 64 |
+
|
src/gift_eval/data.py
ADDED
|
@@ -0,0 +1,234 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023, Salesforce, Inc.
|
| 2 |
+
# SPDX-License-Identifier: Apache-2
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
|
| 16 |
+
import math
|
| 17 |
+
from collections.abc import Iterable, Iterator
|
| 18 |
+
from enum import Enum
|
| 19 |
+
from functools import cached_property
|
| 20 |
+
from pathlib import Path
|
| 21 |
+
from typing import Optional
|
| 22 |
+
|
| 23 |
+
import datasets
|
| 24 |
+
import pyarrow.compute as pc
|
| 25 |
+
from gluonts.dataset import DataEntry
|
| 26 |
+
from gluonts.dataset.common import ProcessDataEntry
|
| 27 |
+
from gluonts.dataset.split import TestData, TrainingDataset, split
|
| 28 |
+
from gluonts.itertools import Map
|
| 29 |
+
from gluonts.time_feature import norm_freq_str
|
| 30 |
+
from gluonts.transform import Transformation
|
| 31 |
+
from pandas.tseries.frequencies import to_offset
|
| 32 |
+
from toolz import compose
|
| 33 |
+
|
| 34 |
+
TEST_SPLIT = 0.1
|
| 35 |
+
MAX_WINDOW = 20
|
| 36 |
+
|
| 37 |
+
M4_PRED_LENGTH_MAP = {
|
| 38 |
+
"A": 6,
|
| 39 |
+
"Q": 8,
|
| 40 |
+
"M": 18,
|
| 41 |
+
"W": 13,
|
| 42 |
+
"D": 14,
|
| 43 |
+
"H": 48,
|
| 44 |
+
"h": 48,
|
| 45 |
+
"Y": 6,
|
| 46 |
+
}
|
| 47 |
+
|
| 48 |
+
PRED_LENGTH_MAP = {
|
| 49 |
+
"M": 12,
|
| 50 |
+
"W": 8,
|
| 51 |
+
"D": 30,
|
| 52 |
+
"H": 48,
|
| 53 |
+
"h": 48,
|
| 54 |
+
"T": 48,
|
| 55 |
+
"S": 60,
|
| 56 |
+
"s": 60,
|
| 57 |
+
"min": 48,
|
| 58 |
+
}
|
| 59 |
+
|
| 60 |
+
TFB_PRED_LENGTH_MAP = {
|
| 61 |
+
"A": 6,
|
| 62 |
+
"Y": 6,
|
| 63 |
+
"H": 48,
|
| 64 |
+
"h": 48,
|
| 65 |
+
"Q": 8,
|
| 66 |
+
"D": 14,
|
| 67 |
+
"M": 18,
|
| 68 |
+
"W": 13,
|
| 69 |
+
"U": 8,
|
| 70 |
+
"T": 8,
|
| 71 |
+
"min": 8,
|
| 72 |
+
"us": 8,
|
| 73 |
+
}
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
class Term(Enum):
|
| 77 |
+
SHORT = "short"
|
| 78 |
+
MEDIUM = "medium"
|
| 79 |
+
LONG = "long"
|
| 80 |
+
|
| 81 |
+
@property
|
| 82 |
+
def multiplier(self) -> int:
|
| 83 |
+
if self == Term.SHORT:
|
| 84 |
+
return 1
|
| 85 |
+
elif self == Term.MEDIUM:
|
| 86 |
+
return 10
|
| 87 |
+
elif self == Term.LONG:
|
| 88 |
+
return 15
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def itemize_start(data_entry: DataEntry) -> DataEntry:
|
| 92 |
+
data_entry["start"] = data_entry["start"].item()
|
| 93 |
+
return data_entry
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
class MultivariateToUnivariate(Transformation):
|
| 97 |
+
def __init__(self, field):
|
| 98 |
+
self.field = field
|
| 99 |
+
|
| 100 |
+
def __call__(
|
| 101 |
+
self, data_it: Iterable[DataEntry], is_train: bool = False
|
| 102 |
+
) -> Iterator:
|
| 103 |
+
for data_entry in data_it:
|
| 104 |
+
item_id = data_entry["item_id"]
|
| 105 |
+
val_ls = list(data_entry[self.field])
|
| 106 |
+
for id, val in enumerate(val_ls):
|
| 107 |
+
univariate_entry = data_entry.copy()
|
| 108 |
+
univariate_entry[self.field] = val
|
| 109 |
+
univariate_entry["item_id"] = item_id + "_dim" + str(id)
|
| 110 |
+
yield univariate_entry
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
class Dataset:
|
| 114 |
+
def __init__(
|
| 115 |
+
self,
|
| 116 |
+
name: str,
|
| 117 |
+
term: Term | str = Term.SHORT,
|
| 118 |
+
to_univariate: bool = False,
|
| 119 |
+
storage_path: str = None,
|
| 120 |
+
max_windows: Optional[int] = None,
|
| 121 |
+
):
|
| 122 |
+
storage_path = Path(storage_path)
|
| 123 |
+
self.hf_dataset = datasets.load_from_disk(str(storage_path / name)).with_format(
|
| 124 |
+
"numpy"
|
| 125 |
+
)
|
| 126 |
+
process = ProcessDataEntry(
|
| 127 |
+
self.freq,
|
| 128 |
+
one_dim_target=self.target_dim == 1,
|
| 129 |
+
)
|
| 130 |
+
|
| 131 |
+
self.gluonts_dataset = Map(compose(process, itemize_start), self.hf_dataset)
|
| 132 |
+
if to_univariate:
|
| 133 |
+
self.gluonts_dataset = MultivariateToUnivariate("target").apply(
|
| 134 |
+
self.gluonts_dataset
|
| 135 |
+
)
|
| 136 |
+
|
| 137 |
+
self.term = Term(term)
|
| 138 |
+
self.name = name
|
| 139 |
+
self.max_windows = max_windows if max_windows is not None else MAX_WINDOW
|
| 140 |
+
|
| 141 |
+
@cached_property
|
| 142 |
+
def prediction_length(self) -> int:
|
| 143 |
+
freq = norm_freq_str(to_offset(self.freq).name)
|
| 144 |
+
if freq.endswith("E"):
|
| 145 |
+
freq = freq[:-1]
|
| 146 |
+
pred_len = (
|
| 147 |
+
M4_PRED_LENGTH_MAP[freq] if "m4" in self.name else PRED_LENGTH_MAP[freq]
|
| 148 |
+
)
|
| 149 |
+
return self.term.multiplier * pred_len
|
| 150 |
+
|
| 151 |
+
@cached_property
|
| 152 |
+
def freq(self) -> str:
|
| 153 |
+
return self.hf_dataset[0]["freq"]
|
| 154 |
+
|
| 155 |
+
@cached_property
|
| 156 |
+
def target_dim(self) -> int:
|
| 157 |
+
return (
|
| 158 |
+
target.shape[0]
|
| 159 |
+
if len((target := self.hf_dataset[0]["target"]).shape) > 1
|
| 160 |
+
else 1
|
| 161 |
+
)
|
| 162 |
+
|
| 163 |
+
@cached_property
|
| 164 |
+
def past_feat_dynamic_real_dim(self) -> int:
|
| 165 |
+
if "past_feat_dynamic_real" not in self.hf_dataset[0]:
|
| 166 |
+
return 0
|
| 167 |
+
elif (
|
| 168 |
+
len(
|
| 169 |
+
(
|
| 170 |
+
past_feat_dynamic_real := self.hf_dataset[0][
|
| 171 |
+
"past_feat_dynamic_real"
|
| 172 |
+
]
|
| 173 |
+
).shape
|
| 174 |
+
)
|
| 175 |
+
> 1
|
| 176 |
+
):
|
| 177 |
+
return past_feat_dynamic_real.shape[0]
|
| 178 |
+
else:
|
| 179 |
+
return 1
|
| 180 |
+
|
| 181 |
+
@cached_property
|
| 182 |
+
def windows(self) -> int:
|
| 183 |
+
if "m4" in self.name:
|
| 184 |
+
return 1
|
| 185 |
+
w = math.ceil(TEST_SPLIT * self._min_series_length / self.prediction_length)
|
| 186 |
+
return min(max(1, w), self.max_windows)
|
| 187 |
+
|
| 188 |
+
@cached_property
|
| 189 |
+
def _min_series_length(self) -> int:
|
| 190 |
+
if self.hf_dataset[0]["target"].ndim > 1:
|
| 191 |
+
lengths = pc.list_value_length(
|
| 192 |
+
pc.list_flatten(
|
| 193 |
+
pc.list_slice(self.hf_dataset.data.column("target"), 0, 1)
|
| 194 |
+
)
|
| 195 |
+
)
|
| 196 |
+
else:
|
| 197 |
+
lengths = pc.list_value_length(self.hf_dataset.data.column("target"))
|
| 198 |
+
return min(lengths.to_numpy())
|
| 199 |
+
|
| 200 |
+
@cached_property
|
| 201 |
+
def sum_series_length(self) -> int:
|
| 202 |
+
if self.hf_dataset[0]["target"].ndim > 1:
|
| 203 |
+
lengths = pc.list_value_length(
|
| 204 |
+
pc.list_flatten(self.hf_dataset.data.column("target"))
|
| 205 |
+
)
|
| 206 |
+
else:
|
| 207 |
+
lengths = pc.list_value_length(self.hf_dataset.data.column("target"))
|
| 208 |
+
return sum(lengths.to_numpy())
|
| 209 |
+
|
| 210 |
+
@property
|
| 211 |
+
def training_dataset(self) -> TrainingDataset:
|
| 212 |
+
training_dataset, _ = split(
|
| 213 |
+
self.gluonts_dataset, offset=-self.prediction_length * (self.windows + 1)
|
| 214 |
+
)
|
| 215 |
+
return training_dataset
|
| 216 |
+
|
| 217 |
+
@property
|
| 218 |
+
def validation_dataset(self) -> TrainingDataset:
|
| 219 |
+
validation_dataset, _ = split(
|
| 220 |
+
self.gluonts_dataset, offset=-self.prediction_length * self.windows
|
| 221 |
+
)
|
| 222 |
+
return validation_dataset
|
| 223 |
+
|
| 224 |
+
@property
|
| 225 |
+
def test_data(self) -> TestData:
|
| 226 |
+
_, test_template = split(
|
| 227 |
+
self.gluonts_dataset, offset=-self.prediction_length * self.windows
|
| 228 |
+
)
|
| 229 |
+
test_data = test_template.generate_instances(
|
| 230 |
+
prediction_length=self.prediction_length,
|
| 231 |
+
windows=self.windows,
|
| 232 |
+
distance=self.prediction_length,
|
| 233 |
+
)
|
| 234 |
+
return test_data
|
src/gift_eval/evaluate.py
ADDED
|
@@ -0,0 +1,421 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import logging
|
| 3 |
+
import warnings
|
| 4 |
+
from pathlib import Path
|
| 5 |
+
from typing import List, Optional, Tuple
|
| 6 |
+
|
| 7 |
+
import matplotlib
|
| 8 |
+
from gluonts.model.evaluation import evaluate_model
|
| 9 |
+
from gluonts.time_feature import get_seasonality
|
| 10 |
+
from linear_operator.utils.cholesky import NumericalWarning
|
| 11 |
+
|
| 12 |
+
from src.gift_eval.constants import (
|
| 13 |
+
DATASET_PROPERTIES,
|
| 14 |
+
MED_LONG_DATASETS,
|
| 15 |
+
METRICS,
|
| 16 |
+
PRETTY_NAMES,
|
| 17 |
+
)
|
| 18 |
+
from src.gift_eval.core import DatasetMetadata, EvaluationItem, expand_datasets_arg
|
| 19 |
+
from src.gift_eval.data import Dataset
|
| 20 |
+
from src.gift_eval.predictor import TimeSeriesPredictor
|
| 21 |
+
from src.gift_eval.results import write_results_to_disk
|
| 22 |
+
from src.plotting.gift_eval_utils import create_plots_for_dataset
|
| 23 |
+
|
| 24 |
+
logger = logging.getLogger(__name__)
|
| 25 |
+
|
| 26 |
+
# Warnings configuration
|
| 27 |
+
warnings.filterwarnings("ignore", category=NumericalWarning)
|
| 28 |
+
warnings.filterwarnings("ignore", category=FutureWarning)
|
| 29 |
+
warnings.filterwarnings("ignore", category=DeprecationWarning)
|
| 30 |
+
matplotlib.set_loglevel("WARNING")
|
| 31 |
+
logging.getLogger("matplotlib").setLevel(logging.WARNING)
|
| 32 |
+
logging.getLogger("matplotlib.font_manager").setLevel(logging.WARNING)
|
| 33 |
+
logging.getLogger("PIL").setLevel(logging.WARNING)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
class WarningFilter(logging.Filter):
|
| 37 |
+
def __init__(self, text_to_filter: str) -> None:
|
| 38 |
+
super().__init__()
|
| 39 |
+
self.text_to_filter = text_to_filter
|
| 40 |
+
|
| 41 |
+
def filter(self, record: logging.LogRecord) -> bool:
|
| 42 |
+
return self.text_to_filter not in record.getMessage()
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
# Filter out gluonts warnings about mean predictions
|
| 46 |
+
gts_logger = logging.getLogger("gluonts.model.forecast")
|
| 47 |
+
gts_logger.addFilter(
|
| 48 |
+
WarningFilter("The mean prediction is not stored in the forecast data")
|
| 49 |
+
)
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def construct_evaluation_data(
|
| 53 |
+
dataset_name: str,
|
| 54 |
+
dataset_storage_path: str,
|
| 55 |
+
terms: List[str] = ["short", "medium", "long"],
|
| 56 |
+
max_windows: Optional[int] = None,
|
| 57 |
+
) -> List[Tuple[Dataset, DatasetMetadata]]:
|
| 58 |
+
"""Build datasets and rich metadata per term for a dataset name."""
|
| 59 |
+
sub_datasets: List[Tuple[Dataset, DatasetMetadata]] = []
|
| 60 |
+
|
| 61 |
+
if "/" in dataset_name:
|
| 62 |
+
ds_key, ds_freq = dataset_name.split("/")
|
| 63 |
+
ds_key = ds_key.lower()
|
| 64 |
+
ds_key = PRETTY_NAMES.get(ds_key, ds_key)
|
| 65 |
+
else:
|
| 66 |
+
ds_key = dataset_name.lower()
|
| 67 |
+
ds_key = PRETTY_NAMES.get(ds_key, ds_key)
|
| 68 |
+
ds_freq = DATASET_PROPERTIES.get(ds_key, {}).get("frequency")
|
| 69 |
+
|
| 70 |
+
for term in terms:
|
| 71 |
+
# Skip medium/long terms for datasets that don't support them
|
| 72 |
+
if (
|
| 73 |
+
term == "medium" or term == "long"
|
| 74 |
+
) and dataset_name not in MED_LONG_DATASETS:
|
| 75 |
+
continue
|
| 76 |
+
|
| 77 |
+
# Probe once to determine dimensionality
|
| 78 |
+
probe_dataset = Dataset(
|
| 79 |
+
name=dataset_name,
|
| 80 |
+
term=term,
|
| 81 |
+
to_univariate=False,
|
| 82 |
+
storage_path=dataset_storage_path,
|
| 83 |
+
max_windows=max_windows,
|
| 84 |
+
)
|
| 85 |
+
|
| 86 |
+
to_univariate = probe_dataset.target_dim > 1
|
| 87 |
+
|
| 88 |
+
dataset = Dataset(
|
| 89 |
+
name=dataset_name,
|
| 90 |
+
term=term,
|
| 91 |
+
to_univariate=to_univariate,
|
| 92 |
+
storage_path=dataset_storage_path,
|
| 93 |
+
max_windows=max_windows,
|
| 94 |
+
)
|
| 95 |
+
|
| 96 |
+
# Compute metadata
|
| 97 |
+
season_length = get_seasonality(dataset.freq)
|
| 98 |
+
actual_freq = ds_freq if ds_freq else dataset.freq
|
| 99 |
+
|
| 100 |
+
metadata = DatasetMetadata(
|
| 101 |
+
full_name=f"{ds_key}/{actual_freq}/{term}",
|
| 102 |
+
key=ds_key,
|
| 103 |
+
freq=actual_freq,
|
| 104 |
+
term=term,
|
| 105 |
+
season_length=season_length,
|
| 106 |
+
target_dim=probe_dataset.target_dim,
|
| 107 |
+
to_univariate=to_univariate,
|
| 108 |
+
prediction_length=dataset.prediction_length,
|
| 109 |
+
windows=dataset.windows,
|
| 110 |
+
)
|
| 111 |
+
|
| 112 |
+
sub_datasets.append((dataset, metadata))
|
| 113 |
+
|
| 114 |
+
return sub_datasets
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
def evaluate_datasets(
|
| 118 |
+
predictor: TimeSeriesPredictor,
|
| 119 |
+
dataset: str,
|
| 120 |
+
dataset_storage_path: str,
|
| 121 |
+
terms: List[str] = ["short", "medium", "long"],
|
| 122 |
+
max_windows: Optional[int] = None,
|
| 123 |
+
batch_size: int = 48,
|
| 124 |
+
max_context_length: Optional[int] = 1024,
|
| 125 |
+
create_plots: bool = False,
|
| 126 |
+
max_plots_per_dataset: int = 10,
|
| 127 |
+
) -> List[EvaluationItem]:
|
| 128 |
+
"""Evaluate predictor on one dataset across the requested terms."""
|
| 129 |
+
sub_datasets = construct_evaluation_data(
|
| 130 |
+
dataset_name=dataset,
|
| 131 |
+
dataset_storage_path=dataset_storage_path,
|
| 132 |
+
terms=terms,
|
| 133 |
+
max_windows=max_windows,
|
| 134 |
+
)
|
| 135 |
+
|
| 136 |
+
results: List[EvaluationItem] = []
|
| 137 |
+
for i, (sub_dataset, metadata) in enumerate(sub_datasets):
|
| 138 |
+
logger.info(f"Evaluating {i + 1}/{len(sub_datasets)}: {metadata.full_name}")
|
| 139 |
+
logger.info(f" Dataset size: {len(sub_dataset.test_data)}")
|
| 140 |
+
logger.info(f" Frequency: {sub_dataset.freq}")
|
| 141 |
+
logger.info(f" Term: {metadata.term}")
|
| 142 |
+
logger.info(f" Prediction length: {sub_dataset.prediction_length}")
|
| 143 |
+
logger.info(f" Target dimensions: {sub_dataset.target_dim}")
|
| 144 |
+
logger.info(f" Windows: {sub_dataset.windows}")
|
| 145 |
+
|
| 146 |
+
# Update context on the reusable predictor
|
| 147 |
+
predictor.set_dataset_context(
|
| 148 |
+
prediction_length=sub_dataset.prediction_length,
|
| 149 |
+
freq=sub_dataset.freq,
|
| 150 |
+
batch_size=batch_size,
|
| 151 |
+
max_context_length=max_context_length,
|
| 152 |
+
)
|
| 153 |
+
|
| 154 |
+
res = evaluate_model(
|
| 155 |
+
model=predictor,
|
| 156 |
+
test_data=sub_dataset.test_data,
|
| 157 |
+
metrics=METRICS,
|
| 158 |
+
axis=None,
|
| 159 |
+
mask_invalid_label=True,
|
| 160 |
+
allow_nan_forecast=False,
|
| 161 |
+
seasonality=metadata.season_length,
|
| 162 |
+
)
|
| 163 |
+
|
| 164 |
+
figs: List[Tuple[object, str]] = []
|
| 165 |
+
if create_plots:
|
| 166 |
+
forecasts = predictor.predict(sub_dataset.test_data.input)
|
| 167 |
+
figs = create_plots_for_dataset(
|
| 168 |
+
forecasts=forecasts,
|
| 169 |
+
test_data=sub_dataset.test_data,
|
| 170 |
+
dataset_metadata=metadata,
|
| 171 |
+
max_plots=max_plots_per_dataset,
|
| 172 |
+
max_context_length=max_context_length,
|
| 173 |
+
)
|
| 174 |
+
|
| 175 |
+
results.append(
|
| 176 |
+
EvaluationItem(dataset_metadata=metadata, metrics=res, figures=figs)
|
| 177 |
+
)
|
| 178 |
+
|
| 179 |
+
return results
|
| 180 |
+
|
| 181 |
+
|
| 182 |
+
def _run_evaluation(
|
| 183 |
+
predictor: TimeSeriesPredictor,
|
| 184 |
+
datasets: List[str] | str,
|
| 185 |
+
terms: List[str],
|
| 186 |
+
dataset_storage_path: str,
|
| 187 |
+
max_windows: Optional[int] = None,
|
| 188 |
+
batch_size: int = 48,
|
| 189 |
+
max_context_length: Optional[int] = 1024,
|
| 190 |
+
output_dir: str = "gift_eval_results",
|
| 191 |
+
model_name: str = "TimeSeriesModel",
|
| 192 |
+
create_plots: bool = False,
|
| 193 |
+
max_plots: int = 10,
|
| 194 |
+
) -> None:
|
| 195 |
+
"""Shared evaluation workflow used by both entry points."""
|
| 196 |
+
datasets_to_run = expand_datasets_arg(datasets)
|
| 197 |
+
results_root = Path(output_dir)
|
| 198 |
+
|
| 199 |
+
for ds_name in datasets_to_run:
|
| 200 |
+
items = evaluate_datasets(
|
| 201 |
+
predictor=predictor,
|
| 202 |
+
dataset=ds_name,
|
| 203 |
+
dataset_storage_path=dataset_storage_path,
|
| 204 |
+
terms=terms,
|
| 205 |
+
max_windows=max_windows,
|
| 206 |
+
batch_size=batch_size,
|
| 207 |
+
max_context_length=max_context_length,
|
| 208 |
+
create_plots=create_plots,
|
| 209 |
+
max_plots_per_dataset=max_plots,
|
| 210 |
+
)
|
| 211 |
+
write_results_to_disk(
|
| 212 |
+
items=items,
|
| 213 |
+
dataset_name=ds_name,
|
| 214 |
+
output_dir=results_root,
|
| 215 |
+
model_name=model_name,
|
| 216 |
+
create_plots=create_plots,
|
| 217 |
+
)
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
def evaluate_from_paths(
|
| 221 |
+
model_path: str,
|
| 222 |
+
config_path: str,
|
| 223 |
+
datasets: List[str] | str,
|
| 224 |
+
terms: List[str],
|
| 225 |
+
dataset_storage_path: str,
|
| 226 |
+
max_windows: Optional[int] = None,
|
| 227 |
+
batch_size: int = 48,
|
| 228 |
+
max_context_length: Optional[int] = 1024,
|
| 229 |
+
output_dir: str = "gift_eval_results",
|
| 230 |
+
model_name: str = "TimeSeriesModel",
|
| 231 |
+
create_plots: bool = False,
|
| 232 |
+
max_plots: int = 10,
|
| 233 |
+
) -> None:
|
| 234 |
+
"""Entry point: load model from disk and save metrics/plots to disk."""
|
| 235 |
+
# Validate inputs early
|
| 236 |
+
if not Path(model_path).exists():
|
| 237 |
+
raise FileNotFoundError(f"Model path does not exist: {model_path}")
|
| 238 |
+
if not Path(config_path).exists():
|
| 239 |
+
raise FileNotFoundError(f"Config path does not exist: {config_path}")
|
| 240 |
+
|
| 241 |
+
predictor = TimeSeriesPredictor.from_paths(
|
| 242 |
+
model_path=model_path,
|
| 243 |
+
config_path=config_path,
|
| 244 |
+
ds_prediction_length=1, # placeholder; set per dataset below
|
| 245 |
+
ds_freq="D", # placeholder; set per dataset below
|
| 246 |
+
batch_size=batch_size,
|
| 247 |
+
max_context_length=max_context_length,
|
| 248 |
+
)
|
| 249 |
+
|
| 250 |
+
_run_evaluation(
|
| 251 |
+
predictor=predictor,
|
| 252 |
+
datasets=datasets,
|
| 253 |
+
terms=terms,
|
| 254 |
+
dataset_storage_path=dataset_storage_path,
|
| 255 |
+
max_windows=max_windows,
|
| 256 |
+
batch_size=batch_size,
|
| 257 |
+
max_context_length=max_context_length,
|
| 258 |
+
output_dir=output_dir,
|
| 259 |
+
model_name=model_name,
|
| 260 |
+
create_plots=create_plots,
|
| 261 |
+
max_plots=max_plots,
|
| 262 |
+
)
|
| 263 |
+
|
| 264 |
+
|
| 265 |
+
def evaluate_in_memory(
|
| 266 |
+
model,
|
| 267 |
+
config: dict,
|
| 268 |
+
datasets: List[str] | str,
|
| 269 |
+
terms: List[str],
|
| 270 |
+
dataset_storage_path: str,
|
| 271 |
+
max_windows: Optional[int] = None,
|
| 272 |
+
batch_size: int = 48,
|
| 273 |
+
max_context_length: Optional[int] = 1024,
|
| 274 |
+
output_dir: str = "gift_eval_results",
|
| 275 |
+
model_name: str = "TimeSeriesModel",
|
| 276 |
+
create_plots: bool = False,
|
| 277 |
+
max_plots: int = 10,
|
| 278 |
+
) -> None:
|
| 279 |
+
"""Entry point: evaluate in-memory model and return results per dataset."""
|
| 280 |
+
predictor = TimeSeriesPredictor.from_model(
|
| 281 |
+
model=model,
|
| 282 |
+
config=config,
|
| 283 |
+
ds_prediction_length=1, # placeholder; set per dataset below
|
| 284 |
+
ds_freq="D", # placeholder; set per dataset below
|
| 285 |
+
batch_size=batch_size,
|
| 286 |
+
max_context_length=max_context_length,
|
| 287 |
+
)
|
| 288 |
+
|
| 289 |
+
_run_evaluation(
|
| 290 |
+
predictor=predictor,
|
| 291 |
+
datasets=datasets,
|
| 292 |
+
terms=terms,
|
| 293 |
+
dataset_storage_path=dataset_storage_path,
|
| 294 |
+
max_windows=max_windows,
|
| 295 |
+
batch_size=batch_size,
|
| 296 |
+
max_context_length=max_context_length,
|
| 297 |
+
output_dir=output_dir,
|
| 298 |
+
model_name=model_name,
|
| 299 |
+
create_plots=create_plots,
|
| 300 |
+
max_plots=max_plots,
|
| 301 |
+
)
|
| 302 |
+
|
| 303 |
+
|
| 304 |
+
def _parse_args() -> argparse.Namespace:
|
| 305 |
+
parser = argparse.ArgumentParser(
|
| 306 |
+
description="Evaluate TimeSeriesModel on GIFT-Eval datasets"
|
| 307 |
+
)
|
| 308 |
+
|
| 309 |
+
# Model configuration
|
| 310 |
+
parser.add_argument(
|
| 311 |
+
"--model_path",
|
| 312 |
+
type=str,
|
| 313 |
+
required=True,
|
| 314 |
+
help="Path to the trained model checkpoint",
|
| 315 |
+
)
|
| 316 |
+
parser.add_argument(
|
| 317 |
+
"--config_path",
|
| 318 |
+
type=str,
|
| 319 |
+
required=True,
|
| 320 |
+
help="Path to the model configuration YAML file",
|
| 321 |
+
)
|
| 322 |
+
parser.add_argument(
|
| 323 |
+
"--model_name",
|
| 324 |
+
type=str,
|
| 325 |
+
default="TimeSeriesModel",
|
| 326 |
+
help="Name identifier for the model",
|
| 327 |
+
)
|
| 328 |
+
|
| 329 |
+
# Dataset configuration
|
| 330 |
+
parser.add_argument(
|
| 331 |
+
"--datasets",
|
| 332 |
+
type=str,
|
| 333 |
+
default="all",
|
| 334 |
+
help="Comma-separated list of dataset names to evaluate (or 'all')",
|
| 335 |
+
)
|
| 336 |
+
parser.add_argument(
|
| 337 |
+
"--dataset_storage_path",
|
| 338 |
+
type=str,
|
| 339 |
+
default="/work/dlclarge2/moroshav-GiftEvalPretrain/gift_eval",
|
| 340 |
+
help="Path to the dataset storage directory (default: GIFT_EVAL)",
|
| 341 |
+
)
|
| 342 |
+
parser.add_argument(
|
| 343 |
+
"--terms",
|
| 344 |
+
type=str,
|
| 345 |
+
default="short,medium,long",
|
| 346 |
+
help="Comma-separated list of prediction terms to evaluate",
|
| 347 |
+
)
|
| 348 |
+
parser.add_argument(
|
| 349 |
+
"--max_windows",
|
| 350 |
+
type=int,
|
| 351 |
+
default=None,
|
| 352 |
+
help="Maximum number of windows to use for evaluation",
|
| 353 |
+
)
|
| 354 |
+
|
| 355 |
+
# Inference configuration
|
| 356 |
+
parser.add_argument(
|
| 357 |
+
"--batch_size", type=int, default=48, help="Batch size for model inference"
|
| 358 |
+
)
|
| 359 |
+
parser.add_argument(
|
| 360 |
+
"--max_context_length",
|
| 361 |
+
type=int,
|
| 362 |
+
default=1024,
|
| 363 |
+
help="Maximum context length to use (None for no limit)",
|
| 364 |
+
)
|
| 365 |
+
|
| 366 |
+
# Output configuration
|
| 367 |
+
parser.add_argument(
|
| 368 |
+
"--output_dir",
|
| 369 |
+
type=str,
|
| 370 |
+
default="gift_eval_results",
|
| 371 |
+
help="Directory to save evaluation results",
|
| 372 |
+
)
|
| 373 |
+
|
| 374 |
+
# Plotting configuration
|
| 375 |
+
parser.add_argument(
|
| 376 |
+
"--create_plots",
|
| 377 |
+
action="store_true",
|
| 378 |
+
help="Create and save plots for each evaluation window",
|
| 379 |
+
)
|
| 380 |
+
parser.add_argument(
|
| 381 |
+
"--max_plots_per_dataset",
|
| 382 |
+
type=int,
|
| 383 |
+
default=10,
|
| 384 |
+
help="Maximum number of plots to create per dataset term",
|
| 385 |
+
)
|
| 386 |
+
|
| 387 |
+
args = parser.parse_args()
|
| 388 |
+
args.terms = args.terms.split(",")
|
| 389 |
+
args.datasets = args.datasets.split(",")
|
| 390 |
+
return args
|
| 391 |
+
|
| 392 |
+
|
| 393 |
+
def _configure_logging() -> None:
|
| 394 |
+
logging.basicConfig(
|
| 395 |
+
level=logging.INFO,
|
| 396 |
+
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s",
|
| 397 |
+
)
|
| 398 |
+
|
| 399 |
+
|
| 400 |
+
if __name__ == "__main__":
|
| 401 |
+
_configure_logging()
|
| 402 |
+
args = _parse_args()
|
| 403 |
+
logger.info(f"Command Line Arguments: {vars(args)}")
|
| 404 |
+
try:
|
| 405 |
+
evaluate_from_paths(
|
| 406 |
+
model_path=args.model_path,
|
| 407 |
+
config_path=args.config_path,
|
| 408 |
+
datasets=args.datasets,
|
| 409 |
+
terms=args.terms,
|
| 410 |
+
dataset_storage_path=args.dataset_storage_path,
|
| 411 |
+
max_windows=args.max_windows,
|
| 412 |
+
batch_size=args.batch_size,
|
| 413 |
+
max_context_length=args.max_context_length,
|
| 414 |
+
output_dir=args.output_dir,
|
| 415 |
+
model_name=args.model_name,
|
| 416 |
+
create_plots=args.create_plots,
|
| 417 |
+
max_plots=args.max_plots_per_dataset,
|
| 418 |
+
)
|
| 419 |
+
except Exception as e:
|
| 420 |
+
logger.error(f"Evaluation failed: {str(e)}")
|
| 421 |
+
raise
|
src/gift_eval/predictor.py
ADDED
|
@@ -0,0 +1,318 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Predictor implementation wrapping the TimeSeriesModel for GIFT-Eval."""
|
| 2 |
+
|
| 3 |
+
import logging
|
| 4 |
+
from typing import Iterator, List, Optional
|
| 5 |
+
|
| 6 |
+
import numpy as np
|
| 7 |
+
import torch
|
| 8 |
+
import yaml
|
| 9 |
+
from gluonts.model.forecast import QuantileForecast
|
| 10 |
+
from gluonts.model.predictor import Predictor
|
| 11 |
+
from torch.nn.parallel import DistributedDataParallel as DDP
|
| 12 |
+
|
| 13 |
+
from src.data.containers import BatchTimeSeriesContainer
|
| 14 |
+
from src.data.frequency import parse_frequency
|
| 15 |
+
from src.data.scalers import RobustScaler
|
| 16 |
+
from src.models.model import TimeSeriesModel
|
| 17 |
+
from src.utils.utils import device
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
logger = logging.getLogger(__name__)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
class TimeSeriesPredictor(Predictor):
|
| 24 |
+
"""Unified predictor for TimeSeriesModel supporting flexible construction."""
|
| 25 |
+
|
| 26 |
+
def __init__(
|
| 27 |
+
self,
|
| 28 |
+
model: TimeSeriesModel,
|
| 29 |
+
config: dict,
|
| 30 |
+
ds_prediction_length: int,
|
| 31 |
+
ds_freq: str,
|
| 32 |
+
batch_size: int = 32,
|
| 33 |
+
max_context_length: Optional[int] = None,
|
| 34 |
+
debug: bool = False,
|
| 35 |
+
) -> None:
|
| 36 |
+
# Dataset-specific context (can be updated per dataset/term)
|
| 37 |
+
self.ds_prediction_length = ds_prediction_length
|
| 38 |
+
self.ds_freq = ds_freq
|
| 39 |
+
self.batch_size = batch_size
|
| 40 |
+
self.max_context_length = max_context_length
|
| 41 |
+
self.debug = debug
|
| 42 |
+
|
| 43 |
+
# Persistent model/config (unwrap DDP if needed)
|
| 44 |
+
self.model = model.module if isinstance(model, DDP) else model
|
| 45 |
+
self.model.eval()
|
| 46 |
+
self.config = config
|
| 47 |
+
|
| 48 |
+
# Initialize scaler (using same type as model)
|
| 49 |
+
scaler_type = self.config.get("TimeSeriesModel", {}).get(
|
| 50 |
+
"scaler", "custom_robust"
|
| 51 |
+
)
|
| 52 |
+
epsilon = self.config.get("TimeSeriesModel", {}).get("epsilon", 1e-3)
|
| 53 |
+
if scaler_type == "custom_robust":
|
| 54 |
+
self.scaler = RobustScaler(epsilon=epsilon)
|
| 55 |
+
else:
|
| 56 |
+
raise ValueError(f"Unsupported scaler type: {scaler_type}")
|
| 57 |
+
|
| 58 |
+
def set_dataset_context(
|
| 59 |
+
self,
|
| 60 |
+
prediction_length: Optional[int] = None,
|
| 61 |
+
freq: Optional[str] = None,
|
| 62 |
+
batch_size: Optional[int] = None,
|
| 63 |
+
max_context_length: Optional[int] = None,
|
| 64 |
+
) -> None:
|
| 65 |
+
"""Update lightweight dataset-specific attributes without reloading the model."""
|
| 66 |
+
|
| 67 |
+
if prediction_length is not None:
|
| 68 |
+
self.ds_prediction_length = prediction_length
|
| 69 |
+
if freq is not None:
|
| 70 |
+
self.ds_freq = freq
|
| 71 |
+
if batch_size is not None:
|
| 72 |
+
self.batch_size = batch_size
|
| 73 |
+
if max_context_length is not None:
|
| 74 |
+
self.max_context_length = max_context_length
|
| 75 |
+
|
| 76 |
+
@classmethod
|
| 77 |
+
def from_model(
|
| 78 |
+
cls,
|
| 79 |
+
model: TimeSeriesModel,
|
| 80 |
+
config: dict,
|
| 81 |
+
ds_prediction_length: int,
|
| 82 |
+
ds_freq: str,
|
| 83 |
+
batch_size: int = 32,
|
| 84 |
+
max_context_length: Optional[int] = None,
|
| 85 |
+
debug: bool = False,
|
| 86 |
+
) -> "TimeSeriesPredictor":
|
| 87 |
+
return cls(
|
| 88 |
+
model=model,
|
| 89 |
+
config=config,
|
| 90 |
+
ds_prediction_length=ds_prediction_length,
|
| 91 |
+
ds_freq=ds_freq,
|
| 92 |
+
batch_size=batch_size,
|
| 93 |
+
max_context_length=max_context_length,
|
| 94 |
+
debug=debug,
|
| 95 |
+
)
|
| 96 |
+
|
| 97 |
+
@classmethod
|
| 98 |
+
def from_paths(
|
| 99 |
+
cls,
|
| 100 |
+
model_path: str,
|
| 101 |
+
config_path: str,
|
| 102 |
+
ds_prediction_length: int,
|
| 103 |
+
ds_freq: str,
|
| 104 |
+
batch_size: int = 32,
|
| 105 |
+
max_context_length: Optional[int] = None,
|
| 106 |
+
debug: bool = False,
|
| 107 |
+
) -> "TimeSeriesPredictor":
|
| 108 |
+
with open(config_path, "r") as f:
|
| 109 |
+
config = yaml.safe_load(f)
|
| 110 |
+
model = cls._load_model_from_path(config=config, model_path=model_path)
|
| 111 |
+
return cls(
|
| 112 |
+
model=model,
|
| 113 |
+
config=config,
|
| 114 |
+
ds_prediction_length=ds_prediction_length,
|
| 115 |
+
ds_freq=ds_freq,
|
| 116 |
+
batch_size=batch_size,
|
| 117 |
+
max_context_length=max_context_length,
|
| 118 |
+
debug=debug,
|
| 119 |
+
)
|
| 120 |
+
|
| 121 |
+
@staticmethod
|
| 122 |
+
def _load_model_from_path(config: dict, model_path: str) -> TimeSeriesModel:
|
| 123 |
+
try:
|
| 124 |
+
model = TimeSeriesModel(**config["TimeSeriesModel"]).to(device)
|
| 125 |
+
checkpoint = torch.load(model_path, map_location=device)
|
| 126 |
+
model.load_state_dict(checkpoint["model_state_dict"])
|
| 127 |
+
model.eval()
|
| 128 |
+
logger.info(f"Successfully loaded model from {model_path}")
|
| 129 |
+
return model
|
| 130 |
+
except Exception as exc: # pragma: no cover - logging path
|
| 131 |
+
logger.error(f"Failed to load model from {model_path}: {exc}")
|
| 132 |
+
raise
|
| 133 |
+
|
| 134 |
+
def predict(self, test_data_input) -> Iterator[QuantileForecast]:
|
| 135 |
+
"""Generate forecasts for the test data."""
|
| 136 |
+
|
| 137 |
+
if hasattr(test_data_input, "__iter__") and not isinstance(test_data_input, list):
|
| 138 |
+
test_data_input = list(test_data_input)
|
| 139 |
+
logger.debug(f"Processing {len(test_data_input)} time series")
|
| 140 |
+
|
| 141 |
+
# Group series by their effective length (after optional truncation),
|
| 142 |
+
# then process each uniform-length group in sub-batches up to batch_size.
|
| 143 |
+
def _effective_length(entry) -> int:
|
| 144 |
+
target = entry["target"]
|
| 145 |
+
if target.ndim == 1:
|
| 146 |
+
seq_len = len(target)
|
| 147 |
+
else:
|
| 148 |
+
# target shape is [num_channels, seq_len]
|
| 149 |
+
seq_len = target.shape[1]
|
| 150 |
+
if self.max_context_length is not None:
|
| 151 |
+
seq_len = min(seq_len, self.max_context_length)
|
| 152 |
+
return seq_len
|
| 153 |
+
|
| 154 |
+
length_to_items: dict[int, List[tuple[int, object]]] = {}
|
| 155 |
+
for idx, entry in enumerate(test_data_input):
|
| 156 |
+
seq_len = _effective_length(entry)
|
| 157 |
+
length_to_items.setdefault(seq_len, []).append((idx, entry))
|
| 158 |
+
|
| 159 |
+
total = len(test_data_input)
|
| 160 |
+
ordered_results: List[Optional[QuantileForecast]] = [None] * total
|
| 161 |
+
|
| 162 |
+
for _, items in length_to_items.items():
|
| 163 |
+
for i in range(0, len(items), self.batch_size):
|
| 164 |
+
chunk = items[i : i + self.batch_size]
|
| 165 |
+
entries = [entry for (_orig_idx, entry) in chunk]
|
| 166 |
+
batch_forecasts = self._predict_batch(entries)
|
| 167 |
+
for forecast_idx, (orig_idx, _entry) in enumerate(chunk):
|
| 168 |
+
ordered_results[orig_idx] = batch_forecasts[forecast_idx]
|
| 169 |
+
|
| 170 |
+
return ordered_results # type: ignore[return-value]
|
| 171 |
+
|
| 172 |
+
def _predict_batch(self, test_data_batch: List) -> List[QuantileForecast]:
|
| 173 |
+
"""Generate predictions for a batch of time series."""
|
| 174 |
+
|
| 175 |
+
logger.debug(f"Processing batch of size: {len(test_data_batch)}")
|
| 176 |
+
|
| 177 |
+
try:
|
| 178 |
+
batch_container = self._convert_to_batch_container(test_data_batch)
|
| 179 |
+
|
| 180 |
+
if isinstance(device, torch.device):
|
| 181 |
+
device_type = device.type
|
| 182 |
+
else:
|
| 183 |
+
device_type = "cuda" if "cuda" in str(device).lower() else "cpu"
|
| 184 |
+
enable_autocast = device_type == "cuda"
|
| 185 |
+
|
| 186 |
+
with torch.autocast(
|
| 187 |
+
device_type=device_type,
|
| 188 |
+
dtype=torch.bfloat16,
|
| 189 |
+
enabled=enable_autocast,
|
| 190 |
+
):
|
| 191 |
+
with torch.no_grad():
|
| 192 |
+
model_output = self.model(batch_container, drop_enc_allow=False)
|
| 193 |
+
|
| 194 |
+
forecasts = self._convert_to_forecasts(
|
| 195 |
+
model_output, test_data_batch, batch_container
|
| 196 |
+
)
|
| 197 |
+
|
| 198 |
+
logger.debug(f"Generated {len(forecasts)} forecasts")
|
| 199 |
+
return forecasts
|
| 200 |
+
except Exception as exc: # pragma: no cover - logging path
|
| 201 |
+
logger.error(f"Error in batch prediction: {exc}")
|
| 202 |
+
raise
|
| 203 |
+
|
| 204 |
+
def _convert_to_batch_container(
|
| 205 |
+
self, test_data_batch: List
|
| 206 |
+
) -> BatchTimeSeriesContainer:
|
| 207 |
+
"""Convert gluonts test data to BatchTimeSeriesContainer."""
|
| 208 |
+
|
| 209 |
+
batch_size = len(test_data_batch)
|
| 210 |
+
history_values_list = []
|
| 211 |
+
start_dates = []
|
| 212 |
+
frequencies = []
|
| 213 |
+
|
| 214 |
+
for entry in test_data_batch:
|
| 215 |
+
target = entry["target"]
|
| 216 |
+
|
| 217 |
+
if target.ndim == 1:
|
| 218 |
+
target = target.reshape(-1, 1)
|
| 219 |
+
else:
|
| 220 |
+
target = target.T
|
| 221 |
+
|
| 222 |
+
if (
|
| 223 |
+
self.max_context_length is not None
|
| 224 |
+
and len(target) > self.max_context_length
|
| 225 |
+
):
|
| 226 |
+
target = target[-self.max_context_length :]
|
| 227 |
+
|
| 228 |
+
history_values_list.append(target)
|
| 229 |
+
start_dates.append(entry["start"].to_timestamp().to_datetime64())
|
| 230 |
+
frequencies.append(parse_frequency(entry["freq"]))
|
| 231 |
+
|
| 232 |
+
history_values_np = np.stack(history_values_list, axis=0)
|
| 233 |
+
num_channels = history_values_np.shape[2]
|
| 234 |
+
|
| 235 |
+
history_values = torch.tensor(
|
| 236 |
+
history_values_np, dtype=torch.float32, device=device
|
| 237 |
+
)
|
| 238 |
+
|
| 239 |
+
future_values = torch.zeros(
|
| 240 |
+
(batch_size, self.ds_prediction_length, num_channels),
|
| 241 |
+
dtype=torch.float32,
|
| 242 |
+
device=device,
|
| 243 |
+
)
|
| 244 |
+
|
| 245 |
+
return BatchTimeSeriesContainer(
|
| 246 |
+
history_values=history_values,
|
| 247 |
+
future_values=future_values,
|
| 248 |
+
start=start_dates,
|
| 249 |
+
frequency=frequencies,
|
| 250 |
+
)
|
| 251 |
+
|
| 252 |
+
def _convert_to_forecasts(
|
| 253 |
+
self,
|
| 254 |
+
model_output: dict,
|
| 255 |
+
test_data_batch: List,
|
| 256 |
+
batch_container: BatchTimeSeriesContainer,
|
| 257 |
+
) -> List[QuantileForecast]:
|
| 258 |
+
"""Convert model predictions to QuantileForecast objects."""
|
| 259 |
+
|
| 260 |
+
predictions = model_output["result"]
|
| 261 |
+
scale_statistics = model_output["scale_statistics"]
|
| 262 |
+
|
| 263 |
+
if predictions.ndim == 4:
|
| 264 |
+
predictions_unscaled = self.scaler.inverse_scale(
|
| 265 |
+
predictions, scale_statistics
|
| 266 |
+
)
|
| 267 |
+
is_quantile = True
|
| 268 |
+
quantile_levels = self.model.quantiles
|
| 269 |
+
else:
|
| 270 |
+
predictions_unscaled = self.scaler.inverse_scale(
|
| 271 |
+
predictions, scale_statistics
|
| 272 |
+
)
|
| 273 |
+
is_quantile = False
|
| 274 |
+
quantile_levels = [0.5]
|
| 275 |
+
|
| 276 |
+
forecasts: List[QuantileForecast] = []
|
| 277 |
+
for idx, entry in enumerate(test_data_batch):
|
| 278 |
+
history_length = int(batch_container.history_values.shape[1])
|
| 279 |
+
start_date = entry["start"]
|
| 280 |
+
forecast_start = start_date + history_length
|
| 281 |
+
|
| 282 |
+
if is_quantile:
|
| 283 |
+
pred_array = predictions_unscaled[idx].cpu().numpy()
|
| 284 |
+
|
| 285 |
+
if pred_array.shape[1] == 1:
|
| 286 |
+
pred_array = pred_array.squeeze(1)
|
| 287 |
+
forecast_arrays = pred_array.T
|
| 288 |
+
else:
|
| 289 |
+
forecast_arrays = pred_array.transpose(2, 0, 1)
|
| 290 |
+
|
| 291 |
+
forecast = QuantileForecast(
|
| 292 |
+
forecast_arrays=forecast_arrays,
|
| 293 |
+
forecast_keys=[str(q) for q in quantile_levels],
|
| 294 |
+
start_date=forecast_start,
|
| 295 |
+
)
|
| 296 |
+
else:
|
| 297 |
+
pred_array = predictions_unscaled[idx].cpu().numpy()
|
| 298 |
+
|
| 299 |
+
if pred_array.shape[1] == 1:
|
| 300 |
+
pred_array = pred_array.squeeze(1)
|
| 301 |
+
forecast_arrays = pred_array.reshape(1, -1)
|
| 302 |
+
else:
|
| 303 |
+
forecast_arrays = pred_array.reshape(1, *pred_array.shape)
|
| 304 |
+
|
| 305 |
+
forecast = QuantileForecast(
|
| 306 |
+
forecast_arrays=forecast_arrays,
|
| 307 |
+
forecast_keys=["0.5"],
|
| 308 |
+
start_date=forecast_start,
|
| 309 |
+
)
|
| 310 |
+
|
| 311 |
+
forecasts.append(forecast)
|
| 312 |
+
|
| 313 |
+
return forecasts
|
| 314 |
+
|
| 315 |
+
|
| 316 |
+
__all__ = ["TimeSeriesPredictor"]
|
| 317 |
+
|
| 318 |
+
|
src/gift_eval/results.py
ADDED
|
@@ -0,0 +1,243 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Utilities for persisting and aggregating GIFT-Eval results."""
|
| 2 |
+
|
| 3 |
+
import argparse
|
| 4 |
+
import csv
|
| 5 |
+
import glob
|
| 6 |
+
import logging
|
| 7 |
+
from pathlib import Path
|
| 8 |
+
from typing import List, Optional
|
| 9 |
+
|
| 10 |
+
import pandas as pd
|
| 11 |
+
|
| 12 |
+
from src.gift_eval.constants import (
|
| 13 |
+
ALL_DATASETS,
|
| 14 |
+
DATASET_PROPERTIES,
|
| 15 |
+
MED_LONG_DATASETS,
|
| 16 |
+
PRETTY_NAMES,
|
| 17 |
+
STANDARD_METRIC_NAMES,
|
| 18 |
+
)
|
| 19 |
+
from src.gift_eval.core import DatasetMetadata, EvaluationItem
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
logger = logging.getLogger(__name__)
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def _ensure_results_csv(csv_file_path: Path) -> None:
|
| 26 |
+
if not csv_file_path.exists():
|
| 27 |
+
csv_file_path.parent.mkdir(parents=True, exist_ok=True)
|
| 28 |
+
with open(csv_file_path, "w", newline="") as csvfile:
|
| 29 |
+
writer = csv.writer(csvfile)
|
| 30 |
+
header = (
|
| 31 |
+
["dataset", "model"]
|
| 32 |
+
+ [f"eval_metrics/{name}" for name in STANDARD_METRIC_NAMES]
|
| 33 |
+
+ ["domain", "num_variates"]
|
| 34 |
+
)
|
| 35 |
+
writer.writerow(header)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def write_results_to_disk(
|
| 39 |
+
items: List[EvaluationItem],
|
| 40 |
+
dataset_name: str,
|
| 41 |
+
output_dir: Path,
|
| 42 |
+
model_name: str,
|
| 43 |
+
create_plots: bool,
|
| 44 |
+
) -> None:
|
| 45 |
+
output_dir = output_dir / dataset_name
|
| 46 |
+
output_dir.mkdir(parents=True, exist_ok=True)
|
| 47 |
+
output_csv_path = output_dir / "results.csv"
|
| 48 |
+
_ensure_results_csv(output_csv_path)
|
| 49 |
+
|
| 50 |
+
try:
|
| 51 |
+
import matplotlib.pyplot as plt # Local import to avoid unnecessary dependency at module import time
|
| 52 |
+
except ImportError: # pragma: no cover - guard for optional dependency
|
| 53 |
+
plt = None
|
| 54 |
+
|
| 55 |
+
with open(output_csv_path, "a", newline="") as csvfile:
|
| 56 |
+
writer = csv.writer(csvfile)
|
| 57 |
+
for item in items:
|
| 58 |
+
md: DatasetMetadata = item.dataset_metadata
|
| 59 |
+
metric_values: List[Optional[float]] = []
|
| 60 |
+
for metric_name in STANDARD_METRIC_NAMES:
|
| 61 |
+
value = item.metrics.get(metric_name, None)
|
| 62 |
+
if value is None:
|
| 63 |
+
metric_values.append(None)
|
| 64 |
+
else:
|
| 65 |
+
if (
|
| 66 |
+
hasattr(value, "__len__")
|
| 67 |
+
and not isinstance(value, (str, bytes))
|
| 68 |
+
and len(value) == 1
|
| 69 |
+
):
|
| 70 |
+
value = value[0]
|
| 71 |
+
elif hasattr(value, "item"):
|
| 72 |
+
value = value.item()
|
| 73 |
+
metric_values.append(value)
|
| 74 |
+
|
| 75 |
+
ds_key = md.key.lower()
|
| 76 |
+
props = DATASET_PROPERTIES.get(ds_key, {})
|
| 77 |
+
domain = props.get("domain", "unknown")
|
| 78 |
+
num_variates = props.get(
|
| 79 |
+
"num_variates", 1 if md.to_univariate else md.target_dim
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
row = [md.full_name, model_name] + metric_values + [domain, num_variates]
|
| 83 |
+
writer.writerow(row)
|
| 84 |
+
|
| 85 |
+
if create_plots and item.figures and plt is not None:
|
| 86 |
+
plots_dir = output_dir / "plots" / md.key / md.term
|
| 87 |
+
plots_dir.mkdir(parents=True, exist_ok=True)
|
| 88 |
+
for fig, filename in item.figures:
|
| 89 |
+
filepath = plots_dir / filename
|
| 90 |
+
fig.savefig(filepath, dpi=300, bbox_inches="tight")
|
| 91 |
+
plt.close(fig)
|
| 92 |
+
|
| 93 |
+
logger.info(
|
| 94 |
+
"Evaluation complete for dataset '%s'. Results saved to %s",
|
| 95 |
+
dataset_name,
|
| 96 |
+
output_csv_path,
|
| 97 |
+
)
|
| 98 |
+
if create_plots:
|
| 99 |
+
logger.info("Plots saved under %s", output_dir / "plots")
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def get_all_datasets_full_name() -> List[str]:
|
| 103 |
+
"""Get all possible dataset full names for validation."""
|
| 104 |
+
|
| 105 |
+
terms = ["short", "medium", "long"]
|
| 106 |
+
datasets_full_names: List[str] = []
|
| 107 |
+
|
| 108 |
+
for name in ALL_DATASETS:
|
| 109 |
+
for term in terms:
|
| 110 |
+
if term in ["medium", "long"] and name not in MED_LONG_DATASETS:
|
| 111 |
+
continue
|
| 112 |
+
|
| 113 |
+
if "/" in name:
|
| 114 |
+
ds_key, ds_freq = name.split("/")
|
| 115 |
+
ds_key = ds_key.lower()
|
| 116 |
+
ds_key = PRETTY_NAMES.get(ds_key, ds_key)
|
| 117 |
+
else:
|
| 118 |
+
ds_key = name.lower()
|
| 119 |
+
ds_key = PRETTY_NAMES.get(ds_key, ds_key)
|
| 120 |
+
ds_freq = DATASET_PROPERTIES.get(ds_key, {}).get("frequency")
|
| 121 |
+
|
| 122 |
+
datasets_full_names.append(
|
| 123 |
+
f"{ds_key}/{ds_freq if ds_freq else 'unknown'}/{term}"
|
| 124 |
+
)
|
| 125 |
+
|
| 126 |
+
return datasets_full_names
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
def aggregate_results(result_root_dir: str | Path) -> pd.DataFrame | None:
|
| 130 |
+
"""Aggregate results from multiple CSV files into a single dataframe."""
|
| 131 |
+
|
| 132 |
+
result_root = Path(result_root_dir)
|
| 133 |
+
|
| 134 |
+
logger.info("Aggregating results in: %s", result_root)
|
| 135 |
+
|
| 136 |
+
result_files = glob.glob(f"{result_root}/**/results.csv", recursive=True)
|
| 137 |
+
|
| 138 |
+
if not result_files:
|
| 139 |
+
logger.error("No result files found!")
|
| 140 |
+
return None
|
| 141 |
+
|
| 142 |
+
dataframes: List[pd.DataFrame] = []
|
| 143 |
+
for file in result_files:
|
| 144 |
+
try:
|
| 145 |
+
df = pd.read_csv(file)
|
| 146 |
+
if len(df) > 0:
|
| 147 |
+
dataframes.append(df)
|
| 148 |
+
else:
|
| 149 |
+
logger.warning("Empty file: %s", file)
|
| 150 |
+
except pd.errors.EmptyDataError:
|
| 151 |
+
logger.warning("Skipping empty file: %s", file)
|
| 152 |
+
except Exception as exc:
|
| 153 |
+
logger.error("Error reading %s: %s", file, exc)
|
| 154 |
+
|
| 155 |
+
if not dataframes:
|
| 156 |
+
logger.warning("No valid CSV files found to combine")
|
| 157 |
+
return None
|
| 158 |
+
|
| 159 |
+
combined_df = pd.concat(dataframes, ignore_index=True).sort_values("dataset")
|
| 160 |
+
|
| 161 |
+
if len(combined_df) != len(set(combined_df.dataset)):
|
| 162 |
+
duplicate_datasets = combined_df.dataset[
|
| 163 |
+
combined_df.dataset.duplicated()
|
| 164 |
+
].tolist()
|
| 165 |
+
logger.warning("Warning: Duplicate datasets found: %s", duplicate_datasets)
|
| 166 |
+
combined_df = combined_df.drop_duplicates(subset=["dataset"], keep="first")
|
| 167 |
+
logger.info(
|
| 168 |
+
"Removed duplicates, %s unique datasets remaining", len(combined_df)
|
| 169 |
+
)
|
| 170 |
+
|
| 171 |
+
logger.info("Combined results: %s datasets", len(combined_df))
|
| 172 |
+
|
| 173 |
+
all_datasets_full_name = get_all_datasets_full_name()
|
| 174 |
+
completed_experiments = combined_df.dataset.tolist()
|
| 175 |
+
|
| 176 |
+
completed_experiments_clean = [
|
| 177 |
+
exp for exp in completed_experiments if exp in all_datasets_full_name
|
| 178 |
+
]
|
| 179 |
+
missing_or_failed_experiments = [
|
| 180 |
+
exp for exp in all_datasets_full_name if exp not in completed_experiments_clean
|
| 181 |
+
]
|
| 182 |
+
|
| 183 |
+
logger.info("=== EXPERIMENT SUMMARY ===")
|
| 184 |
+
logger.info("Total expected datasets: %s", len(all_datasets_full_name))
|
| 185 |
+
logger.info("Completed experiments: %s", len(completed_experiments_clean))
|
| 186 |
+
logger.info("Missing/failed experiments: %s", len(missing_or_failed_experiments))
|
| 187 |
+
|
| 188 |
+
logger.info("Completed experiments:")
|
| 189 |
+
for idx, exp in enumerate(completed_experiments_clean, start=1):
|
| 190 |
+
logger.info(" %3d: %s", idx, exp)
|
| 191 |
+
|
| 192 |
+
if missing_or_failed_experiments:
|
| 193 |
+
logger.info("Missing or failed experiments:")
|
| 194 |
+
for idx, exp in enumerate(missing_or_failed_experiments, start=1):
|
| 195 |
+
logger.info(" %3d: %s", idx, exp)
|
| 196 |
+
|
| 197 |
+
completion_rate = (
|
| 198 |
+
len(completed_experiments_clean) / len(all_datasets_full_name) * 100
|
| 199 |
+
if all_datasets_full_name
|
| 200 |
+
else 0.0
|
| 201 |
+
)
|
| 202 |
+
logger.info("Completion rate: %.1f%%", completion_rate)
|
| 203 |
+
|
| 204 |
+
output_file = result_root / "all_results.csv"
|
| 205 |
+
combined_df.to_csv(output_file, index=False)
|
| 206 |
+
logger.info("Combined results saved to: %s", output_file)
|
| 207 |
+
|
| 208 |
+
return combined_df
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
__all__ = [
|
| 212 |
+
"aggregate_results",
|
| 213 |
+
"get_all_datasets_full_name",
|
| 214 |
+
"write_results_to_disk",
|
| 215 |
+
]
|
| 216 |
+
|
| 217 |
+
|
| 218 |
+
def main() -> None:
|
| 219 |
+
"""CLI entry point for aggregating results from disk."""
|
| 220 |
+
|
| 221 |
+
parser = argparse.ArgumentParser(
|
| 222 |
+
description="Aggregate GIFT-Eval results from multiple CSV files"
|
| 223 |
+
)
|
| 224 |
+
parser.add_argument(
|
| 225 |
+
"--result_root_dir",
|
| 226 |
+
type=str,
|
| 227 |
+
required=True,
|
| 228 |
+
help="Root directory containing result subdirectories",
|
| 229 |
+
)
|
| 230 |
+
|
| 231 |
+
args = parser.parse_args()
|
| 232 |
+
result_root_dir = Path(args.result_root_dir)
|
| 233 |
+
|
| 234 |
+
logging.basicConfig(
|
| 235 |
+
level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s"
|
| 236 |
+
)
|
| 237 |
+
logger.info("Searching in directory: %s", result_root_dir)
|
| 238 |
+
|
| 239 |
+
aggregate_results(result_root_dir=result_root_dir)
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
if __name__ == "__main__":
|
| 243 |
+
main()
|
src/models/__init__.py
ADDED
|
File without changes
|
src/models/blocks.py
ADDED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
|
| 4 |
+
from src.models.gated_deltaproduct import GatedDeltaProductConfig
|
| 5 |
+
from src.models.gated_deltaproduct.modeling_gated_deltaproduct import (
|
| 6 |
+
GatedDeltaProductBlock,
|
| 7 |
+
)
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class GatedDeltaProductEncoder(nn.Module):
|
| 11 |
+
"""
|
| 12 |
+
GatedDeltaNet encoder using GatedDeltaProductBlock for sequence modeling.
|
| 13 |
+
"""
|
| 14 |
+
|
| 15 |
+
def __init__(
|
| 16 |
+
self,
|
| 17 |
+
layer_idx: int,
|
| 18 |
+
token_embed_dim: int,
|
| 19 |
+
num_heads: int = 4,
|
| 20 |
+
attn_mode: str = "chunk",
|
| 21 |
+
expand_v: float = 1.0,
|
| 22 |
+
use_gate: bool = False,
|
| 23 |
+
use_short_conv: bool = True,
|
| 24 |
+
conv_size: int = 4,
|
| 25 |
+
hidden_ratio: int = 1.0,
|
| 26 |
+
allow_neg_eigval: bool = True,
|
| 27 |
+
use_forget_gate: bool = True,
|
| 28 |
+
num_householder: int = 1,
|
| 29 |
+
**kwargs,
|
| 30 |
+
):
|
| 31 |
+
super().__init__()
|
| 32 |
+
config = GatedDeltaProductConfig(
|
| 33 |
+
attn_mode=attn_mode,
|
| 34 |
+
hidden_size=token_embed_dim,
|
| 35 |
+
expand_v=expand_v,
|
| 36 |
+
use_gate=use_gate,
|
| 37 |
+
use_short_conv=use_short_conv,
|
| 38 |
+
conv_size=conv_size,
|
| 39 |
+
head_dim=token_embed_dim // num_heads,
|
| 40 |
+
hidden_ratio=hidden_ratio,
|
| 41 |
+
num_heads=num_heads,
|
| 42 |
+
allow_neg_eigval=allow_neg_eigval,
|
| 43 |
+
use_forget_gate=use_forget_gate,
|
| 44 |
+
num_householder=num_householder,
|
| 45 |
+
)
|
| 46 |
+
|
| 47 |
+
self.encoder_layer = GatedDeltaProductBlock(layer_idx=layer_idx, config=config)
|
| 48 |
+
|
| 49 |
+
def forward(self, x, initial_state=None):
|
| 50 |
+
"""
|
| 51 |
+
Forward pass through the GatedDeltaProductBlock.
|
| 52 |
+
|
| 53 |
+
Args:
|
| 54 |
+
x: Input tensor of shape [batch_size, seq_len, hidden_size]
|
| 55 |
+
|
| 56 |
+
Returns:
|
| 57 |
+
Output tensor of same shape as input
|
| 58 |
+
"""
|
| 59 |
+
x, last_hidden_state, _ = self.encoder_layer(
|
| 60 |
+
x, output_attentions=True, initial_state=initial_state
|
| 61 |
+
)
|
| 62 |
+
return x, last_hidden_state
|
src/models/gated_deltaproduct/README.md
ADDED
|
@@ -0,0 +1,344 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Custom GatedDeltaProduct Implementation
|
| 2 |
+
|
| 3 |
+
This directory contains a custom implementation of the GatedDeltaProduct layer, based on the [Flash Linear Attention (FLA)](https://github.com/fla-org/flash-linear-attention) library, with modifications specifically designed for **time series forecasting** tasks.
|
| 4 |
+
|
| 5 |
+
## Overview
|
| 6 |
+
|
| 7 |
+
Our custom implementation adds **hidden state weaving** functionality that enables information to flow across encoder layers, maintaining temporal continuity - a crucial feature for time series forecasting that differs from the general-purpose language modeling focus of the official FLA implementation.
|
| 8 |
+
|
| 9 |
+
## Reference
|
| 10 |
+
|
| 11 |
+
This implementation is based on:
|
| 12 |
+
- **Official FLA Repository**: [https://github.com/fla-org/flash-linear-attention](https://github.com/fla-org/flash-linear-attention)
|
| 13 |
+
- **Original Paper**: [DeltaProduct: Improving State-Tracking in Linear RNNs via Householder Products](https://arxiv.org/html/2502.10297v3) (Siems et al., 2025)
|
| 14 |
+
|
| 15 |
+
---
|
| 16 |
+
|
| 17 |
+
## What is DeltaProduct?
|
| 18 |
+
|
| 19 |
+
DeltaProduct is a linear RNN architecture that uses **diagonal plus rank-nₕ** state-transition matrices, formed as products of `nₕ` generalized Householder transformations. This provides a tunable mechanism to balance expressivity and efficiency compared to diagonal-only architectures like Mamba or GLA.
|
| 20 |
+
|
| 21 |
+
### Key Concepts
|
| 22 |
+
|
| 23 |
+
- **Householder transformations**: Enable simultaneous token-channel mixing, overcoming the expressivity limitations of purely diagonal state-transition matrices
|
| 24 |
+
- **Rank-nₕ structure**: Allows better expressivity than rank-1 (DeltaNet) while maintaining training efficiency. The parameter `nₕ` (number of Householder transformations) provides a tunable trade-off between expressivity and computational cost
|
| 25 |
+
- **Gated variant**: Adds gating mechanisms for improved performance, allowing the model to control information flow through forget gates and output gates
|
| 26 |
+
|
| 27 |
+
### Architecture Overview
|
| 28 |
+
|
| 29 |
+
DeltaProduct improves upon earlier linear RNN architectures:
|
| 30 |
+
|
| 31 |
+
- **Diagonal architectures** (Mamba, GLA, mLSTM): Use diagonal state-transition matrices for fast runtime but suffer from limited expressivity
|
| 32 |
+
- **Rank-1 architectures** (DeltaNet, RWKV-7): Use diagonal plus rank-1 structure, enabling simultaneous token-channel mixing with only a slight decrease in training efficiency
|
| 33 |
+
- **DeltaProduct**: Extends this to diagonal plus rank-nₕ structure, where multiple Householder transformations (nₕ ≥ 1) provide greater expressivity while maintaining computational efficiency
|
| 34 |
+
|
| 35 |
+
The architecture interprets DeltaNet's recurrence as performing one step of online gradient descent per token on an associative recall loss. DeltaProduct instead takes multiple (`nₕ`) steps per token, naturally leading to the rank-nₕ structure.
|
| 36 |
+
|
| 37 |
+
---
|
| 38 |
+
|
| 39 |
+
## State Weaving Mechanism
|
| 40 |
+
|
| 41 |
+
Unlike DeltaProduct's original design for autoregressive language modeling, time series forecasting across a full horizon does not require causal masking. To exploit this property, we introduce **state weaving**, a mechanism that enables bidirectional information flow across the entire sequence length without additional parameters or computational overhead.
|
| 42 |
+
|
| 43 |
+
<div align="center">
|
| 44 |
+
<img src="https://iili.io/Ks86Z0X.png" alt="State Weaving Architecture" width="450"/>
|
| 45 |
+
</div>
|
| 46 |
+
|
| 47 |
+
*Figure: The TempoPFN architecture using stacked GatedDeltaProduct blocks with learnable initial states H₀ⁱ and state-weaving. The final hidden state of each layer Hₜⁱ is added to the learnable initial state of the next layer H₀ⁱ⁺¹, enabling bidirectional information flow.*
|
| 48 |
+
|
| 49 |
+
### How State Weaving Works
|
| 50 |
+
|
| 51 |
+
In our implementation, state weaving operates as follows:
|
| 52 |
+
|
| 53 |
+
1. **Learnable Initial States**: Each encoder layer `i` has a learnable initial hidden state `H₀ⁱ` that is optimized during training.
|
| 54 |
+
|
| 55 |
+
2. **State Propagation**: The final hidden state from layer `i`, denoted `Hₜⁱ`, is propagated forward and combined with the learnable initial state of the next layer:
|
| 56 |
+
```
|
| 57 |
+
H₀ⁱ⁺¹ = H₀ⁱ⁺¹ + Hₜⁱ
|
| 58 |
+
```
|
| 59 |
+
|
| 60 |
+
3. **Bidirectional Information Flow**: This mechanism effectively lifts the causal constraint while maintaining computational efficiency. Information from later tokens can influence earlier layers through the accumulated hidden states, enabling the model to process the entire sequence (history + future horizon) coherently.
|
| 61 |
+
|
| 62 |
+
4. **No Extra Overhead**: Unlike explicit bidirectional architectures, state weaving requires no additional parameters or computational overhead beyond the existing forward pass.
|
| 63 |
+
|
| 64 |
+
This design is particularly powerful for time series forecasting, where:
|
| 65 |
+
- The full prediction horizon is known at inference time
|
| 66 |
+
- Coherent predictions across all future time steps are desired
|
| 67 |
+
- Historical context should inform all future predictions simultaneously
|
| 68 |
+
|
| 69 |
+
---
|
| 70 |
+
|
| 71 |
+
## Key Differences from Official FLA
|
| 72 |
+
|
| 73 |
+
### 1. **`initial_state` Parameter in Forward Method**
|
| 74 |
+
|
| 75 |
+
#### Official FLA (`fla/layers/gated_deltaproduct.py`)
|
| 76 |
+
```python
|
| 77 |
+
def forward(
|
| 78 |
+
self,
|
| 79 |
+
hidden_states: torch.Tensor,
|
| 80 |
+
attention_mask: torch.Tensor | None = None,
|
| 81 |
+
past_key_values: Cache | None = None,
|
| 82 |
+
use_cache: bool | None = False,
|
| 83 |
+
output_attentions: bool | None = False,
|
| 84 |
+
**kwargs: Unpack[dict],
|
| 85 |
+
) -> tuple[torch.Tensor, torch.Tensor | None, Cache | None]:
|
| 86 |
+
```
|
| 87 |
+
**No `initial_state` parameter** - The official implementation only uses `recurrent_state` from `past_key_values`.
|
| 88 |
+
|
| 89 |
+
#### Our Custom Implementation (`gated_deltaproduct.py`)
|
| 90 |
+
```python
|
| 91 |
+
def forward(
|
| 92 |
+
self,
|
| 93 |
+
hidden_states: torch.Tensor,
|
| 94 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 95 |
+
past_key_values: Optional[Cache] = None,
|
| 96 |
+
initial_state: Optional[torch.Tensor] = None, # ← ADDED
|
| 97 |
+
use_cache: Optional[bool] = False,
|
| 98 |
+
output_attentions: Optional[bool] = False,
|
| 99 |
+
**kwargs: Unpack[Dict],
|
| 100 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Cache]]:
|
| 101 |
+
```
|
| 102 |
+
**Added `initial_state` parameter** - Allows external control of the initial recurrent state, enabling layer-to-layer state propagation.
|
| 103 |
+
|
| 104 |
+
---
|
| 105 |
+
|
| 106 |
+
### 2. **Usage of `initial_state` in Chunk Mode**
|
| 107 |
+
|
| 108 |
+
#### Official FLA
|
| 109 |
+
```python
|
| 110 |
+
if mode == 'chunk':
|
| 111 |
+
o, recurrent_state = chunk_gated_delta_product(
|
| 112 |
+
q=q, k=k, v=v, g=g, beta=beta,
|
| 113 |
+
initial_state=recurrent_state, # ← Only from past_key_values
|
| 114 |
+
output_final_state=use_cache,
|
| 115 |
+
cu_seqlens=cu_seqlens,
|
| 116 |
+
num_householder=self.num_householder,
|
| 117 |
+
use_qk_l2norm_in_kernel=True,
|
| 118 |
+
)
|
| 119 |
+
```
|
| 120 |
+
|
| 121 |
+
#### Our Custom Implementation
|
| 122 |
+
```python
|
| 123 |
+
if mode == "chunk":
|
| 124 |
+
o, recurrent_state = chunk_gated_delta_product(
|
| 125 |
+
q=q, k=k, v=v, g=g, beta=beta,
|
| 126 |
+
initial_state=initial_state, # ← Uses external initial_state if provided
|
| 127 |
+
output_final_state=output_attentions,
|
| 128 |
+
cu_seqlens=cu_seqlens,
|
| 129 |
+
num_householder=self.num_householder,
|
| 130 |
+
use_qk_l2norm_in_kernel=True,
|
| 131 |
+
)
|
| 132 |
+
```
|
| 133 |
+
|
| 134 |
+
**Key Difference**: Our implementation prioritizes the externally provided `initial_state` over `recurrent_state` from `past_key_values`, enabling layer-to-layer state propagation.
|
| 135 |
+
|
| 136 |
+
---
|
| 137 |
+
|
| 138 |
+
### 3. **Return Value: Hidden State Output**
|
| 139 |
+
|
| 140 |
+
#### Official FLA (`fla/models/gated_deltaproduct/modeling_gated_deltaproduct.py`)
|
| 141 |
+
```python
|
| 142 |
+
def forward(
|
| 143 |
+
self,
|
| 144 |
+
hidden_states: torch.Tensor,
|
| 145 |
+
attention_mask: torch.Tensor | None = None,
|
| 146 |
+
past_key_values: Cache | list[torch.FloatTensor] | None = None,
|
| 147 |
+
use_cache: bool | None = False,
|
| 148 |
+
output_attentions: bool | None = False,
|
| 149 |
+
**kwargs: Unpack[dict],
|
| 150 |
+
) -> tuple[torch.FloatTensor, tuple[torch.FloatTensor, torch.FloatTensor] | None]:
|
| 151 |
+
# ...
|
| 152 |
+
return outputs # Returns (hidden_states, attentions, past_key_values)
|
| 153 |
+
```
|
| 154 |
+
|
| 155 |
+
**No `initial_state` parameter** - The block doesn't accept or return hidden states explicitly.
|
| 156 |
+
|
| 157 |
+
#### Our Custom Implementation (`modeling_gated_deltaproduct.py`)
|
| 158 |
+
```python
|
| 159 |
+
def forward(
|
| 160 |
+
self,
|
| 161 |
+
hidden_states: torch.Tensor,
|
| 162 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 163 |
+
past_key_values: Optional[Union[Cache, List[torch.FloatTensor]]] = None,
|
| 164 |
+
use_cache: Optional[bool] = False,
|
| 165 |
+
output_attentions: Optional[bool] = False,
|
| 166 |
+
initial_state: Optional[torch.FloatTensor] = None, # ← ADDED
|
| 167 |
+
**kwargs: Unpack[Dict],
|
| 168 |
+
) -> Tuple[
|
| 169 |
+
torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]
|
| 170 |
+
]:
|
| 171 |
+
# ...
|
| 172 |
+
hidden_states, attentions, past_key_values = self.attn(
|
| 173 |
+
# ...
|
| 174 |
+
initial_state=initial_state, # ← Passed through
|
| 175 |
+
**kwargs,
|
| 176 |
+
)
|
| 177 |
+
# ...
|
| 178 |
+
return outputs # Returns (hidden_states, attentions, past_key_values)
|
| 179 |
+
```
|
| 180 |
+
|
| 181 |
+
**Added `initial_state` parameter** - The block accepts and forwards `initial_state` to the attention layer.
|
| 182 |
+
|
| 183 |
+
---
|
| 184 |
+
|
| 185 |
+
### 4. **Hidden State Weaving Implementation**
|
| 186 |
+
|
| 187 |
+
Our implementation supports two modes of hidden state weaving (controlled by the `weaving` parameter in encoder config):
|
| 188 |
+
|
| 189 |
+
#### **Mode 1: Weaving Enabled (`weaving=True`)** - Default
|
| 190 |
+
```python
|
| 191 |
+
if self.encoder_config.get("weaving", True):
|
| 192 |
+
# initial hidden state is learnable
|
| 193 |
+
hidden_state = torch.zeros_like(
|
| 194 |
+
self.initial_hidden_state[0].repeat(batch_size * num_channels, 1, 1, 1)
|
| 195 |
+
)
|
| 196 |
+
for layer_idx, encoder_layer in enumerate(self.encoder_layers):
|
| 197 |
+
x, hidden_state = encoder_layer(
|
| 198 |
+
x,
|
| 199 |
+
hidden_state + self.initial_hidden_state[layer_idx].repeat(
|
| 200 |
+
batch_size * num_channels, 1, 1, 1
|
| 201 |
+
),
|
| 202 |
+
)
|
| 203 |
+
```
|
| 204 |
+
|
| 205 |
+
**Key Features**:
|
| 206 |
+
- Hidden state accumulates across layers
|
| 207 |
+
- Each layer receives: `previous_hidden_state + learnable_initial_state[layer_idx]`
|
| 208 |
+
- State persists between layers, allowing information to flow through the network
|
| 209 |
+
|
| 210 |
+
#### **Mode 2: No Weaving (`weaving=False`)**
|
| 211 |
+
```python
|
| 212 |
+
else:
|
| 213 |
+
# initial hidden state is separately learnable for each layer
|
| 214 |
+
for layer_idx, encoder_layer in enumerate(self.encoder_layers):
|
| 215 |
+
initial_hidden_state = self.initial_hidden_state[layer_idx].repeat(
|
| 216 |
+
batch_size * num_channels, 1, 1, 1
|
| 217 |
+
)
|
| 218 |
+
x, _ = encoder_layer(x, initial_hidden_state)
|
| 219 |
+
```
|
| 220 |
+
|
| 221 |
+
**Key Features**:
|
| 222 |
+
- Each layer uses its own independent learnable initial state
|
| 223 |
+
- No accumulation between layers
|
| 224 |
+
- Hidden state is discarded after each layer
|
| 225 |
+
|
| 226 |
+
---
|
| 227 |
+
|
| 228 |
+
### 5. **Learnable Initial Hidden States**
|
| 229 |
+
|
| 230 |
+
Our implementation includes learnable initial states managed at the model level:
|
| 231 |
+
|
| 232 |
+
```python
|
| 233 |
+
num_initial_hidden_states = self.num_encoder_layers
|
| 234 |
+
self.initial_hidden_state = nn.ParameterList(
|
| 235 |
+
[
|
| 236 |
+
nn.Parameter(
|
| 237 |
+
torch.randn(
|
| 238 |
+
1, self.encoder_config["num_heads"], head_k_dim, head_v_dim
|
| 239 |
+
)
|
| 240 |
+
/ head_k_dim,
|
| 241 |
+
requires_grad=True,
|
| 242 |
+
)
|
| 243 |
+
for _ in range(num_initial_hidden_states)
|
| 244 |
+
]
|
| 245 |
+
)
|
| 246 |
+
```
|
| 247 |
+
|
| 248 |
+
**Key Features**:
|
| 249 |
+
- One learnable parameter per encoder layer
|
| 250 |
+
- Shape: `[1, num_heads, head_k_dim, head_v_dim]`
|
| 251 |
+
- Initialized with small random values scaled by `head_k_dim`
|
| 252 |
+
- These are trainable parameters that can be optimized during training
|
| 253 |
+
|
| 254 |
+
---
|
| 255 |
+
|
| 256 |
+
### 6. **Parameter Name Differences**
|
| 257 |
+
|
| 258 |
+
- **Official FLA**: Uses `use_output_gate` parameter
|
| 259 |
+
- **Our Implementation**: Uses `use_gate` parameter (renamed for clarity)
|
| 260 |
+
|
| 261 |
+
---
|
| 262 |
+
|
| 263 |
+
### 7. **Return Value Differences**
|
| 264 |
+
|
| 265 |
+
#### Official FLA (`fla/layers/gated_deltaproduct.py`)
|
| 266 |
+
```python
|
| 267 |
+
return o, None, past_key_values # Returns (output, None, past_key_values)
|
| 268 |
+
```
|
| 269 |
+
|
| 270 |
+
#### Our Custom Implementation (`gated_deltaproduct.py`)
|
| 271 |
+
```python
|
| 272 |
+
return o, recurrent_state, past_key_values # Returns (output, recurrent_state, past_key_values)
|
| 273 |
+
```
|
| 274 |
+
|
| 275 |
+
**Key Difference**: Our implementation returns `recurrent_state` (the final hidden state) instead of `None`, enabling state propagation.
|
| 276 |
+
|
| 277 |
+
---
|
| 278 |
+
|
| 279 |
+
### 8. **Encoder Wrapper Return Values**
|
| 280 |
+
|
| 281 |
+
Our `GatedDeltaProductEncoder` (in `src/models/blocks.py`) returns both the output and hidden state:
|
| 282 |
+
|
| 283 |
+
```python
|
| 284 |
+
x, last_hidden_state, _ = self.encoder_layer(
|
| 285 |
+
x, output_attentions=True, initial_state=initial_state
|
| 286 |
+
)
|
| 287 |
+
return x, last_hidden_state # ← Returns hidden state for weaving
|
| 288 |
+
```
|
| 289 |
+
|
| 290 |
+
This allows state propagation between layers in the `TimeSeriesModel`.
|
| 291 |
+
|
| 292 |
+
---
|
| 293 |
+
|
| 294 |
+
## Summary Table
|
| 295 |
+
|
| 296 |
+
| Feature | Official FLA | Our Custom Implementation |
|
| 297 |
+
|---------|-------------|---------------------------|
|
| 298 |
+
| `initial_state` in `forward()` | ❌ No | ✅ Yes |
|
| 299 |
+
| `initial_state` in `GatedDeltaProductBlock.forward()` | ❌ No | ✅ Yes |
|
| 300 |
+
| Hidden state weaving | ❌ No | ✅ Yes (configurable) |
|
| 301 |
+
| Learnable initial states | ❌ No | ✅ Yes (`nn.ParameterList`) |
|
| 302 |
+
| Returns `recurrent_state` | ❌ No (returns `None`) | ✅ Yes |
|
| 303 |
+
| Layer-to-layer state propagation | ❌ No | ✅ Yes (when `weaving=True`) |
|
| 304 |
+
| Parameter name | `use_output_gate` | `use_gate` |
|
| 305 |
+
|
| 306 |
+
---
|
| 307 |
+
|
| 308 |
+
## Why These Differences Matter for Time Series Forecasting
|
| 309 |
+
|
| 310 |
+
1. **Temporal Continuity**: Hidden state weaving allows information to flow across layers, maintaining temporal patterns across the encoder stack. This is crucial for time series where historical context matters.
|
| 311 |
+
|
| 312 |
+
2. **Learnable Initialization**: Learnable initial states allow the model to learn optimal starting points for the recurrent computation, which can be crucial for capturing time series patterns.
|
| 313 |
+
|
| 314 |
+
3. **Flexible State Management**: The `weaving` parameter allows switching between:
|
| 315 |
+
- **Weaving mode**: Better for capturing long-term dependencies across layers
|
| 316 |
+
- **Independent mode**: Each layer processes independently, potentially more stable
|
| 317 |
+
|
| 318 |
+
4. **State Propagation**: Returning and propagating hidden states enables the model to maintain context across multiple encoder layers, which is beneficial for time series forecasting where historical context matters.
|
| 319 |
+
|
| 320 |
+
These modifications make our implementation better suited for time series forecasting tasks compared to the general-purpose language modeling focus of the official FLA implementation.
|
| 321 |
+
|
| 322 |
+
---
|
| 323 |
+
|
| 324 |
+
## Files in This Directory
|
| 325 |
+
|
| 326 |
+
- **`gated_deltaproduct.py`**: Core GatedDeltaProduct layer implementation with `initial_state` support
|
| 327 |
+
- **`modeling_gated_deltaproduct.py`**: GatedDeltaProductBlock wrapper that integrates the layer
|
| 328 |
+
- **`configuration_gated_deltaproduct.py`**: Configuration class for the model
|
| 329 |
+
- **`__init__.py`**: Module exports
|
| 330 |
+
|
| 331 |
+
---
|
| 332 |
+
|
| 333 |
+
## Usage
|
| 334 |
+
|
| 335 |
+
See `src/models/model.py` and `src/models/blocks.py` for examples of how to use this custom implementation with hidden state weaving.
|
| 336 |
+
|
| 337 |
+
To enable/disable weaving, set the `weaving` parameter in your encoder configuration:
|
| 338 |
+
```python
|
| 339 |
+
encoder_config = {
|
| 340 |
+
"weaving": True, # Enable state propagation across layers
|
| 341 |
+
# ... other config parameters
|
| 342 |
+
}
|
| 343 |
+
```
|
| 344 |
+
|
src/models/gated_deltaproduct/__init__.py
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from src.models.gated_deltaproduct.configuration_gated_deltaproduct import (
|
| 2 |
+
GatedDeltaProductConfig,
|
| 3 |
+
)
|
| 4 |
+
from src.models.gated_deltaproduct.modeling_gated_deltaproduct import (
|
| 5 |
+
GatedDeltaProductBlock,
|
| 6 |
+
)
|
| 7 |
+
|
| 8 |
+
__all__ = [
|
| 9 |
+
"GatedDeltaProductConfig",
|
| 10 |
+
"GatedDeltaProductBlock",
|
| 11 |
+
]
|
src/models/gated_deltaproduct/configuration_gated_deltaproduct.py
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import warnings
|
| 2 |
+
|
| 3 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class GatedDeltaProductConfig(PretrainedConfig):
|
| 7 |
+
model_type = "gated_deltaproduct"
|
| 8 |
+
keys_to_ignore_at_inference = ["past_key_values"]
|
| 9 |
+
|
| 10 |
+
def __init__(
|
| 11 |
+
self,
|
| 12 |
+
attn_mode: str = "chunk",
|
| 13 |
+
conv_size: int = 4,
|
| 14 |
+
head_dim: int = 256,
|
| 15 |
+
num_heads: int = 6,
|
| 16 |
+
hidden_size: int = 2048,
|
| 17 |
+
expand_v: float = 2.0,
|
| 18 |
+
use_gate: bool = True, # Changed from use_output_gate to use_gate for custom implementation
|
| 19 |
+
use_short_conv: bool = True,
|
| 20 |
+
max_position_embeddings: int = 2048,
|
| 21 |
+
hidden_ratio: int | None = 4,
|
| 22 |
+
intermediate_size: int | None = None,
|
| 23 |
+
hidden_act: str = "swish",
|
| 24 |
+
num_hidden_layers: int = 21,
|
| 25 |
+
norm_eps: float = 1e-6,
|
| 26 |
+
attn: dict | None = None,
|
| 27 |
+
use_cache: bool = True,
|
| 28 |
+
pad_token_id: int = None,
|
| 29 |
+
bos_token_id: int = 1,
|
| 30 |
+
eos_token_id: int = 2,
|
| 31 |
+
tie_word_embeddings: bool = False,
|
| 32 |
+
initializer_range: float = 0.02,
|
| 33 |
+
fuse_norm: bool = True,
|
| 34 |
+
fuse_swiglu: bool = True,
|
| 35 |
+
fuse_cross_entropy: bool = True,
|
| 36 |
+
fuse_linear_cross_entropy: bool = False,
|
| 37 |
+
use_l2warp: bool = False,
|
| 38 |
+
vocab_size: int = 32000,
|
| 39 |
+
use_forget_gate: bool = False,
|
| 40 |
+
allow_neg_eigval: bool = False,
|
| 41 |
+
num_householder: int = 1,
|
| 42 |
+
**kwargs,
|
| 43 |
+
):
|
| 44 |
+
self.attn_mode = attn_mode
|
| 45 |
+
self.conv_size = conv_size
|
| 46 |
+
self.head_dim = head_dim
|
| 47 |
+
self.num_heads = num_heads
|
| 48 |
+
self.hidden_size = hidden_size
|
| 49 |
+
self.expand_v = expand_v
|
| 50 |
+
self.use_gate = use_gate # Changed from use_output_gate to use_gate
|
| 51 |
+
self.use_short_conv = use_short_conv
|
| 52 |
+
self.max_position_embeddings = max_position_embeddings
|
| 53 |
+
|
| 54 |
+
self.hidden_ratio = hidden_ratio
|
| 55 |
+
self.intermediate_size = intermediate_size
|
| 56 |
+
self.hidden_act = hidden_act
|
| 57 |
+
self.num_hidden_layers = num_hidden_layers
|
| 58 |
+
self.norm_eps = norm_eps
|
| 59 |
+
self.attn = attn
|
| 60 |
+
self.use_cache = use_cache
|
| 61 |
+
self.initializer_range = initializer_range
|
| 62 |
+
|
| 63 |
+
self.fuse_norm = fuse_norm
|
| 64 |
+
self.fuse_swiglu = fuse_swiglu
|
| 65 |
+
self.fuse_cross_entropy = fuse_cross_entropy
|
| 66 |
+
self.fuse_linear_cross_entropy = fuse_linear_cross_entropy
|
| 67 |
+
self.use_l2warp = use_l2warp
|
| 68 |
+
self.vocab_size = vocab_size
|
| 69 |
+
|
| 70 |
+
if fuse_cross_entropy and fuse_linear_cross_entropy:
|
| 71 |
+
raise ValueError(
|
| 72 |
+
"`fuse_cross_entropy` and `fuse_linear_cross_entropy` cannot be True at the same time.",
|
| 73 |
+
)
|
| 74 |
+
if fuse_linear_cross_entropy:
|
| 75 |
+
warnings.warn(
|
| 76 |
+
"`fuse_linear_cross_entropy` is enabled, which can improves memory efficiency "
|
| 77 |
+
"at the potential cost of reduced precision. "
|
| 78 |
+
"If you observe issues like loss divergence, consider disabling this setting.",
|
| 79 |
+
)
|
| 80 |
+
|
| 81 |
+
# DeltaProduct specific
|
| 82 |
+
self.allow_neg_eigval = allow_neg_eigval
|
| 83 |
+
self.num_householder = num_householder
|
| 84 |
+
self.use_forget_gate = use_forget_gate
|
| 85 |
+
|
| 86 |
+
if attn is not None:
|
| 87 |
+
if not isinstance(attn, dict):
|
| 88 |
+
raise ValueError("attn must be a dictionary")
|
| 89 |
+
if "layers" not in attn:
|
| 90 |
+
raise ValueError(
|
| 91 |
+
"Layer indices must be provided to initialize hybrid attention layers"
|
| 92 |
+
)
|
| 93 |
+
if "num_heads" not in attn:
|
| 94 |
+
raise ValueError(
|
| 95 |
+
"Number of heads must be provided to initialize hybrid attention layers"
|
| 96 |
+
)
|
| 97 |
+
attn["num_kv_heads"] = attn.get("num_kv_heads", attn["num_heads"])
|
| 98 |
+
attn["qkv_bias"] = attn.get("qkv_bias", False)
|
| 99 |
+
attn["window_size"] = attn.get("window_size", None)
|
| 100 |
+
attn["rope_theta"] = attn.get("rope_theta", 10000.0)
|
| 101 |
+
|
| 102 |
+
super().__init__(
|
| 103 |
+
pad_token_id=pad_token_id,
|
| 104 |
+
bos_token_id=bos_token_id,
|
| 105 |
+
eos_token_id=eos_token_id,
|
| 106 |
+
tie_word_embeddings=tie_word_embeddings,
|
| 107 |
+
**kwargs,
|
| 108 |
+
)
|
src/models/gated_deltaproduct/gated_deltaproduct.py
ADDED
|
@@ -0,0 +1,351 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
# Copyright (c) 2023-2025, Songlin Yang, Yu Zhang
|
| 3 |
+
|
| 4 |
+
from __future__ import annotations
|
| 5 |
+
|
| 6 |
+
import math
|
| 7 |
+
import warnings
|
| 8 |
+
from typing import TYPE_CHECKING, Dict, Optional, Tuple
|
| 9 |
+
|
| 10 |
+
import torch
|
| 11 |
+
import torch.nn as nn
|
| 12 |
+
from einops import rearrange, repeat
|
| 13 |
+
from fla.layers.utils import get_unpad_data, index_first_axis, pad_input
|
| 14 |
+
from fla.modules import FusedRMSNormGated, RMSNorm, ShortConvolution
|
| 15 |
+
from fla.ops.delta_rule import fused_recurrent_delta_rule
|
| 16 |
+
from fla.ops.gated_delta_product import chunk_gated_delta_product
|
| 17 |
+
from fla.ops.gated_delta_rule import fused_recurrent_gated_delta_rule
|
| 18 |
+
from torch.nn import functional as F
|
| 19 |
+
|
| 20 |
+
if TYPE_CHECKING:
|
| 21 |
+
from fla.models.utils import Cache
|
| 22 |
+
from transformers.processing_utils import Unpack
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
class GatedDeltaProduct(nn.Module):
|
| 26 |
+
"""
|
| 27 |
+
Generalized version of GatedDoubleDeltaNet that supports arbitrary number of householder transformations.
|
| 28 |
+
"""
|
| 29 |
+
|
| 30 |
+
def __init__(
|
| 31 |
+
self,
|
| 32 |
+
hidden_size: int = 2048,
|
| 33 |
+
expand_v: float = 2,
|
| 34 |
+
head_dim: int = 256,
|
| 35 |
+
num_heads: int = 6,
|
| 36 |
+
num_v_heads: int = None,
|
| 37 |
+
mode: str = "chunk",
|
| 38 |
+
use_gate: bool = True,
|
| 39 |
+
use_short_conv: bool = True,
|
| 40 |
+
conv_size: int = 4,
|
| 41 |
+
conv_bias: bool = False,
|
| 42 |
+
layer_idx: int = None,
|
| 43 |
+
norm_eps: float = 1e-5,
|
| 44 |
+
use_forget_gate: bool = True,
|
| 45 |
+
allow_neg_eigval: bool = True,
|
| 46 |
+
num_householder: int = 2,
|
| 47 |
+
**kwargs,
|
| 48 |
+
) -> GatedDeltaProduct:
|
| 49 |
+
super().__init__()
|
| 50 |
+
|
| 51 |
+
self.mode = mode
|
| 52 |
+
|
| 53 |
+
self.hidden_size = hidden_size
|
| 54 |
+
self.expand_v = expand_v
|
| 55 |
+
|
| 56 |
+
self.use_forget_gate = use_forget_gate
|
| 57 |
+
self.allow_neg_eigval = allow_neg_eigval
|
| 58 |
+
self.num_householder = num_householder
|
| 59 |
+
self.use_gate = use_gate
|
| 60 |
+
self.use_short_conv = use_short_conv
|
| 61 |
+
self.conv_size = conv_size
|
| 62 |
+
self.conv_bias = conv_bias
|
| 63 |
+
|
| 64 |
+
self.head_dim = head_dim
|
| 65 |
+
self.num_heads = num_heads
|
| 66 |
+
self.num_v_heads = num_v_heads if num_v_heads is not None else num_heads
|
| 67 |
+
|
| 68 |
+
self.head_k_dim = head_dim
|
| 69 |
+
self.head_v_dim = int(self.head_dim * self.expand_v)
|
| 70 |
+
self.key_dim = int(self.num_heads * self.head_k_dim)
|
| 71 |
+
self.value_dim = int(self.num_v_heads * self.head_v_dim)
|
| 72 |
+
self.layer_idx = layer_idx
|
| 73 |
+
self.init_hidden_state = nn.Parameter(
|
| 74 |
+
torch.randn(self.num_heads, self.head_dim, self.head_dim)
|
| 75 |
+
)
|
| 76 |
+
|
| 77 |
+
# Consistency check: Ensure expand_v produces integer values
|
| 78 |
+
if not math.isclose(
|
| 79 |
+
self.num_v_heads * self.head_dim * expand_v, self.value_dim, rel_tol=1e-5
|
| 80 |
+
):
|
| 81 |
+
raise ValueError(
|
| 82 |
+
f"expand_v={expand_v} does not produce an integer value when multiplied by key_dim={self.key_dim}. "
|
| 83 |
+
f"Resulting value_dim would be {self.num_v_heads * self.head_dim * expand_v}, which is invalid for nn.Linear."
|
| 84 |
+
)
|
| 85 |
+
if self.num_v_heads > self.num_heads and self.num_v_heads % self.num_heads != 0:
|
| 86 |
+
raise ValueError(
|
| 87 |
+
f"num_v_heads={self.num_v_heads} must be divisible by num_heads={self.num_heads}."
|
| 88 |
+
)
|
| 89 |
+
|
| 90 |
+
if not math.isclose(head_dim * expand_v, self.head_v_dim, rel_tol=1e-5):
|
| 91 |
+
raise ValueError(
|
| 92 |
+
f"expand_v={expand_v} does not produce an integer value when multiplied by head_dim={head_dim}. "
|
| 93 |
+
f"Resulting head_v_dim would be {head_dim * expand_v}, which is invalid for FusedRMSNormGated."
|
| 94 |
+
)
|
| 95 |
+
assert mode in ["chunk", "fused_recurrent"], f"Not suppoerted mode `{mode}`."
|
| 96 |
+
|
| 97 |
+
self.q_proj = nn.Linear(hidden_size, self.key_dim, bias=False)
|
| 98 |
+
self.k_proj = nn.Linear(hidden_size, self.key_dim * num_householder, bias=False)
|
| 99 |
+
self.v_proj = nn.Linear(
|
| 100 |
+
hidden_size, self.value_dim * num_householder, bias=False
|
| 101 |
+
)
|
| 102 |
+
self.b_proj = nn.Linear(
|
| 103 |
+
hidden_size, self.num_v_heads * num_householder, bias=False
|
| 104 |
+
)
|
| 105 |
+
|
| 106 |
+
if self.use_forget_gate:
|
| 107 |
+
self.a_proj = nn.Linear(hidden_size, self.num_v_heads, bias=False)
|
| 108 |
+
A = torch.empty(self.num_v_heads, dtype=torch.float32).uniform_(0, 16)
|
| 109 |
+
self.A_log = nn.Parameter(torch.log(A))
|
| 110 |
+
self.A_log._no_weight_decay = True
|
| 111 |
+
# hard coded for now
|
| 112 |
+
dt_min = 0.001
|
| 113 |
+
dt_max = 0.1
|
| 114 |
+
dt_init_floor = 1e-4
|
| 115 |
+
dt = torch.exp(
|
| 116 |
+
torch.rand(self.num_v_heads) * (math.log(dt_max) - math.log(dt_min))
|
| 117 |
+
+ math.log(dt_min)
|
| 118 |
+
)
|
| 119 |
+
dt = torch.clamp(dt, min=dt_init_floor)
|
| 120 |
+
# Inverse of softplus: https://github.com/pytorch/pytorch/issues/72759
|
| 121 |
+
inv_dt = dt + torch.log(-torch.expm1(-dt))
|
| 122 |
+
self.dt_bias = nn.Parameter(inv_dt)
|
| 123 |
+
# Just to be explicit. Without this we already don't put wd on dt_bias because of the check
|
| 124 |
+
# name.endswith("bias") in param_grouping.py
|
| 125 |
+
self.dt_bias._no_weight_decay = True
|
| 126 |
+
|
| 127 |
+
if use_short_conv:
|
| 128 |
+
self.conv_size = conv_size
|
| 129 |
+
self.q_conv1d = ShortConvolution(
|
| 130 |
+
hidden_size=self.key_dim,
|
| 131 |
+
kernel_size=conv_size,
|
| 132 |
+
bias=conv_bias,
|
| 133 |
+
activation="silu",
|
| 134 |
+
)
|
| 135 |
+
self.k_conv1d = ShortConvolution(
|
| 136 |
+
hidden_size=self.key_dim * num_householder,
|
| 137 |
+
kernel_size=conv_size,
|
| 138 |
+
bias=conv_bias,
|
| 139 |
+
activation="silu",
|
| 140 |
+
)
|
| 141 |
+
self.v_conv1d = ShortConvolution(
|
| 142 |
+
hidden_size=self.value_dim * num_householder,
|
| 143 |
+
kernel_size=conv_size,
|
| 144 |
+
bias=conv_bias,
|
| 145 |
+
activation="silu",
|
| 146 |
+
)
|
| 147 |
+
else:
|
| 148 |
+
warnings.warn(
|
| 149 |
+
"ShortConvolution is crucial to the performance. "
|
| 150 |
+
"Do not turn it off, i.e., setting `use_short_conv=False` unless you know what you are doing."
|
| 151 |
+
)
|
| 152 |
+
if use_gate:
|
| 153 |
+
self.g_proj = nn.Linear(hidden_size, self.value_dim, bias=False)
|
| 154 |
+
self.o_norm = FusedRMSNormGated(self.head_v_dim, eps=norm_eps)
|
| 155 |
+
else:
|
| 156 |
+
self.o_norm = RMSNorm(self.head_v_dim, eps=norm_eps)
|
| 157 |
+
self.o_proj = nn.Linear(self.value_dim, hidden_size, bias=False)
|
| 158 |
+
|
| 159 |
+
def _initialize_weights(self, module: nn.Module):
|
| 160 |
+
if getattr(module, "_is_hf_initialized", False):
|
| 161 |
+
return
|
| 162 |
+
if isinstance(module, nn.Linear):
|
| 163 |
+
nn.init.xavier_uniform_(module.weight, gain=2**-2.5)
|
| 164 |
+
if module.bias is not None:
|
| 165 |
+
nn.init.zeros_(module.bias)
|
| 166 |
+
module._is_hf_initialized = True
|
| 167 |
+
|
| 168 |
+
def forward(
|
| 169 |
+
self,
|
| 170 |
+
hidden_states: torch.Tensor,
|
| 171 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 172 |
+
past_key_values: Optional[Cache] = None,
|
| 173 |
+
initial_state: Optional[torch.Tensor] = None,
|
| 174 |
+
use_cache: Optional[bool] = False,
|
| 175 |
+
output_attentions: Optional[bool] = False,
|
| 176 |
+
**kwargs: Unpack[Dict],
|
| 177 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Cache]]:
|
| 178 |
+
if attention_mask is not None:
|
| 179 |
+
assert len(attention_mask.shape) == 2, (
|
| 180 |
+
"Expected attention_mask as a 0-1 matrix with shape [batch_size, seq_len] "
|
| 181 |
+
"for padding purposes (0 indicating padding). "
|
| 182 |
+
"Arbitrary attention masks of shape [batch_size, seq_len, seq_len] are not allowed."
|
| 183 |
+
)
|
| 184 |
+
|
| 185 |
+
batch_size, q_len, _ = hidden_states.shape
|
| 186 |
+
# change to inference mode.
|
| 187 |
+
mode = self.mode
|
| 188 |
+
|
| 189 |
+
if self.training:
|
| 190 |
+
assert mode == "chunk", "Only chunk mode is supported in training."
|
| 191 |
+
|
| 192 |
+
last_state = None
|
| 193 |
+
if past_key_values is not None and len(past_key_values) > self.layer_idx:
|
| 194 |
+
last_state = past_key_values[self.layer_idx]
|
| 195 |
+
|
| 196 |
+
cu_seqlens = kwargs.get("cu_seqlens", None)
|
| 197 |
+
if attention_mask is not None:
|
| 198 |
+
indices, cu_seqlens, _ = get_unpad_data(attention_mask[:, -q_len:])
|
| 199 |
+
hidden_states = index_first_axis(
|
| 200 |
+
rearrange(hidden_states, "b s ... -> (b s) ..."), indices
|
| 201 |
+
).unsqueeze(0)
|
| 202 |
+
|
| 203 |
+
if self.use_short_conv:
|
| 204 |
+
conv_state_q, conv_state_k, conv_state_v = None, None, None
|
| 205 |
+
if last_state is not None:
|
| 206 |
+
conv_state_q, conv_state_k, conv_state_v = last_state["conv_state"]
|
| 207 |
+
q, conv_state_q = self.q_conv1d(
|
| 208 |
+
x=self.q_proj(hidden_states),
|
| 209 |
+
cache=conv_state_q,
|
| 210 |
+
output_final_state=use_cache,
|
| 211 |
+
cu_seqlens=cu_seqlens,
|
| 212 |
+
)
|
| 213 |
+
k, conv_state_k = self.k_conv1d(
|
| 214 |
+
x=self.k_proj(hidden_states),
|
| 215 |
+
cache=conv_state_k,
|
| 216 |
+
output_final_state=use_cache,
|
| 217 |
+
cu_seqlens=cu_seqlens,
|
| 218 |
+
)
|
| 219 |
+
v, conv_state_v = self.v_conv1d(
|
| 220 |
+
x=self.v_proj(hidden_states),
|
| 221 |
+
cache=conv_state_v,
|
| 222 |
+
output_final_state=use_cache,
|
| 223 |
+
cu_seqlens=cu_seqlens,
|
| 224 |
+
)
|
| 225 |
+
else:
|
| 226 |
+
q = F.silu(self.q_proj(hidden_states))
|
| 227 |
+
k = F.silu(self.k_proj(hidden_states))
|
| 228 |
+
v = F.silu(self.v_proj(hidden_states))
|
| 229 |
+
|
| 230 |
+
q = rearrange(q, "... (h d) -> ... h d", d=self.head_k_dim)
|
| 231 |
+
k = rearrange(
|
| 232 |
+
k,
|
| 233 |
+
"... l (n h d) -> ... (l n) h d",
|
| 234 |
+
n=self.num_householder,
|
| 235 |
+
d=self.head_k_dim,
|
| 236 |
+
)
|
| 237 |
+
v = rearrange(
|
| 238 |
+
v,
|
| 239 |
+
"... l (n h d) -> ... (l n) h d",
|
| 240 |
+
n=self.num_householder,
|
| 241 |
+
d=self.head_v_dim,
|
| 242 |
+
)
|
| 243 |
+
|
| 244 |
+
if self.num_v_heads > self.num_heads:
|
| 245 |
+
q, k = map(
|
| 246 |
+
lambda x: repeat(
|
| 247 |
+
x, "... h d -> ... (h g) d", g=self.num_v_heads // self.num_heads
|
| 248 |
+
),
|
| 249 |
+
(q, k),
|
| 250 |
+
)
|
| 251 |
+
|
| 252 |
+
beta = self.b_proj(hidden_states).sigmoid()
|
| 253 |
+
if self.allow_neg_eigval:
|
| 254 |
+
beta = beta * 2.0
|
| 255 |
+
|
| 256 |
+
beta = rearrange(beta, "... l (n h) -> ... (l n) h", n=self.num_householder)
|
| 257 |
+
if self.use_forget_gate:
|
| 258 |
+
g = -self.A_log.float().exp() * F.softplus(
|
| 259 |
+
self.a_proj(hidden_states).float() + self.dt_bias
|
| 260 |
+
)
|
| 261 |
+
else:
|
| 262 |
+
g = None
|
| 263 |
+
|
| 264 |
+
recurrent_state = (
|
| 265 |
+
last_state["recurrent_state"] if last_state is not None else None
|
| 266 |
+
)
|
| 267 |
+
if mode == "chunk":
|
| 268 |
+
o, recurrent_state = chunk_gated_delta_product(
|
| 269 |
+
q=q,
|
| 270 |
+
k=k,
|
| 271 |
+
v=v,
|
| 272 |
+
g=g,
|
| 273 |
+
beta=beta,
|
| 274 |
+
initial_state=initial_state,
|
| 275 |
+
output_final_state=output_attentions,
|
| 276 |
+
cu_seqlens=cu_seqlens,
|
| 277 |
+
num_householder=self.num_householder,
|
| 278 |
+
use_qk_l2norm_in_kernel=True,
|
| 279 |
+
)
|
| 280 |
+
|
| 281 |
+
elif mode == "fused_recurrent":
|
| 282 |
+
if self.use_forget_gate:
|
| 283 |
+
g_new = torch.zeros(
|
| 284 |
+
g.shape[0],
|
| 285 |
+
g.shape[1],
|
| 286 |
+
self.num_householder,
|
| 287 |
+
g.shape[2],
|
| 288 |
+
device=g.device,
|
| 289 |
+
dtype=torch.float32,
|
| 290 |
+
)
|
| 291 |
+
g_new[:, :, 0] = g
|
| 292 |
+
g = rearrange(g_new, "... l n h -> ... (l n) h")
|
| 293 |
+
|
| 294 |
+
q_new = q.new_zeros(
|
| 295 |
+
q.shape[0], q.shape[1], self.num_householder, q.shape[2], q.shape[3]
|
| 296 |
+
)
|
| 297 |
+
q_new[:, :, -1] = q
|
| 298 |
+
q = rearrange(q_new, "... l n h d-> ... (l n) h d")
|
| 299 |
+
if self.use_forget_gate:
|
| 300 |
+
o, recurrent_state = fused_recurrent_gated_delta_rule(
|
| 301 |
+
q=q,
|
| 302 |
+
k=k,
|
| 303 |
+
v=v,
|
| 304 |
+
g=g,
|
| 305 |
+
beta=beta,
|
| 306 |
+
initial_state=recurrent_state,
|
| 307 |
+
output_final_state=use_cache,
|
| 308 |
+
cu_seqlens=cu_seqlens * self.num_householder
|
| 309 |
+
if cu_seqlens is not None
|
| 310 |
+
else None,
|
| 311 |
+
use_qk_l2norm_in_kernel=True,
|
| 312 |
+
)
|
| 313 |
+
else:
|
| 314 |
+
o, recurrent_state = fused_recurrent_delta_rule(
|
| 315 |
+
q=q,
|
| 316 |
+
k=k,
|
| 317 |
+
v=v,
|
| 318 |
+
beta=beta,
|
| 319 |
+
initial_state=recurrent_state,
|
| 320 |
+
output_final_state=use_cache,
|
| 321 |
+
cu_seqlens=cu_seqlens * self.num_householder
|
| 322 |
+
if cu_seqlens is not None
|
| 323 |
+
else None,
|
| 324 |
+
use_qk_l2norm_in_kernel=True,
|
| 325 |
+
)
|
| 326 |
+
o = rearrange(o, "... (l n) h d -> ... l n h d", n=self.num_householder)[
|
| 327 |
+
..., -1, :, :
|
| 328 |
+
].contiguous()
|
| 329 |
+
|
| 330 |
+
if past_key_values is not None:
|
| 331 |
+
past_key_values.update(
|
| 332 |
+
recurrent_state=recurrent_state,
|
| 333 |
+
conv_state=(conv_state_q, conv_state_k, conv_state_v)
|
| 334 |
+
if self.use_short_conv
|
| 335 |
+
else None,
|
| 336 |
+
layer_idx=self.layer_idx,
|
| 337 |
+
offset=q_len,
|
| 338 |
+
)
|
| 339 |
+
|
| 340 |
+
if self.use_gate:
|
| 341 |
+
g = rearrange(
|
| 342 |
+
self.g_proj(hidden_states), "... (h d) -> ... h d", d=self.head_v_dim
|
| 343 |
+
)
|
| 344 |
+
o = self.o_norm(o, g)
|
| 345 |
+
else:
|
| 346 |
+
o = self.o_norm(o)
|
| 347 |
+
o = rearrange(o, "b t h d -> b t (h d)")
|
| 348 |
+
o = self.o_proj(o)
|
| 349 |
+
if attention_mask is not None:
|
| 350 |
+
o = pad_input(o.squeeze(0), indices, batch_size, q_len)
|
| 351 |
+
return o, recurrent_state, past_key_values
|
src/models/gated_deltaproduct/modeling_gated_deltaproduct.py
ADDED
|
@@ -0,0 +1,105 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
from __future__ import annotations
|
| 4 |
+
|
| 5 |
+
from typing import TYPE_CHECKING, Dict, List, Optional, Tuple, Union
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn as nn
|
| 9 |
+
from fla.layers.attn import Attention
|
| 10 |
+
from fla.models.utils import Cache
|
| 11 |
+
from fla.modules import GatedMLP as GatedDeltaProductMLP
|
| 12 |
+
from fla.modules import RMSNorm
|
| 13 |
+
|
| 14 |
+
from src.models.gated_deltaproduct.configuration_gated_deltaproduct import (
|
| 15 |
+
GatedDeltaProductConfig,
|
| 16 |
+
)
|
| 17 |
+
from src.models.gated_deltaproduct.gated_deltaproduct import GatedDeltaProduct
|
| 18 |
+
|
| 19 |
+
if TYPE_CHECKING:
|
| 20 |
+
from transformers.processing_utils import Unpack
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
class GatedDeltaProductBlock(nn.Module):
|
| 24 |
+
def __init__(self, config: GatedDeltaProductConfig, layer_idx: int):
|
| 25 |
+
super().__init__()
|
| 26 |
+
|
| 27 |
+
self.config = config
|
| 28 |
+
self.layer_idx = layer_idx
|
| 29 |
+
|
| 30 |
+
self.attn_norm = (RMSNorm if config.fuse_norm else nn.RMSNorm)(
|
| 31 |
+
config.hidden_size, eps=config.norm_eps
|
| 32 |
+
)
|
| 33 |
+
if config.attn is not None and layer_idx in config.attn["layers"]:
|
| 34 |
+
self.attn = Attention(
|
| 35 |
+
hidden_size=config.hidden_size,
|
| 36 |
+
num_heads=config.attn["num_heads"],
|
| 37 |
+
num_kv_heads=config.attn["num_kv_heads"],
|
| 38 |
+
qkv_bias=config.attn["qkv_bias"],
|
| 39 |
+
window_size=config.attn["window_size"],
|
| 40 |
+
rope_theta=config.attn["rope_theta"],
|
| 41 |
+
max_position_embeddings=config.max_position_embeddings,
|
| 42 |
+
layer_idx=layer_idx,
|
| 43 |
+
)
|
| 44 |
+
else:
|
| 45 |
+
self.attn = GatedDeltaProduct(
|
| 46 |
+
mode=config.attn_mode,
|
| 47 |
+
hidden_size=config.hidden_size,
|
| 48 |
+
expand_v=config.expand_v,
|
| 49 |
+
head_dim=config.head_dim,
|
| 50 |
+
num_heads=config.num_heads,
|
| 51 |
+
use_gate=config.use_gate,
|
| 52 |
+
use_forget_gate=config.use_forget_gate,
|
| 53 |
+
use_short_conv=config.use_short_conv,
|
| 54 |
+
conv_size=config.conv_size,
|
| 55 |
+
norm_eps=config.norm_eps,
|
| 56 |
+
allow_neg_eigval=config.allow_neg_eigval,
|
| 57 |
+
num_householder=config.num_householder,
|
| 58 |
+
layer_idx=layer_idx,
|
| 59 |
+
)
|
| 60 |
+
self.mlp_norm = (RMSNorm if config.fuse_norm else nn.RMSNorm)(
|
| 61 |
+
config.hidden_size, eps=config.norm_eps
|
| 62 |
+
)
|
| 63 |
+
self.mlp = GatedDeltaProductMLP(
|
| 64 |
+
hidden_size=config.hidden_size,
|
| 65 |
+
hidden_ratio=config.hidden_ratio,
|
| 66 |
+
intermediate_size=config.intermediate_size,
|
| 67 |
+
hidden_act=config.hidden_act,
|
| 68 |
+
fuse_swiglu=config.fuse_swiglu,
|
| 69 |
+
)
|
| 70 |
+
|
| 71 |
+
def forward(
|
| 72 |
+
self,
|
| 73 |
+
hidden_states: torch.Tensor,
|
| 74 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 75 |
+
past_key_values: Optional[Union[Cache, List[torch.FloatTensor]]] = None,
|
| 76 |
+
use_cache: Optional[bool] = False,
|
| 77 |
+
output_attentions: Optional[bool] = False,
|
| 78 |
+
initial_state: Optional[torch.FloatTensor] = None,
|
| 79 |
+
**kwargs: Unpack[Dict],
|
| 80 |
+
) -> Tuple[
|
| 81 |
+
torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]
|
| 82 |
+
]:
|
| 83 |
+
residual = hidden_states
|
| 84 |
+
hidden_states = self.attn_norm(hidden_states)
|
| 85 |
+
hidden_states, attentions, past_key_values = self.attn(
|
| 86 |
+
hidden_states=hidden_states,
|
| 87 |
+
attention_mask=attention_mask,
|
| 88 |
+
past_key_values=past_key_values,
|
| 89 |
+
use_cache=use_cache,
|
| 90 |
+
output_attentions=output_attentions,
|
| 91 |
+
initial_state=initial_state,
|
| 92 |
+
**kwargs,
|
| 93 |
+
)
|
| 94 |
+
if self.config.fuse_norm:
|
| 95 |
+
hidden_states, residual = self.mlp_norm(hidden_states, residual, True)
|
| 96 |
+
else:
|
| 97 |
+
hidden_states = residual + hidden_states
|
| 98 |
+
residual = hidden_states
|
| 99 |
+
hidden_states = self.mlp_norm(hidden_states)
|
| 100 |
+
hidden_states = self.mlp(hidden_states, **kwargs)
|
| 101 |
+
hidden_states = residual + hidden_states
|
| 102 |
+
|
| 103 |
+
outputs = (hidden_states, attentions, past_key_values)
|
| 104 |
+
|
| 105 |
+
return outputs
|
src/models/model.py
ADDED
|
@@ -0,0 +1,427 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
from fla.modules import GatedMLP
|
| 4 |
+
|
| 5 |
+
from src.data.containers import BatchTimeSeriesContainer
|
| 6 |
+
from src.data.scalers import MinMaxScaler, RobustScaler
|
| 7 |
+
from src.data.time_features import compute_batch_time_features
|
| 8 |
+
from src.models.blocks import GatedDeltaProductEncoder
|
| 9 |
+
from src.utils.utils import device
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def create_scaler(scaler_type: str, epsilon: float = 1e-3):
|
| 13 |
+
"""Create scaler instance based on type."""
|
| 14 |
+
if scaler_type == "custom_robust":
|
| 15 |
+
return RobustScaler(epsilon=epsilon)
|
| 16 |
+
elif scaler_type == "min_max":
|
| 17 |
+
return MinMaxScaler(epsilon=epsilon)
|
| 18 |
+
else:
|
| 19 |
+
raise ValueError(f"Unknown scaler: {scaler_type}")
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def apply_channel_noise(values: torch.Tensor, noise_scale: float = 0.1):
|
| 23 |
+
"""Add noise to constant channels to prevent model instability."""
|
| 24 |
+
is_constant = torch.all(values == values[:, 0:1, :], dim=1)
|
| 25 |
+
noise = torch.randn_like(values) * noise_scale * is_constant.unsqueeze(1)
|
| 26 |
+
return values + noise
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
class TimeSeriesModel(nn.Module):
|
| 30 |
+
"""Time series forecasting model combining embedding, encoding, and prediction."""
|
| 31 |
+
|
| 32 |
+
def __init__(
|
| 33 |
+
self,
|
| 34 |
+
# Core architecture
|
| 35 |
+
embed_size: int = 128,
|
| 36 |
+
num_encoder_layers: int = 2,
|
| 37 |
+
# Scaling and preprocessing
|
| 38 |
+
scaler: str = "custom_robust",
|
| 39 |
+
epsilon: float = 1e-3,
|
| 40 |
+
scaler_clamp_value: float = None,
|
| 41 |
+
handle_constants: bool = False,
|
| 42 |
+
# Time features
|
| 43 |
+
K_max: int = 6,
|
| 44 |
+
time_feature_config: dict = None,
|
| 45 |
+
encoding_dropout: float = 0.0,
|
| 46 |
+
# Encoder configuration
|
| 47 |
+
encoder_config: dict = None,
|
| 48 |
+
# Loss configuration
|
| 49 |
+
loss_type: str = "huber", # "huber", "quantile"
|
| 50 |
+
quantiles: list[float] = None,
|
| 51 |
+
**kwargs,
|
| 52 |
+
):
|
| 53 |
+
super().__init__()
|
| 54 |
+
|
| 55 |
+
# Core parameters
|
| 56 |
+
self.embed_size = embed_size
|
| 57 |
+
self.num_encoder_layers = num_encoder_layers
|
| 58 |
+
self.epsilon = epsilon
|
| 59 |
+
self.scaler_clamp_value = scaler_clamp_value
|
| 60 |
+
self.handle_constants = handle_constants
|
| 61 |
+
self.encoding_dropout = encoding_dropout
|
| 62 |
+
self.K_max = K_max
|
| 63 |
+
self.time_feature_config = time_feature_config or {}
|
| 64 |
+
self.encoder_config = encoder_config or {}
|
| 65 |
+
|
| 66 |
+
# Store loss parameters
|
| 67 |
+
self.loss_type = loss_type
|
| 68 |
+
self.quantiles = quantiles
|
| 69 |
+
if self.loss_type == "quantile" and self.quantiles is None:
|
| 70 |
+
raise ValueError("Quantiles must be provided for quantile loss.")
|
| 71 |
+
if self.quantiles:
|
| 72 |
+
self.register_buffer(
|
| 73 |
+
"qt", torch.tensor(self.quantiles, device=device).view(1, 1, 1, -1)
|
| 74 |
+
)
|
| 75 |
+
|
| 76 |
+
# Validate configuration before initialization
|
| 77 |
+
self._validate_configuration()
|
| 78 |
+
|
| 79 |
+
# Initialize components
|
| 80 |
+
self.scaler = create_scaler(scaler, epsilon)
|
| 81 |
+
self._init_embedding_layers()
|
| 82 |
+
self._init_encoder_layers(self.encoder_config, num_encoder_layers)
|
| 83 |
+
self._init_projection_layers()
|
| 84 |
+
|
| 85 |
+
def _validate_configuration(self):
|
| 86 |
+
"""Validate essential model configuration parameters."""
|
| 87 |
+
if "num_heads" not in self.encoder_config:
|
| 88 |
+
raise ValueError("encoder_config must contain 'num_heads' parameter")
|
| 89 |
+
|
| 90 |
+
if self.embed_size % self.encoder_config["num_heads"] != 0:
|
| 91 |
+
raise ValueError(
|
| 92 |
+
f"embed_size ({self.embed_size}) must be divisible by "
|
| 93 |
+
f"num_heads ({self.encoder_config['num_heads']})"
|
| 94 |
+
)
|
| 95 |
+
|
| 96 |
+
def _init_embedding_layers(self):
|
| 97 |
+
"""Initialize value and time feature embedding layers."""
|
| 98 |
+
self.expand_values = nn.Linear(1, self.embed_size, bias=True)
|
| 99 |
+
self.nan_embedding = nn.Parameter(
|
| 100 |
+
torch.randn(1, 1, 1, self.embed_size) / self.embed_size,
|
| 101 |
+
requires_grad=True,
|
| 102 |
+
)
|
| 103 |
+
self.time_feature_projection = nn.Linear(self.K_max, self.embed_size)
|
| 104 |
+
|
| 105 |
+
def _init_encoder_layers(self, encoder_config: dict, num_encoder_layers: int):
|
| 106 |
+
"""Initialize encoder layers."""
|
| 107 |
+
self.num_encoder_layers = num_encoder_layers
|
| 108 |
+
|
| 109 |
+
# Ensure encoder_config has token_embed_dim
|
| 110 |
+
encoder_config = encoder_config.copy()
|
| 111 |
+
encoder_config["token_embed_dim"] = self.embed_size
|
| 112 |
+
self.encoder_layers = nn.ModuleList(
|
| 113 |
+
[
|
| 114 |
+
GatedDeltaProductEncoder(layer_idx=layer_idx, **encoder_config)
|
| 115 |
+
for layer_idx in range(self.num_encoder_layers)
|
| 116 |
+
]
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
def _init_projection_layers(self):
|
| 120 |
+
if self.loss_type == "quantile":
|
| 121 |
+
output_dim = len(self.quantiles)
|
| 122 |
+
else:
|
| 123 |
+
output_dim = 1
|
| 124 |
+
self.final_output_layer = nn.Linear(self.embed_size, output_dim)
|
| 125 |
+
|
| 126 |
+
self.mlp = GatedMLP(
|
| 127 |
+
hidden_size=self.embed_size,
|
| 128 |
+
hidden_ratio=4,
|
| 129 |
+
hidden_act="swish",
|
| 130 |
+
fuse_swiglu=True,
|
| 131 |
+
)
|
| 132 |
+
# Initialize learnable initial hidden state for the first encoder layer
|
| 133 |
+
# This will be expanded to match batch size during forward pass
|
| 134 |
+
head_k_dim = self.embed_size // self.encoder_config["num_heads"]
|
| 135 |
+
|
| 136 |
+
# Get expand_v from encoder_config, default to 1.0 if not present
|
| 137 |
+
expand_v = self.encoder_config.get("expand_v", 1.0)
|
| 138 |
+
head_v_dim = int(head_k_dim * expand_v)
|
| 139 |
+
|
| 140 |
+
num_initial_hidden_states = self.num_encoder_layers
|
| 141 |
+
self.initial_hidden_state = nn.ParameterList(
|
| 142 |
+
[
|
| 143 |
+
nn.Parameter(
|
| 144 |
+
torch.randn(
|
| 145 |
+
1, self.encoder_config["num_heads"], head_k_dim, head_v_dim
|
| 146 |
+
)
|
| 147 |
+
/ head_k_dim,
|
| 148 |
+
requires_grad=True,
|
| 149 |
+
)
|
| 150 |
+
for _ in range(num_initial_hidden_states)
|
| 151 |
+
]
|
| 152 |
+
)
|
| 153 |
+
|
| 154 |
+
def _preprocess_data(self, data_container: BatchTimeSeriesContainer):
|
| 155 |
+
"""Extract data shapes and handle constants without padding."""
|
| 156 |
+
history_values = data_container.history_values
|
| 157 |
+
future_values = data_container.future_values
|
| 158 |
+
history_mask = data_container.history_mask
|
| 159 |
+
|
| 160 |
+
batch_size, history_length, num_channels = history_values.shape
|
| 161 |
+
future_length = future_values.shape[1] if future_values is not None else 0
|
| 162 |
+
|
| 163 |
+
# Handle constants
|
| 164 |
+
if self.handle_constants:
|
| 165 |
+
history_values = apply_channel_noise(history_values)
|
| 166 |
+
|
| 167 |
+
return {
|
| 168 |
+
"history_values": history_values,
|
| 169 |
+
"future_values": future_values,
|
| 170 |
+
"history_mask": history_mask,
|
| 171 |
+
"num_channels": num_channels,
|
| 172 |
+
"history_length": history_length,
|
| 173 |
+
"future_length": future_length,
|
| 174 |
+
"batch_size": batch_size,
|
| 175 |
+
}
|
| 176 |
+
|
| 177 |
+
def _compute_scaling(
|
| 178 |
+
self, history_values: torch.Tensor, history_mask: torch.Tensor = None
|
| 179 |
+
):
|
| 180 |
+
"""Compute scaling statistics and apply scaling."""
|
| 181 |
+
scale_statistics = self.scaler.compute_statistics(history_values, history_mask)
|
| 182 |
+
return scale_statistics
|
| 183 |
+
|
| 184 |
+
def _apply_scaling_and_masking(
|
| 185 |
+
self, values: torch.Tensor, scale_statistics: dict, mask: torch.Tensor = None
|
| 186 |
+
):
|
| 187 |
+
"""Apply scaling and optional masking to values."""
|
| 188 |
+
scaled_values = self.scaler.scale(values, scale_statistics)
|
| 189 |
+
|
| 190 |
+
if mask is not None:
|
| 191 |
+
scaled_values = scaled_values * mask.unsqueeze(-1).float()
|
| 192 |
+
|
| 193 |
+
if self.scaler_clamp_value is not None:
|
| 194 |
+
scaled_values = torch.clamp(
|
| 195 |
+
scaled_values, -self.scaler_clamp_value, self.scaler_clamp_value
|
| 196 |
+
)
|
| 197 |
+
|
| 198 |
+
return scaled_values
|
| 199 |
+
|
| 200 |
+
def _get_positional_embeddings(
|
| 201 |
+
self,
|
| 202 |
+
time_features: torch.Tensor,
|
| 203 |
+
num_channels: int,
|
| 204 |
+
batch_size: int,
|
| 205 |
+
drop_enc_allow: bool = False,
|
| 206 |
+
):
|
| 207 |
+
"""Generate positional embeddings from time features."""
|
| 208 |
+
seq_len = time_features.shape[1]
|
| 209 |
+
|
| 210 |
+
if (torch.rand(1).item() < self.encoding_dropout) and drop_enc_allow:
|
| 211 |
+
return torch.zeros(
|
| 212 |
+
batch_size, seq_len, num_channels, self.embed_size, device=device
|
| 213 |
+
).to(torch.float32)
|
| 214 |
+
|
| 215 |
+
pos_embed = self.time_feature_projection(time_features)
|
| 216 |
+
return pos_embed.unsqueeze(2).expand(-1, -1, num_channels, -1)
|
| 217 |
+
|
| 218 |
+
def _compute_embeddings(
|
| 219 |
+
self,
|
| 220 |
+
scaled_history: torch.Tensor,
|
| 221 |
+
history_pos_embed: torch.Tensor,
|
| 222 |
+
history_mask: torch.Tensor | None = None,
|
| 223 |
+
):
|
| 224 |
+
"""Compute value embeddings and combine with positional embeddings."""
|
| 225 |
+
|
| 226 |
+
nan_mask = torch.isnan(scaled_history)
|
| 227 |
+
history_for_embedding = torch.nan_to_num(scaled_history, nan=0.0)
|
| 228 |
+
channel_embeddings = self.expand_values(history_for_embedding.unsqueeze(-1))
|
| 229 |
+
channel_embeddings[nan_mask] = self.nan_embedding.to(channel_embeddings.dtype)
|
| 230 |
+
channel_embeddings = channel_embeddings + history_pos_embed
|
| 231 |
+
|
| 232 |
+
# Suppress padded time steps completely so padding is a pure batching artifact
|
| 233 |
+
# history_mask: [B, S] -> broadcast to [B, S, 1, 1]
|
| 234 |
+
if history_mask is not None:
|
| 235 |
+
mask_broadcast = (
|
| 236 |
+
history_mask.unsqueeze(-1).unsqueeze(-1).to(channel_embeddings.dtype)
|
| 237 |
+
)
|
| 238 |
+
channel_embeddings = channel_embeddings * mask_broadcast
|
| 239 |
+
|
| 240 |
+
batch_size, seq_len = scaled_history.shape[:2]
|
| 241 |
+
all_channels_embedded = channel_embeddings.view(batch_size, seq_len, -1)
|
| 242 |
+
|
| 243 |
+
return all_channels_embedded
|
| 244 |
+
|
| 245 |
+
def _generate_predictions(
|
| 246 |
+
self,
|
| 247 |
+
embedded: torch.Tensor,
|
| 248 |
+
target_pos_embed: torch.Tensor,
|
| 249 |
+
prediction_length: int,
|
| 250 |
+
num_channels: int,
|
| 251 |
+
history_mask: torch.Tensor = None,
|
| 252 |
+
):
|
| 253 |
+
"""
|
| 254 |
+
Generate predictions for all channels using vectorized operations.
|
| 255 |
+
"""
|
| 256 |
+
batch_size, seq_len, _ = embedded.shape
|
| 257 |
+
# embedded shape: [B, S, N*E] -> Reshape to [B, S, N, E]
|
| 258 |
+
embedded = embedded.view(batch_size, seq_len, num_channels, self.embed_size)
|
| 259 |
+
|
| 260 |
+
# Vectorize across channels by merging the batch and channel dimensions.
|
| 261 |
+
# [B, S, N, E] -> [B*N, S, E]
|
| 262 |
+
channel_embedded = (
|
| 263 |
+
embedded.permute(0, 2, 1, 3)
|
| 264 |
+
.contiguous()
|
| 265 |
+
.view(batch_size * num_channels, seq_len, self.embed_size)
|
| 266 |
+
)
|
| 267 |
+
|
| 268 |
+
# Reshape target positional embeddings similarly: [B, P, N, E] -> [B*N, P, E]
|
| 269 |
+
target_pos_embed = (
|
| 270 |
+
target_pos_embed.permute(0, 2, 1, 3)
|
| 271 |
+
.contiguous()
|
| 272 |
+
.view(batch_size * num_channels, prediction_length, self.embed_size)
|
| 273 |
+
)
|
| 274 |
+
x = channel_embedded
|
| 275 |
+
target_repr = target_pos_embed
|
| 276 |
+
x = torch.concatenate([x, target_repr], dim=1)
|
| 277 |
+
if self.encoder_config.get("weaving", True):
|
| 278 |
+
# initial hidden state is learnable
|
| 279 |
+
hidden_state = torch.zeros_like(
|
| 280 |
+
self.initial_hidden_state[0].repeat(batch_size * num_channels, 1, 1, 1)
|
| 281 |
+
)
|
| 282 |
+
for layer_idx, encoder_layer in enumerate(self.encoder_layers):
|
| 283 |
+
x, hidden_state = encoder_layer(
|
| 284 |
+
x,
|
| 285 |
+
hidden_state
|
| 286 |
+
+ self.initial_hidden_state[layer_idx].repeat(
|
| 287 |
+
batch_size * num_channels, 1, 1, 1
|
| 288 |
+
),
|
| 289 |
+
)
|
| 290 |
+
else:
|
| 291 |
+
# initial hidden state is separately learnable for each layer
|
| 292 |
+
for layer_idx, encoder_layer in enumerate(self.encoder_layers):
|
| 293 |
+
initial_hidden_state = self.initial_hidden_state[layer_idx].repeat(
|
| 294 |
+
batch_size * num_channels, 1, 1, 1
|
| 295 |
+
)
|
| 296 |
+
x, _ = encoder_layer(x, initial_hidden_state)
|
| 297 |
+
|
| 298 |
+
# Use the last prediction_length positions
|
| 299 |
+
prediction_embeddings = x[:, -prediction_length:, :]
|
| 300 |
+
|
| 301 |
+
predictions = self.final_output_layer(self.mlp(prediction_embeddings))
|
| 302 |
+
|
| 303 |
+
# Reshape output to handle quantiles
|
| 304 |
+
# Original shape: [B*N, P, Q] where Q is num_quantiles or 1
|
| 305 |
+
# Reshape the output back to [B, P, N, Q]
|
| 306 |
+
output_dim = len(self.quantiles) if self.loss_type == "quantile" else 1
|
| 307 |
+
predictions = predictions.view(
|
| 308 |
+
batch_size, num_channels, prediction_length, output_dim
|
| 309 |
+
)
|
| 310 |
+
predictions = predictions.permute(0, 2, 1, 3) # [B, P, N, Q]
|
| 311 |
+
# Squeeze the last dimension if not in quantile mode for backward compatibility
|
| 312 |
+
if self.loss_type != "quantile":
|
| 313 |
+
predictions = predictions.squeeze(-1) # [B, P, N]
|
| 314 |
+
return predictions
|
| 315 |
+
|
| 316 |
+
def forward(
|
| 317 |
+
self, data_container: BatchTimeSeriesContainer, drop_enc_allow: bool = False
|
| 318 |
+
):
|
| 319 |
+
"""Main forward pass."""
|
| 320 |
+
# Preprocess data
|
| 321 |
+
preprocessed = self._preprocess_data(data_container)
|
| 322 |
+
|
| 323 |
+
# Compute time features dynamically based on actual lengths
|
| 324 |
+
history_time_features, target_time_features = compute_batch_time_features(
|
| 325 |
+
start=data_container.start,
|
| 326 |
+
history_length=preprocessed["history_length"],
|
| 327 |
+
future_length=preprocessed["future_length"],
|
| 328 |
+
batch_size=preprocessed["batch_size"],
|
| 329 |
+
frequency=data_container.frequency,
|
| 330 |
+
K_max=self.K_max,
|
| 331 |
+
time_feature_config=self.time_feature_config,
|
| 332 |
+
)
|
| 333 |
+
|
| 334 |
+
# Compute scaling
|
| 335 |
+
scale_statistics = self._compute_scaling(
|
| 336 |
+
preprocessed["history_values"], preprocessed["history_mask"]
|
| 337 |
+
)
|
| 338 |
+
|
| 339 |
+
# Apply scaling
|
| 340 |
+
history_scaled = self._apply_scaling_and_masking(
|
| 341 |
+
preprocessed["history_values"],
|
| 342 |
+
scale_statistics,
|
| 343 |
+
preprocessed["history_mask"],
|
| 344 |
+
)
|
| 345 |
+
|
| 346 |
+
# Scale future values if present
|
| 347 |
+
future_scaled = None
|
| 348 |
+
if preprocessed["future_values"] is not None:
|
| 349 |
+
future_scaled = self.scaler.scale(
|
| 350 |
+
preprocessed["future_values"], scale_statistics
|
| 351 |
+
)
|
| 352 |
+
|
| 353 |
+
# Get positional embeddings
|
| 354 |
+
history_pos_embed = self._get_positional_embeddings(
|
| 355 |
+
history_time_features,
|
| 356 |
+
preprocessed["num_channels"],
|
| 357 |
+
preprocessed["batch_size"],
|
| 358 |
+
drop_enc_allow,
|
| 359 |
+
)
|
| 360 |
+
target_pos_embed = self._get_positional_embeddings(
|
| 361 |
+
target_time_features,
|
| 362 |
+
preprocessed["num_channels"],
|
| 363 |
+
preprocessed["batch_size"],
|
| 364 |
+
drop_enc_allow,
|
| 365 |
+
)
|
| 366 |
+
|
| 367 |
+
# Compute embeddings
|
| 368 |
+
history_embed = self._compute_embeddings(
|
| 369 |
+
history_scaled, history_pos_embed, preprocessed["history_mask"]
|
| 370 |
+
)
|
| 371 |
+
|
| 372 |
+
# Generate predictions
|
| 373 |
+
predictions = self._generate_predictions(
|
| 374 |
+
history_embed,
|
| 375 |
+
target_pos_embed,
|
| 376 |
+
preprocessed["future_length"],
|
| 377 |
+
preprocessed["num_channels"],
|
| 378 |
+
preprocessed["history_mask"],
|
| 379 |
+
)
|
| 380 |
+
|
| 381 |
+
return {
|
| 382 |
+
"result": predictions,
|
| 383 |
+
"scale_statistics": scale_statistics,
|
| 384 |
+
"future_scaled": future_scaled,
|
| 385 |
+
"history_length": preprocessed["history_length"],
|
| 386 |
+
"future_length": preprocessed["future_length"],
|
| 387 |
+
}
|
| 388 |
+
|
| 389 |
+
def _quantile_loss(self, y_true: torch.Tensor, y_pred: torch.Tensor):
|
| 390 |
+
"""
|
| 391 |
+
Compute the quantile loss.
|
| 392 |
+
y_true: [B, P, N]
|
| 393 |
+
y_pred: [B, P, N, Q]
|
| 394 |
+
"""
|
| 395 |
+
# Add a dimension to y_true to match y_pred: [B, P, N] -> [B, P, N, 1]
|
| 396 |
+
y_true = y_true.unsqueeze(-1)
|
| 397 |
+
|
| 398 |
+
# Calculate errors
|
| 399 |
+
errors = y_true - y_pred
|
| 400 |
+
|
| 401 |
+
# Calculate quantile loss
|
| 402 |
+
# The max operator implements the two cases of the quantile loss formula
|
| 403 |
+
loss = torch.max((self.qt - 1) * errors, self.qt * errors)
|
| 404 |
+
|
| 405 |
+
# Average the loss across all dimensions
|
| 406 |
+
return loss.mean()
|
| 407 |
+
|
| 408 |
+
def compute_loss(self, y_true: torch.Tensor, y_pred: dict):
|
| 409 |
+
"""Compute loss between predictions and scaled ground truth."""
|
| 410 |
+
predictions = y_pred["result"]
|
| 411 |
+
scale_statistics = y_pred["scale_statistics"]
|
| 412 |
+
|
| 413 |
+
if y_true is None:
|
| 414 |
+
return torch.tensor(0.0, device=predictions.device)
|
| 415 |
+
|
| 416 |
+
future_scaled = self.scaler.scale(y_true, scale_statistics)
|
| 417 |
+
|
| 418 |
+
if self.loss_type == "huber":
|
| 419 |
+
if predictions.shape != future_scaled.shape:
|
| 420 |
+
raise ValueError(
|
| 421 |
+
f"Shape mismatch for Huber loss: predictions {predictions.shape} vs future_scaled {future_scaled.shape}"
|
| 422 |
+
)
|
| 423 |
+
return nn.functional.huber_loss(predictions, future_scaled)
|
| 424 |
+
elif self.loss_type == "quantile":
|
| 425 |
+
return self._quantile_loss(future_scaled, predictions)
|
| 426 |
+
else:
|
| 427 |
+
raise ValueError(f"Unknown loss type: {self.loss_type}")
|
src/optim/lr_scheduler.py
ADDED
|
@@ -0,0 +1,360 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# src/utils/lr_scheduler.py
|
| 2 |
+
|
| 3 |
+
import math
|
| 4 |
+
from enum import Enum
|
| 5 |
+
from functools import partial
|
| 6 |
+
from typing import Optional
|
| 7 |
+
|
| 8 |
+
from torch.optim import Optimizer
|
| 9 |
+
from torch.optim.lr_scheduler import LambdaLR
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class SchedulerType(Enum):
|
| 13 |
+
"""Enumeration of available learning rate schedulers."""
|
| 14 |
+
|
| 15 |
+
COSINE = "cosine"
|
| 16 |
+
COSINE_WITH_WARMUP = "cosine_with_warmup"
|
| 17 |
+
COSINE_WITH_RESTARTS = "cosine_with_restarts"
|
| 18 |
+
WARMUP_STABLE_DECAY = "warmup_stable_decay"
|
| 19 |
+
POLYNOMIAL_WITH_WARMUP = "polynomial_with_warmup"
|
| 20 |
+
LINEAR_WITH_WARMUP = "linear_with_warmup"
|
| 21 |
+
CONSTANT_WITH_WARMUP = "constant_with_warmup"
|
| 22 |
+
INVERSE_SQRT = "inverse_sqrt"
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def _get_warmup_stable_decay_lr_lambda(
|
| 26 |
+
current_step: int,
|
| 27 |
+
*,
|
| 28 |
+
num_warmup_steps: int,
|
| 29 |
+
num_stable_steps: int,
|
| 30 |
+
num_training_steps: int,
|
| 31 |
+
min_lr_ratio: float = 0.001,
|
| 32 |
+
decay_type: str = "cosine",
|
| 33 |
+
):
|
| 34 |
+
"""
|
| 35 |
+
Learning rate lambda function for Warmup-Stable-Decay (WSD) schedule.
|
| 36 |
+
|
| 37 |
+
This scheduler implements three phases:
|
| 38 |
+
1. Warmup: Linear increase from 0 to peak learning rate
|
| 39 |
+
2. Stable: Constant learning rate for majority of training
|
| 40 |
+
3. Decay: Gradual decrease using cosine or linear decay
|
| 41 |
+
|
| 42 |
+
Args:
|
| 43 |
+
current_step: Current training step
|
| 44 |
+
num_warmup_steps: Number of warmup steps
|
| 45 |
+
num_stable_steps: Number of stable learning rate steps
|
| 46 |
+
num_training_steps: Total number of training steps
|
| 47 |
+
min_lr_ratio: Minimum learning rate as ratio of peak learning rate
|
| 48 |
+
decay_type: Type of decay schedule ("cosine" or "linear")
|
| 49 |
+
"""
|
| 50 |
+
if current_step < num_warmup_steps:
|
| 51 |
+
# Warmup phase: linear increase
|
| 52 |
+
return float(current_step) / float(max(1, num_warmup_steps))
|
| 53 |
+
|
| 54 |
+
elif current_step < num_warmup_steps + num_stable_steps:
|
| 55 |
+
# Stable phase: constant learning rate
|
| 56 |
+
return 1.0
|
| 57 |
+
|
| 58 |
+
else:
|
| 59 |
+
# Decay phase
|
| 60 |
+
decay_steps = num_training_steps - num_warmup_steps - num_stable_steps
|
| 61 |
+
if decay_steps <= 0:
|
| 62 |
+
return max(min_lr_ratio, 1.0)
|
| 63 |
+
|
| 64 |
+
progress = (current_step - num_warmup_steps - num_stable_steps) / decay_steps
|
| 65 |
+
progress = min(progress, 1.0) # Clamp to [0, 1]
|
| 66 |
+
|
| 67 |
+
if decay_type == "cosine":
|
| 68 |
+
# Cosine decay
|
| 69 |
+
decay_factor = 0.5 * (1.0 + math.cos(math.pi * progress))
|
| 70 |
+
return max(min_lr_ratio, decay_factor)
|
| 71 |
+
elif decay_type == "linear":
|
| 72 |
+
# Linear decay
|
| 73 |
+
decay_factor = 1.0 - progress
|
| 74 |
+
return max(min_lr_ratio, decay_factor)
|
| 75 |
+
else:
|
| 76 |
+
raise ValueError(f"Unknown decay_type: {decay_type}")
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
def get_warmup_stable_decay_schedule(
|
| 80 |
+
optimizer: Optimizer,
|
| 81 |
+
num_warmup_steps: int,
|
| 82 |
+
num_stable_steps: int,
|
| 83 |
+
num_training_steps: int,
|
| 84 |
+
min_lr_ratio: float = 0.01,
|
| 85 |
+
decay_type: str = "cosine",
|
| 86 |
+
last_epoch: int = -1,
|
| 87 |
+
):
|
| 88 |
+
"""
|
| 89 |
+
Create a Warmup-Stable-Decay learning rate schedule.
|
| 90 |
+
|
| 91 |
+
This scheduler is particularly well-suited for foundation model training as it:
|
| 92 |
+
- Provides stable learning during the majority of training
|
| 93 |
+
- Doesn't require pre-committing to exact training duration
|
| 94 |
+
- Allows for extended training without aggressive decay
|
| 95 |
+
|
| 96 |
+
Args:
|
| 97 |
+
optimizer: The optimizer for which to schedule the learning rate
|
| 98 |
+
num_warmup_steps: Number of steps for warmup phase
|
| 99 |
+
num_stable_steps: Number of steps for stable learning rate phase
|
| 100 |
+
num_training_steps: Total number of training steps
|
| 101 |
+
min_lr_ratio: Minimum learning rate as fraction of peak learning rate
|
| 102 |
+
decay_type: Type of decay ("cosine" or "linear")
|
| 103 |
+
last_epoch: The index of the last epoch when resuming training
|
| 104 |
+
|
| 105 |
+
Returns:
|
| 106 |
+
torch.optim.lr_scheduler.LambdaLR with the WSD schedule
|
| 107 |
+
"""
|
| 108 |
+
lr_lambda = partial(
|
| 109 |
+
_get_warmup_stable_decay_lr_lambda,
|
| 110 |
+
num_warmup_steps=num_warmup_steps,
|
| 111 |
+
num_stable_steps=num_stable_steps,
|
| 112 |
+
num_training_steps=num_training_steps,
|
| 113 |
+
min_lr_ratio=min_lr_ratio,
|
| 114 |
+
decay_type=decay_type,
|
| 115 |
+
)
|
| 116 |
+
return LambdaLR(optimizer, lr_lambda, last_epoch=last_epoch)
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
def _get_cosine_schedule_with_warmup_lr_lambda(
|
| 120 |
+
current_step: int,
|
| 121 |
+
*,
|
| 122 |
+
num_warmup_steps: int,
|
| 123 |
+
num_training_steps: int,
|
| 124 |
+
num_cycles: float = 0.5,
|
| 125 |
+
min_lr_ratio: float = 0.0,
|
| 126 |
+
):
|
| 127 |
+
"""Enhanced cosine schedule with configurable minimum learning rate."""
|
| 128 |
+
if current_step < num_warmup_steps:
|
| 129 |
+
return float(current_step) / float(max(1, num_warmup_steps))
|
| 130 |
+
|
| 131 |
+
progress = float(current_step - num_warmup_steps) / float(
|
| 132 |
+
max(1, num_training_steps - num_warmup_steps)
|
| 133 |
+
)
|
| 134 |
+
cosine_factor = 0.5 * (1.0 + math.cos(math.pi * float(num_cycles) * 2.0 * progress))
|
| 135 |
+
return max(min_lr_ratio, cosine_factor)
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
def get_enhanced_cosine_schedule_with_warmup(
|
| 139 |
+
optimizer: Optimizer,
|
| 140 |
+
num_warmup_steps: int,
|
| 141 |
+
num_training_steps: int,
|
| 142 |
+
num_cycles: float = 0.5,
|
| 143 |
+
min_lr_ratio: float = 0.01,
|
| 144 |
+
last_epoch: int = -1,
|
| 145 |
+
):
|
| 146 |
+
"""
|
| 147 |
+
Enhanced cosine schedule with warmup and configurable minimum learning rate.
|
| 148 |
+
|
| 149 |
+
Args:
|
| 150 |
+
optimizer: The optimizer for which to schedule the learning rate
|
| 151 |
+
num_warmup_steps: Number of steps for warmup phase
|
| 152 |
+
num_training_steps: Total number of training steps
|
| 153 |
+
num_cycles: Number of cosine cycles (0.5 = half cosine)
|
| 154 |
+
min_lr_ratio: Minimum learning rate as fraction of peak learning rate
|
| 155 |
+
last_epoch: The index of the last epoch when resuming training
|
| 156 |
+
"""
|
| 157 |
+
lr_lambda = partial(
|
| 158 |
+
_get_cosine_schedule_with_warmup_lr_lambda,
|
| 159 |
+
num_warmup_steps=num_warmup_steps,
|
| 160 |
+
num_training_steps=num_training_steps,
|
| 161 |
+
num_cycles=num_cycles,
|
| 162 |
+
min_lr_ratio=min_lr_ratio,
|
| 163 |
+
)
|
| 164 |
+
return LambdaLR(optimizer, lr_lambda, last_epoch=last_epoch)
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
def _get_cosine_with_restarts_lr_lambda(
|
| 168 |
+
current_step: int,
|
| 169 |
+
*,
|
| 170 |
+
num_warmup_steps: int,
|
| 171 |
+
num_training_steps: int,
|
| 172 |
+
num_cycles: int = 1,
|
| 173 |
+
min_lr_ratio: float = 0.0,
|
| 174 |
+
):
|
| 175 |
+
"""Cosine schedule with hard restarts and configurable minimum learning rate."""
|
| 176 |
+
if current_step < num_warmup_steps:
|
| 177 |
+
return float(current_step) / float(max(1, num_warmup_steps))
|
| 178 |
+
|
| 179 |
+
progress = float(current_step - num_warmup_steps) / float(
|
| 180 |
+
max(1, num_training_steps - num_warmup_steps)
|
| 181 |
+
)
|
| 182 |
+
if progress >= 1.0:
|
| 183 |
+
return min_lr_ratio
|
| 184 |
+
|
| 185 |
+
cosine_factor = 0.5 * (
|
| 186 |
+
1.0 + math.cos(math.pi * ((float(num_cycles) * progress) % 1.0))
|
| 187 |
+
)
|
| 188 |
+
return max(min_lr_ratio, cosine_factor)
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
def get_cosine_with_restarts_schedule(
|
| 192 |
+
optimizer: Optimizer,
|
| 193 |
+
num_warmup_steps: int,
|
| 194 |
+
num_training_steps: int,
|
| 195 |
+
num_cycles: int = 4,
|
| 196 |
+
min_lr_ratio: float = 0.01,
|
| 197 |
+
last_epoch: int = -1,
|
| 198 |
+
):
|
| 199 |
+
"""
|
| 200 |
+
Cosine schedule with hard restarts.
|
| 201 |
+
|
| 202 |
+
Args:
|
| 203 |
+
optimizer: The optimizer for which to schedule the learning rate
|
| 204 |
+
num_warmup_steps: Number of steps for warmup phase
|
| 205 |
+
num_training_steps: Total number of training steps
|
| 206 |
+
num_cycles: Number of restart cycles
|
| 207 |
+
min_lr_ratio: Minimum learning rate as fraction of peak learning rate
|
| 208 |
+
last_epoch: The index of the last epoch when resuming training
|
| 209 |
+
"""
|
| 210 |
+
lr_lambda = partial(
|
| 211 |
+
_get_cosine_with_restarts_lr_lambda,
|
| 212 |
+
num_warmup_steps=num_warmup_steps,
|
| 213 |
+
num_training_steps=num_training_steps,
|
| 214 |
+
num_cycles=num_cycles,
|
| 215 |
+
min_lr_ratio=min_lr_ratio,
|
| 216 |
+
)
|
| 217 |
+
return LambdaLR(optimizer, lr_lambda, last_epoch=last_epoch)
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
# Scheduler registry for easy lookup
|
| 221 |
+
SCHEDULER_REGISTRY = {
|
| 222 |
+
SchedulerType.WARMUP_STABLE_DECAY: get_warmup_stable_decay_schedule,
|
| 223 |
+
SchedulerType.COSINE_WITH_WARMUP: get_enhanced_cosine_schedule_with_warmup,
|
| 224 |
+
SchedulerType.COSINE_WITH_RESTARTS: get_cosine_with_restarts_schedule,
|
| 225 |
+
}
|
| 226 |
+
|
| 227 |
+
|
| 228 |
+
def get_scheduler(
|
| 229 |
+
scheduler_type: str | SchedulerType,
|
| 230 |
+
optimizer: Optimizer,
|
| 231 |
+
num_warmup_steps: int,
|
| 232 |
+
num_training_steps: int,
|
| 233 |
+
scheduler_kwargs: Optional[dict] = None,
|
| 234 |
+
):
|
| 235 |
+
"""
|
| 236 |
+
Unified interface to create learning rate schedulers.
|
| 237 |
+
|
| 238 |
+
Args:
|
| 239 |
+
scheduler_type: Type of scheduler to create
|
| 240 |
+
optimizer: The optimizer to schedule
|
| 241 |
+
num_warmup_steps: Number of warmup steps
|
| 242 |
+
num_training_steps: Total training steps
|
| 243 |
+
scheduler_kwargs: Additional scheduler-specific parameters
|
| 244 |
+
|
| 245 |
+
Returns:
|
| 246 |
+
Configured learning rate scheduler
|
| 247 |
+
"""
|
| 248 |
+
if isinstance(scheduler_type, str):
|
| 249 |
+
scheduler_type = SchedulerType(scheduler_type)
|
| 250 |
+
|
| 251 |
+
if scheduler_kwargs is None:
|
| 252 |
+
scheduler_kwargs = {}
|
| 253 |
+
|
| 254 |
+
if scheduler_type not in SCHEDULER_REGISTRY:
|
| 255 |
+
raise ValueError(f"Unsupported scheduler type: {scheduler_type}")
|
| 256 |
+
|
| 257 |
+
scheduler_func = SCHEDULER_REGISTRY[scheduler_type]
|
| 258 |
+
return scheduler_func(
|
| 259 |
+
optimizer=optimizer,
|
| 260 |
+
num_warmup_steps=num_warmup_steps,
|
| 261 |
+
num_training_steps=num_training_steps,
|
| 262 |
+
**scheduler_kwargs,
|
| 263 |
+
)
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
class WarmupStableDecayScheduler:
|
| 267 |
+
"""
|
| 268 |
+
Alternative implementation as a standalone scheduler class.
|
| 269 |
+
|
| 270 |
+
This provides more flexibility and better state management for
|
| 271 |
+
complex training scenarios with checkpointing.
|
| 272 |
+
"""
|
| 273 |
+
|
| 274 |
+
def __init__(
|
| 275 |
+
self,
|
| 276 |
+
optimizer: Optimizer,
|
| 277 |
+
num_warmup_steps: int,
|
| 278 |
+
num_stable_steps: int,
|
| 279 |
+
total_steps: int,
|
| 280 |
+
min_lr_ratio: float = 0.01,
|
| 281 |
+
decay_type: str = "cosine",
|
| 282 |
+
verbose: bool = False,
|
| 283 |
+
):
|
| 284 |
+
self.optimizer = optimizer
|
| 285 |
+
self.num_warmup_steps = num_warmup_steps
|
| 286 |
+
self.num_stable_steps = num_stable_steps
|
| 287 |
+
self.total_steps = total_steps
|
| 288 |
+
self.min_lr_ratio = min_lr_ratio
|
| 289 |
+
self.decay_type = decay_type
|
| 290 |
+
self.verbose = verbose
|
| 291 |
+
|
| 292 |
+
# Store initial learning rates
|
| 293 |
+
self.base_lrs = [group["lr"] for group in optimizer.param_groups]
|
| 294 |
+
self.current_step = 0
|
| 295 |
+
|
| 296 |
+
def get_lr_factor(self, step: int) -> float:
|
| 297 |
+
"""Calculate the learning rate multiplication factor for given step."""
|
| 298 |
+
if step < self.num_warmup_steps:
|
| 299 |
+
# Warmup phase
|
| 300 |
+
return step / max(1, self.num_warmup_steps)
|
| 301 |
+
elif step < self.num_warmup_steps + self.num_stable_steps:
|
| 302 |
+
# Stable phase
|
| 303 |
+
return 1.0
|
| 304 |
+
else:
|
| 305 |
+
# Decay phase
|
| 306 |
+
decay_steps = (
|
| 307 |
+
self.total_steps - self.num_warmup_steps - self.num_stable_steps
|
| 308 |
+
)
|
| 309 |
+
if decay_steps <= 0:
|
| 310 |
+
return max(self.min_lr_ratio, 1.0)
|
| 311 |
+
|
| 312 |
+
progress = (
|
| 313 |
+
step - self.num_warmup_steps - self.num_stable_steps
|
| 314 |
+
) / decay_steps
|
| 315 |
+
progress = min(progress, 1.0)
|
| 316 |
+
|
| 317 |
+
if self.decay_type == "cosine":
|
| 318 |
+
decay_factor = 0.5 * (1.0 + math.cos(math.pi * progress))
|
| 319 |
+
elif self.decay_type == "linear":
|
| 320 |
+
decay_factor = 1.0 - progress
|
| 321 |
+
else:
|
| 322 |
+
raise ValueError(f"Unknown decay_type: {self.decay_type}")
|
| 323 |
+
|
| 324 |
+
return max(self.min_lr_ratio, decay_factor)
|
| 325 |
+
|
| 326 |
+
def step(self):
|
| 327 |
+
"""Update learning rates for all parameter groups."""
|
| 328 |
+
lr_factor = self.get_lr_factor(self.current_step)
|
| 329 |
+
|
| 330 |
+
for param_group, base_lr in zip(self.optimizer.param_groups, self.base_lrs):
|
| 331 |
+
param_group["lr"] = base_lr * lr_factor
|
| 332 |
+
|
| 333 |
+
if self.verbose and self.current_step % 1000 == 0:
|
| 334 |
+
phase = self.get_phase()
|
| 335 |
+
print(
|
| 336 |
+
f"Step {self.current_step}: LR factor = {lr_factor:.6f}, Phase = {phase}"
|
| 337 |
+
)
|
| 338 |
+
|
| 339 |
+
self.current_step += 1
|
| 340 |
+
|
| 341 |
+
def get_phase(self) -> str:
|
| 342 |
+
"""Get current training phase."""
|
| 343 |
+
if self.current_step < self.num_warmup_steps:
|
| 344 |
+
return "warmup"
|
| 345 |
+
elif self.current_step < self.num_warmup_steps + self.num_stable_steps:
|
| 346 |
+
return "stable"
|
| 347 |
+
else:
|
| 348 |
+
return "decay"
|
| 349 |
+
|
| 350 |
+
def state_dict(self) -> dict:
|
| 351 |
+
"""Return scheduler state for checkpointing."""
|
| 352 |
+
return {
|
| 353 |
+
"current_step": self.current_step,
|
| 354 |
+
"base_lrs": self.base_lrs,
|
| 355 |
+
}
|
| 356 |
+
|
| 357 |
+
def load_state_dict(self, state_dict: dict):
|
| 358 |
+
"""Load scheduler state from checkpoint."""
|
| 359 |
+
self.current_step = state_dict["current_step"]
|
| 360 |
+
self.base_lrs = state_dict["base_lrs"]
|
src/plotting/__init__.py
ADDED
|
File without changes
|
src/plotting/gift_eval_utils.py
ADDED
|
@@ -0,0 +1,215 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
from typing import List, Optional, Tuple
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import pandas as pd
|
| 6 |
+
from gluonts.model.forecast import QuantileForecast
|
| 7 |
+
|
| 8 |
+
from src.data.frequency import parse_frequency
|
| 9 |
+
from src.plotting.plot_timeseries import (
|
| 10 |
+
plot_multivariate_timeseries,
|
| 11 |
+
)
|
| 12 |
+
|
| 13 |
+
logger = logging.getLogger(__name__)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def _prepare_data_for_plotting(
|
| 17 |
+
input_data: dict, label_data: dict, max_context_length: int
|
| 18 |
+
):
|
| 19 |
+
history_values = np.asarray(input_data["target"], dtype=np.float32)
|
| 20 |
+
future_values = np.asarray(label_data["target"], dtype=np.float32)
|
| 21 |
+
start_period = input_data["start"]
|
| 22 |
+
|
| 23 |
+
def ensure_time_first(arr: np.ndarray) -> np.ndarray:
|
| 24 |
+
if arr.ndim == 1:
|
| 25 |
+
return arr.reshape(-1, 1)
|
| 26 |
+
elif arr.ndim == 2:
|
| 27 |
+
if arr.shape[0] < arr.shape[1]:
|
| 28 |
+
return arr.T
|
| 29 |
+
return arr
|
| 30 |
+
else:
|
| 31 |
+
return arr.reshape(arr.shape[-1], -1).T
|
| 32 |
+
|
| 33 |
+
history_values = ensure_time_first(history_values)
|
| 34 |
+
future_values = ensure_time_first(future_values)
|
| 35 |
+
|
| 36 |
+
if max_context_length is not None and history_values.shape[0] > max_context_length:
|
| 37 |
+
history_values = history_values[-max_context_length:]
|
| 38 |
+
|
| 39 |
+
# Convert Period to Timestamp if needed
|
| 40 |
+
start_timestamp = (
|
| 41 |
+
start_period.to_timestamp()
|
| 42 |
+
if hasattr(start_period, "to_timestamp")
|
| 43 |
+
else pd.Timestamp(start_period)
|
| 44 |
+
)
|
| 45 |
+
return history_values, future_values, start_timestamp
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def _extract_quantile_predictions(
|
| 49 |
+
forecast,
|
| 50 |
+
) -> Tuple[Optional[np.ndarray], Optional[np.ndarray], Optional[np.ndarray]]:
|
| 51 |
+
def ensure_2d_time_first(arr):
|
| 52 |
+
if arr is None:
|
| 53 |
+
return None
|
| 54 |
+
arr = np.asarray(arr)
|
| 55 |
+
if arr.ndim == 1:
|
| 56 |
+
return arr.reshape(-1, 1)
|
| 57 |
+
elif arr.ndim == 2:
|
| 58 |
+
return arr
|
| 59 |
+
else:
|
| 60 |
+
return arr.reshape(arr.shape[0], -1)
|
| 61 |
+
|
| 62 |
+
if isinstance(forecast, QuantileForecast):
|
| 63 |
+
try:
|
| 64 |
+
median_pred = forecast.quantile(0.5)
|
| 65 |
+
try:
|
| 66 |
+
lower_bound = forecast.quantile(0.1)
|
| 67 |
+
upper_bound = forecast.quantile(0.9)
|
| 68 |
+
except (KeyError, ValueError):
|
| 69 |
+
lower_bound = None
|
| 70 |
+
upper_bound = None
|
| 71 |
+
median_pred = ensure_2d_time_first(median_pred)
|
| 72 |
+
lower_bound = ensure_2d_time_first(lower_bound)
|
| 73 |
+
upper_bound = ensure_2d_time_first(upper_bound)
|
| 74 |
+
return median_pred, lower_bound, upper_bound
|
| 75 |
+
except Exception:
|
| 76 |
+
try:
|
| 77 |
+
median_pred = forecast.quantile(0.5)
|
| 78 |
+
median_pred = ensure_2d_time_first(median_pred)
|
| 79 |
+
return median_pred, None, None
|
| 80 |
+
except Exception:
|
| 81 |
+
return None, None, None
|
| 82 |
+
else:
|
| 83 |
+
try:
|
| 84 |
+
samples = forecast.samples
|
| 85 |
+
if samples.ndim == 1:
|
| 86 |
+
median_pred = samples
|
| 87 |
+
elif samples.ndim == 2:
|
| 88 |
+
if samples.shape[0] == 1:
|
| 89 |
+
median_pred = samples[0]
|
| 90 |
+
else:
|
| 91 |
+
median_pred = np.median(samples, axis=0)
|
| 92 |
+
elif samples.ndim == 3:
|
| 93 |
+
median_pred = np.median(samples, axis=0)
|
| 94 |
+
else:
|
| 95 |
+
median_pred = samples[0] if len(samples) > 0 else samples
|
| 96 |
+
median_pred = ensure_2d_time_first(median_pred)
|
| 97 |
+
return median_pred, None, None
|
| 98 |
+
except Exception:
|
| 99 |
+
return None, None, None
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def _create_plot(
|
| 103 |
+
input_data: dict,
|
| 104 |
+
label_data: dict,
|
| 105 |
+
forecast,
|
| 106 |
+
dataset_full_name: str,
|
| 107 |
+
dataset_freq: str,
|
| 108 |
+
max_context_length: int,
|
| 109 |
+
title: Optional[str] = None,
|
| 110 |
+
):
|
| 111 |
+
try:
|
| 112 |
+
history_values, future_values, start_timestamp = _prepare_data_for_plotting(
|
| 113 |
+
input_data, label_data, max_context_length
|
| 114 |
+
)
|
| 115 |
+
median_pred, lower_bound, upper_bound = _extract_quantile_predictions(forecast)
|
| 116 |
+
if median_pred is None:
|
| 117 |
+
logger.warning(f"Could not extract predictions for {dataset_full_name}")
|
| 118 |
+
return None
|
| 119 |
+
|
| 120 |
+
def ensure_compatible_shape(pred_arr, target_arr):
|
| 121 |
+
if pred_arr is None:
|
| 122 |
+
return None
|
| 123 |
+
pred_arr = np.asarray(pred_arr)
|
| 124 |
+
target_arr = np.asarray(target_arr)
|
| 125 |
+
if pred_arr.ndim == 1:
|
| 126 |
+
pred_arr = pred_arr.reshape(-1, 1)
|
| 127 |
+
if target_arr.ndim == 1:
|
| 128 |
+
target_arr = target_arr.reshape(-1, 1)
|
| 129 |
+
if pred_arr.shape != target_arr.shape:
|
| 130 |
+
if pred_arr.shape[0] == target_arr.shape[0]:
|
| 131 |
+
if pred_arr.shape[1] == 1 and target_arr.shape[1] > 1:
|
| 132 |
+
pred_arr = np.broadcast_to(pred_arr, target_arr.shape)
|
| 133 |
+
elif pred_arr.shape[1] > 1 and target_arr.shape[1] == 1:
|
| 134 |
+
pred_arr = pred_arr[:, :1]
|
| 135 |
+
elif pred_arr.shape[1] == target_arr.shape[1]:
|
| 136 |
+
min_time = min(pred_arr.shape[0], target_arr.shape[0])
|
| 137 |
+
pred_arr = pred_arr[:min_time]
|
| 138 |
+
else:
|
| 139 |
+
if pred_arr.T.shape == target_arr.shape:
|
| 140 |
+
pred_arr = pred_arr.T
|
| 141 |
+
else:
|
| 142 |
+
if pred_arr.size >= target_arr.shape[0]:
|
| 143 |
+
pred_arr = pred_arr.flatten()[
|
| 144 |
+
: target_arr.shape[0]
|
| 145 |
+
].reshape(-1, 1)
|
| 146 |
+
if target_arr.shape[1] > 1:
|
| 147 |
+
pred_arr = np.broadcast_to(pred_arr, target_arr.shape)
|
| 148 |
+
return pred_arr
|
| 149 |
+
|
| 150 |
+
median_pred = ensure_compatible_shape(median_pred, future_values)
|
| 151 |
+
lower_bound = ensure_compatible_shape(lower_bound, future_values)
|
| 152 |
+
upper_bound = ensure_compatible_shape(upper_bound, future_values)
|
| 153 |
+
|
| 154 |
+
title = title or f"GIFT-Eval: {dataset_full_name}"
|
| 155 |
+
frequency = parse_frequency(dataset_freq)
|
| 156 |
+
fig = plot_multivariate_timeseries(
|
| 157 |
+
history_values=history_values,
|
| 158 |
+
future_values=future_values,
|
| 159 |
+
predicted_values=median_pred,
|
| 160 |
+
lower_bound=lower_bound,
|
| 161 |
+
upper_bound=upper_bound,
|
| 162 |
+
start=start_timestamp,
|
| 163 |
+
frequency=frequency,
|
| 164 |
+
title=title,
|
| 165 |
+
show=False,
|
| 166 |
+
)
|
| 167 |
+
return fig
|
| 168 |
+
except Exception as e:
|
| 169 |
+
logger.warning(f"Failed to create plot for {dataset_full_name}: {e}")
|
| 170 |
+
return None
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
def create_plots_for_dataset(
|
| 174 |
+
forecasts: List,
|
| 175 |
+
test_data,
|
| 176 |
+
dataset_metadata,
|
| 177 |
+
max_plots: int,
|
| 178 |
+
max_context_length: int,
|
| 179 |
+
) -> List[Tuple[object, str]]:
|
| 180 |
+
input_data_list = list(test_data.input)
|
| 181 |
+
label_data_list = list(test_data.label)
|
| 182 |
+
num_plots = min(len(forecasts), max_plots)
|
| 183 |
+
logger.info(
|
| 184 |
+
f"Creating {num_plots} plots for {getattr(dataset_metadata, 'full_name', str(dataset_metadata))}"
|
| 185 |
+
)
|
| 186 |
+
|
| 187 |
+
figures_with_names: List[Tuple[object, str]] = []
|
| 188 |
+
for i in range(num_plots):
|
| 189 |
+
try:
|
| 190 |
+
forecast = forecasts[i]
|
| 191 |
+
input_data = input_data_list[i]
|
| 192 |
+
label_data = label_data_list[i]
|
| 193 |
+
title = (
|
| 194 |
+
f"GIFT-Eval: {dataset_metadata.full_name} - Window {i + 1}/{num_plots}"
|
| 195 |
+
if hasattr(dataset_metadata, "full_name")
|
| 196 |
+
else f"Window {i + 1}/{num_plots}"
|
| 197 |
+
)
|
| 198 |
+
fig = _create_plot(
|
| 199 |
+
input_data=input_data,
|
| 200 |
+
label_data=label_data,
|
| 201 |
+
forecast=forecast,
|
| 202 |
+
dataset_full_name=getattr(dataset_metadata, "full_name", "dataset"),
|
| 203 |
+
dataset_freq=getattr(dataset_metadata, "freq", "D"),
|
| 204 |
+
max_context_length=max_context_length,
|
| 205 |
+
title=title,
|
| 206 |
+
)
|
| 207 |
+
if fig is not None:
|
| 208 |
+
filename = (
|
| 209 |
+
f"{getattr(dataset_metadata, 'freq', 'D')}_window_{i + 1:03d}.png"
|
| 210 |
+
)
|
| 211 |
+
figures_with_names.append((fig, filename))
|
| 212 |
+
except Exception as e:
|
| 213 |
+
logger.warning(f"Error creating plot for window {i + 1}: {e}")
|
| 214 |
+
continue
|
| 215 |
+
return figures_with_names
|
src/plotting/plot_timeseries.py
ADDED
|
@@ -0,0 +1,292 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
from typing import List, Optional, Tuple, Union
|
| 3 |
+
|
| 4 |
+
import matplotlib.pyplot as plt
|
| 5 |
+
import numpy as np
|
| 6 |
+
import pandas as pd
|
| 7 |
+
import torch
|
| 8 |
+
import torchmetrics
|
| 9 |
+
from matplotlib.figure import Figure
|
| 10 |
+
|
| 11 |
+
from src.data.containers import BatchTimeSeriesContainer
|
| 12 |
+
from src.data.frequency import Frequency
|
| 13 |
+
|
| 14 |
+
logger = logging.getLogger(__name__)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def calculate_smape(y_true: np.ndarray, y_pred: np.ndarray) -> float:
|
| 18 |
+
"""Calculate Symmetric Mean Absolute Percentage Error (SMAPE)."""
|
| 19 |
+
pred_tensor = torch.from_numpy(y_pred).float()
|
| 20 |
+
true_tensor = torch.from_numpy(y_true).float()
|
| 21 |
+
return torchmetrics.SymmetricMeanAbsolutePercentageError()(
|
| 22 |
+
pred_tensor, true_tensor
|
| 23 |
+
).item()
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def _create_date_ranges(
|
| 27 |
+
start: Optional[Union[np.datetime64, pd.Timestamp]],
|
| 28 |
+
frequency: Optional[Union[Frequency, str]],
|
| 29 |
+
history_length: int,
|
| 30 |
+
prediction_length: int,
|
| 31 |
+
) -> Tuple[pd.DatetimeIndex, pd.DatetimeIndex]:
|
| 32 |
+
"""Create date ranges for history and future periods."""
|
| 33 |
+
if start is not None and frequency is not None:
|
| 34 |
+
start_timestamp = pd.Timestamp(start)
|
| 35 |
+
pandas_freq = frequency.to_pandas_freq(for_date_range=True)
|
| 36 |
+
|
| 37 |
+
history_dates = pd.date_range(
|
| 38 |
+
start=start_timestamp, periods=history_length, freq=pandas_freq
|
| 39 |
+
)
|
| 40 |
+
|
| 41 |
+
if prediction_length > 0:
|
| 42 |
+
next_timestamp = history_dates[-1] + pd.tseries.frequencies.to_offset(
|
| 43 |
+
pandas_freq
|
| 44 |
+
)
|
| 45 |
+
future_dates = pd.date_range(
|
| 46 |
+
start=next_timestamp, periods=prediction_length, freq=pandas_freq
|
| 47 |
+
)
|
| 48 |
+
else:
|
| 49 |
+
future_dates = pd.DatetimeIndex([])
|
| 50 |
+
else:
|
| 51 |
+
# Fallback to default daily frequency
|
| 52 |
+
history_dates = pd.date_range(
|
| 53 |
+
end=pd.Timestamp.now(), periods=history_length, freq="D"
|
| 54 |
+
)
|
| 55 |
+
|
| 56 |
+
if prediction_length > 0:
|
| 57 |
+
future_dates = pd.date_range(
|
| 58 |
+
start=history_dates[-1] + pd.Timedelta(days=1),
|
| 59 |
+
periods=prediction_length,
|
| 60 |
+
freq="D",
|
| 61 |
+
)
|
| 62 |
+
else:
|
| 63 |
+
future_dates = pd.DatetimeIndex([])
|
| 64 |
+
|
| 65 |
+
return history_dates, future_dates
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def _plot_single_channel(
|
| 69 |
+
ax: plt.Axes,
|
| 70 |
+
channel_idx: int,
|
| 71 |
+
history_dates: pd.DatetimeIndex,
|
| 72 |
+
future_dates: pd.DatetimeIndex,
|
| 73 |
+
history_values: np.ndarray,
|
| 74 |
+
future_values: Optional[np.ndarray] = None,
|
| 75 |
+
predicted_values: Optional[np.ndarray] = None,
|
| 76 |
+
lower_bound: Optional[np.ndarray] = None,
|
| 77 |
+
upper_bound: Optional[np.ndarray] = None,
|
| 78 |
+
) -> None:
|
| 79 |
+
"""Plot a single channel's time series data."""
|
| 80 |
+
# Plot history
|
| 81 |
+
ax.plot(
|
| 82 |
+
history_dates, history_values[:, channel_idx], color="black", label="History"
|
| 83 |
+
)
|
| 84 |
+
|
| 85 |
+
# Plot ground truth future
|
| 86 |
+
if future_values is not None:
|
| 87 |
+
ax.plot(
|
| 88 |
+
future_dates,
|
| 89 |
+
future_values[:, channel_idx],
|
| 90 |
+
color="blue",
|
| 91 |
+
label="Ground Truth",
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
# Plot predictions
|
| 95 |
+
if predicted_values is not None:
|
| 96 |
+
ax.plot(
|
| 97 |
+
future_dates,
|
| 98 |
+
predicted_values[:, channel_idx],
|
| 99 |
+
color="orange",
|
| 100 |
+
linestyle="--",
|
| 101 |
+
label="Prediction (Median)",
|
| 102 |
+
)
|
| 103 |
+
|
| 104 |
+
# Plot uncertainty band
|
| 105 |
+
if lower_bound is not None and upper_bound is not None:
|
| 106 |
+
ax.fill_between(
|
| 107 |
+
future_dates,
|
| 108 |
+
lower_bound[:, channel_idx],
|
| 109 |
+
upper_bound[:, channel_idx],
|
| 110 |
+
color="orange",
|
| 111 |
+
alpha=0.2,
|
| 112 |
+
label="Uncertainty Band",
|
| 113 |
+
)
|
| 114 |
+
|
| 115 |
+
ax.set_title(f"Channel {channel_idx + 1}")
|
| 116 |
+
ax.grid(True, which="both", linestyle="--", linewidth=0.5)
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
def _setup_figure(num_channels: int) -> Tuple[Figure, List[plt.Axes]]:
|
| 120 |
+
"""Create and configure the matplotlib figure and axes."""
|
| 121 |
+
fig, axes = plt.subplots(
|
| 122 |
+
num_channels, 1, figsize=(15, 3 * num_channels), sharex=True
|
| 123 |
+
)
|
| 124 |
+
if num_channels == 1:
|
| 125 |
+
axes = [axes]
|
| 126 |
+
return fig, axes
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
def _finalize_plot(
|
| 130 |
+
fig: Figure,
|
| 131 |
+
axes: List[plt.Axes],
|
| 132 |
+
title: Optional[str] = None,
|
| 133 |
+
smape_value: Optional[float] = None,
|
| 134 |
+
output_file: Optional[str] = None,
|
| 135 |
+
show: bool = True,
|
| 136 |
+
) -> None:
|
| 137 |
+
"""Add legend, title, and save/show the plot."""
|
| 138 |
+
# Create legend from first axis
|
| 139 |
+
handles, labels = axes[0].get_legend_handles_labels()
|
| 140 |
+
fig.legend(handles, labels, loc="upper right")
|
| 141 |
+
|
| 142 |
+
# Set title with optional SMAPE
|
| 143 |
+
if title:
|
| 144 |
+
if smape_value is not None:
|
| 145 |
+
title = f"{title} | SMAPE: {smape_value:.4f}"
|
| 146 |
+
fig.suptitle(title, fontsize=16)
|
| 147 |
+
|
| 148 |
+
# Adjust layout
|
| 149 |
+
plt.tight_layout(rect=[0, 0.03, 1, 0.95] if title else None)
|
| 150 |
+
|
| 151 |
+
# Save and/or show
|
| 152 |
+
if output_file:
|
| 153 |
+
plt.savefig(output_file, dpi=300)
|
| 154 |
+
if show:
|
| 155 |
+
plt.show()
|
| 156 |
+
else:
|
| 157 |
+
plt.close(fig)
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
def plot_multivariate_timeseries(
|
| 161 |
+
history_values: np.ndarray,
|
| 162 |
+
future_values: Optional[np.ndarray] = None,
|
| 163 |
+
predicted_values: Optional[np.ndarray] = None,
|
| 164 |
+
start: Optional[Union[np.datetime64, pd.Timestamp]] = None,
|
| 165 |
+
frequency: Optional[Union[Frequency, str]] = None,
|
| 166 |
+
title: Optional[str] = None,
|
| 167 |
+
output_file: Optional[str] = None,
|
| 168 |
+
show: bool = True,
|
| 169 |
+
lower_bound: Optional[np.ndarray] = None,
|
| 170 |
+
upper_bound: Optional[np.ndarray] = None,
|
| 171 |
+
) -> Figure:
|
| 172 |
+
"""Plot a multivariate time series with history, future, predictions, and uncertainty bands."""
|
| 173 |
+
# Calculate SMAPE if both predicted and true values are available
|
| 174 |
+
smape_value = None
|
| 175 |
+
if predicted_values is not None and future_values is not None:
|
| 176 |
+
try:
|
| 177 |
+
smape_value = calculate_smape(future_values, predicted_values)
|
| 178 |
+
except Exception as e:
|
| 179 |
+
logger.warning(f"Failed to calculate SMAPE: {str(e)}")
|
| 180 |
+
|
| 181 |
+
# Extract dimensions
|
| 182 |
+
num_channels = history_values.shape[1]
|
| 183 |
+
history_length = history_values.shape[0]
|
| 184 |
+
prediction_length = (
|
| 185 |
+
predicted_values.shape[0]
|
| 186 |
+
if predicted_values is not None
|
| 187 |
+
else (future_values.shape[0] if future_values is not None else 0)
|
| 188 |
+
)
|
| 189 |
+
|
| 190 |
+
# Create date ranges
|
| 191 |
+
history_dates, future_dates = _create_date_ranges(
|
| 192 |
+
start, frequency, history_length, prediction_length
|
| 193 |
+
)
|
| 194 |
+
|
| 195 |
+
# Setup figure
|
| 196 |
+
fig, axes = _setup_figure(num_channels)
|
| 197 |
+
|
| 198 |
+
# Plot each channel
|
| 199 |
+
for i in range(num_channels):
|
| 200 |
+
_plot_single_channel(
|
| 201 |
+
ax=axes[i],
|
| 202 |
+
channel_idx=i,
|
| 203 |
+
history_dates=history_dates,
|
| 204 |
+
future_dates=future_dates,
|
| 205 |
+
history_values=history_values,
|
| 206 |
+
future_values=future_values,
|
| 207 |
+
predicted_values=predicted_values,
|
| 208 |
+
lower_bound=lower_bound,
|
| 209 |
+
upper_bound=upper_bound,
|
| 210 |
+
)
|
| 211 |
+
|
| 212 |
+
# Finalize plot
|
| 213 |
+
_finalize_plot(fig, axes, title, smape_value, output_file, show)
|
| 214 |
+
|
| 215 |
+
return fig
|
| 216 |
+
|
| 217 |
+
|
| 218 |
+
def _extract_quantile_predictions(
|
| 219 |
+
predicted_values: np.ndarray,
|
| 220 |
+
model_quantiles: List[float],
|
| 221 |
+
) -> Tuple[Optional[np.ndarray], Optional[np.ndarray], Optional[np.ndarray]]:
|
| 222 |
+
"""Extract median, lower, and upper bound predictions from quantile output."""
|
| 223 |
+
try:
|
| 224 |
+
median_idx = model_quantiles.index(0.5)
|
| 225 |
+
lower_idx = model_quantiles.index(0.1)
|
| 226 |
+
upper_idx = model_quantiles.index(0.9)
|
| 227 |
+
|
| 228 |
+
median_preds = predicted_values[..., median_idx]
|
| 229 |
+
lower_bound = predicted_values[..., lower_idx]
|
| 230 |
+
upper_bound = predicted_values[..., upper_idx]
|
| 231 |
+
|
| 232 |
+
return median_preds, lower_bound, upper_bound
|
| 233 |
+
except (ValueError, IndexError):
|
| 234 |
+
logger.warning(
|
| 235 |
+
"Could not find 0.1, 0.5, 0.9 quantiles for plotting. Using median of available quantiles."
|
| 236 |
+
)
|
| 237 |
+
median_preds = predicted_values[..., predicted_values.shape[-1] // 2]
|
| 238 |
+
return median_preds, None, None
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
def plot_from_container(
|
| 242 |
+
batch: BatchTimeSeriesContainer,
|
| 243 |
+
sample_idx: int,
|
| 244 |
+
predicted_values: Optional[np.ndarray] = None,
|
| 245 |
+
model_quantiles: Optional[List[float]] = None,
|
| 246 |
+
title: Optional[str] = None,
|
| 247 |
+
output_file: Optional[str] = None,
|
| 248 |
+
show: bool = True,
|
| 249 |
+
) -> Figure:
|
| 250 |
+
"""Plot a single sample from a BatchTimeSeriesContainer with proper quantile handling."""
|
| 251 |
+
# Extract data for the specific sample
|
| 252 |
+
history_values = batch.history_values[sample_idx].cpu().numpy()
|
| 253 |
+
future_values = batch.future_values[sample_idx].cpu().numpy()
|
| 254 |
+
|
| 255 |
+
# Process predictions
|
| 256 |
+
if predicted_values is not None:
|
| 257 |
+
# Handle batch vs single sample predictions
|
| 258 |
+
if predicted_values.ndim >= 3 or (
|
| 259 |
+
predicted_values.ndim == 2
|
| 260 |
+
and predicted_values.shape[0] > future_values.shape[0]
|
| 261 |
+
):
|
| 262 |
+
sample_preds = predicted_values[sample_idx]
|
| 263 |
+
else:
|
| 264 |
+
sample_preds = predicted_values
|
| 265 |
+
|
| 266 |
+
# Extract quantile information if available
|
| 267 |
+
if model_quantiles:
|
| 268 |
+
median_preds, lower_bound, upper_bound = _extract_quantile_predictions(
|
| 269 |
+
sample_preds, model_quantiles
|
| 270 |
+
)
|
| 271 |
+
else:
|
| 272 |
+
median_preds = sample_preds
|
| 273 |
+
lower_bound = None
|
| 274 |
+
upper_bound = None
|
| 275 |
+
else:
|
| 276 |
+
median_preds = None
|
| 277 |
+
lower_bound = None
|
| 278 |
+
upper_bound = None
|
| 279 |
+
|
| 280 |
+
# Create the plot
|
| 281 |
+
return plot_multivariate_timeseries(
|
| 282 |
+
history_values=history_values,
|
| 283 |
+
future_values=future_values,
|
| 284 |
+
predicted_values=median_preds,
|
| 285 |
+
start=batch.start[sample_idx],
|
| 286 |
+
frequency=batch.frequency[sample_idx],
|
| 287 |
+
title=title,
|
| 288 |
+
output_file=output_file,
|
| 289 |
+
show=show,
|
| 290 |
+
lower_bound=lower_bound,
|
| 291 |
+
upper_bound=upper_bound,
|
| 292 |
+
)
|
src/synthetic_generation/__init__.py
ADDED
|
File without changes
|
src/synthetic_generation/abstract_classes.py
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from abc import ABC, abstractmethod
|
| 2 |
+
from typing import Any, Dict, Optional
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
|
| 7 |
+
from src.data.containers import TimeSeriesContainer
|
| 8 |
+
from src.data.frequency import (
|
| 9 |
+
select_safe_random_frequency,
|
| 10 |
+
select_safe_start_date,
|
| 11 |
+
)
|
| 12 |
+
from src.synthetic_generation.generator_params import GeneratorParams
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class AbstractTimeSeriesGenerator(ABC):
|
| 16 |
+
"""
|
| 17 |
+
Abstract base class for synthetic time series generators.
|
| 18 |
+
"""
|
| 19 |
+
|
| 20 |
+
@abstractmethod
|
| 21 |
+
def generate_time_series(self, random_seed: Optional[int] = None) -> np.ndarray:
|
| 22 |
+
"""
|
| 23 |
+
Generate synthetic time series data.
|
| 24 |
+
|
| 25 |
+
Parameters
|
| 26 |
+
----------
|
| 27 |
+
random_seed : int, optional
|
| 28 |
+
Random seed for reproducibility.
|
| 29 |
+
|
| 30 |
+
Returns
|
| 31 |
+
-------
|
| 32 |
+
np.ndarray
|
| 33 |
+
Time series values of shape (length,) for univariate or
|
| 34 |
+
(length, num_channels) for multivariate time series.
|
| 35 |
+
"""
|
| 36 |
+
pass
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
class GeneratorWrapper:
|
| 40 |
+
"""
|
| 41 |
+
Unified base class for all generator wrappers, using a GeneratorParams dataclass
|
| 42 |
+
for configuration. Provides parameter sampling, validation, and batch formatting utilities.
|
| 43 |
+
"""
|
| 44 |
+
|
| 45 |
+
def __init__(self, params: GeneratorParams):
|
| 46 |
+
"""
|
| 47 |
+
Initialize the GeneratorWrapper with a GeneratorParams dataclass.
|
| 48 |
+
|
| 49 |
+
Parameters
|
| 50 |
+
----------
|
| 51 |
+
params : GeneratorParams
|
| 52 |
+
Dataclass instance containing all generator configuration parameters.
|
| 53 |
+
"""
|
| 54 |
+
self.params = params
|
| 55 |
+
self._set_random_seeds(self.params.global_seed)
|
| 56 |
+
|
| 57 |
+
def _set_random_seeds(self, seed: int) -> None:
|
| 58 |
+
# For parameter sampling, we want diversity across batches even with similar seeds
|
| 59 |
+
# Use a hash of the generator class name to ensure different generators get different parameter sequences
|
| 60 |
+
param_seed = seed + hash(self.__class__.__name__) % 2**31
|
| 61 |
+
self.rng = np.random.default_rng(param_seed)
|
| 62 |
+
|
| 63 |
+
# Set global numpy and torch seeds for deterministic behavior in underlying generators
|
| 64 |
+
np.random.seed(seed)
|
| 65 |
+
torch.manual_seed(seed)
|
| 66 |
+
|
| 67 |
+
def _sample_parameters(self, batch_size: int) -> Dict[str, Any]:
|
| 68 |
+
"""
|
| 69 |
+
Sample parameters with total_length fixed and history_length calculated.
|
| 70 |
+
|
| 71 |
+
Returns
|
| 72 |
+
-------
|
| 73 |
+
Dict[str, Any]
|
| 74 |
+
Dictionary containing sampled parameter values where
|
| 75 |
+
history_length = total_length - future_length.
|
| 76 |
+
"""
|
| 77 |
+
|
| 78 |
+
# Select a suitable frequency based on the total length
|
| 79 |
+
frequency = [
|
| 80 |
+
select_safe_random_frequency(self.params.length, self.rng)
|
| 81 |
+
for _ in range(batch_size)
|
| 82 |
+
]
|
| 83 |
+
start = [
|
| 84 |
+
select_safe_start_date(self.params.length, frequency[i], self.rng)
|
| 85 |
+
for i in range(batch_size)
|
| 86 |
+
]
|
| 87 |
+
|
| 88 |
+
return {
|
| 89 |
+
"frequency": frequency,
|
| 90 |
+
"start": start,
|
| 91 |
+
}
|
| 92 |
+
|
| 93 |
+
@abstractmethod
|
| 94 |
+
def generate_batch(
|
| 95 |
+
self, batch_size: int, seed: Optional[int] = None, **kwargs
|
| 96 |
+
) -> TimeSeriesContainer:
|
| 97 |
+
raise NotImplementedError("Subclasses must implement generate_batch()")
|